
Cursus
Principes fondamentaux de l'IA
10 h
Si vous avez suivi l'actualité technologique, vous avez certainement entendu parler des "grands modèles linguistiques" (Large Language Models - LLM). Les LLM sont actuellement le terme technologique le plus populaire, et leur importance dans le monde de l'intelligence artificielle (IA) s'accroît de jour en jour. Les LLM continuent d'alimenter la révolution de l'IA générative, car ces modèles apprennent à traiter les langues humaines, comme le ChatGPT et le Bard.
Les LLM sont devenus un acteur important sur le marché actuel en raison de leur capacité à refléter les conversations humaines grâce à leurs systèmes de traitement du langage naturel (NLP). Naturellement, tout a ses limites, et les assistants alimentés par l'IA ont leurs propres défis à relever.
Ce défi unique est la possibilité d'un biais LLM, qui est ancré dans les données utilisées pour former les modèles.
Prenons un peu de recul. Qu'est-ce qu'un LLM ?
Les LLM sont des systèmes d'IA tels que le ChatGPT, qui sont utilisés pour modéliser et traiter le langage humain. Il s'agit d'un type d'algorithme d'IA qui utilise des techniques d'apprentissage profond pour résumer, générer et prédire de nouveaux contenus. La raison pour laquelle ils sont qualifiés de "grands" est que le modèle nécessite des millions, voire des milliards de paramètres, qui sont utilisés pour former le modèle à l'aide d'un "grand" corpus de données textuelles.
Les LLM et le NLP travaillent main dans la main, car ils ont pour objectif d'acquérir une grande compréhension du langage humain et de ses schémas et d'apprendre des connaissances en utilisant de grands ensembles de données.
Si vous êtes un novice dans le monde des LLM, l'article suivant est recommandé pour vous mettre au courant :
Qu'est-ce qu'un LLM ? Un guide sur les grands modèles linguistiques et leur fonctionnement. Vous pouvez également suivre notre cours sur les concepts des grands modèles de langage (LLM), qui est également parfait pour découvrir les LLM.
Les LLM ont été largement utilisés dans différents types d'applications d'intelligence artificielle. Ils deviennent de plus en plus populaires et les entreprises cherchent différents moyens de les intégrer dans leurs systèmes et outils actuels afin d'améliorer la productivité du flux de travail.
Les LLM peuvent être utilisés dans les cas suivants :
Les LLM utilisent des modèles Transformer, une architecture d'apprentissage profond qui apprend le contexte et comprend grâce à l'analyse séquentielle des données.
La tokenisation consiste à décomposer le texte d'entrée en unités plus petites appelées "tokens", que le modèle traite et analyse au moyen d'équations mathématiques afin de découvrir les relations entre les différents "tokens". Le processus mathématique consiste à adopter une approche probabiliste pour prédire la prochaine séquence de mots pendant la phase d'apprentissage du modèle.
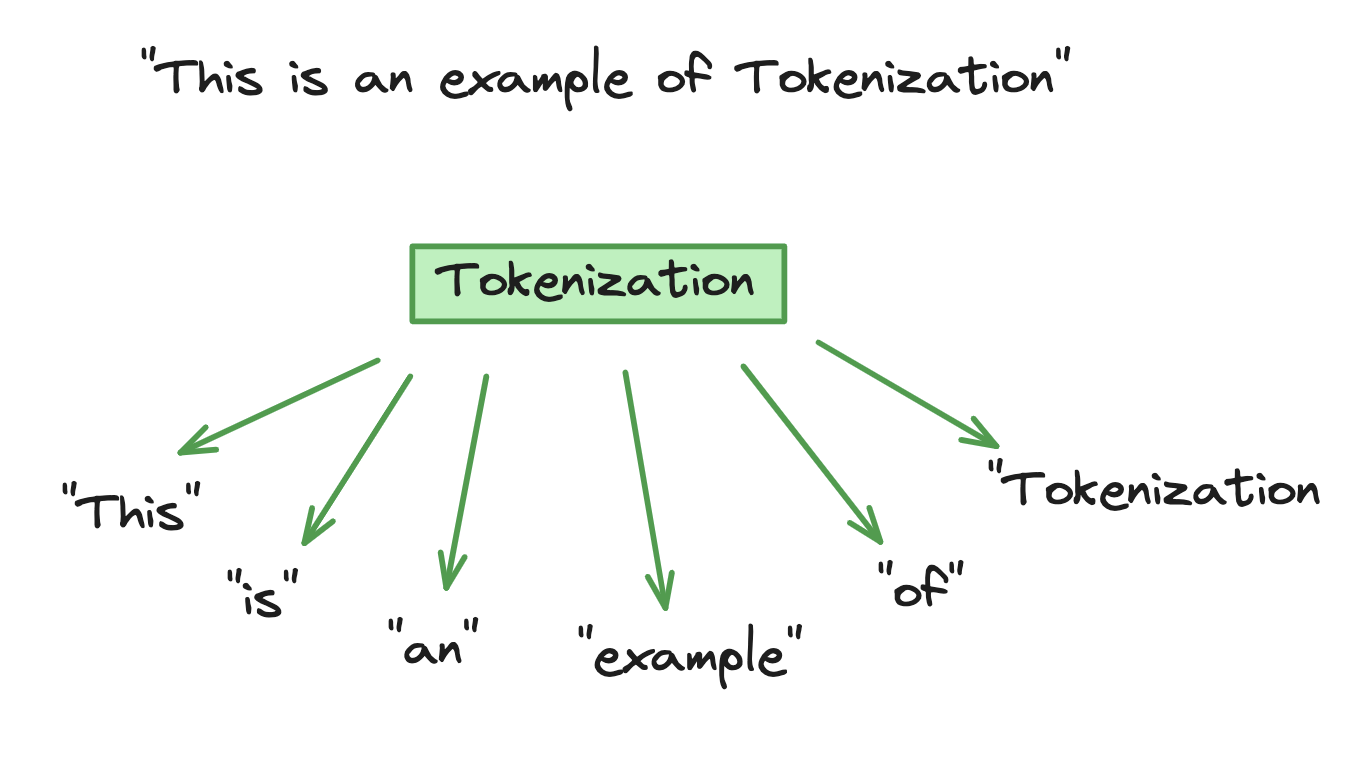
Exemple de tokenisation
La phase d'entraînement consiste à introduire dans le modèle des ensembles massifs de données textuelles afin de l'aider à comprendre les différents contextes, nuances et styles linguistiques. Les LLM créeront une base de connaissances qui leur permettra d'imiter efficacement le langage humain.
La polyvalence et la compréhension des langues que possèdent les LLM témoignent de leurs capacités avancées en matière d'intelligence artificielle. Le fait d'avoir été formés sur de vastes ensembles de données de genres et de styles différents, tels que des documents juridiques et des récits fictifs, a donné aux LLM la capacité de s'adapter à différents scénarios et contextes.
Cependant, la polyvalence des LLM va au-delà de la prédiction de texte. Être capable de gérer des tâches dans différentes langues, différents contextes et différents résultats est un type de polyvalence qui se manifeste dans une variété d'applications d'adaptabilité telles que le service à la clientèle. Cela est dû à la formation approfondie sur de grands ensembles de données spécifiques et au processus de mise au point, qui ont permis d'améliorer son efficacité dans divers domaines.
Toutefois, nous ne devons pas oublier le défi unique que représente le LLM : les préjugés.
Comme nous le savons, les LLM sont formés sur une variété de données textuelles provenant de diverses sources. Lorsque les données sont introduites dans le modèle, celui-ci les utilise comme sa seule base de connaissances et les interprète comme des faits. Cependant, les données peuvent être entachées de préjugés et d'informations erronées, ce qui peut conduire à ce que les résultats du mécanisme d'apprentissage tout au long de la vie reflètent des préjugés.
Un outil connu pour améliorer la productivité et faciliter les tâches quotidiennes présente des aspects éthiques préoccupants. Vous pouvez en savoir plus sur l'éthique de l'IA dans notre cours.
Plus vous disposez de données, mieux c'est. Si les données d'apprentissage utilisées pour les LLM contiennent des échantillons non représentatifs ou des biais, le modèle héritera naturellement de ces biais et les apprendra. Les préjugés liés au sexe, à la race et à la culture sont des exemples de préjugés en matière de gestion du cycle de vie.
Par exemple, les LLM peuvent avoir des préjugés sexistes si la majorité de leurs données montrent que les femmes travaillent principalement comme femmes de ménage ou infirmières, et que les hommes sont généralement ingénieurs ou PDG. Le LLM a hérité des stéréotypes de la société en raison des données de formation qui lui sont fournies. Un autre exemple est celui des préjugés raciaux, dans lesquels les LLM peuvent refléter certains groupes ethniques parmi les stéréotypes, ainsi que les préjugés culturels de surreprésentation pour correspondre au stéréotype.
Les deux principales origines des biais dans les LLM sont les suivantes :
Bien que les LLM soient très polyvalents, ce défi montre que le modèle est moins efficace lorsqu'il s'agit de contenu multiculturel. La préoccupation concernant les MLD et les préjugés se résume à l'utilisation des MLD dans le processus de prise de décision, ce qui soulève naturellement des questions d'ordre éthique.
L'impact des préjugés dans les LLM affecte à la fois les utilisateurs du modèle et la société dans son ensemble.
Comme nous l'avons évoqué plus haut, il existe différents types de stéréotypes, tels que la culture et le sexe. Les préjugés dans les données de formation des LLM continuent à renforcer ces stéréotypes nuisibles, ce qui maintient la société dans le cycle des préjugés et empêche effectivement tout progrès dans la société.
Si les gestionnaires du droit d'auteur continuent d'assimiler des données biaisées, ils continueront à promouvoir la division culturelle et l'inégalité entre les hommes et les femmes.
La discrimination est le traitement préjudiciable de différentes catégories de personnes en fonction de leur sexe, de leur appartenance ethnique, de leur âge ou de leur handicap. Les données d'entraînement peuvent être fortement sous-représentées, c'est-à-dire que les données ne montrent pas une véritable représentation des différents groupes.
Les résultats des LLM qui contiennent des réponses biaisées qui continuent à conserver et à maintenir la discrimination raciale, de genre et d'âge contribuent à l'impact négatif sur la vie quotidienne des personnes issues de communautés marginalisées, comme le processus de recrutement et les opportunités d'éducation. Il en résulte un manque de diversité et d'inclusivité dans les résultats du LLM, ce qui soulève des questions éthiques car ces résultats peuvent être utilisés dans le processus de prise de décision.
Si l'on craint que les données d'apprentissage utilisées pour les MLD contiennent des échantillons non représentatifs ou des biais, la question se pose également de savoir si les données contiennent des informations correctes. La diffusion de fausses informations ou de désinformations par l'intermédiaire des MFR peut avoir des conséquences importantes.
Par exemple, dans le domaine des soins de santé, l'utilisation de MFT contenant des informations biaisées peut conduire à des décisions sanitaires dangereuses. Un autre exemple est celui des LLM qui contiennent des données politiquement biaisées et qui poussent à la désinformation politique.
Les préoccupations éthiques concernant les LLM ne sont pas la principale raison pour laquelle une partie de la société n'a pas bien accueilli la mise en œuvre de systèmes d'IA dans notre vie quotidienne. Certains ou de nombreuses personnes s'inquiètent de l'utilisation des systèmes d'IA et de leur impact sur notre société, par exemple en termes de perte d'emploi et d'instabilité économique.
Les systèmes d'IA suscitent déjà un manque de confiance. Par conséquent, les préjugés produits par les LLM peuvent complètement diminuer la confiance que la société a dans les systèmes d'IA en général. Pour que la technologie LLM soit acceptée en toute confiance, la société doit lui faire confiance.
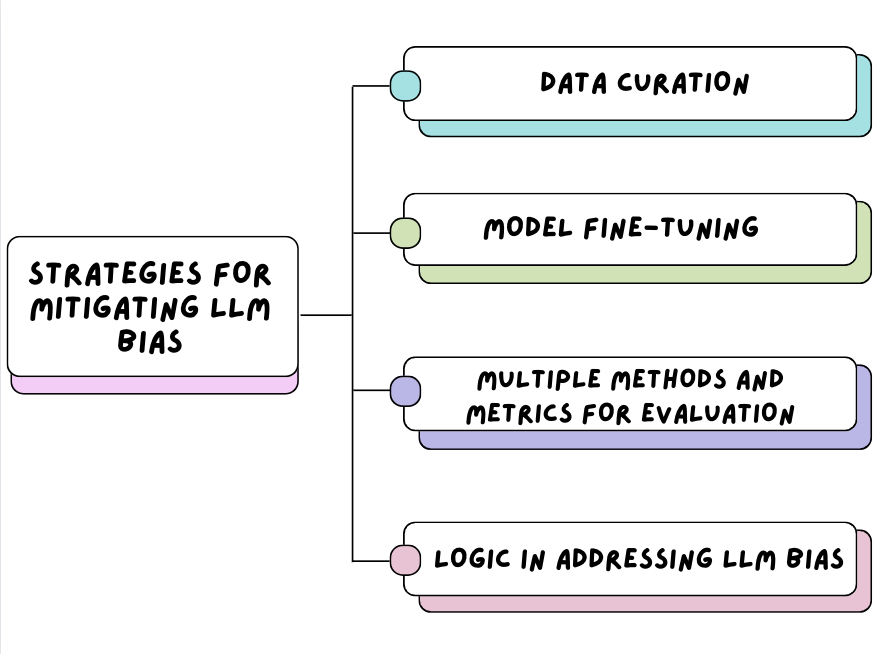
Stratégies d'atténuation des préjugés en matière d'éducation et de formation tout au long de la vie
Commençons par le commencement, les données concernées. Les entreprises doivent être très responsables du type de données qu'elles introduisent dans les modèles.
Veiller à ce que les données d'entraînement utilisées pour les LLM proviennent d'un large éventail de sources de données. Les ensembles de données textuelles provenant de différents groupes démographiques, langues et cultures équilibreront la représentation du langage humain. Cela garantit que les données d'apprentissage ne contiennent pas d'échantillons non représentatifs et oriente les efforts de mise au point du modèle, ce qui peut réduire l'impact des biais lorsqu'il est utilisé par la communauté au sens large.
Une fois qu'une série de sources de données ont été rassemblées et introduites dans le modèle, les organisations peuvent continuer à améliorer la précision et à réduire les biais en affinant le modèle. Il existe plusieurs approches de réglage fin, telles que :
Vous pouvez en savoir plus sur le processus de réglage fin en consultant notre didacticiel Réglage fin de LLaMA 2, qui contient un guide étape par étape pour ajuster le modèle pré-entraîné.
Afin de développer en permanence des systèmes d'IA qui peuvent être intégrés en toute sécurité dans la société d'aujourd'hui, les organisations doivent utiliser de multiples méthodes et mesures dans leur processus d'évaluation. Avant que les systèmes d'IA tels que les LLM ne soient ouverts à une communauté plus large, les méthodes et les mesures correctes doivent être mises en œuvre pour garantir que les différentes dimensions de la partialité sont prises en compte dans les résultats des LLM.
L'évaluation humaine, l'évaluation automatique ou l'évaluation hybride sont des exemples de méthodes. Toutes ces méthodes sont utilisées pour détecter, estimer ou filtrer les biais dans les LLM. Parmi les exemples de mesures, citons l'exactitude, le sentiment, l'équité, etc. Ces mesures peuvent fournir un retour d'information sur les biais dans les sorties LLM et aider à améliorer continuellement les biais détectés dans les LLM.
Si vous souhaitez en savoir plus sur les différentes évaluations utilisées pour améliorer la qualité des LLM, consultez notre code-along sur l'évaluation des réponses aux LLM.
Une étude du Computer Science and Artificial Intelligence Laboratory (CSAIL) du MIT a permis de réaliser des avancées significatives dans les LLM en intégrant le raisonnement logique : Les grands modèles linguistiques sont biaisés. La logique peut-elle aider à les sauver ?
L'importance de la pensée logique et structurée dans les LLM permet aux modèles de traiter et de générer des résultats avec l'application du raisonnement logique et de la pensée critique afin que les LLM puissent fournir des réponses plus précises en utilisant le raisonnement qui les sous-tend.
Le processus consiste à construire un modèle linguistique neutre dans lequel les relations entre les jetons sont considérées comme "neutres" car il n'y a pas de logique indiquant qu'il existe une relation entre les deux. CSAIL a entraîné cette méthode sur un modèle linguistique et a constaté que le nouveau modèle entraîné était moins biaisé sans qu'il soit nécessaire d'obtenir plus de données et d'entraîner davantage l'algorithme.
Les modèles linguistiques logiques auront la capacité d'éviter de produire des stéréotypes nuisibles.
Google Research continue d'améliorer son LLM BERT en élargissant ses données de formation pour s'assurer qu'elles sont plus inclusives et diversifiées. L'utilisation de grands ensembles de données contenant des textes non annotés pour la phase de pré-entraînement a permis d'affiner ultérieurement le modèle pour l'adapter à des tâches spécifiques. L'objectif est de créer un mécanisme d'apprentissage tout au long de la vie qui soit moins biaisé et qui produise des résultats plus solides. Google Research a déclaré que cette méthode a permis de réduire les sorties stéréotypées générées par le modèle et continue d'améliorer ses performances en matière de compréhension des différents dialectes et contextes culturels.
L'équipe de recherche de Google a mis au point plusieurs outils appelés "indicateurs d'équité", qui visent à détecter les biais dans les modèles d'apprentissage automatique et à mettre en œuvre un processus d'atténuation. Ces indicateurs utilisent des mesures telles que les faux positifs et les faux négatifs pour évaluer les performances et identifier les lacunes qui peuvent être masquées par les mesures générales.
OpenAI a assuré la communauté au sens large que la sécurité, la vie privée et les préoccupations éthiques sont au premier plan de ses objectifs. Les mesures d'atténuation prises avant l'entraînement pour DALL-E 2 comprenaient le filtrage des images violentes et sexuelles de l'ensemble des données d'entraînement, la suppression des images d'horreur et des images de violence. Les images qui sont visuellement similaires les unes aux autres, puis l'apprentissage du modèle pour atténuer les effets du filtrage de l'ensemble des données.
Il est parfois impossible de réaliser une chose sans sacrifier l'autre. Ceci s'applique lorsque vous essayez d'atteindre un équilibre entre la réduction du biais LLM et la possibilité de maintenir ou même d'améliorer la performance du modèle. Les modèles de débiaisage sont impératifs pour parvenir à l'équité. Toutefois, les performances et la précision du modèle ne doivent pas être compromises.
Une approche stratégique doit être mise en œuvre pour s'assurer que les méthodes d'atténuation des biais, telles que la conservation des données, la mise au point du modèle et l'utilisation de méthodes multiples, n'affectent pas la capacité du modèle à comprendre et à générer des résultats linguistiques. Des améliorations doivent être apportées, mais la performance du modèle ne doit pas être un compromis.
C'est une question d'essais et d'erreurs, de contrôle et d'ajustement, d'épuration et d'amélioration.
Dans cet article, nous avons abordé les sujets suivants :
Les préjugés liés au LLM constituent un défi complexe et à multiples facettes qui doit être traité en priorité pour que la société lui fasse davantage confiance et accepte librement son intégration dans les tâches quotidiennes. Les organisations doivent comprendre l'impact négatif durable des stéréotypes sur les individus et la société et s'en servir pour s'assurer que la voie vers l'atténuation des biais de la MLT par la conservation des données, l'affinement du modèle et la modélisation logique est tracée.
Pour en savoir plus sur les LLM, consultez notre cours sur les concepts des grands modèles de langage, qui explique comment ces outils puissants remodèlent le paysage de l'IA.
Commencez dès aujourd'hui votre voyage dans l'IA !
Cursus
Cours
Cours