
Cursus
Développer des LLM
16 h
Imaginez que vous racontiez une longue histoire à un ami, pour finalement vous rendre compte qu'il a oublié le début au moment où vous arrivez à la chute. Cette frustration est précisément ce qui se produit lorsqu'une IA manque de « mémoire à court terme », ce qui l'oblige à abandonner des détails essentiels pour faire de la place à de nouveaux.
Dans le domaine des grands modèles linguistiques (LLM), cette capacité d'attention est déterminée par la fenêtre contextuelle.
À mesure que les modèles deviennent plus puissants et que la taille des contextes augmente, il devient essentiel de comprendre le fonctionnement de ces fenêtres pour pouvoir développer des systèmes d'IA fiables et évolutifs. Dans ce guide, nous aborderons les principes fondamentaux des fenêtres contextuelles, les avantages et inconvénients de leur expansion, ainsi que les stratégies pour les utiliser efficacement.
Pour aller au-delà de la théorie et apprendre à gérer les limites contextuelles dans des applications Python réelles, nous vous invitons à consulter notre cours Développer des applications LLM avec LangChain.
La fenêtre contextuelle d'un modèle d'IA détermine la quantité de texte qu'il peut contenir dans sa mémoire de travail tout en générant une réponse. Cela limite la durée d'une conversation sans oublier les détails des interactions précédentes.
Vous pouvez le considérer comme la mémoire à court terme d'un individu. Il stocke temporairement les informations issues des conversations précédentes afin de les utiliser pour la tâche en cours.

Les fenêtres contextuelles ont une incidence sur divers aspects, notamment la qualité du raisonnement, la profondeur de la conversation et la capacité du modèle à personnaliser efficacement les réponses. Il détermine également la taille maximale des données qu'il peut traiter simultanément. Lorsqu'une invite ou un contexte de conversation dépasse cette limite, le modèle tronque (coupe) les premières parties du texte afin de libérer de l'espace.
Pour mieux comprendre ce que cela signifie exactement, examinons quelques concepts fondamentaux qui sous-tendent les modèles d'IA et les fenêtres contextuelles.
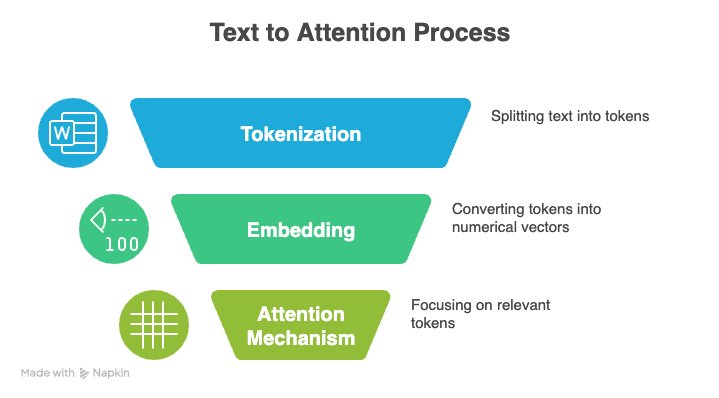
Trois concepts fondamentaux sous-tendent les LLM : la tokenisation, le mécanisme d'attention et le codage positionnel.
La tokenisation est le processus qui consiste à convertir du texte brut en une séquence d'unités plus petites, ou tokens, qu'un LLM peut traiter. Ces jetons peuvent représenter des mots entiers, des caractères individuels ou même des syllabes partielles. Collectivement, l'ensemble des jetons uniques qu'un modèle reconnaît est appelé son vocabulaire.
Par exemple, la phrase « Bonjour, monde » pourrait être tokenisée en [“Hello”, “,”, “ world”].
Au cours de l'entraînement ou de l'inférence, chaque jeton est converti en un nombre entier unique, et le modèle lit ces nombres à la place du texte original. Il analyse la séquence numérique, apprend comment les tokens sont liés les uns aux autres et génère un nouveau texte en prédisant le prochain token probable.
Une tokenisation efficace joue un rôle important dans la quantité d'informations qui s'intègrent dans la fenêtre contextuelle d'un modèle. Lorsqu'un tokeniseur peut représenter du texte avec moins de tokens, davantage de contenu peut être affiché dans la même fenêtre.
Les tokeniseurs qui représentent des mots ou des expressions courants sous forme de tokens uniques sont particulièrement efficaces, car ils réduisent le nombre de tokens, ce qui permet au modèle de traiter des documents plus longs dans les limites de son contexte.
Le mécanisme dit « d'attention » constitue un autre fondement des LLM modernes. Cela permet à un modèle de se concentrer sur les parties les plus pertinentes de ses données d'entrée lorsqu'il génère une sortie.
Au lieu de traiter chaque jeton de manière égale, le modèle compare la représentation actuelle à toutes les autres représentations de jetons et attribue une note à chaque comparaison. Cette pondération sélective permet au modèle de traiter de longues séquences et de mieux comprendre le contexte.
L'attention s'articule autour de trois éléments : Requêtes, clés et valeurs.
Questions : Le signal envoyé par le jeton actuel pour rechercher des informations pertinentes dans le reste de la séquence.
Clés : Identifiant de chaque jeton dans la séquence qui détermine son degré de correspondance avec le signal de recherche.
Valeurs : Le contenu informatif réel qui est récupéré et utilisé lorsqu'une correspondance entre une requête et une clé est trouvée.
Le modèle calcule les scores de similarité entre les requêtes et les clés, convertit ces scores en pondérations à l'aide de la fonction d'activation softmax, puis produit le résultat final sous forme de somme pondérée des valeurs.
L'auto-attention compare le token actuel à tous les autres tokens de la séquence. Cela entraîne un coût de calcul quadratique : doubler la fenêtre contextuelle quadruple la puissance de traitement et la mémoire requises.
À mesure que les fenêtres contextuelles s'agrandissent, cela devient rapidement coûteux, de sorte que les modèles s'appuient sur des optimisations telles que l'attention clairsemée, l'approximation de rang faible ou le découpage en morceaux pour que les calculs restent gérables.
Les transformateurs, qui alimentent les modèles linguistiques modernes, ne comprennent pas naturellement l'ordre des tokens. Au lieu de cela, ils s'appuient sur le codage positionnel pour intégrer ces informations.
Le codage positionnel ajoute un petit signal à chaque token qui aide le modèle à comprendre la distance et la disposition relative.
La méthode spécifique d'information de position définit également dans quelle mesure le modèle peut suivre de manière fiable les relations au sein d'une séquence, ce qui détermine la taille et l'efficacité de sa fenêtre contextuelle. Comparons quelques méthodes courantes :
Embeddings positionnels absolus : Le modèle apprend un vecteur distinct pour chaque position dans la séquence, comme s'il attribuait à chaque token une adresse fixe. Cela fonctionne pour les séquences plus courtes, mais le modèle ne peut pas traiter les positions au-delà de celles pour lesquelles il a été formé, ce qui rend la fenêtre contextuelle difficile à étendre.
Codages sinusoïdaux : Les positions sont codées à l'aide d'ondes sinusoïdales et cosinusoïdales répétitives, qui attribuent à chaque jeton un motif unique en fonction de son emplacement. Ils se généralisent mieux à des longueurs inconnues que les intégrations absolues, bien qu'ils deviennent moins stables avec des séquences extrêmement longues.
Codages de position relative : Au lieu de marquer des positions exactes, le modèle apprend la distance entre les jetons. Cela permet de généraliser à des séquences plus longues, mais la limite globale du contexte dépend toujours de l'architecture et de la mémoire du modèle.
Embeddings positionnels rotatifs (RoPE) : RoPE encode la position en faisant pivoter la représentation vectorielle de chaque token en fonction de sa position absolue, en calculant la distance par rapport aux autres tokens. Cette méthode reste stable à mesure que les séquences s'allongent et prend en charge des fenêtres contextuelles beaucoup plus grandes.
ALiBi (Attention aux biais linéaires) : ALiBi applique un biais simple basé sur la distance au sein du mécanisme d'attention, de sorte que les tokens les plus proches reçoivent naturellement un poids plus élevé. Il s'adapte parfaitement aux séquences longues.
Je vous recommande de consulter ce tutoriel sur le fonctionnement des transformateurs pour obtenir un aperçu détaillé.
Si le contexte dépasse la fenêtre de contexte, le modèle peut tronquer ou ignorer les premières parties, ce qui peut entraîner la perte d'informations contextuelles importantes. C'est pourquoi les chercheurs expérimentent continuellement de nouvelles techniques afin de repousser ces limites et de permettre des fenêtres contextuelles plus longues.
Jusqu'en 2022, les modèles GPT d'OpenAI ont dominé le paysage. Le premier modèle GPT, publié en 2018, prenait en charge une fenêtre de 512 tokens. Les deux versions suivantes, en 2019 et 2020, ont chacune doublé cette limite, atteignant 2 048 jetons pour GPT-3. Les modèles successifs ont continué à repousser ces limites jusqu'à un million de tokens (GPT-4.1).
Récemment, OpenAI a été rattrapé, voire dépassé, par la concurrence. Les versions Gemini 2.5 et 3 Pro de Google correspondent à cette taille de fenêtre pouvant atteindre un million de tokens, ce qui permet de traiter des livres entiers, des bases de code volumineuses et des charges de travail multi-documents en un seul passage.
La série Claude Sonnet 4.5 d'Anthropic teste actuellement la même taille de fenêtre contextuelle en version bêta, passant de sa taille initiale de 200 000 jetons.
Les familles de modèles open source telles que Llama et Mistral se situent généralement dans une fourchette comprise entre 100 000 et 200 000, offrant des performances respectables dans un contexte étendu tout en restant pratiques à déployer localement ou à affiner.
Parmi les exceptions notables, citons Llama Maverick, qui prend en charge une fenêtre d'un million de jetons conçue pour le raisonnement général sur des documents longs. Parallèlement, Llama Scout repousse encore plus loin les limites avec une capacité impressionnante de 10 millions de jetons, spécialement conçue pour traiter des bases de code ou des archives juridiques entières en un seul passage.
Cependant, la sortie de GPT-5.2 cette semaine a marqué un changement de stratégie. Plutôt que de rechercher un contexte infini, OpenAI a limité son tout dernier produit phare à une fenêtre de 400 000 tokens, privilégiant la taille brute au profit d'une « mémoire parfaite » et de capacités de raisonnement supérieures qui évitent les problèmes de distraction courants dans les modèles plus volumineux.
Les différences de taille de la fenêtre contextuelle influencent les performances de chaque modèle dans les flux de travail réels. Les modèles contextuels étendus offrent une grande précision, une forte cohérence et un raisonnement à long terme, mais ils nécessitent également davantage de calculs et une sélection plus minutieuse du contexte.
Les modèles de milieu de gamme restent performants et permettent de gérer des documents volumineux et des discussions prolongées, bien qu'ils nécessitent une structure adaptée pour les entrées de très grande taille.
Les cas d'utilisation suivants illustrent comment les atouts des modèles dotés de grandes fenêtres contextuelles se manifestent dans des applications concrètes.
Avec suffisamment d'espace pour contenir des rapports complets, des transcriptions, des bases de code ou des documents de recherche, un modèle peut suivre des modèles, relier des détails éloignés et maintenir une compréhension cohérente du début à la fin. Cela offre de nombreux domaines d'application :
Droit : De grandes fenêtres permettent aux modèles d'analyser des contrats complets, de comparer des clauses dans plusieurs documents et de suivre les références cachées dans de longs documents.
Santé : Les équipes peuvent examiner des directives cliniques détaillées, des antécédents médicaux de patients ou des ensembles de données provenant de plusieurs études tout en conservant un contexte important qui serait perdu dans des fenêtres plus petites.
Recherche : Un modèle à grande fenêtre permet de lire des articles complets et des revues de littérature en un seul passage et de mettre en évidence des liens qui n'apparaissent que lorsque l'ensemble du document est visible.
Les fenêtres contextuelles plus grandes rendent l'IA conversationnelle plus naturelle, car le modèle peut mémoriser davantage de la conversation sans oublier les messages précédents.
Dans le domaine du service à la clientèle, cela permet des interactions plus fluides et plus personnalisées. Le modèle peut utiliser les préférences passées et les conversations antérieures pour fournir des réponses plus précises et pertinentes.
Les fenêtres contextuelles étendues facilitent le raisonnement complexe à travers le texte, l'audio et les éléments visuels en fournissant au modèle suffisamment d'espace pour regrouper toutes les modalités au lieu de les traiter séparément.
Lorsque la transcription complète, les images et les documents écrits associés tiennent dans une seule fenêtre, le modèle peut comparer les détails entre les différents formats, suivre les relations et construire une compréhension unifiée du contexte.
Cela élimine les lacunes qui apparaissent lorsque les informations doivent être fragmentées ou résumées et permet au modèle de raisonner sur l'ensemble des entrées à la fois.
Les fenêtres contextuelles de grande taille offrent des capacités de modélisation puissantes, mais elles posent également de nouveaux défis en matière de performances à mesure que la taille des entrées augmente. Même les modèles avancés ont des difficultés à maintenir une attention parfaite sur des séquences extrêmement longues, de sorte qu'ils n'utilisent pas toujours les informations provenant de chaque partie du contexte de manière aussi fiable que vous pourriez vous y attendre.
Un problème courant dans les modèles à contexte long est l'effet « perdu au milieu ». Les modèles se souviennent assez bien du début et de la fin d'une longue séquence, mais ils omettent ou ignorent souvent des détails importants qui se trouvent au milieu. Cela peut entraîner des réponses moins pertinentes, même lorsque le contexte complet est disponible.
Structurer les données de manière intelligente permet d'éviter ce problème pour les tâches importantes. Cela implique de le diviser en sections claires ou de répéter les points clés afin que le modèle ne les néglige pas.
Les coûts peuvent augmenter rapidement avec l'augmentation de la taille de la fenêtre contextuelle. Chaque jeton supplémentaire augmente la taille du calcul d'attention, ce qui augmente le temps d'inférence, les besoins en mémoire GPU et la charge globale du système.
Pour y parvenir, il est nécessaire de trouver des moyens plus efficaces pour alimenter le modèle en informations. Des techniques telles que la récupération sélective, le découpage hiérarchique ou les résumés rapides permettent de réduire la quantité de données saisies, afin que le modèle ne soit pas surchargé.
Les grandes fenêtres soulèvent également des questions relatives à la sécurité et à la confidentialité. Lorsque vous fournissez davantage de données au modèle, le risque d'exposer des informations sensibles augmente.
C'est pourquoi les équipes ont besoin de règles strictes en matière de traitement des données, de procédures de rédaction et de contrôles d'accès afin de s'assurer que les fenêtres contextuelles de grande taille ne créent pas de nouveaux risques.
Dans de nombreux cas, les informations non pertinentes ou vaguement liées augmentent la charge cognitive du modèle, ce qui accroît le risque d'hallucinations et de modèles incorrects. Les entrées trop longues introduisent également du bruit qui peut fausser la compréhension de la tâche par le modèle.
Dans la pratique, des performances de haute qualité découlent souvent d'un contexte soigneusement sélectionné, garantissant que le modèle voit les bonnes informations au lieu d'être simplement exposé à la plus grande quantité d'informations possible.
Plusieurs méthodes peuvent être utilisées pour exploiter de manière optimale les fenêtres contextuelles. Parmi celles-ci figurent la génération augmentée par la récupération (RAG), l'ingénierie contextuelle, le découpage en morceaux et la sélection de modèles.
La génération augmentée par récupération (RAG) fonctionne en extrayant des informations supplémentaires d'une base de données externe et en les transmettant au modèle chaque fois que le contexte l'exige.
Au lieu d'intégrer des documents entiers dans la fenêtre contextuelle, RAG stocke tout séparément et ne récupère que les éléments pertinents pour la question en cours. Cela permet de réduire le contexte tout en fournissant au modèle toutes les informations dont il a besoin.
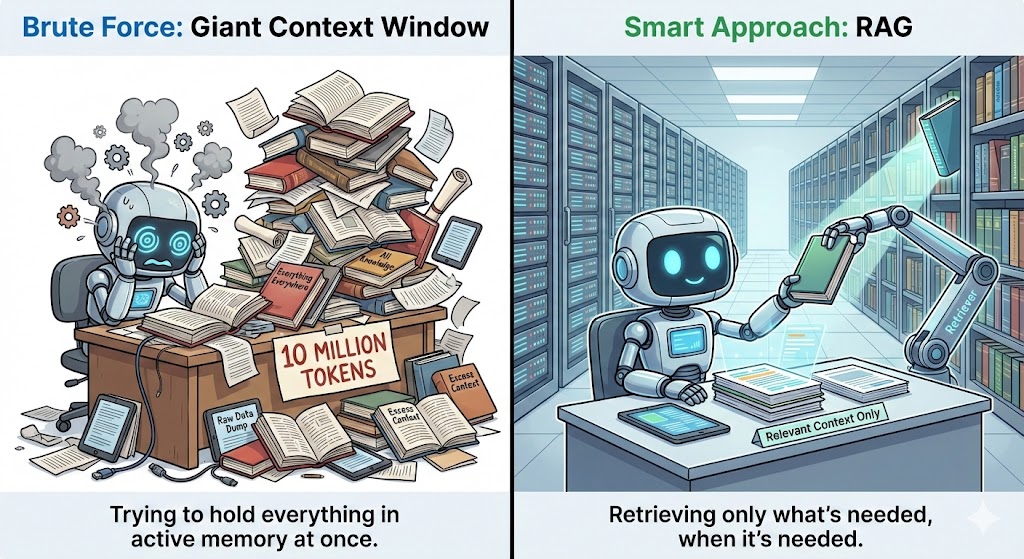
Pour ce faire, il utilise des intégrations ou des recherches vectorielles afin d'identifier les segments les plus pertinents et de les transmettre au modèle de manière claire et structurée. Cela améliore la précision en garantissant que le modèle peut utiliser des informations supplémentaires pertinentes au-delà de ses données d'entraînement.
L'ingénierie contextuelle vise à fournir aux modèles des informations pertinentes plutôt que de les surcharger de détails inutiles. Les stratégies efficaces consistent notamment à segmenter les documents volumineux, à résumer les sections de moindre importance et à utiliser des étapes de prétraitement légères pour mettre en évidence les points principaux.
La recherche sémantique facilite cette tâche en identifiant le texte pertinent pour la requête en cours. Vous pouvez également améliorer les résultats en déplaçant les informations les plus importantes au début ou à la fin du contexte, car les modèles ont tendance à mieux mémoriser ces emplacements.
Le découpage en morceaux permet de diviser les documents volumineux en sections plus petites et cohérentes. L'objectif est de regrouper le contenu en fonction de son sujet, de sa structure ou de la tâche qu'il soutient.
Cela permet de maintenir la cohérence de chaque segment et aide le modèle à rester concentré au lieu de se perdre dans un bloc de texte volumineux. Si vous souhaitez en savoir plus, n'hésitez pas à consulter cet article sur les stratégies avancées de découpage en morceaux.
Le découpage sémantique regroupe les phrases qui partagent une signification similaire au lieu de diviser le texte de manière aléatoire en fonction d'un nombre de caractères limité. Il divise le contenu en points de rupture naturels, tels que les changements de sujet, les transitions entre paragraphes ou les en-têtes de section.
Le découpage en blocs basé sur les tâches va encore plus loin en structurant chaque bloc autour de la question spécifique à laquelle vous essayez de répondre. Chaque section ne contient alors que les informations réellement pertinentes pour cette tâche.
Les tâches qui impliquent une analyse complète de documents, un raisonnement multi-fichiers ou des conversations de longue durée bénéficient de modèles avec des fenêtres comprises entre 200 000 et 1 million. Pour des tâches plus spécifiques telles que la synthèse, la révision de code ou la réponse à des questions courtes, les modèles de 100 000 à 200 000 mots offrent souvent le meilleur équilibre entre vitesse, coût et précision.
Les fenêtres plus petites peuvent néanmoins être efficaces lorsqu'elles sont associées à des systèmes de récupération performants. Un système RAG ( ) ou un protocole MCP (Model Context Protocol) performant peut extraire lesinformations pertinentesà la demande, ce qui évite au modèle de devoir tout conserver en mémoire.
Avant de conclure, examinons les perspectives d'évolution de la technologie en matière de fenêtres contextuelles.
Les architectures des futurs modèles s'orientent vers des fenêtres contextuelles dynamiques, plutôt que vers des fenêtres de taille fixe.
Les chercheurs explorent des approches qui combinent les atouts des transformateurs avec de nouveaux systèmes de mémoire à long terme, ce qui aboutit à des modèles capables de stocker et de rappeler des informations sans dépendre uniquement de mécanismes d'attention.
Ces architectures surmontent les limites actuelles en passant de fenêtres contextuelles statiques à des couches de mémoire dynamiques qui s'adaptent à la tâche.
Les systèmes de mémoire constituent un autre domaine d'innovation. Les futurs modèles devraient s'appuyer davantage sur des systèmes de mémoire contextuels qui s'étendent au-delà d'une seule session et assurent une continuité dans le temps.
Au lieu de traiter chaque conversation comme un nouveau départ, ces systèmes stockent les préférences clés, les décisions passées et les thèmes récurrents dans une couche de mémoire structurée qui peut être consultée lorsque cela est pertinent.
Cela permet de passer d'une personnalisation réactive à une personnalisation proactive, permettant au modèle de mieux comprendre les utilisateurs dans leur globalité et de soutenir les objectifs à long terme avec une cohérence bien plus grande.
La récupération externe évolue également. Actuellement, RAG fonctionne comme un moteur de recherche, en extrayant le texte pertinent dans l'invite. Des versions avancées telles que la génération augmentée par récupération corrective (CRAG, Corrective Retrieval-Augmented Generation) d', ont déjà fait leur apparition, mais ce n'est qu'un début.
À l'avenir, la récupération semblera plus intégrée, presque comme si le modèle disposait de sa propre mémoire externe. Ils collecteront, compresseront et réafficheront automatiquement les informations avec une intervention minimale de l'utilisateur.
La mémoire persistante modifiera également notre manière d'interagir avec l'IA. Au lieu d'oublier tout à la fin d'une session, le modèle se souviendra des détails importants pendant plusieurs jours, semaines, voire mois. En apprenant à connaître votre style, vos habitudes et vos priorités, il peut vous fournir des réponses plus personnalisées et utiles, sans que vous ayez à vous répéter.
Des outilstels que Mem0 sont déjà disponibles à l'adresseet ouvrent la voie à cette approche, en agissant comme une couche mémoire dédiée entre les applications et les LLM. Cependant, à l'avenir, nous prévoyons que ces capacités seront davantage intégrées directement dans les architectures des modèles plutôt que de dépendre de couches externes.
Les fenêtres plus grandes offrent de nouveaux flux de travail puissants, mais elles posent également des défis en matière d'attention, entraînent des coûts informatiques plus élevés et présentent des risques pour la qualité lorsque le contexte est surchargé. Cela rend la gestion stratégique du contexte essentielle.
Des techniques telles que l'augmentation de la récupération, le découpage sémantique et l'ingénierie contextuelle permettent aux modèles de rester concentrés, efficaces et fiables, même lorsque leurs capacités s'étendent.
À l'avenir, les meilleurs systèmes basés sur le LLM combineront des outils intelligents et une solide compréhension de la manière dont le contexte influence le raisonnement. En appliquant ces principes, les équipes peuvent tirer parti des avantages des modèles à contexte long tout en se préparant à la prochaine génération d'architectures qui repoussent encore plus loin les limites du contexte.
Améliorez vos connaissances de base en Python grâce au parcours de compétences « Développement de grands modèles linguistiques ».le cursus de compétences Développement de grands modèles linguistiques. Il est conçu pour vous guider depuis les bases du code jusqu'à la création et au perfectionnement de vos propres applications d'IA performantes.
Cours de maîtrise en droit
Cursus
Cours
Cours