
Cursus
Principes fondamentaux de l'IA
10 h
Le mécanisme d'attention est au cœur des modèles de transformateurs modèles de transformateurs. Toutes les architectures de modèles populaires, telles que GPTet LLaMAet Mixture of Experts (MoE), s'appuient sur ce principe pour relier les tokens et construire du sens.
Cependant, l'attention a un coût élevé. Son calcul implique des multiplications de matrices volumineuses et, surtout, des transferts de données importants entre la mémoire du GPU et les unités de calcul. À mesure que la longueur des séquences augmente, la bande passante mémoire devient le véritable goulot d'étranglement.
L'optimisation de l'attention a donc un impact considérable sur les performances du LLM. performances des LLM, et c'est précisément là qu'intervient Flash Attention. Dans cet article, je vais vous expliquer ce qu'est Flash Attention, comment cela fonctionne et comment l'utiliser avec PyTorch et Hugging Face Transformers.
Si vous souhaitez vous initier aux LLM, je vous recommande de suivre notre cours d'introduction aux concepts des LLM.
Flash Attention est un mécanisme d'attention optimisé par transformateur. ,, ce qui le rend considérablement plus rapide et plus économe en mémoire sur les GPU.
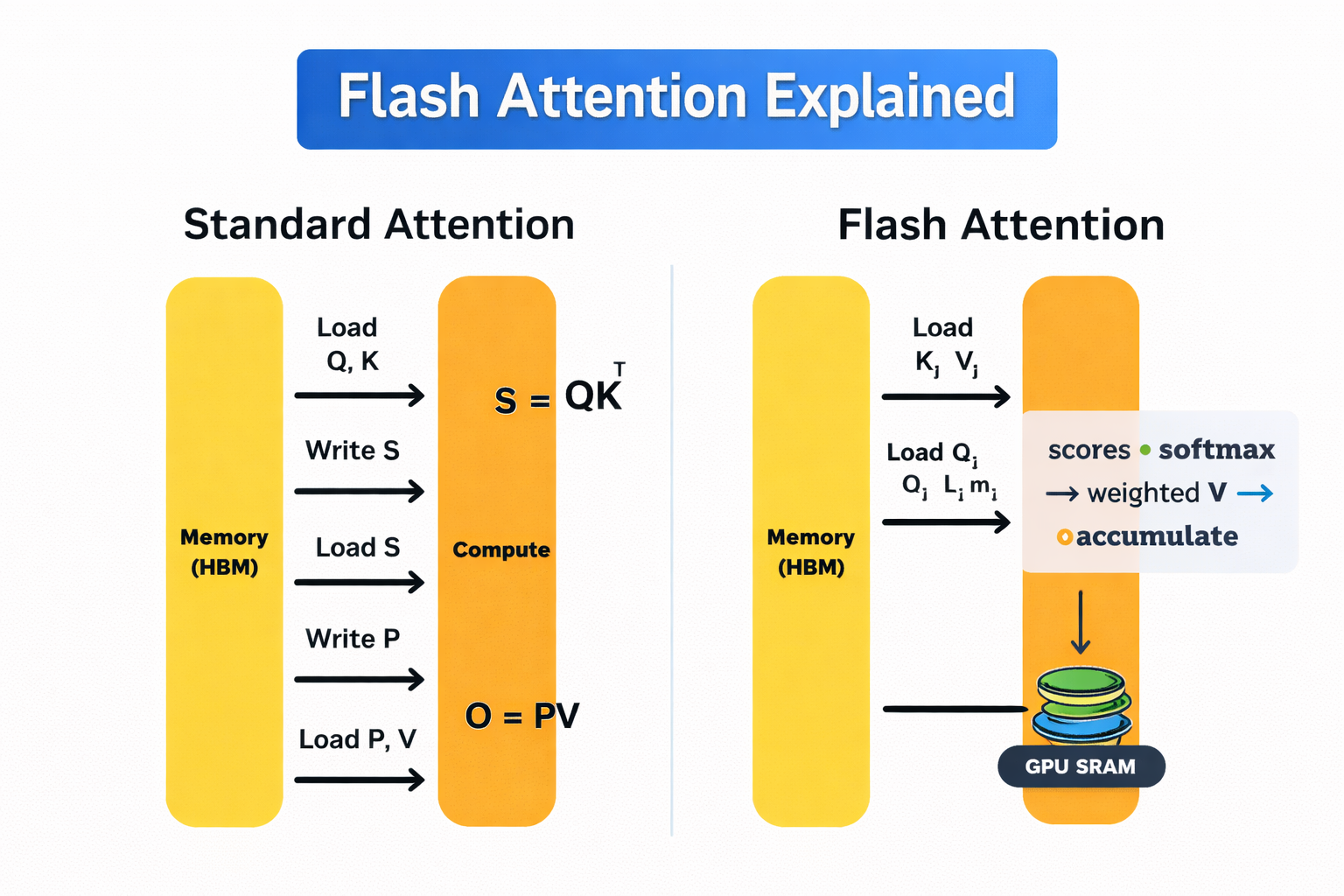
Attention standard vs attention flash
Les GPU disposent de deux principaux types de mémoire. La mémoire à bande passante élevée (HBM) est volumineuse mais relativement lente. La mémoire SRAM intégrée est extrêmement rapide, mais sa taille est très limitée.
L'auto-attention standard transfère constamment des données entre ces deux éléments. Ces allers-retours sont coûteux et représentent un coût important à mesure que la longueur de la séquence augmente.
Flash Attention évite ce problème en calculant l'attention dans de petites tuiles qui tiennent entièrement dans la mémoire SRAM rapide. Chaquetuile d' s est traitée de bout en bout par, avec application incrémentielle de softmax, de sorte que les résultats intermédiaires n'ont pas besoin d'être réécrits dans la mémoire HBM. Par conséquent, la matrice d'attention complète n'est jamais stockée en mémoire.
Contrairement aux méthodes d'attention linéaire ou clairsemée, l'attention flash n'est pas une approximation. Il produit exactement le même résultat mathématique que l'auto-attention standard, mais de manière plus efficace en termes de mémoire.
Flash Attention atteint son efficacité en repensant la manière dont il calcule l'attention sur le GPU. Le principe est simple : effectuer autant de tâches que possible dans la mémoire rapide intégrée à la puce et éviter tout déplacement inutile vers la mémoire lente.
Une analogie avec la cuisine peut être utile pour comprendre ce concept. La mémoire SRAM intégrée au GPU est comparable à un petit plan de travail rapide dans une cuisine. C'est là que vous préparez et cuisinez réellement. La mémoire à bande passante élevée (HBM) du GPU est comparable à un grand magasin d'alimentation situé dans la rue. Il peut contenir tout ce dont vous avez besoin, mais les allers-retours prennent du temps.
En termes simples, l'attention standard consiste à se rendre régulièrement à l'épicerie après chaque étape. En revanche, Flash Attention planifie la préparation des repas de manière à ce que tous les ingrédients puissent être placés sur le plan de travail pendant que vous cuisinez. Examinons cela plus en détail :
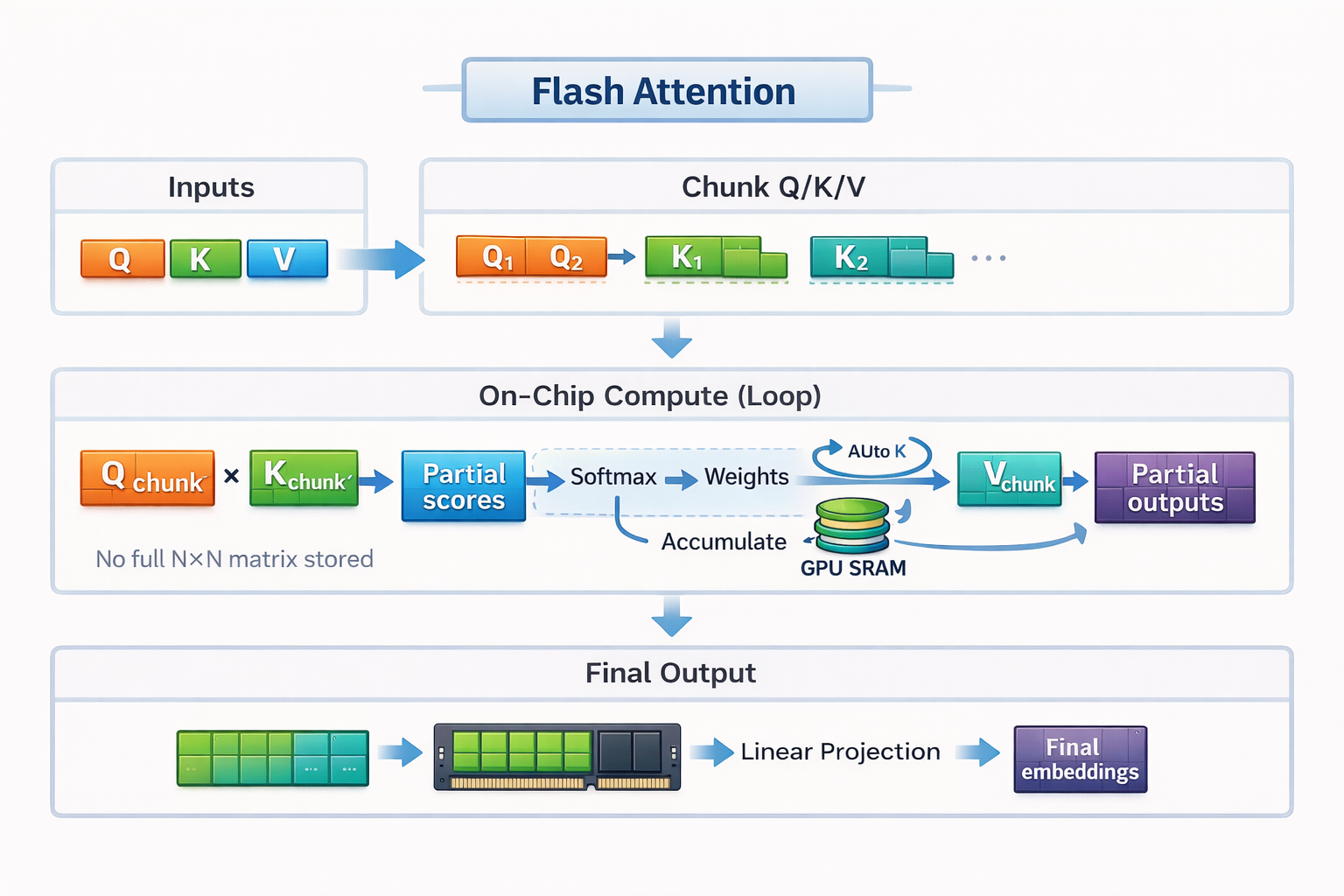
Mécanisme de fonctionnement de Flash Attention
Flash Attention repose sur deux concepts clés : le mosaïquage et recalcul.
Pour rester dans notre exemple culinaire, le pavage est la manière dont Flash Attention adapte le calcul de l'attention au petit comptoir.
Au lieu de charger la séquence entière et de construire une matrice d'attention complète, Flash Attention divise les entrées en petits blocs, ou tuiles. Chaque tuile s'intègre entièrement dans la mémoire SRAM rapide du GPU. Flash Attention calcule l'attention une tuile à la fois, du début à la fin, avant de passer à la tuile suivante.
En utilisant l'analogie de la cuisine, il n'est pas possible de disposer tous les ingrédients nécessaires à la préparation d'un banquet complet sur un petit comptoir. Il est donc conseillé de préparer et de cuisiner en petites quantités. Vous coupez quelques légumes, vous les faites cuire, vous libérez l'espace, puis vous passez à la prochaine fournée. En procédant ainsi, vous évitez de devoir vous rendre fréquemment à l'épicerie.
Cette exécution bloc par bloc permet à Flash Attention de conserver les données localement, rapidement et efficacement, sans jamais matérialiser la matrice d'attention complète dans une mémoire lente.
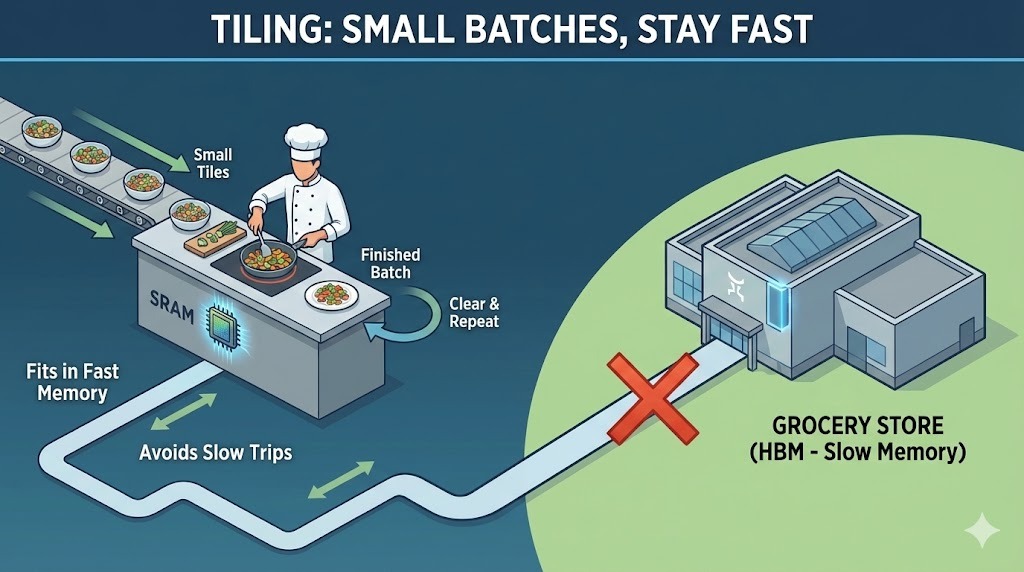
Carrelage dans Flash Attention
Pendant l'entraînement, l'attention standard stocke les résultats intermédiaires importants afin qu'ils puissent être réutilisés lors du passage en arrière. Ce stockage implique un coût élevé en termes de mémoire. Flash Attention adopte une approche différente. Au lieu de stocker ces intermédiaires, il recalcule de petites parties des scores d'attention chaque fois que cela est nécessaire.
Dans la cuisine, cela s'apparente à émincer des oignons. Vous pourriez vous rendre à pied à l'épicerie pour conserver vos oignons hachés, puis revenir plus tard pour les récupérer. Ou vous pourriez les jeter et simplement hacher un oignon frais au moment de cuisiner. Étonnamment, la deuxième option est plus rapide car elle évite les mouvements fréquents/plus longs.
Sur les GPU modernes, le recalcul suit la même logique, car les calculs supplémentaires sont peu coûteux par rapport aux mouvements de mémoire. En recalculant les petites valeurs au lieu de les stocker et de les charger, Flash Attention réduit considérablement le trafic mémoire tout en conservant l'efficacité de l'entraînement.
Ensemble, le tiling et le recomputation permettent à Flash Attention de maintenir le calcul de l'attention sur le compteur, de minimiser les déplacements à l'épicerie et d'exploiter pleinement les atouts du matériel GPU moderne.
Flash Attention 2 (FA2), lancé en 2023, constitue une mise à niveau majeure par rapport à la première génération. Il conserve la même idée fondamentale d'attention précise et sensible à l'E/S, mais améliore l'efficacité dans plusieurs dimensions importantes pour les charges de travail réelles.
La première version de Flash Attention a parallélisé le calcul entre la taille du lot et les têtes d'attention. Cela s'est avéré efficace pour les configurations de formation avec de grands lots. Cependant, cela s'avérait moins idéal pour l'inférence, où les tailles des lots sont souvent réduites et les longueurs de séquence importantes.
FA2 ajoute un parallélisme à travers la dimension de la longueur de la séquence elle-même. Cela permet à davantage de parties du calcul de l'attention de s'exécuter simultanément, même lorsque la taille du lot est réduite. En répartissant le travail entre les jetons de la séquence, la version 2 permet d'occuper simultanément un plus grand nombre d'unités de calcul du GPU.
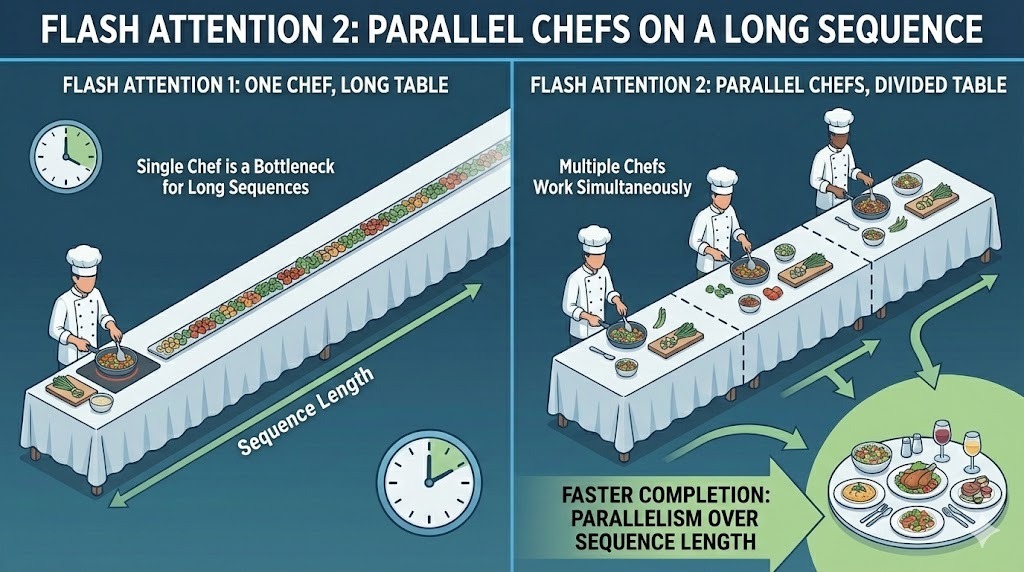
Parallélisme entre les lots dans Flash Attention 2
L'avantage pratique réside dans un débit plus élevé et une meilleure utilisation du matériel dans les scénarios d'inférence courants, où les invites longues et les petits lots sont la norme.
Les GPU sont particulièrement performants pour la multiplication matricielle. Un matériel spécialisé appelé « Tensor Cores » est capable d'exécuter des opérations de multiplication matricielle générale (GEMM) à très grande vitesse.
Le problème réside dans le fait que l'attention ne se limite pas à la multiplication matricielle : elle implique des opérations telles que la mise à l'échelle, le masquage et le softmax, qui s'exécutent sur des cœurs GPU standard et sont beaucoup plus lentes en comparaison.
La FA2 a permis de réduire ce déséquilibre. Il restructure le calcul afin de minimiser les opérations en virgule flottante non matricielles, en particulier celles impliquées dans le recalibrage des scores d'attention. La majeure partie du temps d'exécution est consacrée à des opérations matricielles importantes et efficaces que les Tensor Cores peuvent accélérer.
Flash Attention v1 a été optimisé pour des dimensions de tête de 64 ou 128, ce qui correspondait à des modèles tels que BERT et GPT-3. À mesure que les architectures des modèles ont évolué, les dimensions des têtes ont augmenté afin de prendre en charge des tailles d'intégration plus importantes et une capacité de modèle plus élevée.
FA2 a étendu la prise en charge aux dimensions de tête jusqu'à 256. Cela l'a rendu compatible avec les architectures plus récentes qui s'appuient sur des têtes d'attention plus larges.
Flash Attention 3 (FA3) est la norme industrielle actuelle qui alimente des modèles de pointe tels que GPT-5.2. Il s'appuie sur les mêmes fondements que les versions précédentes, à savoir la prise en compte des E/S et l'attention précise, mais il est spécialement conçu pour les GPU NVIDIA H100 (Hopper).
Le changement majeur réside dans le fait que FA3 est conçu pour exploiter les nouvelles fonctionnalités matérielles asynchrones de Hopper, permettant ainsi un chevauchement beaucoup plus important qu'auparavant entre les mouvements de mémoire et les calculs.
Dans les versions précédentes, tous les threads GPU, appelés warps, suivaient le même chemin d'exécution. FA3 modifie ce modèle grâce à la spécialisation dans la distorsion. Il attribue l'un des deux rôles distincts à chaque chaîne :
Cette séparation permet le transfert de données et le calcul simultanément. Pendant que les warps producteurs récupèrent les tuiles de données suivantes, les warps consommateurs continuent à traiter les tuiles actuelles, ce qui améliore considérablement la latence.
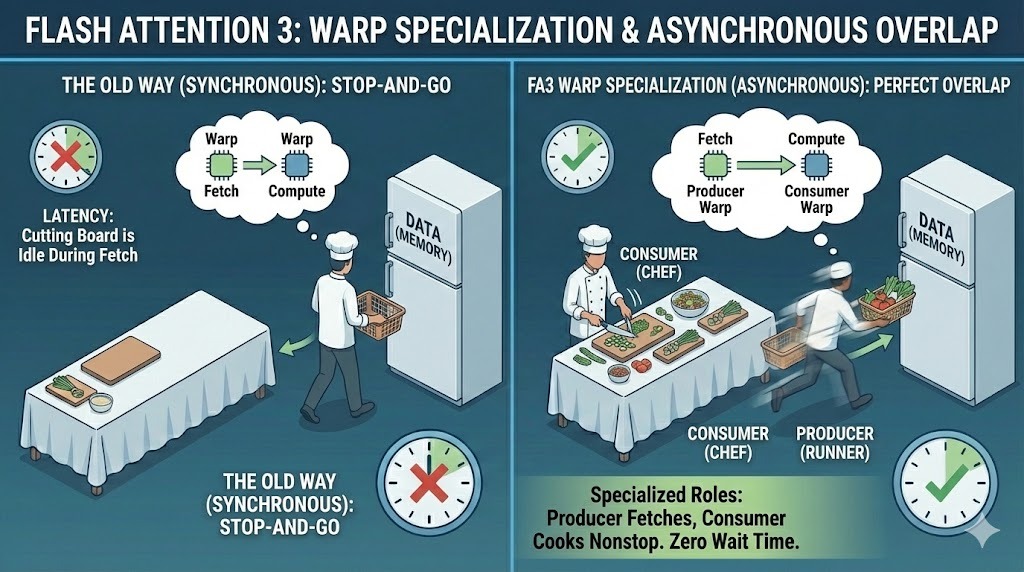
Spécialisation Warp dans Flash Attention 3
Flash Attention 3 introduit également la prise en charge native de FP8, ou précision à virgule flottante 8 bits. Les versions précédentes reposaient principalement sur FP16 ou BF16, qui réduisaient déjà l'utilisation de la mémoire par rapport à FP32, mais consommaient encore une bande passante importante.
FP8 réduit l'empreinte mémoire de moitié environ. Cette réduction se traduit directement par un débit plus élevé et une pression mémoire réduite. Sur les GPU Hopper, FP8 bénéficie d'une accélération matérielle, ce qui signifie que FA3 peut traiter davantage d'opérations d'attention par seconde sans compromettre la précision au niveau du modèle.
Cette capacité est l'une des principales raisons pour lesquelles les grands modèles tels que Gemini 3 peuvent traiter des fenêtres contextuelles volumineuses fenêtres contextuelles tout en desservant efficacement des millions d'utilisateurs.
La dernière caractéristique de la conception du FA3 est l'utilisation du Tensor Memory Accelerator (TMA) du H100. Le TMA est un matériel spécialisé qui gère les copies de mémoire de manière asynchrone, sans occuper les principaux cœurs de calcul.
Flash Attention 3 utilise la technologie TMA pour déplacer des blocs de données en arrière-plan tout en permettant la poursuite des calculs sans interruption. En synchronisant étroitement les mouvements de la mémoire avec les calculs mathématiques, FA3 est en mesure d'atteindre près de 75 % des performances maximales théoriques du matériel.
Flash Attention 4 (FA4) représente la prochaine étape expérimentale dans l'optimisation de l'attention. Il est conçu pour les futurs GPU Blackwell B200 de NVIDIA et explore les possibilités offertes par la création de noyaux d'attention pour une toute nouvelle catégorie de matériel.
À mesure que la taille des modèles continue d'augmenter et que les entraînements tendent vers l'échelle des trillions de paramètres, même Flash Attention 3 finira par atteindre ses limites. FA4 est une première tentative visant à supprimer ces limites en poussant l'utilisation du matériel plus loin que n'importe quel noyau attentionnel précédent.
À ce stade, Flash Attention 4 est une technologie en phase de recherche et de préproduction. Il s'agit d'une technologie très prometteuse, mais elle n'est pas encore utilisée dans les modèles déployés ou de série.
L'une des principales avancées de Flash Attention 4 réside dans ses performances. Il s'agit du premier noyau d'attention conçu pour dépasser 1 PFLOPS, soit un quadrillion d'opérations en virgule flottante par seconde, sur un seul GPU.
Il vise un avenir où la formation de modèles à des milliers de milliards de paramètres prendrait un temps considérable. À cette échelle, même les plus petites inefficacités peuvent entraîner des retards considérables. Le FA4 vise à rendre ces futurs entraînements possibles en tirant des performances exceptionnelles d'une seule puce.
Pour atteindre ce niveau de performance, FA4 pousse l'asynchronisme bien plus loin que les versions précédentes. Il étend le modèle producteur-consommateur à des pipelines hautement complexes à plusieurs étapes où le transfert de données, le calcul et la synchronisation fonctionnent tous de manière indépendante.
Au lieu d'un simple chevauchement entre le chargement et le calcul, FA4 gère une exécution profondément asynchrone à travers plusieurs étapes. Les différentes parties du noyau progressent à des vitesses différentes, coordonnées par une planification au niveau matériel plutôt que par un flux synchronisé unique.
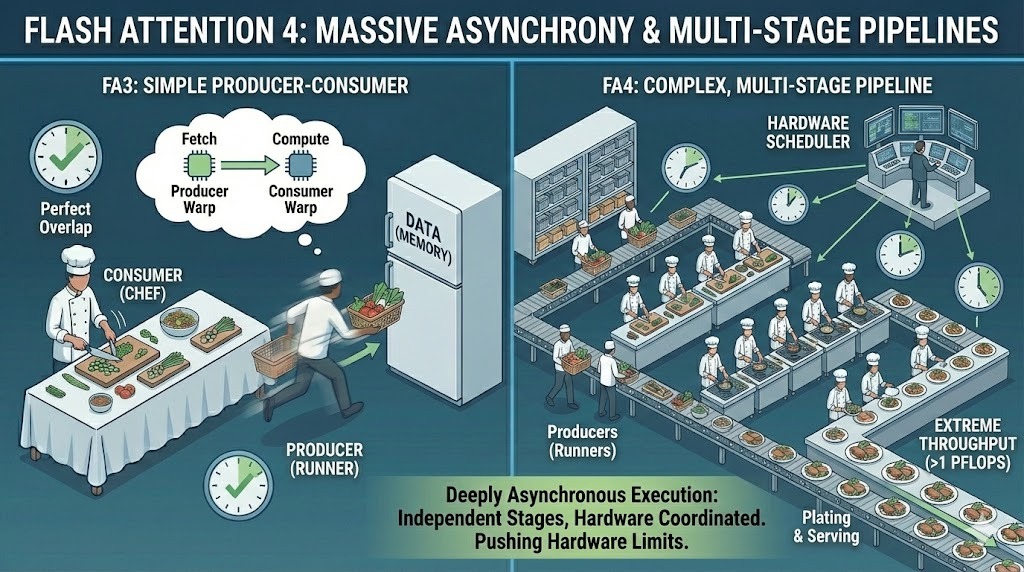
Asynchronie importante dans Flash Attention 4
Cette complexité explique également pourquoi la FA4 reste à un stade expérimental. Gérer la précision, la stabilité et l'intégration à ce niveau représente un défi. La communauté doit encore fournir des efforts avant que les équipes puissent l'utiliser de manière fiable dans le cadre de modèles de production à grande échelle.
Comparons Flash Attention au mécanisme d'attention standard dans quelques domaines clés.
Les tests de performance démontrent systématiquement que toutes les versions de Flash Attention surpassent l'auto-attention standard, avec des gains qui augmentent à mesure que la longueur de la séquence s'allonge.
Le document original Flash Attention article original sur Flash Attention fait état d'une accélération d'environ 2 à 4 fois supérieure à celle de l'attention standard optimisée. Flash Attention 2 améliore encore davantage ce résultat en augmentant le parallélisme et en saturant davantage le GPU, ce qui permet souvent d'obtenir un gain supplémentaire d'environ 2× dans la pratique.
Flash Attention 3 améliore encore davantage les performances sur les GPU Hopper, en particulier avec FP8, en atteignant un taux d'utilisation du matériel bien supérieur à celui obtenu avec l'attention standard.
L'attention standard matérialise explicitement la matrice d'attention complète N × N, ce qui entraîne une croissance quadratique de la mémoire par rapport à la longueur de la séquence. À mesure que N augmente, l'utilisation de la mémoire augmente considérablement, saturant rapidement la mémoire du GPU. Flash Attention évite de stocker cette matrice dans son intégralité.
En calculant l'attention dans des tuiles et en conservant les résultats intermédiaires dans une mémoire intégrée rapide, il réduit l'utilisation de la mémoire à une valeur linéaire en fonction de la longueur de la séquence pour des dimensions de tête fixes. Ce passage d'une mise à l'échelle quadratique à une mise à l'échelle linéaire de la mémoire élimine le principal goulot d'étranglement structurel de l'attention standard.
Cette réduction de la mémoire permet directement d'utiliser des fenêtres contextuelles plus longues. Avec une attention standard, les modèles rencontrent souvent des erreurs de mémoire insuffisante lorsque les séquences atteignent quelques milliers de tokens.
Flash Attention rend les contextes de jetons 4k et 8k pratiques sur un seul GPU, et permet même d'accéder à des fenêtres beaucoup plus longues, telles que 16k ou 32k jetons, sur ce même appareil lorsqu'il est associé à d'autres techniques d'économie de mémoire.
Veuillez ne pas vous méprendre : Les fenêtres massives d'un million de jetons obtenues dans certains modèles de pointe actuels tels que Gemini 3, sont obtenues en répartissant la séquence sur de grands clusters de GPU, car elles dépassent largement la capacité de mémoire d'un seul appareil.
L'utilisation de Flash Attention est aujourd'hui beaucoup plus simple qu'auparavant. Dans la plupart des cas, il n'est pas nécessaire de créer des noyaux CUDA personnalisés ou de modifier l'architecture de votre modèle. Cette fonctionnalité est déjà intégrée dans les outils courants actuels.
Depuis PyTorch 2.0, Flash Attention est directement accessible via torch.nn.functional.scaled_dot_product_attention. Lorsque vous appelez cette fonction, PyTorch sélectionne automatiquement le backend d'attention le plus rapide disponible pour votre matériel.
Sur les GPU pris en charge, ce backend est Flash Attention. Du point de vue de l'utilisateur, cela ressemble souvent à un code d'attention standard, mais en arrière-plan, PyTorch distribue un noyau Flash Attention optimisé.
Si vous utilisez Hugging Face Transformers, l'activation de Flash Attention nécessite généralement une modification d'une seule ligne. En définissant attn_implementation="flash_attention_2" dans la configuration du modèle, vous indiquez à la bibliothèque d'utiliser Flash Attention 2 dans la mesure du possible.
Pour de nombreux modèles de transformateurs, cela suffit pour obtenir des améliorations en termes de vitesse et de mémoire sans modifier le reste du code d'entraînement ou d'inférence.
Flash Attention 2 est conçu pour les GPU NVIDIA modernes et fonctionne de manière optimale sur les architectures Ampere, Ada et Hopper, notamment les modèles A100, RTX 3090, RTX 4090 et H100. Ces processeurs graphiques offrent la bande passante mémoire et les caractéristiques architecturales nécessaires pour tirer pleinement parti du tiling et du parallélisme dans FA2.
Il convient également de noter que la version originale Flash Attention v1 est également compatible avec les anciens processeurs graphiques. Les cartes basées sur Turing, telles que la T4 et la RTX 2080, peuvent toujours utiliser Flash Attention v1, bien que les versions plus récentes nécessitent un matériel plus récent pour exploiter pleinement leurs gains de performances.
En pratique, si vous utilisez déjà PyTorch 2.x ou Hugging Face Transformers sur un GPU NVIDIA moderne, Flash Attention est souvent accessible par simple changement de configuration.
L'attention standard s'est heurtée à un obstacle majeur, car la croissance quadratique de la mémoire rendait les longues séquences lentes, coûteuses, voire tout simplement impossibles en raison de pannes dues à un manque de mémoire. Flash Attention a modifié cela en repensant la manière dont l'attention est mise en œuvre.
En réduisant l'utilisation de la mémoire de quadratique à linéaire par rapport à la longueur de la séquence, Flash Attention rend la modélisation à long contexte pratique. Les fenêtres contextuelles qui, auparavant, surchargeaient les processeurs graphiques avec quelques milliers de jetons, peuvent désormais atteindre 4 000, 8 000, voire plus de 32 000 jetons sur le même matériel.
Si vous travaillez avec des transformateurs à grande échelle et que vous n'utilisez pas Flash Attention, vous passez certainement à côté d'un gain de performance considérable.
Souhaitez-vous créer vos propres modèles compatibles avec Flash Attention ? Nous vous invitons à suivre notre cours sur les modèles de transformateurs avec PyTorch. les modèles de transformateurs avec PyTorch!
Cours sur l'intelligence artificielle
Cursus
Cours
Cours