 :
: 
Cours
Introduction à Python
4 h
6.9M
Si vous envisagez de vous lancer dans une carrière dans le domaine de la science des données, il est recommandé de commencer à coder le plus tôt possible. Apprendre à coder est une étape essentielle pour tout aspirant data scientist. Cependant, se lancer dans la programmation peut être intimidant, surtout si vous n'avez aucune expérience préalable en codage.
Pour sélectionner le langage de programmation approprié, il est nécessaire d'examiner d'abord les tâches quotidiennes des scientifiques des données. Un data scientist est un expert technique qui utilise des techniques mathématiques et statistiques pour manipuler, analyser et extraire des informations à partir de données. Le domaine de la science des données englobe de nombreux domaines, allant de l'apprentissage automatique et l'apprentissage profond à l'analyse de réseaux, en passant par le traitement du langage naturel et l'analyse géospatiale. Pour accomplir leurs tâches, les scientifiques des données s'appuient sur la puissance des ordinateurs. La programmation est la technique qui permet aux scientifiques des données d'interagir avec les ordinateurs et de leur envoyer des instructions.
Il existe des centaines de langages de programmation, conçus pour divers usages. Certains d'entre eux sont plus adaptés à la science des données, offrant une productivité et des performances élevées pour traiter de grandes quantités de données. Cependant, ce groupe comprend encore un nombre important de langages de programmation.
Dans cet article, nous examinons certains des principaux langages de programmation utilisés en science des données pour 2026 et présentons les atouts et les capacités de chacun d'entre eux.
Toutes les données ont été mises à jour afin de refléter les dernières tendances pour 2026 et au-delà.

Classé premier dans plusieurs indices de popularité des langages de programmation, notamment l'indice TIOBE et l'indice PYPL, Python a connu un essor considérable ces dernières années et reste le langage de programmation le plus populaire. Python est un langage de programmation open source polyvalent qui trouve de nombreuses applications non seulement dans le domaine de la science des données, mais également dans d'autres domaines, tels que le développement web et le développement de jeux vidéo.
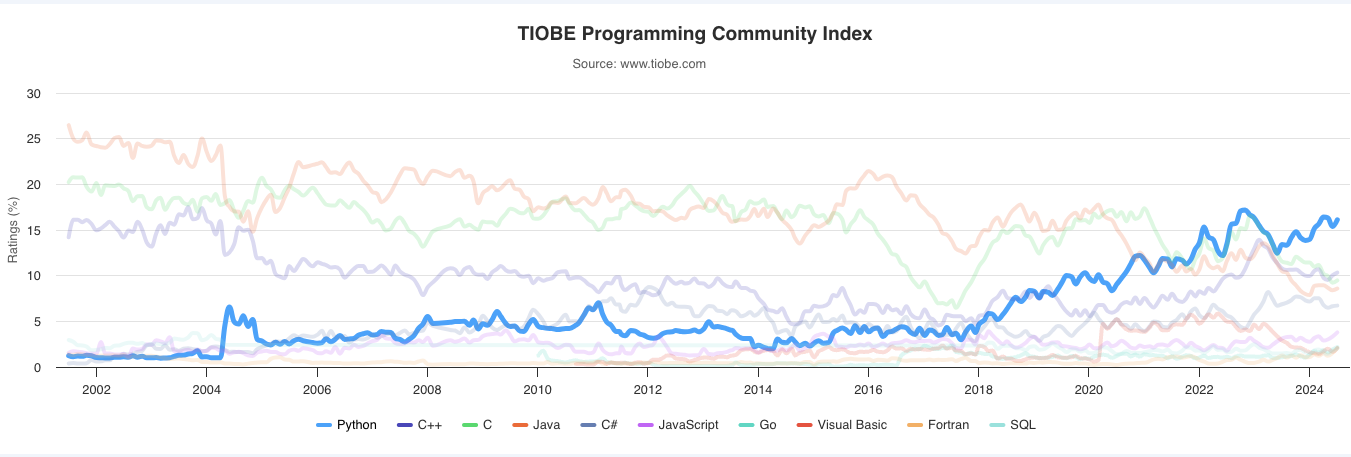
Toutes les tâches liées à la science des données peuvent être réalisées avec Python. Ceci est principalement dû à son riche écosystème de bibliothèques. Grâce à des milliers de packages performants soutenus par une vaste communauté d'utilisateurs, Python est capable d'effectuer toutes sortes d'opérations, du prétraitement des données à la visualisation et à l'analyse statistique, en passant par le déploiement de modèles d'apprentissage automatique et d'apprentissage profond. Voici quelques-unes des bibliothèques les plus utilisées pour la science des données et l'apprentissage automatique :
En raison de sa syntaxe simple et lisible, Python est souvent considéré comme l'un des langages de programmation les plus faciles à apprendre et à utiliser pour les débutants. Si vous débutez dans le domaine de la science des données et que vous ne savez pas quelle langue apprendre en premier, Python est l'une des meilleures options.
Si vous souhaitez devenir un expert en Python, DataCamp est là pour vous aider. Veuillez consulter les cours Python dans notre catalogue et commencez votre formation pour devenir un data scientist accompli.

Bien qu'il ne soit pas aussi tendance que Python ces dernières années, selon les indices de popularité, R est un choix de premier ordre pour les aspirants data scientists. Souvent présenté dans les forums consacrés à la science des données comme le principal concurrent de Python, l'apprentissage de l'un de ces deux langages est une étape essentielle pour se lancer dans ce domaine.
R est un langage open source spécifique à un domaine, explicitement conçu pour la science des données. Très populaire dans les milieux financiers et universitaires, R est un langage idéal pour la manipulation, le traitement et la visualisation des données, ainsi que pour le calcul statistique et l'apprentissage automatique.
Tout comme Python, R bénéficie d'une importante communauté d'utilisateurs et d'une vaste collection de bibliothèques spécialisées pour l'analyse de données. Certains des plus remarquables appartiennent à la famille Tidyverse, une collection de paquets destinés à la science des données. Il comprend dplyr, pour la manipulation des données, et le puissant ggplot2, la bibliothèque standard pour la visualisation des données dans R. En ce qui concerne les tâches d'apprentissage automatique, des bibliothèques telles que caret vous faciliteront considérablement la tâche lors du développement de vos algorithmes.
Bien qu'il soit possible de travailler avec R directement sur la ligne de commande, il est courant d'utiliser Rstudio, une interface tierce puissante qui intègre diverses fonctionnalités, telles qu'un éditeur de données, un visualiseur de données et un débogueur.
Que vous soyez novice en science des données ou que vous souhaitiez ajouter de nouveaux langages à votre arsenal, apprendre le langage R est un choix idéal. Veuillez consulter notre catalogue complet de cours R pour commencer à perfectionner vos compétences.

Une grande partie des données mondiales est stockée dans des bases de données. SQL (Structured Query Language) est un langage spécifique qui permet aux programmeurs de communiquer avec des bases de données, de les modifier et d'en extraire des données. Il est indispensable d'avoir une connaissance pratique des bases de données et du langage SQL si vous souhaitez devenir data scientist.
La maîtrise du langage SQL vous permettra de travailler avec différentes bases de données relationnelles, y compris des systèmes populaires tels que SQLite, MySQL et PostgreSQL. Malgré les différences minimes entre ces bases de données relationnelles, la syntaxe des requêtes de base est assez similaire, ce qui rend SQL très polyvalent.
Que vous choisissiez Python ou R pour débuter votre parcours dans le domaine de la science des données, il est également recommandé d'envisager l'apprentissage du langage SQL. Grâce à sa syntaxe déclarative et simple, le langage SQL est très facile à apprendre par rapport à d'autres langages, et il vous sera d'une grande utilité tout au long de votre parcours.
Souhaitez-vous vous initier au langage SQL ? Veuillez examiner les différents cours SQL et cursus de compétences proposés par DataCamp et préparez-vous à devenir un expert en requêtes. Vous pouvez également obtenir une certification SQL Associate via DataCamp.

Classé n° 2 dans l'indice PYPL et n° 4 dans l'indice TIOBE, Java est l'un des langages de programmation les plus populaires. dans le monde, bien que sa popularité ait diminué au cours de la dernière décennie, tandis que l'intérêt pour des langages tels que Python a considérablement augmenté. Java est un langage open source orienté objet, réputé pour ses performances et son efficacité de premier ordre. De nombreuses technologies, applications logicielles et sites Web dépendent de l'écosystème Java.
Bien que Java soit un choix privilégié pour le développement de sites Web ou la création d'applications à partir de zéro, ces dernières années, Java a acquis un rôle prépondérant dans le secteur de la science des données. Cela s'explique principalement par les machines virtuelles Java, qui fournissent un cadre solide et efficace pour les outils Big Data populaires, tels que Hadoop, Spark et Scala.
En raison de ses performances élevées, Java est un langage adapté au développement de tâches ETL et à l'exécution de tâches de données qui nécessitent un stockage important et des traitements complexes, comme les algorithmes d'apprentissage automatique.

Julia peut être considérée comme une étoile montante dans le domaine de la science des données. Bien qu'il s'agisse de l'un des langages les plus récents de cette liste (il a été lancé en 2011), Julia a déjà impressionné le monde du calcul numérique. Parfois considérée comme l'héritière de Python, Julia est un outil très efficace par rapport aux autres langages utilisés pour l'analyse de données. Pour en savoir plus, nous vous invitons à commencer par notre cursus de compétences Julia Fundamentals.
Bien qu'il ait acquis une certaine notoriété grâce à son adoption précoce par plusieurs grandes organisations, notamment dans le secteur financier, Julia n'est pas aussi largement utilisé que des langages tels que Python et R. Sa communauté est plus restreinte et il ne dispose pas d'autant de bibliothèques que ses principaux concurrents. Malgré cela, Julia est un langage prometteur pour la science des données en raison de sa rapidité, de sa syntaxe claire et de sa polyvalence, et il existe de nombreux cas d'utilisation où il excelle.

Bien qu'il soit peu courant de voir Scala figurer dans le classement des langages de programmation les plus populaires (il occupe actuellement la 21e place dans l'indice PYPL et la 33e place dans l'indice TIOBE), il est indispensable de mentionner ce langage de programmation dans le contexte de la science des données.
Scala est récemment devenu l'un des meilleurs langages pour l'apprentissage automatique et le big data. Lancé en 2004, Scala est un langage multi-paradigmatique explicitement conçu pour offrir une alternative plus claire et moins verbeuse à Java.
Scala fonctionne également sur la machine virtuelle Java, ce qui permet l'interopérabilité avec Java et en fait un langage idéal pour les projets de données massives distribuées. Par exemple, le framework de calcul en cluster Apache Spark est développé en Scala.


Considérés comme deux des langages les plus optimisés, la maîtrise du C et de son proche parent, le C++, peut s'avérer très utile pour traiter des tâches de science des données nécessitant une puissance de calcul importante.
Le C et le C++ sont relativement plus rapides que d'autres langages de programmation, ce qui les rend particulièrement adaptés au développement d'applications de big data et d'apprentissage automatique. Ce n'est pas un hasard si certains des composants essentiels des bibliothèques d'apprentissage automatique populaires, notamment PyTorch et TensorFlow, sont écrits en C++.
En raison de leur nature basique, le C et le C++ comptent parmi les langages les plus complexes à maîtriser. Par conséquent, même s'ils ne constituent pas nécessairement le premier choix lorsque l'on se lance dans le domaine de la science des données, une fois que vous avez acquis une solide compréhension des principes fondamentaux de la programmation, il est judicieux de les maîtriser, car cela peut faire une grande différence sur votre CV.

JavaScript occupe la troisième place dans l'indice PYPL et la sixième place dans l'indice TIOBE, ce qui le classe parmi les langages de programmation les plus populaires au monde. JavaScript est un langage polyvalent et multiparadigme, largement reconnu pour sa capacité à créer des pages web riches et interactives.
Bien que la majorité des utilisateurs de JavaScript travaillent dans le secteur du développement web, ce langage a acquis une notoriété croissante dans le domaine de la science des données au cours des dernières années. Aujourd'hui, JavaScript prend en charge des bibliothèques populaires pour l'apprentissage automatique et l'apprentissage profond, telles que TensorFlow et Keras, ainsi que des outils de visualisation extrêmement puissants, comme D3.
Grâce au soutien des bibliothèques populaires pour l'apprentissage automatique et à sa grande popularité auprès des développeurs web, il s'agit d'une option d'entrée en matière fluide pour tous les programmeurs front-end et back-end qui souhaitent se lancer dans la science des données.

L'un des inconvénients de Python et de R est qu'aucun des deux n'a été conçu pour les appareils mobiles. Au cours des prochaines années, nous pouvons nous attendre à une avancée encore plus importante des technologies mobiles, des appareils portables et de l'Internet des objets (IoT). Swift a été développé par Apple afin de faciliter la création d'applications et, par conséquent, de développer son écosystème d'applications et d'augmenter la fidélisation de sa clientèle. Peu après sa sortie en 2014, Apple et Google ont commencé à collaborer afin d'en faire un outil essentiel dans l'interaction entre les appareils mobiles et l'apprentissage automatique.
Classé n° 9 dans l'indice PYPL et n° 17 dans l'indice TIOBE, Swift est désormais compatible avec TensorFlow et interopérable avec Python. Un avantage supplémentaire de Swift est qu'il n'est plus limité à l'écosystème iOS et qu'il est désormais open source pour fonctionner sous Linux.
Pour ces raisons, si vous êtes développeur mobile et que vous vous intéressez à la science des données, Swift est la solution qu'il vous faut.

Go (ou GoLang) est un langage qui gagne en popularité, en particulier pour les projets d'apprentissage automatique. Il a progressé dans les classements de popularité tant dans l'indice PYPL (12e place) que dans celui de TIOBE (7e place).
Google l'a introduit en 2009 avec une syntaxe et des mises en page similaires à celles du langage C. Selon de nombreux développeurs, Go est la version du langage C adaptée au XXIe siècle. Plus de dix ans après son lancement, Go connaît un succès croissant grâce à sa flexibilité et à sa simplicité. Dans le contexte de la science des données, Go peut constituer un excellent outil pour les tâches d'apprentissage automatique. Malgré ses perspectives prometteuses, la communauté des scientifiques des données de Go reste relativement restreinte.
MATLAB est un langage principalement conçu pour le calcul numérique. Il occupe actuellement la 14e place dans l'indice PYPL et la 12e place dans l'indice TIOBE.
Largement adopté dans le milieu universitaire et la recherche scientifique depuis son lancement en 1984, MATLAB fournit des outils puissants pour effectuer des opérations mathématiques et statistiques avancées, ce qui en fait un excellent candidat pour la science des données. Cependant, MATLAB présente un inconvénient majeur : il s'agit d'un logiciel propriétaire. Selon le cas (utilisation académique, personnelle ou professionnelle), il peut être nécessaire de payer une somme importante pour obtenir une licence, ce qui rend ce langage moins attractif que d'autres langages de programmation pouvant être utilisés gratuitement.

SAS (Statistical Analytical System) est un environnement logiciel conçu pour l'intelligence économique et le calcul numérique avancé. SAS existe depuis longtemps et est largement adopté par les grandes entreprises dans de nombreux secteurs, ce qui crée un marché important pour les développeurs SAS.
Cependant, SAS perd progressivement en popularité face à d'autres langages de programmation utilisés en science des données, tels que Python et R. Cela s'explique principalement par le fait que, comme pour MATLAB, une licence est nécessaire pour utiliser SAS. Cela crée un obstacle à l'entrée pour les nouveaux utilisateurs et les nouvelles entreprises, qui seront enclins à utiliser des langages libres et open source.
Nous espérons que cet article vous aidera à vous orienter dans le paysage riche et varié des langages de programmation utilisés en science des données. Il n'existe pas de langage unique qui soit le plus approprié en termes absolus pour résoudre tous les problèmes et toutes les situations pouvant survenir dans le cadre de votre travail en tant que data scientist. Le choix d'un langage de programmation préféré est subjectif et dépend souvent du parcours d'apprentissage ou de la pile technologique utilisée au travail par le data scientist. Par exemple, Richie Cotton, évangéliste des données chez DataCamp, estime que :
La science des données se concentre de plus en plus sur Python et SQL pour la programmation, bien que R reste populaire et que Julia gagne en importance. Je prévois que cette tendance se poursuivra en 2023 et au-delà, mais il convient de surveiller les outils de veille économique à faible code tels que Power BI et Tableau.
Si vous débutez dans le domaine de la science des données, Python ou R constituent un excellent point de départ. Vous pouvez vous inscrire à nos tutoriels gratuits « Introduction à Python » et « Introduction à R » afin de déterminer lequel vous convient le mieux. À partir de là, la clé du succès réside dans la patience et la pratique. Pour acquérir une expérience pratique en programmation, DataLabest un environnement en ligne qui vous permet d'écrire du code, de mettre en application vos compétences, de collaborer avec d'autres personnes et de créer votre portfolio en science des données.
Une fois que vous vous sentez à l'aise avec le langage que vous avez choisi, vous pouvez passer au niveau supérieur grâce à une formation approfondie en SQL. Heureusement, DataCamp propose une gamme de cours sur le langage SQL.
À partir de là, les possibilités sont infinies. Maîtriser plusieurs langages de programmation constitue un atout, et être capable de passer d'un langage à l'autre en fonction des besoins de votre organisation vous aidera à devenir un data scientist polyvalent et à mener une carrière plus fructueuse.
Pour en savoir plus :
Cours sur Python
Cours
Cours
Cours
blog
Nathaniel Taylor-Leach
8 min
blog
Kurtis Pykes
15 min
blog
Nathaniel Taylor-Leach
blog
Lynn Heidmann
Tutoriel
Sejal Jaiswal
Tutoriel
Matt Crabtree
