
Kurs
Einführung in MongoDB mit Python
3 Std.
24K
Da künstliche Intelligenz jede Branche infiltriert und umgestaltet, liegt das Hauptaugenmerk immer auf neuen Features und Funktionen, aber was passiert eigentlich hinter den Kulissen? Hinter jeder KI-Anwendung steht etwas weniger Glamouröses, aber unglaublich Wichtiges: die Infrastruktur, die sie betreibt. Welche Werkzeuge ermöglichen es also, dass maschinelles Lernen gedeihen kann?
In einer datengesteuerten Welt fängt alles damit an, wie Daten gespeichert werden und vor allem, wie sie durchsucht werden. Hier kommen die Vektordatenbanken ins Spiel.
Was genau ist also eine Vektordatenbank? Eine Vektordatenbank ist eine Datenbank, die speziell dafür entwickelt wurde, Vektoreinbettungen zu speichern und zu durchsuchen. Sie ermöglicht es Entwicklern, verschiedene KI-Funktionen wie semantische Suche, Bilderkennung, Chatbots und vieles mehr zu nutzen.
Aber was genau bedeutet das? Um zu verstehen, was eine Vektordatenbank ist, gehen wir ein paar Schritte zurück. Entmystifizieren wir diese integralen Datenbanken, indem wir uns von Anfang an mit den Grundlagen beschäftigen und mit dem Hauptakteur in diesem Prozess beginnen: der Vektoreinbettung.
Ein Vektor (im Kontext der künstlichen Intelligenz) ist einfach eine Liste von Zahlen, die die semantische Bedeutung eines Bildes, eines Satzes, eines Audios und sogar eines Videos darstellt. Diese Zahlenfolge hilft Computern zu verstehen, wie die einzelnen Daten einander ähneln: Sie platzieren Daten (wie Wörter oder Bilder) als Punkte auf einer "mathematischen Karte", auf der ähnliche Konzepte näher beieinander liegen.
Wir können uns die Vektoreinbettung so vorstellen, als würden wir ein Stück Daten in eine GPS-Koordinate verwandeln - Daten mit ähnlichen Bedeutungen (wie "Hund" und "Welpe") landen in derselben Gegend!
Warum müssen wir unsere Daten in Vektoren umwandeln? Nun, stell dir vor, du versuchst einer Maschine den Unterschied zwischen einer Katze und einem Hund zu erklären. Während der Mensch in der Lage ist, diesen Unterschied zu verstehen, kann eine Maschine nur Zahlen erfassen und verstehen: Es ist unmöglich, deinem Laptop den Unterschied zwischen Toto und Garfield zu erklären.
Indem du deine Daten in spezifische Vektorstrukturen umwandelst, in denen jede Zahl eindeutig nach den Quelldaten geordnet ist, ist deine Maschine in der Lage, Beziehungen zwischen verschiedenen Datenpunkten zu verstehen!
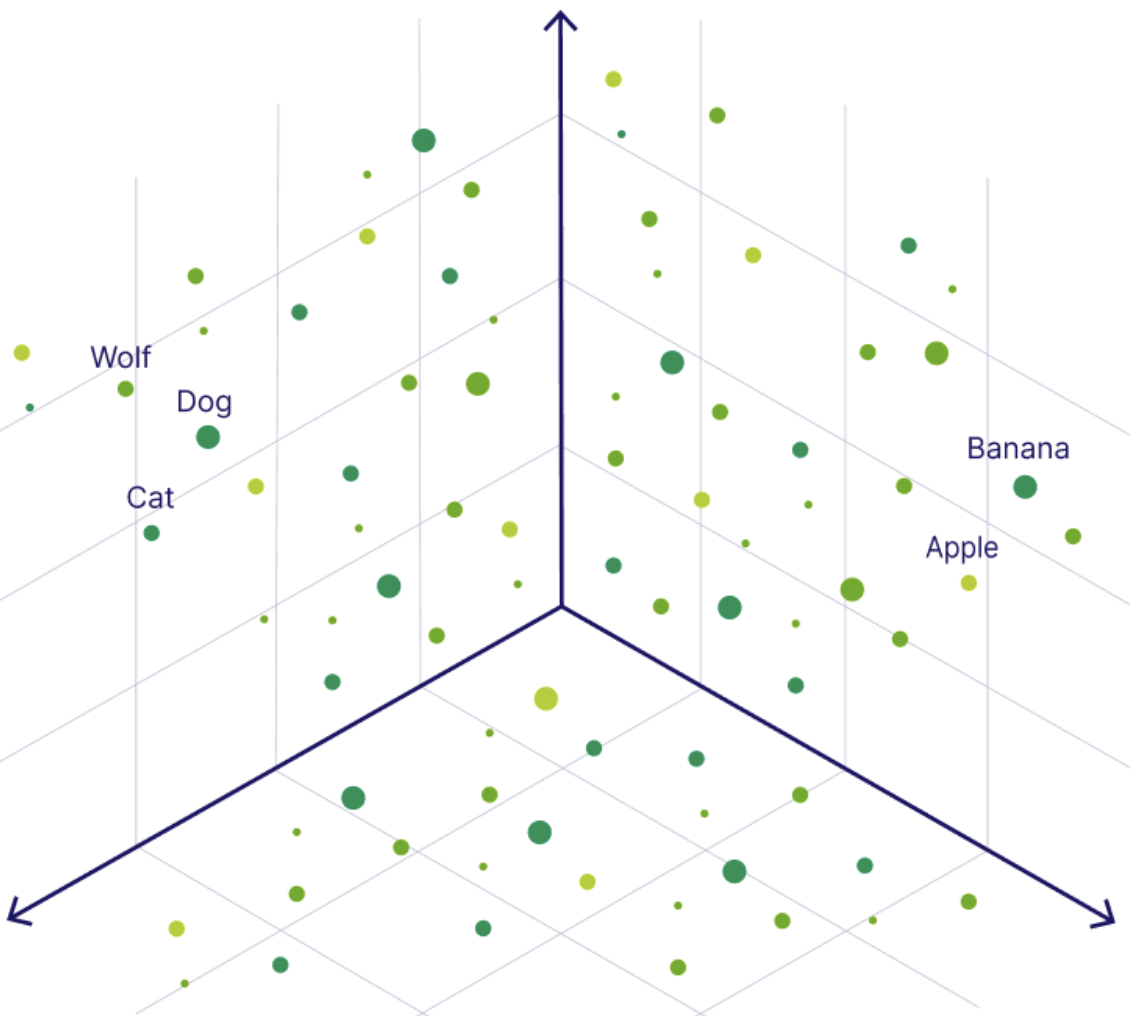
Darstellung einer Vektoreinbettung im mehrdimensionalen Raume. Bildquelle.
Wie das möglich ist, wollen wir anhand der Ähnlichkeitssuche erläutern.
Die Ähnlichkeitssuche ist eine Technik, die dabei hilft, die Dokumente zu finden, die der ursprünglichen Anfrage eines Nutzers am ähnlichsten sind. Die Suche mit Vektoren ist so, als würdest du fragen: "Welches dieser Bilder sieht am ehesten wie eine Katze aus?", anstatt nur das Wort "Katze" genau zu treffen.
Da wir es mit Vektoren in einem mehrdimensionalen Raum zu tun haben, ist ein wenig Mathematik im Spiel, um herauszufinden, welche Einbettungen sich am ähnlichsten sind.
Es gibt eine Vielzahl von Algorithmen für die Ähnlichkeitssuche, aber die drei gängigsten sind:
Die Cosinus-Ähnlichkeitmisst den Winkel zwischen zwei Vektoren (die Größe des Vektors spielt dabei keine Rolle) und wird am häufigsten für Texteinbettungen, semantische Ähnlichkeit und Empfehlungssysteme verwendet. Sie hilft den Entwicklern, die Gesamtrichtung der Vektoren zu vergleichen, was wiederum hilft, den Gesamtinhalt der Dokumente herauszufinden, weshalb sie für die aufgeführten Themen so wichtig ist.
Der euklidische Abstand misstden geradlinigen Abstand zwischen zwei Vektoren im Raum. Eine gute Art, darüber nachzudenken, ist, den kürzesten Weg zwischen zwei Punkten auf einer Karte zu messen!
Dieser Abstand ist der einfachste, denn wenn der berechnete Abstand sehr klein ist, bedeutet das, dass die Vektorkoordinaten sehr nahe beieinander liegen oder einander sehr ähnlich sind.
Da diese Metrik sehr empfindlich auf Größenordnungen reagiert, ist sie am nützlichsten, wenn die Einbettungen mit numerischen Werten zu tun haben. Das ist besonders nützlich für Empfehlungsmaschinen, damit die Nutzer/innen wissen, was sie als Nächstes bestellen sollen, je nachdem, wie oft sie einen Artikel in der Vergangenheit gekauft haben.
Die Punktproduktähnlichkeit misst nicht nur das Produkt der Vektorgrößen, sondern auch den Kosinus des Winkels zwischen ihnen. Das bedeutet, dass das Punktprodukt sowohl die Länge (Betrag) als auch die Richtung von Vektoren berücksichtigt!
Wenn Vektoren normalisiert werden (der Betrag des Vektors ist eins, aber die Richtung bleibt gleich), wird die Ähnlichkeit des Punktprodukts gleich der Ähnlichkeit des Kosinus, da der Betrag nicht mehr berücksichtigt wird.
Die Punktproduktähnlichkeit wird am häufigsten in Bereichen wieder Verarbeitung natürlicher Sprache (NLP) und dem Computersehenverwendet.
Jetzt hast du also deine Rohdaten als Vektoreinbettungen dargestellt. Lass uns in all die unglaublichen Möglichkeiten eintauchen, die sich dadurch ergeben, dass deine Daten durch diese Einbettungen dargestellt werden.
Die semantische Suche ist eine Möglichkeit, Daten auf der Grundlage der tatsächlichen Bedeutung der Anfrage eines Nutzers zu durchsuchen, und nicht nur nach exakten Übereinstimmungen. Das bedeutet, dass anstelle der Suche nach bestimmten Schlüsselwörtern Ergebnisse angezeigt werden, auch wenn ein Wort falsch geschrieben ist, und dass Ergebnisse auf der Grundlage von Synonymen der ursprünglichen Anfrage angezeigt werden.
Wenn ein Nutzer zum Beispiel nach "den besten Cafés in meiner Nähe" sucht, werden bei einer exakten Suche nur speziell gekennzeichnete "Cafés" angezeigt, während eine semantische Suchmaschine Orte mit "Tee", "Kaffee", "Gebäck" oder anderen Ergebnissen, die ein tieferes kontextuelles Verständnis ergeben würden, verstehen und anzeigen würde.
Wie wird diese Suche also möglich gemacht? Vektorielle Einbettungen! Nehmen wir an, wir betten die Anfrage eines Nutzers und die Daten (z. B. Ortsbeschreibungen) ein. Dadurch ist es möglich, sie im mehrdimensionalen Raum miteinander zu vergleichen und mit Methoden wie der Ähnlichkeitssuche nach Vektoren zu suchen, die einander am ähnlichsten sind.
Wenn ein Nutzer zum Beispiel die Anfrage "Die besten Cafés in meiner Nähe" stellt und eine Datenbank mit eingebetteten Google Maps-Beschreibungen hat, zeigt die semantische Suche die Orte an, deren Einbettungen der ursprünglichen Anfrage am ähnlichsten sind - auch wenn das Wort "Café" in diesen Beschreibungen nie vorkommt!
Empfehlungssysteme nutzen Daten, um Menschen dabei zu helfen, das zu finden, was ihnen statistisch gesehen am meisten Spaß machen würde, und zwar auf der Grundlage früherer Einkäufe, des Suchverlaufs, von Umgebungs- und demografischen Informationen und mehr. Sie werden in fast jeder Branche eingesetzt, von der Unterhaltung bis zum Finanzwesen.
Einige der offensichtlichsten Plattformen, die Empfehlungssysteme nutzen, sind Unternehmen wie Spotify, Netflix und Amazon, aber es gibt sie in jeder Branche, vor allem da immer mehr Unternehmen KI-Richtlinien einführen.
Sie sind so geschult, dass sie die verschiedenen Eigenschaften, früheren Entscheidungen und Vorlieben der Nutzer/innen anhand einer Vielzahl von Interaktionen wie Klicks, Likes und Views verstehen. Wir alle kennen es, dass uns neue Produkte, Filme oder Songs empfohlen werden, die auf früheren Käufen basieren, aber wie kann ein Algorithmus wissen, was uns gefallen könnte? Vektorielle Einbettungen!
Auf einer sehr hohen Ebene vergleichen Empfehlungssysteme verschiedene Artikel mit den bekannten Vorlieben eines Nutzers. Um diese Empfehlungen aussagekräftig zu machen, werden sowohl die Nutzer als auch die Gegenstände in Vektor-Embeddings umgewandelt. Dafür gibt es zwei sehr gängige Techniken: inhaltsbasierte Empfehlungen und kollaboratives Filtern.
Nehmen wir Filme als Beispiel. Bei inhaltsbasierten Empfehlungen werden Filme aufgrund ihrer verschiedenen Merkmale eingebettet, und Nutzer/innen werden aufgrund von Filmen, die sie in der Vergangenheit gesehen haben, eingebettet. Dieses System kann dann neue Filme empfehlen, deren Vektoren den Präferenzvektoren des Nutzers am nächsten kommen, oder die Filme, die er in der Vergangenheit gesehen hat.
Beim kollaborativen Filtern werden viele Nutzer berücksichtigt. Anstatt sich nur auf einen einzelnen Nutzer und ein Objekt zu konzentrieren, findet die kollaborative Filterung verschiedene Nutzer, die Vektoren haben, die deinen am nächsten sind, und empfiehlt Objekte oder Filme, die ihnen gefallen haben.
Eine weitere großartige Anwendung für Vektoreinbettungen sind Chatbots oder RAG.
Retrieval-augmented generation ist ein Weg, um die Fähigkeiten von großen Sprachmodellen (LLMs) wirklich voll auszuschöpfen, indem externe, aktuelle Informationen integriert werden, so dass LLMs genauere Antworten generieren können. Das liegt daran, dass LLMs normalerweise auf statischen Daten trainiert werden. Sie haben also eine begrenzte Wissensbasis und können nicht auf lokale oder personalisierte Daten zugreifen.
Mit Vektoreinbettungen ist es möglich, benutzerdefinierte Daten in einer Vektordatenbank zu speichern. So kann man eine vollständig anpassbare Datenbank mit personalisierten Daten erstellen, die in jedem Projekt verwendet werden kann! Da die Daten als Vektoreinbettungen gespeichert werden, ist es möglich, semantisch ähnliche Dokumente direkt aus der Datenbank abzurufen, basierend auf der Anfrage des Nutzers.
Das Tolle an RAG ist, dass es sich perfekt für verschiedene Aufgaben eignet, z. B. für die Beantwortung von Fragen und die Erstellung von Texten. Das bedeutet, dass es sich perfekt für die Entwicklung von Chatbots eignet, die mit personalisierten Daten trainiert werden!
Dies sind nur einige der Möglichkeiten, die mit Vektoreinbettungen möglich sind.
Die grundlegenden Eigenschaften von Vektordatenbanken sind natürlich die Tatsache, dass sie Vektoren speichern und effizient verarbeiten können, dass sie sich hervorragend für die Arbeit mit sehr hochdimensionalen Daten eignen und dass sie superschnelle Abfragen ermöglichen.
Bei einer traditionellen relationalen Datenbank sind die Benutzer/innen gezwungen, mit strukturierten Daten umzugehen, da relationale Datenbanken Spalten und Zeilen von Daten in Tabellen verarbeiten. Außerdem sind die Nutzer gezwungen, Drittanbieterpakete zu verwenden, um mit relationalen Datenbanken und vektorbezogenen Prozessen umzugehen, da strukturierte Datenbanken nicht in der Lage sind, Vektoreinbettungen zu speichern oder zu durchsuchen.
Vektordatenbanken sind für diese Art von Arbeit konzipiert: Daten werden als Vektoren gespeichert und verarbeitet, was bedeutet, dass komplexere, auf KI ausgerichtete Anwendungen einfach erstellt werden können. Vektordatenbanken sind auch für ihre Leistung, Skalierbarkeit, Flexibilität und Zuverlässigkeit bekannt. Sie sind darauf ausgelegt, große Datenmengen zu verarbeiten, unterstützen unstrukturierte und halbstrukturierte Daten und bieten Entwicklern Flexibilität bei ihren Projekten.
Hier ist ein tieferer Blick auf den Unterschied zwischen Vektordatenbankenund traditionellen relationalen Datenbanken:
|
Aspekt |
Vektordatenbanken |
Traditionelle relationale Datenbanken |
|
Primäres Datenmodell |
Speichert Daten als hochdimensionale Vektoren (oft mit Hunderttausenden von Dimensionen). |
Speichert strukturierte Daten in Tabellen mit Zeilen und typisierten Spalten. |
|
Kernparadigma der Abfrage |
Ähnlichkeitssuche (z. B. Nächste-Nachbarn-Suche) über Vektoreinbettungen. |
Genaue Übereinstimmung, Bereichs-, Aggregations- und Verknüpfungsabfragen für genau definierte Spalten. |
|
Native Unterstützung für Einbettungen |
Integrierte Speicherung, Indexierung (z. B. HNSW, IVF) und schnelles Abrufen von Vektoreinbettungen. |
Kein nativer Vektortyp; erfordert externe Erweiterungen oder Pipelines zur Verarbeitung von Einbettungen. |
|
Leistung im großen Maßstab |
Optimiert für die Ähnlichkeitssuche in Sekundenschnelle bei Millionen bis Milliarden von Vektoren. |
Optimiert für ACID-Transaktionen und relationale Operationen; die Vektorsuche ist langsam oder wird ausgelagert. |
|
Datenflexibilität |
Verarbeitet unstrukturierte und halbstrukturierte Eingaben (Text, Bilder, Audio), sobald sie in Vektoren umgewandelt wurden. |
Am besten mit streng strukturierten Schemata; unstrukturierte Daten müssen umgewandelt oder separat gespeichert werden (z. B. BLOBs). |
|
Skalierbarkeitsmodell |
Horizontales Sharding/Partitionierung von Vektorindizes; konzipiert für den verteilten Betrieb. |
Ausgereifte vertikale und horizontale Skalierung für tabellarische Daten, aber Indizes Ballon mit hochdimensionalen Vektoren. |
|
Entwickler-Workflow |
Ein System zum Speichern von Einbettungen und Ausführen von KI/semantischen Abfragen; einfacherer Stack für ML/AI-Anwendungen. |
Erfordert separate Vektorspeicher oder Bibliotheken sowie ETL-Code zur Synchronisierung mit der relationalen DB. |
|
Typische Anwendungsfälle |
Semantische Suche, Empfehlungen, Bild-/Audio-Retrieval, RAG für LLMs, Anomalieerkennung. |
OLTP/OLAP-Anwendungen, Finanzbücher, Inventar, CRM, traditionelle BI-Analysen. |
|
Stärken |
Hochdimensionale Suchgeschwindigkeit, Einfachheit für KI-Projekte, Skalierbarkeit, Flexibilität. |
Hohe Konsistenz (ACID), ausgereifte Tools, umfangreiche SQL-Analysen, komplexe Joins. |
|
Kompromisse / Grenzen |
Schwächer bei komplexen relationalen Verknüpfungen und mehrzeiligen Transaktionen. |
Schlechte native Unterstützung für Vektorähnlichkeit, weniger geeignet für KI-lastige Workloads. |
Viele kennen MongoDB als dokumentenbasierte NoSQL-Datenbank, aber viele wissen nicht, dass es eigentlich eine Vektordatenbank ist - dank MongoDB Atlas Vector Search!
Da es sich bei MongoDB um eine NoSQL-Datenbank handelt, können diejenigen, die diesen Datenbanktyp noch nicht kennen, voneiner Einführung in NoSQLprofitieren.
Die Stärke von MongoDB als Vektordatenbank liegt darin, dass sich die Vektoreinbettungen ganz natürlich in das flexible Dokumentenmodell einfügen. MongoDB Atlas Vector Search ermöglicht es Entwicklern, Vektoreinbettungen direkt in jeder Sammlung zu speichern und abzufragen. Das bedeutet, dass deine Vektoreinbettungen direkt neben deinen Quelldaten gespeichert werden, damit du sie leicht finden kannst.
Dank dieses Formats können Entwickler eine hybride Suchedurchführen,die eine Kombination aus Volltext- und semantischer Suche ist und den zusätzlichen Vorteil bietet, dass nicht nur kontextuell ähnliche Ergebnisse angezeigt werden, sondern auch synonyme Ergebnisse. Wir können uns die hybride Suche so vorstellen, als hätten wir einen superschlauen Bibliothekar, der nicht nur Bücher mit genau demselben Titel findet, nach dem du gefragt hast, sondern auch solche mit ähnlichen Geschichten vorschlägt!
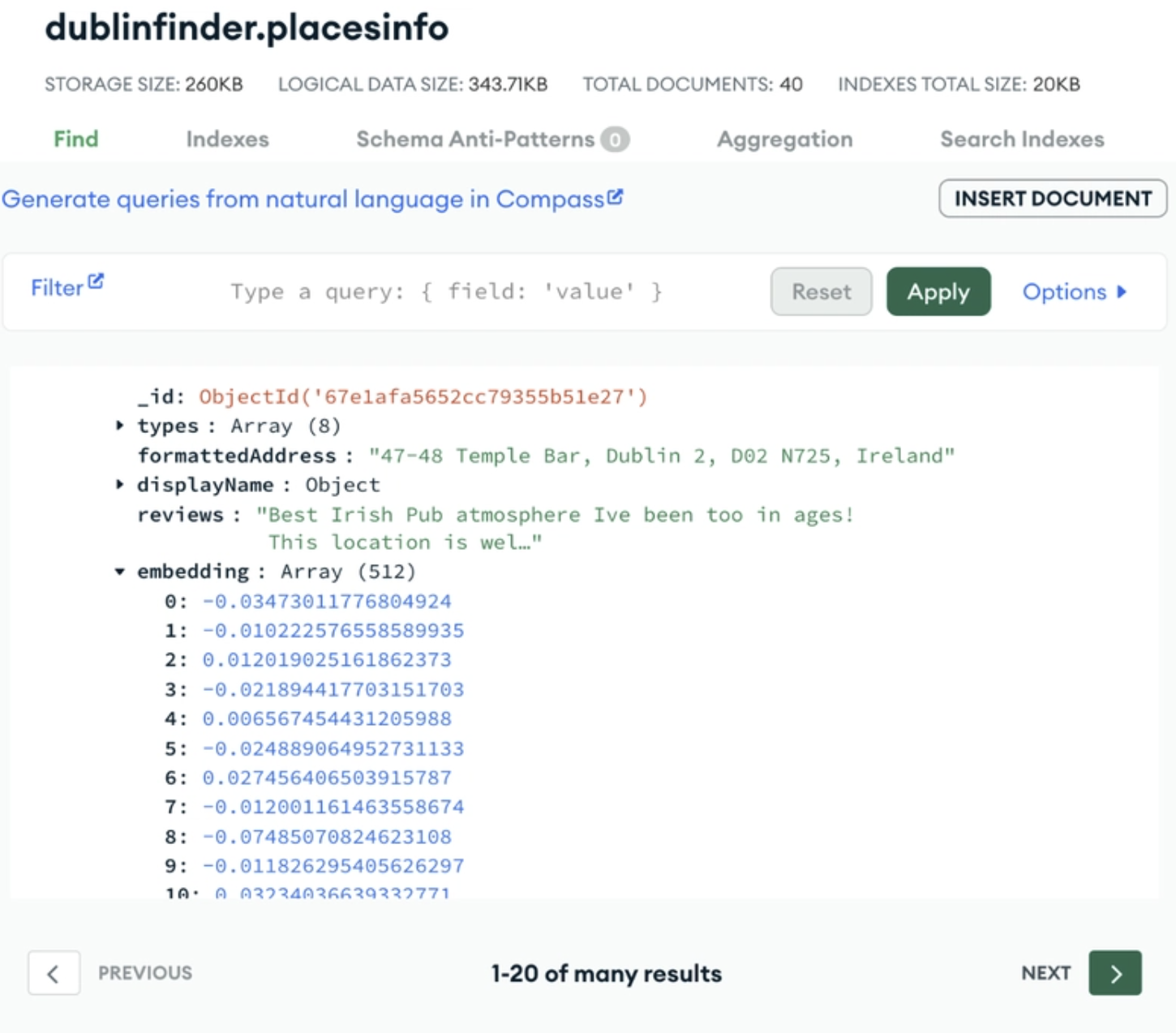
Ein Beispiel für die Speicherung deiner Vektoreinbettung neben deinen Quelldaten in MongoDB Atlas. Bildquelle.
Ein weiterer Vorteil dieses Formats ist, dass Entwickler die gesamte Plattform von MongoDB in ihren hochperformanten und komplexen KI-Anwendungen voll ausschöpfen können. Funktionen wie Stream-Processing, Echtzeit-Analysen, Geodatenabfragen und vieles mehr können problemlos in jede einzelne Anwendung integriert werden.
Die kürzliche Übernahmevon Voyage AI durch MongoDBhilft dabei, diesen Prozess noch einfacher zu gestalten. Die erstklassigen Einbettungsmodelle und Reranker, die zur Verfügung gestellt werden, ermöglichen es Entwicklern, ihre Daten in Vektoren umzuwandeln, die eine extrem hohe Genauigkeit aufweisen, im Raum wettbewerbsfähig sind und eine schnelle Inferenz und Unterstützung mehrerer Sprachen ermöglichen.
Im Folgenden erfährst du, wie du mit MongoDB Atlas Vector Search loslegen kannst.
Um mit MongoDB Atlas Vector Search zu beginnen, folge bitte der Schnellstartanleitung, die dich durch einen 15-minütigen Einrichtungsprozess führt.
Es wird dir zeigen, wie du:
Vektordatenbanken haben sich bei der Entwicklung komplexer KI-Anwendungen als unverzichtbar erwiesen. Sie erleichtern den Entwicklungsprozess bei der Arbeit mit Vektoreinbettungen, die für diese fortschrittlicheren Anwendungen erforderlich sind, und das Schöne an MongoDB ist, dass Entwickler nicht ihren gesamten Stack neu erfinden müssen, um von ihnen zu profitieren.
Indem MongoDB die Leistungsfähigkeit des Dokumentenmodells nutzt, können Entwickler ihre Vektordatenbank nutzen. Es ist möglich, strukturierte Felder, unstrukturierte Daten und hochdimensionale Einbettungen an einem einzigen Ort zu kombinieren!
Einige wichtige Erkenntnisse:
Um wirklich zu verstehen, wie leistungsfähig eine Vektordatenbank für deine KI-Anwendung sein kann, solltest dueinen kostenlosen Clusterüber die MongoDB-Plattform einrichtenund ihn selbst ausprobieren.
Lerne, wie du mit LLMs in Python direkt in deinem Browser arbeiten kannst

Lerne mehr über MongoDB mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
