
Kursus
Konsep Large Language Models (LLM)
2 Hr
104K
Transformer pertama kali dikembangkan untuk menyelesaikan masalah sequence transduction, atau neural machine translation, yang berarti model ini ditujukan untuk menyelesaikan tugas apa pun yang mengubah sebuah urutan masukan menjadi urutan keluaran. Itulah mengapa disebut “Transformer”.
Namun mari mulai dari awal.
Model transformer adalah jaringan saraf yang mempelajari konteks data sekuensial dan menghasilkan data baru darinya.
Secara sederhana:
Transformer adalah jenis model kecerdasan buatan yang belajar memahami dan menghasilkan teks seperti manusia dengan menganalisis pola dalam sejumlah besar data teks.
Transformer adalah model NLP tercanggih saat ini dan dianggap sebagai evolusi arsitektur encoder–decoder. Namun, sementara arsitektur encoder–decoder terutama bergantung pada Recurrent Neural Networks (RNN) untuk mengekstrak informasi sekuensial, Transformer sama sekali tidak memiliki rekursi ini.
Jadi, bagaimana caranya?
Model ini dirancang khusus untuk memahami konteks dan makna dengan menganalisis hubungan antar elemen, dan hampir sepenuhnya bergantung pada teknik matematika yang disebut attention untuk melakukannya.

Gambar oleh penulis.
Berasal dari makalah riset Google tahun 2017, model transformer adalah salah satu perkembangan terbaru dan paling berpengaruh di bidang Machine Learning. Model Transformer pertama dijelaskan dalam makalah berpengaruh "Attention is All You Need".
Konsep perintis ini bukan hanya kemajuan teoretis tetapi juga mendapat implementasi praktis, terutama dalam paket Tensor2Tensor milik TensorFlow. Selain itu, kelompok NLP Harvard berkontribusi pada bidang yang berkembang ini dengan menawarkan panduan beranotasi untuk makalah tersebut, dilengkapi dengan implementasi PyTorch. Anda dapat mempelajari lebih lanjut tentang cara mengimplementasikan Transformer dari nol dalam tutorial terpisah kami.
Pengenalannya memicu lonjakan signifikan di bidang ini, sering disebut sebagai Transformer AI. Model revolusioner ini meletakkan dasar bagi terobosan selanjutnya di ranah model bahasa besar, termasuk BERT. Pada 2018, perkembangan ini sudah dianggap sebagai tonggak penting dalam NLP.
Pada 2020, para peneliti di OpenAI mengumumkan GPT-3. Dalam hitungan minggu, keserbagunaan GPT-3 dengan cepat terbukti ketika orang-orang menggunakannya untuk membuat puisi, program, lagu, situs web, dan lainnya, memikat imajinasi pengguna di seluruh dunia. Mengamati perubahan ini, para sarjana Stanford menerbitkan makalah tahun 2021 yang tepat menyebut inovasi ini sebagai "foundation models," menegaskan peran kritisnya dalam membentuk ulang AI.
Sementara model proprietary menarik perhatian publik lebih awal, revolusi open-source yang berjalan paralel dengan cepat mendemokratisasi teknologi transformer. Platform seperti Hugging Face muncul sebagai pusat penting untuk berbagi model, tetapi lanskap ini berubah secara fundamental pada 2023 dengan rilis keluarga Llama dari Meta. Ini memicu gerakan "open-weights", membuktikan bahwa pengembang tidak lagi harus bergantung pada ekosistem korporat tertutup untuk membangun AI tercanggih.
Sepanjang 2024 dan 2025, pengembangan open-source melaju kencang. Model seperti Llama 3.1 yang masif dari Meta dan seri Llama 4 berikutnya, bersama arsitektur yang sangat efisien dari startup seperti Mistral dan model penalaran kuat dari DeepSeek, membuktikan bahwa model yang tersedia secara terbuka dapat menyamai, dan kadang melampaui, kinerja raksasa proprietary.
Sementara itu, model closed-source terus mengembangkan kapabilitas kompleks. GPT-4 pada 2023 memperkenalkan kemampuan multimodal, dan GPT-4o pada 2024 menyatukan pemrosesan teks, visi, dan audio dalam satu model.
Akhir 2024 menandai poros fundamental lain di industri dengan model seperti seri o1 dari OpenAI dan R1 terbuka dari DeepSeek, memperkenalkan 'chain-of-thought' internal untuk menalar logika dan matematika kompleks sebelum merespons.
Menjelang akhir 2025 dan memasuki 2026, lanskap bergeser sepenuhnya dari asisten percakapan menjadi sistem otonom dengan peluncuran keluarga GPT-5, menghadirkan perencanaan multi-langkah tingkat lanjut, memori jangka panjang, dan alur kerja agen yang andal ke infrastruktur enterprise.
Pada saat pengenalan model Transformer, Recurrent Neural Networks (RNN) adalah pendekatan pilihan untuk menangani data sekuensial, yang dicirikan oleh urutan tertentu pada masukannya.
RNN berfungsi mirip jaringan saraf feed-forward tetapi memproses masukan secara berurutan, satu elemen pada satu waktu.
Transformer terinspirasi oleh arsitektur encoder–decoder pada RNN. Namun, alih-alih menggunakan rekursi, model Transformer sepenuhnya didasarkan pada mekanisme Attention.
Selain meningkatkan kinerja RNN, Transformer menghadirkan arsitektur baru untuk menyelesaikan banyak tugas lain, seperti peringkasan teks, penjelasan gambar, dan pengenalan suara.
Lalu, apa masalah utama RNN? Model ini cukup tidak efektif untuk tugas NLP karena dua alasan utama:
Peralihan dari Recurrent Neural Networks (RNN) seperti LSTM ke Transformer dalam NLP didorong oleh dua masalah utama ini dan kemampuan Transformer mengatasi keduanya dengan memanfaatkan perbaikan mekanisme Attention:
Dengan demikian, Transformer menjadi peningkatan alami dari RNN.
Selanjutnya, mari lihat bagaimana cara kerja transformer.
Awalnya dirancang untuk sequence transduction atau neural machine translation, transformer unggul dalam mengonversi urutan masukan menjadi urutan keluaran. Ini adalah model transduksi pertama yang sepenuhnya mengandalkan self-attention untuk menghitung representasi masukan dan keluarannya tanpa menggunakan RNN yang disejajarkan dengan urutan atau konvolusi. Karakteristik inti utama dari arsitektur Transformer adalah mempertahankan model encoder–decoder.
Jika kita menganggap Transformer untuk penerjemahan bahasa sebagai kotak hitam sederhana, ia akan mengambil sebuah kalimat dalam satu bahasa, misalnya bahasa Inggris, sebagai masukan dan menghasilkan terjemahannya dalam bahasa Inggris.

Gambar oleh penulis.
Jika kita menyelami sedikit, kita melihat bahwa kotak hitam ini terdiri dari dua bagian utama:
Gambar oleh penulis. Struktur global Encoder–Decoder.
Namun, baik encoder maupun decoder sebenarnya berupa tumpukan dengan beberapa lapisan (jumlahnya sama untuk masing-masing). Semua encoder memiliki struktur yang sama, dan masukan masuk ke masing-masing lalu diteruskan ke berikutnya. Semua decoder juga memiliki struktur yang sama dan menerima masukan dari encoder terakhir dan decoder sebelumnya.
Arsitektur asli terdiri dari 6 encoder dan 6 decoder, tetapi kita dapat mereplikasi sebanyak yang kita inginkan. Jadi mari kita asumsikan N lapisan untuk masing-masing.
Gambar oleh penulis. Struktur global Encoder–Decoder. Banyak Lapisan.
Sekarang kita sudah punya gambaran umum arsitektur Transformer, mari fokus pada Encoder dan Decoder untuk lebih memahami alur kerjanya:
Encoder adalah komponen fundamental dari arsitektur Transformer. Fungsi utamanya adalah mengubah token masukan menjadi representasi yang ter-kontekstual. Berbeda dari model sebelumnya yang memproses token secara independen, encoder Transformer menangkap konteks setiap token terhadap seluruh urutan.
Komposisi strukturnya sebagai berikut:
Gambar oleh penulis. Struktur global Encoder.
Mari kita uraikan alur kerjanya menjadi langkah-langkah paling dasar:
Embedding hanya terjadi di encoder paling bawah. Encoder mulai dengan mengonversi token masukan — kata atau subkata — menjadi vektor menggunakan lapisan embedding. Embedding ini menangkap makna semantik token dan mengubahnya menjadi vektor numerik.
Semua encoder menerima daftar vektor, masing-masing berukuran 512 (ukuran tetap). Di encoder terbawah, itu adalah word embeddings, tetapi di encoder lain, itu adalah keluaran dari encoder tepat di bawahnya.
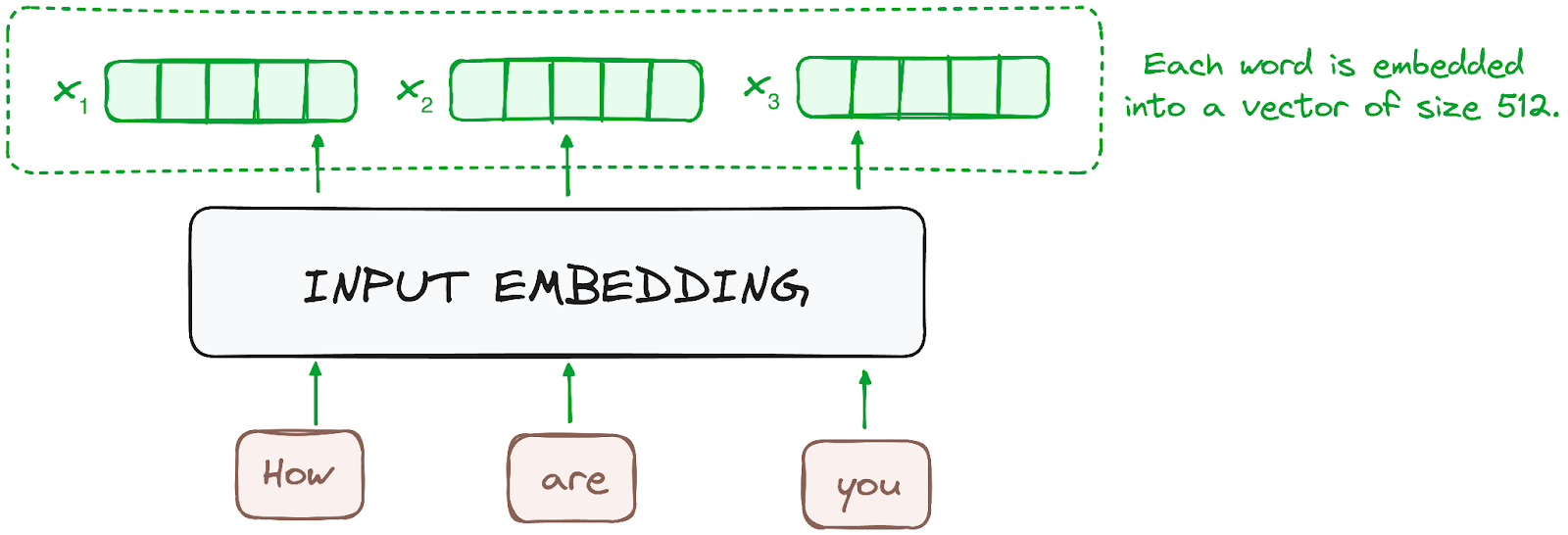
Gambar oleh penulis. Alur kerja Encoder. Input embedding.
Karena Transformer tidak memiliki mekanisme rekursi seperti RNN, model ini menggunakan positional encoding yang ditambahkan ke input embeddings untuk memberikan informasi tentang posisi setiap token dalam urutan. Ini memungkinkan mereka memahami posisi setiap kata dalam kalimat.
Untuk itu, para peneliti menyarankan penggunaan kombinasi berbagai fungsi sinus dan kosinus untuk membuat vektor posisional, sehingga memungkinkan penggunaan positional encoder ini untuk kalimat dengan panjang apa pun.
Dalam pendekatan ini, setiap dimensi direpresentasikan oleh frekuensi dan offset gelombang yang unik, dengan nilai berkisar dari -1 hingga 1, yang secara efektif merepresentasikan setiap posisi.
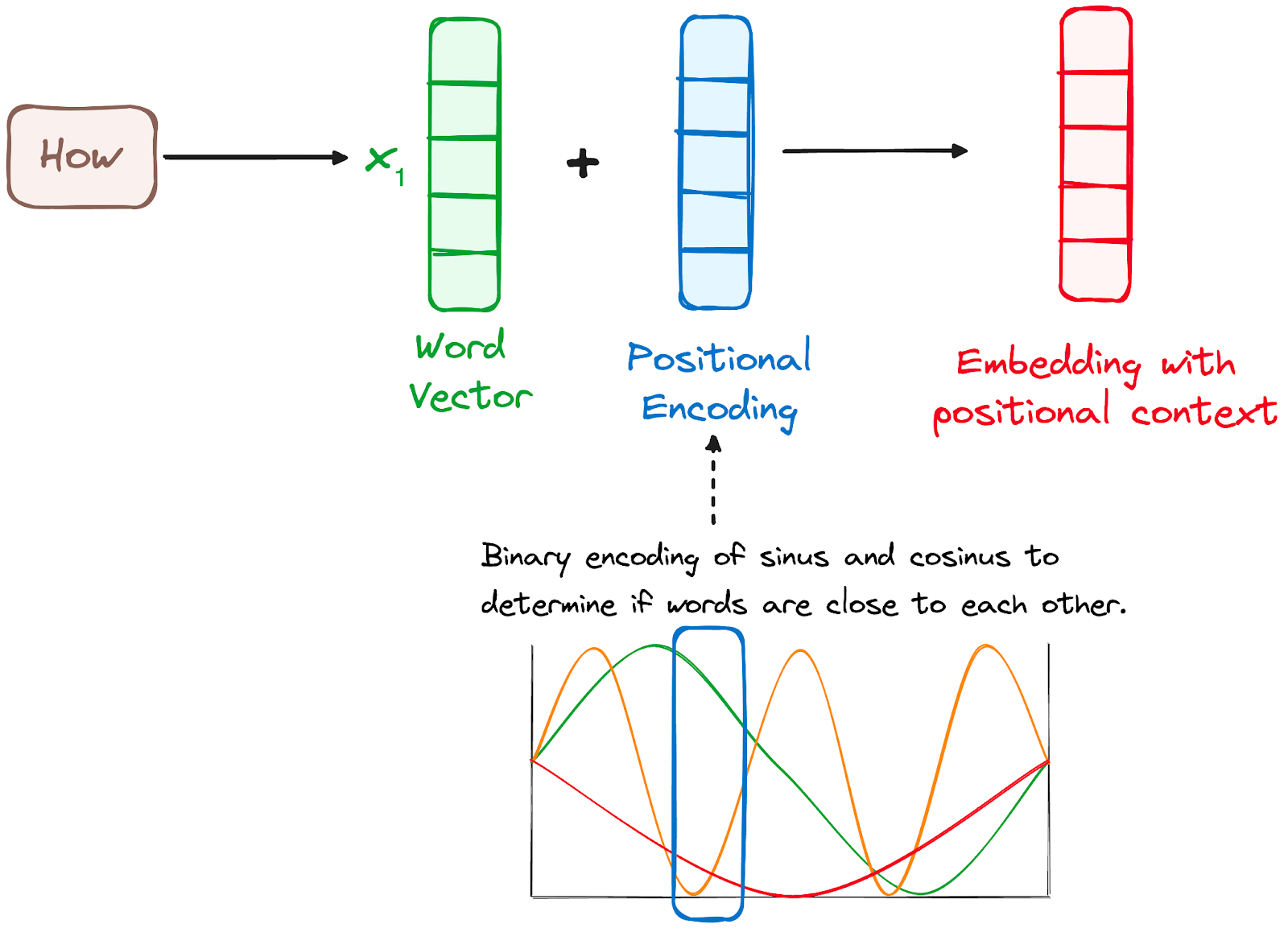
Gambar oleh penulis. Alur kerja Encoder. Positional encoding.
Encoder Transformer terdiri dari tumpukan lapisan identik (6 pada model Transformer asli).
Lapisan encoder berfungsi mengubah semua urutan masukan menjadi representasi kontinu dan abstrak yang merangkum informasi yang dipelajari dari seluruh urutan. Lapisan ini terdiri dari dua submodul:
Selain itu, ia menggabungkan koneksi residual di sekitar setiap sublapisan, yang kemudian diikuti normalisasi lapisan.
Gambar oleh penulis. Alur kerja Encoder. Tumpukan Lapisan Encoder
Di encoder, attention multi-head menggunakan mekanisme attention khusus yang dikenal sebagai self-attention. Pendekatan ini memungkinkan model mengaitkan setiap kata dalam masukan dengan kata-kata lain. Misalnya, dalam contoh tertentu, model mungkin belajar menghubungkan kata “are” dengan “you”.
Mekanisme ini memungkinkan encoder memusatkan perhatian pada bagian berbeda dari urutan masukan saat memproses setiap token. Ia menghitung skor attention berdasarkan:
Modul Self-Attention pertama ini memungkinkan model menangkap informasi kontekstual dari seluruh urutan. Alih-alih melakukan satu fungsi attention, query, key, dan value diproyeksikan secara linear sebanyak h kali. Pada setiap versi terproyeksi dari query, key, dan value ini, mekanisme attention dijalankan secara paralel, menghasilkan keluaran berdimensi h.
Arsitektur terperinci sebagai berikut:
Setelah vektor query, key, dan value melewati lapisan linear, dilakukan perkalian matriks dot product antara query dan key, menghasilkan matriks skor.
Matriks skor menetapkan tingkat penekanan yang harus diberikan setiap kata pada kata-kata lain. Karena itu, setiap kata diberi skor relatif terhadap kata-kata lain dalam langkah waktu yang sama. Skor yang lebih tinggi menunjukkan fokus yang lebih besar.
Proses ini secara efektif memetakan query ke key yang bersesuaian.
Gambar oleh penulis. Alur kerja Encoder. Mekanisme Attention - Perkalian Matriks.
Skor kemudian diskalakan turun dengan membaginya dengan akar kuadrat dari dimensi vektor query dan key. Langkah ini diterapkan untuk memastikan gradien lebih stabil, karena perkalian nilai dapat menyebabkan efek yang terlalu besar.
Gambar oleh penulis. Alur kerja Encoder. Mengurangi skor attention.
Selanjutnya, fungsi softmax diterapkan pada skor yang disesuaikan untuk memperoleh bobot attention. Ini menghasilkan nilai probabilitas antara 0 hingga 1. Fungsi softmax menekankan skor yang lebih tinggi sekaligus mengurangi skor yang lebih rendah, sehingga meningkatkan kemampuan model untuk menentukan kata-kata mana yang harus lebih diperhatikan.
Gambar oleh penulis. Alur kerja Encoder. Skor softmax yang disesuaikan.
Langkah berikutnya dari mekanisme attention adalah mengalikan bobot yang diperoleh dari fungsi softmax dengan vektor value, menghasilkan vektor keluaran.
Dalam proses ini, hanya kata-kata yang memiliki skor softmax tinggi yang dipertahankan. Terakhir, vektor keluaran ini dimasukkan ke lapisan linear untuk pemrosesan lebih lanjut.
Gambar oleh penulis. Alur kerja Encoder. Menggabungkan hasil Softmax dengan vektor value.
Dan akhirnya kita mendapatkan keluaran dari mekanisme Attention!
Lalu, Anda mungkin bertanya mengapa disebut Multi-Head Attention?
Ingat bahwa sebelum semua proses dimulai, kita membagi query, key, dan value kita sebanyak h kali. Proses ini, yang dikenal sebagai self-attention, terjadi secara terpisah di masing-masing tahap kecil atau 'head'. Setiap head bekerja secara independen, menghasilkan sebuah vektor keluaran.
Kumpulan ini melewati lapisan linear akhir, mirip filter yang menyetel kinerja kolektifnya. Keindahannya terletak pada keragaman pembelajaran di tiap head, memperkaya model encoder dengan pemahaman yang kuat dan multifaset.
Untuk pemahaman lebih mendalam tentang mekanisme attention, lihat tutorial kami tentang multi-head attention pada Transformer.
Setiap sublapisan dalam lapisan encoder diikuti langkah normalisasi. Selain itu, keluaran setiap sublapisan dijumlahkan dengan masukannya (koneksi residual) untuk membantu mengurangi masalah vanishing gradient, sehingga memungkinkan model lebih dalam. Proses ini akan diulang setelah Jaringan Saraf Feed-Forward juga.
Gambar oleh penulis. Alur kerja Encoder. Normalisasi dan koneksi residual setelah Multi-Head Attention.
Perjalanan keluaran residual yang telah dinormalisasi berlanjut saat memasuki jaringan feed-forward pointwise, fase krusial untuk pemurnian tambahan.
Bayangkan jaringan ini sebagai duet lapisan linear, dengan aktivasi ReLU di antaranya sebagai jembatan. Setelah diproses, keluarannya menempuh jalur yang familier: kembali dan bergabung dengan masukan jaringan feed-forward pointwise.
Pertemuan kembali ini diikuti putaran normalisasi lainnya, memastikan semuanya tersetel baik dan sinkron untuk langkah-langkah berikutnya.
Gambar oleh penulis. Alur kerja Encoder. Sublapisan Jaringan Saraf Feed-Forward.
Keluaran dari lapisan encoder terakhir adalah sekumpulan vektor, masing-masing merepresentasikan urutan masukan dengan pemahaman kontekstual yang kaya. Keluaran ini kemudian digunakan sebagai masukan bagi decoder dalam model Transformer.
Pengodean yang cermat ini membuka jalan bagi decoder, membimbingnya untuk memperhatikan kata-kata yang tepat pada masukan saat waktunya melakukan decoding.
Pikirkan seperti membangun menara, di mana Anda dapat menumpuk N lapisan encoder. Setiap lapisan dalam tumpukan ini mendapat kesempatan mengeksplorasi dan mempelajari berbagai aspek attention, layaknya lapisan pengetahuan. Ini tidak hanya memperkaya pemahaman tetapi juga dapat secara signifikan meningkatkan kemampuan prediktif jaringan transformer.
Peran decoder berpusat pada penyusunan urutan teks. Mencerminkan encoder, decoder dilengkapi serangkaian sublapisan serupa. Ia memiliki dua lapisan attention multi-head, satu lapisan feed-forward pointwise, dan menggabungkan koneksi residual serta normalisasi lapisan setelah setiap sublapisan.
Gambar oleh penulis. Struktur global Encoder.
Komponen-komponen ini berfungsi mirip dengan lapisan encoder, namun dengan perbedaan: setiap lapisan attention multi-head pada decoder memiliki misi uniknya.
Tahap akhir proses decoder melibatkan lapisan linear, berfungsi sebagai pengklasifikasi, dilengkapi fungsi softmax untuk menghitung probabilitas berbagai kata.
Decoder Transformer memiliki struktur yang dirancang khusus untuk menghasilkan keluaran ini dengan mendekode informasi yang terenkode selangkah demi selangkah.
Penting untuk dicatat bahwa decoder beroperasi secara autoregresif, memulai prosesnya dengan token awal. Ia dengan cerdas menggunakan daftar keluaran yang dihasilkan sebelumnya sebagai masukannya, bersama dengan keluaran dari encoder yang kaya informasi attention dari masukan awal.
Tarian decoding berurutan ini berlanjut hingga decoder mencapai momen penting: menghasilkan token yang menandakan akhir pembuatan keluarannya.
Di garis awal decoder, prosesnya mencerminkan encoder. Di sini, masukan terlebih dahulu melewati lapisan embedding
Setelah embedding, lagi-lagi seperti pada encoder, masukan melewati lapisan positional encoding. Urutan ini dirancang untuk menghasilkan positional embeddings.
Positional embeddings ini kemudian disalurkan ke lapisan attention multi-head pertama pada decoder, di mana skor attention spesifik untuk masukan decoder dihitung dengan saksama.
Decoder terdiri dari tumpukan lapisan identik (6 pada model Transformer asli). Setiap lapisan memiliki tiga subkomponen utama:
Ini mirip mekanisme self-attention pada encoder tetapi dengan perbedaan penting: ia mencegah posisi memperhatikan posisi berikutnya, yang berarti setiap kata dalam urutan tidak dipengaruhi oleh token masa depan.
Misalnya, ketika skor attention untuk kata "are" dihitung, penting agar "are" tidak mengintip "you", yang merupakan kata berikutnya dalam urutan.
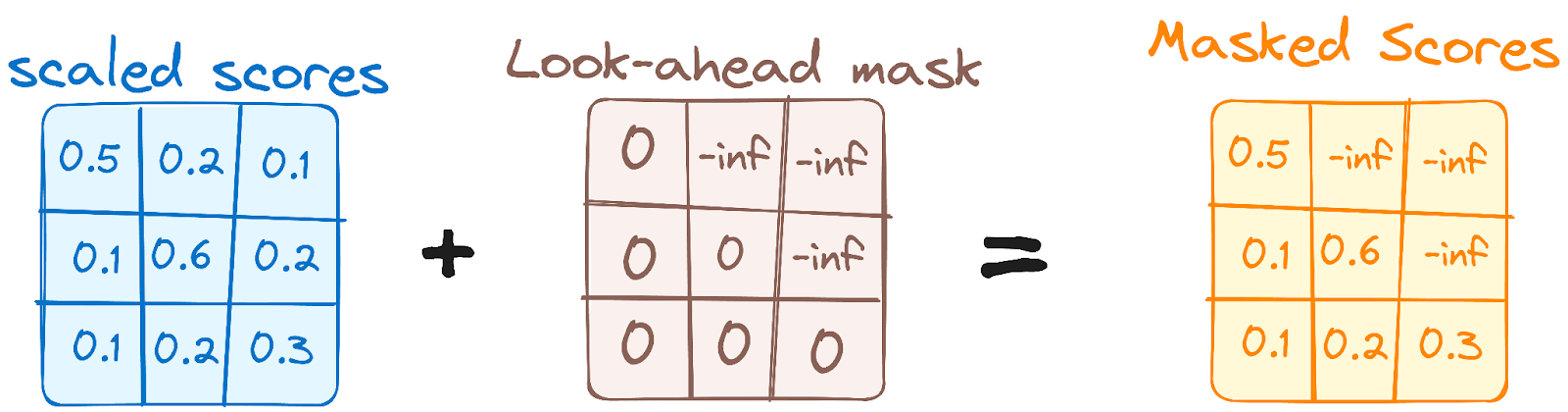
Gambar oleh penulis. Alur kerja Decoder. Masker Multi-Head Attention pertama.
Masking ini memastikan bahwa prediksi untuk posisi tertentu hanya dapat bergantung pada keluaran yang diketahui pada posisi sebelumnya.
Di lapisan attention multi-head kedua pada decoder, kita melihat interaksi unik antara komponen encoder dan decoder. Di sini, keluaran dari encoder berperan sebagai query dan key, sementara keluaran dari lapisan attention multi-head pertama pada decoder berfungsi sebagai value.
Pengaturan ini secara efektif menyelaraskan masukan encoder dengan decoder, memberdayakan decoder untuk mengidentifikasi dan menekankan bagian paling relevan dari masukan encoder.
Setelah itu, keluaran dari lapisan attention multi-head kedua ini kemudian disempurnakan melalui lapisan feed-forward pointwise, lebih meningkatkan pemrosesan.
Gambar oleh penulis. Alur kerja Decoder. Encoder–Decoder Attention.
Dalam sublapisan ini, query berasal dari lapisan decoder sebelumnya, dan key serta value berasal dari keluaran encoder. Ini memungkinkan setiap posisi di decoder untuk memperhatikan semua posisi dalam urutan masukan, secara efektif mengintegrasikan informasi dari encoder dengan informasi di decoder.
Mirip dengan encoder, setiap lapisan decoder mencakup jaringan feed-forward fully connected, diterapkan pada setiap posisi secara terpisah dan identik.
Perjalanan data melalui model transformer berpuncak pada melewati lapisan linear terakhir, yang berfungsi sebagai pengklasifikasi.
Ukuran pengklasifikasi ini sesuai dengan jumlah kelas yang terlibat (jumlah kata dalam kosakata). Misalnya, dalam skenario dengan 1000 kelas berbeda yang merepresentasikan 1000 kata berbeda, keluaran pengklasifikasi akan berupa larik dengan 1000 elemen.
Keluaran ini kemudian dimasukkan ke lapisan softmax, yang mengubahnya menjadi rentang skor probabilitas antara 0 dan 1. Skor probabilitas tertinggi adalah kunci; indeks yang bersesuaian langsung menunjuk pada kata yang diprediksi model sebagai berikutnya dalam urutan.
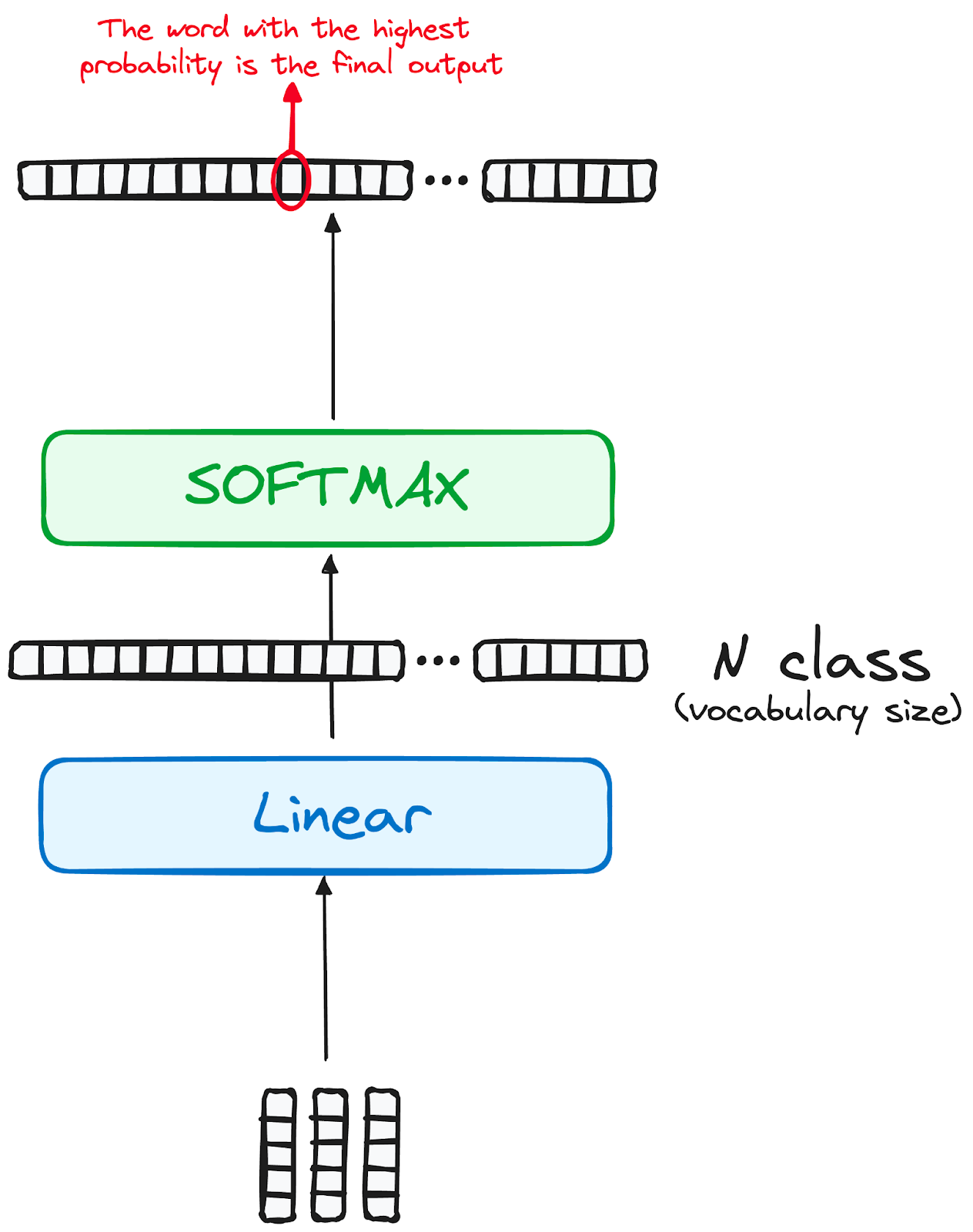
Gambar oleh penulis. Alur kerja Decoder. Keluaran akhir Transformer.
Setiap sublapisan (masked self-attention, encoder–decoder attention, jaringan feed-forward) diikuti langkah normalisasi, dan masing-masing juga menyertakan koneksi residual di sekelilingnya.
Keluaran lapisan terakhir diubah menjadi urutan prediksi, biasanya melalui lapisan linear yang diikuti softmax untuk menghasilkan probabilitas atas kosakata.
Decoder, dalam alur operasionalnya, memasukkan keluaran yang baru dihasilkan ke dalam daftar masukannya yang terus bertambah, lalu melanjutkan proses decoding. Siklus ini berulang hingga model memprediksi token tertentu yang menandakan selesai.
Token yang diprediksi dengan probabilitas tertinggi ditetapkan sebagai kelas penutup, yang sering direpresentasikan oleh end token.
Ingat lagi bahwa decoder tidak terbatas pada satu lapisan. Ia dapat disusun dengan N lapisan, masing-masing membangun di atas masukan yang diterima dari encoder dan lapisan sebelumnya. Arsitektur berlapis ini memungkinkan model mendiversifikasi fokus dan mengekstrak pola attention yang berbeda di seluruh head attention-nya.
Pendekatan berlapis semacam ini dapat secara signifikan meningkatkan kemampuan prediksi model, karena mengembangkan pemahaman yang lebih bernuansa atas berbagai kombinasi attention.
Arsitektur akhirnya terlihat seperti ini (dari makalah asli):
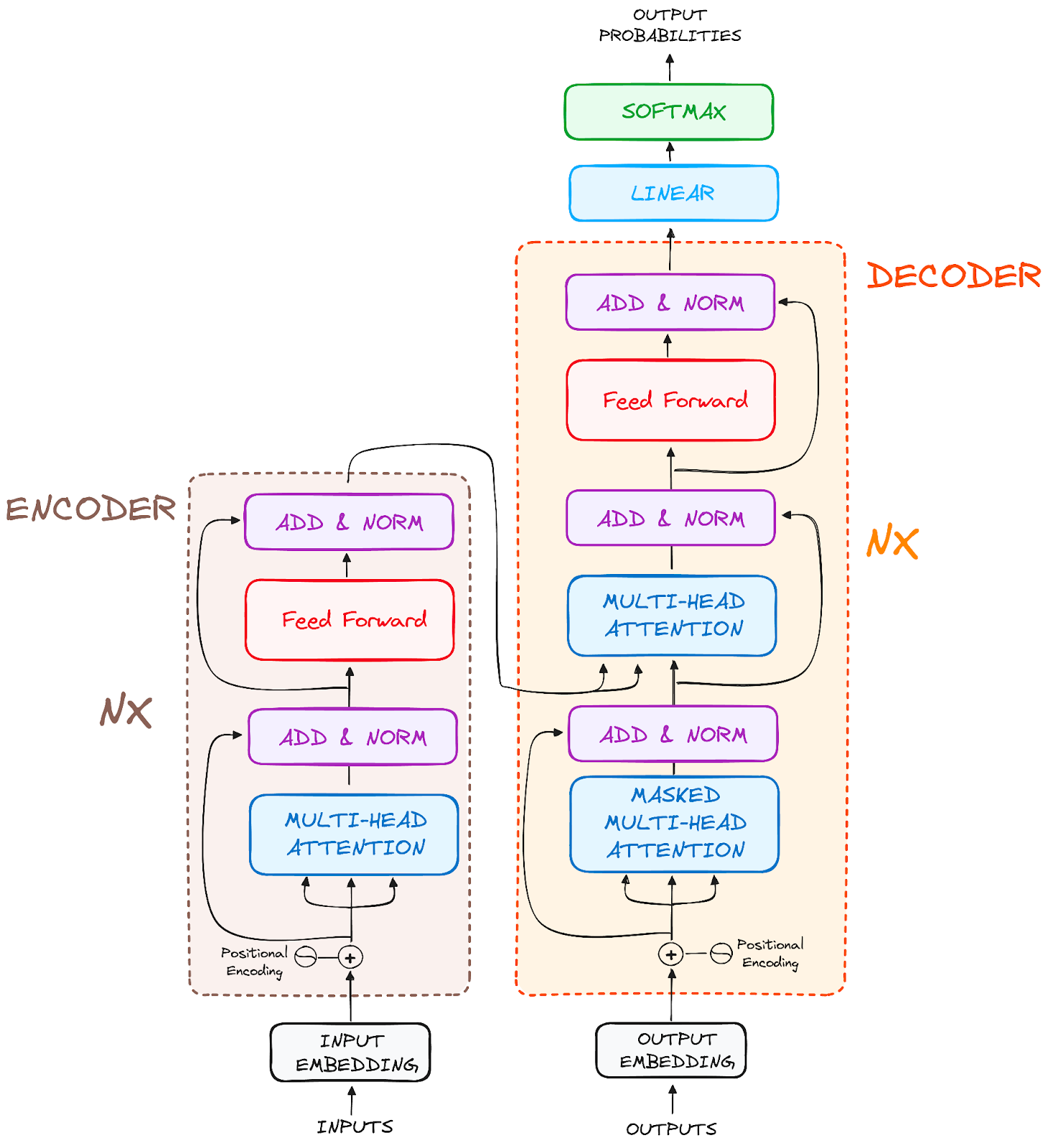
Gambar oleh penulis. Struktur asli Transformer.
Untuk lebih memahami arsitektur ini, saya merekomendasikan mencoba menerapkan Transformer dari nol mengikuti tutorial membangun transformer dengan PyTorch ini.
Rilis BERT oleh Google pada 2018, sebuah kerangka kerja pemrosesan bahasa alami open-source, merevolusi NLP dengan pelatihan bidireksional yang unik, yang memungkinkan model membuat prediksi yang lebih berlandaskan konteks tentang apa kata berikutnya.
Dengan memahami konteks dari segala sisi sebuah kata, BERT mengungguli model sebelumnya dalam tugas seperti tanya–jawab dan memahami bahasa ambigu. Intinya menggunakan Transformer, menghubungkan setiap elemen keluaran dan masukan secara dinamis.
BERT, yang dipra-latih pada Wikipedia, unggul dalam berbagai tugas NLP, mendorong Google untuk mengintegrasikannya ke mesin telusur guna kueri yang lebih natural. Inovasi ini memicu perlombaan mengembangkan model bahasa canggih dan secara signifikan memajukan kemampuan bidang ini dalam menangani pemahaman bahasa yang kompleks.
Untuk mengetahui lebih banyak tentang BERT, Anda dapat melihat artikel terpisah kami yang memperkenalkan model BERT.
LaMDA (Language Model for Dialogue Applications) adalah model berbasis Transformer yang dikembangkan Google, dirancang khusus untuk tugas percakapan, dan diluncurkan selama keynote Google I/O 2021. Model ini dirancang untuk menghasilkan respons yang lebih natural dan relevan secara kontekstual, meningkatkan interaksi pengguna di berbagai aplikasi.
Desain LaMDA memungkinkannya memahami dan merespons berbagai topik dan maksud pengguna, menjadikannya ideal untuk aplikasi chatbot, asisten virtual, dan sistem AI interaktif lain di mana percakapan dinamis adalah kunci.
Fokus pada pemahaman percakapan dan respons ini menjadikan LaMDA sebagai kemajuan signifikan di bidang pemrosesan bahasa alami dan komunikasi berbasis AI.
Jika Anda tertarik untuk memahami lebih jauh model LaMDA, Anda dapat memperoleh pemahaman lebih baik melalui artikel kami tentang LaMDA.
GPT dan ChatGPT, dikembangkan oleh OpenAI, adalah model generatif canggih yang dikenal karena kemampuannya menghasilkan teks yang koheren dan relevan secara kontekstual. GPT-1 adalah model pertama yang diluncurkan pada Juni 2018 dan GPT-3, salah satu model paling berdampak, diluncurkan dua tahun kemudian pada 2020.
Model-model ini andal dalam berbagai tugas, termasuk pembuatan konten, percakapan, penerjemahan bahasa, dan lainnya. Arsitektur GPT memungkinkannya menghasilkan teks yang sangat mirip tulisan manusia, menjadikannya berguna dalam aplikasi seperti penulisan kreatif, dukungan pelanggan, dan bahkan bantuan pengkodean. ChatGPT, varian yang dioptimalkan untuk konteks percakapan, unggul dalam menghasilkan dialog yang menyerupai manusia, meningkatkan penerapannya pada chatbot dan asisten virtual.
Claude, dikembangkan oleh Anthropic, adalah keluarga asisten AI berbasis Transformer yang dirancang dengan fokus pada keamanan dan kebermanfaatan. Claude menggunakan Constitutional AI (CAI), pendekatan pelatihan di mana model dipandu oleh seperangkat prinsip agar menghasilkan respons yang bermanfaat, tidak berbahaya, dan jujur.
Claude 3 (dirilis 2024) memperkenalkan tiga tingkatan model, Haiku, Sonnet, dan Opus, yang menawarkan kompromi berbeda antara kecepatan dan kapabilitas. Model-model ini unggul dalam penalaran yang bernuansa, mengikuti instruksi kompleks, dan mempertahankan konteks dalam percakapan panjang (hingga 200K token).
Pada 2025 dan 2026, Anthropic meluncurkan model Claude 4, dengan yang terbaru, Opus 4.6 dan Sonnet 4.6, memuncaki banyak tolok ukur LLM.
Lanskap foundation model, khususnya model transformer, berkembang pesat. Sebuah studi mengidentifikasi lebih dari 50 model transformer signifikan, sementara kelompok Stanford mengevaluasi 30 di antaranya, mengakui pertumbuhan cepat bidang ini. NLP Cloud, startup inovatif bagian dari program Inception NVIDIA, memanfaatkan sekitar 25 model bahasa besar secara komersial untuk berbagai sektor seperti maskapai dan apotek.
Ada tren yang meningkat untuk membuat model-model ini menjadi open-source, dengan platform seperti model hub Hugging Face memimpin jalan. Selain itu, banyak model berbasis Transformer telah dikembangkan, masing-masing terspesialisasi untuk tugas NLP yang berbeda, menunjukkan keserbagunaan dan efisiensi model dalam aplikasi yang beragam.
Anda dapat mempelajari lebih lanjut semua Foundation Model yang ada dalam artikel terpisah, yang membahas apa itu dan mana yang paling banyak digunakan.
Sejak arsitektur awal 2017, Transformer telah berkembang pesat untuk mengatasi keterbatasan dan memperluas ke domain baru.
Vision Transformers menerapkan mekanisme self-attention pada gambar dengan membaginya menjadi patch dan memperlakukan setiap patch sebagai token. Pendekatan ini terbukti sangat efektif untuk klasifikasi gambar, deteksi objek, dan pembuatan gambar, sering melampaui CNN tradisional pada dataset besar.
Model modern seperti GPT-5, Gemini 3, dan Llama 4 memproses banyak jenis masukan (teks, gambar, audio, video) dalam satu arsitektur. Transformer multimodal ini menggunakan ruang embedding terpadu dan mekanisme cross-attention untuk menalar lintas berbagai modalitas secara simultan.
Kompleksitas kuadratik self-attention membatasi panjang konteks. Beberapa inovasi mengatasinya:
Membuat tolok ukur dan mengevaluasi kinerja model Transformer dalam NLP melibatkan pendekatan sistematis untuk menilai efektivitas dan efisiensinya.
Bergantung pada sifat tugas, ada berbagai cara dan sumber daya untuk melakukannya:
Saat menangani tugas Penerjemahan Mesin, Anda dapat memanfaatkan dataset standar seperti WMT (Workshop on Machine Translation) di mana sistem MT menghadapi hamparan pasangan bahasa, masing-masing menawarkan tantangan unik.
Metrik seperti BLEU, METEOR, TER, dan chrF berperan sebagai alat navigasi, menuntun kita menuju akurasi dan kefasihan.
Selain itu, pengujian di berbagai domain seperti berita, sastra, dan teks teknis memastikan kemampuan adaptasi dan keserbagunaan sistem MT, menjadikannya benar-benar poliglot di dunia digital.
Untuk mengevaluasi model QA, kita menggunakan kumpulan khusus pertanyaan dan jawaban, seperti SQuAD (Stanford Question Answering Dataset), Natural Questions, atau TriviaQA.
Masing-masing seperti permainan berbeda dengan aturannya sendiri. Misalnya, SQuAD tentang menemukan jawaban dalam teks yang diberikan, sementara yang lain lebih seperti kuis dengan pertanyaan dari mana saja.
Untuk melihat seberapa baik kinerja program ini, kita menggunakan skor seperti Precision, Recall, F1, dan terkadang bahkan skor exact match.
Saat menangani Natural Language Inference (NLI), kita menggunakan dataset khusus seperti SNLI (Stanford Natural Language Inference), MultiNLI, dan ANLI.
Ini seperti perpustakaan besar variasi bahasa dan kasus-kasus rumit, membantu kita melihat seberapa baik komputer memahami berbagai jenis kalimat. Kita terutama memeriksa seberapa akurat komputer dalam memahami apakah pernyataan saling menyetujui, bertentangan, atau tidak terkait.
Penting juga meninjau bagaimana komputer memahami hal-hal bahasa yang rumit, seperti ketika sebuah kata merujuk pada sesuatu yang disebutkan sebelumnya, atau memahami 'tidak', 'semua', dan 'sebagian'.
Di dunia Jaringan Saraf, dua struktur menonjol biasanya dibandingkan dengan Transformer. Masing-masing menawarkan manfaat dan tantangan berbeda, disesuaikan untuk jenis pemrosesan data tertentu. RNN, yang telah muncul berkali-kali sepanjang artikel ini, dan Lapisan Konvolusional.
Lapisan Rekuren, pilar Recurrent Neural Networks (RNN), unggul dalam menangani data sekuensial. Kekuatan arsitektur ini terletak pada kemampuannya melakukan operasi berurutan, krusial untuk tugas seperti pemrosesan bahasa atau analisis deret waktu. Dalam Lapisan Rekuren, keluaran dari langkah sebelumnya dimasukkan kembali ke jaringan sebagai masukan untuk langkah berikutnya. Mekanisme berulang ini memungkinkan jaringan mengingat informasi sebelumnya, yang vital dalam memahami konteks dalam urutan.
Namun, seperti yang telah kita bahas, pemrosesan berurutan ini memiliki dua implikasi utama:
Model Transformer berbeda secara signifikan dari arsitektur yang menggunakan lapisan rekuren karena tidak memiliki rekursi. Seperti yang telah kita lihat, lapisan Attention pada Transformer mengatasi kedua masalah tersebut, menjadikannya evolusi alami RNN untuk aplikasi NLP.
Di sisi lain, Lapisan Konvolusional, blok pembangun Convolutional Neural Networks (CNN), terkenal karena efisien memproses data spasial seperti gambar.
Lapisan ini menggunakan kernel (filter) yang memindai data masukan untuk mengekstrak fitur. Lebar kernel ini dapat disesuaikan, memungkinkan jaringan fokus pada fitur kecil atau besar, tergantung tugasnya.
Walau Lapisan Konvolusional sangat baik dalam menangkap hierarki dan pola spasial dalam data, lapisan ini menghadapi tantangan dengan ketergantungan jangka panjang. Lapisan ini tidak secara inheren memperhitungkan informasi sekuensial, sehingga kurang cocok untuk tugas yang memerlukan pemahaman urutan atau konteks suatu sekuens.
Inilah mengapa CNN dan Transformer disesuaikan untuk jenis data dan tugas yang berbeda. CNN mendominasi bidang computer vision karena efisien memproses informasi spasial, sementara Transformer menjadi pilihan utama untuk tugas sekuensial yang kompleks, khususnya di NLP, karena kemampuannya memahami ketergantungan jarak jauh.
Terlepas dari keberhasilannya, Transformer memiliki keterbatasan yang perlu dicatat:
Riset terus mengatasi keterbatasan ini melalui inovasi arsitektural seperti Flash Attention, mixture-of-experts, dan retrieval-augmented generation (RAG).
Sebagai penutup, Transformer telah muncul sebagai terobosan monumental dalam kecerdasan buatan dan pemrosesan bahasa alami (NLP).
Dengan secara efektif mengelola data sekuensial melalui mekanisme self-attention yang unik, model-model ini mengungguli RNN tradisional. Kemampuannya menangani sekuens panjang lebih efisien dan memparalelkan pemrosesan data secara signifikan mempercepat pelatihan.
Model perintis seperti BERT dari Google dan seri GPT dari OpenAI menjadi contoh dampak transformatif Transformer dalam meningkatkan mesin telusur dan menghasilkan teks mirip manusia.
Akibatnya, Transformer menjadi tak tergantikan dalam pembelajaran mesin modern, mendorong batas AI ke depan dan membuka peluang baru dalam kemajuan teknologi.
Jika Anda ingin menyelami Transformer dan penggunaannya secara praktis, artikel kami tentang Transformer dan Hugging Face adalah titik awal yang tepat! Anda juga dapat belajar membangun Transformer dengan PyTorch melalui panduan mendalam kami.
Pelajari Lebih Lanjut tentang Transformer dan LLM!
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Javier Canales Luna
14 mnt
