
Track
AI Fundamentals
10 hr
Despite their impressive trailer, I'm always skeptical that the examples video AI generation companies use to showcase their models are cherry-picked and that reality often doesn't match the hype.
In this article, I’ll teach you how to use Runway 4.5 and show unfiltered examples to see if Runway 4.5 truly delivers on the promise.
Runway 4.5 is a text-to-video AI generation model from Runway ML. While Runway 4 focused on generating videos from images, Runway 4.5 focuses on text prompts. The new model currently doesn't yet support sound, but it should be rolling out soon, according to Runway.
The lack of audio support also means that the sounds in their launch trailer were made externally and not generated by Runway 4.5.
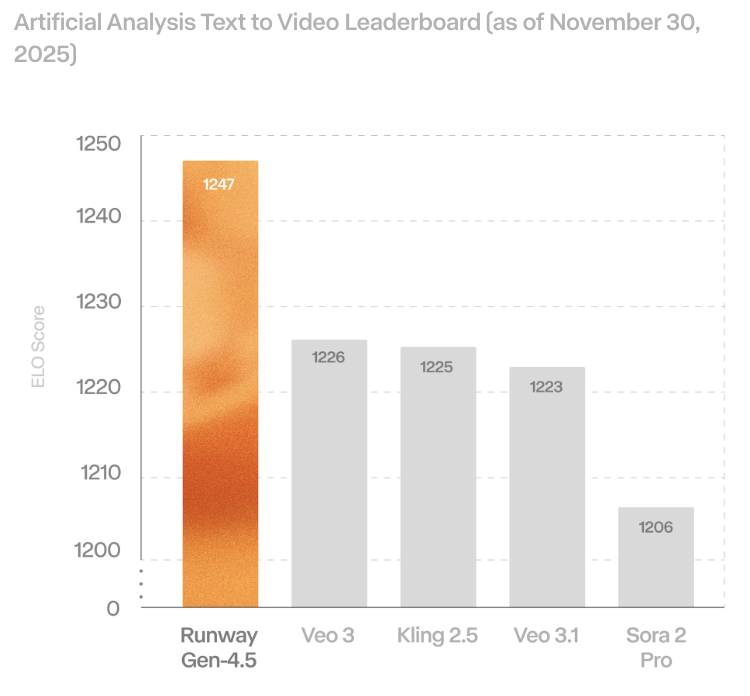
While the new model beats other existing models in text-to-video benchmarks, this feels like a step backward because their previous models had good sound and image support.
From my experience, image support is fundamental to creating a consistent story because even if a model can adhere to a text prompt fully, it would be impossible to maintain character consistency using text alone.
If you're new to Runway, we recommend you check our other articles on Runway ML:
Runway 4.5 is accessible through their web app.
Using it isn't free and requires a subscription. For more details, see their pricing page.
Each second of video generation for Gen 4.5 costs 25 credits. Their cheapest subscription comes with 625 credits, which only allows generating 25 seconds of video.
Let’s check out the new features of Runway Gen 4.5:
In their release article, they claim that Runway 4.5 can adhere to complex prompts with a high degree of accuracy. Namely, it can:
The video below is a compilation of one example for each of these features taken from their official website:
Top DataCamp Courses
Track
Course
Course
blog
Iva Vrtaric
11 min
blog
Dr Ana Rojo-Echeburúa
9 min
blog
Abid Ali Awan
9 min
Tutorial
François Aubry
Tutorial
François Aubry
Tutorial
François Aubry