
Cours
Comprendre l'intelligence artificielle
2 h
401.5K
Si vous souhaitez commencer à utiliser le modèle de diffusion stable immédiatement, vous pouvez l'exécuter en ligne à l'aide des outils suivants.
Stability AI, les créateurs de Stable Diffusion, ont rendu extrêmement simple pour les curieux de tester leur modèle de conversion de texte en image avec leur outil en ligne, DreamStudio.
DreamStudio donne aux utilisateurs l'accès à la dernière version des modèles de diffusion stable et leur permet de générer une image en 15 secondes.
Interface utilisateur de DreamStudio. Source de l'image : DreamStudio.
Lors de la rédaction de ce tutoriel, les nouveaux utilisateurs reçoivent 100 crédits gratuits pour essayer DreamStudio, ce qui est suffisant pour 500 images en utilisant les paramètres par défaut ! Des crédits supplémentaires peuvent être achetés dans l'application à votre convenance, pour seulement 10,00 $ par 1000 crédits.
Hugging Face est une communauté et une plateforme d'IA qui encourage les contributions à code source ouvert. Bien qu'il soit reconnu pour ses modèles de transformateurs, Hugging Face permet également d'accéder au dernier modèle de diffusion Stable, et comme un véritable amoureux des logiciels libres, il est gratuit.
Pour utiliser la diffusion stable dans Hugging Face, vous pouvez essayer l'une des démos, comme la démo Stable Diffusion 2.1.
La contrepartie de Hugging Face est que vous ne pouvez pas personnaliser les propriétés comme vous pouvez le faire dans DreamStudio, et que la génération d'une image prend sensiblement plus de temps.

Démonstration de diffusion stable dans un visage étreint. Image de l'auteur.
Mais que faire si vous souhaitez expérimenter la diffusion stable sur votre ordinateur local ? Nous avons tout ce qu'il vous faut.
L'exécution locale de la diffusion stable vous permet d'expérimenter différentes entrées de texte afin de générer des images mieux adaptées à vos besoins. Vous pouvez également affiner le modèle sur vos données afin d'améliorer les résultats, compte tenu des données que vous fournissez.
Avis de non-responsabilité : Vous devez disposer d'un GPU pour exécuter Stable Diffusion localement.
Pour exécuter Stable Diffusion à partir de votre ordinateur local, vous aurez besoin de Python 3.10.6. Vous pouvez l'installer à partir du site officiel de Python. Si vous êtes bloqué, consultez notre tutoriel Comment installer Python.
Vérifiez que l'installation s'est déroulée correctement en ouvrant l'invite de commande, en tapant python et en exécutant la commande. Ceci devrait afficher la version de Python que vous utilisez.
Avis de non-responsabilité : La version recommandée pour faire fonctionner Stable Diffusion est Python 3.10.6. Nous vous recommandons de ne pas procéder sans cette version afin d'éviter tout problème.
Ensuite, vous devez installer le système de gestion de référentiel de code Git. Le tutoriel d'installation de Git peut vous aider, et notre cours d'introduction à Git peut approfondir vos connaissances de Git.
GitHub est un service d'hébergement de logiciels où les développeurs hébergent leur code afin de pouvoir suivre et collaborer avec d'autres développeurs sur des projets. Si vous n'avez pas de compte Github, c'est aussi le moment d'en créer un - consultez Github et Git Tutorial for Beginners pour obtenir de l'aide.
Hugging Face, quant à lui, est une communauté d'IA qui prône les contributions à code source ouvert. C'est la plaque tournante de plusieurs modèles d'intelligence artificielle dans divers domaines, notamment le traitement du langage naturel, la vision par ordinateur, etc. Vous aurez besoin d'un compte pour télécharger la dernière version de Stable Diffusion. Nous reviendrons sur cette étape ultérieurement.
Au cours de cette étape, vous allez télécharger l'interface Web de diffusion stable sur votre ordinateur local. Bien qu'il soit utile de créer un dossier dédié (par exemple, stable-diffusion-demo-project) à cette fin, ce n'est pas obligatoire.
1. Ouvrez Git Bash:
2. Naviguez jusqu'au dossier de votre choix:
cd pour naviguer jusqu'au dossier où vous souhaitez cloner la Web-UI de Stable Diffusion. Par exemple :cd path/to/your/folder3. Clonez le dépôt:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
4. Vérifiez le clone:
stable-diffusion-webui dans le répertoire que vous avez choisi.
Note : Vous trouverez des instructions plus spécifiques pour votre matériel et votre système d'exploitation dans le dépôt Github de l'interface web Stable Diffusion.
1. Connectez-vous à Hugging Face:
2. Téléchargez le modèle de diffusion stable:
3. Localisez le dossier du modèle:
stable-diffusion-webui\models\Stable-diffusion4. Déplacez le modèle téléchargé:
Stable-diffusion, vous trouverez un fichier texte nommé Put Stable Diffusion Checkpoints here.Dans cette étape, vous installerez les outils nécessaires à l'exécution de Stable Diffusion.
1. Ouvrez l'invite de commande ou le terminal.
2. Naviguez jusqu'au dossier de l'interface web de Stable Diffusion:
cd pour accéder au dossier stable-diffusion-webui que vous avez cloné précédemment. Par exemple :cd path/to/stable-diffusion-webui3. Exécutez le script d'installation:
stable-diffusion-webui, exécutez la commande suivante :webui-user.batCe script va créer un environnement virtuel et installer toutes les dépendances nécessaires à l'exécution de Stable Diffusion. Le processus peut prendre environ 10 minutes, soyez patient.
Note : Vous trouverez des instructions plus spécifiques pour votre matériel et votre système d'exploitation dans le dépôt Github de l'interface web Stable Diffusion.
Une fois les dépendances installées, une URL apparaîtra dans votre invite de commande : http://127.0.0.1:7860.
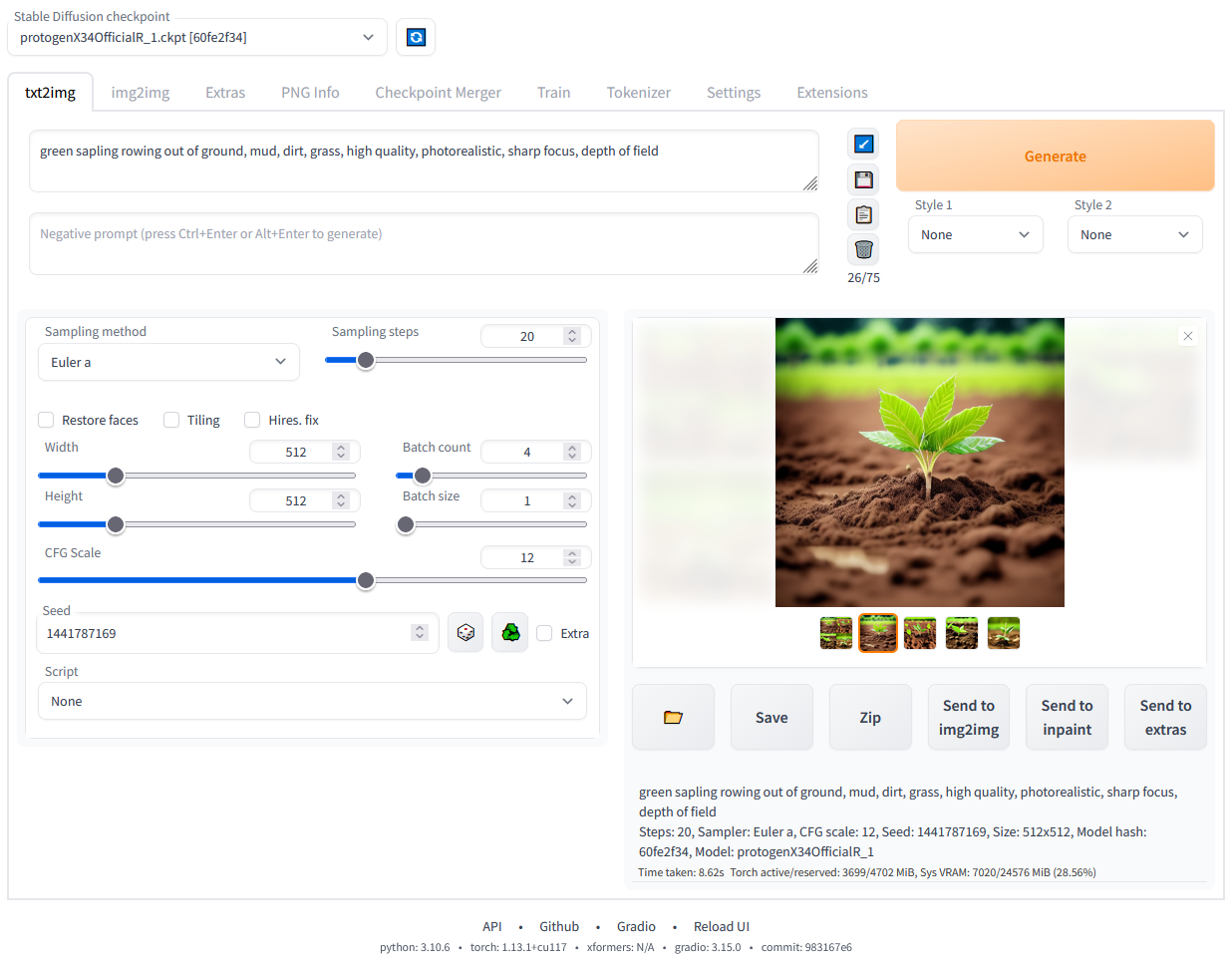
L'interface web de Diffusion est stable et fonctionne localement. Image de l'auteur.
La diffusion stable représente une avancée significative dans le domaine de l'IA générative. Il permet de générer des images détaillées de haute qualité à partir de descriptions textuelles. Que vous cherchiez à modifier des images existantes, à améliorer des images basse résolution ou à créer des visuels entièrement nouveaux, Stable Diffusion vous offre un ensemble d'outils puissants et polyvalents.
Avec les récentes mises à jour et améliorations de Stable Diffusion 3 et Medium, les capacités du modèle ont encore été renforcées, ce qui en fait un leader dans le domaine de l'IA générative.
L'utilisation de Stable Diffusion au niveau local ou par le biais de diverses plateformes en ligne telles que DreamStudio et Hugging Face vous permet d'explorer et de tirer parti de tout son potentiel. En suivant les étapes décrites dans ce guide, vous pourrez mettre en place et commencer à utiliser la diffusion stable pour répondre à vos besoins créatifs et pratiques !
L'IA générative est un mode révolutionnaire d'apprentissage profond qui crée des textes, des images et d'autres contenus de haute qualité à partir des données sur lesquelles elle a été formée. Des outils comme Stable Diffusion, ChatGPT et DALL-E sont d'excellents exemples de la façon dont l'IA générative transforme diverses industries en permettant de nouvelles formes de créativité et d'innovation. Au fur et à mesure que ces technologies évoluent, elles offrent aux artistes, aux développeurs et aux chercheurs de nouvelles possibilités de repousser les limites du possible.
Pour ceux qui souhaitent plonger plus profondément dans le monde de l'IA générative, voici quelques ressources à explorer :
Apprenez-en plus sur l'IA générative et l'apprentissage profond avec ces cours !
Cours
Cours
Cours
blog
blog
Kurtis Pykes
9 min
blog
Kurtis Pykes
15 min
Tutoriel
Tutoriel
Samuel Shaibu
Tutoriel
Aditya Sharma

