
Programa
Associate AI Engineer para desenvolvedores
26 h
A Meta acaba de lançar a série Llama 4, que inclui dois modelos avançados: Llama 4 Scout e Llama 4 Maverick. Ambos são de peso aberto, mas o ajuste fino do Llama 4 Scout requer quatro GPUs H100, e o Llama 4 Maverick precisa de oito. Isso significa que somente empresas com recursos substanciais podem se dar ao luxo de ajustá-los.
Neste blog, mostrarei a você como fazer o ajuste fino do Llama 4 Scout por apenas US$ 10 usando a plataforma RunPod. Você aprenderá:
Mantemos nossos leitores atualizados sobre as últimas novidades em IA enviando o The Median, nosso boletim informativo gratuito de sexta-feira que detalha as principais histórias da semana. Inscreva-se e fique atento em apenas alguns minutos por semana:
Vá para o RunPod e crie uma conta. Depois disso, vá para a seção Runpod Billing (Cobrança da Runpod) e adicione US$ 25 usando o cartão de crédito. Você também pode pagar com criptomoeda.
Navegue até a seção Meus pods para começar a configurar seu pod. O pod funciona como um servidor virtual que fornece a você as CPUs, GPUs, memória e armazenamento necessários para suas tarefas.
Selecionaremos 3 GPUs H200 SXM, que fornecerão memória suficiente para carregar o modelo , quantizar e fazer o ajuste fino no novo conjunto de dados. Como alternativa, você pode usar a função Unsloth para executar o modelo em um único H100 - no entanto, essa abordagem não funcionou bem para mim.
Para configurar seu pod, siga estas etapas:
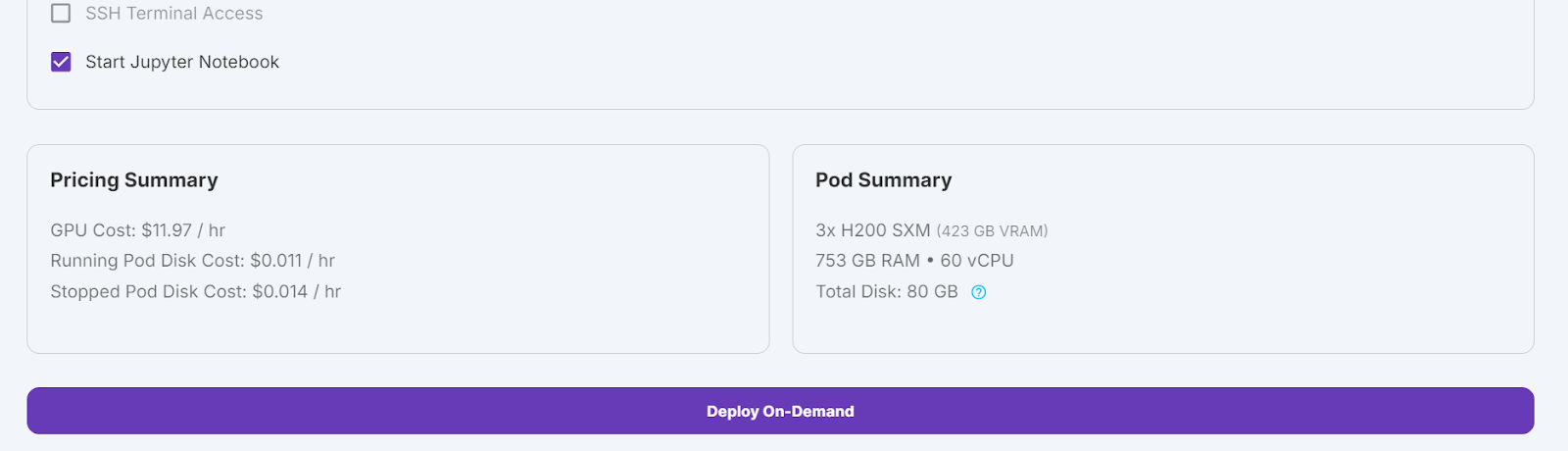
Editaremos o nosso pod aumentando o tamanho do disco do contêiner para 300 GB e adicionando a variável de ambiente HF_TOKEN, que é o token de acesso Hugging Face que você usa. Esse token é essencial para carregar e salvar o modelo com eficiência.
Você levará algum tempo para configurar o contêiner. Quando tudo estiver configurado, clique no botão "Connect" (Conectar) e inicie a instância do JupyterLab.
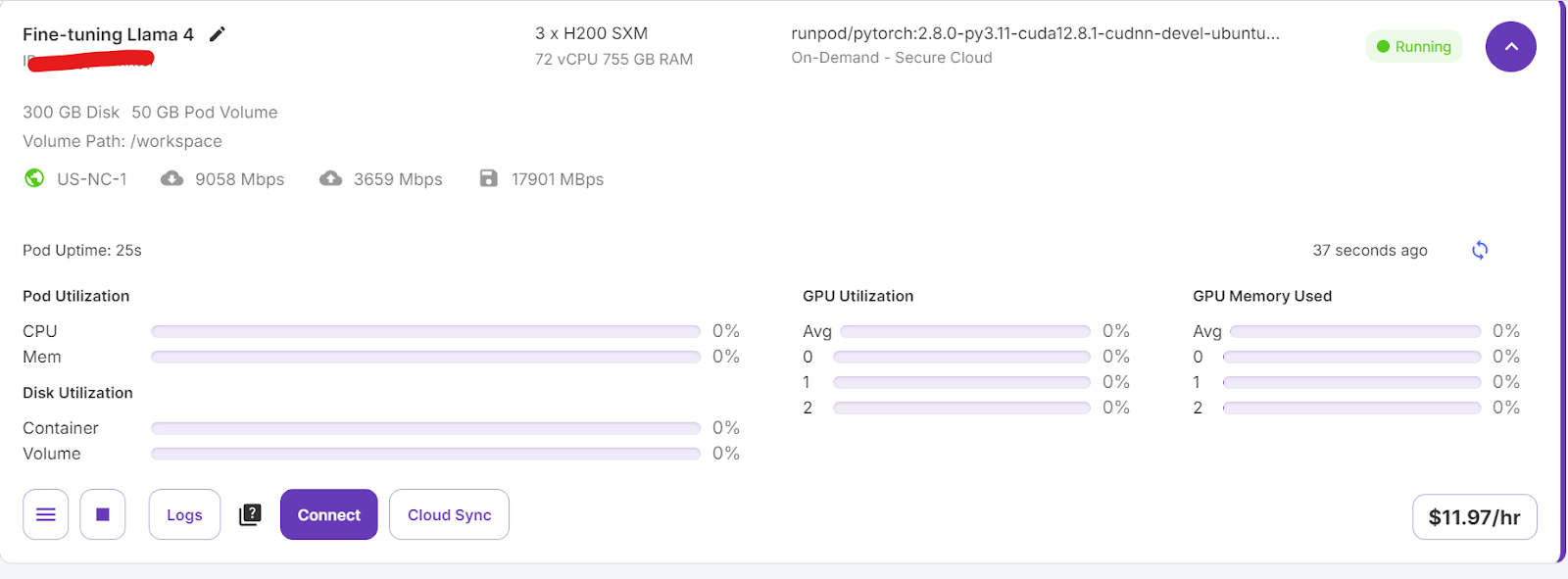
Crie um novo notebook e comece a usar esse novo ambiente, semelhante à sua configuração local.
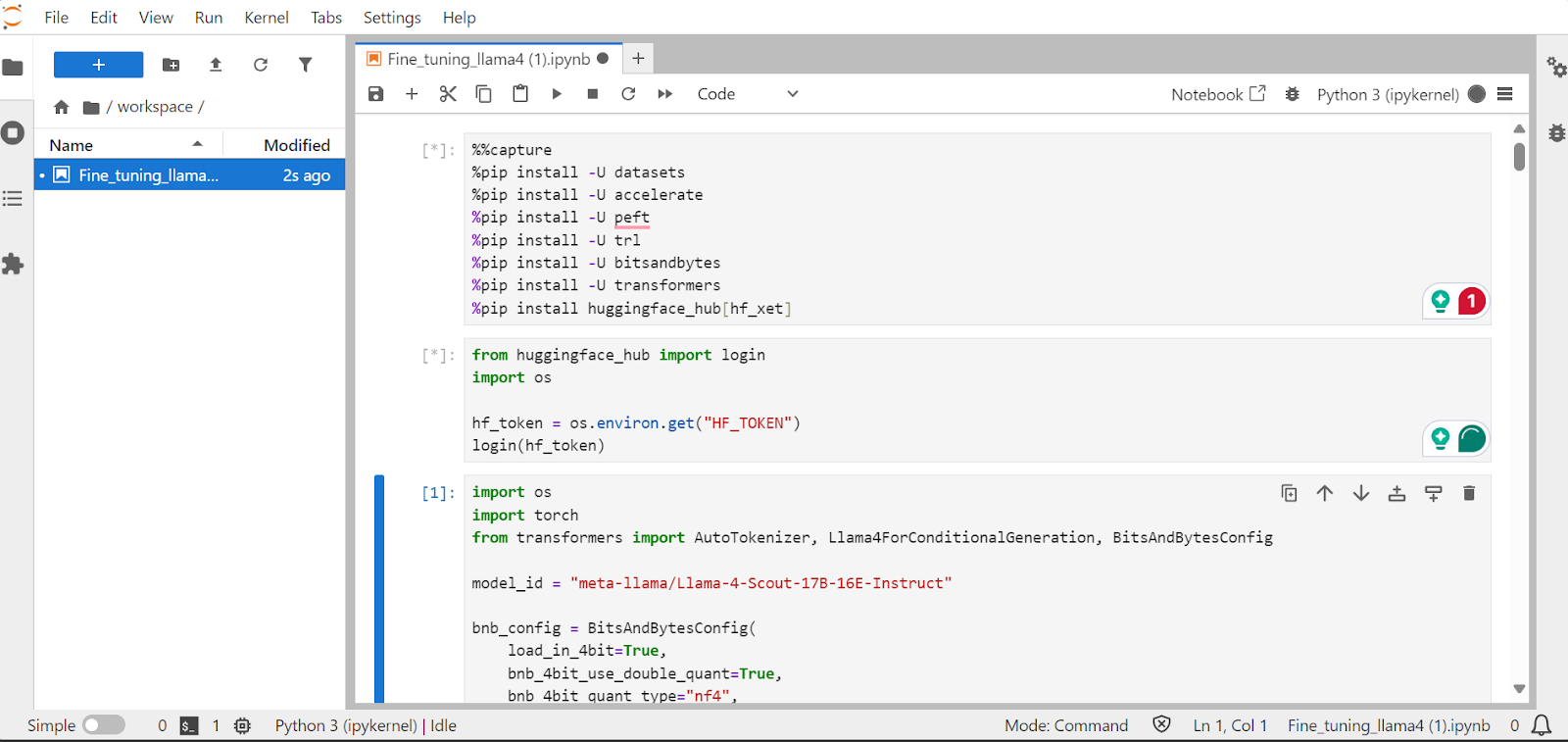
Nesta seção, aprenderemos a lidar com desafios comuns ao fazer o ajuste fino do novo modelo Llama 4, como problemas de falta de memória e bugs na biblioteca Transformers. Também abordaremos como carregar, ajustar e salvar o adaptador LoRA sem problemas. Ao seguir essas etapas, você pode se concentrar no processo de ajuste fino sem se preocupar com obstáculos técnicos.
Instalaremos os pacotes Python necessários para que você possa fazer o ajuste fino dos modelos de linguagem grandes.
Observação:
xet que é mais rápida do que Git-LFS. Essa integração aumentará a velocidade de download em três vezes.%%capture
!pip install transformers==4.51.0
%pip install -U datasets
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install huggingface_hub[hf_xet]Carregue a chave de API da variável de ambiente variável de ambiente para que você faça login no Hugging Face. Ao fazer login, você pode obter acesso a modelos fechados e também salvar modelos e tokenizadores ajustados.
from huggingface_hub import login
import os
hf_token = os.environ.get("HF_TOKEN")
login(hf_token)Carregue o Llama-4-Scout-17B-16E-Instruct com quantização de 4 bits para uso eficiente da memória. Certifique-se de que você definiu device_map como auto para usar todas as três GPUs H200.
Observação: Verifique se você tem acesso ao modelo, pois esse modelo é fechado e exige que você preencha o formulário acessando o site meta-llama/Llama-4-Scout-17B-16E-Instruct URL.
import os
import torch
from transformers import AutoTokenizer, Llama4ForConditionalGeneration, BitsAndBytesConfig
model_id = "meta-llama/Llama-4-Scout-17B-16E-Instruct"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model = Llama4ForConditionalGeneration.from_pretrained(
model_id,
device_map="auto",
torch_dtype=torch.bfloat16,
quantization_config=bnb_config,
trust_remote_code=True,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
Também carregaremos o tokenizador usando o mesmo ID de modelo.
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)Ao executar o comando abaixo, você pode verificar a quantidade de memória restante para configurar o treinador e ajustar o modelo.
!nvidia-smi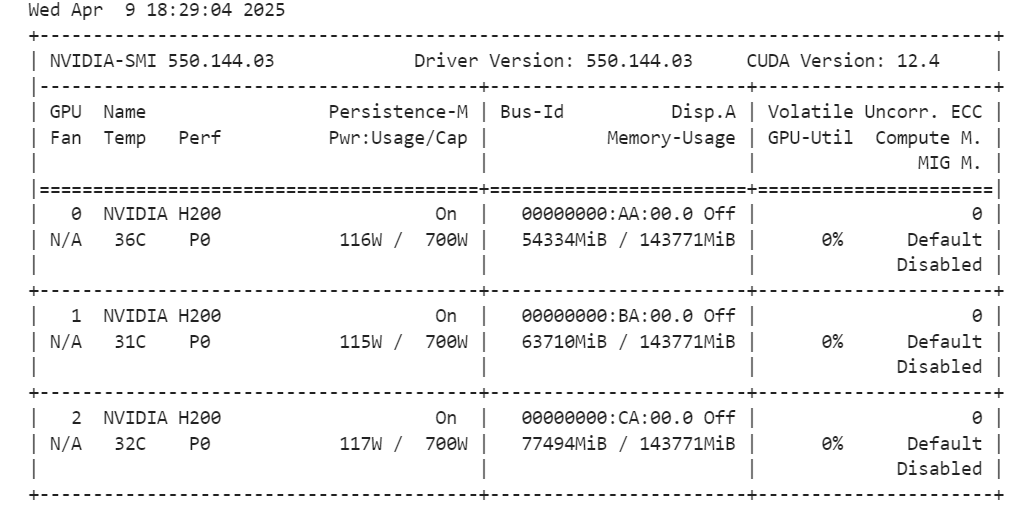
Criaremos um estilo de prompt para o modelo, incluindo um prompt do sistema com espaços reservados para a pergunta, cadeia de pensamentoe resposta. Esse prompt ajudará o modelo a pensar passo a passo e a dar respostas claras e precisas.
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""Em seguida, criaremos a função Python para gerar a coluna “text” usando o estilo do prompt de treinamento e as colunas do conjunto de dados.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
complex_cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for question, cot, response in zip(inputs, complex_cots, outputs):
# Append the EOS token to the response if it's not already there
if not response.endswith(tokenizer.eos_token):
response += tokenizer.eos_token
text = train_prompt_style.format(question, cot, response)
texts.append(text)
return {"text": texts}Carregaremos as primeiras 500 amostras do arquivo FreedomIntelligence/medical-o1-reasoning-SFT disponíveis no Hugging Face Hub e, em seguida, aplicaremos a função formatting_prompts_func para criar a coluna “text”.
from datasets import load_dataset
dataset = load_dataset("FreedomIntelligence/medical-o1-reasoning-SFT","en", split = "train[0:500]",trust_remote_code=True)
dataset = dataset.map(formatting_prompts_func, batched = True,)
dataset["text"][0]A coluna "texto" tem um prompt do sistema, instruções, pergunta, cadeia de pensamento e a resposta.

O novo instrutor do STF não aceita tokenizadores, portanto, converteremos o tokenizador em um agrupador de dados e forneceremos ao instrutor o agrupador de dados em vez do tokenizador.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)Agora, criaremos um estilo de solicitação de teste que inclui tudo do estilo de solicitação de treinamento, exceto a cadeia de pensamento e a resposta.
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""Pegaremos a primeira pergunta do conjunto de dados, a converteremos em um prompt usando o estilo de prompt de teste e, em seguida, a prepararemos para que o modelo gere a resposta.
question = dataset[0]['Question']
inputs = tokenizer(
[prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])A cadeia de raciocínio do modelo é longa, e a resposta que ele fornece é bastante breve, diferindo significativamente do conjunto de dados.
<think>assistant
To approach this question, let's break down the key elements provided and analyze them step by step:
1. **Symptoms**: The patient experiences involuntary urine loss during activities like coughing or sneezing but has no leakage at night. This pattern of urinary incontinence is suggestive of stress urinary incontinence (SUI), which is characterized by the involuntary leakage of urine on effort or exertion, or on sneezing or coughing.
2. **Diagnostic Tests Mentioned**:
- **Gynecological Exam**: This is likely performed to assess the pelvic anatomy, including the position and support of the urethra and bladder neck, and to check for any pelvic organ prolapse.
- **Q-tip Test**: This test is used to assess urethral mobility. A Q-tip (cotton swab) is inserted into the urethra, and its angle of movement is measured. Increased mobility (an angle change of more than 30 degrees) is often associated with stress urinary incontinence.
3. **Cystometry (Cystometrogram)**: This test measures the pressure within the bladder during filling and helps assess bladder function, including the residual volume and detrusor muscle contractions. The detrusor muscle is the smooth muscle in the wall of the bladder that contracts to allow urine to be expelled.
Given that the patient likely has stress urinary incontinence (SUI) based on her symptoms:
- **Residual Volume**: In patients with SUI, the bladder usually functions normally, and thus, the residual volume (the amount of urine left in the bladder after urination) is typically not significantly affected. Therefore, one would expect the residual volume to be normal or near-normal.
- **Detrusor Contractions**: In SUI, the problem primarily lies with the urethral sphincter mechanism and support rather than with the detrusor muscle itself. Hence, detrusor contractions are usually normal. The patient does not have symptoms suggestive of an overactive bladder (like urgency, urge incontinence, or nocturia), which would be more indicative of detrusor overactivity.
Based on this analysis, cystometry in this patient would most likely reveal:
- A **normal residual volume**, as her symptoms do not suggest a problem with bladder emptying.
- **Normal detrusor contractions**, as her condition (stress urinary incontinence) primarily involves issues with urethral support and continence mechanisms rather than detrusor function.
Therefore, cystometry would likely show that she has a normal residual volume and normal detrusor contractions.
</think>
The final answer is: $\boxed{Normal residual volume and normal detrusor contractions}$Agora, implementaremos o LoRA (Low-Rank Adaptation) para um ajuste fino eficiente dos parâmetros e o aplicaremos ao modelo. LoRA é uma técnica projetada para fazer o ajuste fino de grandes modelos de linguagem congelando a maioria dos parâmetros do modelo e treinando apenas um pequeno subconjunto de parâmetros adicionais.
Essa abordagem é eficiente em termos de memória, mais rápida e econômica e, ao mesmo tempo, mantém uma alta precisão comparável ao ajuste fino completo.
from peft import LoraConfig, get_peft_model
# LoRA config
peft_config = LoraConfig(
lora_alpha=16, # Scaling factor for LoRA
lora_dropout=0.05, # Add slight dropout for regularization
r=64, # Rank of the LoRA update matrices
bias="none", # No bias reparameterization
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # Target modules for LoRA
)
model = get_peft_model(model, peft_config)Agora vamos configurar e inicializar o SFTTrainer (Supervised Fine-Tuning Trainer), fornecendo a ele o conjunto de dados, o modelo, o coletor de dados, os argumentos de treinamento e a configuração do LoRA. O SFTTrainer simplifica o processo de ajuste fino ao integrar todos esses componentes em um único fluxo de trabalho otimizado, facilitando o treinamento de grandes modelos de linguagem, como o Llama 4, com o LoRA.
from trl import SFTTrainer
from transformers import TrainingArguments
# Training Arguments
training_arguments = TrainingArguments(
output_dir="output",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
logging_steps=0.2,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="none"
)
# Initialize the Trainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset,
peft_config=peft_config,
data_collator=data_collator,
)Comece o processo de treinamento executando o seguinte comando:
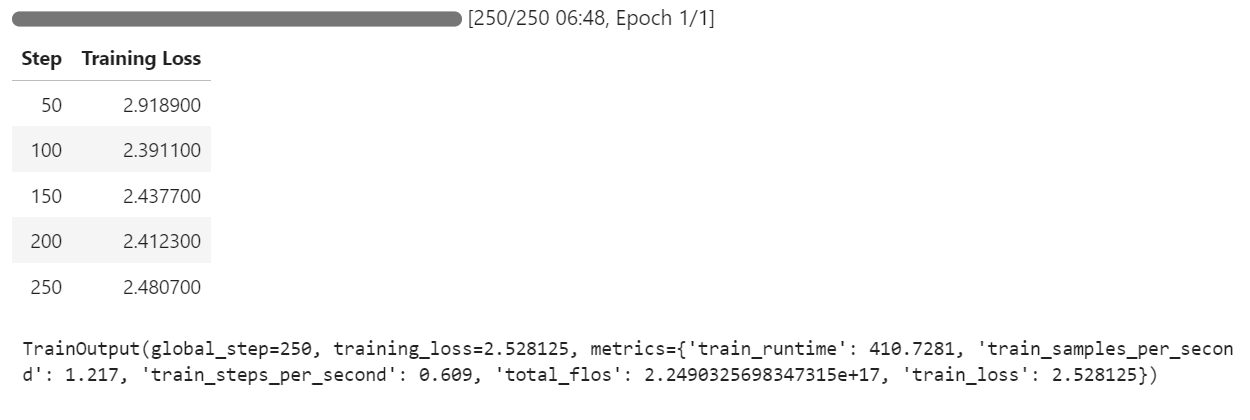
trainer.train()Se você mudar para o painel do Pod, verá que o instrutor está utilizando todas as três GPUs para treinamento.
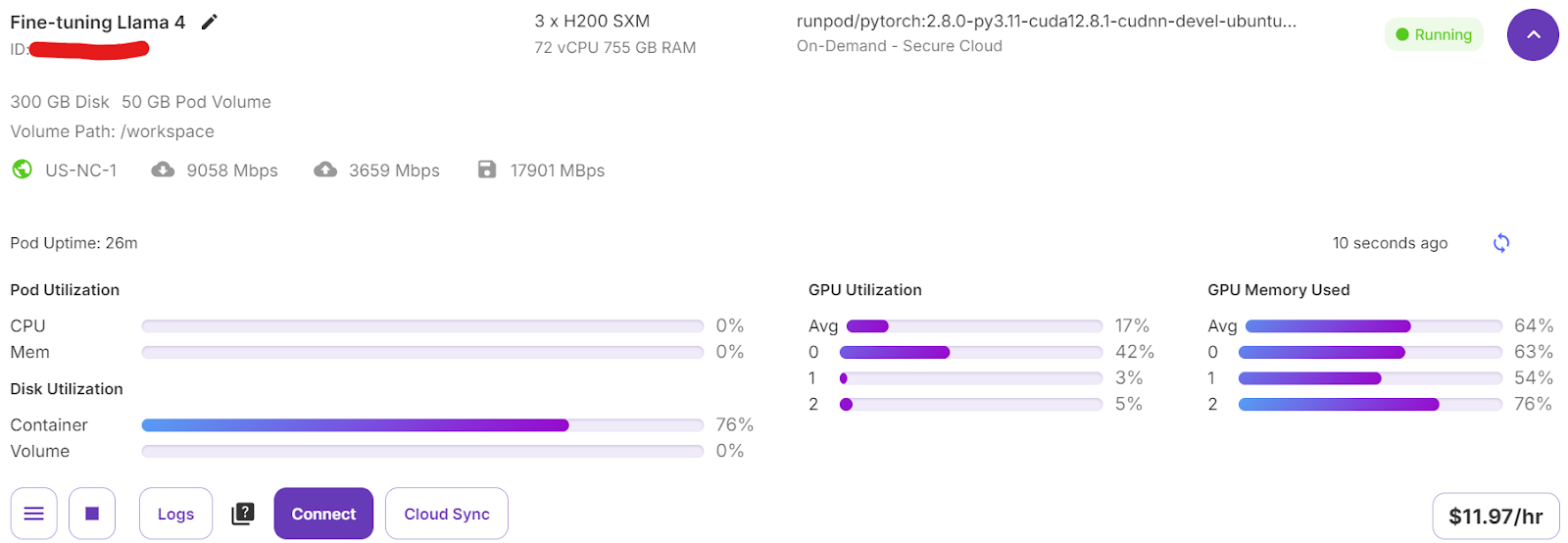
Levamos apenas 7 minutos para ajustar o modelo e, no total, 30 minutos para executar todo o projeto do início ao fim.
Agora, testaremos o modelo com ajuste fino usando a mesma amostra de antes para comparar seu desempenho após o ajuste fino. Isso nos ajudará a avaliar o quanto o modelo melhorou em termos de raciocínio e geração de respostas detalhadas.
question = dataset[0]['Question']
inputs = tokenizer(
[prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])O processo de raciocínio do modelo é preciso, e a resposta é detalhada e lógica:
<think>
Alright, let's think about what's going on with this 61-year-old woman. She's experiencing involuntary urine loss when she coughs or sneezes, which is classic for stress urinary incontinence. But there's no leakage at night, which is interesting. That detail might help us rule out other types of incontinence, like overactive bladder.
Now, let's think about the tests she's had. The gynecological exam and the Q-tip test are usually done to check for any anatomical issues that could be causing her symptoms. If the Q-tip test is positive, it means there's some mobility in the urethra, which can be a sign of stress incontinence.
Okay, so we've got stress urinary incontinence in mind. What does cystometry tell us? It's a test that looks at how well the bladder functions by measuring pressure and volume during filling and voiding.
For someone with stress incontinence, the cystometry would probably show that her bladder is doing its job properly. The residual volume, which is the amount of urine left in the bladder after she pees, should be normal. This means her bladder is emptying well enough.
Also, with stress incontinence, you wouldn't expect to see abnormal detrusor contractions. These are like muscle spasms in the bladder that can cause urgency and urge incontinence. But in stress incontinence, the problem is more about the urethral support and pressure control during activities, not the bladder muscle itself.
So, putting it all together, the cystometry should show a normal residual volume and no abnormal detrusor contractions. This fits perfectly with what we know about stress urinary incontinence. Yep, that's what I'd expect to see in this case.
</think>
In this scenario, the cystometry would most likely reveal a normal residual volume and no abnormal detrusor contractions. This is because stress urinary incontinence, as indicated by the patient's symptoms and the positive Q-tip test, is primarily related to issues with urethral support and pressure control during activities, not with the bladder muscle's function or emptying ability.Vamos testar o modelo em uma amostra diferente do conjunto de dados para avaliar melhor seu desempenho.
question = dataset[10]['Question']
inputs = tokenizer(
[prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])A resposta é lógica, detalhada e demonstra a capacidade do modelo de aplicar o raciocínio médico de forma eficaz:
<think>
Alright, let's break this down. So, we have a 42-year-old guy who's just recovered from pneumonia, and his T3 levels are low. Now, his TSH is slightly elevated at 4.7 µU/mL, which isn't too high but is definitely not normal. T4 is at 6 µg/dL, which is kind of in the middle range, and T3 is 68 ng/dL, which is low. Hmm, these numbers make me think of a condition called sick euthyroid syndrome. It's like when the body gets sick, the thyroid function tests can get all wonky, even if the thyroid itself is working fine.
In this syndrome, T3 usually drops first, and T4 might stay normal or even rise a bit. This makes sense here because his T3 is low, but T4 is still around 6 µg/dL. Now, the TSH is slightly elevated, which is a bit puzzling, but in sick euthyroid syndrome, TSH can be normal or even slightly elevated. So, this fits.
But wait, what about the other hormones? In sick euthyroid syndrome, we often see an increase in reverse T3 (rT3). This is because the body might convert T4 to rT3 instead of T3 when it's stressed. So, if I were to guess, I'd say the reverse T3 level is probably elevated in this case.
This all makes sense because the clinical picture and lab results are lining up nicely with sick euthyroid syndrome. So, if I had to pick an additional hormone that's likely elevated, it would be the reverse T3. Yeah, that seems to fit the scenario perfectly.
</think>
In this scenario, considering the clinical context of a 42-year-old man recovering from pneumonia with decreased T3 levels and slightly elevated TSH, along with normal T4 levels, the likely condition is sick euthyroid syndrome. In this condition, the body often converts T4 to reverse T3 (rT3) instead of T3 during stress or illness. Therefore, the additional hormone level that is likely to be elevated in this patient is reverse T3 (rT3).Agora, enviaremos o modelo ajustado (adaptador LoRA) e o tokenizador para o Hugging Face Hub. Esse processo criará automaticamente um repositório para você e carregará todos os arquivos de modelo necessários, tornando o modelo acessível publicamente para uso ou compartilhamento posterior.
model.push_to_hub("Llama-4-Scout-17B-16E-Instruct-Medical-ChatBot")
tokenizer.push_to_hub("Llama-4-Scout-17B-16E-Instruct-Medical-ChatBot")
Quando o processo estiver concluído, você poderá acessar o repositório de modelos no seguinte link: kingabzpro/Llama-4-Scout-17B-16E-Instruct-Medical-ChatBot
Aqui está o notebook complementar que contém todo o código necessário, saídas e instruções detalhadas para ajudar você a ajustar o seu próprio modelo Llama 4.
A criação deste tutorial foi uma experiência desafiadora, porém gratificante. Ao trabalhar com o Llama 4, encontrei vários problemas que destacaram as complexidades do uso desse modelo. Na minha opinião, o Llama 4 ainda não está totalmente otimizado para uso generalizado, especialmente para pessoas que dependem de GPUs de nível de consumidor. Aqui estão alguns dos principais desafios que enfrentei:
Apesar desses desafios, se você seguir este guia passo a passo, poderá fazer o ajuste fino do Llama 4 em qualquer novo conjunto de dados com relativa facilidade.
Para saber mais sobre a Llama 4, confira estes recursos:
Aprenda IA com estes cursos!
Programa
Programa
Curso
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Dimitri Didmanidze
Tutorial
Moez Ali


