
Cursus
Concepten van Large Language Models (LLMs)
2 Hr
104K
Transformers zijn oorspronkelijk ontwikkeld om het probleem van sequentietransductie, oftewel neurale machinale vertaling, op te lossen. Dat betekent dat ze bedoeld zijn voor elke taak die een inputsequentie naar een outputsequentie transformeert. Daarom heten ze “Transformers”.
Maar laten we bij het begin beginnen.
Een transformer-model is een neuraal netwerk dat de context van sequentiële data leert en daaruit nieuwe data genereert.
Eenvoudig gezegd:
Een transformer is een type AI-model dat leert om mensachtige tekst te begrijpen en te genereren door patronen in grote hoeveelheden tekstdata te analyseren.
Transformers zijn de huidige state-of-the-art in NLP en worden gezien als de evolutie van de encoder–decoder-architectuur. Waar die architectuur echter vooral leunt op Recurrent Neural Networks (RNN’s) om sequentiële informatie te extraheren, missen Transformers recurrency volledig.
Hoe doen ze dat dan?
Ze zijn specifiek ontworpen om context en betekenis te begrijpen door de relaties tussen verschillende elementen te analyseren, en vertrouwen daarbij vrijwel volledig op een wiskundige techniek genaamd attention.

Afbeelding door de auteur.
Ontstaan uit een onderzoekspaper van Google uit 2017, zijn transformer-modellen een van de meest recente en invloedrijke ontwikkelingen in machine learning. Het eerste Transformer-model werd uitgelegd in de invloedrijke paper "Attention is All You Need".
Dit baanbrekende concept was niet alleen een theoretische vooruitgang, maar vond ook praktische toepassing, onder meer in TensorFlow's Tensor2Tensor-pakket. Daarnaast droeg de Harvard NLP-groep bij aan dit snelgroeiende veld met een geannoteerde gids bij de paper, aangevuld met een PyTorch-implementatie. Je kunt meer leren over hoe je een Transformer from scratch implementeert in onze aparte tutorial.
Hun introductie veroorzaakte een sterke opmars in het veld, vaak aangeduid als Transformer AI. Dit revolutionaire model legde de basis voor latere doorbraken in grote taalmodellen, waaronder BERT. In 2018 werden deze ontwikkelingen al gezien als een kantelpunt in NLP.
In 2020 kondigden onderzoekers bij OpenAI GPT-3 aan. Binnen enkele weken werd GPT-3's veelzijdigheid duidelijk toen mensen het gebruikten om gedichten, programma’s, liedjes, websites en meer te maken, waarmee het de verbeelding van gebruikers wereldwijd prikkelde. Naar aanleiding van deze verschuiving publiceerden Stanford-wetenschappers in 2021 een paper waarin ze deze innovaties "foundation models" noemden, waarmee ze hun cruciale rol in het hervormen van AI onderstreepten.
Hoewel propriëtaire modellen in het begin de publieke aandacht trokken, democratiseerde een parallelle open-sourcerevolutie transformer-technologie in rap tempo. Platforms als Hugging Face werden belangrijke hubs voor het delen van modellen, maar het landschap veranderde fundamenteel in 2023 met de release van Meta's Llama-familie. Dit ontketende een "open-weights"-beweging, waaruit bleek dat ontwikkelaars niet langer afhankelijk hoefden te zijn van gesloten bedrijfs-ecosystemen om state-of-the-art AI te bouwen.
Gedurende 2024 en 2025 versnelde open-sourceontwikkeling fel. Modellen als Meta's enorme Llama 3.1 en de latere Llama 4-serie, naast zeer efficiënte architecturen van startups zoals Mistral en krachtige redeneermodellen van DeepSeek, bewezen dat open beschikbare modellen de prestaties van propriëtaire giganten konden evenaren en soms overtreffen.
Ondertussen bleven closed-source modellen complexe capaciteiten ontwikkelen. GPT-4 in 2023 introduceerde multimodale capaciteiten, en GPT-4o in 2024 verenigde tekst-, beeld- en audioprocessing in één model.
Eind 2024 markeerde opnieuw een fundamentele wending in de sector met modellen als OpenAI's o1-serie en DeepSeek's open R1, die een interne 'chain-of-thought' introduceerden om complexe logica en wiskunde te doorgronden vóór het antwoorden.
Tegen eind 2025 en in 2026 verschoof het landschap volledig van conversatie-assistenten naar autonome systemen met de lancering van de GPT-5-familie, die geavanceerde meerstapsplanning, langetermijngeheugen en robuuste agent-workflows naar enterprise-infrastructuur bracht.
Ten tijde van de introductie van het Transformer-model waren Recurrent Neural Networks (RNN’s) de voorkeursaanpak voor het omgaan met sequentiële data, die wordt gekenmerkt door een specifieke volgorde in de input.
RNN’s functioneren vergelijkbaar met een feedforward-neuraal netwerk, maar verwerken de input sequentieel, één element per keer.
Transformers zijn geïnspireerd op de encoder–decoder-architectuur uit RNN’s. In plaats van recurrency te gebruiken, is het Transformer-model echter volledig gebaseerd op het Attention-mechanisme.
Naast het verbeteren van de prestaties van RNN’s bieden Transformers een nieuwe architectuur om vele andere taken op te lossen, zoals tekstsamenvatting, beeldonderschrift-generatie en spraakherkenning.
Wat zijn dan de belangrijkste problemen van RNN’s? Ze zijn vrij ineffectief voor NLP-taken om twee hoofdredenen:
De verschuiving van RNN’s zoals LSTM naar Transformers in NLP wordt gedreven door deze twee problemen en door het vermogen van Transformers om beide aan te pakken dankzij verbeteringen in het Attention-mechanisme:
Zo werden Transformers de natuurlijke verbetering van RNN’s.
Laten we nu kijken hoe transformers werken.
Oorspronkelijk bedacht voor sequentietransductie of neurale machinale vertaling, blinken transformers uit in het omzetten van inputsequenties naar outputsequenties. Het is het eerste transductiemodel dat volledig vertrouwt op self-attention om representaties van input en output te berekenen, zonder sequence-aligned RNN’s of convoluties te gebruiken. De kern van de Transformer-architectuur is dat deze het encoder–decoder-model behoudt.
Als we een Transformer voor taalvertaling als een eenvoudige black box bekijken, neemt die een zin in één taal, bijvoorbeeld Engels, als input en geeft de vertaling in het Engels als output.

Afbeelding door de auteur.
Kijken we iets dieper, dan zien we dat deze black box uit twee hoofddelen bestaat:
Afbeelding door de auteur. Globale structuur van Encoder–Decoder.
Zowel de encoder als de decoder zijn in feite een stapel met meerdere lagen (een gelijk aantal voor beide). Alle encoders hebben dezelfde structuur; de input gaat in elke encoder en wordt doorgegeven aan de volgende. Alle decoders hebben eveneens dezelfde structuur en krijgen de input van de laatste encoder en de vorige decoder.
De oorspronkelijke architectuur bestond uit 6 encoders en 6 decoders, maar we kunnen zoveel lagen repliceren als we willen. Laten we dus uitgaan van N lagen van elk.
Afbeelding door de auteur. Globale structuur van Encoder–Decoder. Meerdere lagen.
Nu we een globaal idee hebben van de Transformer-architectuur, zoomen we in op zowel Encoders als Decoders om hun werking beter te begrijpen:
De encoder is een fundamenteel onderdeel van de Transformer-architectuur. De primaire functie is om de inputtokens om te zetten in gecontextualiseerde representaties. In tegenstelling tot eerdere modellen die tokens onafhankelijk verwerkten, vangt de Transformer-encoder de context van elk token op ten opzichte van de gehele sequentie.
De opbouw is als volgt:
Afbeelding door de auteur. Globale structuur van Encoders.
Laten we de workflow opdelen in de meest basale stappen:
De embedding gebeurt alleen in de onderste encoder. De encoder begint met het omzetten van inputtokens – woorden of subwoorden – in vectoren via embedding-lagen. Deze embeddings vangen de semantische betekenis van de tokens en zetten ze om in numerieke vectoren.
Alle encoders ontvangen een lijst vectoren, elk van grootte 512 (vaste grootte). In de onderste encoder zijn dat de woordembeddings, maar in de hogere encoders is dat de output van de encoder direct eronder.
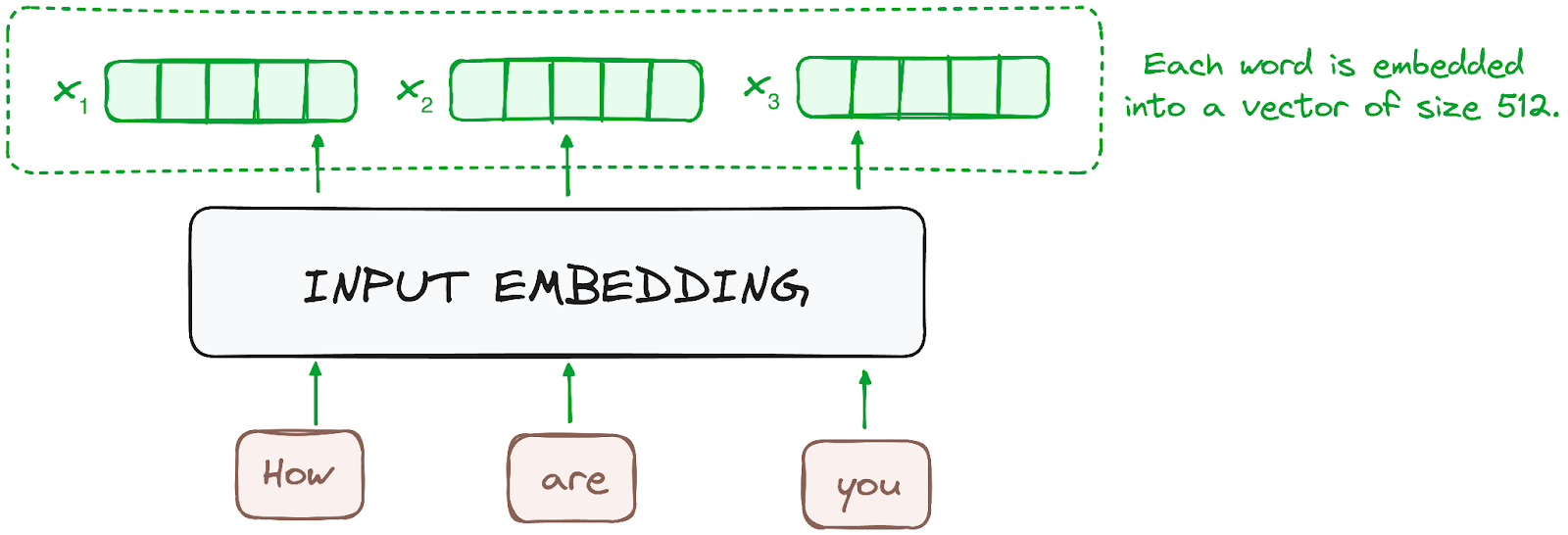
Afbeelding door de auteur. Workflow van de encoder. Input-embedding.
Omdat Transformers geen recurrency-mechanisme hebben zoals RNN’s, gebruiken ze positionele coderingen die worden toegevoegd aan de input-embeddings om informatie te geven over de positie van elk token in de sequentie. Zo begrijpen ze de plaats van elk woord in de zin.
Om dit te doen, stelden de onderzoekers voor om een combinatie van verschillende sinus- en cosinusfuncties te gebruiken om positionele vectoren te creëren, waardoor deze positionele encoder bruikbaar is voor zinnen van elke lengte.
In deze aanpak wordt elke dimensie weergegeven door unieke frequenties en offsets van de golf, met waarden tussen -1 en 1, die effectief elke positie representeren.
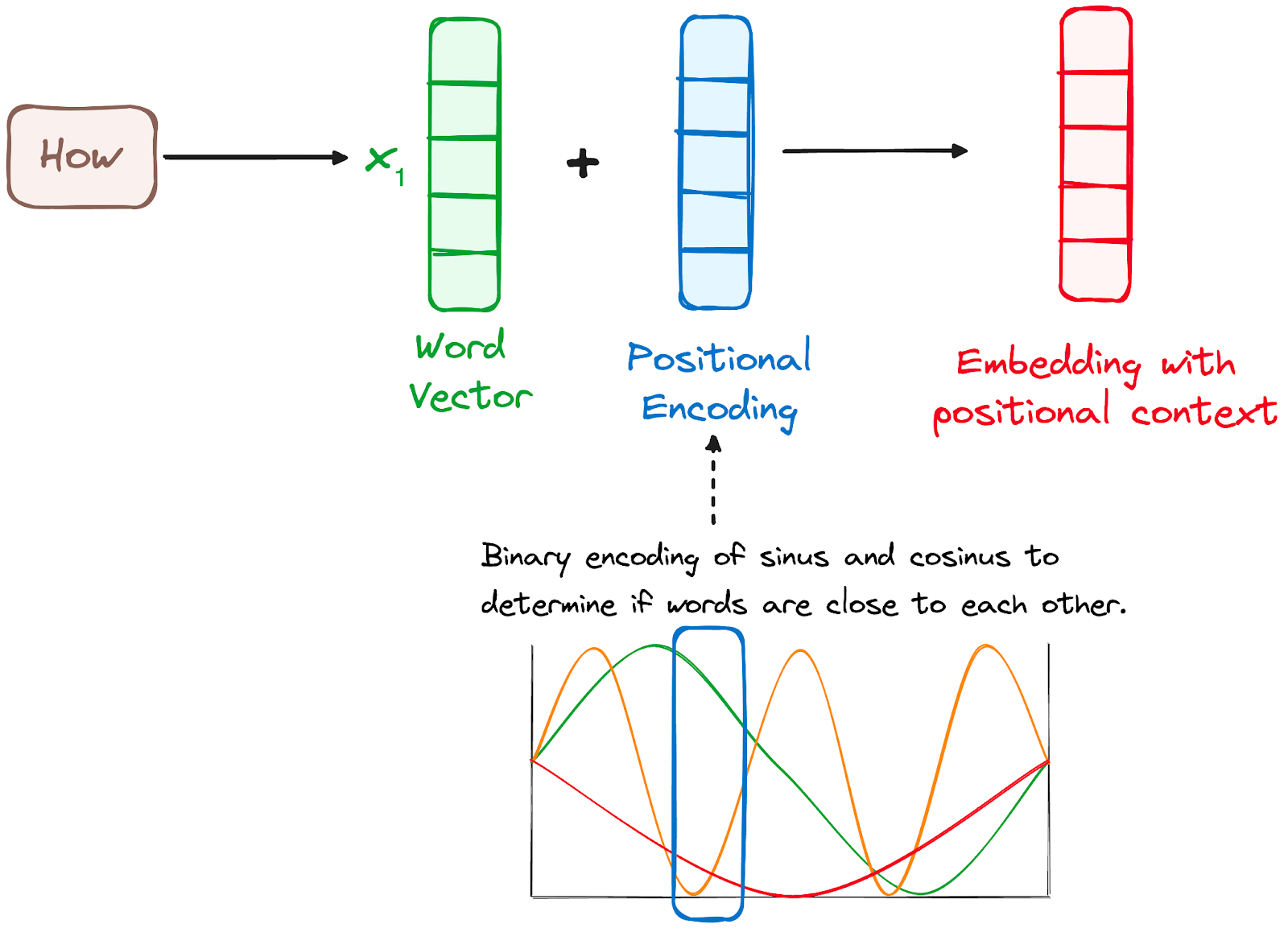
Afbeelding door de auteur. Workflow van de encoder. Positionele codering.
De Transformer-encoder bestaat uit een stapel identieke lagen (6 in het oorspronkelijke Transformer-model).
De encoderlaag zet alle inputsequenties om in een continue, abstracte representatie die de geleerde informatie van de gehele sequentie omvat. Deze laag bestaat uit twee submodules:
Daarnaast bevat hij residuele verbindingen rond elke sublaag, gevolgd door layer normalisatie.
Afbeelding door de auteur. Workflow van de encoder. Stapel encoder-lagen
In de encoder gebruikt de multi-head attention een gespecialiseerd attention-mechanisme, self-attention. Deze aanpak stelt modellen in staat om elk woord in de input te relateren aan andere woorden. In een voorbeeld kan het model bijvoorbeeld leren het woord “are” te verbinden met “you”.
Dit mechanisme laat de encoder focussen op verschillende delen van de inputsequentie tijdens de verwerking van elk token. Het berekent attention-scores op basis van:
Deze eerste self-attention-module stelt het model in staat contextuele informatie uit de hele sequentie te vangen. In plaats van één enkele attention-functie uit te voeren, worden queries, keys en values h keer lineair geprojecteerd. Op elk van deze geprojecteerde versies van queries, keys en values wordt het attention-mechanisme parallel uitgevoerd, wat h-dimensionale outputwaarden oplevert.
De gedetailleerde architectuur verloopt als volgt:
Zodra de query-, key- en value-vectoren door een lineaire laag zijn gegaan, wordt een dotproduct-matrixvermenigvuldiging uitgevoerd tussen de queries en keys, wat resulteert in een scorematrix.
De scorematrix geeft aan hoeveel nadruk elk woord op andere woorden moet leggen. Elk woord krijgt dus een score ten opzichte van andere woorden binnen dezelfde tijdstap. Een hogere score betekent meer focus.
Dit proces brengt de queries effectief in kaart naar hun corresponderende keys.
Afbeelding door de auteur. Workflow van de encoder. Attention-mechanisme - Matrixvermenigvuldiging.
De scores worden vervolgens geschaald door ze te delen door de vierkantswortel van de dimensie van de query- en key-vectoren. Deze stap zorgt voor stabielere gradiënten, omdat vermenigvuldigingen anders tot te grote effecten kunnen leiden.
Afbeelding door de auteur. Workflow van de encoder. Attention-scores verkleinen.
Vervolgens wordt een softmax-functie toegepast op de aangepaste scores om de attention-gewichten te verkrijgen. Dit levert waarschijnlijkheidswaarden op tussen 0 en 1. De softmax-functie benadrukt hogere scores en dempt lagere scores, waardoor het model effectiever kan bepalen welke woorden meer aandacht verdienen.
Afbeelding door de auteur. Workflow van de encoder. Softmax aangepaste scores.
De volgende stap in het attention-mechanisme is dat de gewichten uit de softmax-functie worden vermenigvuldigd met de value-vector, wat resulteert in een outputvector.
In dit proces blijven alleen de woorden met hoge softmax-scores behouden. Ten slotte gaat deze outputvector door een lineaire laag voor verdere verwerking.
Afbeelding door de auteur. Workflow van de encoder. Softmax-resultaten combineren met de value-vector.
En dan krijgen we eindelijk de output van het Attention-mechanisme!
Waarom heet het dan Multi-Head Attention?
Onthoud dat we voordat het proces start, onze queries, keys en values h keer opsplitsen. Dit proces, bekend als self-attention, gebeurt afzonderlijk in elk van deze kleinere stadia of ‘heads’. Elke head werkt onafhankelijk en produceert een outputvector.
Deze set gaat door een laatste lineaire laag, als een filter dat hun gezamenlijke prestatie fijnstemt. Het mooie is de diversiteit aan wat elke head leert, wat de encoder verrijkt met een robuust en veelzijdig begrip.
Voor een diepere uitleg van het attention-mechanisme, zie onze tutorial over multi-head attention in Transformers.
Op elke sublaag in een encoderlaag volgt een normalisatiestap. Ook wordt de output van elke sublaag bij de input opgeteld (residuele verbinding) om het probleem van verdwijnende gradiënten te beperken, wat diepere modellen mogelijk maakt. Dit proces wordt ook herhaald na het feedforward-neuraal netwerk.
Afbeelding door de auteur. Workflow van de encoder. Normalisatie en residuele verbinding na Multi-Head Attention.
De weg van de genormaliseerde residuele output gaat verder door een pointwise feedforward-netwerk, een cruciale fase voor extra verfijning.
Zie dit netwerk als een duo van lineaire lagen met daartussen een ReLU-activatie als brug. Na verwerking volgt een bekend pad: de output wordt teruggekoppeld en samengevoegd met de input van het pointwise feedforward-netwerk.
Deze hereniging wordt gevolgd door nog een normalisatieronde, zodat alles goed is afgestemd voor de volgende stappen.
Afbeelding door de auteur. Workflow van de encoder. Feedforward-neuraal-netwerk-sublayer.
De output van de laatste encoderlaag is een set vectoren die elk de inputsequentie representeren met een rijk contextueel begrip. Deze output wordt vervolgens gebruikt als input voor de decoder in een Transformer-model.
Deze zorgvuldige codering effent het pad voor de decoder en helpt die de juiste woorden in de input te benadrukken tijdens het decoderen.
Zie het als een toren bouwen, waarbij je N encoderlagen kunt stapelen. Elke laag in deze stapel krijgt de kans om verschillende facetten van attention te verkennen en te leren, als lagen van kennis. Dit vergroot niet alleen de diversiteit in begrip, maar kan de voorspellende capaciteiten van het netwerk aanzienlijk versterken.
De rol van de decoder draait om het construeren van tekstsequenties. Net als de encoder is de decoder uitgerust met vergelijkbare sublagen. Hij heeft twee multi-head attention-lagen, een pointwise feedforward-laag, en bevat na elke sublaag residuele verbindingen en layer normalisatie.
Afbeelding door de auteur. Globale structuur van Encoders.
Deze componenten werken vergelijkbaar met die van de encoderlagen, maar met een twist: elke multi-head attention-laag in de decoder heeft een eigen taak.
De laatste stap in het proces van de decoder omvat een lineaire laag, die fungeert als classifier, gevolgd door een softmax-functie om de waarschijnlijkheden van verschillende woorden te berekenen.
De Transformer-decoder heeft een structuur die specifiek is ontworpen om deze output te genereren door de gecodeerde informatie stap voor stap te decoderen.
Belangrijk is dat de decoder autoregressief werkt en begint met een starttoken. Hij gebruikt slim een lijst van eerder gegenereerde outputs als zijn inputs, samen met de outputs van de encoder die rijk zijn aan attention-informatie uit de oorspronkelijke input.
Deze sequentiële dans van decoderen gaat door totdat de decoder een token genereert dat het einde van de output aangeeft.
Aan de start van de decoder spiegelt het proces dat van de encoder. Hier gaat de input eerst door een embedding-laag
Na de embedding, opnieuw net als bij de encoder, gaat de input door de positionele coderingslaag. Deze sequentie is ontworpen om positionele embeddings te produceren.
Deze positionele embeddings gaan vervolgens naar de eerste multi-head attention-laag van de decoder, waar de attention-scores, specifiek voor de input van de decoder, nauwkeurig worden berekend.
De decoder bestaat uit een stapel identieke lagen (6 in het oorspronkelijke Transformer-model). Elke laag heeft drie hoofdsublagen:
Dit lijkt op het self-attention-mechanisme in de encoder, maar met een cruciaal verschil: het voorkomt dat posities naar latere posities kijken. Dat betekent dat elk woord in de sequentie niet wordt beïnvloed door toekomstige tokens.
Wanneer bijvoorbeeld de attention-scores voor het woord "are" worden berekend, is het belangrijk dat "are" geen kijkje kan nemen bij "you", dat later in de sequentie komt.
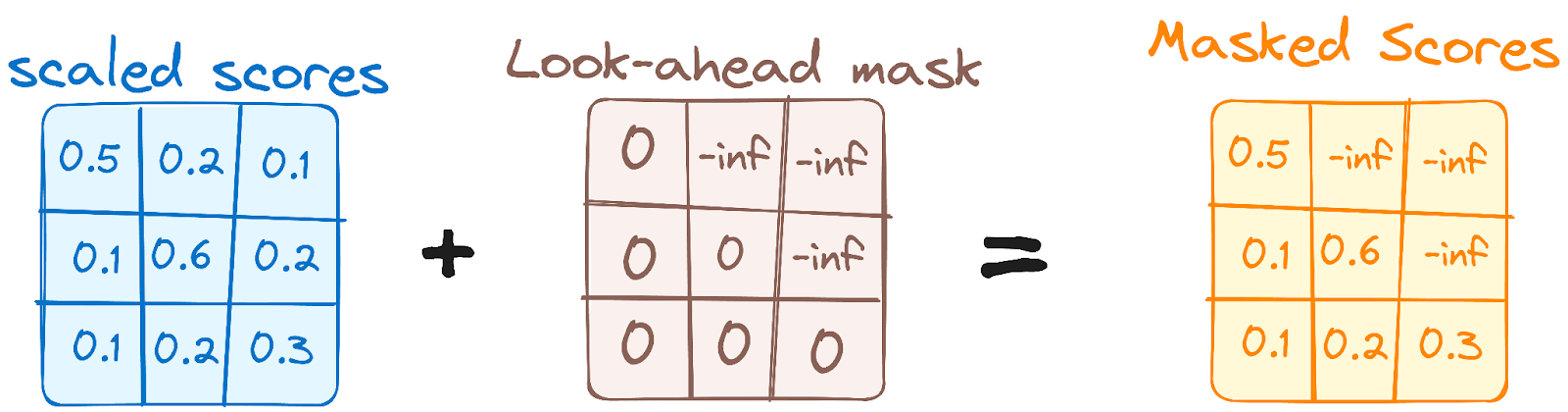
Afbeelding door de auteur. Workflow van de decoder. Eerste Multi-Head Attention-masker.
Deze masking zorgt ervoor dat de voorspellingen voor een bepaalde positie alleen kunnen afhangen van bekende outputs op eerdere posities.
In de tweede multi-head attention-laag van de decoder zien we een unieke wisselwerking tussen de componenten van encoder en decoder. Hier nemen de outputs van de encoder de rol van zowel queries als keys op zich, terwijl de outputs van de eerste multi-head attention-laag van de decoder als values dienen.
Deze opzet brengt de input van de encoder effectief in lijn met die van de decoder, waardoor de decoder de meest relevante delen van de encoder-input kan identificeren en benadrukken.
Daarna wordt de output van deze tweede multi-head attention-laag verfijnd via een pointwise feedforward-laag, wat de verwerking verder versterkt.
Afbeelding door de auteur. Workflow van de decoder. Encoder–decoder attention.
In deze sublaag komen de queries uit de vorige decoderlaag, en de keys en values uit de output van de encoder. Dit stelt elke positie in de decoder in staat om naar alle posities in de inputsequentie te kijken, zodat informatie uit de encoder effectief wordt geïntegreerd met de informatie in de decoder.
Net als in de encoder bevat elke decoderlaag een volledig verbonden feedforward-netwerk dat op elke positie afzonderlijk en identiek wordt toegepast.
De reis van data door het transformer-model eindigt in een laatste lineaire laag, die fungeert als classifier.
De grootte van deze classifier komt overeen met het totale aantal klassen (het aantal woorden in de woordenschat). In een scenario met 1000 verschillende klassen die 1000 verschillende woorden vertegenwoordigen, zal de output van de classifier bijvoorbeeld een array met 1000 elementen zijn.
Deze output gaat vervolgens naar een softmax-laag, die het omzet in waarschijnlijkheidsscores tussen 0 en 1. De hoogste van deze scores is bepalend; de corresponderende index wijst direct naar het woord dat het model als volgende in de sequentie voorspelt.
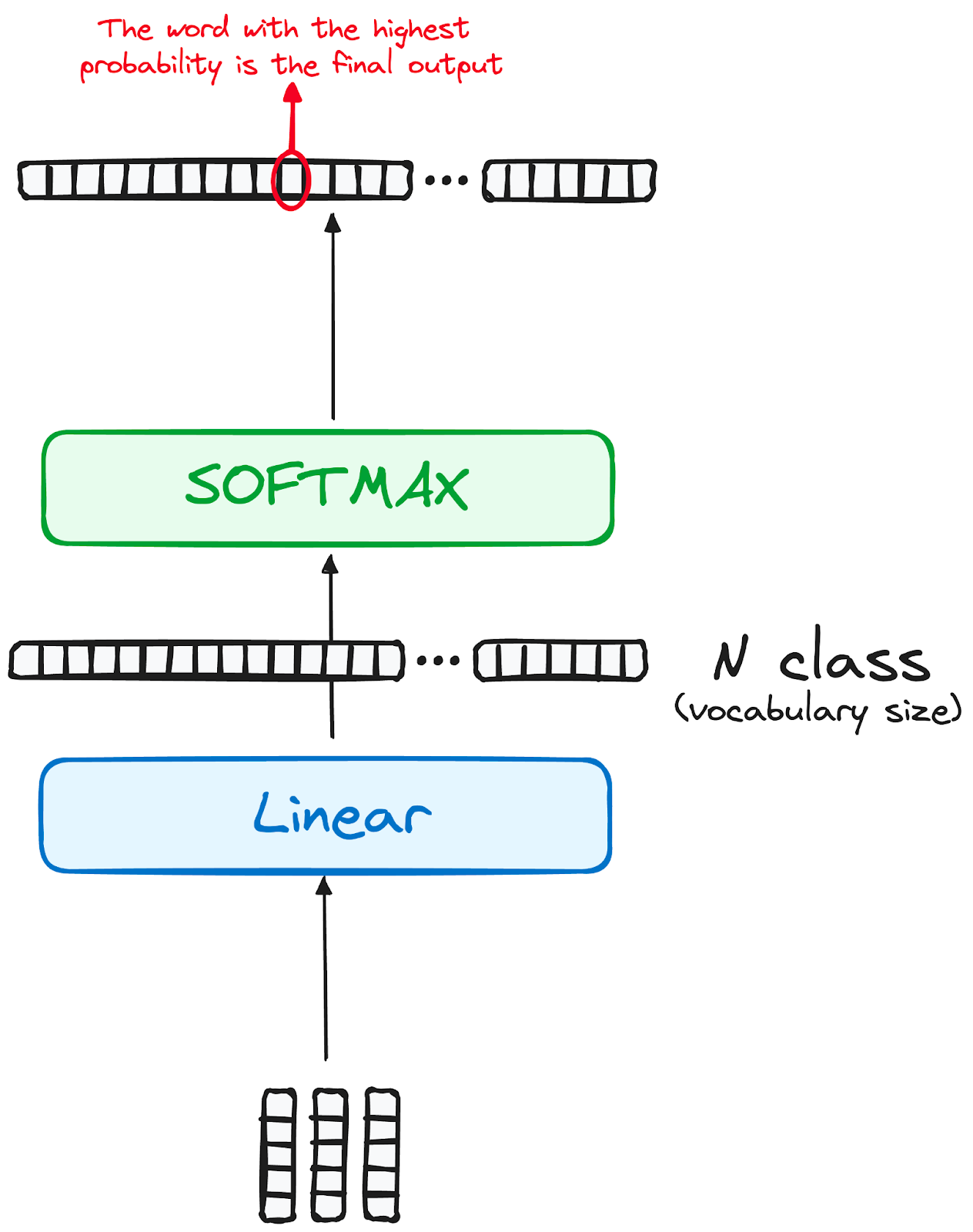
Afbeelding door de auteur. Workflow van de decoder. Einde-output van de Transformer.
Op elke sublaag (gemaskeerde self-attention, encoder–decoder attention, feedforward-netwerk) volgt een normalisatiestap, en elke sublaag heeft ook een residuele verbinding eromheen.
De output van de laatste laag wordt omgezet in een voorspelde sequentie, typisch via een lineaire laag gevolgd door softmax om waarschijnlijkheden over de woordenschat te genereren.
De decoder voegt in zijn operationele flow de zojuist gegenereerde output toe aan zijn groeiende lijst inputs en gaat dan verder met het decoderen. Deze cyclus herhaalt zich totdat het model een specifiek token voorspelt dat het einde aangeeft.
Het token met de hoogste voorspelde waarschijnlijkheid wordt toegewezen als de afsluitende klasse, vaak gerepresenteerd door het eindtoken.
Onthoud opnieuw dat de decoder niet is beperkt tot een enkele laag. Hij kan worden opgebouwd met N lagen, waarbij elke laag voortbouwt op de input van de encoder en de voorgaande lagen. Deze gelaagde architectuur stelt het model in staat de focus te variëren en verschillende attention-patronen te extraheren over de attention-heads.
Zo’n meerlagige aanpak kan het voorspellend vermogen van het model aanzienlijk verbeteren doordat het een genuanceerder begrip ontwikkelt van verschillende attention-combinaties.
De uiteindelijke architectuur ziet er zo uit (uit de oorspronkelijke paper):
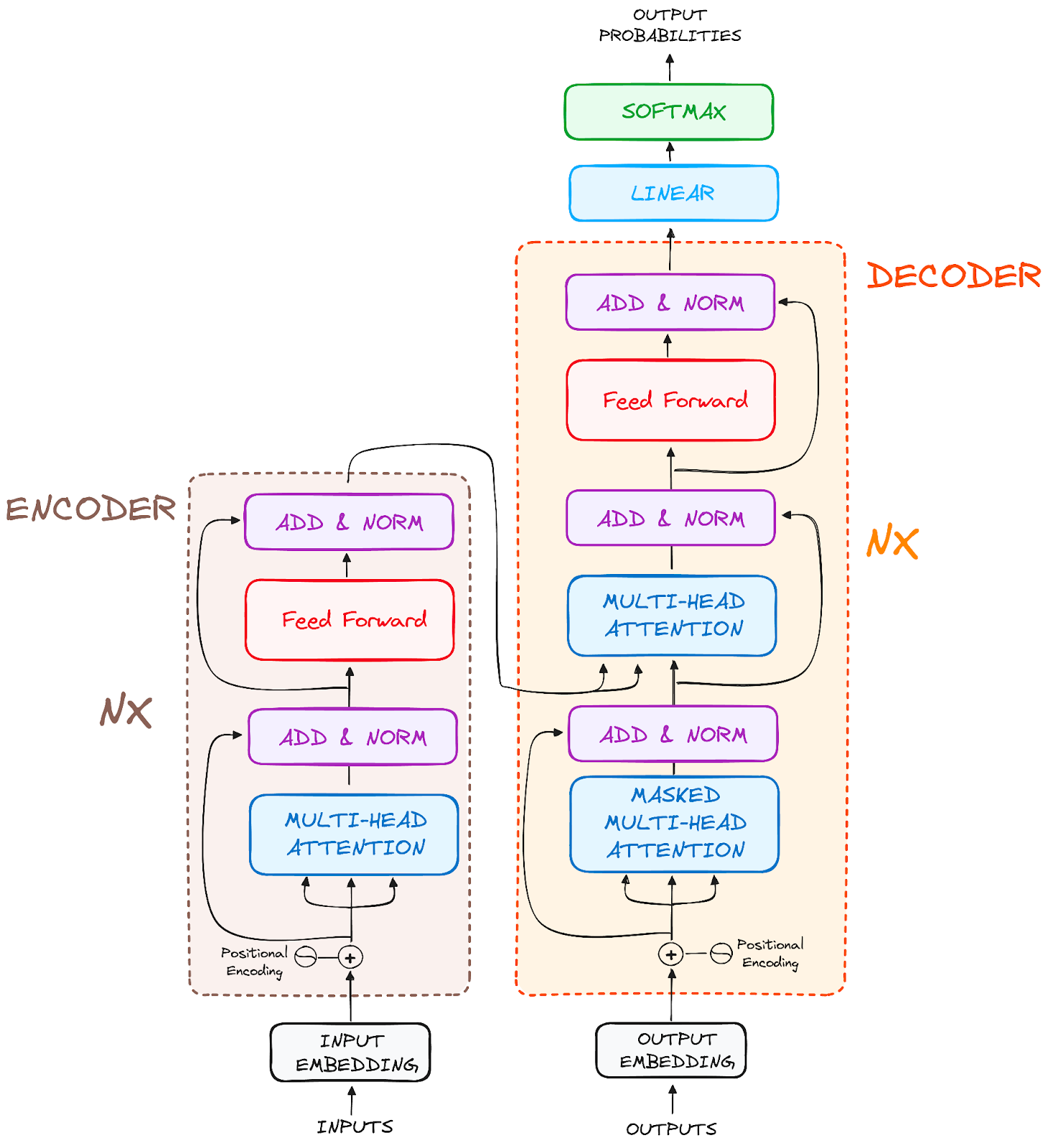
Afbeelding door de auteur. Oorspronkelijke structuur van Transformers.
Om deze architectuur beter te begrijpen, raad ik aan om een Transformer from scratch toe te passen met deze tutorial om een transformer met PyTorch te bouwen.
Googles open-source release van BERT in 2018, een framework voor natuurlijke taalverwerking, zorgde voor een revolutie in NLP met zijn unieke bidirectionele training, die het model in staat stelt contextrijkere voorspellingen te doen over wat het volgende woord moet zijn.
Door context van beide kanten van een woord te begrijpen, presteerde BERT beter dan eerdere modellen op taken als vraagbeantwoording en het begrijpen van dubbelzinnige taal. De kern maakt gebruik van Transformers, die elk output- en inputelement dynamisch verbinden.
BERT, voorgetraind op Wikipedia, blonk uit in diverse NLP-taken, waardoor Google het integreerde in zijn zoekmachine voor natuurlijker zoekopdrachten. Deze innovatie ontketende een wedloop om geavanceerde taalmodellen te ontwikkelen en bracht het vakgebied aanzienlijk verder in het omgaan met complexe taalbegripstaken.
Wil je meer weten over BERT, bekijk dan ons aparte artikel dat het BERT-model introduceert.
LaMDA (Language Model for Dialogue Applications) is een Transformer-gebaseerd model ontwikkeld door Google, specifiek ontworpen voor conversatietaken en gelanceerd tijdens de Google I/O-keynote van 2021. Het is ontworpen om natuurlijkere en contextueel relevantere antwoorden te genereren en zo interacties in verschillende applicaties te verbeteren.
De opzet van LaMDA stelt het in staat een breed scala aan onderwerpen en gebruikersintenties te begrijpen en te beantwoorden, waardoor het ideaal is voor toepassingen in chatbots, virtuele assistenten en andere interactieve AI-systemen waar een dynamisch gesprek centraal staat.
Deze focus op conversatiebegrip en -reactie maakt LaMDA tot een belangrijke sprong voorwaarts in NLP en AI-gestuurde communicatie.
Als je LaMDA-modellen verder wilt begrijpen, krijg je meer inzicht met ons artikel over LaMDA.
GPT en ChatGPT, ontwikkeld door OpenAI, zijn geavanceerde generatieve modellen die bekendstaan om hun vermogen om coherente en contextueel relevante tekst te produceren. GPT-1 was het eerste model, gelanceerd in juni 2018, en GPT-3, een van de meest impactvolle modellen, werd twee jaar later in 2020 gelanceerd.
Deze modellen zijn bedreven in uiteenlopende taken, waaronder contentcreatie, conversatie, vertaling en meer. De architectuur van GPT stelt het in staat tekst te genereren die sterk lijkt op menselijke schrijfstijl, wat het nuttig maakt voor creatieve schrijfhulp, klantenondersteuning en zelfs code-assistentie. ChatGPT, een variant geoptimaliseerd voor conversatie, blinkt uit in het genereren van mensachtige dialogen, wat het bijzonder geschikt maakt voor chatbots en virtuele assistenten.
Claude, ontwikkeld door Anthropic, is een familie van Transformer-gebaseerde AI-assistenten met een focus op veiligheid en behulpzaamheid. Claude gebruikt Constitutional AI (CAI), een trainingsaanpak waarbij het model wordt geleid door een set principes om behulpzame, onschadelijke en eerlijke antwoorden te produceren.
Claude 3 (uitgebracht in 2024) introduceerde drie modelniveaus, Haiku, Sonnet en Opus, met elk een andere balans tussen snelheid en capaciteit. De modellen blinken uit in genuanceerd redeneren, het volgen van complexe instructies en het vasthouden van context over lange gesprekken (tot 200K tokens).
In 2025 en 2026 lanceerde Anthropic de Claude 4-modellen, waarvan de meest recente, Opus 4.6 en Sonnet 4.6, vele LLM-benchmarks aanvoerden.
Het landschap van foundation-modellen, met name transformer-modellen, breidt zich snel uit. Een studie identificeerde meer dan 50 belangrijke transformer-modellen, terwijl de Stanford-groep er 30 evalueerde en de snelle groei van het veld erkende. NLP Cloud, een innovatieve startup in NVIDIA's Inception-programma, gebruikt commercieel zo’n 25 grote taalmodellen voor diverse sectoren zoals luchtvaart en apotheken.
Er is een toenemende trend om deze modellen open-source te maken, met platforms zoals de modelhub van Hugging Face die hierin vooroplopen. Daarnaast zijn tal van Transformer-gebaseerde modellen ontwikkeld, elk gespecialiseerd voor verschillende NLP-taken, wat de veelzijdigheid en efficiëntie van het model in uiteenlopende toepassingen laat zien.
Je kunt meer leren over alle bestaande Foundation Models in een apart artikel, dat uitlegt wat ze zijn en welke het meest worden gebruikt.
Sinds de oorspronkelijke architectuur uit 2017 zijn Transformers aanzienlijk geëvolueerd om beperkingen aan te pakken en uit te breiden naar nieuwe domeinen.
Vision Transformers passen het self-attention-mechanisme toe op afbeeldingen door ze op te delen in patches en elke patch als token te behandelen. Deze aanpak is zeer effectief gebleken voor beeldclassificatie, objectdetectie en beeldgeneratie, en overtreft vaak traditionele CNN’s op grote datasets.
Moderne modellen zoals GPT-5, Gemini 3 en Llama 4 verwerken meerdere inputtypen (tekst, afbeeldingen, audio, video) binnen één architectuur. Deze multimodale Transformers gebruiken uniforme embeddingsruimtes en cross-attention-mechanismen om simultaan over verschillende modaliteiten te redeneren.
De kwadratische complexiteit van self-attention beperkt de contextlengte. Verscheidene innovaties pakken dit aan:
Het benchmarken en evalueren van de prestaties van Transformer-modellen in NLP vereist een systematische aanpak om effectiviteit en efficiëntie te beoordelen.
Afhankelijk van de aard van de taak zijn er verschillende manieren en middelen:
Bij machinale vertaling kun je gebruikmaken van standaarddatasets zoals WMT (Workshop on Machine Translation), waar MT-systemen te maken krijgen met een lappendeken van taalkoppels, elk met eigen uitdagingen.
Metrieken zoals BLEU, METEOR, TER en chrF dienen als navigatiemiddelen die richting geven aan nauwkeurigheid en vloeiendheid.
Daarnaast zorgt testen in diverse domeinen zoals nieuws, literatuur en technische teksten ervoor dat een MT-systeem zich kan aanpassen en veelzijdig is — een ware polyglot in de digitale wereld.
Voor het evalueren van QA-modellen gebruiken we speciale verzamelingen van vragen en antwoorden, zoals SQuAD (Stanford Question Answering Dataset), Natural Questions of TriviaQA.
Elke set is als een ander spel met eigen regels. SQuAD draait bijvoorbeeld om het vinden van antwoorden in een gegeven tekst, terwijl andere meer lijken op een quiz met vragen uit allerlei bronnen.
Om te zien hoe goed deze programma’s presteren, gebruiken we scores zoals Precision, Recall, F1 en soms zelfs exact match-scores.
Bij Natural Language Inference (NLI) gebruiken we datasets zoals SNLI (Stanford Natural Language Inference), MultiNLI en ANLI.
Dit zijn als grote bibliotheken met taalvariaties en lastige gevallen, waarmee we zien hoe goed computers verschillende soorten zinnen begrijpen. We kijken vooral naar de nauwkeurigheid bij het bepalen of uitspraken overeenkomen, tegenspreken of niet gerelateerd zijn.
Het is ook belangrijk te kijken hoe het systeem omgaat met lastige taalverschijnselen, zoals verwijzingen naar eerder genoemde zaken, of het begrijpen van ‘niet’, ‘alle’ en ‘sommige’.
In de wereld van neurale netwerken worden twee prominente structuren vaak vergeleken met Transformers. Elk biedt eigen voordelen en uitdagingen, afgestemd op specifieke soorten dataverwerking. RNN’s, die al meerdere keren in dit artikel zijn genoemd, en Convolutional Layers.
Recurrente lagen, de ruggengraat van Recurrent Neural Networks (RNN’s), blinken uit in het verwerken van sequentiële data. De kracht van deze architectuur ligt in het uitvoeren van sequentiële bewerkingen, cruciaal voor taken zoals taalverwerking of tijdreeksanalyse. In een recurrente laag wordt de output van een vorige stap teruggevoerd als input voor de volgende stap. Dit lusmechanisme laat het netwerk eerdere informatie onthouden, wat essentieel is voor contextbegrip in een sequentie.
Zoals we al bespraken, heeft deze sequentiële verwerking twee belangrijke implicaties:
Transformer-modellen verschillen significant van architecturen met recurrente lagen omdat ze geen recurrency hebben. Zoals we zagen, pakt de Attention-laag van de Transformer beide problemen aan, waardoor ze de natuurlijke evolutie van RNN’s zijn voor NLP-toepassingen.
Convolutionele lagen, de bouwstenen van Convolutional Neural Networks (CNN’s), staan daarentegen bekend om hun efficiëntie bij het verwerken van ruimtelijke data zoals afbeeldingen.
Deze lagen gebruiken kernels (filters) die over de inputdata schuiven om kenmerken te extraheren. De breedte van deze kernels kan worden aangepast, zodat het netwerk zich kan richten op kleine of grote kenmerken, afhankelijk van de taak.
Hoewel convolutionele lagen uitstekend zijn in het vastleggen van ruimtelijke hiërarchieën en patronen in data, hebben ze moeite met langetermijnafhankelijkheden. Ze houden niet inherent rekening met sequentiële informatie, waardoor ze minder geschikt zijn voor taken die begrip van volgorde of context vereisen.
Daarom zijn CNN’s en Transformers geschikt voor verschillende soorten data en taken. CNN’s domineren in computervisie door hun efficiëntie in het verwerken van ruimtelijke informatie, terwijl Transformers de voorkeurskeuze zijn voor complexe sequentietaken, vooral in NLP, vanwege hun vermogen om langeafstandsafhankelijkheden te begrijpen.
Ondanks hun succes hebben Transformers duidelijke beperkingen:
Onderzoek blijft deze beperkingen aanpakken met architecturale innovaties zoals Flash Attention, mixture-of-experts en retrieval-augmented generation (RAG).
Kortom, Transformers zijn uitgegroeid tot een monumentale doorbraak in kunstmatige intelligentie en natuurlijke taalverwerking (NLP).
Door sequentiële data effectief te beheren via hun unieke self-attention-mechanisme, hebben deze modellen traditionele RNN’s overtroffen. Hun vermogen om lange sequenties efficiënter te verwerken en dataverwerking te paralleliseren versnelt de training aanzienlijk.
Baanbrekende modellen als Googles BERT en OpenAI’s GPT-serie illustreren de transformerende impact van Transformers op zoekmachines en het genereren van mensachtige tekst.
Daardoor zijn ze onmisbaar geworden in moderne machine learning, waarmee ze de grenzen van AI verleggen en nieuwe mogelijkheden openen in technologische vooruitgang.
Wil je je verdiepen in Transformers en hun praktische toepassingen, dan is ons artikel over Transformers en Hugging Face een perfect startpunt! Je kunt ook leren hoe je een Transformer met PyTorch bouwt met onze diepgaande gids.
Leer meer over Transformers en LLM’s!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
