
Courses
Hiểu về Trí tuệ Nhân tạo
2 giờ
409.4K
Nếu bạn muốn bắt đầu sử dụng mô hình Stable Diffusion ngay, bạn có thể chạy trực tuyến bằng các công cụ sau.
Stability AI, đơn vị tạo ra Stable Diffusion, đã giúp những người tò mò có thể thử mô hình chuyển văn bản thành hình ảnh của họ một cách cực kỳ đơn giản với công cụ trực tuyến DreamStudio.
DreamStudio cung cấp cho người dùng quyền truy cập vào phiên bản mới nhất của các mô hình Stable Diffusion và cho phép tạo hình ảnh chỉ trong tối đa 15 giây.
Giao diện người dùng DreamStudio. Nguồn ảnh: DreamStudio.
Khi viết hướng dẫn này, người dùng mới nhận được 100 tín dụng miễn phí để thử DreamStudio, đủ cho 500 hình ảnh với cài đặt mặc định! Bạn có thể mua thêm tín dụng trong ứng dụng khi tiện, chỉ với $10,00 cho mỗi 1000 tín dụng.
Hugging Face là một cộng đồng và nền tảng AI thúc đẩy đóng góp mã nguồn mở. Dù được biết đến nhiều với các mô hình transformer, Hugging Face cũng cung cấp quyền truy cập vào phiên bản Stable Diffusion mới nhất, và đúng với tinh thần nguồn mở, nó là miễn phí.
Để chạy Stable Diffusion trên Hugging Face, bạn có thể thử một trong các bản demo, chẳng hạn như bản demo Stable Diffusion 2.1.
Điểm đánh đổi với Hugging Face là bạn không thể tùy chỉnh thuộc tính như ở DreamStudio và thời gian tạo ảnh lâu hơn thấy rõ.

Bản demo Stable Diffusion trên Hugging Face. Ảnh: tác giả.
Nhưng nếu bạn muốn thử nghiệm Stable Diffusion trên máy tính của mình thì sao? Chúng tôi có hướng dẫn cho bạn.
Chạy Stable Diffusion cục bộ cho phép bạn thử nhiều đầu vào văn bản để tạo ảnh phù hợp hơn với yêu cầu. Bạn cũng có thể tinh chỉnh mô hình trên dữ liệu của bạn để cải thiện kết quả, dựa trên đầu vào bạn cung cấp.
Lưu ý: Bạn cần có GPU để chạy Stable Diffusion cục bộ.
Để chạy Stable Diffusion từ máy tính của bạn, bạn sẽ cần Python 3.10.6. Có thể cài đặt từ trang web Python chính thức. Nếu gặp khó khăn, hãy xem hướng dẫn Cách cài đặt Python của chúng tôi.
Kiểm tra cài đặt đã thành công bằng cách mở command prompt, gõ python và chạy lệnh. Màn hình sẽ in ra phiên bản Python bạn đang dùng.
Lưu ý: Phiên bản khuyến nghị để chạy Stable Diffusion là Python 3.10.6. Chúng tôi khuyên bạn không nên tiếp tục nếu không dùng phiên bản này để tránh sự cố.
Tiếp theo, bạn cần cài đặt hệ thống quản lý kho mã Git. Hướng dẫn cài đặt Git có thể giúp bạn, và khóa học Giới thiệu về Git của chúng tôi có thể giúp bạn đào sâu kiến thức về Git.
GitHub là dịch vụ lưu trữ phát triển phần mềm nơi các nhà phát triển lưu trữ mã để theo dõi và cộng tác với nhau trên các dự án. Nếu bạn chưa có tài khoản Github, đây là lúc thích hợp để tạo—hãy xem Hướng dẫn Github và Git cho người mới bắt đầu để được hỗ trợ.
Hugging Face là một cộng đồng AI ủng hộ đóng góp mã nguồn mở. Đây là trung tâm của nhiều mô hình AI thuộc nhiều lĩnh vực, bao gồm xử lý ngôn ngữ tự nhiên, thị giác máy tính và hơn thế nữa. Bạn sẽ cần một tài khoản để tải về phiên bản Stable Diffusion mới nhất. Chúng ta sẽ đến bước này sau.
Ở bước này, bạn sẽ tải Stable Diffusion Web-UI về máy tính của mình. Việc tạo một thư mục riêng (ví dụ stable-diffusion-demo-project) là hữu ích nhưng không bắt buộc.
1. Mở Git Bash:
2. Điều hướng đến thư mục mong muốn:
cd để chuyển đến thư mục nơi bạn muốn clone Stable Diffusion Web-UI. Ví dụ:cd path/to/your/folder3. Clone repository:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
4. Xác minh đã clone:
stable-diffusion-webui trong thư mục đã chọn.
Lưu ý: Bạn có thể tìm hướng dẫn cụ thể hơn cho phần cứng và hệ điều hành của mình trong repository GitHub Stable Diffusion web UI.
1. Đăng nhập Hugging Face:
2. Tải mô hình Stable Diffusion:
3. Xác định thư mục mô hình:
stable-diffusion-webui\models\Stable-diffusion4. Di chuyển mô hình đã tải:
Stable-diffusion, bạn sẽ thấy một tệp văn bản tên Put Stable Diffusion Checkpoints here.Ở bước này, bạn sẽ cài đặt các công cụ cần thiết để chạy Stable Diffusion.
1. Mở Command Prompt hoặc Terminal.
2. Điều hướng đến thư mục web UI của Stable Diffusion:
cd để chuyển đến thư mục stable-diffusion-webui bạn đã clone trước đó. Ví dụ:cd path/to/stable-diffusion-webui3. Chạy script thiết lập:
stable-diffusion-webui, chạy lệnh sau:webui-user.batScript này sẽ tạo môi trường ảo và cài đặt tất cả các phụ thuộc cần thiết để chạy Stable Diffusion. Quá trình có thể mất khoảng 10 phút, vui lòng kiên nhẫn.
Lưu ý: Bạn có thể tìm hướng dẫn cụ thể hơn cho phần cứng và hệ điều hành của mình trong repository GitHub Stable Diffusion web UI.
Sau khi các phụ thuộc đã được cài đặt, một URL sẽ xuất hiện trong command prompt của bạn: http://127.0.0.1:7860.
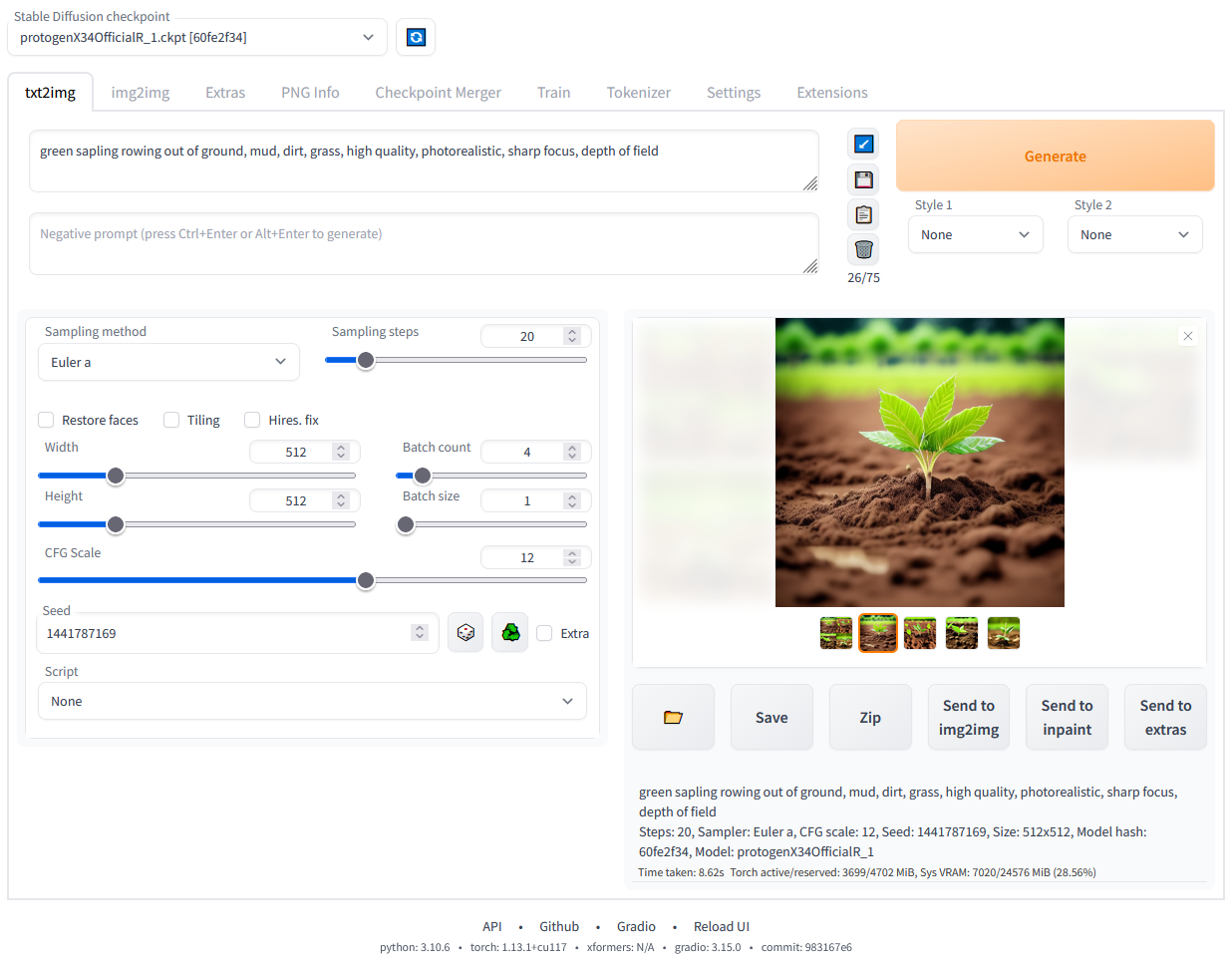
Giao diện web Stable Diffusion chạy cục bộ. Ảnh: tác giả.
Stable Diffusion đại diện cho một bước tiến đáng kể trong lĩnh vực AI sinh. Nó cung cấp khả năng tạo hình ảnh chất lượng cao, chi tiết từ mô tả văn bản. Dù bạn muốn chỉnh sửa ảnh hiện có, nâng cấp ảnh độ phân giải thấp hay tạo hình ảnh hoàn toàn mới, Stable Diffusion mang đến một bộ công cụ mạnh mẽ và linh hoạt.
Với các bản cập nhật và cải tiến gần đây ở Stable Diffusion 3 và Medium, khả năng của mô hình đã được nâng cao hơn nữa, khiến nó trở thành một trong những lựa chọn dẫn đầu trong lĩnh vực AI sinh.
Chạy Stable Diffusion cục bộ hoặc qua các nền tảng trực tuyến như DreamStudio và Hugging Face cho phép bạn khám phá và khai thác tối đa tiềm năng của nó. Làm theo các bước trong hướng dẫn này, bạn có thể thiết lập và bắt đầu dùng Stable Diffusion để đáp ứng các nhu cầu sáng tạo và thực tiễn của mình!
AI sinh là một phương thức học sâu đột phá tạo ra văn bản, hình ảnh và nội dung chất lượng cao khác dựa trên dữ liệu đã được huấn luyện. Các công cụ như Stable Diffusion, ChatGPT và DALL-E là ví dụ điển hình cho cách AI sinh đang chuyển đổi nhiều ngành bằng cách cho phép những hình thức sáng tạo và đổi mới mới. Khi các công nghệ này tiếp tục phát triển, chúng mở ra những khả năng mới cho nghệ sĩ, nhà phát triển và nhà nghiên cứu trong việc mở rộng giới hạn của điều có thể.
Nếu bạn muốn đào sâu hơn vào thế giới AI sinh, dưới đây là một số tài nguyên để khám phá:
Tìm hiểu thêm về AI sinh và học sâu với các khóa học sau!
Courses
Courses
Courses
blogs
Matt Crabtree
10 phút