Cours
Introduction aux LLM en Python
3 h
33.6K
Le domaine de l'intelligence artificielle (IA) connaît une explosion des capacités des grands modèles de langage (LLM), qui sont de plus en plus aptes à effectuer des tâches nécessitant une compréhension et une génération sophistiquées du langage humain. Ces modèles devenant de plus en plus puissants, il devient nécessaire de disposer de méthodes d'évaluation robustes.
C'est là qu'intervient le test MMLU (Massive Multitask Language Understanding). Il s'agit d'un test complet et stimulant pour les systèmes d'IA les plus avancés d'aujourd'hui. Le score MMLU est devenu un indicateur clé de la progression d'un modèle et une force motrice dans la quête permanente de la construction de machines plus intelligentes.
Il est important de comprendre la signification et le rôle de la MMLU pour toute personne impliquée dans la science des données ou l'IA, car elle fournit un moyen standardisé d'évaluer les connaissances générales et les capacités de raisonnement de ces modèles sur un large éventail de sujets. Ces capacités sont essentielles à l'élaboration de modèles linguistiques de grande envergure.
Dans cet article, nous verrons ce qu'est le MMLU, en quoi consiste le processus d'évaluation du MMLU, comment est structuré le vaste ensemble de données du MMLU et pourquoi ce critère est si important pour l'avancement de l'IA.
Massive Multitask Language Understanding (MMLU) est un benchmark complet conçu pour évaluer les connaissances et les capacités de résolution de problèmes des grands modèles de langage (LLM) dans une gamme vaste et diversifiée de sujets. Il s'agit de questions à choix multiples couvrant 57 tâches différentes, dont les mathématiques élémentaires, l'histoire des États-Unis, l'informatique, le droit, etc.
L'idée de base du benchmark MMLU est de tester les connaissances acquises et les capacités de raisonnement d'un modèle dans un environnement sans ou avec peu d'exemples, ce qui signifie que le modèle doit répondre à des questions avec peu ou pas d'exemples spécifiques à la tâche.
Cette approche vise à mesurer la capacité des modèles à comprendre et à appliquer les connaissances issues de leur phase de préformation à des tâches pour lesquelles ils n'ont pas été explicitement affinés, ce qui reflète une forme d'intelligence plus générale et plus robuste. La performance d'un modèle est généralement résumée par son score MMLU, qui indique sa précision dans ces différents domaines.
Le cadre d'évaluation MMLU est extrêmement important pour la recherche et le développement en matière d'IA pour plusieurs raisons essentielles, notamment :
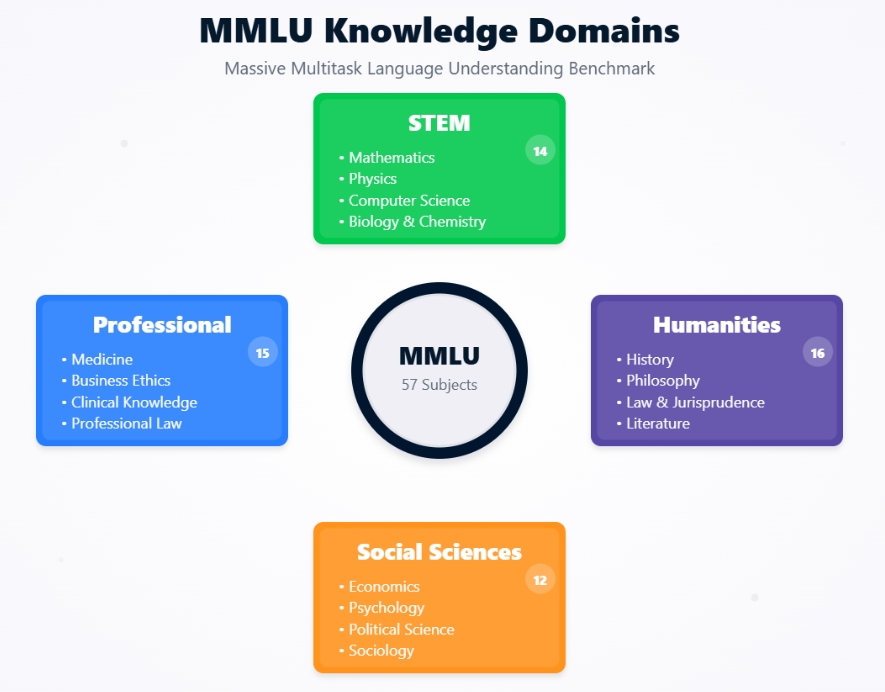
Domaines de connaissances du MMLU
La meilleure façon de comprendre l'émergence de MMLU est d'examiner l'évolution de l'évaluation des modèles linguistiques et les motivations qui ont conduit à sa création.
La MMLU a été introduite par Dan Hendrycks et une équipe de chercheurs dans leur article de 2020 intitulé "Measuring Massive Multitask Language Understanding". La motivation première était l'observation que les points de référence existants étaient saturés par des LLM qui s'amélioraient rapidement.
Les modèles atteignaient des performances quasi-humaines, voire surhumaines, sur des critères de référence tels que GLUE et SuperGLUE, mais il n'était pas toujours évident que cela se traduise par une compréhension du monde plus large, semblable à celle d'un être humain.
Les créateurs du MMLU ont cherché à mettre au point un test plus difficile et plus complet, capable de.. :
L'objectif était de créer une évaluation permettant de mieux différencier les capacités de LLM de plus en plus puissants et de fournir une voie plus claire vers des systèmes intelligents plus généraux.
MMLU représente une étape importante dans l'évolution des critères de référence pour la compréhension du langage naturel (NLU).
Les premières évaluations de NLU se sont souvent concentrées sur des tâches individuelles telles que l'analyse des sentiments, la reconnaissance des entités nommées ou la traduction automatique, chacune ayant son propre ensemble de données et ses propres mesures.
Introduit en 2018, GLUE (General Language Understanding Evaluation) était une collection de neuf tâches NLU diverses, conçues pour fournir une métrique à chiffre unique pour la performance globale du modèle. Il est devenu une norme pendant un certain temps, mais a été rapidement dépassé par des modèles.
Développé en 2019 pour succéder à GLUE, SuperGLUE propose des tâches plus difficiles et une base de référence humaine plus complète. Cependant, même SuperGLUE a vu des modèles se rapprocher rapidement des performances humaines.
MMLU a amélioré ces précédents critères de référence de plusieurs manières essentielles. Avec 57 tâches, l'ensemble de données MMLU est beaucoup plus étendu et couvre un éventail beaucoup plus large de sujets académiques et professionnels que GLUE (9 tâches) ou SuperGLUE (8 tâches + un ensemble de données de diagnostic). Cette étendue rend plus difficile la spécialisation des modèles et encourage une connaissance plus générale.
Alors que GLUE/SuperGLUE ont testé divers phénomènes linguistiques, MMLU évalue directement les connaissances dans des domaines spécifiques tels que le droit, la médecine et l'éthique, ce qui exige plus qu'un simple traitement du langage.
MMLU donne la priorité à l'évaluation de modèles comportant un minimum d'exemples spécifiques à une tâche. Cela contraste avec de nombreuses tâches de GLUE/SuperGLUE, où les modèles ont souvent été affinés sur des ensembles d'entraînement spécifiques à la tâche. L'évaluation MMLU constitue donc un meilleur test de la capacité d'un modèle à se généraliser à partir de son pré-entraînement.
Les questions du MMLU sont souvent conçues pour être difficiles même pour les humains, en particulier dans des domaines spécialisés, ce qui permet de mesurer les progrès de l'IA sur une plus longue période.
En abordant ces aspects, MMLU a établi une nouvelle norme, plus exigeante, sur ce que signifie pour un LLM "comprendre" la langue et le monde.
Pour apprécier à sa juste valeur l'indice de référence MMLU, il est essentiel de comprendre sa structure sous-jacente et la manière dont il évalue les modèles linguistiques. Examinons la composition de l'ensemble de données MMLU, l'étendue des sujets qu'il couvre et les méthodologies d'évaluation spécifiques qui en font un test solide des capacités de l'IA.
La force de l'évaluation du MMLU réside dans son ensemble de données méticuleusement sélectionnées, conçues pour être à la fois larges et profondes.
L'ensemble de données MMLU n'est pas une entité monolithique mais une collection de 57 tâches distinctes, chacune correspondant à un domaine spécifique. Ces sujets sont volontairement diversifiés et couvrent plusieurs grandes catégories :
Chaque tâche de l'ensemble de données MMLU consiste en des questions à choix multiples. En règle générale, chaque question présente un problème ou une requête suivie de quatre réponses possibles, dont une est correcte. Les questions sont conçues pour tester les connaissances à différents niveaux de difficulté, allant de l'école secondaire à l'université et même aux niveaux professionnels experts.
Par exemple, une question dans la matière "Médecine professionnelle" exigerait un niveau de connaissances attendu d'un professionnel de la médecine, ce qui en fait un test difficile même pour des LLM très compétents.
Le volume et la diversité des questions font que les modèles ne peuvent pas se contenter de mémoriser les réponses, mais doivent posséder une véritable compréhension du sujet pour obtenir un score élevé au MMLU.
Les questions de l'ensemble de données MMLU proviennent d'une variété de documents du monde réel afin de garantir leur pertinence et leur difficulté. Ces sources sont les suivantes
Cette stratégie d'approvisionnement garantit que les questions reflètent le type de défis en matière de connaissances et de raisonnement rencontrés dans les contextes académiques et professionnels.
L'objectif est d'évaluer la capacité d'un modèle à comprendre et à appliquer des connaissances dans des contextes similaires à ceux auxquels sont confrontés les humains instruits.
Un aspect essentiel de la signification du MMLU et de son pouvoir d'évaluation réside dans son utilisation des paradigmes d'apprentissage à zéro et à quelques coups. Ces méthodologies sont importantes pour tester la capacité d'un modèle à généraliser ses connaissances sans une formation approfondie à une tâche spécifique.
Dans le cadre d'un essai à zéro, le LLM se voit présenter des questions provenant d'une tâche spécifique du MMLU (par exemple, "Algèbre abstraite" ou "Scénarios moraux") sans avoir vu aucun sans avoir vu d'exemples de cette tâche particulière pendant sa phase de réglage ou dans l'invite elle-même.
Le modèle doit comprendre la question et sélectionner la bonne réponse à choix multiples en se basant uniquement sur ses connaissances pré-entraînées.
Par exemple, l'invite peut être simplement la suivante :
Les questions suivantes sont des questions à choix multiples (avec réponses) sur [nom du sujet].
[Question]
A) [Option A]
B) [Option B]
C) [Option C]
D) [Option D]
Réponse :
Le modèle doit ensuite fournir la lettre de l'option correcte. Cette configuration permet de tester rigoureusement la capacité du modèle à généraliser sa compréhension à des domaines et des styles de questions entièrement nouveaux.
Dans le cas d'une configuration à quelques tirages, le modèle reçoit un petit nombre d'exemples (généralement cinq, d'où le terme "5 tirages") de la tâche spécifique de l'UMLM directement dans l'invite avant avant de rencontrer la question du test.
Ces exemples se composent d'une question, d'options à choix multiples et de la bonne réponse.
Par exemple :
Les questions suivantes sont des questions à choix multiples (avec réponses) sur les différends moraux.
Question : John Doe est un ingénieur logiciel qui travaille pour une entreprise qui développe des armes autonomes. Il a de sérieuses préoccupations éthiques quant à l'utilisation abusive potentielle de cette technologie, qui pourrait entraîner des pertes civiles. Cependant, il a également une famille à charge et craint de perdre son emploi s'il s'exprime. Quel est le principal conflit éthique auquel John est confronté ?
A) Conflit d'intérêts
B) Le dilemme du dénonciateur
C) Faute professionnelle
D) Droits de propriété intellectuelle
Réponse : B
[... 4 autres exemples ...]
Question : [Question test réelle]
A) [Option A]
B) [Option B]
C) [Option C]
D) [Option D]
Réponse :
Le modèle utilise ces quelques exemples pour comprendre le contexte, le style et le raisonnement attendu pour la tâche avant de tenter la nouvelle question inédite. Cela permet de tester la capacité du modèle à apprendre et à s'adapter rapidement, en contexte.
L'importance de ces méthodologies pour l'évaluation de la MMLU réside dans le fait qu'elles reflètent la manière dont les êtres humains abordent souvent les nouveaux problèmes, soit en appliquant les connaissances existantes à quelque chose d'entièrement nouveau (zero-shot), soit en apprenant rapidement à partir de quelques exemples (few-shot).
Ces paramètres d'évaluation simulent des tâches courantes de traitement du langage dans le monde réel.
Les scénarios d'essai sont comparables à une question posée par un utilisateur à une IA sur un sujet sur lequel l'IA n'a jamais été interrogée auparavant. Par exemple, un utilisateur peut poser une question juridique complexe ou une requête philosophique nuancée à un assistant d'IA généraliste. La capacité de l'IA à fournir une réponse sensée repose sur ses vastes connaissances pré-entraînées.
Les scénarios à court terme reflètent des situations dans lesquelles un utilisateur fournit un contexte ou des exemples pour guider l'IA. Par exemple, un utilisateur peut montrer à l'IA quelques exemples de résumés de rapports médicaux avant de lui demander d'en résumer un nouveau, ou fournir des exemples d'un style poétique spécifique avant de demander à l'IA de générer un poème dans ce style.
En évaluant les modèles à la fois dans le cadre d'un essai à zéro et d'un essai à quelques, MMLU fournit une image plus complète de leur flexibilité et de leurs capacités d'apprentissage, qui sont importantes pour construire des systèmes d'intelligence artificielle réellement utiles et adaptables.
La capacité d'obtenir de bons résultats dans ces conditions est un bon indicateur du potentiel d'un modèle à être appliqué dans la pratique à un large éventail de tâches, sans qu'il soit nécessaire de procéder à un réentraînement important et coûteux pour chaque nouveau problème.
L'évolution des modèles de langage sur le benchmark MMLU met en évidence le développement rapide de l'IA. Examinons les performances initiales, les progrès ultérieurs des scores MMLU et comparons les capacités de l'IA avec les références des experts humains.
Introduit fin 2020, le MMLU a rapidement révélé les limites des LLM existants à la pointe de la technologie. Les premières rencontres avec l'ensemble de données MMLU ont été difficiles. Les scores MMLU initiaux pour la plupart des modèles contemporains se situaient autour de 25-30%, tandis que le plus grand GPT-3 atteignait ~44%.
Comme vous pouvez le constater, même les modèles capables, comme les premières versions du GPT-3, ont connu des difficultés, ce qui montre qu'une compréhension large, semblable à celle de l'homme, est encore loin d'être acquise.
Parmi les principaux défis à relever, citons les lacunes en matière de connaissances spécialisées (droit, médecine, etc.), un raisonnement complexe limité, une fragilité dans les scénarios à zéro ou à peu d'occasions, et une vulnérabilité face aux options de distraction dans les questions. Ces résultats soulignent la valeur du MMLU dans l'identification des frontières du LLM.
Depuis les débuts de MMLU, les performances de LLM ont fait un bond en avant. Ces progrès découlent d'innovations architecturales, d'une augmentation de l'échelle du modèle, de meilleures données d'entraînement et de méthodes affinées telles que le réglage fin des instructions et l'apprentissage par renforcement à partir du retour d'information humain (RLHF). En conséquence, les scores du MMLU ont fortement augmenté.
Parmi les principaux facteurs, citons la confirmation des lois d'échelle, les perfectionnements architecturaux des transformateurs, les techniques de formation avancées qui améliorent le raisonnement et l'alignement, et la conception inhérente de MMLU qui favorise les compétences multitâches. Le développement de pratiques MLOps sophistiquées a également joué un rôle crucial dans l'optimisation des processus de formation et de déploiement des modèles.
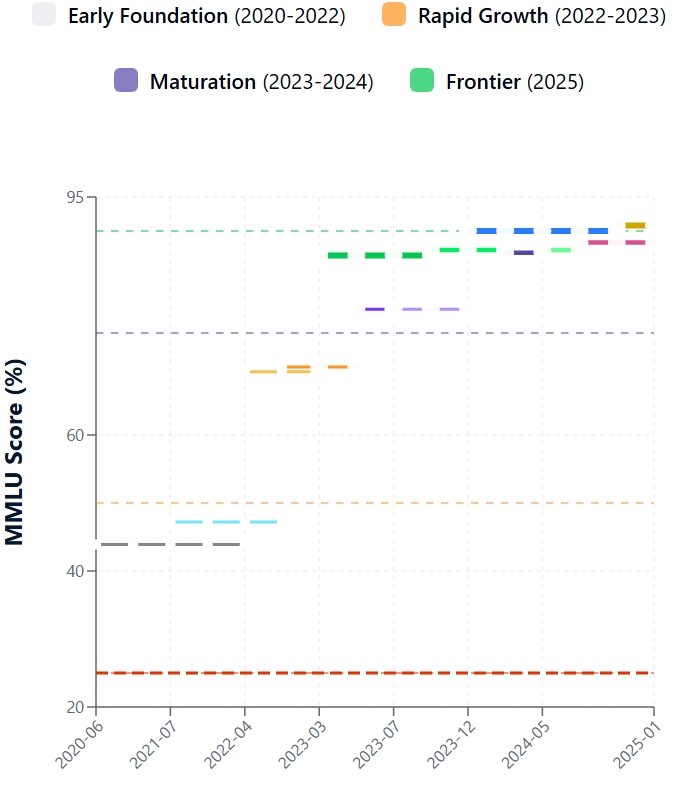
Évolution du score du MMLU
MMLU juxtapose de manière cruciale les performances de l'IA et l'intelligence humaine. La recherche originale MMLU a fixé la précision des experts humains à environ 90 %. Dans un premier temps, l'apprentissage tout au long de la vie a pris un retard considérable. Toutefois, les modèles les plus récents ont considérablement réduit cet écart.
Les principaux modèles affichent désormais des scores MMLU qui atteignent ou dépassent légèrement la valeur de référence moyenne des experts humains. Il est essentiel de noter que l'expression "expert humain" est une fourchette et que les performances du modèle varient en fonction du sujet. Par exemple, le récent modèle GPT-4.1 affiche un score de 90,2 % au MMLU, et Claude 4 Opus atteint 88,8 %.
Bien qu'impressionnant, le fait de dépasser les scores moyens n'équivaut pas à une compréhension, un bon sens ou une créativité semblables à ceux de l'homme. Les modèles peuvent encore être fragiles ou se heurter à des raisonnements nouveaux. Les résultats des tirs zéro, qui constituent un test plus pur de la généralisation, se sont également améliorés, mais ils sont souvent inférieurs aux résultats des tirs peu nombreux.
Atteindre et parfois dépasser les scores MMLU des experts humains a de profondes implications : cela valide les progrès de l'IA, renforce l'utilité dans le monde réel dans les domaines à forte intensité de connaissances, catalyse le développement de critères de référence plus difficiles (comme MMLU-Pro) et intensifie les dialogues éthiques et sociétaux sur le rôle de l'IA. Si des scores élevés au MMLU sont des étapes clés, l'accent reste mis sur la création d'une IA robuste, interprétable et conforme à l'éthique.
Alors que le benchmark MMLU original a fait progresser de manière significative l'évaluation du LLM, ses limites sont devenues évidentes avec les progrès rapides de l'IA. Cela a conduit à des dérivés tels que MMLU-Pro et MMLU-CF, visant à des évaluations plus rigoureuses.
Le MMLU initial a été confronté à plusieurs défis au fur et à mesure que les modèles devenaient plus sophistiqués. Une préoccupation majeure est que les questions de l'ensemble de données MMLU disponibles publiquement peuvent se trouver dans les données de formation LLM, gonflant les scores MMLU et ne reflétant pas la vraie généralisation.
Dans tout grand benchmark, certaines questions peuvent être erronées, ambiguës ou obsolètes, ce qui affecte la fiabilité de l'évaluation du MMLU. Au fur et à mesure que les meilleurs modèles s'approchaient des scores parfaits, la capacité du MMLU à différencier les capacités de raisonnement avancées diminuait, ce qui a incité à demander des tâches plus complexes.
Son ensemble de questions fixes n'évolue pas en fonction des avancées du modèle ou des nouveaux domaines de connaissance. Comme il s'agit d'un questionnaire à choix multiples, le MMLU ne teste pas les capacités génératives, explicatives ou créatives essentielles du LLM. Il est essentiel d'aborder ces questions pour une évaluation significative de l'IA.
MMLU-Pro a été développé pour tester un raisonnement plus profond avec des questions plus difficiles. MMLU-Pro augmente la difficulté de l'évaluation en se concentrant sur des questions exigeant une compréhension approfondie et un raisonnement sophistiqué. Les principales améliorations sont les suivantes
MMLU-Pro reflète les efforts en cours pour garantir que les critères de référence favorisent les progrès du raisonnement en matière d'IA.
MMLU-CF (Contamination-Free) s'attaque spécifiquement à la contamination des données dans l'évaluation comparative du LLM. MMLU-CF vise à fournir une évaluation MMLU avec des questions très peu susceptibles de figurer dans les données d'apprentissage du modèle. Les stratégies sont les suivantes :
MMLU-CF est important pour l'intégrité des repères. Un score élevé au MMLU sur une version sans contamination indique de manière plus fiable une véritable généralisation et un raisonnement, et non une mémorisation. Cela est essentiel pour assurer un cursus précis des progrès de l'IA et une comparaison équitable des modèles.
La création et la large acceptation du benchmark MMLU ont eu un impact significatif sur le domaine de l'IA, en façonnant à la fois les recherches théoriques et les utilisations dans le monde réel. Il est essentiel de comprendre ses implications pour saisir son importance globale.
Le MMLU a considérablement influencé l'orientation de la recherche sur l'intelligence artificielle. En fixant un niveau élevé de connaissances et de raisonnement, il a été à l'origine d'innovations dans l'architecture des modèles et les méthodologies de formation.
Les chercheurs explorent constamment de nouveaux moyens d'améliorer le score MMLU de leurs modèles, ce qui permet de réaliser des progrès dans des domaines tels que :
L'intégration des méthodologies LLMOps est devenue essentielle pour gérer ces processus de développement de modèles de plus en plus complexes.
En outre, l'émergence d'approches innovantes telles que LMQL pour les interactions structurées avec les LLM démontre que le domaine se développe pour créer des outils plus spécialisés pour travailler avec les LLM.
Les capacités obtenues en s'efforçant d'améliorer l'évaluation MMLU se traduisent directement par des applications plus puissantes et plus fiables dans le monde réel.
Les modèles qui obtiennent de bons résultats au MMLU sont généralement plus aptes à effectuer des tâches nécessitant une compréhension et un raisonnement approfondis, ce qui leur ouvre des portes dans divers secteurs d'activité, tels que l'industrie automobile :
Les progrès reflétés dans les scores MMLU soulignent l'utilité croissante des grands modèles linguistiques dans ces domaines.
Des implémentations modernes comme Llama 3 montrent comment les LLM avancés peuvent être déployés efficacement dans des scénarios réels.
L'évaluation des modèles linguistiques est loin d'être terminée. Le MMLU lui-même, ainsi que ses dérivés, indiquent plusieurs tendances et défis émergents.
Les futurs critères de référence intégreront probablement des formats d'évaluation plus diversifiés, notamment des réponses à des questions ouvertes, des dialogues interactifs et la réalisation de tâches dans des environnements simulés, afin d'évaluer un éventail plus large de capacités d'IA.
L'IA évoluant vers la compréhension et la génération de contenu à partir de textes, d'images, de sons et de vidéos, les critères de référence devront évoluer pour évaluer ces compétences multimodales.
L'accent est mis de plus en plus sur l'élaboration de critères de référence qui testent rigoureusement la sécurité, l'équité, la partialité et l'alignement éthique des modèles. La mise en œuvre de flux de travail MLOps automatisés sera cruciale pour maintenir l'intégrité de l'évaluation à l'échelle.
Garantir l'intégrité des références grâce à des méthodes telles que celles de MMLU-CF restera un défi majeur, en particulier lorsque les organisations adopteront des cadres MLOps complets pour gérer leurs systèmes d'intelligence artificielle.
Le benchmark MMLU a indéniablement remodelé la manière dont nous mesurons et faisons progresser les grands modèles de langage. De son ensemble de données MMLU complet à ses méthodes d'évaluation MMLU stimulantes, il pousse l'IA vers une connaissance plus large et un raisonnement plus approfondi. Les modèles continuent d'évoluer, tout comme les critères qui les guident, garantissant ainsi un avenir où l'IA sera de plus en plus performante et polyvalente.
Prêt à aller plus loin dans le monde des LLM et des MLOps ? Explorez le cours sur les concepts des grands modèles de langage (LLM) pour développer votre expertise.
Les meilleurs cours de DataCamp
Cours
Cours
Cours