
Kurs
Large Language Models (LLMs) Kavramları
2 sa
104K
Transformer'lar ilk olarak dizi dönüştürme (sequence transduction) ya da sinirsel makine çevirisi sorununu çözmek için geliştirildi; yani bir girdi dizisini çıktı dizisine dönüştüren her türlü görevi çözmek üzere tasarlandılar. Bu yüzden “Transformer” olarak adlandırılırlar.
Ama en baştan başlayalım.
Bir transformer modeli, ardışık verinin bağlamını öğrenen ve bundan yeni veri üretebilen bir sinir ağıdır.
Basitçe söylemek gerekirse:
Transformer, büyük miktarda metin verisindeki kalıpları analiz ederek insan benzeri metni anlamayı ve üretmeyi öğrenen bir yapay zekâ model türüdür.
Transformer'lar güncel en gelişmiş NLP modelidir ve kodlayıcı-çözücü mimarisinin evrimi olarak kabul edilir. Ancak kodlayıcı-çözücü mimarisi ardışıklık bilgisini çıkarmak için ağırlıkla Tekrarlayan Sinir Ağlarına (RNN) dayanırken, Transformer'larda bu yineleme tamamen yoktur.
Peki, bunu nasıl başarıyorlar?
Özellikle, farklı öğeler arasındaki ilişkiyi analiz ederek bağlam ve anlamı kavrayacak şekilde tasarlanmışlardır; bunu yapmak için de neredeyse tamamen dikkat (attention) adı verilen matematiksel bir tekniğe dayanırlar.

Görsel: yazar.
Kökeni 2017'de Google'ın bir araştırma makalesine dayanan transformer modelleri, Makine Öğrenimi alanındaki en yeni ve etkili gelişmelerden biridir. İlk Transformer modeli, etkili "Attention is All You Need" makalesinde açıklandı.
Bu öncü fikir sadece kuramsal bir ilerleme değildi; özellikle TensorFlow'un Tensor2Tensor paketinde pratik karşılık buldu. Ayrıca Harvard NLP grubu, bir PyTorch uygulamasıyla desteklenen açıklamalı bir rehber sunarak bu gelişen alana katkıda bulundu. Sıfırdan bir Transformer'ı nasıl uygularsınız başlıklı ayrı eğitimimizde daha fazlasını öğrenebilirsiniz.
Tanıtımları, sıklıkla Transformer AI olarak anılan alanda büyük bir sıçramayı tetikledi. Bu devrimci model, BERT dâhil olmak üzere büyük dil modelleri alanındaki sonraki atılımların temelini attı. 2018'e gelindiğinde, bu gelişmeler NLP'de dönüm noktası olarak görülüyordu.
2020'de OpenAI araştırmacıları GPT-3'ü duyurdu. Haftalar içinde GPT-3'ün çok yönlülüğü, insanların şiirler, programlar, şarkılar, web siteleri ve daha fazlasını üretmesiyle hızla sergilendi ve dünya çapında kullanıcıların hayal gücünü cezbetti. Bu değişimi gözlemleyen Stanford araştırmacıları, 2021'de yayımladıkları bir makalede bu yenilikleri "temel modeller" olarak adlandırarak, yapay zekâyı yeniden şekillendirmedeki kritik rollerini vurguladı.
İlk dönemde tescilli modeller kamuoyunun ilgisini çekerken, buna paralel açık kaynak devrimi transformer teknolojisini hızla demokratikleştirdi. Hugging Face gibi platformlar, modellerin paylaşımı için kritik merkezler olarak ortaya çıktı ancak manzara, 2023'te Meta'nın Llama ailesinin yayımlanmasıyla kökten değişti. Bu durum, geliştiricilerin en gelişmiş yapay zekâyı oluşturmak için kapalı kurumsal ekosistemlere bağımlı olmak zorunda olmadığını kanıtlayan bir “açık ağırlıklar” hareketini tetikledi.
2024 ve 2025 boyunca açık kaynak geliştirme şiddetle hızlandı. Meta'nın devasa Llama 3.1'i ve onu izleyen Llama 4 serisi, Mistral gibi girişimlerin son derece verimli mimarileri ve DeepSeek'in güçlü akıl yürütme modelleri, açıkça erişilebilir modellerin tescilli devlerle eşleşebildiğini, hatta bazen onları aştığını kanıtladı.
Bu arada kapalı kaynak modeller karmaşık yetenekler geliştirmeye devam etti. 2023'te çok kipli yetenekler getiren GPT-4 ve metin, görme ve ses işlemesini tek bir modelde birleştiren 2024'te GPT-4o.
2024'ün sonları, OpenAI'nin o1 serisi ve DeepSeek'in açık R1'i gibi modellerle sektörde başka bir temel dönüşümü işaretledi; yanıtlamadan önce karmaşık mantık ve matematiği çözmek için dahili bir “düşünce zinciri” yaklaşımı getirdiler.
2025 sonu ve 2026'ya gelindiğinde, GPT-5 ailesinin piyasaya sürülmesiyle manzara, sohbet asistanlarından otonom sistemlere tamamen kaydı; çok adımlı planlama, uzun süreli bellek ve kurumsal altyapıya sağlam aracısal iş akışları getirdi.
Transformer modelinin tanıtıldığı dönemde, girdi içinde belirli bir sırayla karakterize edilen ardışık verilerle uğraşmak için Tekrarlayan Sinir Ağları (RNN) tercih edilen yaklaşımdı.
RNN'ler ileri beslemeli bir sinir ağına benzer şekilde çalışır ancak girdiyi ardışık olarak, öğe öğe işler.
Transformer'lar RNN'lerde bulunan kodlayıcı-çözücü mimarisinden esinlenmiştir. Ancak yineleme kullanmak yerine, Transformer modeli bütünüyle Dikkat mekanizmasına dayanır.
RNN performansını iyileştirmenin ötesinde, Transformer'lar metin özetleme, görsel açıklama üretimi ve konuşma tanıma gibi pek çok görevi çözmek için yeni bir mimari sunmuştur.
Peki RNN'lerin temel sorunları nedir? NLP görevlerinde iki ana nedenle oldukça etkisiz kalırlar:
LSTM gibi Tekrarlayan Sinir Ağlarından (RNN) NLP'de Transformer'lara geçiş, bu iki ana sorun ve Transformer'ların Dikkat mekanizmasındaki iyileştirmelerden yararlanarak ikisini de ele alma becerisiyle tetiklenmiştir:
Böylece Transformer'lar, RNN'lerin doğal bir evrimi hâline gelmiştir.
Şimdi sırada transformer'ların nasıl çalıştığına bakmak var.
Aslen dizi dönüştürme ya da sinirsel makine çevirisi için tasarlanan transformer'lar, girdi dizilerini çıktı dizilerine dönüştürmede ustadır. Girdi ve çıktının temsillerini, diziye hizalı RNN ya da evrişimi kullanmadan, bütünüyle kendi-kendine dikkatle hesaplayan ilk dönüştürücü modeldir. Transformer mimarisinin temel özelliği, kodlayıcı-çözücü modelini korumasıdır.
Transformer'ı dil çevirisi için basit bir siyah kutu olarak düşünürsek, örneğin İngilizce bir cümleyi girdi olarak alır ve çıktıda onun çevirisini verir.

Görsel: yazar.
Biraz derine indiğimizde, bu siyah kutunun iki ana bölümden oluştuğunu görürüz:
Görsel: yazar. Kodlayıcı-Çözücü genel yapısı.
Ancak hem kodlayıcı hem çözücü aslında çok katmandan oluşan bir yığındır (her biri için aynı sayıda). Tüm kodlayıcılar aynı yapıyı sunar; girdi her birine girer ve bir sonrakine aktarılır. Tüm çözücüler de aynı yapıyı sunar ve girdiyi son kodlayıcıdan ve bir önceki çözücüden alır.
Özgün mimari 6 kodlayıcı ve 6 çözücüden oluşuyordu, ancak dilediğimiz kadar katman çoğaltabiliriz. Öyleyse her birinden N katman varsayalım.
Görsel: yazar. Kodlayıcı-Çözücü genel yapısı. Çoklu katmanlar.
Artık genel mimariye dair bir fikrimiz olduğuna göre, iş akışlarını daha iyi anlamak için Kodlayıcılar ve Çözücülere ayrı ayrı odaklanalım:
Kodlayıcı, Transformer mimarisinin temel bir bileşenidir. Birincil işlevi, girdi belirteçlerini (token) bağlamsallaştırılmış temsillere dönüştürmektir. Önceki modellerden farklı olarak, Transformer kodlayıcı her belirtecin bağlamını tüm diziye göre yakalar.
Yapısal bileşimi şu şekildedir:
Görsel: yazar. Kodlayıcıların genel yapısı.
İş akışını en temel adımlarına ayıralım:
Gömme işlemi yalnızca en alttaki kodlayıcıda gerçekleşir. Kodlayıcı, girdi belirteçlerini —kelimeler veya alt kelimeler— gömme katmanları kullanarak vektörlere dönüştürerek başlar. Bu gömmeler, belirteçlerin anlamsal bilgisini yakalar ve onları sayısal vektörlere çevirir.
Tüm kodlayıcılar, her biri 512 boyutunda (sabit boyutlu) vektörlerden oluşan bir liste alır. En alt kodlayıcıda bunlar sözcük gömmeleri olur; diğer kodlayıcılarda ise doğrudan altındaki kodlayıcının çıktısıdır.
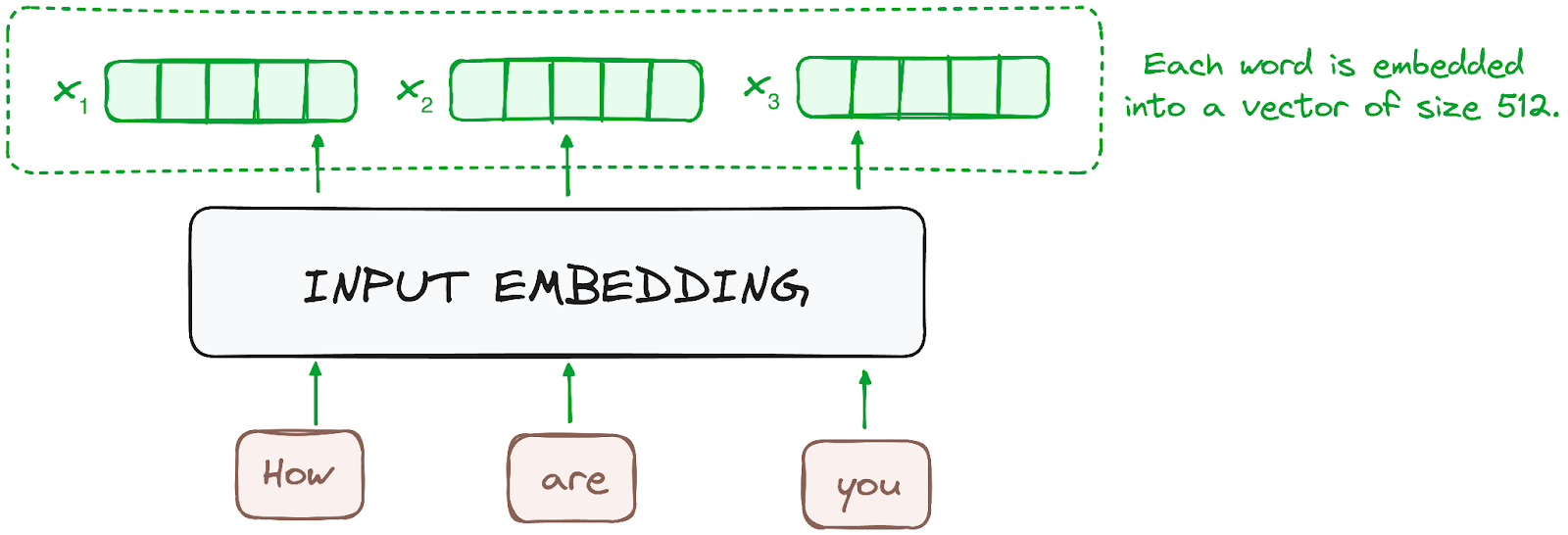
Görsel: yazar. Kodlayıcı iş akışı. Girdi gömme.
Transformer'larda RNN'ler gibi yineleme mekanizması olmadığından, her belirtecin dizideki konumu hakkında bilgi sağlamak için girdi gömmelerine eklenen konumsal kodlamalar kullanılır. Bu, cümledeki her kelimenin yerini anlamalarını sağlar.
Bunu yapmak için araştırmacılar, çeşitli sinüs ve kosinüs işlevlerinin bir kombinasyonunu kullanarak konumsal vektörler oluşturmayı önerdi; bu sayede bu konumsal kodlayıcı, herhangi bir uzunluktaki cümlelerde kullanılabilir.
Bu yaklaşımda, her boyut dalganın benzersiz frekansları ve ötelemeleriyle temsil edilir; değerler -1 ile 1 arasında değişir ve her konumu etkili şekilde temsil eder.
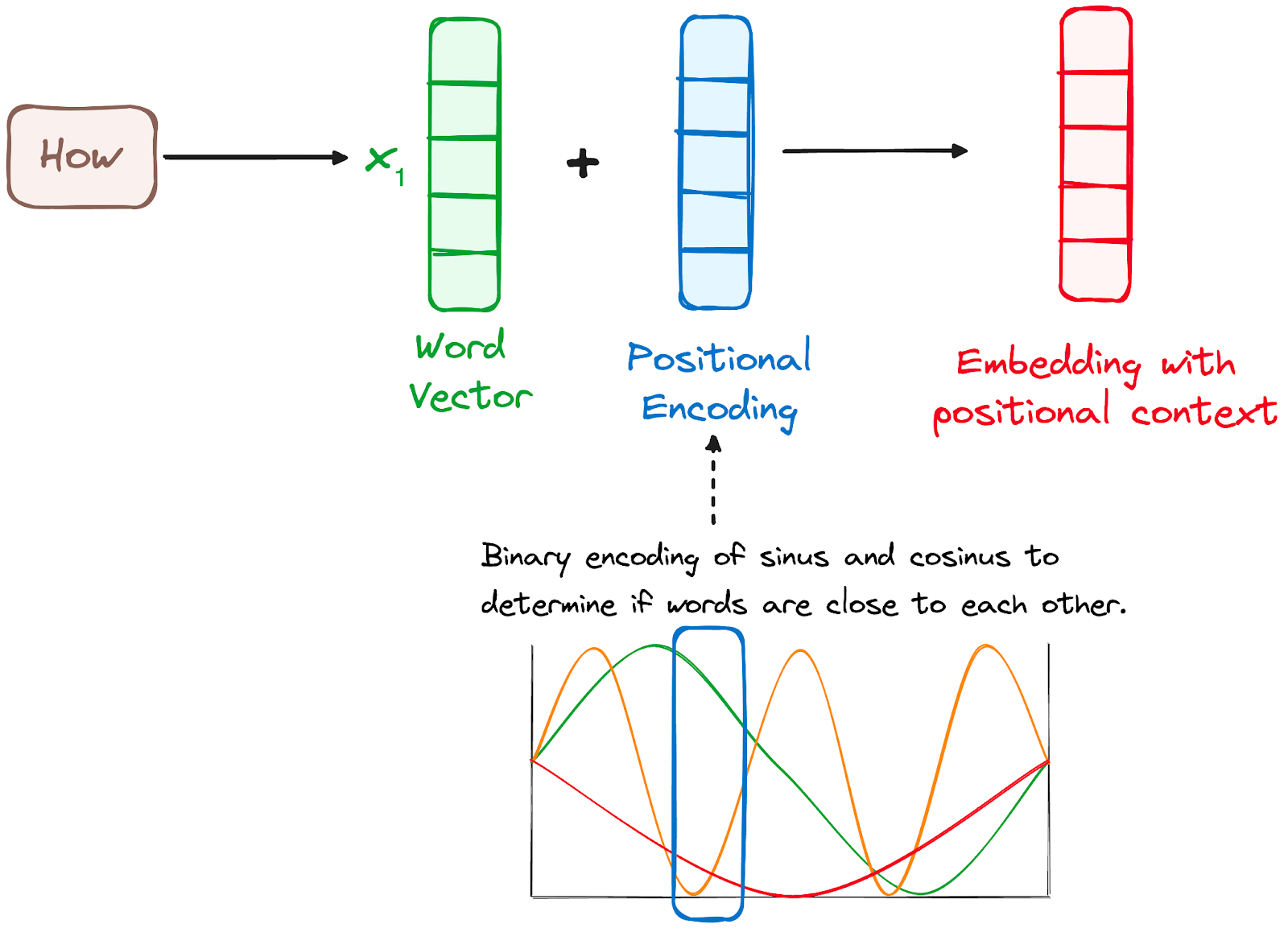
Görsel: yazar. Kodlayıcı iş akışı. Konumsal kodlama.
Transformer kodlayıcı, özdeş katmanların bir yığınından oluşur (özgün modelde 6).
Kodlayıcı katmanı, tüm girdi dizilerini, tüm diziden öğrenilen bilgiyi kapsayan, sürekli ve soyut bir temsile dönüştürmeye hizmet eder. Bu katman iki alt modülden oluşur:
Ek olarak, her alt katmanın etrafında artık bağlantılar bulunur ve bunları katman normalizasyonu izler.
Görsel: yazar. Kodlayıcı iş akışı. Kodlayıcı Katmanları Yığını
Kodlayıcıda çok başlıklı dikkat, kendi-kendine dikkat adı verilen özel bir dikkat mekanizması kullanır. Bu yaklaşım, modellerin girdideki her kelimeyi diğer kelimelerle ilişkilendirmesine imkân tanır. Örneğin, bir örnekte model “are” kelimesini “you” ile ilişkilendirmeyi öğrenebilir.
Bu mekanizma, kodlayıcının her belirteci işlerken girdi dizisinin farklı kısımlarına odaklanmasını sağlar. Aşağıdakilere dayalı dikkat puanları hesaplanır:
Bu ilk Kendi-Kendine Dikkat modülü, modelin tüm diziden bağlamsal bilgi yakalamasını sağlar. Tek bir dikkat fonksiyonu uygulamak yerine, sorgular, anahtarlar ve değerler doğrusal olarak h kez izdüşürülür. Bu izdüşürülmüş sürümlerin her birinde dikkat mekanizması paralel yürütülür ve h boyutlu çıktı değerleri elde edilir.
Ayrıntılı mimari şu şekildedir:
Sorgu, anahtar ve değer vektörleri doğrusal bir katmandan geçirildikten sonra, sorgular ile anahtarlar arasında noktasal çarpım matris çarpımı yapılır ve bir puan matrisi oluşturulur.
Puan matrisi, her kelimenin diğer kelimelere ne ölçüde vurgu yapması gerektiğini belirler. Dolayısıyla her kelimeye, aynı zaman adımındaki diğer kelimelere göre bir puan atanır. Yüksek puan daha büyük odaklanma demektir.
Bu süreç, sorguların karşılık gelen anahtarlara eşlenmesini etkili şekilde sağlar.
Görsel: yazar. Kodlayıcı iş akışı. Dikkat mekanizması - Matris Çarpımı.
Puanlar, sorgu ve anahtar vektörlerinin boyutunun kareköküne bölünerek aşağı ölçeklenir. Bu adım, değerlerin çarpımının aşırı büyük etkilere yol açabilmesi nedeniyle, gradyanların daha kararlı olmasını sağlamak için uygulanır.
Görsel: yazar. Kodlayıcı iş akışı. Dikkat puanlarını azaltma.
Ardından, ayarlanmış puanlara softmax fonksiyonu uygulanarak dikkat ağırlıkları elde edilir. Bu, 0 ile 1 arasında olasılık değerleri üretir. Softmax fonksiyonu, yüksek puanları vurgulayıp düşük puanları bastırarak modelin hangi kelimelere daha fazla dikkat etmesi gerektiğini daha etkili biçimde belirlemesini sağlar.
Görsel: yazar. Kodlayıcı iş akışı. Softmax ile ayarlanmış puanlar.
Dikkat mekanizmasının bir sonraki adımı, softmax'ten elde edilen ağırlıkların değer vektörü ile çarpılması ve bir çıktı vektörü elde edilmesidir.
Bu süreçte yalnızca softmax puanı yüksek olan kelimeler korunur. Son olarak, bu çıktı vektörü daha ileri işleme için doğrusal bir katmana verilir.
Görsel: yazar. Kodlayıcı iş akışı. Softmax sonuçlarını değer vektörü ile birleştirme.
Ve nihayet Dikkat mekanizmasının çıktısını elde ederiz!
Peki neden Çok Başlıklı Dikkat olarak adlandırılıyor diye merak ediyor olabilirsiniz?
Tüm süreç başlamadan önce sorgularımızı, anahtarlarımızı ve değerlerimizi h kez böldüğümüzü unutmayın. Kendi-kendine dikkat olarak bilinen bu süreç, bu daha küçük aşamaların ya da “başların” her birinde ayrı ayrı gerçekleşir. Her baş bağımsız çalışır ve bir çıktı vektörü üretir.
Bu topluluk, son bir doğrusal katmandan geçer; adeta toplu performansı ince ayar yapan bir filtredir. Güzellik, her baştaki öğrenmenin çeşitliliğinde yatar; bu da kodlayıcı modele zengin ve çok yönlü bir anlayış kazandırır.
Dikkat mekanizmasını daha derinlemesine anlamak için Transformer'larda çok başlıklı dikkat eğitimimize bakın.
Bir kodlayıcı katmanındaki her alt katmanı bir normalizasyon adımı izler. Ayrıca her alt katman çıktısı, daha derin modelleri mümkün kılan sönümlenen gradyan sorununu hafifletmeye yardımcı olmak için girdisine eklenir (artık bağlantı). Bu süreç, İleri Beslemeli Sinir Ağı'ndan sonra da tekrar edilir.
Görsel: yazar. Kodlayıcı iş akışı. Çok Başlıklı Dikkat sonrası normalizasyon ve artık bağlantı.
Normalize edilmiş artık çıktının yolculuğu, noktasal (pointwise) bir ileri beslemeli ağdan geçerek devam eder; bu, ek iyileştirme için kritik bir aşamadır.
Bu ağı, arasına köprü gibi yerleşmiş bir ReLU etkinleştirmesi bulunan iki doğrusal katmanlı bir ikili olarak düşünün. İşlendikten sonra çıktı tanıdık bir yola girer: geri beslenir ve noktasal ileri beslemeli ağın girdisiyle birleşir.
Bu kavuşmayı, bir sonraki adımlar için her şeyin iyi ayarlandığından emin olmak üzere bir başka normalizasyon izler.
Görsel: yazar. Kodlayıcı iş akışı. İleri Beslemeli Sinir Ağı alt katmanı.
Son kodlayıcı katmanının çıktısı, her biri girdi dizisini zengin bir bağlamsal anlayışla temsil eden bir dizi vektördür. Bu çıktı daha sonra Transformer modelinde çözücünün girdisi olarak kullanılır.
Bu özenli kodlama, çözümleme zamanı geldiğinde çözücünün girdideki doğru kelimelere dikkat etmesini sağlar.
Bunu, N kodlayıcı katmanı üst üste koyabildiğiniz bir kule inşa etmek gibi düşünün. Bu yığındaki her katman, tıpkı bilgi katmanları gibi, dikkatin farklı yönlerini keşfetme ve öğrenme şansı bulur. Bu, yalnızca anlayışı çeşitlendirmekle kalmaz, aynı zamanda transformer ağının kestirim yeteneklerini önemli ölçüde artırabilir.
Çözücünün rolü, metin dizileri üretmeye odaklanır. Kodlayıcıya ayna tutar şekilde, çözücü benzer alt katman setiyle donatılmıştır. İki çok başlıklı dikkat katmanına, noktasal ileri beslemeli bir katmana ve her alt katmandan sonra hem artık bağlantılara hem de katman normalizasyonuna sahiptir.
Görsel: yazar. Kodlayıcıların genel yapısı.
Bu bileşenler, kodlayıcının katmanlarına benzer şekilde çalışır ancak bir farkla: çözücüdeki her çok başlıklı dikkat katmanının kendine özgü bir görevi vardır.
Çözücünün süreci, bir sınıflandırıcı görevi gören doğrusal bir katmanla ve farklı kelimelerin olasılıklarını hesaplamak için en üstte bir softmax ile sona erer.
Transformer çözücüsü, kodlanmış bilgiyi adım adım çözerek bu çıktıyı üretmek üzere özel olarak tasarlanmıştır.
Dikkat edilmesi gereken önemli bir nokta, çözücünün otoregresif biçimde çalışmasıdır; sürece bir başlangıç belirteciyle başlar. Akıllıca, önceden ürettiği çıktılar listesini, başlangıç girdisinden gelen dikkat bilgisiyle zengin encoder çıktılarıyla birlikte girdi olarak kullanır.
Bu ardışık çözümleme dansı, çözücünün çıkış üretiminin bittiğini bildiren bir belirteci üretme anına kadar devam eder.
Çözücünün başlangıç çizgisinde süreç, kodlayıcıdakiyle aynıdır. Burada girdi önce bir gömme katmanından geçer
Gömmenin ardından, yine kodlayıcıdaki gibi, girdi konumsal kodlama katmanından geçer. Bu adım, konumsal gömmeler üretmek üzere tasarlanmıştır.
Bu konumsal gömmeler daha sonra çözücünün ilk çok başlıklı dikkat katmanına aktarılır; burada çözücünün girdisine özgü dikkat puanları titizlikle hesaplanır.
Çözücü, özdeş katmanların bir yığınından oluşur (özgün modelde 6). Her katmanda üç ana alt bileşen bulunur:
Bu, kodlayıcıdaki kendi-kendine dikkat mekanizmasına benzer ancak kritik bir farkla: konumların sonraki konumlara dikkat etmesini engeller; yani dizideki her kelime gelecekteki belirteçlerden etkilenmez.
Örneğin “are” kelimesi için dikkat puanları hesaplanırken, dizide daha sonra gelen “you”ya bakmaması önemlidir.
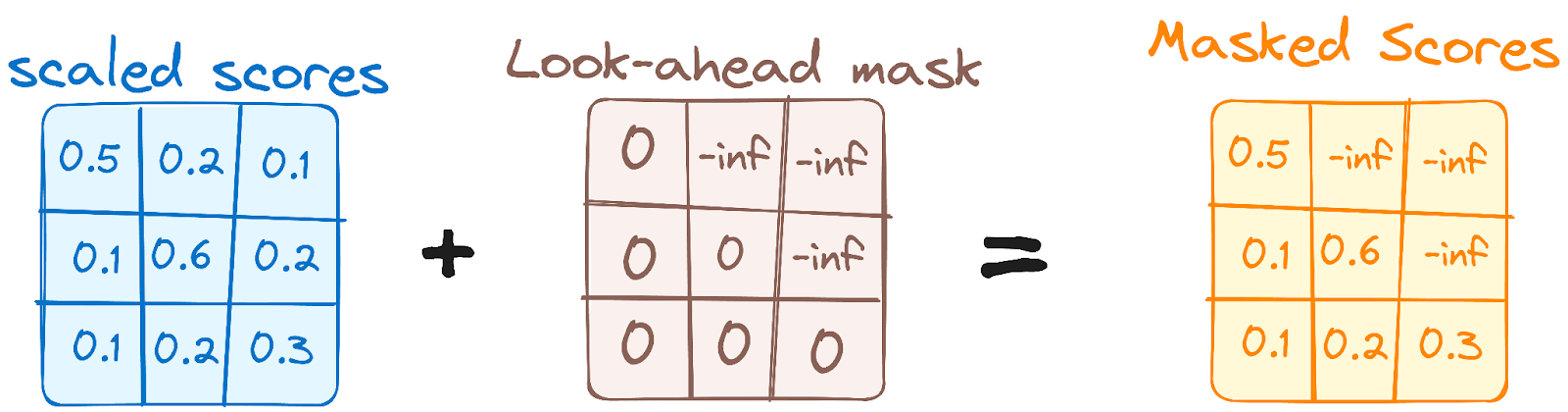
Görsel: yazar. Çözücü iş akışı. İlk Çok Başlıklı Dikkat Maskesi.
Bu maskeleme, belirli bir konum için tahminlerin yalnızca ondan önceki konumlardaki bilinen çıktılara bağlı olmasını garanti eder.
Çözücünün ikinci çok başlıklı dikkat katmanında, kodlayıcı ve çözücü bileşenleri arasında benzersiz bir etkileşim görülür. Burada kodlayıcıdan gelen çıktılar hem sorgu hem anahtar rolünü üstlenirken, çözücünün ilk çok başlıklı dikkat katmanının çıktıları değer olarak hizmet eder.
Bu kurulum, kodlayıcının girdisini çözücününkiyle etkili şekilde hizalar ve çözücünün, kodlayıcının girdisinin en ilgili kısımlarını belirleyip vurgulamasını sağlar.
Ardından, bu ikinci çok başlıklı dikkat katmanının çıktısı noktasal bir ileri beslemeli katmanla iyileştirilir ve işleme daha da güç kazandırılır.
Görsel: yazar. Çözücü iş akışı. Kodlayıcı-Çözücü Dikkati.
Bu alt katmanda, sorgular önceki çözücü katmanından gelir; anahtarlar ve değerler ise kodlayıcının çıktısından. Bu sayede çözücüdeki her konum, girdi dizisindeki tüm konumlara dikkat edebilir ve kodlayıcıdaki bilgiyi çözücüdeki bilgilerle etkili biçimde bütünleştirir.
Kodlayıcıya benzer biçimde, her çözücü katmanı, her konuma ayrı ve özdeş biçimde uygulanan tam bağlantılı bir ileri beslemeli ağ içerir.
Verinin transformer modelindeki yolculuğu, bir sınıflandırıcı işlevi gören son bir doğrusal katmandan geçerek tamamlanır.
Bu sınıflandırıcının boyutu, dâhil olan toplam sınıf sayısına (sözlükteki kelime sayısı) karşılık gelir. Örneğin, 1000 farklı kelimeyi temsil eden 1000 ayrı sınıfın bulunduğu bir senaryoda, sınıflandırıcının çıktısı 1000 öğeli bir dizidir.
Bu çıktı, ardından softmax katmanına verilir; burada 0 ile 1 arasında değişen olasılık puanlarına dönüştürülür. Bu olasılık puanlarının en yükseği kilittir; karşılık gelen indeks, modelin dizide bir sonraki olarak tahmin ettiği kelimeyi doğrudan gösterir.
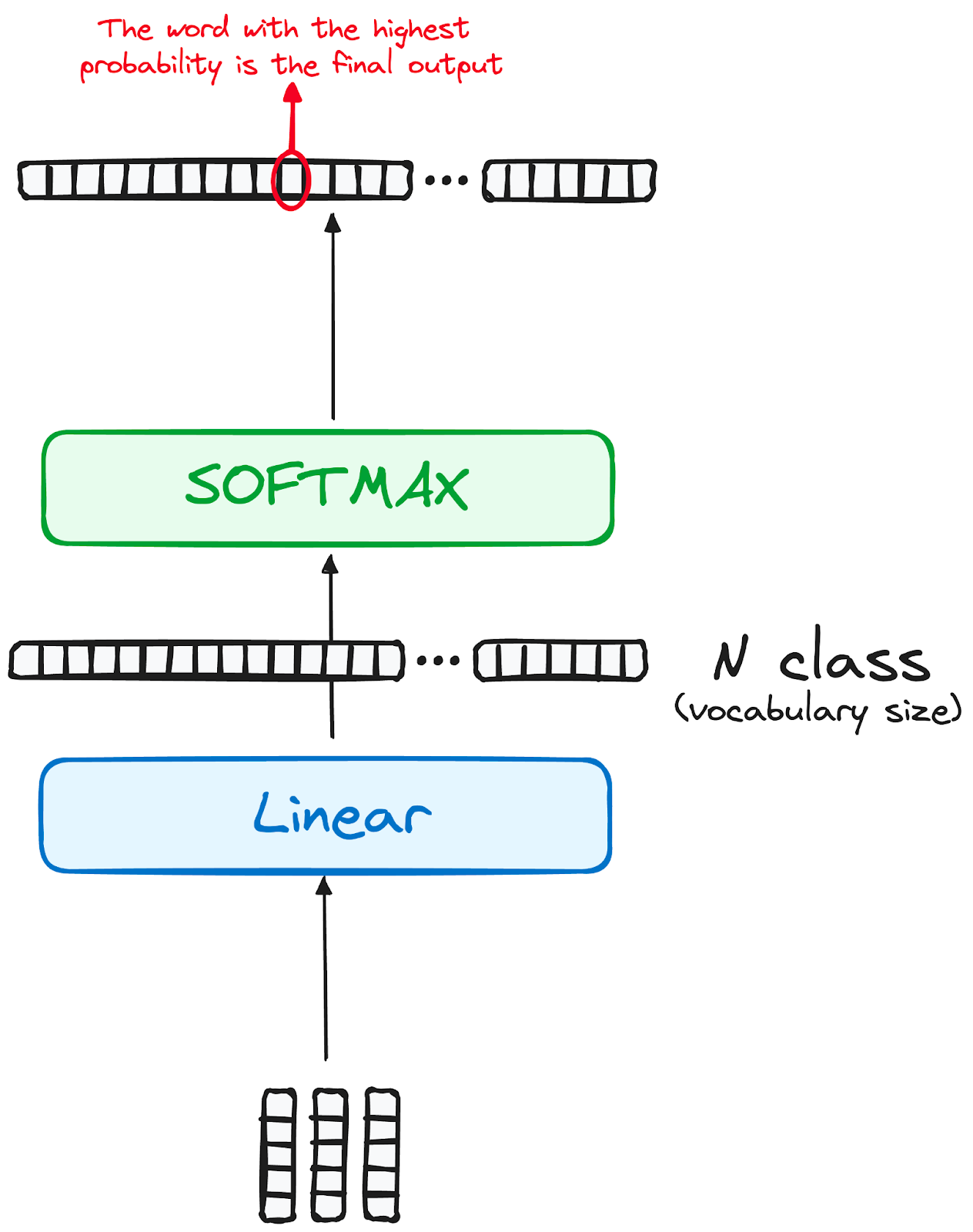
Görsel: yazar. Çözücü iş akışı. Transformer'ın nihai çıktısı.
Her alt katmanı (maskeli kendi-kendine dikkat, kodlayıcı-çözücü dikkat, ileri beslemeli ağ) bir normalizasyon adımı izler ve her birinin etrafında artık bağlantı bulunur.
Son katmanın çıktısı, tipik olarak bir doğrusal katmanı ve ardından sözlük üzerinde olasılık üretmek için bir softmax'i izleyen bir tahmin dizisine dönüştürülür.
Çözücü, işletim akışında, taze ürettiği çıktıyı büyüyen girdi listesine dâhil eder ve ardından çözümlemeye devam eder. Bu döngü, model belirli bir belirteci —tamamlandığını bildiren— tahmin edene kadar tekrar eder.
En yüksek olasılıkla tahmin edilen belirteç, sıklıkla bitiş belirteciyle temsil edilen son sınıf olarak atanır.
Tekrar hatırlayın: çözücü tek bir katmanla sınırlı değildir. Kodlayıcıdan ve önceki katmanlarından aldığı girdinin üzerine inşa olan N katmanla yapılandırılabilir. Bu katmanlı mimari, modelin odağını çeşitlendirmesine ve farklı dikkat başlıkları arasında değişen dikkat örüntülerini çıkarmasına imkân tanır.
Böylesi çok katmanlı bir yaklaşım, farklı dikkat bileşimlerine daha incelikli bir anlayış geliştirdikçe modelin kestirim kabiliyetini önemli ölçüde artırabilir.
Nihai mimari şu şekilde görünür (özgün makaleden):
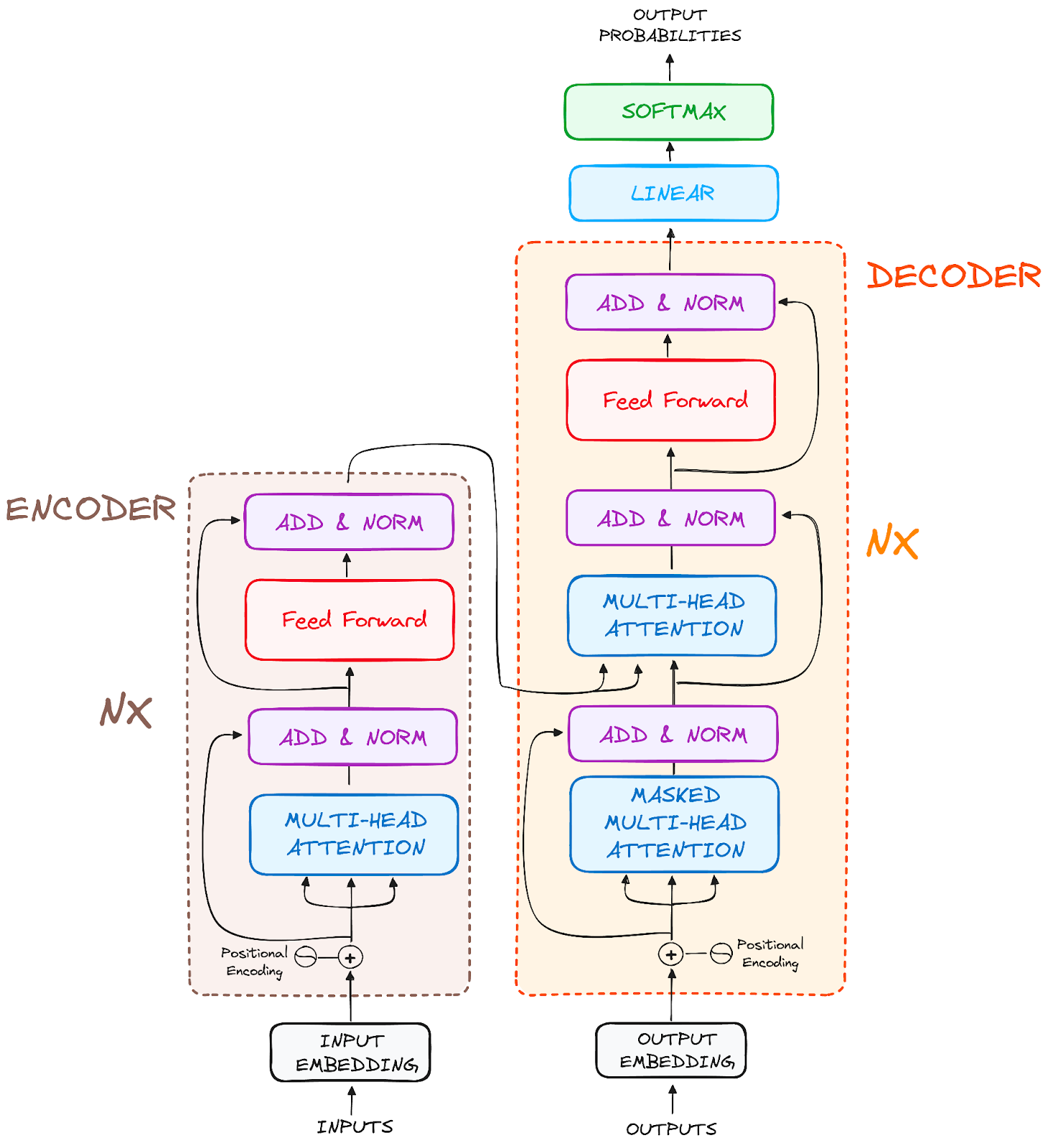
Görsel: yazar. Transformer'ların özgün yapısı.
Bu mimariyi daha iyi anlamak için, PyTorch ile bir transformer inşa etme eğitimini izleyerek sıfırdan uygulamayı denemenizi öneririm.
Google'ın 2018'de yayımladığı, açık kaynaklı bir doğal dil işleme çerçevesi olan BERT, benzersiz çift yönlü eğitimiyle NLP'de devrim yarattı; bu sayede model, bir sonraki kelimenin ne olması gerektiğine dair bağlama daha çok dayanan tahminler yapabildi.
Bir kelimenin bağlamını her iki taraftan anlayarak, BERT soru yanıtlama ve belirsiz dili anlama gibi görevlerde önceki modelleri geride bıraktı. Çekirdeğinde Transformer'ları kullanır; her çıktı ve girdi öğesini dinamik olarak bağlar.
Wikipedia üzerinde önceden eğitilen BERT, çeşitli NLP görevlerinde mükemmel performans sergiledi; Google'ın, daha doğal sorgular için arama motoruna entegre etmesine yol açtı. Bu yenilik, gelişmiş dil modelleri geliştirme yarışını tetikleyerek, karmaşık dil anlayışıyla başa çıkma becerisini önemli ölçüde ilerletti.
BERT hakkında daha fazla bilgi için, BERT modelini tanıtan ayrı makalemize göz atabilirsiniz.
LaMDA (Language Model for Dialogue Applications), Google tarafından özellikle sohbet görevleri için tasarlanan ve 2021 Google I/O açılışında duyurulan Transformer tabanlı bir modeldir. Daha doğal ve bağlamsal olarak ilgili yanıtlar üretmek üzere tasarlanmıştır; bu da çeşitli uygulamalarda kullanıcı etkileşimlerini geliştirir.
LaMDA'nın tasarımı, geniş konu ve kullanıcı niyetlerini anlayıp yanıtlamasına olanak tanır; bu da onu, dinamik sohbetin kilit olduğu sohbet botları, sanal asistanlar ve diğer etkileşimli yapay zekâ sistemleri için ideal kılar.
Sohbeti anlama ve yanıt üretimine odaklanması, LaMDA'yı doğal dil işleme ve yapay zekâ destekli iletişim alanında önemli bir ilerleme olarak konumlandırır.
LaMDA modellerini daha iyi anlamakla ilgileniyorsanız, LaMDA ile ilgili makalemiz size daha iyi bir kavrayış sağlayacaktır.
OpenAI tarafından geliştirilen GPT ve ChatGPT, tutarlı ve bağlamsal olarak ilgili metin üretme becerileriyle bilinen ileri düzey üretken modellerdir. İlk model GPT-1 Haziran 2018'de, en etkili modellerden biri olan GPT-3 ise iki yıl sonra 2020'de piyasaya sürüldü.
Bu modeller içerik üretimi, sohbet, dil çevirisi ve daha fazlası dâhil geniş bir görev yelpazesinde yetkindir. GPT'nin mimarisi, insan yazısına çok benzeyen metin üretmesini sağlar; bu da onu yaratıcı yazım, müşteri desteği ve hatta kodlama desteği gibi uygulamalarda faydalı kılar. Sohbet bağlamları için optimize edilmiş bir varyant olan ChatGPT, insan benzeri diyalog üretmede mükemmeldir ve bu sayede sohbet botları ve sanal asistanlardaki kullanımını güçlendirir.
Anthropic tarafından geliştirilen Claude, güvenlik ve faydalılık odaklı tasarlanmış Transformer tabanlı yapay zekâ asistanlarından oluşan bir ailedir. Claude, modelin faydalı, zararsız ve dürüst yanıtlar üretmesi için bir ilke kümesiyle yönlendirildiği bir eğitim yaklaşımı olan Constitutional AI (CAI) kullanır.
Claude 3 (2024'te yayımlandı), hız ve yetenek arasında farklı dengeler sunan üç model katmanı —Haiku, Sonnet ve Opus— tanıttı. Modeller, incelikli akıl yürütme, karmaşık talimatları takip etme ve uzun sohbetler boyunca (200K belirtece kadar) bağlamı korumada üstündür.
2025 ve 2026'da Anthropic, en günceli Opus 4.6 ve Sonnet 4.6 olan Claude 4 modellerini piyasaya sürdü; pek çok LLM kıyaslamasında zirveye yerleştiler.
Temel modellerin, özellikle de transformer modellerinin manzarası hızla genişliyor. Bir çalışma 50'den fazla önemli transformer modelini belirledi; Stanford grubu bunların 30'unu değerlendirdi ve alanın hızlı büyümesini teslim etti. NVIDIA'nın Inception programının parçası olan yenilikçi girişim NLP Cloud, havayolları ve eczaneler gibi çeşitli sektörler için ticari olarak yaklaşık 25 büyük dil modeli kullanıyor.
Bu modelleri açık kaynak yapma yönünde artan bir eğilim var; Hugging Face'in model merkezi gibi platformlar başı çekiyor. Ayrıca, farklı NLP görevlerine özel olarak geliştirilmiş çok sayıda Transformer tabanlı model mevcut ve bu da modelin çeşitli uygulamalarda çok yönlülüğünü ve verimliliğini sergiliyor.
Tüm mevcut Temel Modeller hakkında daha fazlasını, ne olduklarını ve hangilerinin en çok kullanıldığını ele alan ayrı bir makaleden öğrenebilirsiniz.
2017'deki özgün mimariden bu yana Transformer'lar, sınırlamaları ele almak ve yeni alanlara genişlemek için önemli ölçüde evrildi.
Vision Transformer'lar, görüntüleri yamalara bölerek ve her yamayı bir belirteç gibi ele alarak kendi-kendine dikkat mekanizmasını görsellere uygular. Bu yaklaşım, özellikle büyük veri kümelerinde, görüntü sınıflandırma, nesne tespiti ve görüntü üretimi için son derece etkilidir ve sıklıkla geleneksel CNN'leri geride bırakır.
GPT-5, Gemini 3 ve Llama 4 gibi modern modeller, tek bir mimari içinde birden çok girdi türünü (metin, görsel, ses, video) işler. Bu çok kipli Transformer'lar, farklı kipleri eşzamanlı olarak ilişkilendirmek için birleşik gömme uzayları ve çapraz dikkat mekanizmaları kullanır.
Kendi-kendine dikkatin karesel karmaşıklığı, bağlam uzunluğunu sınırlar. Bunu ele alan çeşitli yenilikler vardır:
NLP'de Transformer modellerinin performansını kıyaslamak ve değerlendirmek, etkililik ve verimliliklerini ölçmek için sistematik bir yaklaşım gerektirir.
Görevin doğasına bağlı olarak bunu yapmanın farklı yolları ve kaynakları vardır:
Makine Çevirisi görevleriyle uğraşırken, MT sistemlerinin her biri kendine özgü zorluklar sunan dil çifti dokularıyla karşılaştığı WMT (Workshop on Machine Translation) gibi standart veri kümelerinden yararlanabilirsiniz.
BLEU, METEOR, TER ve chrF gibi metrikler, bizi doğruluk ve akıcılığa götüren kılavuzlar olarak hizmet eder.
Ayrıca haber, edebiyat ve teknik metinler gibi çeşitli alanlarda test yapmak, bir MT sisteminin uyarlanabilirliğini ve çok yönlülüğünü güvence altına alır ve onu dijital dünyada gerçek bir çokdilli yapar.
QA modellerini değerlendirmek için SQuAD (Stanford Question Answering Dataset), Natural Questions veya TriviaQA gibi özel soru ve cevap koleksiyonlarını kullanırız.
Her biri, kendi kuralları olan farklı bir oyun gibidir. Örneğin SQuAD verilen bir metinde yanıt bulmayla ilgilidir; diğerleriyse her yerden gelebilecek sorularla bir bilgi yarışmasına daha çok benzer.
Bu programların ne kadar iyi performans gösterdiğini görmek için Kesinlik (Precision), Duyarlılık (Recall), F1 ve bazen bire bir eşleşme puanları gibi ölçütleri kullanırız.
Doğal Dil Çıkarımı (NLI) söz konusu olduğunda SNLI (Stanford Natural Language Inference), MultiNLI ve ANLI gibi özel veri kümeleri kullanırız.
Bunlar, dil varyasyonları ve yanıltıcı durumların büyük kütüphaneleri gibidir; bilgisayarlarımızın farklı türde cümleleri ne kadar iyi anladığını görmemize yardımcı olur. Esasen, ifadelerin uzlaşıp uzlaşmadığını, çelişip çelişmediğini ya da ilgisiz olup olmadığını anlama doğruluğunu ölçeriz.
Ayrıca, bir kelimenin daha önce bahsedilen bir şeye gönderme yapması ya da ‘değil’, ‘hepsi’ ve ‘bazı’ gibi nicelikleri anlamak gibi zor dil unsurlarını bilgisayarın nasıl çözdüğüne bakmak da önemlidir.
Sinir Ağları dünyasında, Transformer'larla genellikle iki belirgin yapı karşılaştırılır. Her biri belirli veri işleme türlerine uyarlanmış farklı faydalar ve zorluklar sunar: bu yazı boyunca birkaç kez geçen RNN'ler ve Evrişim Katmanları.
Tekrarlayan Katmanlar, Tekrarlayan Sinir Ağlarının (RNN) temel taşıdır ve ardışık veriyi işlemekte üstündür. Bu mimarinin gücü, dil işleme ya da zaman serisi analizi gibi görevler için kritik olan ardışık işlemleri gerçekleştirme yeteneğinde yatar. Bir Tekrarlayan Katmanda, önceki adımdan gelen çıktı, bir sonraki adımın girdisi olarak ağa geri beslenir. Bu döngüsel mekanizma, ağın önceki bilgileri hatırlamasını sağlar; bu, bir dizideki bağlamı anlamak için hayati önemdedir.
Ancak daha önce tartıştığımız üzere, bu ardışık işlemeye dair iki temel sonuç vardır:
Transformer modelleri, yinelemeye sahip olmadıkları için tekrarlayan katman kullanan mimarilerden önemli ölçüde ayrılır. Daha önce gördüğümüz gibi Transformer'ın Dikkat katmanı, her iki sorunu da ele alır ve onları NLP uygulamaları için RNN'lerin doğal evrimi hâline getirir.
Öte yandan Evrişim Katmanları, Evrişimsel Sinir Ağlarının (CNN) yapı taşlarıdır ve görüntü gibi uzamsal verileri işlerken gösterdikleri verimlilikle bilinir.
Bu katmanlar, özellikleri çıkarmak için girdinin üzerinden tarama yapan çekirdekler (filtreler) kullanır. Bu çekirdeklerin genişliği ayarlanabilir; bu da ağa göreve bağlı olarak küçük ya da büyük özelliklere odaklanma olanağı tanır.
Evrişim Katmanları verideki uzamsal hiyerarşileri ve örüntüleri yakalamada son derece iyi olsa da uzun dönem bağımlılıklarla ilgili zorluklar yaşarlar. Ardışık bilgiyi içkin olarak hesaba katmazlar; bu da onları bir dizinin sırası ya da bağlamını anlamayı gerektiren görevler için daha az uygun kılar.
Bu nedenle CNN'ler ve Transformer'lar farklı veri ve görev türleri için biçimlendirilmiştir. CNN'ler uzamsal bilgiyi işleme verimliliği sayesinde bilgisayarlı görü alanında baskındır; Transformer'lar ise uzun menzilli bağımlılıkları anlama yetenekleriyle, özellikle NLP'de, karmaşık ardışık görevlerin tercih edilen yapısıdır.
Başarılarına rağmen Transformer'ların dikkat çekici sınırlamaları vardır:
Araştırmalar, Flash Attention, uzman karışımı ve geri getirme artırımlı üretim (RAG) gibi mimari yeniliklerle bu sınırlamaları ele almaya devam ediyor.
Sonuç olarak Transformer'lar, yapay zekâ ve doğal dil işleme (NLP) alanında anıtsal bir atılım olarak ortaya çıkmıştır.
Benzersiz kendi-kendine dikkat mekanizmalarıyla ardışık veriyi etkin biçimde yöneterek, bu modeller geleneksel RNN'leri geride bıraktı. Uzun dizileri daha verimli ele alabilmeleri ve veri işlemesini paralelleştirebilmeleri, eğitimi önemli ölçüde hızlandırır.
Google'ın BERT'i ve OpenAI'nin GPT serisi gibi öncü modeller, arama motorlarını iyileştirmede ve insan benzeri metin üretiminde Transformer'ların dönüştürücü etkisini örnekler.
Sonuç olarak, modern makine öğreniminde vazgeçilmez hâle gelmiş, yapay zekânın sınırlarını ileriye taşımış ve teknolojik ilerlemelerde yeni kapılar açmışlardır.
Transformer'lara ve pratik kullanımına dalmak isterseniz, Transformer'lar ve Hugging Face hakkındaki makalemiz mükemmel bir başlangıçtır! Ayrıca kapsamlı rehberimizle PyTorch ile bir Transformer nasıl kurulur öğrenebilirsiniz.
Transformer'lar ve LLM'ler Hakkında Daha Fazla Bilgi Edinin!
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
