
Track
AI Fundamentals
10 hr
If you’ve been keeping up with the technology world, you’ll have heard the term ‘Large Language Models (LLMs)’ being thrown around. LLMs are currently the most popular tech term, and their significance in the artificial intelligence (AI) world is becoming greater by the day. LLMs continue to fuel the generative AI revolution as these models learn to process human languages, such as ChatGPT and Bard.
LLMs have become a significant player in today's evolving market due to their ability to mirror human conversations through their in-depth natural language processing (NLP) systems. Naturally, everything has its limitations, and AI-powered assistants have their unique challenges.
This unique challenge is the potential for LLM bias, which is entrenched in the data used to train the models.
Let’s take it a step back. What are LLMs?
LLMs are AI systems such as ChatGPT, which are used to model and process human language. It is a type of AI algorithm that uses deep learning techniques to summarize, generate, and predict new content. The reason why they are called “large” is because the model requires millions or even billions of parameters, which are used to train the model using a ‘large’ corpus of text data.
LLMs and NLP work hand in hand as they aim to possess a high understanding of the human language and its patterns and learn knowledge using large datasets.
If you are a newbie to the world of LLMs, the following article is recommended to get you up to speed:
What is an LLM? A Guide on Large Language Models and How They Work. Or take our Large Language Models (LLMs) Concepts Course, which is also perfect for learning about LLMs.
LLMs have been widely used in different types of AI applications. They are becoming more popular by the day, and businesses are looking at different ways to integrate them into their current systems and tooling to improve workflow productivity.
LLMs can be used for the following use cases:
LLMs use Transformer models, a deep learning architecture that learns context and understands through sequential data analysis.
Tokenization is when input text is broken down into smaller units called tokens for the model to process and analyze through mathematical equations to discover the relationships between the different tokens. The mathematical process consists of adopting a probabilistic approach to predict the next sequence of words during the model's training phase.
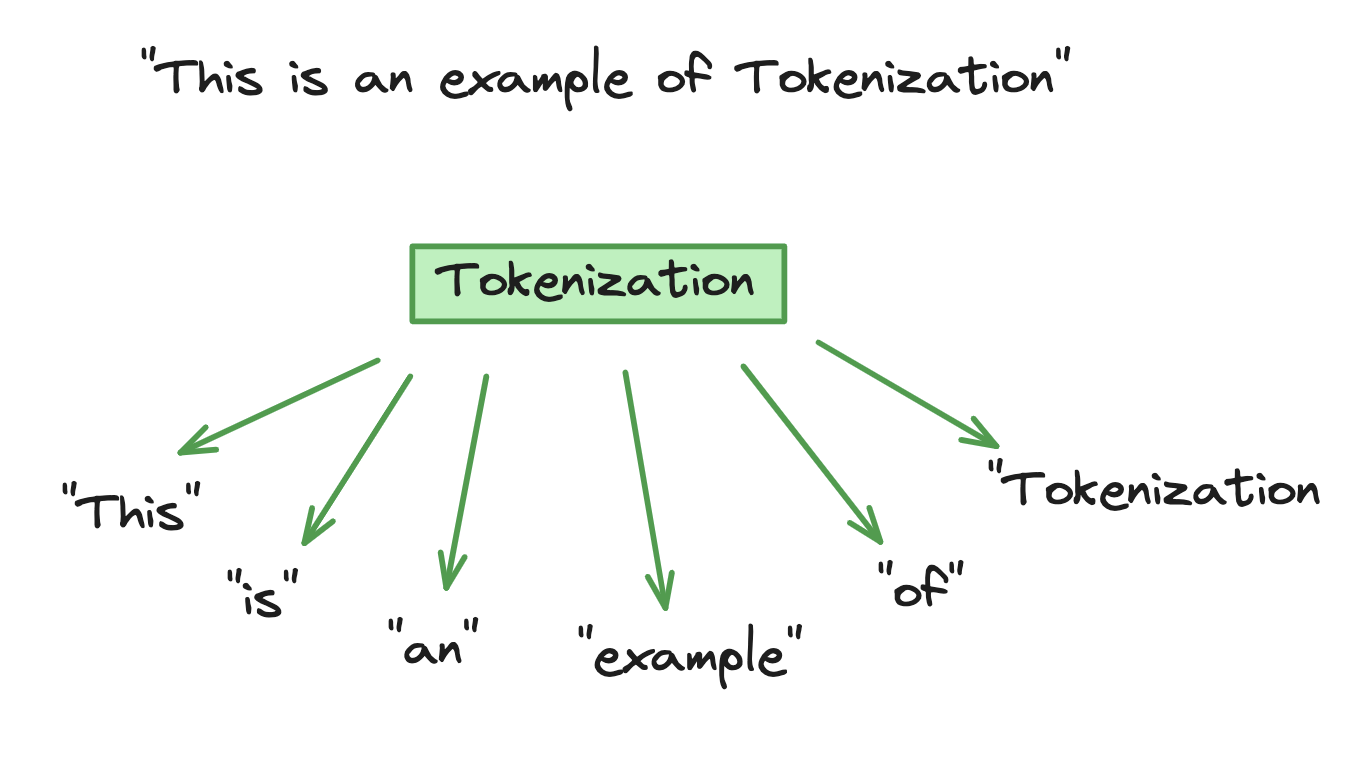
Example of Tokenization
The training phase consists of inputting the model with massive sets of text data to help the model understand various linguistic contexts, nuances, and styles. LLMs will create a knowledge base in which they can effectively mimic the human language.
The versatility and language comprehension that LLMs possess is a testament to their advanced AI capability. Being trained on extensive datasets from various genres and styles, such as legal documents and fictional narratives, has provided LLMs with the ability to adapt to different scenarios and contexts.
However, the versatility of LLMs goes beyond text prediction. Being able to handle tasks in different languages, different contexts, and different outputs is a type of versatility that is shown in a variety of adaptability applications such as customer service. This is thanks to the extensive training on large specific datasets and the fine-tuning process, which has enhanced its effectiveness in diverse fields.
However, we must remember LLM's unique challenge: bias.
As we know, LLMs are trained on a variety of text data from various sources. When the data is inputted into the model, it uses this data as its sole knowledge base and interprets it as factual. However, the data may be ingrained with biases along with misinformation, which can lead to the LLM's outputs reflecting bias.
A tool that is known to improve productivity and assist in day-to-day tasks is showing areas of ethical concern. You can learn more about the ethics of AI in our course.
The more data you have, the better. If the training data used for LLMs contain unrepresentative samples or biases, naturally, the model will inherit and learn these biases. Examples of LLM bias are gender, race, and cultural bias.
For example, LLMs can be biased towards genders if the majority of their data shows that women predominantly work as cleaners or nurses, and men are typically engineers or CEOs. The LLM has inherited society's stereotypes due to the training data being fed into it. Another example is racial bias, in which LLMs may reflect certain ethnic groups among stereotypes, as well as cultural bias of overrepresentation to fit the stereotype.
The two main origins of biases in LLMs are:
Although LLMs are very versatile, this challenge shows how the model is less effective when it comes to multicultural content. The concern around LLMs and biases comes down to the use of LLMs in the decision-making process, naturally raising ethical concerns.
The impacts of bias in LLMs affect both the users of the model and the wider society.
As we touched on above, there are different types of stereotypes, such as culture and gender. Biases in the training data of LLMs continue to reinforce these harmful stereotypes, causing society to stay in the cycle of prejudice and effectively preventing progress in society.
If LLMs continue to digest biased data, they will continue to push cultural division and gender inequality.
Discrimination is the prejudicial treatment of different categories of people based on their sex, ethnicity, age, or disability. Training data can be heavily underrepresented, in which the data does not show a true representation of different groups.
LLMs outputs that contain biased responses that continue to conserve and maintain racial, gender, and age discrimination aid the negative impact on people's daily lives from marginalized communities, such as the recruitment hiring process to opportunities for education. This leads to a lack of diversity and inclusivity in LLMs outputs, raising ethical concerns as these outputs can be further used for the decision-making process.
If there are concerns that the training data used for LLMs contain unrepresentative samples or biases, it also raises the question of whether the data contains the correct information. A spread of misinformation or disinformation through LLMs can have consequential effects.
For example, in the healthcare department, the use of LLMs that contain biased information can lead to dangerous health decisions. Another example is LLMs containing politically biased data and pushing this narrative that can lead to political disinformation.
The ethical concerns around LLMs are not the main reason why some of society have not taken well to the implementation of AI systems in our everyday lives. Some or many people have concerns about the use of AI systems and how they will impact our society, for example, job loss and economic instability.
There is already a lack of trust when it comes to AI systems. Therefore, the bias produced by LLMs can completely diminish any trust or confidence that society has in AI systems overall. In order for LLM technology to be confidently accepted, society needs to trust it.
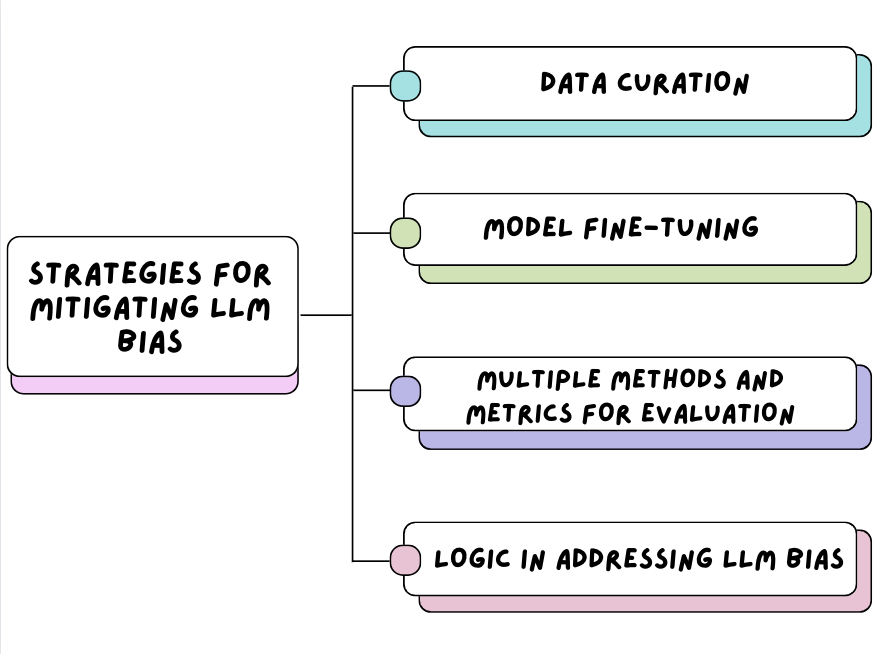
Strategies for Mitigating LLM Bias
Let's start from the beginning, the data involved. Companies need to be highly responsible for the type of data that they input into models.
Ensuring that the training data used for LLMs has been curated from a diverse range of data sources. Text datasets that have come from different demographics, languages, and cultures will balance the representation of the human language. This ensures that the training data does not contain unrepresentative samples and guides targeted model fine-tuning efforts, which can reduce the impact of bias when used by the wider community.
Once a range of data sources has been collated and inputted into the model, organizations can continue to improve accuracy and reduce biases through model fine-tuning. There are several fine-tuning approaches, such as:
You can learn more about the fine-tuning process with our Fine-Tuning LLaMA 2 tutorial, which has a step-by-step guide to adjusting the pre-trained model.
In order to continuously grow AI systems that can be safely integrated with today's society, organizations need to have multiple methods and metrics used in their evaluation process. Before AI systems such as LLMs are open to the wider community, the correct methods and metrics must be implemented to ensure that the different dimensions of bias are captured in LLM outputs.
Examples of methods include human evaluation, automatic evaluation, or hybrid evaluation. All of these methods are used to either detect, estimate, or filter biases in LLMs. Examples of metrics include accuracy, sentiment, fairness, and more. These metrics can provide feedback on the bias in LLM outputs and help to continuously improve the biases detected in LLMs.
If you would like to learn more about the different evaluations used to improve LLM quality, check out our code-along on Evaluating LLM Responses.
A study from MIT's Computer Science and Artificial Intelligence Laboratory (CSAIL) has made significant advancements in LLMs by integrating logical reasoning: Large language models are biased. Can logic help save them?
The importance of logical and structured thinking in LLMs allows the models to be able to process and generate outputs with the application of logical reasoning and critical thinking so that LLMs can provide more accurate responses using the reasoning behind them.
The process consists of building a neutral language model in which the relationships between tokens are considered ‘neutral’ as there is no logic stating that there is a relationship between the two. CSAIL trained this method on a language model and found the newly trained model was less biased without the need for more data and additional algorithm training.
Logic-aware language models will have the ability to avoid producing harmful stereotypes.
Google Research continues to improve its LLM BERT by expanding its training data to ensure that it is more inclusive and diverse. The use of large datasets that contain unannotated text for the pre-training phase has allowed the model to later be fine-tuned to adapt to specific tasks. The aim is to create an LLM that is less biased and produces more robust outputs. Google Research has stated that this method has shown a reduction in stereotypical outputs generated by the model and continues to improve its performance in understanding different dialects and cultural contexts.
The Google Research team has put together several tools called ‘Fairness Indicators,’ which aim to detect bias in machine learning models and go through a mitigating process. These indicators use metrics such as false positives and false negatives to evaluate performance and identify gaps that may be concealed by general metrics.
OpenAI has ensured the wider community that safety, privacy, and ethical concerns are at the forefront of their goals. Their pre-training mitigations for DALL-E 2 included filtering out violent and sexual images from the training dataset, removing images that are visually similar to one another, and then teaching the model to mitigate the effects of filtering the dataset.
Being able to achieve one thing without sacrificing the other can be impossible at times. This applies when trying to achieve a balance between reducing LLM bias while being able to maintain or even improve the model's performance. Debiasing models are imperative to achieve fairness. However, the model's performance and accuracy should not be compromised.
A strategic approach needs to be implemented to ensure that mitigation methods to reduce bias, such as data curation, model fine-tuning, and the use of multiple methods, do not affect the model's ability to understand and generate language outputs. Improvements need to be made; however, the model's performance should not be a trade-off.
It is a matter of trial and error, monitoring and adjustment, debiasing and improvement.
In this article, we have covered:
LLM bias is a complex and multi-faceted challenge that needs to be prioritized for society to have more trust in it and freely accept its integration into everyday tasks. Organizations need to understand the lasting negative impact that stereotypes have on individuals and society and use this to ensure that the path to mitigating LLM biases through data curation, model fine-tuning, and logical modelling is established.
To learn more about LLMs, check out our Large Language Models Concepts course, which covers how these powerful tools are reshaping the AI landscape.
Start Your AI Journey Today!
Track
Course
Course
blog
Javier Canales Luna
12 min
blog
Zoumana Keita
13 min
blog
Dr Ana Rojo-Echeburúa
8 min
podcast
Tutorial
Josep Ferrer
Tutorial
Andrea Valenzuela


