

Cours
Concepts d'IA générative
2 h
107.6K
If you want to learn more about the latest releases in this space, I recommend checking out our guide on other top video generation models.
Kling AI is a generative AI platform designed to create videos from text prompts, images, or a combination of both. Developed by the Chinese technology company Kuaishou, it quickly became one of the best AI models for character consistency. The videos it generates come with native sound, making them feel polished and ready to use.
As with many AI video models, Kling AI's pricing is based on credits. We pay a monthly subscription that gives us access to a fixed number of monthly credits. There are also other small features locked behind each subscription tier, but the main differentiator remains the number of generation credits we're given.
To write this article, I used their Pro plan ($32.56 a month), which comes with 3,000 credits. For more details on their pricing plans, check the Kling AI official pricing page.
Credit usage is primarily determined by three factors:
Assuming we generate videos with native audio, with a Pro subscription, we can expect to generate around 6 minutes of 720p video or 4 minutes of 1080p video per month.
The examples in this section were taken from the Kling 3.0 model official user guide.
Most AI video models work best when the prompt describes a single shot or action. Kling 3.0 is able to understand a prompt that describes multiple shots in a single prompt.
The following example prompt describes the video's setting and four shots without explicitly listing them:
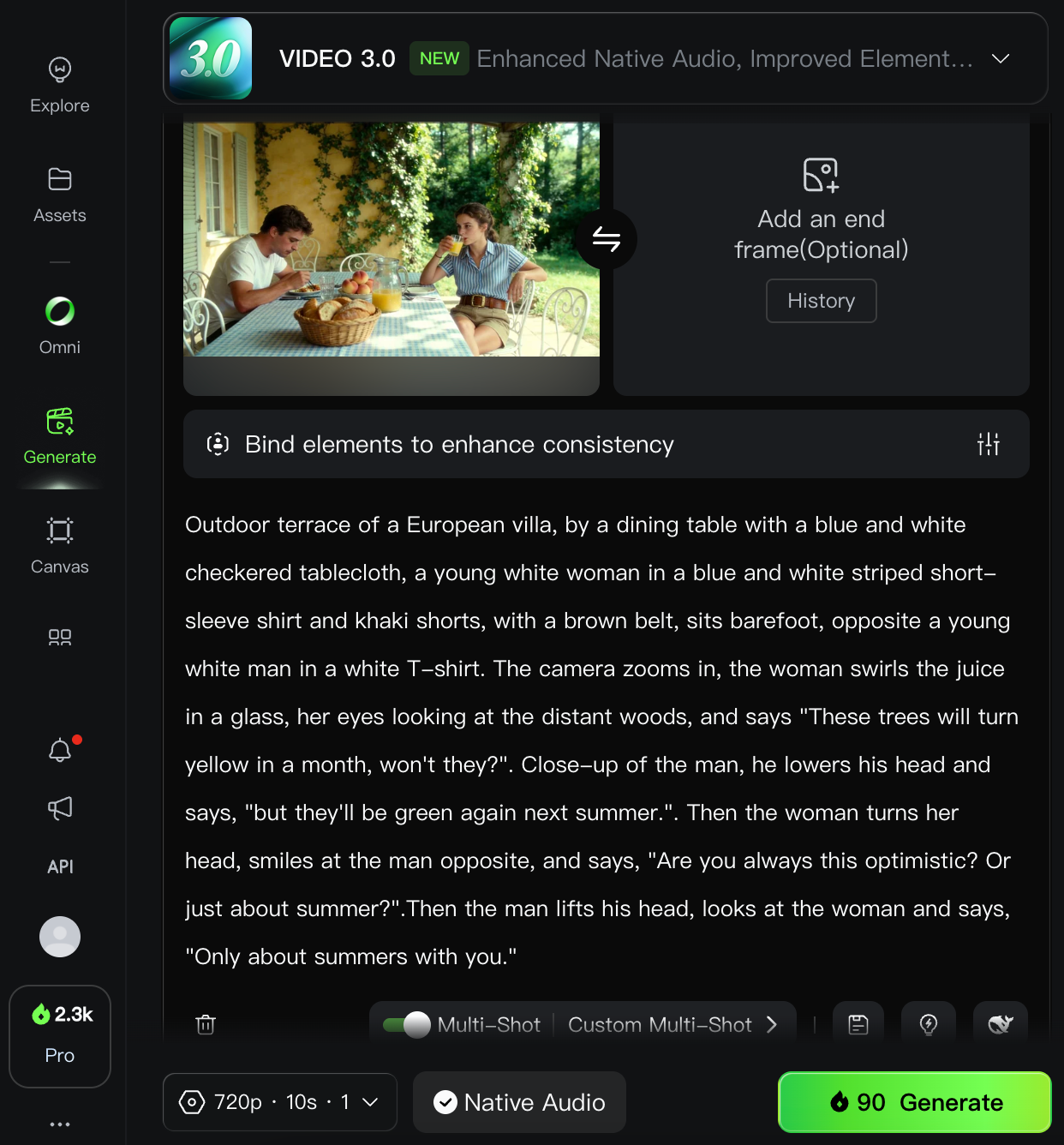
Outdoor terrace of a European villa, by a dining table with a blue and white checkered tablecloth, a young white woman in a blue and white striped short-sleeve shirt and khaki shorts, with a brown belt, sits barefoot, opposite a young white man in a white T-shirt.
The camera zooms in, the woman swirls the juice in a glass, her eyes looking at the distant woods, and says, "These trees will turn yellow in a month, won't they?"
Close-up of the man, he lowers his head and says, "But they'll be green again next summer."
Then the woman turns her head, smiles at the man opposite, and says, "Are you always this optimistic? Or just about summer?"
Then the man lifts his head, looks at the woman, and says, "Only about summers with you."The prompt was paired with an image, which the model used as the first frame of the video.
Here's the result:
I was very impressed by this video. The prompt adherence is strong, and the video looks quite realistic to me.
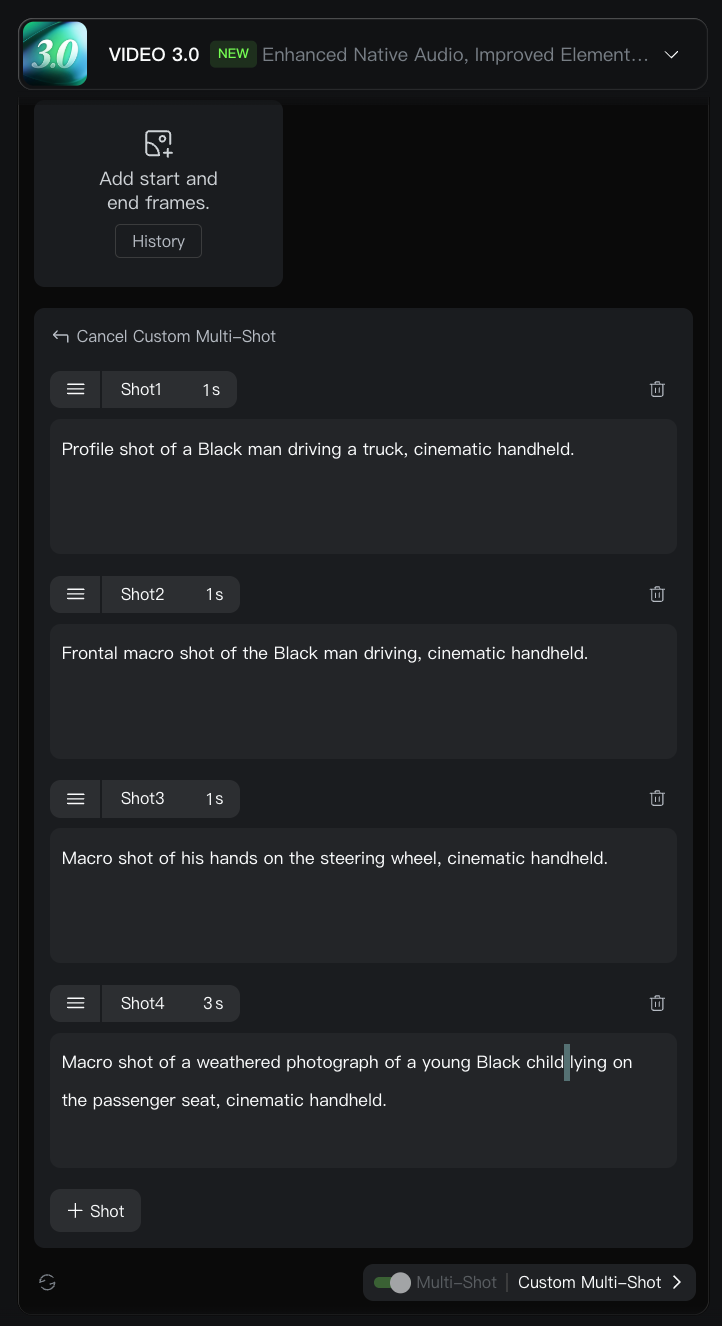
Despite the model's ability to understand where one shot ends and the next starts from a text prompt, it's not perfect and may interpret the prompt differently than we intended. We can force the structure of a scene by explicitly mentioning the scenes in the prompt.
Shot 1: Profile shot of a Black man driving a truck, cinematic handheld.
Shot 2: Frontal macro shot of the Black man driving, cinematic handheld.
Shot 3: Macro shot of his hands on the steering wheel, cinematic handheld.
Shot 4: Macro shot of a weathered photograph of a young Black child lying on the passenger seat, cinematic handheld.To specify each shot, we click the Custom Multi-Shot button at the bottom of the prompt input. There, we can provide a prompt for each shot and also set the duration. The model allows up to 6 shots per video.
Below is the result from this multi-shot prompt:
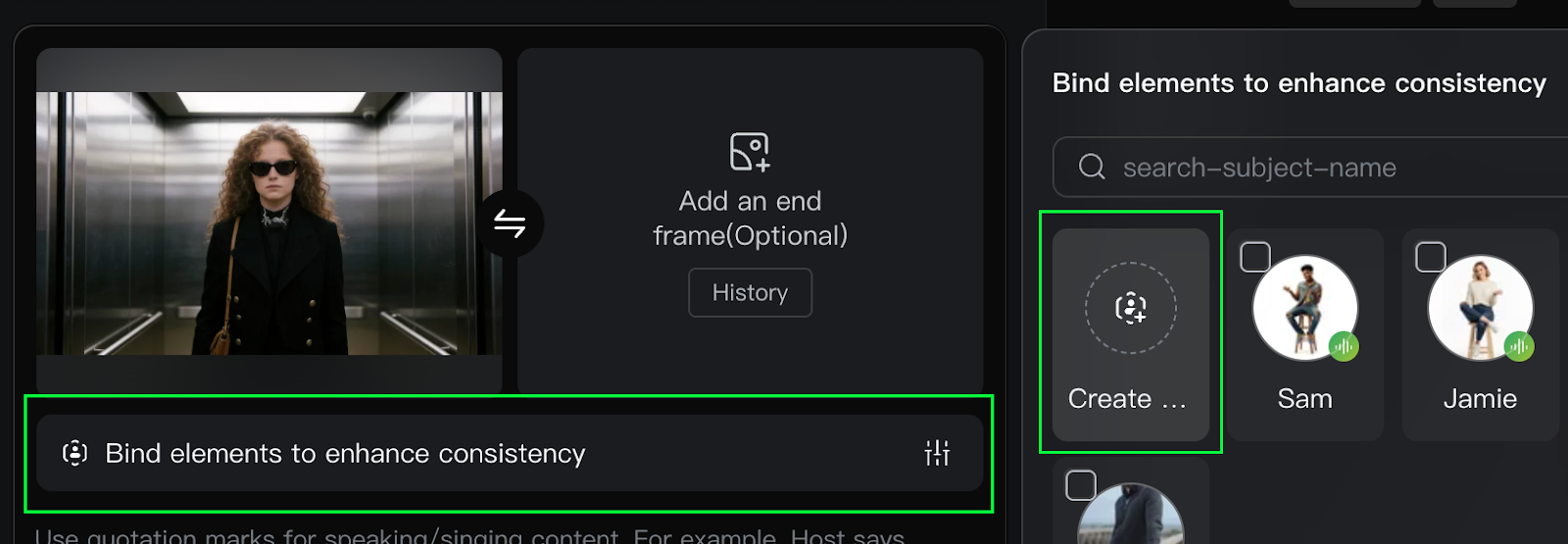
Subject binding is a feature that allows specific characters or visual elements to remain consistent throughout a generated video. Locking a subject’s appearance and characteristics helps ensure the main focus stays stable and recognizable, even when camera movements such as zooming, panning, or tilting occur.
After uploading an image as the initial frame, we can activate this feature by selecting the Bind elements to enhance Consistency option. This creates a reference that the system uses to maintain visual stability and prevent unwanted changes to the subject during video generation.
Without subject binding, the model will have to guess the features of the subject that aren't visible in the initial image. For example, in the image above, the subject is wearing sunglasses. So, it would be useful to provide an image of the subject's face. Providing other poses, such as the subject looking left and right, is also useful if we want the model to "not invent" what the person looks like.
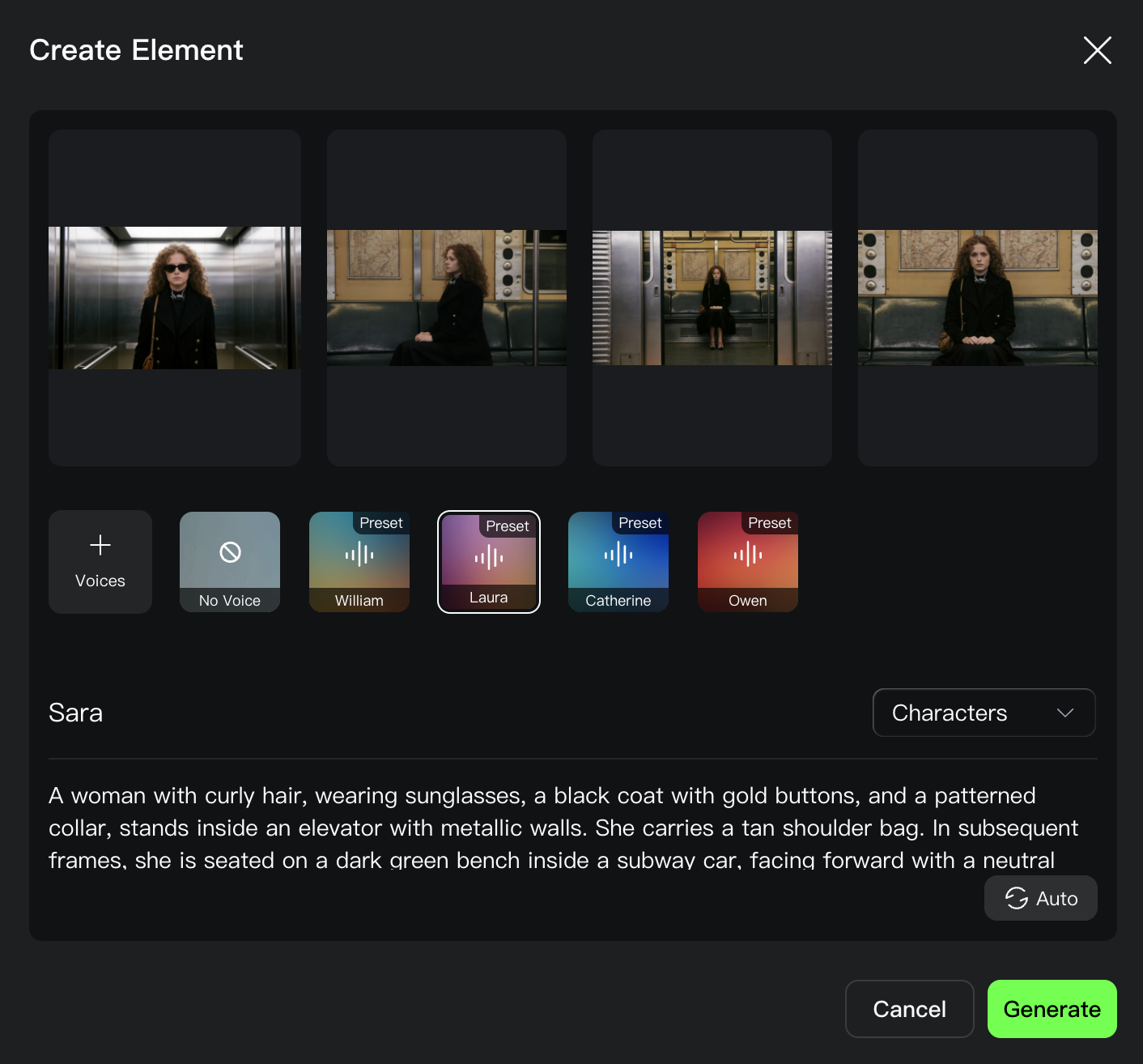
When creating an element, we can provide up to three images. We're also given the option to select a voice and a name for the character.
Here's the result:
I personally find these features to be a game-changer because character consistency was one of the aspects of AI video generation that I found the most frustrating to work with. It often required very detailed text prompts and iterating over and over to get it right.
The Omni mode from Kling AI brings every feature together into a single model. We can think of it as subject binding on steroids, as it allows us to create elements (characters, scenes, items, etc.) and then bring them all together into a single prompt. This makes it possible to generate very complex scenes with a high level of accuracy.
For example, we can create a character element by providing reference images and then a scene element, easily placing the character in that scene. As another example, we can create multiple characters and develop back-and-forth dialogue between them by referring to these characters in the prompt.
When using Omni mode, we can refer to previously created elements using @. This will open a pop-up where we can select the element we want to refer to.
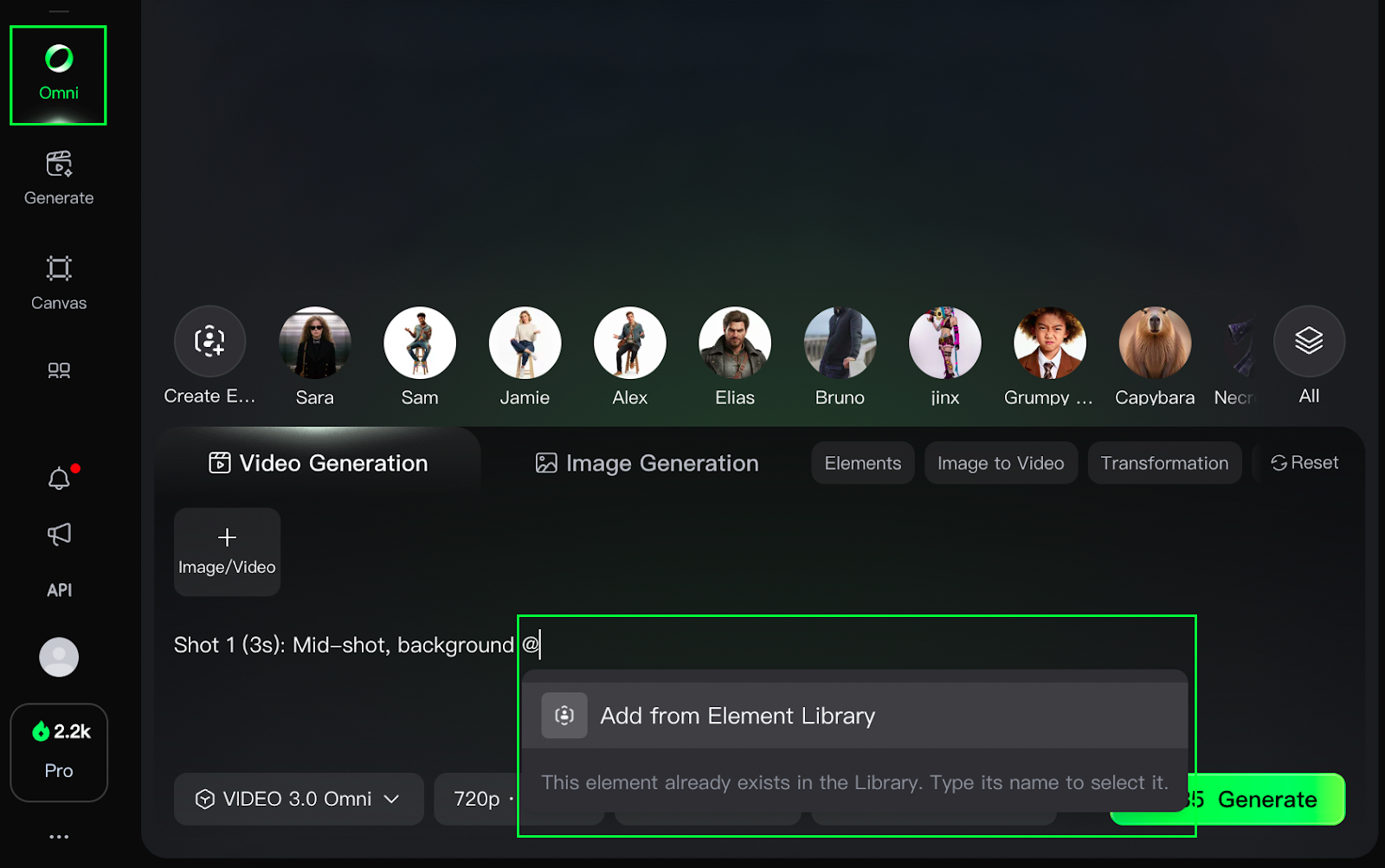
Here's a three-shot example showcasing the power and versatility of Omni:
Shot 1 (3s): Mid-shot, background @Image. @Grace sits on the sofa eating cookies as @Alan walks in holding @Samoyed.@Samoyed lunges for the cookie in @Grace's hand. @Grace says, "Hey! Watch your dog!"
Shot 2 (2s): @Alan sits beside her, pulling the leash and lifting @Samoyed. Close-up, @Alan says, "He just likes cookies more than me."
Shot 3 (3s): Close-up, @Grace smiles and says, "Well, he has good taste at least."In this example, @Image, @Grace, @Alan, and @Samoyed are elements created separately and used together in a single prompt.

In the previous section, we learned about the core capabilities of Kling 3.0 and showcased a few examples taken from their official website. I think the results are very impressive, but one should always be skeptical of the examples companies provide, as they are usually curated, cherry-picking only the best examples.
In this section, we take it for a spin and test it on new examples to see whether the model really lives up to the expectations.
I used AI to generate a fantasy character. I generated a full-body image and then a few different poses, like looking left, looking right, and having a mad expression.

I combined those elements to create a character I named Elias. I then generated an image for the first frame of the video and used subject binding to bind the two.

This is the prompt I used:
Elias stands alone in front of the burning village. Elias is breathing heavily, his hands clenched into tight fists at his sides.
Elias looks at something just off-camera, something we cannot see. Elias says, in a low and dangerous voice, "I told you what would happen if you crossed that line."
Elias pauses for a second.
The camera zooms in close to his face. His face burns with anger, and he says, "I gave you my word, and I gave you a choice." Note that it doesn't use @ references because I didn't use Omni mode for this video, only subject binding. Here's the result
Here, I tried to create a sitcom scene between friends. I created three characters, Alex, Jamie, and Sam, using AI. As before, I generated a few different poses for each of them.

I also generated an image for the location and created a scene element with it.

This is the final prompt I used. I used a text prompt to describe the shots instead of their multi-shot functionality because that limits the scene to six shots. Turns out Kling 3.0 is fully capable of handling this as well.
Shot 1: Mid-shot, background @Image.
Shot 2: @Jamie and @Sam sit on the couch as @Alex rushes into the coffee shop and says, "I just liked my ex’s photo from 2016."
Shot 3: @Jamie turns to @Alex and says, "How bad?"
Shot 4: @Alex replies, "She’s with the guy she left me for."
Shot 5: Camera focuses on @Sam, and he replies, "Delete it, dude!"
Shot 6: @Alex replies, "I did, but what if she saw?"
Shot 7: @Sam says, "Then act confident, like her wedding photo."
Shot 8: @Jamie laughs, and @Alex says, "I need new friends..."And this was the result:
We can see a few mistakes in the video:
However, despite these, I found the result to be very impressive. The characters feel lively and authentic, and overall, the scene flows quite well.
In this last example, I tried reusing the characters I had created in a different context. The idea was to get a feel for how consistent they remain between videos to see if the idea of creating multiple scenes with the same characters is viable. Because if the characters remain looking and feeling the same way, then I really believe that Kling 3.0 could be used to generate longer-form content.
In this case, I used the multi-shot functionality to describe each shot. Here's the scene configuration:
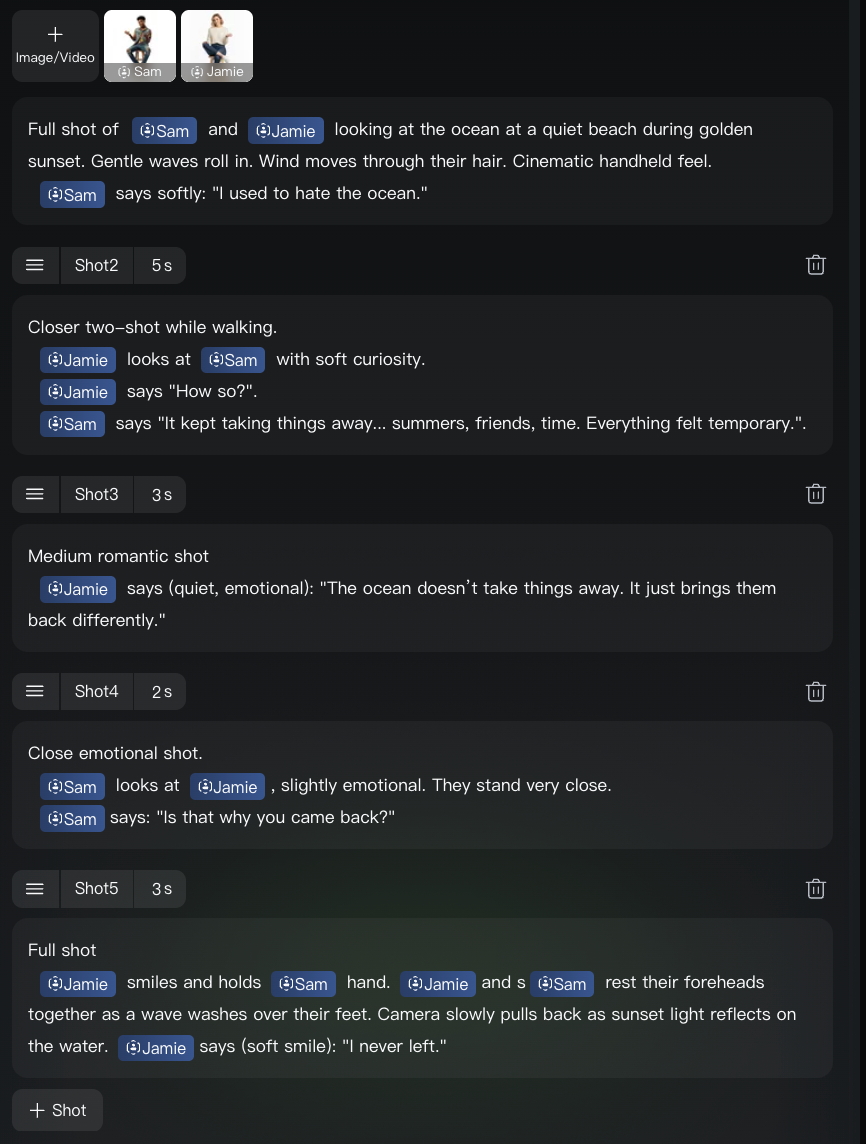
This is the video it generated:
Generative AI Courses
Cours
Cours
Cours
blog
Dr Ana Rojo-Echeburúa
9 min
blog
Abid Ali Awan
9 min
Tutoriel
François Aubry
Tutoriel
François Aubry
Tutoriel
Alex Olteanu
Tutoriel
Bhavishya Pandit

