
Corso
Concetti sui Large Language Models (LLM)
2 h
104K
I Transformer sono stati sviluppati inizialmente per risolvere il problema della trasduzione di sequenze, ovvero la traduzione automatica neurale: sono quindi pensati per affrontare qualsiasi compito che trasformi una sequenza di input in una sequenza di output. Per questo si chiamano “Transformer”.
Ma partiamo dall'inizio.
Un modello transformer è una rete neurale che apprende il contesto di dati sequenziali e genera nuovi dati a partire da esso.
In parole semplici:
Un transformer è un tipo di modello di intelligenza artificiale che impara a comprendere e generare testo simile a quello umano analizzando schemi in grandi quantità di dati testuali.
I Transformer sono lo stato dell'arte attuale nell'NLP e sono considerati l'evoluzione dell'architettura encoder-decoder. Tuttavia, mentre l'architettura encoder-decoder si basa principalmente su RNN (Recurrent Neural Networks) per estrarre informazioni sequenziali, i Transformer sono completamente privi di ricorrenza.
Quindi, come ci riescono?
Sono progettati specificamente per comprendere contesto e significato analizzando le relazioni tra i diversi elementi, e si basano quasi interamente su una tecnica matematica chiamata attention per farlo.

Immagine dell'autore.
Originati da un paper di ricerca del 2017 di Google, i modelli transformer sono tra gli sviluppi più recenti e influenti nel campo del Machine Learning. Il primo modello Transformer è stato spiegato nell'influente paper "Attention is All You Need".
Questo concetto pionieristico non è stato solo un avanzamento teorico, ma ha trovato implementazioni pratiche, in particolare nel pacchetto Tensor2Tensor di TensorFlow. Inoltre, il gruppo Harvard NLP ha contribuito offrendo una guida annotata al paper, con un'implementazione in PyTorch. Puoi approfondire come implementare un Transformer da zero in un nostro tutorial dedicato.
La loro introduzione ha alimentato un forte slancio nel settore, spesso chiamato Transformer AI. Questo modello rivoluzionario ha posto le basi per successivi progressi nel campo dei large language model, tra cui BERT. Già nel 2018, questi sviluppi venivano salutati come un momento di svolta nell'NLP.
Nel 2020, i ricercatori di OpenAI hanno annunciato GPT-3. Nel giro di poche settimane, la versatilità di GPT-3 è stata dimostrata quando le persone lo hanno usato per creare poesie, programmi, canzoni, siti web e altro ancora, catturando l'immaginazione degli utenti a livello globale. Osservando questo cambiamento, studiosi di Stanford hanno pubblicato nel 2021 un paper definendo appropriatamente queste innovazioni "foundation models", sottolineandone il ruolo critico nel rimodellare l'AI.
Mentre i modelli proprietari catturavano inizialmente l'attenzione pubblica, una parallela rivoluzione open source ha rapidamente democratizzato la tecnologia dei transformer. Piattaforme come Hugging Face sono emerse come hub vitali per la condivisione di modelli, ma il panorama è cambiato in modo sostanziale nel 2023 con il rilascio della famiglia Llama di Meta. Questo ha acceso un movimento "open-weights", dimostrando che gli sviluppatori non avevano più bisogno di fare affidamento su ecosistemi aziendali chiusi per costruire AI allo stato dell'arte.
Nel 2024 e 2025, lo sviluppo open source è accelerato in modo deciso. Modelli come il massiccio Llama 3.1 di Meta e la successiva serie Llama 4, insieme ad architetture altamente efficienti di startup come Mistral e potenti modelli di ragionamento di DeepSeek, hanno dimostrato che modelli disponibili apertamente potevano eguagliare, e talvolta superare, le prestazioni dei giganti proprietari.
Nel frattempo, i modelli closed-source hanno continuato a evolvere capacità complesse. GPT-4 nel 2023 ha introdotto capacità multimodali, e GPT-4o nel 2024 ha unificato l'elaborazione di testo, visione e audio in un unico modello.
La fine del 2024 ha segnato un'altra svolta fondamentale nel settore con modelli come la serie o1 di OpenAI e l'open R1 di DeepSeek, introducendo una 'chain-of-thought' interna per ragionare su logica e matematica complesse prima di rispondere.
Tra la fine del 2025 e l'inizio del 2026, il panorama è passato completamente da assistenti conversazionali a sistemi autonomi con il lancio della famiglia GPT-5, portando pianificazione multi-step avanzata, memoria a lungo termine e solidi workflow agentici nelle infrastrutture enterprise.
All'epoca dell'introduzione del modello Transformer, le Reti Neurali Ricorrenti (RNN) erano l'approccio preferito per gestire dati sequenziali, caratterizzati da un ordine specifico nell'input.
Le RNN funzionano in modo simile a una rete neurale feed-forward ma elaborano l'input in sequenza, un elemento alla volta.
I Transformer si sono ispirati all'architettura encoder-decoder presente nelle RNN. Tuttavia, invece di usare la ricorrenza, il modello Transformer si basa completamente sul meccanismo di Attention.
Oltre a migliorare le prestazioni delle RNN, i Transformer hanno fornito una nuova architettura per risolvere molti altri compiti, come il riassunto di testi, la didascalia di immagini e il riconoscimento vocale.
Quali sono quindi i principali problemi delle RNN? Sono poco efficaci per i compiti NLP per due ragioni principali:
Il passaggio dalle RNN come LSTM ai Transformer nell'NLP è guidato da questi due problemi principali e dalla capacità dei Transformer di affrontarli grazie ai miglioramenti del meccanismo di Attention:
Così, i Transformer sono diventati un'evoluzione naturale delle RNN.
Ora vediamo più da vicino come funzionano i transformer.
Originariamente ideati per la trasduzione di sequenze o la traduzione automatica neurale, i transformer eccellono nel convertire sequenze di input in sequenze di output. È il primo modello di trasduzione che si basa interamente sul self-attention per calcolare rappresentazioni di input e output senza usare RNN allineate alla sequenza o convoluzioni. La caratteristica centrale dell'architettura dei Transformer è che mantengono il modello encoder-decoder.
Se consideriamo un Transformer per la traduzione linguistica come una semplice scatola nera, prenderebbe una frase in una lingua, per esempio l'inglese, come input e restituirebbe la sua traduzione in inglese.

Immagine dell'autore.
Se approfondiamo un po', osserviamo che questa scatola nera è composta da due parti principali:
Immagine dell'autore. Struttura globale di Encoder-Decoder.
Tuttavia, sia l'encoder che il decoder sono in realtà uno stack con più layer (stesso numero per ciascuno). Tutti gli encoder presentano la stessa struttura: l'input entra in ognuno di essi e viene passato al successivo. Tutti i decoder hanno la stessa struttura e ricevono l'input dall'ultimo encoder e dal decoder precedente.
L'architettura originale consisteva in 6 encoder e 6 decoder, ma possiamo replicare quanti layer vogliamo. Quindi supponiamo N layer per ciascuno.
Immagine dell'autore. Struttura globale di Encoder-Decoder. Layer multipli.
Ora che abbiamo un'idea generale dell'architettura complessiva del Transformer, concentriamoci su Encoder e Decoder per comprendere meglio il loro flusso di lavoro:
L'encoder è un componente fondamentale dell'architettura Transformer. La sua funzione primaria è trasformare i token di input in rappresentazioni contestualizzate. A differenza dei modelli precedenti che elaboravano i token indipendentemente, l'encoder del Transformer cattura il contesto di ciascun token rispetto all'intera sequenza.
La sua struttura è composta come segue:
Immagine dell'autore. Struttura globale degli Encoder.
Scomponiamo quindi il suo workflow nei passi più basilari:
L'embedding avviene solo nell'encoder più in basso. L'encoder inizia convertendo i token di input - parole o sub-parole - in vettori usando layer di embedding. Questi embedding catturano il significato semantico dei token e li convertono in vettori numerici.
Tutti gli encoder ricevono una lista di vettori, ciascuno di dimensione 512 (dimensione fissa). Nell'encoder più basso, questi sono i word embedding, ma negli altri encoder sono l'output dell'encoder immediatamente sottostante.
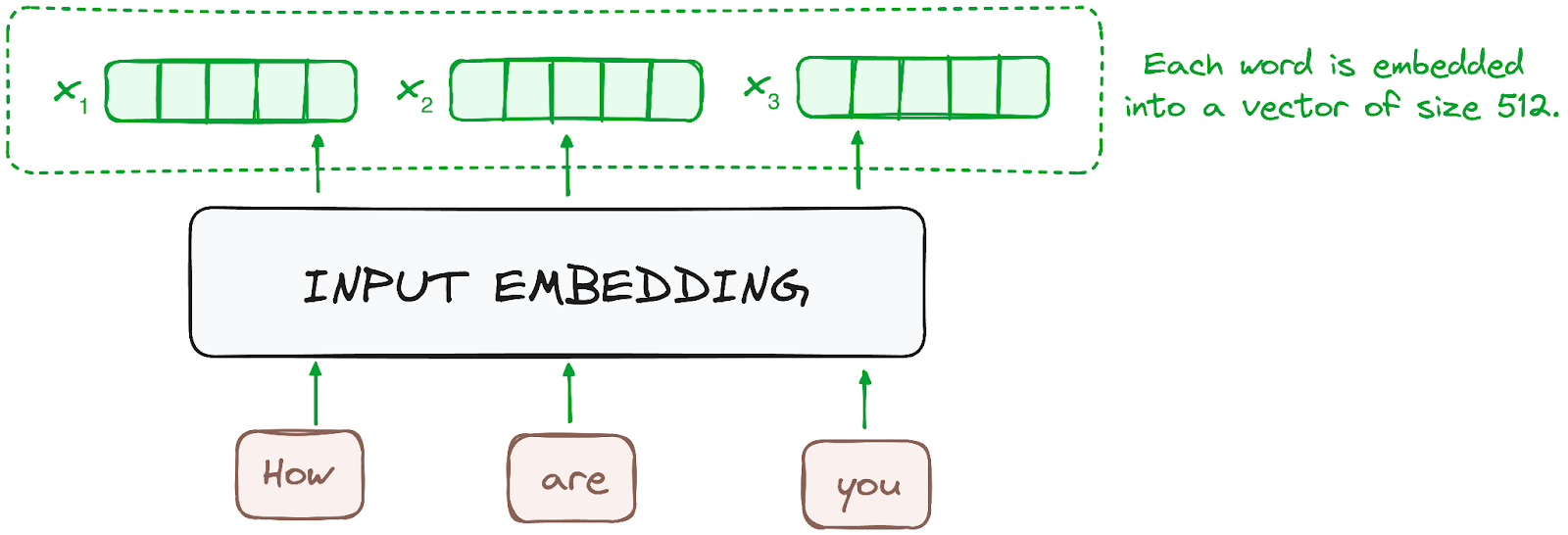
Immagine dell'autore. Workflow dell'encoder. Input embedding.
Poiché i Transformer non hanno un meccanismo di ricorrenza come le RNN, usano positional encoding aggiunti agli embedding di input per fornire informazioni sulla posizione di ciascun token nella sequenza. Questo permette loro di comprendere la posizione di ogni parola all'interno della frase.
Per farlo, i ricercatori hanno suggerito di impiegare una combinazione di diverse funzioni seno e coseno per creare vettori posizionali, consentendo di usare questo positional encoder per frasi di qualsiasi lunghezza.
In questo approccio, ogni dimensione è rappresentata da frequenze e offset unici dell'onda, con valori che vanno da -1 a 1, rappresentando efficacemente ogni posizione.
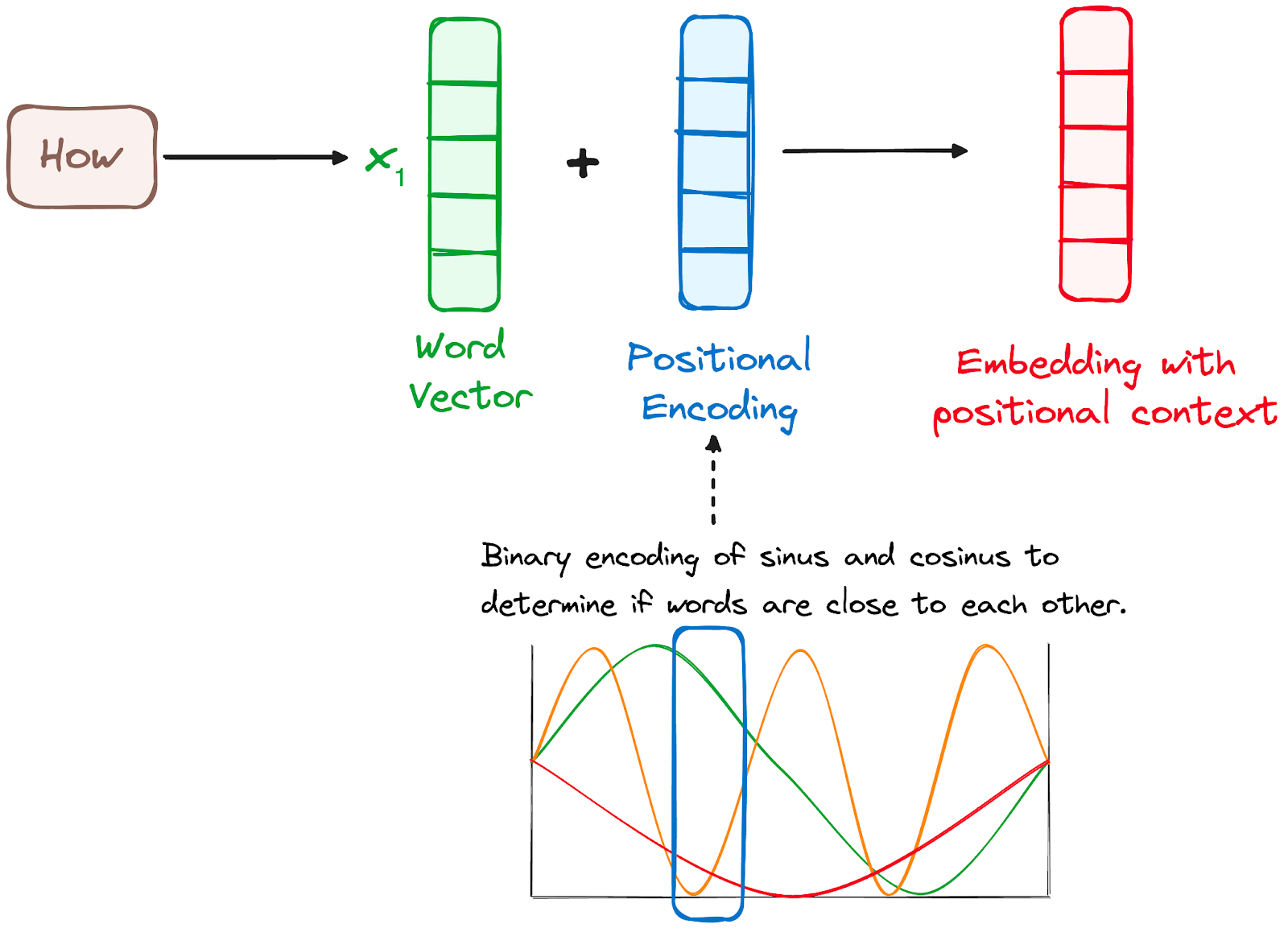
Immagine dell'autore. Workflow dell'encoder. Positional encoding.
L'encoder del Transformer consiste in uno stack di layer identici (6 nel modello Transformer originale).
Il layer dell'encoder serve a trasformare tutte le sequenze di input in una rappresentazione continua e astratta che racchiude le informazioni apprese dall'intera sequenza. Questo layer comprende due sottomoduli:
Inoltre, incorpora connessioni residuali attorno a ciascun sotto-layer, seguite da layer normalization.
Immagine dell'autore. Workflow dell'encoder. Stack di layer dell'Encoder
Nell'encoder, la multi-head attention utilizza un meccanismo specializzato noto come self-attention. Questo approccio consente ai modelli di collegare ogni parola dell'input con le altre parole. Per esempio, in un dato esempio, il modello potrebbe imparare a collegare la parola “are” con “you”.
Questo meccanismo permette all'encoder di concentrarsi su parti diverse della sequenza di input mentre elabora ciascun token. Calcola punteggi di attenzione basati su:
Questo primo modulo di Self-Attention consente al modello di catturare informazioni contestuali dall'intera sequenza. Invece di eseguire una singola funzione di attenzione, query, key e value vengono proiettate linearmente h volte. Su ognuna di queste versioni proiettate di query, key e value il meccanismo di attenzione viene eseguito in parallelo, producendo output di dimensione h.
L'architettura dettagliata è la seguente:
Una volta che i vettori di query, key e value sono passati attraverso un layer lineare, viene eseguita una moltiplicazione di matrici (prodotto scalare) tra query e key, ottenendo la matrice degli score.
La matrice degli score stabilisce quanto ciascuna parola debba porre enfasi sulle altre. Pertanto, a ogni parola viene assegnato un punteggio in relazione alle altre parole nello stesso time step. Un punteggio più alto indica maggiore attenzione.
Questo processo mappa efficacemente le query alle key corrispondenti.
Immagine dell'autore. Workflow dell'encoder. Meccanismo di attenzione - Moltiplicazione di matrici.
Gli score vengono poi ridimensionati dividendo per la radice quadrata della dimensione dei vettori di query e key. Questo passaggio serve a garantire gradienti più stabili, poiché la moltiplicazione dei valori può portare a effetti eccessivamente grandi.
Immagine dell'autore. Workflow dell'encoder. Riduzione degli score di attenzione.
Successivamente si applica una funzione softmax agli score regolati per ottenere i pesi di attenzione. Si ottengono valori di probabilità compresi tra 0 e 1. La softmax enfatizza gli score più alti attenuando quelli più bassi, migliorando così la capacità del modello di determinare efficacemente a quali parole prestare maggiore attenzione.
Immagine dell'autore. Workflow dell'encoder. Softmax degli score regolati.
Il passo successivo del meccanismo di attenzione è moltiplicare i pesi derivati dalla softmax per il vettore value, ottenendo così un vettore di output.
In questo processo, vengono preservate solo le parole con score softmax elevati. Infine, questo vettore di output viene passato a un layer lineare per un'ulteriore elaborazione.
Immagine dell'autore. Workflow dell'encoder. Combinazione dei risultati della Softmax con il vettore value.
E finalmente otteniamo l'output del meccanismo di Attention!
Ti starai quindi chiedendo perché si chiama Multi-Head Attention?
Ricorda che, prima che inizi tutto il processo, spezzettiamo query, key e value h volte. Questo processo, noto come self-attention, avviene separatamente in ognuna di queste fasi più piccole o 'teste'. Ogni testa lavora in modo indipendente, producendo un vettore di output.
Questo insieme passa poi attraverso un layer lineare finale, come un filtro che affina le loro prestazioni collettive. La bellezza sta nella diversità dell'apprendimento in ogni testa, che arricchisce l'encoder con una comprensione robusta e sfaccettata.
Per approfondire il meccanismo di attenzione, vedi il nostro tutorial sulla multi-head attention nei Transformer.
Ogni sotto-layer in un layer dell'encoder è seguito da un passaggio di normalizzazione. Inoltre, l'output di ciascun sotto-layer viene sommato al suo input (connessione residuale) per aiutare a mitigare il problema del gradiente che svanisce, consentendo modelli più profondi. Questo processo verrà ripetuto anche dopo la rete neurale feed-forward.
Immagine dell'autore. Workflow dell'encoder. Normalizzazione e connessione residuale dopo la Multi-Head Attention.
Il percorso dell'output residuale normalizzato prosegue attraverso una rete feed-forward pointwise, una fase cruciale per un'ulteriore raffinazione.
Immagina questa rete come un duo di layer lineari, con un'attivazione ReLU in mezzo a fare da ponte. Una volta elaborato, l'output ripercorre una strada familiare: torna indietro e si fonde con l'input della rete feed-forward pointwise.
A questa riunione segue un'altra fase di normalizzazione, assicurando che tutto sia ben regolato e sincronizzato per i passaggi successivi.
Immagine dell'autore. Workflow dell'encoder. Sotto-layer della rete neurale Feed-Forward.
L'output dell'ultimo layer dell'encoder è un insieme di vettori, ciascuno dei quali rappresenta la sequenza di input con una ricca comprensione contestuale. Questo output viene poi usato come input per il decoder in un modello Transformer.
Questa codifica accurata spiana la strada al decoder, guidandolo a prestare attenzione alle parole giuste nell'input quando è il momento di decodificare.
Pensalo come costruire una torre, dove puoi impilare N layer di encoder. Ogni layer in questo stack ha la possibilità di esplorare e apprendere diversi aspetti dell'attenzione, come strati di conoscenza. Questo non solo diversifica la comprensione ma può amplificare significativamente le capacità predittive della rete transformer.
Il ruolo del decoder è incentrato sulla creazione di sequenze di testo. A specchio dell'encoder, il decoder è dotato di un set simile di sotto-layer. Vanta due layer di multi-head attention, un layer feed-forward pointwise e incorpora sia connessioni residuali sia layer normalization dopo ogni sotto-layer.
Immagine dell'autore. Struttura globale degli Encoder.
Questi componenti funzionano in modo analogo ai layer dell'encoder, ma con una differenza: ogni layer di multi-head attention nel decoder ha una missione specifica.
La fase finale del processo del decoder prevede un layer lineare, che funge da classificatore, seguito da una funzione softmax per calcolare le probabilità delle diverse parole.
Il decoder del Transformer ha una struttura progettata specificamente per generare questo output decodificando le informazioni codificate passo dopo passo.
È importante notare che il decoder opera in modo autoregressivo, avviando il suo processo con un token di inizio. Usa in modo intelligente un elenco di output generati in precedenza come propri input, insieme agli output dell'encoder ricchi di informazioni di attenzione dall'input iniziale.
Questa danza sequenziale di decodifica continua fino a quando il decoder raggiunge un momento chiave: la generazione di un token che segnala la fine della creazione dell'output.
Al punto di partenza del decoder, il processo rispecchia quello dell'encoder. Qui l'input passa prima attraverso un layer di embedding
Dopo l'embedding, di nuovo come per l'encoder, l'input passa per il layer di positional encoding. Questa sequenza è progettata per produrre embedding posizionali.
Questi embedding posizionali vengono quindi convogliati nel primo layer di multi-head attention del decoder, dove vengono calcolati con cura gli score di attenzione specifici per l'input del decoder.
Il decoder consiste in uno stack di layer identici (6 nel modello Transformer originale). Ogni layer ha tre sotto-componenti principali:
È simile al meccanismo di self-attention dell'encoder ma con una differenza cruciale: impedisce alle posizioni di prestare attenzione a posizioni successive, il che significa che ogni parola nella sequenza non è influenzata da token futuri.
Per esempio, quando si calcolano gli score di attenzione per la parola "are", è importante che "are" non sbirci "you", che è una parola successiva nella sequenza.
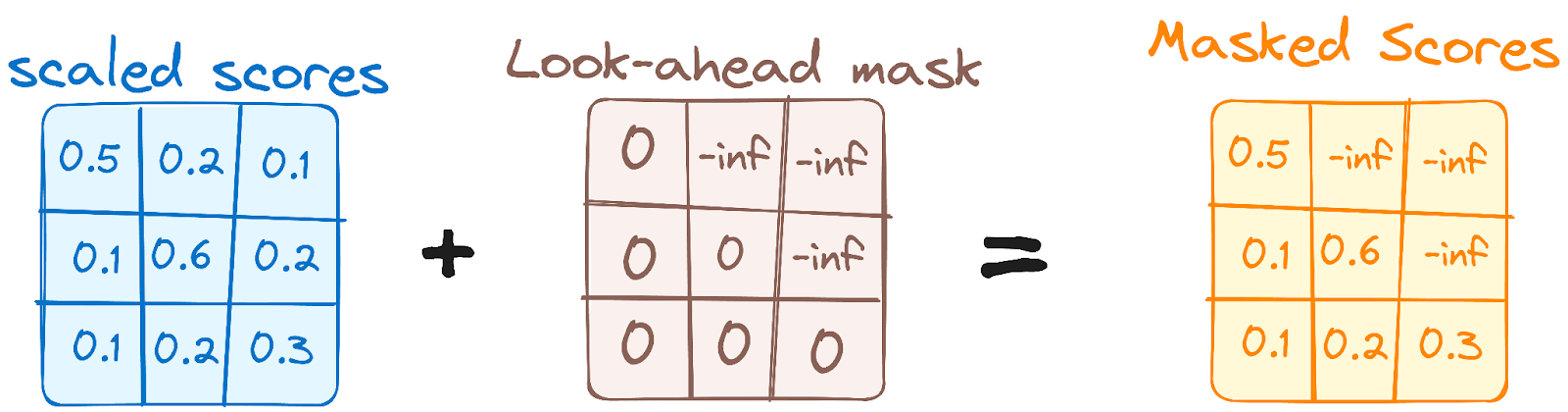
Immagine dell'autore. Workflow del decoder. Prima maschera di Multi-Head Attention.
Questa mascheratura garantisce che le previsioni per una particolare posizione possano dipendere solo dagli output noti nelle posizioni precedenti.
Nel secondo layer di multi-head attention del decoder, vediamo un'interazione unica tra i componenti di encoder e decoder. Qui gli output dell'encoder assumono i ruoli sia di query sia di key, mentre gli output del primo layer di multi-head attention del decoder fungono da value.
Questa configurazione allinea efficacemente l'input dell'encoder con quello del decoder, consentendo al decoder di identificare ed enfatizzare le parti più rilevanti dell'input dell'encoder.
Successivamente, l'output di questo secondo layer di multi-head attention viene raffinato tramite un layer feed-forward pointwise, migliorando ulteriormente l'elaborazione.
Immagine dell'autore. Workflow del decoder. Encoder-Decoder Attention.
In questo sotto-layer, le query provengono dal layer precedente del decoder, mentre key e value provengono dall'output dell'encoder. Questo permette a ogni posizione del decoder di prestare attenzione a tutte le posizioni della sequenza di input, integrando efficacemente le informazioni dell'encoder con quelle del decoder.
Similmente all'encoder, ogni layer del decoder include una rete feed-forward completamente connessa, applicata a ogni posizione separatamente e in modo identico.
Il percorso dei dati attraverso il modello transformer culmina nel passaggio attraverso un layer lineare finale, che funziona come classificatore.
La dimensione di questo classificatore corrisponde al numero totale di classi coinvolte (numero di parole contenute nel vocabolario). Per esempio, in uno scenario con 1000 classi distinte che rappresentano 1000 parole diverse, l'output del classificatore sarà un array con 1000 elementi.
Questo output viene poi introdotto in un layer softmax, che lo trasforma in una gamma di punteggi di probabilità, ciascuno compreso tra 0 e 1. Il più alto di questi punteggi è la chiave: il suo indice corrispondente punta direttamente alla parola che il modello prevede come successiva nella sequenza.
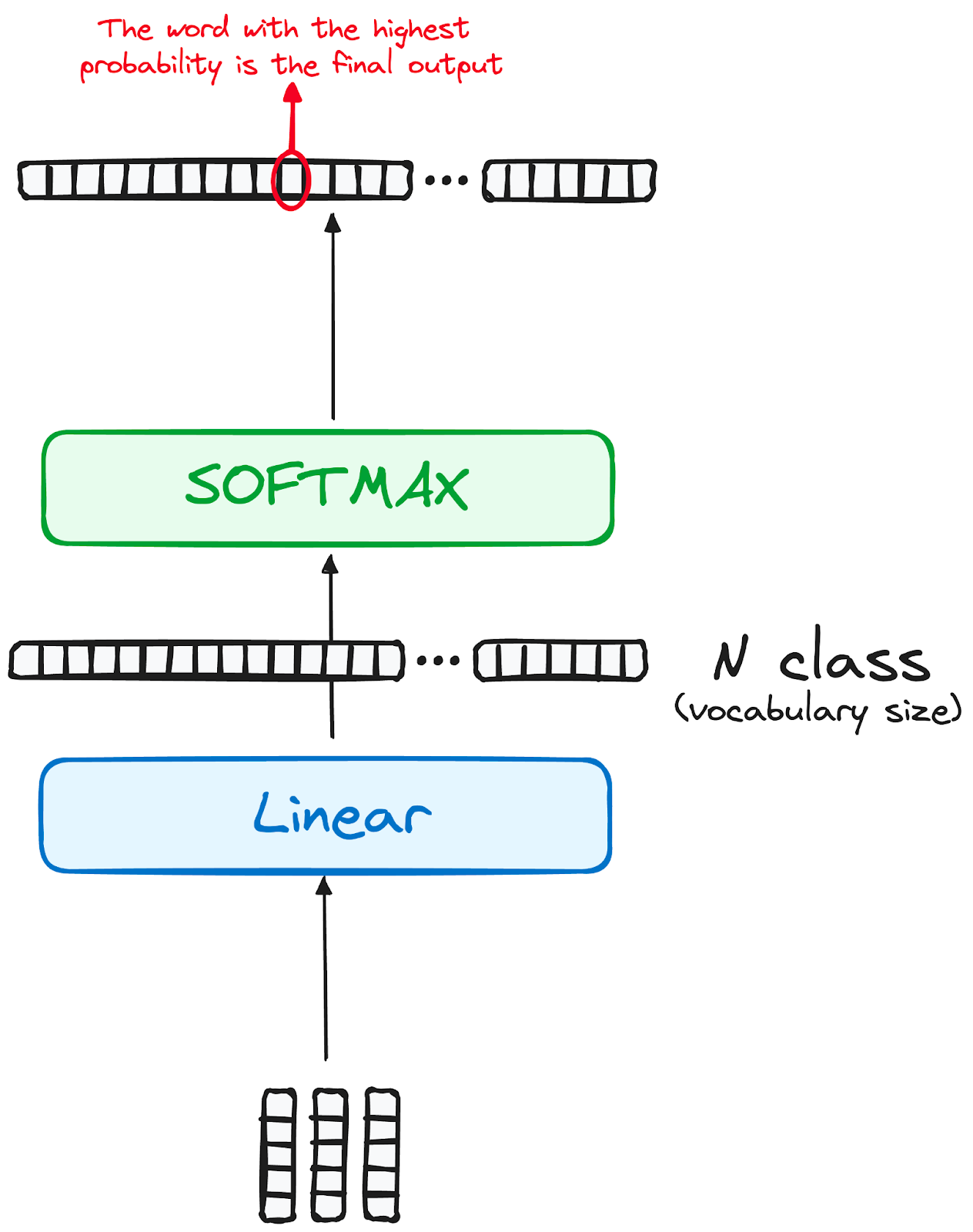
Immagine dell'autore. Workflow del decoder. Output finale del Transformer.
Ogni sotto-layer (self-attention mascherata, attenzione encoder-decoder, rete feed-forward) è seguito da un passaggio di normalizzazione e include anche una connessione residuale.
L'output dell'ultimo layer viene trasformato in una sequenza prevista, tipicamente tramite un layer lineare seguito da una softmax per generare probabilità sul vocabolario.
Il decoder, nel suo flusso operativo, incorpora l'output appena generato nel suo elenco crescente di input e poi prosegue con la decodifica. Questo ciclo si ripete finché il modello prevede un token specifico, che segnala il completamento.
Il token previsto con la probabilità più alta viene assegnato come classe conclusiva, spesso rappresentata dal token di fine.
Ricorda ancora che il decoder non è limitato a un singolo layer. Può essere strutturato con N layer, ognuno dei quali si basa sull'input ricevuto dall'encoder e dai layer precedenti. Questa architettura stratificata permette al modello di diversificare il focus ed estrarre pattern di attenzione variabili tra le sue teste di attenzione.
Un approccio multilayer di questo tipo può migliorare significativamente la capacità predittiva del modello, poiché sviluppa una comprensione più sfumata di diverse combinazioni di attenzione.
L'architettura finale è questa (dal paper originale):
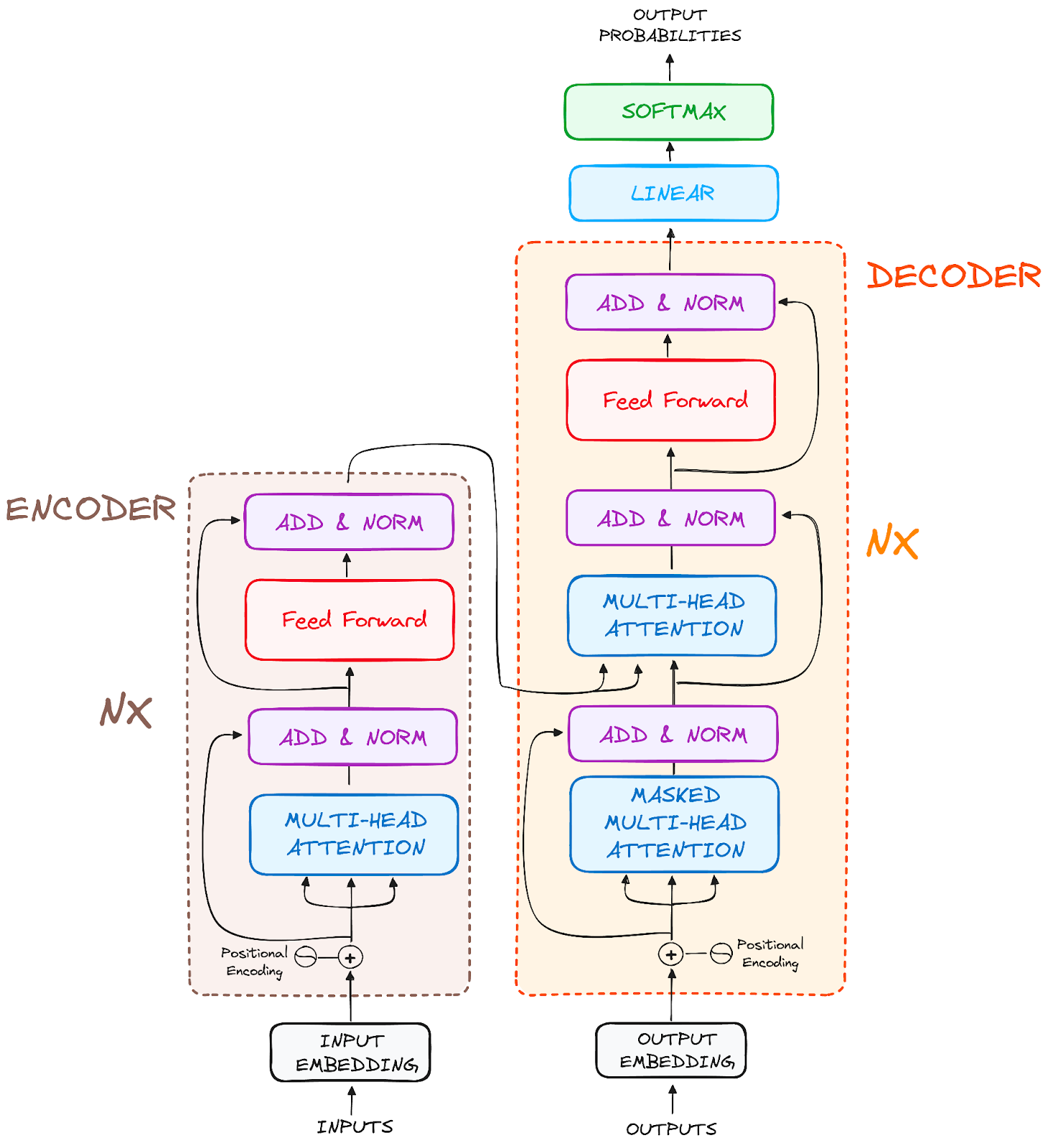
Immagine dell'autore. Struttura originale dei Transformer.
Per comprendere meglio questa architettura, ti consiglio di provare ad applicare un Transformer da zero seguendo questo tutorial per costruire un transformer con PyTorch.
Nel 2018 Google ha rilasciato BERT, un framework open-source di elaborazione del linguaggio naturale che ha rivoluzionato l'NLP con il suo training bidirezionale unico, che permette al modello di avere previsioni più informate dal contesto su quale dovrebbe essere la parola successiva.
Comprendendo il contesto da tutti i lati di una parola, BERT ha superato i modelli precedenti in compiti come question answering e comprensione del linguaggio ambiguo. Al suo core utilizza i Transformer, collegando dinamicamente ogni elemento di output e input.
BERT, pre-addestrato su Wikipedia, ha eccelso in vari compiti NLP, spingendo Google a integrarlo nel suo motore di ricerca per query più naturali. Questa innovazione ha innescato una corsa allo sviluppo di modelli linguistici avanzati e ha fatto progredire significativamente la capacità del settore di gestire una comprensione linguistica complessa.
Per saperne di più su BERT, puoi consultare il nostro articolo dedicato che introduce il modello BERT.
LaMDA (Language Model for Dialogue Applications) è un modello basato su Transformer sviluppato da Google, progettato specificamente per compiti conversazionali e lanciato durante il keynote di Google I/O 2021. È progettato per generare risposte più naturali e contestualmente pertinenti, migliorando le interazioni con l'utente in varie applicazioni.
Il design di LaMDA gli consente di comprendere e rispondere a un'ampia gamma di argomenti e intenzioni, rendendolo ideale per applicazioni in chatbot, assistenti virtuali e altri sistemi AI interattivi in cui è fondamentale una conversazione dinamica.
Questa attenzione alla comprensione e alla risposta conversazionale rende LaMDA un progresso significativo nel campo dell'elaborazione del linguaggio naturale e della comunicazione guidata dall'AI.
Se ti interessa approfondire i modelli LaMDA, puoi capire meglio con il nostro articolo su LaMDA.
GPT e ChatGPT, sviluppati da OpenAI, sono modelli generativi avanzati noti per la loro capacità di produrre testo coerente e contestualmente pertinente. GPT-1 è stato il primo modello, lanciato a giugno 2018, e GPT-3, uno dei modelli più impattanti, è arrivato due anni dopo, nel 2020.
Questi modelli sono abili in un'ampia gamma di compiti, tra cui creazione di contenuti, conversazione, traduzione linguistica e altro. L'architettura di GPT gli consente di generare testo che somiglia da vicino alla scrittura umana, rendendolo utile in applicazioni come scrittura creativa, assistenza clienti e persino supporto alla programmazione. ChatGPT, una variante ottimizzata per contesti conversazionali, eccelle nel generare dialoghi simili a quelli umani, ampliando le applicazioni in chatbot e assistenti virtuali.
Claude, sviluppato da Anthropic, è una famiglia di assistenti AI basati su Transformer progettati con un focus su sicurezza e utilità. Claude usa la Constitutional AI (CAI), un approccio di training in cui il modello è guidato da un insieme di principi per produrre risposte utili, innocue e oneste.
Claude 3 (rilasciato nel 2024) ha introdotto tre fasce di modelli, Haiku, Sonnet e Opus, offrendo diversi compromessi tra velocità e capacità. I modelli eccellono nel ragionamento sfumato, nel seguire istruzioni complesse e nel mantenere il contesto in conversazioni lunghe (fino a 200K token).
Nel 2025 e 2026, Anthropic ha lanciato i modelli Claude 4; i più recenti, Opus 4.6 e Sonnet 4.6, sono in cima a molte benchmark per LLM.
Il panorama dei foundation model, in particolare dei modelli transformer, si sta espandendo rapidamente. Uno studio ha identificato oltre 50 modelli transformer significativi, mentre il gruppo di Stanford ne ha valutati 30, riconoscendo la crescita veloce del campo. NLP Cloud, una startup innovativa parte del programma Inception di NVIDIA, utilizza commercialmente circa 25 large language model per vari settori come compagnie aeree e farmacie.
C'è una tendenza crescente a rendere questi modelli open-source, con piattaforme come l'hub dei modelli di Hugging Face in prima linea. Inoltre, sono stati sviluppati numerosi modelli basati su Transformer, ciascuno specializzato per diversi compiti NLP, a dimostrazione della versatilità ed efficienza del modello in applicazioni diverse.
Puoi saperne di più su tutti i Foundation Models esistenti in un articolo separato, che spiega cosa sono e quali sono i più usati.
Dall'architettura originale del 2017, i Transformer si sono evoluti in modo significativo per affrontare limitazioni ed espandersi in nuovi domini.
I Vision Transformer applicano il meccanismo di self-attention alle immagini dividendole in patch e trattando ogni patch come un token. Questo approccio si è rivelato molto efficace per classificazione di immagini, object detection e generazione di immagini, spesso superando le CNN tradizionali su grandi dataset.
Modelli moderni come GPT-5, Gemini 3 e Llama 4 elaborano più tipi di input (testo, immagini, audio, video) all'interno di un'unica architettura. Questi Transformer multimodali usano spazi di embedding unificati e meccanismi di cross-attention per ragionare simultaneamente tra diverse modalità.
La complessità quadratica del self-attention limita la lunghezza del contesto. Diverse innovazioni affrontano questo problema:
Il benchmarking e la valutazione delle prestazioni dei modelli Transformer in NLP richiedono un approccio sistematico per valutarne efficacia ed efficienza.
A seconda della natura del compito, esistono diversi modi e risorse per farlo:
Per i compiti di traduzione automatica, puoi sfruttare dataset standard come WMT (Workshop on Machine Translation) dove i sistemi MT incontrano un mosaico di coppie di lingue, ciascuna con sfide uniche.
Metriche come BLEU, METEOR, TER e chrF fungono da strumenti di navigazione, guidandoci verso accuratezza e fluidità.
Inoltre, testare su domini diversi come notizie, letteratura e testi tecnici assicura l'adattabilità e versatilità di un sistema MT, rendendolo un vero poliglotta nel mondo digitale.
Per valutare i modelli di QA, usiamo collezioni speciali di domande e risposte, come SQuAD (Stanford Question Answering Dataset), Natural Questions o TriviaQA.
Ognuno è come un gioco diverso con regole proprie. Ad esempio, SQuAD riguarda il trovare risposte in un testo dato, mentre altri sono più simili a un quiz con domande da qualsiasi ambito.
Per vedere quanto bene si comportano questi programmi, usiamo punteggi come Precision, Recall, F1 e talvolta anche l'esatto match.
Quando si affronta la Natural Language Inference (NLI), usiamo dataset specifici come SNLI (Stanford Natural Language Inference), MultiNLI e ANLI.
Sono come grandi librerie di variazioni linguistiche e casi insidiosi, che ci aiutano a vedere quanto bene i computer comprendono diversi tipi di frasi. Controlliamo principalmente l'accuratezza nel capire se le affermazioni sono in accordo, in contraddizione o non correlate.
È anche importante esaminare come il computer gestisce aspetti linguistici delicati, come quando una parola si riferisce a qualcosa menzionato prima, o la comprensione di 'non', 'tutti' e 'alcuni'.
Nel mondo delle reti neurali, due strutture prominenti vengono solitamente confrontate con i Transformer. Ognuna offre benefici e sfide distinti, pensati per specifici tipi di elaborazione dei dati. Le RNN, apparse più volte nell'articolo, e i layer convoluzionali.
I layer ricorrenti, pilastri delle Reti Neurali Ricorrenti (RNN), eccellono nella gestione dei dati sequenziali. La forza di questa architettura risiede nella capacità di eseguire operazioni sequenziali, cruciali per compiti come l'elaborazione del linguaggio o l'analisi di serie temporali. In un layer ricorrente, l'output di uno step precedente viene reimmesso nella rete come input per lo step successivo. Questo meccanismo ad anello permette alla rete di ricordare informazioni precedenti, fondamentale per comprendere il contesto in una sequenza.
Tuttavia, come già discusso, questa elaborazione sequenziale ha due implicazioni principali:
I modelli Transformer differiscono significativamente dalle architetture che usano layer ricorrenti perché privi di ricorrenza. Come visto, il layer di Attention del Transformer affronta entrambi i problemi, rendendoli l'evoluzione naturale delle RNN per le applicazioni NLP.
Dall'altro lato, i layer convoluzionali, i mattoni delle Convolutional Neural Network (CNN), sono rinomati per l'efficienza nell'elaborare dati spaziali come le immagini.
Questi layer usano kernel (filtri) che scorrono sui dati di input per estrarre feature. La larghezza di questi kernel può essere regolata, permettendo alla rete di concentrarsi su feature piccole o grandi, a seconda del compito.
Sebbene i layer convoluzionali siano eccezionali nel catturare gerarchie e pattern spaziali nei dati, incontrano difficoltà con le dipendenze a lungo termine. Non tengono intrinsecamente conto dell'informazione sequenziale, rendendoli meno adatti a compiti che richiedono la comprensione dell'ordine o del contesto di una sequenza.
Ecco perché le CNN e i Transformer sono pensati per tipi di dati e compiti diversi. Le CNN dominano nel campo della computer vision per la loro efficienza nell'elaborare informazioni spaziali, mentre i Transformer sono la scelta di riferimento per compiti sequenziali complessi, soprattutto nell'NLP, grazie alla loro capacità di comprendere dipendenze a lungo raggio.
Nonostante il successo, i Transformer hanno limitazioni notevoli:
La ricerca continua ad affrontare queste limitazioni tramite innovazioni architetturali come Flash Attention, mixture-of-experts e retrieval-augmented generation (RAG).
In conclusione, i Transformer sono emersi come una svolta monumentale nell'intelligenza artificiale e nell'elaborazione del linguaggio naturale (NLP).
Gestendo efficacemente i dati sequenziali tramite il loro meccanismo unico di self-attention, questi modelli hanno superato le RNN tradizionali. La loro capacità di gestire sequenze lunghe in modo più efficiente e di parallelizzare l'elaborazione dei dati accelera significativamente l'addestramento.
Modelli pionieristici come BERT di Google e la serie GPT di OpenAI esemplificano l'impatto trasformativo dei Transformer nel migliorare i motori di ricerca e nel generare testo simile a quello umano.
Di conseguenza, sono diventati indispensabili nel machine learning moderno, spingendo avanti i confini dell'AI e aprendo nuove strade ai progressi tecnologici.
Se vuoi approfondire i Transformer e il loro uso pratico, il nostro articolo su Transformer e Hugging Face è un ottimo punto di partenza! Puoi anche imparare a costruire un Transformer con PyTorch con la nostra guida dettagliata.
Scopri di più su Transformer e LLM!
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

