
Courses
Các khái niệm về Large Language Models (LLMs)
2 giờ
104K
Transformer ban đầu được phát triển để giải quyết bài toán chuyển dịch chuỗi (sequence transduction), hay dịch máy bằng mạng nơ-ron, nghĩa là chúng được thiết kế để giải mọi tác vụ biến đổi một chuỗi đầu vào thành một chuỗi đầu ra. Đó là lý do chúng được gọi là “Transformer”.
Nhưng hãy bắt đầu từ những điều cơ bản.
Transformer là một mạng nơ-ron học bối cảnh của dữ liệu tuần tự và từ đó sinh dữ liệu mới.
Nói đơn giản:
Transformer là một loại mô hình trí tuệ nhân tạo học cách hiểu và tạo văn bản giống con người bằng cách phân tích các mẫu trong lượng dữ liệu văn bản lớn.
Transformer hiện là mô hình NLP tối tân và được xem là sự tiến hóa của kiến trúc encoder-decoder. Tuy nhiên, trong khi kiến trúc encoder-decoder chủ yếu dựa vào Mạng Nơ-ron Hồi quy (RNN) để trích xuất thông tin tuần tự, Transformer hoàn toàn không có tính lặp này.
Vậy, chúng làm điều đó như thế nào?
Chúng được thiết kế đặc biệt để hiểu ngữ cảnh và ý nghĩa bằng cách phân tích mối quan hệ giữa các phần tử khác nhau, và gần như hoàn toàn dựa vào một kỹ thuật toán học gọi là attention (chú ý) để thực hiện.

Hình do tác giả cung cấp.
Bắt nguồn từ bài báo năm 2017 của Google, các mô hình transformer là một trong những phát triển mới nhất và có ảnh hưởng nhất trong lĩnh vực Học máy. Mô hình Transformer đầu tiên được trình bày trong bài báo có ảnh hưởng "Attention is All You Need".
Khái niệm tiên phong này không chỉ là tiến bộ lý thuyết mà còn được triển khai thực tiễn, đáng chú ý trong gói Tensor2Tensor của TensorFlow. Hơn nữa, nhóm Harvard NLP đã đóng góp cho lĩnh vực đang nở rộ này bằng cách cung cấp bản hướng dẫn có chú thích cho bài báo, kèm theo bản cài đặt bằng PyTorch. Bạn có thể tìm hiểu thêm về cách triển khai Transformer từ đầu trong hướng dẫn riêng của chúng tôi.
Sự ra đời của chúng đã thúc đẩy một làn sóng lớn trong lĩnh vực này, thường được gọi là Transformer AI. Mô hình cách mạng này đặt nền móng cho những đột phá tiếp theo trong các mô hình ngôn ngữ lớn, bao gồm BERT. Đến năm 2018, những phát triển này đã được ca ngợi là cột mốc bước ngoặt trong NLP.
Năm 2020, các nhà nghiên cứu tại OpenAI công bố GPT-3. Chỉ trong vài tuần, tính linh hoạt của GPT-3 nhanh chóng được chứng minh khi mọi người dùng nó để tạo thơ, chương trình, bài hát, trang web và nhiều hơn nữa, khơi gợi trí tưởng tượng của người dùng toàn cầu. Quan sát sự chuyển dịch này, các học giả Stanford đã xuất bản một bài báo năm 2021, đặt tên thích đáng cho những đổi mới này là "mô hình nền tảng," nhấn mạnh vai trò then chốt của chúng trong việc tái định hình AI.
Trong khi các mô hình độc quyền thu hút sự chú ý công chúng ban đầu, một cuộc cách mạng mã nguồn mở song song đã nhanh chóng dân chủ hóa công nghệ transformer. Các nền tảng như Hugging Face nổi lên như các trung tâm quan trọng để chia sẻ mô hình, nhưng bối cảnh đã thay đổi căn bản vào năm 2023 với việc phát hành dòng Llama của Meta. Điều này châm ngòi cho phong trào "open-weights", chứng minh các nhà phát triển không còn cần phụ thuộc vào hệ sinh thái doanh nghiệp đóng để xây dựng AI tối tân.
Xuyên suốt 2024 và 2025, phát triển mã nguồn mở tăng tốc mạnh mẽ. Các mô hình như Llama 3.1 siêu lớn của Meta và loạt Llama 4 sau đó, cùng các kiến trúc hiệu quả cao từ các startup như Mistral và các mô hình suy luận mạnh từ DeepSeek, đã chứng minh mô hình mở có thể sánh ngang, thậm chí đôi khi vượt, hiệu năng của các ông lớn độc quyền.
Trong khi đó, các mô hình đóng vẫn tiếp tục phát triển năng lực phức tạp. GPT-4 năm 2023, giới thiệu khả năng đa phương thức, và GPT-4o năm 2024, hợp nhất xử lý văn bản, thị giác và âm thanh trong một mô hình duy nhất.
Cuối 2024 đánh dấu một bước ngoặt cơ bản khác trong toàn ngành với các mô hình như dòng o1 của OpenAI và R1 mở của DeepSeek, đưa vào một 'chuỗi suy nghĩ' nội bộ để suy luận qua logic và toán học phức tạp trước khi phản hồi.
Đến cuối 2025 và sang 2026, bối cảnh chuyển dịch hoàn toàn từ trợ lý hội thoại sang hệ thống tự động với việc ra mắt dòng GPT-5, mang đến lập kế hoạch đa bước tiên tiến, bộ nhớ dài hạn và quy trình tác tử mạnh mẽ cho hạ tầng doanh nghiệp.
Tại thời điểm Transformer ra đời, Mạng Nơ-ron Hồi quy (RNN) là cách tiếp cận ưa thích để xử lý dữ liệu tuần tự, vốn đặc trưng bởi thứ tự cụ thể trong đầu vào.
RNN hoạt động tương tự mạng feed-forward nhưng xử lý đầu vào tuần tự, từng phần tử một.
Transformer lấy cảm hứng từ kiến trúc encoder-decoder trong RNN. Tuy nhiên, thay vì dùng tính lặp, Transformer hoàn toàn dựa trên cơ chế Attention.
Bên cạnh việc cải thiện hiệu năng RNN, Transformer còn mang lại kiến trúc mới để giải nhiều tác vụ khác như tóm tắt văn bản, tạo chú thích ảnh và nhận dạng giọng nói.
Vậy những vấn đề chính của RNN là gì? Chúng kém hiệu quả cho NLP vì hai lý do chính:
Sự chuyển dịch từ RNN như LSTM sang Transformer trong NLP được thúc đẩy bởi hai vấn đề này và khả năng của Transformer giải quyết cả hai nhờ cải tiến cơ chế Attention:
Vì vậy, Transformer trở thành bước tiến tự nhiên từ RNN.
Tiếp theo, hãy xem transformer hoạt động như thế nào.
Ban đầu được nghĩ ra cho chuyển dịch chuỗi hoặc dịch máy bằng mạng nơ-ron, transformer xuất sắc trong việc chuyển đổi chuỗi đầu vào thành chuỗi đầu ra. Đây là mô hình chuyển dịch đầu tiên dựa hoàn toàn vào tự chú ý để tính biểu diễn của đầu vào và đầu ra mà không dùng RNN căn chỉnh theo chuỗi hay tích chập. Đặc điểm cốt lõi của kiến trúc Transformer là duy trì mô hình encoder-decoder.
Nếu xem Transformer cho dịch ngôn ngữ như một hộp đen đơn giản, nó sẽ nhận một câu ở một ngôn ngữ, chẳng hạn tiếng Anh, làm đầu vào và xuất ra bản dịch bằng tiếng Anh.

Hình do tác giả cung cấp.
Nếu đi sâu hơn một chút, ta thấy hộp đen này gồm hai phần chính:
Hình do tác giả cung cấp. Cấu trúc tổng thể Encoder-Decoder.
Tuy nhiên, cả encoder và decoder thực chất là một chồng nhiều lớp (cùng số lượng cho mỗi bên). Tất cả encoder có cùng cấu trúc, đầu vào đi vào từng cái và được truyền lên cái tiếp theo. Tất cả decoder cũng có cấu trúc giống nhau và nhận đầu vào từ encoder cuối cùng và decoder trước đó.
Kiến trúc gốc gồm 6 encoder và 6 decoder, nhưng ta có thể lặp lại bao nhiêu lớp tùy ý. Hãy giả sử có N lớp cho mỗi bên.
Hình do tác giả cung cấp. Cấu trúc tổng thể Encoder-Decoder. Nhiều lớp.
Giờ khi đã có cái nhìn tổng quan, hãy tập trung vào Encoder và Decoder để hiểu rõ hơn luồng hoạt động của chúng:
Encoder là thành phần nền tảng của kiến trúc Transformer. Chức năng chính của encoder là biến đổi các token đầu vào thành các biểu diễn theo ngữ cảnh. Không như các mô hình trước xử lý token độc lập, encoder của Transformer nắm bắt ngữ cảnh của mỗi token so với toàn chuỗi.
Cấu trúc của nó gồm những phần sau:
Hình do tác giả cung cấp. Cấu trúc tổng thể của Encoder.
Hãy chia nhỏ quy trình thành các bước cơ bản nhất:
Embedding chỉ diễn ra ở encoder dưới cùng. Encoder bắt đầu bằng việc chuyển các token đầu vào — từ hoặc subword — thành vector bằng các lớp embedding. Các embedding này nắm bắt ý nghĩa ngữ nghĩa của token và chuyển chúng thành vector số.
Tất cả encoder nhận một danh sách vector, mỗi vector kích thước 512 (cố định). Ở encoder dưới cùng, đó là word embedding, còn ở các encoder khác, đó là đầu ra của encoder ngay bên dưới.
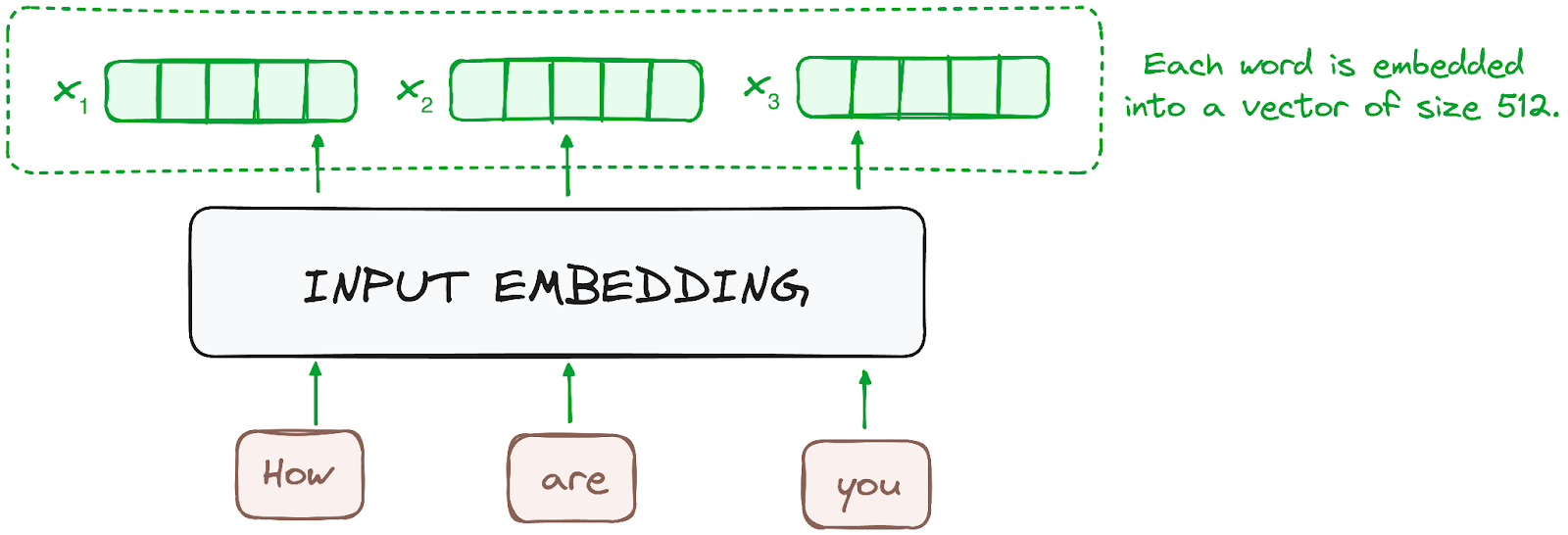
Hình do tác giả cung cấp. Quy trình Encoder. Input embedding.
Vì Transformer không có cơ chế lặp như RNN, chúng dùng mã hóa vị trí cộng vào embedding đầu vào để cung cấp thông tin về vị trí của mỗi token trong chuỗi. Điều này cho phép hiểu vị trí của mỗi từ trong câu.
Để làm vậy, các nhà nghiên cứu đề xuất dùng tổ hợp các hàm sin và cos để tạo vector vị trí, cho phép sử dụng bộ mã hóa vị trí này cho câu có độ dài bất kỳ.
Trong cách tiếp cận này, mỗi chiều được biểu diễn bởi tần số và độ lệch pha riêng, với giá trị từ -1 đến 1, biểu diễn hiệu quả từng vị trí.
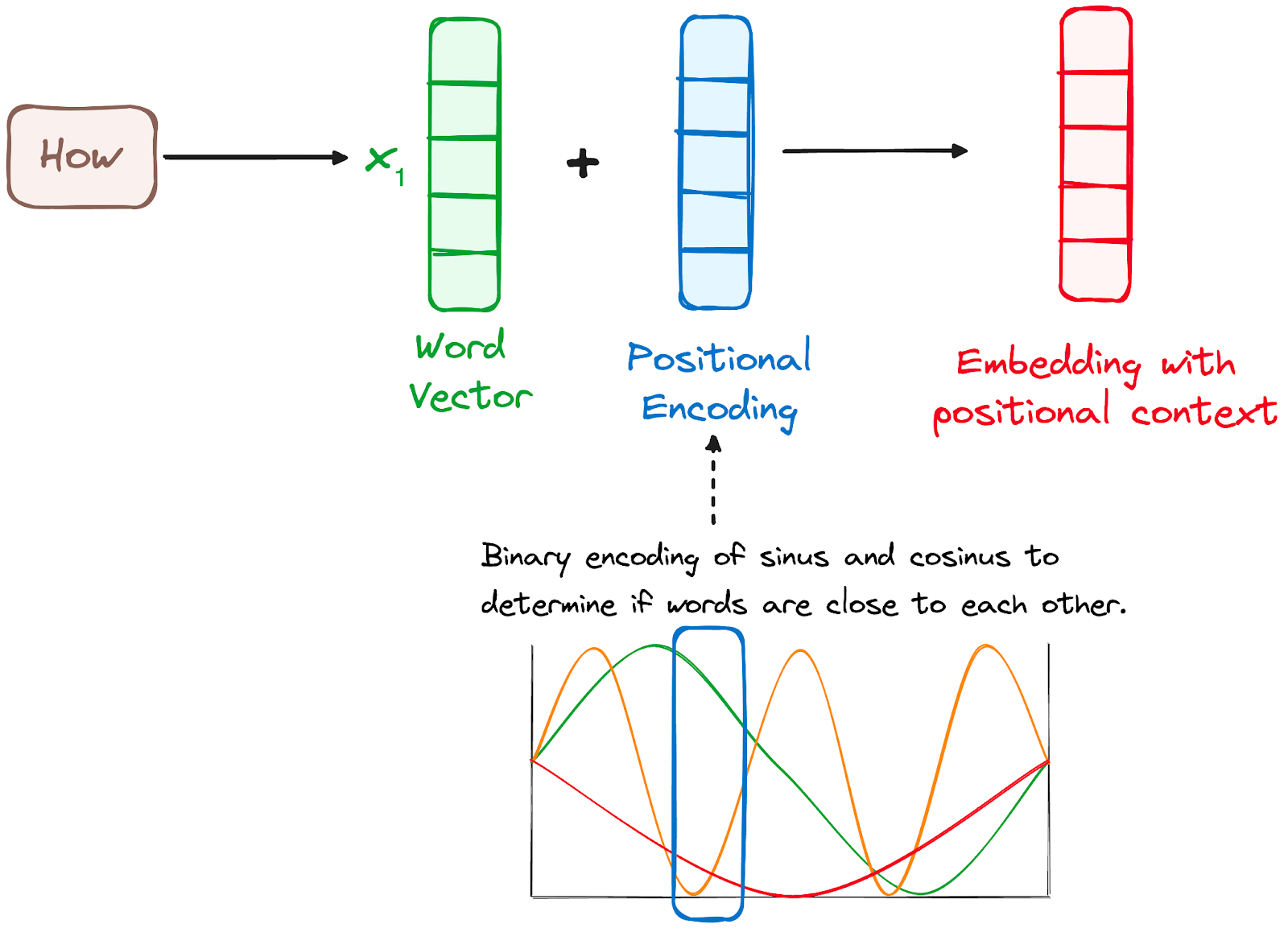
Hình do tác giả cung cấp. Quy trình Encoder. Positional encoding.
Encoder của Transformer gồm một chồng các lớp giống hệt nhau (6 lớp trong mô hình gốc).
Lớp encoder có nhiệm vụ biến đổi toàn bộ chuỗi đầu vào thành một biểu diễn liên tục, trừu tượng, bao quát thông tin học được từ toàn chuỗi. Lớp này gồm hai tiểu mô-đun:
Ngoài ra, nó còn có kết nối dư quanh mỗi tiểu lớp, sau đó là chuẩn hóa lớp.
Hình do tác giả cung cấp. Quy trình Encoder. Chồng các lớp Encoder
Trong encoder, attention đa đầu sử dụng một cơ chế chú ý chuyên biệt gọi là tự chú ý (self-attention). Cách tiếp cận này cho phép mô hình liên hệ mỗi từ trong đầu vào với các từ khác. Ví dụ, trong một câu, mô hình có thể học liên kết từ “are” với “you”.
Cơ chế này cho phép encoder tập trung vào các phần khác nhau của chuỗi đầu vào khi xử lý từng token. Nó tính điểm chú ý dựa trên:
Mô-đun Self-Attention đầu tiên này cho phép mô hình nắm bắt thông tin ngữ cảnh từ toàn chuỗi. Thay vì thực hiện một hàm attention duy nhất, các query, key và value được chiếu tuyến tính h lần. Trên mỗi phiên bản đã chiếu này, cơ chế attention được thực hiện song song, tạo ra các giá trị đầu ra h chiều.
Kiến trúc chi tiết như sau:
Khi các vector query, key và value đi qua một lớp tuyến tính, phép nhân ma trận tích vô hướng được thực hiện giữa query và key, tạo ra ma trận điểm số.
Ma trận điểm số xác lập mức độ mỗi từ nên nhấn mạnh các từ khác. Vì vậy, mỗi từ được gán điểm liên quan đến các từ khác trong cùng bước thời gian. Điểm cao hơn đồng nghĩa tập trung nhiều hơn.
Quá trình này hiệu quả ánh xạ các query tới key tương ứng.
Hình do tác giả cung cấp. Quy trình Encoder. Attention - Nhân ma trận.
Các điểm số sau đó được chia cho căn bậc hai của kích thước vector query và key để giảm tỉ lệ. Bước này giúp gradient ổn định hơn, vì phép nhân các giá trị có thể dẫn tới hiệu ứng quá lớn.
Hình do tác giả cung cấp. Quy trình Encoder. Giảm điểm chú ý.
Sau đó, hàm softmax được áp dụng lên các điểm đã điều chỉnh để thu được trọng số chú ý. Kết quả là các xác suất từ 0 đến 1. Softmax nhấn mạnh điểm cao và làm giảm điểm thấp, giúp mô hình xác định hiệu quả từ nào cần chú ý hơn.
Hình do tác giả cung cấp. Quy trình Encoder. Softmax cho điểm điều chỉnh.
Bước tiếp theo là nhân các trọng số thu được từ softmax với vector value, tạo ra một vector đầu ra.
Trong quá trình này, chỉ các từ có điểm softmax cao được giữ lại. Cuối cùng, vector đầu ra này đi vào một lớp tuyến tính để xử lý tiếp.
Hình do tác giả cung cấp. Quy trình Encoder. Kết hợp kết quả Softmax với vector value.
Và cuối cùng ta có đầu ra của cơ chế Attention!
Vậy vì sao gọi là Multi-Head Attention?
Hãy nhớ rằng trước khi quá trình bắt đầu, ta tách query, key và value thành h phần. Quá trình này, gọi là self-attention, diễn ra riêng biệt trong từng giai đoạn nhỏ hay 'đầu' này. Mỗi đầu hoạt động độc lập, tạo ra một vector đầu ra.
Tập hợp này đi qua một lớp tuyến tính cuối, giống như một bộ lọc tinh chỉnh hiệu năng tổng thể. Điểm hay nằm ở sự đa dạng học hỏi giữa các đầu, làm phong phú hiểu biết của encoder.
Để hiểu sâu hơn về cơ chế attention, xem hướng dẫn về multi-head attention trong Transformer.
Mỗi tiểu lớp trong một lớp encoder được theo sau bởi bước chuẩn hóa. Đồng thời, đầu ra của mỗi tiểu lớp được cộng với đầu vào của nó (kết nối dư) để giảm vấn đề mất mát gradient, cho phép mô hình sâu hơn. Quá trình này cũng được lặp lại sau Mạng Nơ-ron Feed-Forward.
Hình do tác giả cung cấp. Quy trình Encoder. Chuẩn hóa và kết nối dư sau Multi-Head Attention.
Đầu ra đã được chuẩn hóa-kèm-dư tiếp tục đi qua một mạng feed-forward theo điểm (pointwise), một giai đoạn quan trọng để tinh chỉnh thêm.
Hãy hình dung mạng này như một cặp lớp tuyến tính, với một kích hoạt ReLU ở giữa đóng vai trò cầu nối. Sau khi xử lý, đầu ra quay trở lại và trộn với đầu vào của mạng feed-forward theo điểm.
Sự tái hợp này được theo sau bởi một lần chuẩn hóa nữa, bảo đảm mọi thứ được điều chỉnh tốt và đồng bộ cho các bước tiếp theo.
Hình do tác giả cung cấp. Quy trình Encoder. Tiểu lớp Feed-Forward.
Đầu ra của lớp encoder cuối là một tập vector, mỗi vector biểu diễn chuỗi đầu vào với hiểu biết ngữ cảnh phong phú. Đầu ra này được dùng làm đầu vào cho decoder trong mô hình Transformer.
Việc mã hóa cẩn thận này mở đường cho decoder, dẫn dắt nó chú ý đúng từ trong đầu vào khi giải mã.
Hãy hình dung như xây một tòa tháp, nơi bạn có thể xếp chồng N lớp encoder. Mỗi lớp trong chồng có cơ hội khám phá và học các khía cạnh chú ý khác nhau, giống như các tầng tri thức. Điều này không chỉ đa dạng hóa hiểu biết mà còn có thể khuếch đại đáng kể khả năng dự đoán của mạng transformer.
Vai trò của decoder là tạo chuỗi văn bản. Phản chiếu encoder, decoder được trang bị bộ tiểu lớp tương tự. Nó có hai lớp attention đa đầu, một lớp feed-forward theo điểm, và kết hợp cả kết nối dư lẫn chuẩn hóa lớp sau mỗi tiểu lớp.
Hình do tác giả cung cấp. Cấu trúc tổng thể của Encoder.
Các thành phần này hoạt động tương tự các lớp của encoder, nhưng có một điểm khác: mỗi lớp attention đa đầu trong decoder có nhiệm vụ riêng.
Giai đoạn cuối của quy trình decoder gồm một lớp tuyến tính, đóng vai trò bộ phân loại, kèm theo hàm softmax để tính xác suất của các từ khác nhau.
Decoder của Transformer có cấu trúc được thiết kế đặc biệt để sinh đầu ra bằng cách giải mã thông tin đã mã hóa từng bước.
Lưu ý rằng decoder hoạt động theo kiểu tự hồi quy, khởi động với một token bắt đầu. Nó khéo léo dùng danh sách các đầu ra đã sinh trước làm đầu vào cho chính mình, cùng với đầu ra từ encoder giàu thông tin chú ý của đầu vào ban đầu.
Vũ điệu giải mã tuần tự này tiếp diễn cho đến khi decoder tạo ra token báo hiệu kết thúc quá trình sinh.
Ở vạch xuất phát của decoder, quy trình phản chiếu encoder. Tại đây, đầu vào trước tiên đi qua một lớp embedding
Sau embedding, tương tự encoder, đầu vào đi qua lớp mã hóa vị trí. Trình tự này tạo ra các positional embedding.
Những positional embedding này sau đó được đưa vào lớp attention đa đầu đầu tiên của decoder, nơi các điểm chú ý đặc thù cho đầu vào của decoder được tính toán cẩn thận.
Decoder gồm một chồng các lớp giống hệt nhau (6 lớp trong mô hình gốc). Mỗi lớp có ba tiểu thành phần chính:
Giống cơ chế tự chú ý trong encoder nhưng khác biệt then chốt: nó ngăn các vị trí chú ý tới các vị trí phía sau, tức mỗi từ trong chuỗi không bị ảnh hưởng bởi các token tương lai.
Ví dụ, khi tính điểm chú ý cho từ "are", điều quan trọng là "are" không được nhìn thấy "you", vốn là từ đứng sau trong chuỗi.
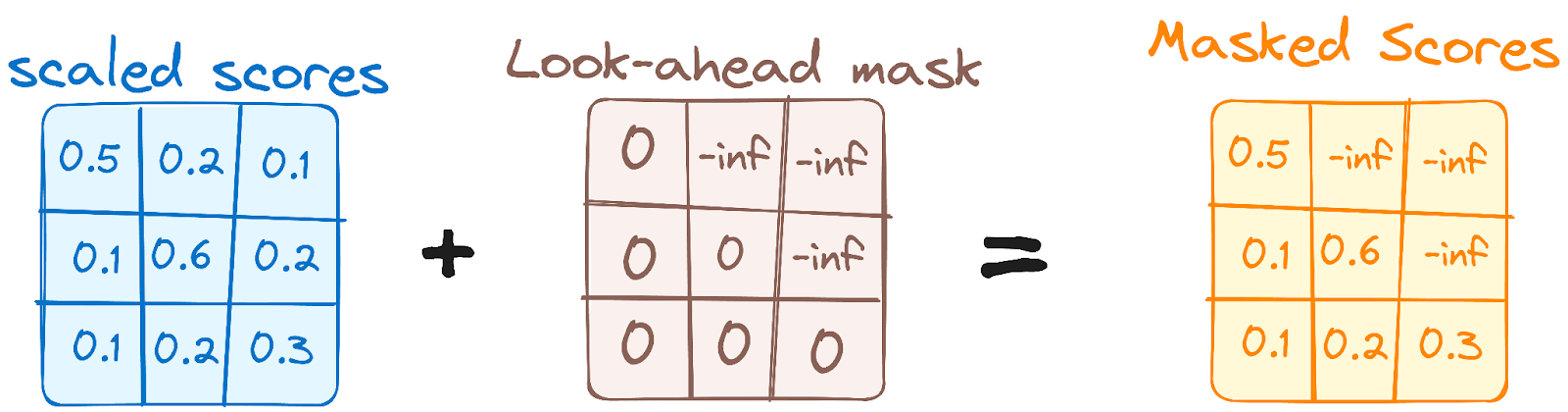
Hình do tác giả cung cấp. Quy trình Decoder. Lớp mặt nạ Multi-Head Attention đầu tiên.
Mặt nạ này đảm bảo dự đoán ở một vị trí chỉ phụ thuộc vào các đầu ra đã biết ở các vị trí trước đó.
Ở lớp attention đa đầu thứ hai của decoder, ta thấy sự tương tác độc đáo giữa thành phần encoder và decoder. Tại đây, đầu ra từ encoder đóng vai trò query và key, còn đầu ra từ lớp attention đa đầu thứ nhất của decoder đóng vai trò value.
Thiết lập này hiệu quả căn chỉnh đầu vào của encoder với decoder, giúp decoder nhận diện và nhấn mạnh những phần liên quan nhất của đầu vào encoder.
Sau đó, đầu ra từ lớp attention đa đầu thứ hai này được tinh chỉnh qua một lớp feed-forward theo điểm, tăng cường xử lý hơn nữa.
Hình do tác giả cung cấp. Quy trình Decoder. Attention Encoder-Decoder.
Trong tiểu lớp này, query đến từ lớp decoder trước đó, còn key và value đến từ đầu ra của encoder. Điều này cho phép mọi vị trí trong decoder chú ý tới tất cả vị trí trong chuỗi đầu vào, tích hợp hiệu quả thông tin từ encoder với thông tin trong decoder.
Tương tự encoder, mỗi lớp decoder bao gồm một mạng feed-forward fully connected, được áp dụng riêng rẽ và giống hệt cho mỗi vị trí.
Hành trình của dữ liệu qua mô hình transformer kết thúc khi đi qua lớp tuyến tính cuối, hoạt động như một bộ phân loại.
Kích thước của bộ phân loại tương ứng với tổng số lớp (số từ trong từ vựng). Ví dụ, với 1000 lớp đại diện cho 1000 từ khác nhau, đầu ra của bộ phân loại sẽ là một mảng 1000 phần tử.
Đầu ra này sau đó đi vào lớp softmax, biến đổi thành dải xác suất từ 0 đến 1. Xác suất cao nhất là then chốt, chỉ số tương ứng trỏ trực tiếp tới từ mà mô hình dự đoán là tiếp theo trong chuỗi.
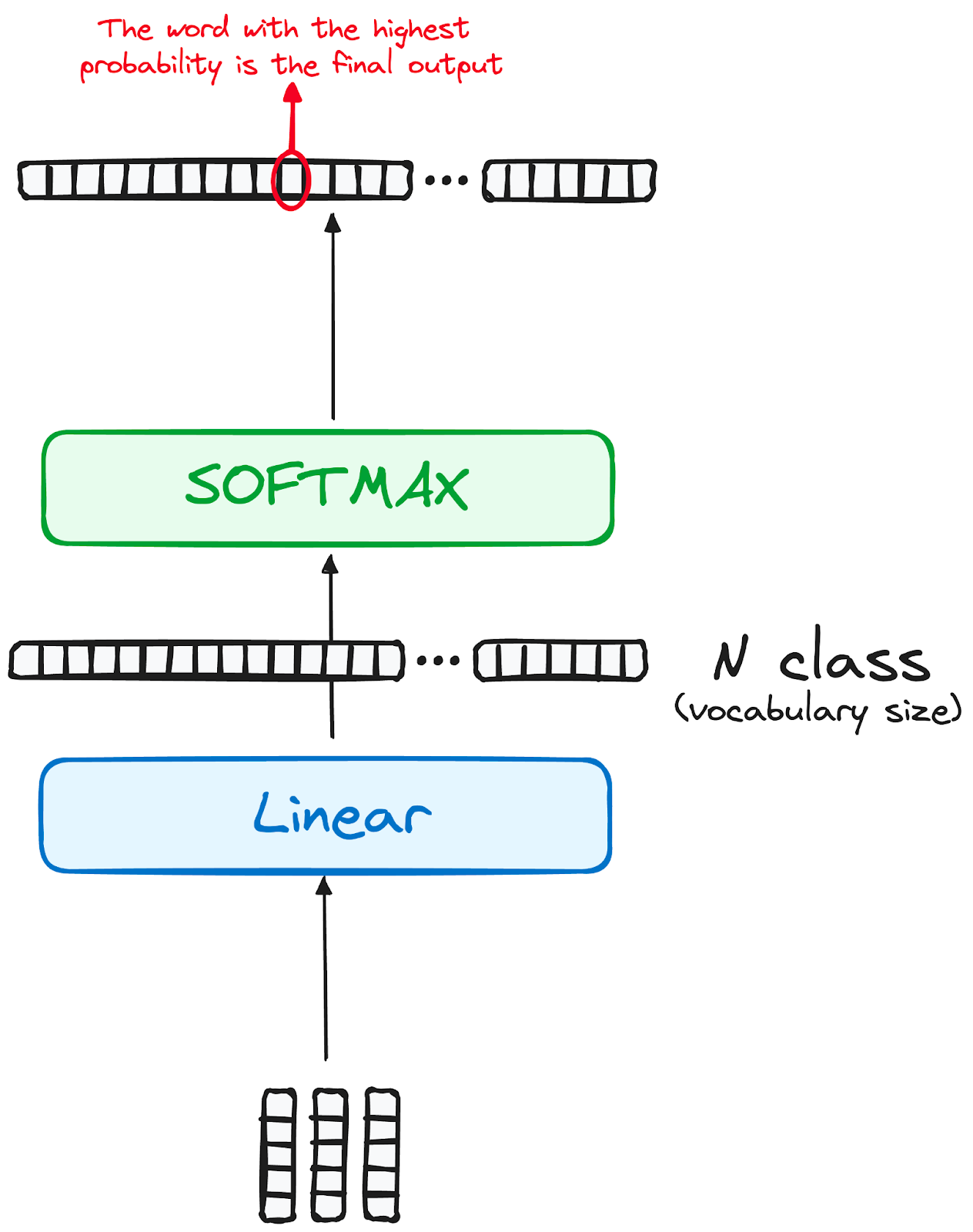
Hình do tác giả cung cấp. Quy trình Decoder. Đầu ra cuối của Transformer.
Mỗi tiểu lớp (tự chú ý có mặt nạ, attention encoder-decoder, mạng feed-forward) đều theo sau bởi bước chuẩn hóa, và mỗi tiểu lớp cũng có một kết nối dư bao quanh.
Đầu ra của lớp cuối được biến đổi thành chuỗi dự đoán, thường qua một lớp tuyến tính rồi softmax để sinh xác suất trên từ vựng.
Decoder, trong luồng vận hành, đưa đầu ra vừa sinh vào danh sách đầu vào đang tăng dần của nó, rồi tiếp tục giải mã. Chu trình lặp lại cho đến khi mô hình dự đoán một token cụ thể, báo hiệu hoàn tất.
Token có xác suất cao nhất được gán là lớp kết thúc, thường được biểu diễn bởi token kết thúc.
Hãy nhớ rằng decoder không bị giới hạn ở một lớp. Nó có thể được cấu trúc với N lớp, mỗi lớp xây dựng dựa trên đầu vào nhận từ encoder và các lớp trước đó. Kiến trúc nhiều lớp này cho phép mô hình đa dạng hóa tiêu điểm và trích xuất các mẫu chú ý khác nhau qua các đầu chú ý.
Cách tiếp cận nhiều lớp như vậy có thể tăng đáng kể khả năng dự đoán của mô hình, vì nó phát triển hiểu biết tinh tế hơn về các tổ hợp chú ý khác nhau.
Kiến trúc cuối cùng trông như sau (từ bài báo gốc):
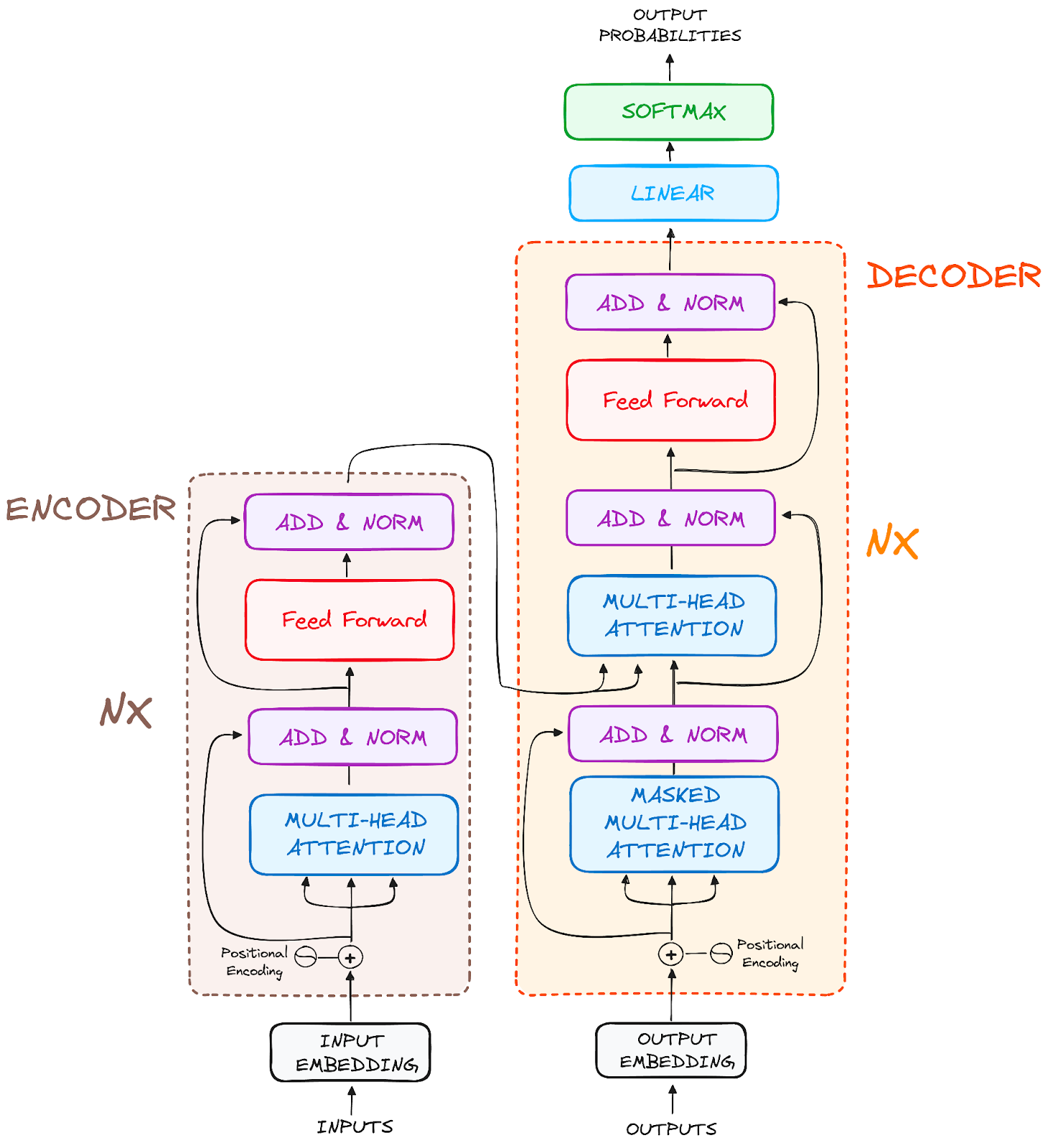
Hình do tác giả cung cấp. Cấu trúc gốc của Transformer.
Để hiểu rõ kiến trúc này, tôi khuyến nghị thử áp dụng Transformer từ đầu theo hướng dẫn xây dựng transformer với PyTorch này.
BERT, khuôn khổ xử lý ngôn ngữ tự nhiên nguồn mở do Google phát hành năm 2018, đã cách mạng hóa NLP với huấn luyện hai chiều độc đáo, cho phép mô hình đưa ra dự đoán về từ tiếp theo có nhiều ngữ cảnh hơn.
Bằng cách hiểu ngữ cảnh từ cả hai phía của một từ, BERT vượt trội các mô hình trước trong những tác vụ như hỏi-đáp và hiểu ngôn ngữ mơ hồ. Cốt lõi của nó dùng Transformer, kết nối linh hoạt từng phần tử đầu vào và đầu ra.
BERT, được tiền huấn luyện trên Wikipedia, xuất sắc trong nhiều tác vụ NLP, thúc đẩy Google tích hợp vào công cụ tìm kiếm để xử lý truy vấn tự nhiên hơn. Đổi mới này châm ngòi cho cuộc đua phát triển các mô hình ngôn ngữ tiên tiến và nâng cao đáng kể khả năng xử lý ngôn ngữ phức tạp của lĩnh vực.
Để biết thêm về BERT, bạn có thể xem bài viết riêng giới thiệu mô hình BERT.
LaMDA (Language Model for Dialogue Applications) là một mô hình dựa trên Transformer do Google phát triển, thiết kế riêng cho tác vụ hội thoại và ra mắt trong sự kiện Google I/O 2021. Chúng được thiết kế để tạo phản hồi tự nhiên và phù hợp ngữ cảnh hơn, nâng cao tương tác người dùng trong nhiều ứng dụng.
Thiết kế của LaMDA cho phép nó hiểu và phản hồi nhiều chủ đề và ý định người dùng, lý tưởng cho chatbot, trợ lý ảo và các hệ thống AI tương tác nơi hội thoại linh hoạt là chìa khóa.
Sự tập trung vào hiểu hội thoại và phản hồi này đánh dấu LaMDA như một bước tiến đáng kể trong xử lý ngôn ngữ tự nhiên và giao tiếp do AI dẫn dắt.
Nếu bạn muốn hiểu sâu hơn về LaMDA, bạn có thể nắm rõ hơn với bài viết về LaMDA của chúng tôi.
GPT và ChatGPT, do OpenAI phát triển, là các mô hình sinh tiên tiến nổi tiếng với khả năng tạo văn bản mạch lạc và phù hợp ngữ cảnh. GPT-1 là mô hình đầu tiên ra mắt tháng 6/2018 và GPT-3, một trong những mô hình có tác động lớn, ra mắt năm 2020.
Các mô hình này giỏi ở nhiều tác vụ, bao gồm sáng tạo nội dung, hội thoại, dịch ngôn ngữ và hơn thế nữa. Kiến trúc của GPT cho phép nó tạo văn bản rất giống cách viết của con người, hữu ích trong viết sáng tạo, hỗ trợ khách hàng, thậm chí hỗ trợ viết mã. ChatGPT, biến thể tối ưu cho ngữ cảnh hội thoại, xuất sắc trong tạo đối thoại giống con người, nâng cao ứng dụng trong chatbot và trợ lý ảo.
Claude, do Anthropic phát triển, là họ trợ lý AI dựa trên Transformer với trọng tâm về an toàn và hữu ích. Claude sử dụng Constitutional AI (CAI), một cách huấn luyện trong đó mô hình được định hướng bởi một tập nguyên tắc để tạo phản hồi hữu ích, vô hại và trung thực.
Claude 3 (phát hành 2024) giới thiệu ba tầng mô hình Haiku, Sonnet và Opus, đưa ra các đánh đổi khác nhau giữa tốc độ và năng lực. Các mô hình này xuất sắc ở suy luận tinh tế, làm theo hướng dẫn phức tạp và duy trì ngữ cảnh trong hội thoại dài (lên đến 200K token).
Trong 2025 và 2026, Anthropic ra mắt các mô hình Claude 4, với các bản mới nhất, Opus 4.6 và Sonnet 4.6, dẫn đầu nhiều bảng xếp hạng LLM.
Bức tranh các mô hình nền tảng, đặc biệt là transformer, đang mở rộng nhanh chóng. Một nghiên cứu xác định hơn 50 mô hình transformer quan trọng, trong khi nhóm Stanford đánh giá 30 mô hình, ghi nhận tốc độ tăng trưởng nhanh của lĩnh vực. NLP Cloud, một startup sáng tạo thuộc chương trình Inception của NVIDIA, sử dụng khoảng 25 mô hình ngôn ngữ lớn trong thương mại cho nhiều ngành như hàng không và dược.
Xu hướng mở nguồn các mô hình này đang gia tăng, với các nền tảng như kho mô hình của Hugging Face dẫn đầu. Ngoài ra, đã có nhiều mô hình dựa trên Transformer được phát triển, mỗi mô hình chuyên biệt cho các tác vụ NLP khác nhau, cho thấy tính linh hoạt và hiệu quả của kiến trúc trong nhiều ứng dụng.
Bạn có thể tìm hiểu thêm về tất cả các Mô hình Nền tảng hiện có trong bài viết riêng, nói về chúng là gì và những mô hình nào được dùng nhiều nhất.
Kể từ kiến trúc năm 2017, Transformer đã phát triển đáng kể để khắc phục hạn chế và mở rộng sang các lĩnh vực mới.
Vision Transformers áp dụng cơ chế tự chú ý lên ảnh bằng cách chia ảnh thành các patch và coi mỗi patch như một token. Cách tiếp cận này chứng tỏ rất hiệu quả cho phân loại ảnh, phát hiện đối tượng và tạo ảnh, thường vượt trội CNN truyền thống trên các bộ dữ liệu lớn.
Các mô hình hiện đại như GPT-5, Gemini 3 và Llama 4 xử lý nhiều loại đầu vào (văn bản, hình ảnh, âm thanh, video) trong một kiến trúc duy nhất. Các Transformer đa phương thức này dùng không gian embedding thống nhất và cơ chế cross-attention để suy luận đồng thời qua các phương thức khác nhau.
Độ phức tạp bậc hai của self-attention giới hạn độ dài ngữ cảnh. Nhiều đổi mới giải quyết điều này:
Việc đo chuẩn và đánh giá hiệu năng của Transformer trong NLP đòi hỏi một cách tiếp cận có hệ thống để xem xét hiệu quả và hiệu suất của chúng.
Tùy thuộc vào bản chất tác vụ, có nhiều cách và nguồn lực khác nhau để thực hiện:
Khi xử lý các bài toán Dịch máy, bạn có thể tận dụng các bộ dữ liệu chuẩn như WMT (Workshop on Machine Translation) nơi hệ thống MT gặp một bức tranh nhiều cặp ngôn ngữ, mỗi cặp có thách thức riêng.
Các thước đo như BLEU, METEOR, TER và chrF đóng vai trò như công cụ điều hướng, dẫn dắt chúng ta tới độ chính xác và độ trôi chảy.
Ngoài ra, thử nghiệm trên đa dạng miền như tin tức, văn học và văn bản kỹ thuật đảm bảo khả năng thích ứng và linh hoạt của hệ thống MT, biến nó thành một "đa ngữ" thực thụ trong thế giới số.
Để đánh giá mô hình QA, chúng ta dùng các bộ câu hỏi và trả lời đặc biệt như SQuAD (Stanford Question Answering Dataset), Natural Questions hoặc TriviaQA.
Mỗi bộ giống như một trò chơi khác nhau với luật riêng. Ví dụ, SQuAD là tìm câu trả lời trong đoạn văn cho sẵn, trong khi các bộ khác giống trò đố vui với câu hỏi từ bất cứ đâu.
Để xem các chương trình này hoạt động tốt đến đâu, ta dùng các điểm như Precision, Recall, F1, và đôi khi cả điểm khớp chính xác (exact match).
Khi xử lý NLI, ta dùng các bộ dữ liệu như SNLI (Stanford Natural Language Inference), MultiNLI và ANLI.
Chúng giống như thư viện lớn của các biến thể ngôn ngữ và trường hợp tinh vi, giúp ta xem máy tính hiểu các loại câu khác nhau tốt ra sao. Ta chủ yếu kiểm tra độ chính xác trong việc hiểu các phát biểu là suy luận, mâu thuẫn hay không liên quan.
Cũng quan trọng là xem máy tính xử lý các hiện tượng ngôn ngữ khó như quy chiếu (một từ ám chỉ điều đã nhắc trước), hay hiểu 'không', 'tất cả', 'một số'.
Trong thế giới Mạng nơ-ron, hai cấu trúc nổi bật thường được so sánh với Transformer. Mỗi cấu trúc mang lại lợi ích và thách thức riêng, phù hợp cho từng kiểu xử lý dữ liệu. RNN, đã xuất hiện nhiều lần trong bài, và các lớp Tích chập.
Các lớp Hồi quy, nền tảng của RNN, xuất sắc trong xử lý dữ liệu tuần tự. Sức mạnh của kiến trúc này nằm ở khả năng thực hiện các phép toán tuần tự, quan trọng cho các tác vụ như xử lý ngôn ngữ hay chuỗi thời gian. Trong một lớp Hồi quy, đầu ra của bước trước được đưa lại làm đầu vào cho bước tiếp theo. Cơ chế vòng lặp này cho phép mạng ghi nhớ thông tin trước đó, điều cốt yếu để hiểu ngữ cảnh trong chuỗi.
Tuy nhiên, như đã bàn, xử lý tuần tự có hai hệ quả chính:
Transformer khác biệt đáng kể so với kiến trúc dùng lớp hồi quy vì chúng không có tính lặp. Như đã thấy, lớp Attention của Transformer giải quyết cả hai vấn đề, khiến chúng trở thành bước tiến tự nhiên của RNN cho ứng dụng NLP.
Mặt khác, các lớp Tích chập, viên gạch của CNN, nổi tiếng với hiệu quả khi xử lý dữ liệu không gian như ảnh.
Các lớp này dùng kernel (bộ lọc) quét qua dữ liệu đầu vào để trích xuất đặc trưng. Bề rộng kernel có thể điều chỉnh, cho phép mạng tập trung vào đặc trưng nhỏ hoặc lớn tùy tác vụ.
Trong khi lớp Tích chập rất giỏi nắm bắt phân cấp không gian và mẫu trong dữ liệu, chúng gặp thách thức với phụ thuộc dài hạn. Chúng không tự nhiên tính đến thông tin tuần tự, khiến ít phù hợp cho tác vụ đòi hỏi hiểu thứ tự hay ngữ cảnh.
Đó là lý do CNN và Transformer phù hợp cho các loại dữ liệu và tác vụ khác nhau. CNN thống trị thị giác máy tính nhờ hiệu quả xử lý thông tin không gian, còn Transformer là lựa chọn hàng đầu cho các tác vụ tuần tự phức tạp, đặc biệt trong NLP, nhờ khả năng hiểu phụ thuộc xa.
Dù thành công, Transformer vẫn có hạn chế đáng chú ý:
Nghiên cứu tiếp tục giải quyết các hạn chế này qua đổi mới kiến trúc như Flash Attention, mixture-of-experts và retrieval-augmented generation (RAG).
Tóm lại, Transformer đã nổi lên như một đột phá vĩ đại trong trí tuệ nhân tạo và xử lý ngôn ngữ tự nhiên (NLP).
Bằng cách quản lý hiệu quả dữ liệu tuần tự thông qua cơ chế tự chú ý độc đáo, các mô hình này đã vượt qua RNN truyền thống. Khả năng xử lý chuỗi dài hiệu quả hơn và song song hóa xử lý dữ liệu giúp tăng tốc huấn luyện đáng kể.
Các mô hình tiên phong như BERT của Google và dòng GPT của OpenAI minh họa tác động biến đổi của Transformer trong việc nâng cao công cụ tìm kiếm và tạo văn bản giống con người.
Kết quả là chúng trở nên không thể thiếu trong học máy hiện đại, thúc đẩy ranh giới AI tiến lên và mở ra các hướng đi công nghệ mới.
Nếu bạn muốn đào sâu về Transformer và cách dùng thực tiễn, bài viết về Transformer và Hugging Face là điểm khởi đầu hoàn hảo! Bạn cũng có thể học cách xây dựng Transformer với PyTorch trong hướng dẫn chuyên sâu của chúng tôi.
Tìm hiểu thêm về Transformer và LLM!
Courses
Courses
Courses
blogs
Matt Crabtree
10 phút