
Course
Introduction to MongoDB in Python
3 hr
24K
With artificial intelligence infiltrating and reshaping every industry, the primary focus is always on new features and functionalities, but what goes on behind the scenes? Behind every AI application is something a bit less glamorous yet incredibly crucial: the infrastructure that powers it. So, what tools make it possible for machine learning to thrive?
In a data-driven world, it truly all starts with how data is stored, and most importantly, how data is searched. This is where vector databases come into play.
So, what exactly is a vector database? A vector database is a database specifically designed to store and search over vector embeddings, allowing developers to utilize various AI functionalities like semantic search, image recognition, chatbots, and so much more.
But what exactly does that mean? To fully understand what a vector database is, let’s back up a couple of steps. Let’s demystify these integral databases by covering our basics from the very beginning, starting with the key player in this process: the vector embedding.
A vector (in the context of artificial intelligence) is simply a list of numbers that represents the semantic meaning of an image, a sentence, audio, and even video. This sequence of numbers helps computers understand how each piece of data is similar to each other: They place data (like words or images) as points in a “math map” where similar concepts are closer together.
We can think of vector embeddings like turning a piece of data into a GPS coordinate—data with similar meanings (like “dog” and “puppy”) end up in the same neighborhood!
Why do we need to turn our data into vectors? Well, imagine trying to explain to a machine the difference between a cat and a dog. While human beings are capable of understanding this difference, a machine can only grasp and understand numbers: It’s impossible to explain to your laptop the difference between Toto and Garfield.
By turning your data into specific vector structures where each number is uniquely ordered according to that source data, your machine is capable of understanding relationships between various data points!
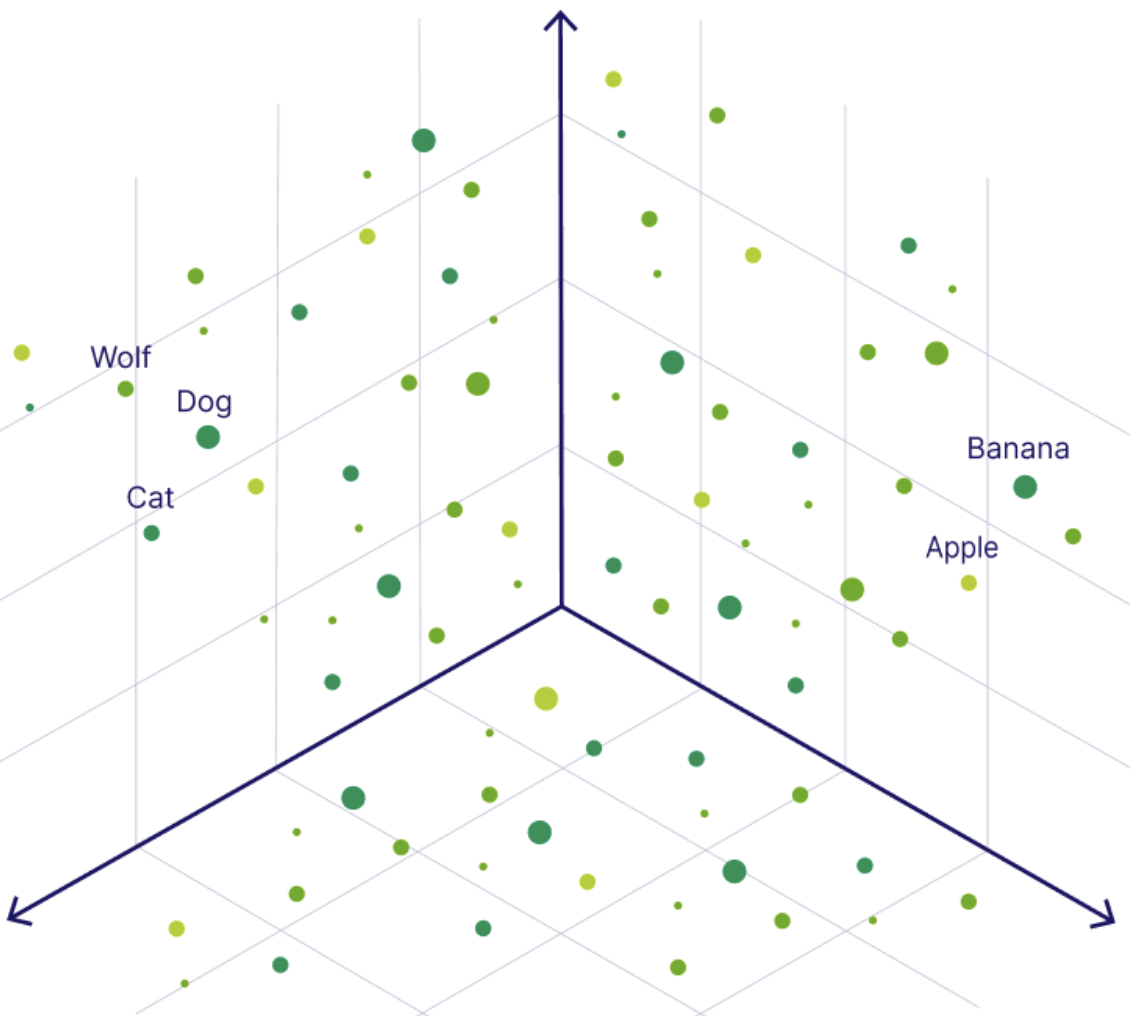
Showcasing a vector embedding in multidimensional space. Image source.
Let’s go over how this is possible by discussing similarity search.
Similarity search is the technique used to help find the documents that are most similar to a user’s original query. Searching with vectors is like asking, “Which of these pictures looks most like a cat?” instead of just matching the word “cat” exactly.
As we are dealing with vectors in multidimensional space, some math gets involved in this process to help us figure out which embeddings are most alike.
There are a multitude of similarity search algorithms, but the most common three are:
Cosine similarity measures the angle between two vectors (it doesn’t care about the size of the vector) and is most commonly used for text embeddings, semantic similarity, and recommendation systems. It helps developers compare the overall direction of the vectors, which in turn helps figure out the overall content of the documents, which is why it’s so important for the topics listed.
The Euclidean distance measures the straight-line distance between two vectors in space. A great way of thinking about it is measuring the shortest path between two dots on a map!
This distance is the most straightforward since if the distance calculated is very small, that means the vector coordinates are very close, or very similar to one another.
Since this metric is very sensitive to magnitudes, it’s most useful when embeddings have to do with numeric values. This is especially useful for recommendation engines to let users know what to order next based on how many times they’ve purchased an item in the past.
Dot product similarity measures not only the product of vector magnitudes, but also the cosine of the angle between them. This means the dot product cares about both the length (magnitude) and the direction of vectors!
When vectors are normalized (the magnitude of the vector is one but the direction stays the same), dot product similarity becomes the same as cosine similarity since the magnitude is no longer taken into account.
The dot product similarity is most commonly used in areas such as natural language processing (NLP) and computer vision.
So, now you have your raw data represented as vector embeddings. Let’s dive into all the incredible possibilities that are opened up due to having your data represented by these embeddings.
Semantic search is a way of searching through data based on the actual meaning of a user’s query, not just exact match searching. This means that instead of searching based on specific keywords, results will be shown even if a word is spelled incorrectly, and results will be shown based on synonyms from the original query.
For example, if a user is searching for “best cafes near me”, with exact searching, only specifically labeled “cafes” will come up, whereas a semantic search engine would understand and show places that have “tea”, “coffee”, “pastries”, or other findings that a deeper contextual understanding would result in.
So, how is this search made possible? Vector embeddings! Let’s say we embed a user’s query and the data (such as location descriptions). This makes it possible to compare them against each other in multidimensional space, looking for vectors that are closest to each other using methods like similarity search.
For example, if the user has the query “best cafes near me” and a database full of scraped Google Maps location descriptions that have been embedded, semantic search will show the places whose embeddings are most similar to the original query—even if the word “cafe” is never used in those location descriptions!
Recommendation systems use data to help people find what they would statistically most enjoy, based on previous purchases, search history, environmental and demographic information, and more. They are used in almost every industry, ranging from entertainment to finance.
Some of the more obvious platforms that utilize recommendation systems are companies like Spotify, Netflix, and Amazon, but they are in every industry, especially as more and more companies adopt AI policies.
They are fully trained to understand the various characteristics, previous decisions, and preferences of users based on a multitude of interactions, including clicks, likes, and views. So, we’re all familiar with being recommended new products, movies, or songs based on past purchases, but how can an algorithm know what we might like? Vector embeddings!
From a very high level, recommendation systems compare various items to a user’s known preferences. In order to help make these recommendations meaningful, both the users and the items are converted into vector embeddings. There are two very common techniques for this: content-based recommendations and collaborative filtering.
Let’s use movies as our example. With content-based recommendations, movies are embedded based on their various features, and users are embedded based on movies they have watched in the past. This system can then recommend new movies with vectors closest to the user’s preference vectors, or the movies they have watched in the past.
With collaborative filtering, many users are taken into consideration. Instead of just focusing on a single user and an item, collaborative filtering finds various users who have vectors closest to yours and recommends items or movies that they have enjoyed.
Another great use for vector embeddings is with chatbots or RAG.
Retrieval-augmented generation is a way to truly, fully utilize the capabilities of large language models (LLMs) by integrating external, up-to-date information so that LLMs can generate more accurate responses. This is because LLMs are normally trained on static data, so they have a limited knowledge base and aren’t able to access any local or personalized data.
With vector embeddings, it’s possible to save custom data in a vector database, allowing one to create a fully customizable database of personalized data that can be used in any project! With the data being stored as vector embeddings, it’s possible to retrieve semantically similar documents directly from the database based on the user’s query.
The great aspect about RAG is that it’s perfect for various tasks, such as answering questions and generating text. This means it’s perfect for building chatbots that are trained on personalized data!
These are just a few of the capabilities that are possible with vector embeddings.
The fundamental properties of vector databases are, of course, the fact that they can store and efficiently handle vectors, they are great at working with very high-dimensional data, and they enable super quick querying.
With a traditional relational database, users are forced to deal with structured data, as relational databases handle columns and rows of data within tables. Users are also forced to use third-party packages to deal with relational databases and vector-related processes, as structured databases are unable to store or search over vector embeddings natively.
Vector databases are designed for this kind of work: Data is stored and processed as vectors, meaning more complex, AI-focused applications can be simply built. Vector databases are also known for their performance, ability to scale, flexibility, and reliability. They are designed to handle massive datasets, are capable of supporting unstructured and semi-structured data, and allow for developer flexibility over their projects.
Here’s a deeper look at the difference between vector databases and traditional relational databases:
|
Aspect |
Vector Databases |
Traditional Relational Databases |
|
Primary data model |
Stores data as high-dimensional vectors (often hundreds–thousands of dimensions). |
Stores structured data in tables of rows & typed columns. |
|
Core query paradigm |
Similarity search (e.g., nearest-neighbor) over vector embeddings. |
Exact match, range, aggregation, and join queries on well-defined columns. |
|
Native support for embeddings |
Built-in storage, indexing (e.g., HNSW, IVF), and fast retrieval of vector embeddings. |
No native vector type; requires external extensions or pipelines to handle embeddings. |
|
Performance at scale |
Optimized for sub-second similarity search across millions-to-billions of vectors. |
Optimized for ACID transactions and relational operations; vector search is slow or off-loaded. |
|
Data flexibility |
Handles unstructured & semi-structured inputs (text, images, audio) once converted to vectors. |
Best with strictly structured schemas; unstructured data must be transformed or stored separately (e.g., BLOBs). |
|
Scalability model |
Horizontal sharding/partitioning of vector indexes; designed for distributed operation. |
Mature vertical & horizontal scaling for tabular data, but indexes balloon with high-dimensional vectors. |
|
Developer workflow |
One system for storing embeddings + running AI/semantic queries; simpler stack for ML/AI apps. |
Requires separate vector stores or libraries, plus ETL glue code to sync with the relational DB. |
|
Typical use-cases |
Semantic search, recommendation, image/audio retrieval, RAG for LLMs, anomaly detection. |
OLTP/OLAP apps, financial ledgers, inventory, CRM, traditional BI analytics. |
|
Strengths |
High-dimensional search speed, simplicity for AI projects, scale, flexibility. |
Strong consistency (ACID), mature tooling, rich SQL analytics, complex joins. |
|
Trade-offs / limits |
Weaker at complex relational joins & multi-row transactions. |
Poor native support for vector similarity, less suited to AI-heavy workloads. |
While many people know MongoDB as a document-based NoSQL database, many aren’t aware that it is actually a vector database, thanks to MongoDB Atlas Vector Search!
Given MongoDB's roots as a NoSQL database, those new to this database type might benefit from an Introduction to NoSQL.
The powerful aspect of MongoDB as a vector database is how naturally vector embeddings are able to fit into its flexible document model. MongoDB Atlas Vector Search allows developers to store and query vector embeddings directly inside any collection. This means your vector embeddings are stored directly next to your source data for easy reference.
Due to this format, developers are able to conduct hybrid search, which is a combination of full-text and semantic search for the additional benefit of ensuring not only contextually similar results are shown, but also synonymous results. We can think of hybrid search as having a super-smart librarian who not only finds books with the exact same title you asked for, but also suggests ones with similar stories!
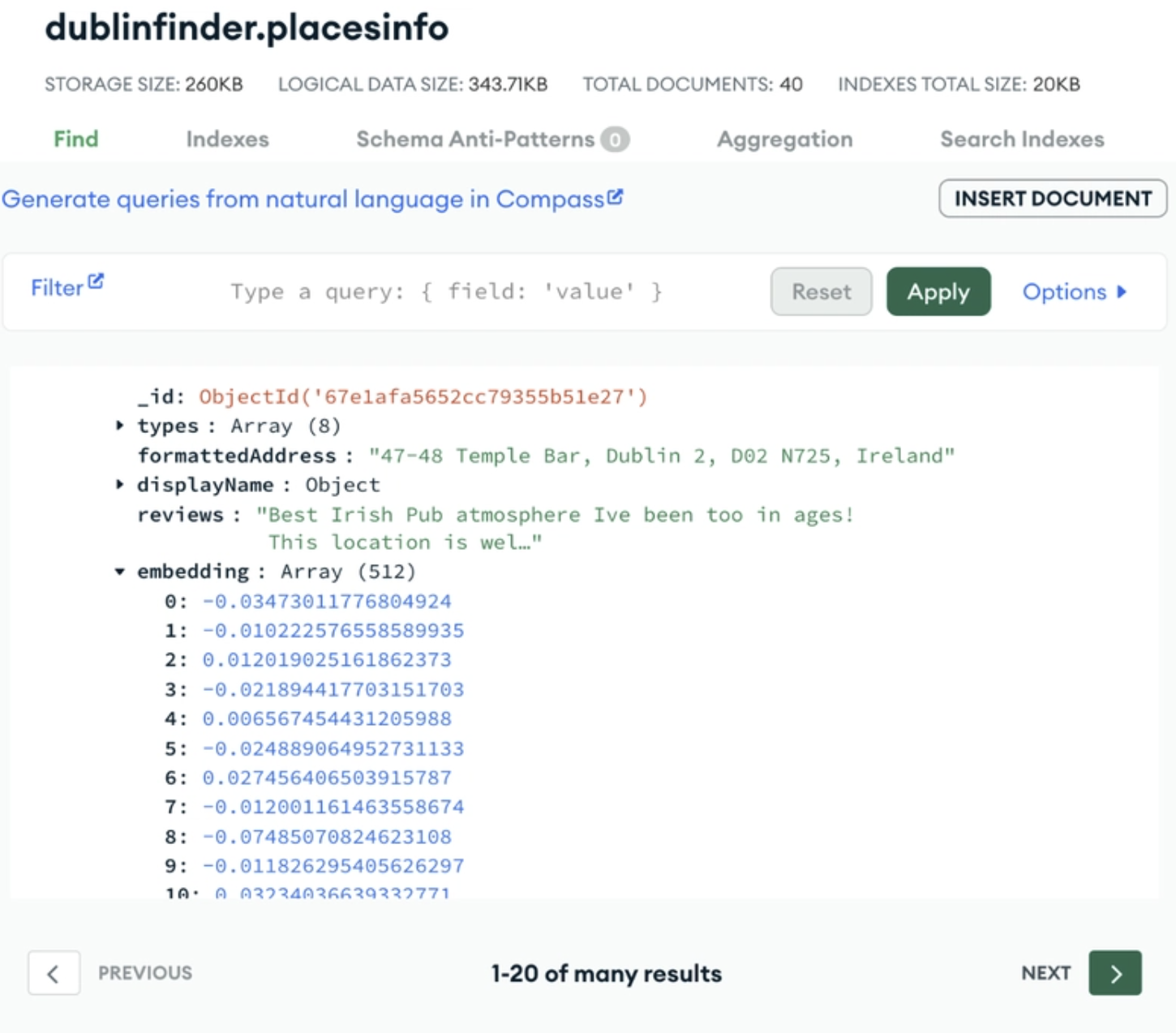
An example of storing your vector embedding next to your source data in MongoDB Atlas. Image source.
Another benefit of this format is that developers can fully utilize MongoDB’s entire platform in their highly performant and complex AI applications. Features such as stream processing, real-time analytics, geospatial queries, and more can all be easily incorporated into any single application.
MongoDB’s recent acquisition of Voyage AI helps enable this process to be even simpler. The world-class embedding models and rerankers provided allow for developers to have their data transformed into vectors that have extremely high accuracy, are competitive in the space, and allow for fast inference and multi-language support.
Let’s go over how to get started with MongoDB Atlas Vector Search.
In order to get started with MongoDB Atlas Vector Search, please follow the quickstart guide that will take you through a 15-minute setup process.
It will show you how to:
Vector databases have proven to be a necessity for building complex AI applications. They help smooth the development process when working with vector embeddings that are required for these more advanced applications, and the beauty of MongoDB is that developers don’t need to reinvent their entire stack to start benefiting from them.
By utilizing the power of the document model, MongoDB empowers developers with their vector database. It’s possible to combine structured fields, unstructured data, and high-dimensional embeddings in a single place!
Some key takeaways:
To truly understand the power a vector database will have in your AI application, spin up a free cluster through MongoDB’s platform and try it for yourself.
Learn how to work with LLMs in Python right in your browser

Learn more about MongoDB with these courses!
Course
Course
Course
blog
Moez Ali
14 min
blog
Karen Zhang
15 min
podcast
Tutorial
Gary Alway
Tutorial
Moez Ali
Tutorial
Arunn Thevapalan

