Cours
Introduction à R
4 h
3M

Il ne suffit pas de rédiger un CV impressionnant pour réussir à intégrer le marché du travail dans le domaine de la science des données. Si vous envisagez de vous lancer dans une carrière dans le domaine de la science des données, il est essentiel de constituer un portfolio de projets pertinents qui mettront en valeur vos compétences en matière de données lors des entretiens.
La bonne nouvelle est qu'il n'est jamais trop tôt ni trop tard pour commencer à constituer un tel portefeuille. Que vous soyez débutant ou déjà à mi-chemin dans votre apprentissage de la science des données, vous pouvez commencer dès maintenant à travailler sur vos projets R.
Il est tout à fait normal que vos premiers projets aient un aspect amateur. Vous pouvez toujours y revenir ultérieurement, les développer, les affiner ou même les supprimer lorsque vous réaliserez des projets plus avancés. Le plus important ici est de commencer le processus.
Dans cet article, nous vous présenterons quelques idées utiles pour vos projets de science des données utilisant R et examinerons quelques exemples pour vous aider à démarrer. Nous aborderons également le langage de programmation R et son utilisation dans l'analyse de données et la science des données.
R est un langage de programmation utilisé pour l'analyse de données, la science des données et l'apprentissage automatique. Il comprend également un environnement pour le calcul statistique et les graphiques. R est spécialement conçu pour le calcul statistique avancé et rapide, la modélisation de données et la création de visualisations percutantes. C'est là que ce langage démontre sa véritable puissance.
De plus, R :
Vous trouverez plus d'informations sur le langage de programmation R et sur la manière de l'apprendre dans nos articles « Qu'est-ce que R ? - La puissance de calcul statistique » et « Comment débuter avec R ». Vous pouvez également suivre le cours DataCamp Introduction à R.
Pour commencer à apprendre R à partir de zéro ou pour maîtriser des compétences techniques particulières, veuillez consulter nos différentes ressources d'apprentissage, notamment nos cours, nos cursus de compétences et nos cursus professionnels. En particulier, pour un parcours d'apprentissage équilibré et complet de R, envisagez les cursus Data Scientist avec R et Machine Learning Scientist avec R.
L'analyse des données constitue la première étape de tout projet lié à la science des données. Il est logique qu'avant de nous lancer dans la prévision de scénarios futurs à l'aide de techniques d'apprentissage automatique et d'apprentissage profond, nous devions d'abord exposer la situation actuelle (et passée).
D'autre part, l'analyse des données peut être une tâche autonome. Dans les deux cas, R nous offre un large éventail de bibliothèques utiles spécialement adaptées à des fins analytiques.
Avec R, nous pouvons analyser les données provenant de sites Web, les nettoyer et les organiser, les visualiser, explorer leurs statistiques, formuler et tester des hypothèses, et extraire des informations et des modèles significatifs à partir des données initiales. Parmi ces tâches, l'analyse statistique et les visualisations remarquables constituent un véritable atout pour R, et c'est là que ce langage de programmation surpasse généralement son principal concurrent, Python.
Outre les paquets polyvalents courants de R, il existe de nombreux modules conçus pour divers problèmes analytiques appliqués. Par exemple :
Actifs : Ce progiciel est conçu pour analyser et modéliser les actifs financiers.
mdapack : Il s'agit d'un progiciel d'analyse de données médicales.
GEOmap : Ce progiciel est utilisé pour la cartographie topographique et géologique.
AeRobiology: Cet outil informatique est destiné aux données aérobiologiques.
galigor : Il s'agit d'une collection de packages destinés au marketing sur Internet.
lingtypologie : Ce package est utilisé pour la typologie linguistique et la cartographie.
De plus, R inclut même des bibliothèques hyper-spécialisées telles que :
Comme nous l'avons mentionné précédemment, R est un langage de programmation orienté vers la science des données qui propose plus de 19 000 packages liés à la science des données. Outre les tâches purement analytiques énumérées dans la section précédente, nous pouvons utiliser R pour des problèmes plus avancés dans le domaine de la prévision et de la modélisation de données inconnues. L'utilisation de R nous permet de :
Une fois encore, outre les packages couramment utilisés en science des données (caret pour l'apprentissage par classification et régression, naivebayes pour la mise en œuvre de l'algorithme Naive Bayes, randomForest pour la construction de modèles de forêts aléatoires, deepNN pour l'apprentissage profond, etc.), il existe de nombreuses bibliothèques hautement spécialisées, certaines étant même très spécifiques. Pour n'en citer que quelques-uns :
OenoKPM : Ce package est utilisé pour modéliser la cinétique de la production de CO2 dans la fermentation alcoolique.
fHMM : Ce package est conçu pour adapter les modèles de Markov cachés aux données financières.
paleopop : Il s'agit d'un cadre de modélisation orienté vers les modèles pour les modèles paléoclimatiques couplés niche-population.
ibdsim2 : Ce package est utilisé pour simuler les régions chromosomiques partagées par les membres d'une même famille.
rSHAPE : Ce package est conçu pour simuler l'évolution d'une population asexuée haploïde.
Nous allons maintenant examiner quelques exemples de projets R et identifier des idées intéressantes à développer, tant pour les débutants que pour les utilisateurs expérimentés.
L'une des méthodes les plus efficaces pour rechercher des projets R consiste à créer vous-même de tels exemples.
Veuillez ne pas vous inquiéter, ce n'est pas aussi effrayant qu'il n'y paraît. Même si vous êtes novice en science des données dans R, vous pouvez opter pour des projets « sandbox » qui fournissent des données prêtes à être analysées ou modélisées, vous présentent le contexte d'un problème et vous fournissent des conseils utiles sur les étapes à suivre et les raisons de les suivre.
Si vous êtes un apprenant plus avancé, vous êtes toujours invité à explorer les données plus en profondeur, sous différents angles, et à aller bien au-delà des instructions suggérées afin de satisfaire votre curiosité à leur sujet. Dans tous les cas, l'apprentissage actif par la pratique constitue une meilleure alternative à la simple lecture des projets d'autres personnes.
DataCamp propose un large choix de projets de science des données dans R qui vous permettront de mettre en pratique de nombreuses compétences techniques. Parmi ces exemples, on peut citer l'importation et le nettoyage des données, la manipulation des données, la visualisation des données, les probabilités et les statistiques, l'apprentissage automatique, etc.
Outre les sujets populaires (tels que « Explorer le marché Airbnb à New York », « Visualiser la COVID-19 », « Regrouper les données des patients atteints de maladies cardiaques » ou « Prédire les tarifs de taxi avec Random Forests ») qui sont traditionnellement analysés dans diverses écoles de science des données, vous trouverez ici de nombreux autres sujets nouveaux et intéressants. N'hésitez pas à les explorer plus en détail :
Après avoir examiné les projets R existants ou réalisé vous-même quelques projets guidés, vous pouvez décider de commencer à créer vos propres projets à partir de zéro. C'est toujours une bonne idée, quel que soit votre niveau d'apprentissage de R.
Si vous réalisez l'un de vos premiers projets sans accompagnement, la première question à vous poser est de savoir où trouver les données sur lesquelles travailler. Heureusement, il existe de nombreux référentiels en ligne populaires qui offrent d'importantes collections de jeux de données gratuits et bien documentés, tant réels que synthétiques. Parmi les ressources notables, on peut citer DataLab, Kaggle, UCI Machine Learning Repository, Google Dataset Search, Google Cloud Platform, FiveThirtyEight et Quandl.
Maintenant que vous disposez d'un large choix de données, que pouvez-vous faire exactement avec celles-ci en tant que débutant dans R ? Étant donné qu'il s'agira de vos premiers projets en science des données dans R, envisagez de procéder à un nettoyage et à une manipulation de base des données, à une exploration simple des données et à leur visualisation.
Spotify est l'un des plus grands services de musique, de vidéo et de médias numériques, où vous pouvez trouver des millions de chansons, de vidéos et de podcasts du monde entier.
Vous pouvez utiliser un ensemble de données Spotify Music Data déjà prêt, qui contient environ 600 chansons populaires sur une certaine période, et explorer ses statistiques sous différents angles. Par exemple, envisagez d'analyser les facteurs et questions suivants, en complétant vos conclusions par des graphiques pertinents si nécessaire :
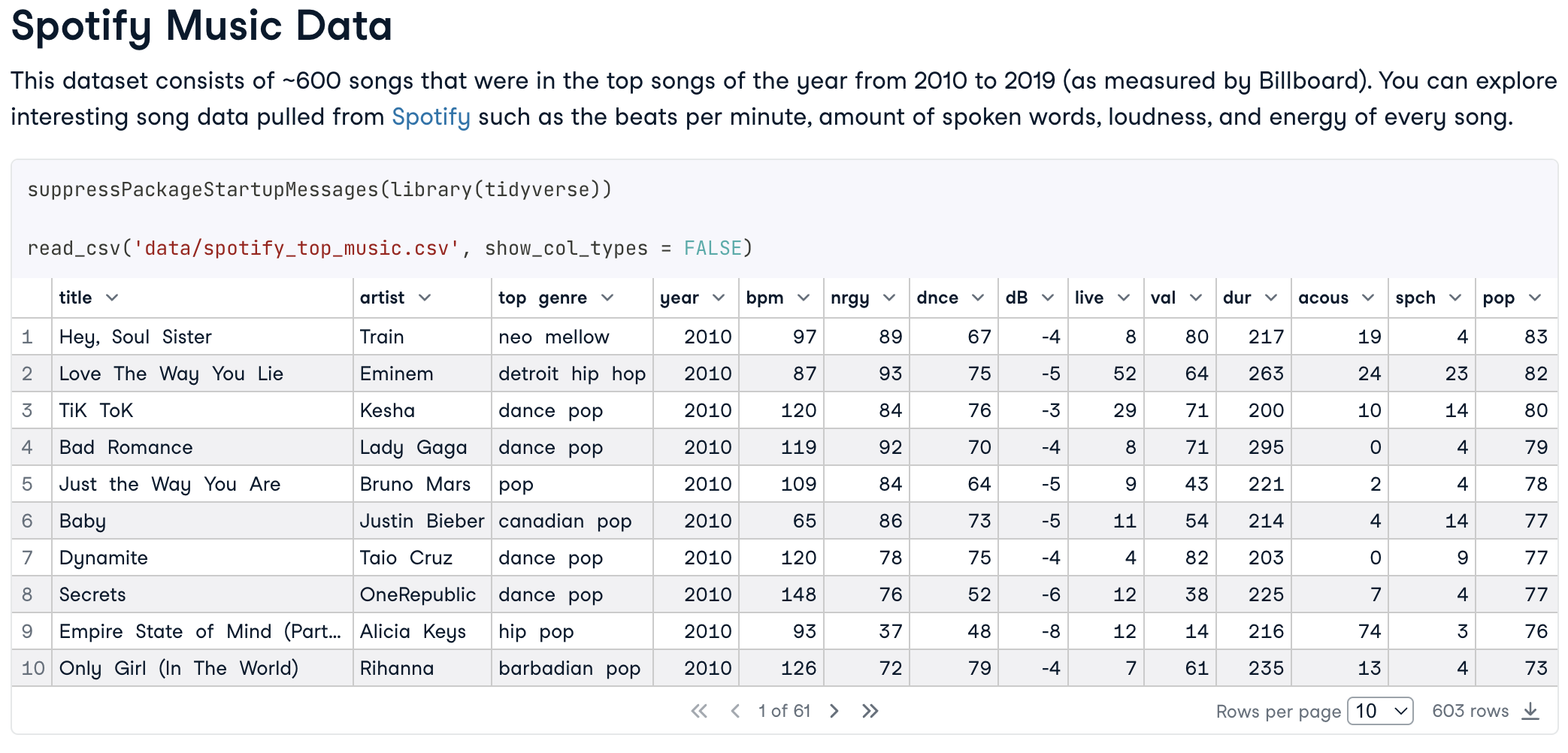
Un exemple tiré du projet Spotify Music Data R
La National Basketball Association (NBA) est une ligue professionnelle nord-américaine de basket-ball masculin composée de 30 équipes, l'une des plus importantes au monde.
L'ensemble de données NBA Shooting Data contient les données recueillies pour quatre joueurs différents lors des play-offs NBA 2021. Vous pouvez analyser et visualiser ces données et tenter de répondre aux questions suivantes :
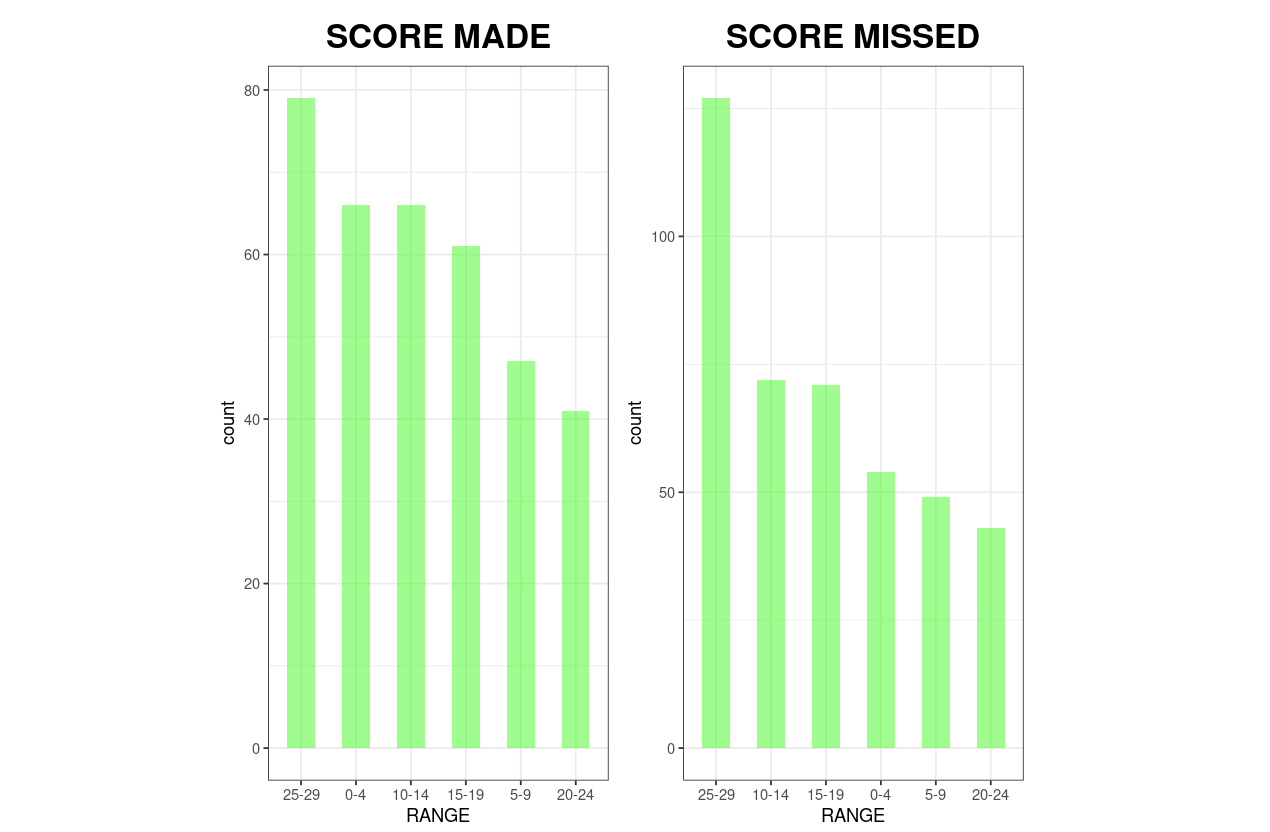
Un exemple tiré du projet R sur les statistiques de tirs de la NBA
Une autre idée intéressante pour un projet R en science des données pour débutants consiste à étudier les tendances démographiques mondiales.
L'ensemble de données sur la population mondiale fournit des statistiques sur la population totale de chaque pays de 1960 à 2020, ainsi que des informations supplémentaires par pays, telles que sa région, son groupe de revenu et des remarques particulières (le cas échéant). Il existe plusieurs questions que vous pouvez explorer ici :
N'oubliez pas d'ajouter des graphiques captivants lorsque cela est utile : ils aideront vos lecteurs à mieux comprendre les principales conclusions de votre analyse.
Si vous êtes à mi-chemin dans votre apprentissage de la science des données dans R, vous pourriez être intéressé par la création de projets R plus sophistiqués dans lesquels vous mettriez en pratique à la fois vos compétences en analyse de données et certains algorithmes d'apprentissage automatique.
Quels thèmes pouvez-vous sélectionner pour eux ? Examinons quelques idées potentielles pour vos projets avancés en science des données R.
Le taux de désabonnement désigne la tendance des clients à résilier leur abonnement à un service et, par conséquent, à cesser d'être clients de ce service. Il est calculé comme le pourcentage de clients perdus au cours d'une période donnée.
Cet indicateur dépend de nombreux facteurs et reflète la santé financière globale de l'entreprise. Lorsqu'il est trop élevé, le taux de désabonnement des clients représente un problème grave pour toute entreprise, car il entraîne une perte de revenus et nuit à la réputation de l'entreprise. Il est donc essentiel de pouvoir prévoir le taux de désabonnement des clients afin de le prévenir.
Vous pouvez utiliser l'ensemble de données Telecom Customer Churn pour élaborer un projet de science des données visant à prédire le taux de désabonnement des clients dans une entreprise de télécommunications.
En particulier, vous devez prédire si un client va se désabonner ou non en vous basant sur les données disponibles et sur les facteurs qui augmentent la probabilité qu'un client se désabonne. D'un point de vue technique, il s'agit d'un problème de classification typique de l'apprentissage automatique lorsque les clients sont étiquetés comme 1 (défection) ou 0 (non-défection).
La fraude à la carte de crédit représente un défi majeur dans le secteur bancaire, car ce domaine traite traditionnellement un nombre élevé de transactions en ligne. La détection des fraudes à la carte de crédit est principalement un problème de classification supervisée où nous pouvons appliquer des méthodes telles que les k plus proches voisins (KNN), la régression logistique, les machines à vecteurs de support (SVM) ou l'arbre de décision.
Cependant, il est également possible de résoudre ce problème en utilisant des approches telles que le regroupement, la reconnaissance d'anomalies ou les réseaux neuronaux artificiels.
Ce problème est complexe pour le secteur bancaire en général, car les modes opératoires et les tactiques des fraudeurs évoluent constamment, ce qui oblige les systèmes de détection des fraudes à s'adapter rapidement à ces changements.
Pour un data scientist ou un chercheur en apprentissage automatique, le défi réside également dans la nature même de ces ensembles de données : ils impliquent toujours un déséquilibre entre les classes, car les cas de fraude sont toujours minoritaires (heureusement) et bien dissimulés parmi les transactions réelles (malheureusement).
L'ensemble de données sur la fraude à la carte de crédit contient des informations sur les transactions par carte de crédit dans l'ouest des États-Unis. Veuillez envisager de l'utiliser pour détecter les fraudes à la carte de crédit en appliquant l'approche de classification.
À titre de recommandation supplémentaire, le modèle devrait privilégier une approche plus prudente, ce qui signifie que, dans un souci de sécurité, il n'est pas préjudiciable de signaler des transactions comme frauduleuses alors qu'elles ne le sont pas. Vous pourriez également envisager d'étudier la répartition géospatiale des taux de fraude dans les différents États.
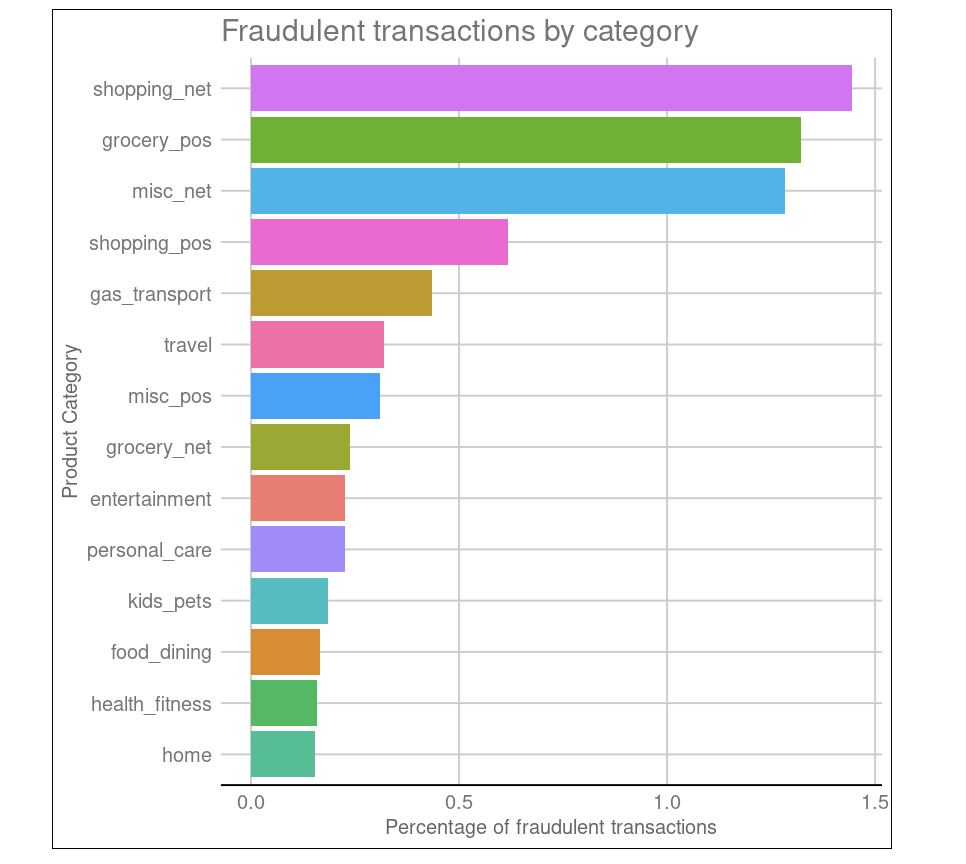
Un autre exemple de projet R issu de DataCamp
Alors que les deux projets précédents concernaient le classement de données dans des catégories prédéfinies, vous devez ici prédire des résultats continus à partir de caractéristiques d'entrée. En d'autres termes, il est nécessaire de résoudre un problème de régression en appliquant des méthodes telles que la régression linéaire, la régression ridge, la régression lasso, l'arbre de décision ou les machines à vecteurs de support (SVM).
L'ensemble de données sur la demande de vélos en libre-service comprend des informations sur le nombre de vélos publics loués dans le système de vélos en libre-service de Séoul par heure, la météo, la date, l'heure, s'il s'agissait d'un jour férié ou non, et plus encore. Votre tâche consiste à estimer le nombre de vélos qui seront loués à partir de ces informations.
Vous pouvez également utiliser ce projet pour comparer le nombre moyen de vélos loués par moment de la journée (matin, après-midi et soir) au cours des quatre saisons, explorer la relation entre la température et le nombre de vélos loués, etc. Le cas échéant, veuillez ajouter des visualisations pertinentes pour appuyer vos conclusions.
Il est toujours judicieux d'inclure dans votre portfolio au moins un projet qui démontre votre capacité à appliquer des approches d'apprentissage non supervisé.
À cette fin, veuillez examiner l'ensemble de données sur le commerce électronique, qui comprend les achats effectués auprès d'un détaillant en ligne basé au Royaume-Uni par des clients de différents pays au cours d'une certaine période.
Un scénario possible serait que le détaillant souhaite faire l'inventaire des articles disponibles. En tant que spécialiste des données potentiel au sein de cette entreprise, il est nécessaire de regrouper les produits en un petit nombre de catégories en fonction de leur similitude selon certaines caractéristiques communes (prix, quantité vendue, etc.). Il s'agit d'un problème de regroupement dans le cadre de l'apprentissage non supervisé, l'algorithme k-means étant le plus couramment utilisé.
Vous pouvez également analyser des questions supplémentaires, telles que les cinq pays qui génèrent le plus de bénéfices ou si les commandes provenant de pays hors du Royaume-Uni sont significativement plus importantes que celles provenant du Royaume-Uni.
Enfin, envisagez de mettre en pratique vos compétences en traitement du langage naturel (NLP) dans R dans l'un de vos projets.
L'ensemble de données SMS Spam Collection contient une collection de plus de 5 500 messages en anglais classés comme spam ou non-spam (« ham »).
À partir de ces données, veuillez créer un filtre capable de distinguer avec précision les spams des messages normaux. Pour ce faire, il est nécessaire d'utiliser un package NLP de R (par exemple, koRpus) afin d'identifier les modèles linguistiques et contextuels dans le texte des messages et de déterminer ce qui caractérise un message spam ou ham, pour ensuite généraliser ces observations aux nouvelles données.
Vous pouvez également identifier les mots les plus fréquemment utilisés dans les spams en créant un nuage de mots.
Pour conclure, nous avons discuté de l'importance de constituer un portfolio de projets pour débuter une carrière dans la science des données, des raisons et de la manière d'utiliser R pour l'analyse des données et la science des données, des sources où trouver des données pertinentes et des exemples de projets R, ainsi que des thèmes que vous pouvez développer dans ces projets, que vous soyez débutant ou avancé dans l'apprentissage de la science des données.
Bien entendu, les suggestions proposées pour vos projets ne constituent qu'une partie des possibilités disponibles. Avec R, vous pouvez accomplir bien plus : créer des systèmes de recommandation, effectuer une segmentation de la clientèle, prévoir les cours boursiers, analyser le sentiment des clients, déterminer le positionnement optimal des taxis, et bien d'autres choses encore.
Que vous aspiriez à devenir data scientist avec R, analyste de données avec R, scientifique en apprentissage automatique avec R ou statisticien avec R, il est essentiel de démontrer vos compétences à travers des projets pratiques. La bibliothèque étendue et le soutien communautaire de R en font un choix idéal pour l'analyse de données, l'apprentissage automatique et le calcul statistique avancé.
En commençant par des projets simples et en abordant progressivement des défis plus complexes, vous pouvez constituer un portfolio qui démontre non seulement vos compétences techniques, mais également votre capacité à tirer des enseignements significatifs des données. Cette expérience pratique impressionnera non seulement les employeurs potentiels, mais vous préparera également aux défis variés et dynamiques auxquels vous serez confronté dans votre carrière en science des données.
Pour plus d'inspiration, veuillez consulter DataLab, un IDE en ligne avec des ensembles de données préchargés et des modèles prédéfinis pour l'écriture de code et l'analyse de données, qui vous aidera à passer de l'apprentissage à la pratique de la science des données.
Cours pour R
Cours
Cours
Cours