
Curso
Entendendo a inteligência artificial
2 h
401.5K
Se quiser começar a usar o modelo de difusão estável imediatamente, você pode executá-lo on-line usando as seguintes ferramentas.
A Stability AI, criadora do Stable Diffusion, tornou extremamente simples para os curiosos testarem seu modelo de texto para imagem com sua ferramenta on-line, o DreamStudio.
O DreamStudio concede aos usuários acesso à versão mais recente dos modelos Stable Diffusion e permite que eles gerem uma imagem em até 15 segundos.
Interface de usuário do DreamStudio. Fonte da imagem: DreamStudio.
Ao escrever este tutorial, os novos usuários recebem 100 créditos gratuitos para experimentar o DreamStudio, o que é suficiente para 500 imagens usando as configurações padrão! Créditos adicionais podem ser comprados no aplicativo conforme sua conveniência, custando apenas US$ 10,00 por 1.000 créditos.
Hugging Face é uma comunidade e plataforma de IA que promove contribuições de código aberto. Embora seja altamente reconhecido por seus modelos de transformadores, o Hugging Face também fornece acesso ao modelo de difusão Stable mais recente e, como um verdadeiro amante do código aberto, é gratuito.
Para executar a difusão estável no Hugging Face, você pode tentar uma das demonstrações, como a demonstração Stable Diffusion 2.1.
A desvantagem do Hugging Face é que você não pode personalizar as propriedades como no DreamStudio, e leva muito mais tempo para gerar uma imagem.

Demonstração de difusão estável em um rosto abraçado. Imagem do autor.
Mas e se você quiser fazer experiências com o Stable Diffusion em seu computador local? Nós ajudamos você.
A execução do Stable Diffusion localmente permite que você faça experiências com várias entradas de texto para gerar imagens mais adaptadas às suas necessidades. Você também pode ajustar o modelo em seus dados para melhorar os resultados, considerando os dados fornecidos.
Isenção de responsabilidade: Você deve ter uma GPU para executar o Stable Diffusion localmente.
Para executar o Stable Diffusion em seu computador local, você precisará do Python 3.10.6. Ele pode ser instalado no site oficial do Python. Se você tiver dúvidas, consulte nosso tutorial Como instalar o Python.
Verifique se a instalação funcionou corretamente abrindo o prompt de comando, digitando python e executando o comando. Isso deve imprimir a versão do Python que você está usando.
Isenção de responsabilidade: A versão recomendada para executar o Stable Diffusion é a Python 3.10.6. Recomendamos que você não prossiga sem essa versão para evitar problemas.
Em seguida, você deve instalar o sistema de gerenciamento de repositório de código Git. O Tutorial de instalação do Git pode ajudar, e nosso curso de Introdução ao Git pode aprofundar seu conhecimento sobre o Git.
O GitHub é um serviço de hospedagem de desenvolvimento de software em que os desenvolvedores hospedam seus códigos para que possam acompanhar e colaborar com outros desenvolvedores em projetos. Se você ainda não tem uma conta no Github, agora também é um bom momento para criar uma - confira o Tutorial do Github e do Git para iniciantes para obter ajuda.
O Hugging Face, por outro lado, é uma comunidade de IA que defende contribuições de código aberto. Ele é o centro de vários modelos de IA de vários domínios, incluindo processamento de linguagem natural, visão computacional e muito mais. Você precisará de uma conta para fazer o download da versão mais recente do Stable Diffusion. Você verá essa etapa mais adiante.
Nesta etapa, você fará o download do Stable Diffusion Web-UI para o seu computador local. Embora seja útil criar uma pasta dedicada (por exemplo, stable-diffusion-demo-project) para essa finalidade, isso não é obrigatório.
1. Abra o Git Bash:
2. Navegue até a pasta que você deseja:
cd para navegar até a pasta em que você deseja clonar a Stable Diffusion Web-UI. Por exemplo:cd path/to/your/folder3. Clone o repositório:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
4. Verifique o clone:
stable-diffusion-webui no diretório escolhido.
Observação: Você pode encontrar instruções mais específicas para seu hardware e sistema operacional no repositório do Github da interface do usuário da Web do Stable Diffusion.
1. Faça login no Hugging Face:
2. Faça o download do modelo Stable Diffusion:
3. Localize a pasta do modelo:
stable-diffusion-webui\models\Stable-diffusion4. Mova o modelo baixado:
Stable-diffusion, você verá um arquivo de texto chamado Put Stable Diffusion Checkpoints here.Nesta etapa, você instalará as ferramentas necessárias para executar o Stable Diffusion.
1. Abra o prompt de comando ou o terminal.
2. Navegue até a pasta da interface do usuário da Web do Stable Diffusion:
cd para navegar até a pasta stable-diffusion-webui que você clonou anteriormente. Por exemplo:cd path/to/stable-diffusion-webui3. Execute o script de configuração:
stable-diffusion-webui, execute o seguinte comando:webui-user.batEsse script criará um ambiente virtual e instalará todas as dependências necessárias para que você possa executar o Stable Diffusion. O processo pode levar cerca de 10 minutos, portanto, seja paciente.
Observação: Você pode encontrar instruções mais específicas para seu hardware e sistema operacional no repositório do Github da interface do usuário da Web do Stable Diffusion.
Depois que as dependências forem instaladas, um URL será exibido no prompt de comando: http://127.0.0.1:7860.
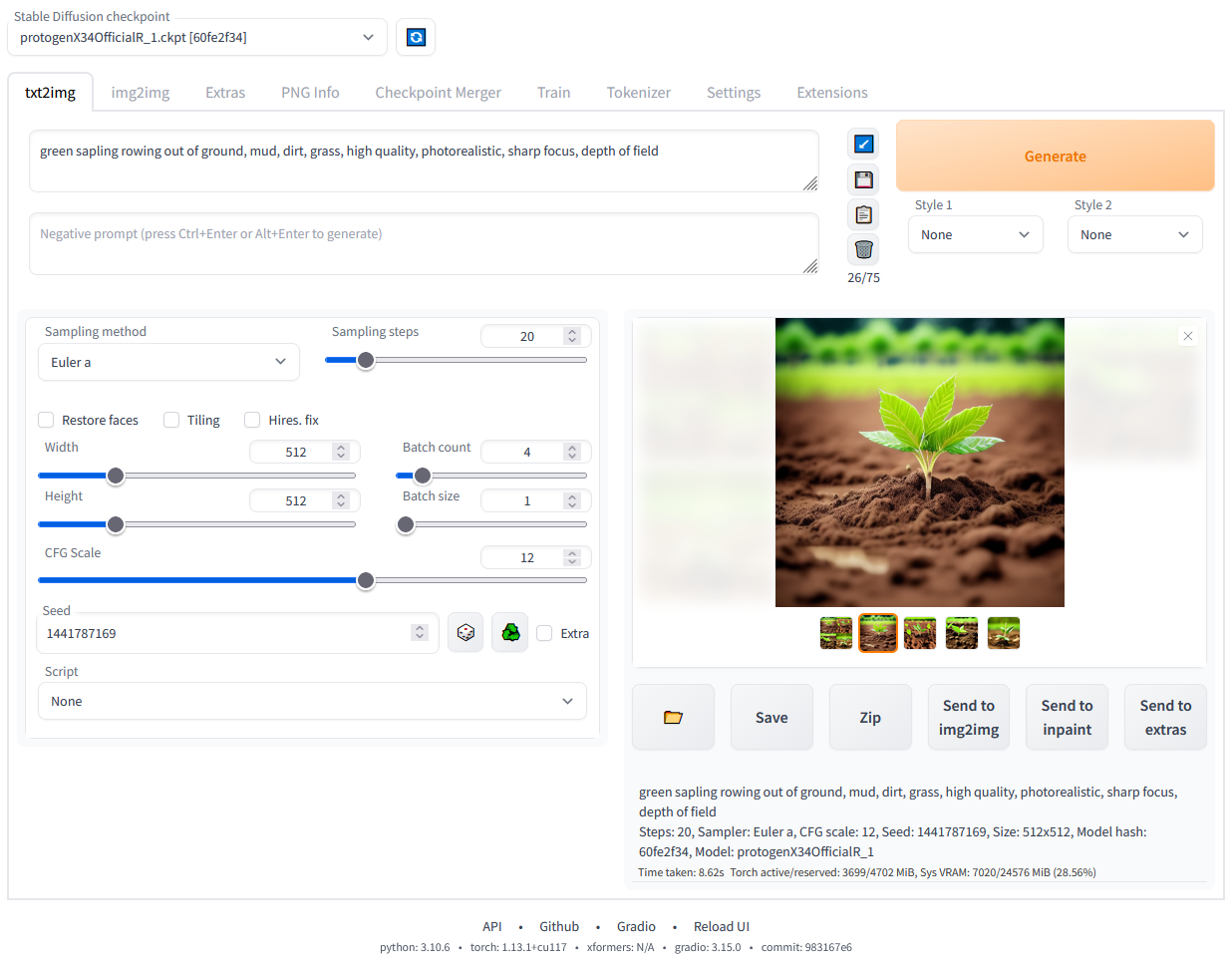
IU da Web do Diffusion estável em execução local. Imagem do autor.
O Stable Diffusion representa um avanço significativo no campo da IA generativa. Ele oferece a capacidade de gerar imagens detalhadas e de alta qualidade a partir de descrições textuais. Se você deseja modificar imagens existentes, aprimorar imagens de baixa resolução ou criar visuais totalmente novos, o Stable Diffusion oferece um conjunto de ferramentas avançado e versátil.
Com as recentes atualizações e melhorias no Stable Diffusion 3 e Medium, os recursos do modelo foram aprimorados ainda mais, tornando-o líder no espaço de IA generativa.
A execução do Stable Diffusion localmente ou por meio de várias plataformas on-line, como DreamStudio e Hugging Face, permite que você explore e aproveite todo o seu potencial. Seguindo as etapas descritas neste guia, você pode configurar e começar a usar o Stable Diffusion para atender às suas necessidades criativas e práticas!
A IA generativa é um modo inovador de aprendizagem profunda que cria textos, imagens e outros conteúdos de alta qualidade com base nos dados em que foi treinada. Ferramentas como Stable Diffusion, ChatGPT e DALL-E são excelentes exemplos de como a IA generativa está transformando vários setores ao permitir novas formas de criatividade e inovação. À medida que essas tecnologias continuam a evoluir, elas abrem novas possibilidades para que artistas, desenvolvedores e pesquisadores ultrapassem os limites do que é possível.
Para os interessados em se aprofundar no mundo da IA generativa, aqui estão alguns recursos que você pode explorar:
Saiba mais sobre IA generativa e aprendizagem profunda com estes cursos!
Curso
Curso
Curso
blog
Richie Cotton
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Amberle McKee
Tutorial
Zoumana Keita
Tutorial
Kurtis Pykes



