
Kurs
Künstliche Intelligenz verstehen
2 Std.
401.5K
Wenn du das Stabile Diffusionsmodell sofort einsetzen möchtest, kannst du es mit den folgenden Tools online ausführen.
Stability AI, die Macher von Stable Diffusion, haben es Neugierigen mit ihrem Online-Tool DreamStudio extrem einfach gemacht, ihr Text-zu-Bild-Modell zu testen.
DreamStudio gewährt den Nutzern Zugang zur neuesten Version der Stable Diffusion Modelle und ermöglicht es ihnen, ein Bild in bis zu 15 Sekunden zu erstellen.
DreamStudio Benutzeroberfläche. Bildquelle: DreamStudio.
Wenn du dieses Tutorial schreibst, erhalten neue Benutzer 100 kostenlose Credits, um DreamStudio auszuprobieren. Das reicht für 500 Bilder mit den Standardeinstellungen! Zusätzliche Credits können innerhalb der Anwendung erworben werden und kosten nur $10,00 pro 1000 Credits.
Hugging Face ist eine KI-Community und Plattform, die Open-Source-Beiträge fördert. Obwohl Hugging Face vor allem für seine Transformer-Modelle bekannt ist, bietet es auch Zugriff auf das neueste Stable-Diffusionsmodell, und wie es sich für einen echten Open-Source-Liebhaber gehört, ist es kostenlos.
Um die stabile Diffusion in Hugging Face auszuführen, kannst du eine der Demos ausprobieren, z. B. die Demo Stable Diffusion 2.1.
Der Nachteil von Hugging Face ist, dass du die Eigenschaften nicht wie in DreamStudio anpassen kannst und dass es deutlich länger dauert, ein Bild zu erstellen.

Stabile Diffusionsdemo im umarmenden Gesicht. Bild vom Autor.
Was aber, wenn du mit Stable Diffusion auf deinem lokalen Computer experimentieren möchtest? Wir haben das Richtige für dich.
Wenn du Stable Diffusion lokal ausführst, kannst du mit verschiedenen Texteingaben experimentieren, um Bilder zu erzeugen, die besser auf deine Anforderungen zugeschnitten sind. Du kannst das Modell auch auf deine Daten abstimmen, um die Ergebnisse anhand der von dir bereitgestellten Eingaben zu verbessern.
Haftungsausschluss: Du musst einen Grafikprozessor haben, um Stable Diffusion lokal zu betreiben.
Um Stable Diffusion auf deinem lokalen Computer auszuführen, benötigst du Python 3.10.6. Diese kann von der offiziellen Python-Website installiert werden. Wenn du nicht weiterkommst, sieh dir unser Tutorial zur Installation von Python an.
Überprüfe, ob die Installation richtig funktioniert hat, indem du die Eingabeaufforderung öffnest, python eingibst und den Befehl ausführst. Dies sollte die Version von Python ausgeben, die du verwendest.
Haftungsausschluss: Die empfohlene Version für die Ausführung von Stable Diffusion ist Python 3.10.6. Wir empfehlen, nicht ohne diese Version fortzufahren, um Probleme zu vermeiden.
Als nächstes musst du das Code-Repository-Management-System Git installieren. Das Git-Installationstutorial kann dir dabei helfen, und unser Kurs Einführung in Git kann dein Wissen über Git vertiefen.
GitHub ist ein Hosting-Dienst für die Softwareentwicklung, bei dem Entwickler ihren Code hosten, damit sie Projekte verfolgen und mit anderen Entwicklern zusammenarbeiten können. Wenn du noch keinen Github-Account hast, ist jetzt auch ein guter Zeitpunkt, einen zu erstellen - schau dir Github und Git Tutorial for Beginners an, um Hilfe zu bekommen.
Hugging Face hingegen ist eine KI-Community, die sich für Open-Source-Beiträge einsetzt. Sie ist die Drehscheibe für verschiedene KI-Modelle aus unterschiedlichen Bereichen, darunter natürliche Sprachverarbeitung, Computer Vision und mehr. Du brauchst ein Konto, um die neueste Version von Stable Diffusion herunterzuladen. Zu diesem Schritt kommen wir später.
In diesem Schritt lädst du die Stable Diffusion Web-UI auf deinen lokalen Computer herunter. Es ist zwar hilfreich, einen eigenen Ordner (z. B. stable-diffusion-demo-project) für diesen Zweck anzulegen, aber nicht zwingend notwendig.
1. Öffne die Git Bash:
2. Navigiere zu deinem gewünschten Ordner:
cd, um zu dem Ordner zu navigieren, in den du die Stable Diffusion Web-UI klonen willst. Zum Beispiel:cd path/to/your/folder3. Klone das Repository:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
4. Überprüfe den Klon:
stable-diffusion-webui in deinem gewählten Verzeichnis sehen.
Hinweis: Genauere Anweisungen für deine Hardware und dein Betriebssystem findest du im Github-Repository der Stable Diffusion Web UI.
1. Melde dich bei Hugging Face an:
2. Lade das Modell der stabilen Diffusion herunter:
3. Finde den Modellordner:
stable-diffusion-webui\models\Stable-diffusion4. Verschiebe das heruntergeladene Modell:
Stable-diffusion findest du eine Textdatei namens Put Stable Diffusion Checkpoints here.In diesem Schritt installierst du die notwendigen Tools, um Stable Diffusion zu starten.
1. Öffne die Eingabeaufforderung oder das Terminal.
2. Navigiere zum Ordner "Stable Diffusion web UI":
cd, um zu dem Ordner stable-diffusion-webui zu navigieren, den du zuvor geklont hast. Zum Beispiel:cd path/to/stable-diffusion-webui3. Führe das Setup-Skript aus:
stable-diffusion-webui befindest, führe den folgenden Befehl aus:webui-user.batDieses Skript erstellt eine virtuelle Umgebung und installiert alle erforderlichen Abhängigkeiten für die Ausführung von Stable Diffusion. Der Vorgang kann etwa 10 Minuten dauern, also sei geduldig.
Hinweis: Genauere Anweisungen für deine Hardware und dein Betriebssystem findest du im Github-Repository der Stable Diffusion Web UI.
Nachdem die Abhängigkeiten installiert wurden, wird eine URL in deiner Eingabeaufforderung angezeigt: http://127.0.0.1:7860.
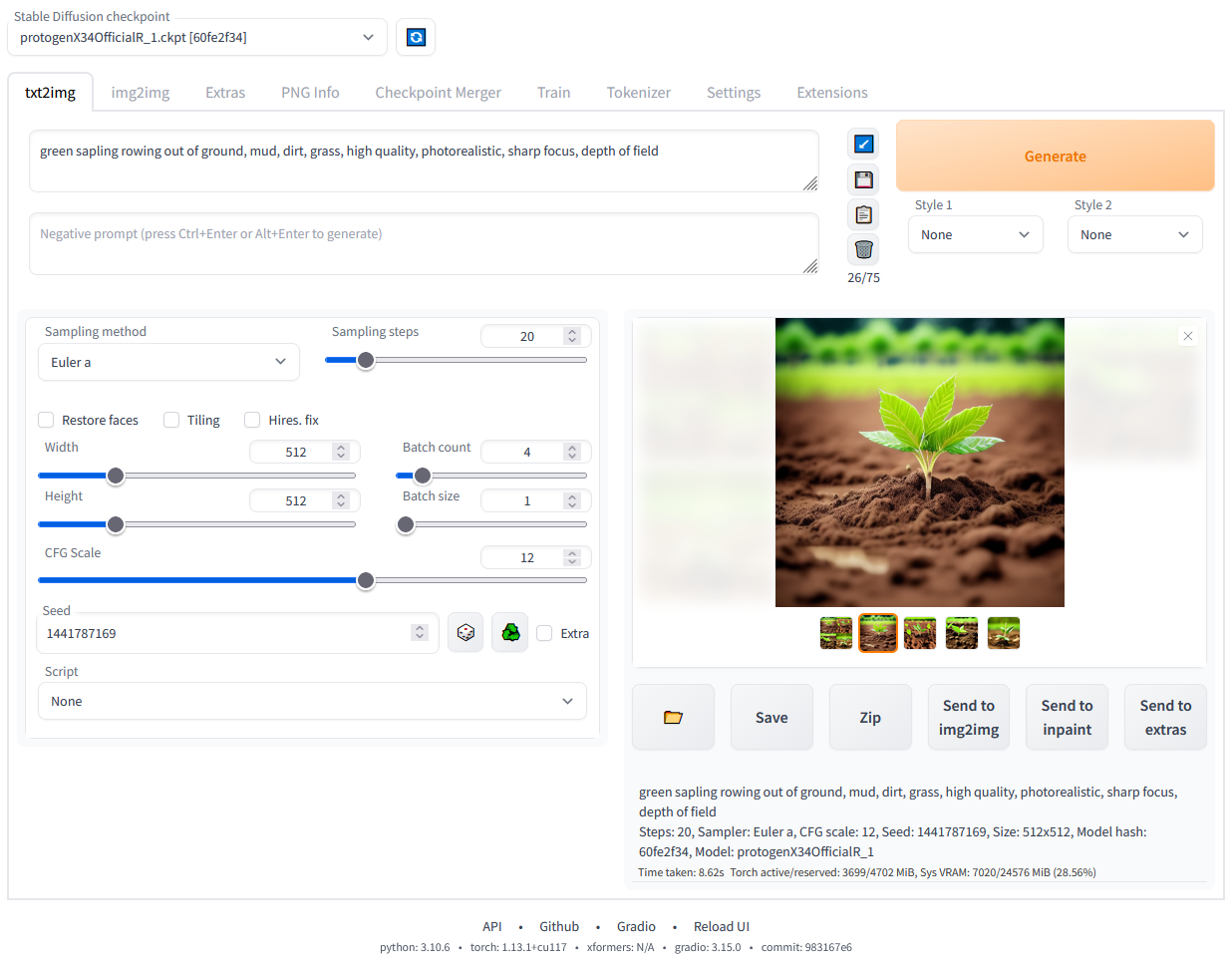
Stabile Diffusion Web-UI, die lokal läuft. Bild vom Autor.
Stable Diffusion ist ein bedeutender Fortschritt auf dem Gebiet der generativen KI. Es bietet die Möglichkeit, aus Textbeschreibungen hochwertige, detaillierte Bilder zu erstellen. Ganz gleich, ob du bestehende Bilder verändern, Bilder mit niedriger Auflösung verbessern oder ganz neue Bilder erstellen möchtest, Stable Diffusion bietet dir ein leistungsstarkes und vielseitiges Werkzeugset.
Mit den jüngsten Aktualisierungen und Verbesserungen in Stable Diffusion 3 und Medium wurden die Fähigkeiten des Modells weiter ausgebaut, was es zu einem der führenden Modelle im Bereich der generativen KI macht.
Wenn du Stable Diffusion lokal oder über verschiedene Online-Plattformen wie DreamStudio und Hugging Face betreibst, kannst du sein volles Potenzial entdecken und nutzen. Wenn du die in diesem Leitfaden beschriebenen Schritte befolgst, kannst du Stable Diffusion einrichten und nutzen, um deine kreativen und praktischen Bedürfnisse zu erfüllen!
Generative KI ist eine bahnbrechende Form des Deep Learning, die auf der Grundlage der trainierten Daten hochwertige Texte, Bilder und andere Inhalte erstellt. Tools wie Stable Diffusion, ChatGPT und DALL-E sind hervorragende Beispiele dafür, wie generative KI verschiedene Branchen verändert, indem sie neue Formen von Kreativität und Innovation ermöglicht. Mit der Weiterentwicklung dieser Technologien eröffnen sie Künstlern, Entwicklern und Forschern neue Möglichkeiten, die Grenzen des Machbaren zu erweitern.
Für diejenigen, die tiefer in die Welt der generativen KI eintauchen wollen, gibt es hier einige Ressourcen, die du erkunden kannst:
Lerne in diesen Kursen mehr über generative KI und Deep Learning!
Kurs
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Satyabrata Pal
Tutorial
Matt Crabtree
Tutorial
Aditya Sharma
Tutorial
Sejal Jaiswal