
Corso
Comprendere l'intelligenza artificiale
2 h
409.4K
Se vuoi iniziare subito a usare il modello Stable Diffusion, puoi eseguirlo online con i seguenti strumenti.
Stability AI, i creatori di Stable Diffusion, hanno reso estremamente semplice per chi è curioso testare il loro modello testo-immagine grazie allo strumento online DreamStudio.
DreamStudio offre accesso alla versione più recente dei modelli Stable Diffusion e consente di generare un'immagine in fino a 15 secondi.
Interfaccia utente di DreamStudio. Fonte immagine: DreamStudio.
Al momento della stesura di questo tutorial, i nuovi utenti ricevono 100 crediti gratuiti per provare DreamStudio, sufficienti per 500 immagini con le impostazioni predefinite! Ulteriori crediti possono essere acquistati all'interno dell'applicazione quando preferisci, a soli $10,00 per 1000 crediti.
Hugging Face è una community e piattaforma di IA che promuove i contributi open source. Sebbene sia molto conosciuta per i suoi modelli transformer, Hugging Face fornisce anche accesso al più recente modello Stable Diffusion e, da vero amante dell'open source, è gratuito.
Per eseguire Stable Diffusion su Hugging Face, puoi provare una delle demo, ad esempio la demo di Stable Diffusion 2.1.
Il compromesso con Hugging Face è che non puoi personalizzare le proprietà come in DreamStudio e il tempo di generazione di un'immagine è visibilmente più lungo.

Demo di Stable Diffusion su Hugging Face. Immagine dell'autore.
E se invece vuoi fare esperimenti con Stable Diffusion sul tuo computer locale? Ci pensiamo noi.
Eseguire Stable Diffusion in locale ti permette di sperimentare con vari input testuali per generare immagini più adatte alle tue esigenze. Puoi anche ottimizzare finemente il modello sui tuoi dati per migliorare i risultati, in base agli input che fornisci.
Disclaimer: Devi avere una GPU per eseguire Stable Diffusion in locale.
Per eseguire Stable Diffusion dal tuo computer locale, ti servirà Python 3.10.6. Puoi installarlo dal sito ufficiale di Python. Se ti blocchi, dai un'occhiata al nostro tutorial Come installare Python.
Verifica che l'installazione sia andata a buon fine aprendo il prompt dei comandi, digitando python ed eseguendo il comando. Dovrebbe stampare la versione di Python in uso.
Disclaimer: La versione consigliata per eseguire Stable Diffusion è Python 3.10.6. Ti suggeriamo di non procedere senza questa versione per evitare problemi.
Successivamente devi installare il sistema di gestione dei repository di codice Git. La guida all'installazione di Git può aiutarti, e il nostro corso Introduzione a Git può approfondire le tue conoscenze su Git.
GitHub è un servizio di hosting per lo sviluppo software dove gli sviluppatori ospitano il loro codice per poter tracciare e collaborare con altri sviluppatori sui progetti. Se non hai un account GitHub, questo è anche un buon momento per crearne uno: consulta GitHub and Git Tutorial for Beginners per assistenza.
Hugging Face, invece, è una community di IA che sostiene i contributi open source. È l'hub per numerosi modelli di IA da vari domini, tra cui elaborazione del linguaggio naturale, computer vision e altro. Ti servirà un account per scaricare l'ultima versione di Stable Diffusion. Arriveremo a questo passaggio più avanti.
In questo passaggio scaricherai la Web-UI di Stable Diffusion sul tuo computer locale. Anche se è utile creare una cartella dedicata (ad es. stable-diffusion-demo-project) per questo scopo, non è obbligatorio.
1. Apri Git Bash:
2. Vai alla cartella desiderata:
cd per spostarti nella cartella in cui vuoi clonare la Web-UI di Stable Diffusion. Ad esempio:cd path/to/your/folder3. Clona il repository:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
4. Verifica la clonazione:
stable-diffusion-webui nella directory scelta.
Nota: Puoi trovare istruzioni più specifiche per il tuo hardware e sistema operativo nel repository GitHub della web UI di Stable Diffusion.
1. Accedi a Hugging Face:
2. Scarica il modello Stable Diffusion:
3. Individua la cartella del modello:
stable-diffusion-webui\models\Stable-diffusion4. Sposta il modello scaricato:
Stable-diffusion vedrai un file di testo chiamato Put Stable Diffusion Checkpoints here.In questo passaggio installerai gli strumenti necessari per eseguire Stable Diffusion.
1. Apri il Prompt dei comandi o il Terminale.
2. Vai alla cartella della web UI di Stable Diffusion:
cd per spostarti nella cartella stable-diffusion-webui clonata in precedenza. Ad esempio:cd path/to/stable-diffusion-webui3. Esegui lo script di setup:
stable-diffusion-webui, esegui il seguente comando:webui-user.batQuesto script creerà un ambiente virtuale e installerà tutte le dipendenze necessarie per eseguire Stable Diffusion. Il processo può richiedere circa 10 minuti, quindi abbi pazienza.
Nota: Puoi trovare istruzioni più specifiche per il tuo hardware e sistema operativo nel repository GitHub della web UI di Stable Diffusion.
Dopo che le dipendenze sono state installate, nel prompt dei comandi apparirà un URL: http://127.0.0.1:7860.
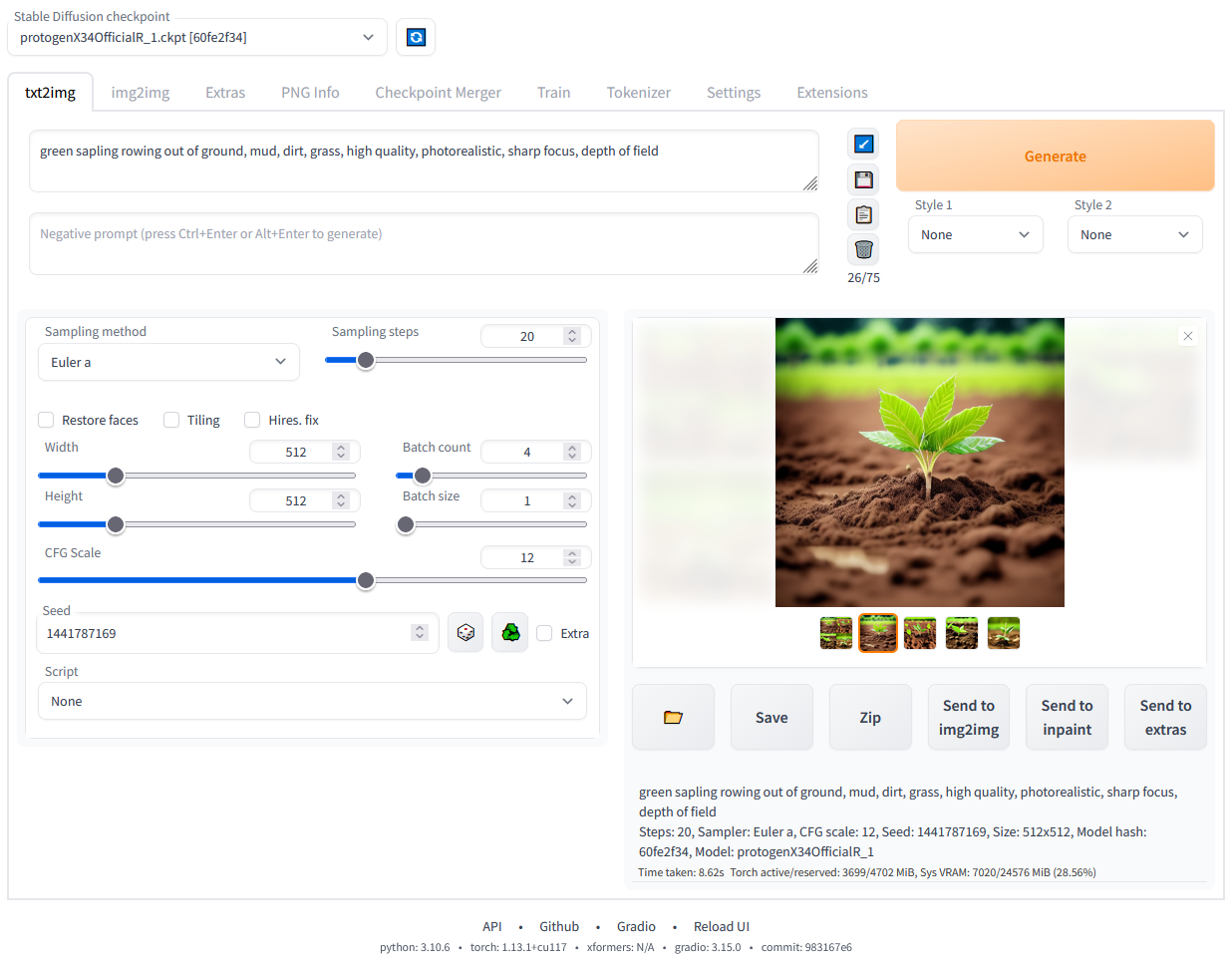
Web UI di Stable Diffusion in esecuzione in locale. Immagine dell'autore.
Stable Diffusion rappresenta un significativo progresso nel campo dell'IA generativa. Offre la possibilità di generare immagini dettagliate e di alta qualità a partire da descrizioni testuali. Che tu voglia modificare immagini esistenti, migliorare immagini a bassa risoluzione o creare visual completamente nuovi, Stable Diffusion mette a disposizione un set di strumenti potente e versatile.
Con gli aggiornamenti e i miglioramenti recenti in Stable Diffusion 3 e Medium, le capacità del modello sono state ulteriormente potenziate, rendendolo un punto di riferimento nello spazio dell'IA generativa.
Eseguire Stable Diffusion in locale o tramite varie piattaforme online come DreamStudio e Hugging Face ti permette di esplorarne e sfruttarne appieno il potenziale. Seguendo i passaggi descritti in questa guida, puoi configurare e iniziare a usare Stable Diffusion per soddisfare le tue esigenze creative e pratiche!
L'IA generativa è una modalità rivoluzionaria di deep learning che crea testi, immagini e altri contenuti di alta qualità basandosi sui dati su cui è stata addestrata. Strumenti come Stable Diffusion, ChatGPT e DALL-E sono ottimi esempi di come l'IA generativa stia trasformando vari settori, abilitando nuove forme di creatività e innovazione. Man mano che queste tecnologie evolvono, aprono nuove possibilità per artisti, sviluppatori e ricercatori per spingere oltre i confini di ciò che è possibile.
Se vuoi approfondire il mondo dell'IA generativa, ecco alcune risorse da esplorare:
Approfondisci l'IA generativa e il deep learning con questi corsi!
Corso
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min

