courses
R로 배우는 데이터 과학을 위한 선형대수
4
21.2K
선형 회귀는 처음 시도하기에 훌륭한 모델이지만, 데이터가 정규분포를 따르지 않는 순간 한계를 드러냅니다.
예를 들어 고객 이탈 여부(예/아니오)를 예측한다고 해봅시다. 선형 회귀는 이를 처리할 수 없습니다. 연속값을 예측하므로 0 또는 1만 가능한 대상에 -0.3이나 1.7 같은 값을 내놓게 됩니다. 시간당 지원 티켓 수처럼 개수 데이터도 마찬가지입니다. 선형 회귀는 음의 개수를 예측할 수 있는데, 이는 말이 되지 않습니다.
일반화 선형 모형(GLM)은 다양한 유형의 결과를 다룰 수 있도록 선형 회귀를 확장해 이러한 문제를 해결합니다. 핵심 아이디어는 동일합니다. 입력의 선형 결합이지만, 이진 데이터와 기타 비정규 분포를 유연하게 모델링할 수 있습니다.
이 글에서는 GLM이 무엇인지, 세 가지 핵심 구성요소를 차근차근 살펴보고, Python과 R에서 적합하고 해석하는 방법을 보여드리겠습니다.
그런데 선형 회귀는 정확히 어떻게 작동할까요? 가정과 진단, 결과 해석 방법을 알아보려면 단순 선형 회귀 가이드를 읽어보세요.
일반화 선형 모형(GLM)은 반응 변수가 정규분포뿐 아니라 다양한 확률분포를 따를 수 있도록 한 선형 회귀의 확장입니다.
중요한 점은 GLM이 단일 모델이 아니라 프레임워크라는 것입니다. 선형 회귀, 로지스틱 회귀, 포아송 회귀는 모두 GLM입니다. 각 모델은 서로 다른 분포와 입력-출력 연결 방식(링크)을 사용하지만, 동일한 구조를 따릅니다.
표준 선형 회귀는 두 가지 큰 가정을 합니다. 결과가 정규분포를 따르고, 예측 전 범위에서 분산이 일정하다는 것입니다. 이 가정이 성립하지 않으면 말이 안 되는 결과가 나옵니다.
예를 들어 대출 신청자의 연체 여부를 예측한다면 결과는 0 또는 1의 이진값입니다. 선형 회귀는 그 경계를 지키지 못합니다. -0.2나 1.4 같은, 불가능한 값을 예측할 수 있습니다.
개수 데이터도 동일한 문제를 가집니다. 월별 재입원 횟수를 예측한다면 선형 회귀는 음수를 낼 수 있습니다. 재입원을 -3번 할 수는 없습니다.
두 경우 모두 문제는 입력의 선형 결합이 아닙니다. 그 부분은 잘 작동합니다. 문제는 모델이 입력을 출력으로 매핑하는 방식입니다. GLM은 출력값을 데이터의 자연스러운 범위로 변환하는 링크 함수를 추가해 이를 해결합니다. 확률은 0과 1 사이에 머물고, 개수는 0 이상을 유지합니다. 곧 자세히 보겠습니다.
모든 GLM은 분포, 선형 예측자, 링크 함수의 세 부분으로 구성됩니다. 각 요소를 살펴보겠습니다.
확률 성분은 반응 변수가 어떤 종류의 데이터를 생성하는지 정의합니다. 즉, 결과를 가장 잘 설명하는 확률분포를 선택합니다.
선형 회귀는 정규분포를 가정하므로 결과는 평균을 중심으로 대칭인 연속값입니다. 하지만 모든 데이터가 그렇게 작동하는 것은 아닙니다.
결과가 이진(예/아니오, 0/1)이라면 이항분포를 사용합니다. 하루당 오류 개수처럼 개수 데이터를 모델링한다면 포아송 분포가 더 적합합니다.
선택한 분포가 모델의 나머지를 좌우합니다.
체계 성분은 선형 회귀에서 이미 알고 있는 부분입니다. 입력 변수의 선형 결합입니다:
체계 성분
여기서 X는 입력 특성의 행렬이고, β는 계수 벡터입니다. 각 특성에 가중치를 곱해 더합니다.
이 부분은 GLM 유형에 따라 달라지지 않습니다. 즉, 로지스틱 회귀든 포아송 회귀든 선형 예측자는 동일한 형태입니다.
링크 함수는 선형 예측자와 반응 변수의 기댓값을 연결합니다. GLM을 유연하게 만드는 요소입니다.
링크 함수가 없으면 선형 예측자는 음의 무한대부터 양의 무한대까지 어떤 값이든 출력할 수 있습니다. 이는 연속형 결과엔 괜찮지만, 확률이나 개수에는 적합하지 않습니다. 링크 함수는 선택한 분포에 맞게 출력이 올바른 범위에 위치하도록 변환합니다.
예를 들어 로지스틱 회귀는 로짓 링크를 사용해 실수 전 범위의 선형 예측자를 0과 1 사이의 확률로 사상합니다. 포아송 회귀는 로그 링크를 사용해 예측값이 항상 양수가 되도록 합니다.
완전한 GLM 방정식은 이 세 요소를 결합합니다:
GLM 방정식
여기서 g()는 링크 함수이고, μ는 반응의 기댓값입니다. 분포는 μ가 무엇을 의미하는지 정의하고, 선형 예측자는 Xβ를 계산하며, 링크 함수는 둘을 이어줍니다.
링크 함수는 선형 예측자가 결과로 변환되는 방식을 결정합니다. 데이터 유형마다 다른 변환이 필요하며, 각 GLM 유형에는 분포와 짝을 이루는 기본 링크 함수가 있습니다.
항등 링크는 가장 단순합니다. 아무것도 하지 않습니다. 선형 예측자는 반응의 기댓값과 같습니다:
항등 링크
이것이 선형 회귀가 사용하는 링크입니다. 입력이 가중합으로 결합되고, 그 합이 곧 예측값이 됩니다. 결과가 임의의 연속값을 가질 수 있으므로 변환이 필요 없습니다.
로짓 링크는 확률(0과 1 사이)을 실수 전 범위로 사상합니다:
로짓 링크
이는 로지스틱 회귀가 사용합니다. 선형 예측자는 음의 무한대부터 양의 무한대까지 어떤 값이든 가질 수 있지만, 역변환 후 예측은 항상 0과 1 사이에 위치합니다. 로그 안의 비율 μ/(1-μ)을 오즈(odds)라 하고, 그 로그를 로그 오즈(log-odds)라 합니다. 따라서 로지스틱 회귀 계수를 해석할 때는 로그 오즈 공간에서 작업하게 됩니다.
로그 링크는 기댓값의 자연로그를 취합니다:
로그 링크
이는 포아송 회귀가 사용합니다. 선형 예측자는 임의의 실수일 수 있지만, 역변환으로 지수화를 거치면 예측은 항상 양수가 됩니다. 음수 사건 수는 있을 수 없으므로 개수 데이터에 꼭 맞습니다.
GLM은 익숙한 모델로 바라볼 때 훨씬 구체적으로 느껴집니다. 선형 회귀, 로지스틱 회귀, 포아송 회귀는 모두 GLM입니다. 차이는 각각이 사용하는 분포와 링크 함수의 조합뿐입니다.
선형 회귀는 가장 단순한 GLM입니다. 반응은 정규분포를 따르고, 링크 함수는 항등 링크, 즉 변환이 전혀 없습니다.
GLM으로서의 선형 회귀
선형 예측자는 반응의 기댓값과 정확히 같습니다. 여러분이 지금껏 사용해온 GLM이지만 그렇게 부르지 않았을 뿐입니다.
로지스틱 회귀는 이항분포와 로짓 링크를 사용해 이진 결과를 모델링합니다.
GLM으로서의 로지스틱 회귀
왼쪽은 사건의 로그 오즈이고, 오른쪽은 표준적인 입력의 선형 결합입니다. 로짓 링크 덕분에 Xβ가 얼마나 크거나 작아져도 예측은 0과 1 사이의 확률로 매핑됩니다.
포아송 회귀는 포아송 분포와 로그 링크를 사용해 개수 데이터를 모델링합니다.
GLM으로서의 포아송 회귀
기대 개수의 로그가 선형 예측자와 같습니다. 양변을 지수화하면 μ = e^(Xβ)가 되며, 이는 항상 양수입니다. 개수 데이터에 꼭 필요한 성질입니다.
GLM은 선형 회귀처럼 최소제곱법을 사용하지 않습니다. 대신 최대우도추정(MLE)에 의존합니다.
아이디어는 간단합니다. MLE는 선택한 분포하에서 관측 데이터를 가장 그럴듯하게 만드는 계수 집합을 찾습니다. 로지스틱 회귀에서는 이항 모형이 주어졌을 때 관측된 0과 1을 가장 그럴듯하게 만드는 계수를 찾습니다. 포아송 회귀에서는 관측된 개수를 가장 잘 설명하는 계수를 찾습니다.
대부분의 GLM에는 해석해가 없으므로 최적화는 반복적으로 이뤄집니다. 알고리즘은 초기 계수 추정에서 시작해 적합도를 평가하고, 조정한 뒤, 추정치가 수렴할 때까지 반복합니다.
가장 일반적인 방법은 반복 가중 최소제곱(IRLS)로, MLE 문제를 일련의 가중 선형 회귀로 재구성합니다. 기울기 기반 방법도 작동하며, 최급강하 방향을 계산해 그쪽으로 이동합니다. statsmodels나 R의 glm() 같은 라이브러리가 이러한 과정을 내부에서 처리하므로, 직접 해법을 구현할 필요는 없습니다.
기억할 점은 분포와 링크 함수는 여러분이 선택하고, 최적화기는 최적의 계수를 찾는다는 것입니다. 이제 실전에서 어떻게 작동하는지 보여드리겠습니다.
이 섹션에서는 동일한 데이터셋(급여, 경력 연수, 초과근무 시간, 퇴사 여부(이진), 병가 일수(개수) 열을 가진 모의 직원 이탈 데이터셋)을 사용해 Python과 R에서 로지스틱 회귀와 포아송 회귀를 살펴보겠습니다.
언급한 데이터셋을 Python에서 생성한 뒤, Python과 R에서 계산에 사용하겠습니다:
import numpy as np
import pandas as pd
np.random.seed(42)
n = 500
# Employee dataset
df = pd.DataFrame({
"salary": np.random.normal(55000, 12000, n).astype(int),
"experience_years": np.random.poisson(5, n),
"overtime_hours": np.random.poisson(8, n),
})
# Simulate binary outcome: left the company
prob_left = 1 / (1 + np.exp(-(
-2 + -0.00003 * df["salary"] + -0.05 * df["experience_years"] + 0.12 * df["overtime_hours"]
)))
df["left"] = np.random.binomial(1, prob_left)
# Simulate count outcome: sick days per year
df["sick_days"] = np.random.poisson(
np.exp(1.2 + 0.00001 * df["salary"] + 0.02 * df["overtime_hours"])
)
# Save to use later in R
df.to_csv("data.csv", index=False)
df.head()
샘플 직원 이탈 데이터셋
Python에서 GLM을 위한 주된 선택지는 statsmodels와 scikit-learn입니다. 여기서는 statsmodels를 사용하겠습니다. 계수, p-값, 신뢰구간 등을 포함한 완전한 통계 요약을 제공하기 때문입니다. GLM을 해석할 때 꼭 필요합니다.
직원이 퇴사했는지 여부를 예측하는 로지스틱 회귀를 적합하는 방법은 다음과 같습니다:
import statsmodels.api as sm
X = sm.add_constant(df[["salary", "experience_years", "overtime_hours"]])
logit_model = sm.GLM(df["left"], X, family=sm.families.Binomial())
logit_results = logit_model.fit()
print(logit_results.summary())
GLM 로지스틱 회귀 결과
핵심은 sm.families.Binomial()입니다. 이 한 가지 인자로 분포(이항)와 기본 링크 함수(로짓)를 모두 설정합니다. 기본이 아닌 링크를 원하지 않는 한 별도로 링크를 지정할 필요가 없습니다.
이제 동일한 데이터셋에서 병가 일수를 예측하는 포아송 회귀를 적합해봅시다:
poisson_model = sm.GLM(df["sick_days"], X, family=sm.families.Poisson())
poisson_results = poisson_model.fit()
print(poisson_results.summary())
GLM 포아송 회귀 결과
Binomial()을 Poisson()으로 바꾸기만 하면, 포아송 분포와 로그 링크가 적용됩니다. 출력 표는 비슷해 보이지만, 링크 함수가 달라졌으므로 해석은 달라집니다.
이제 로지스틱 회귀에서 예측된 확률을 초과근무 시간에 대해 시각화해보겠습니다:
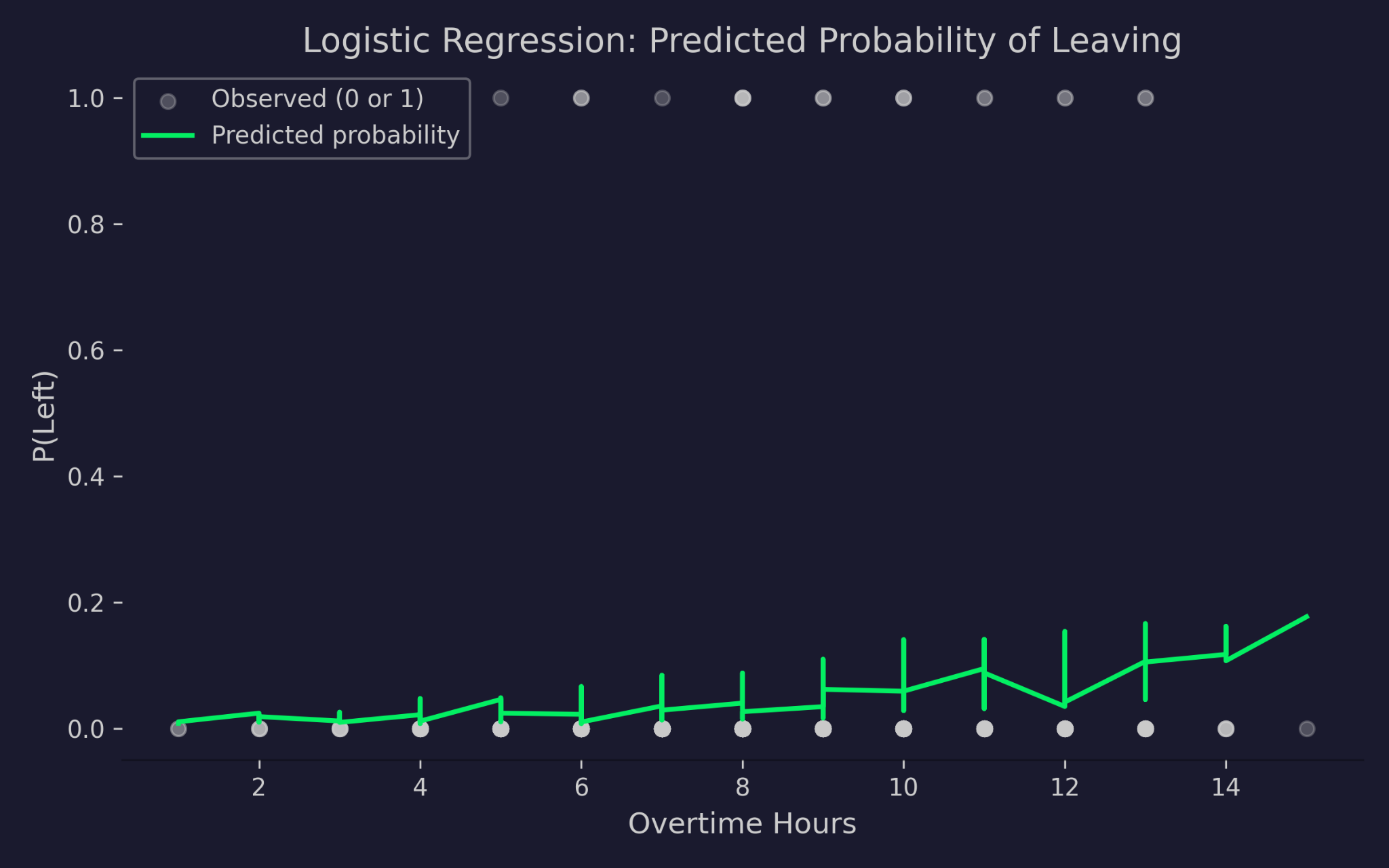
초과근무 시간 대비 퇴사 확률 예측
차트는 x축에 초과근무 시간, y축에 퇴사 확률을 나타냅니다. 회색 점은 실제 결과(0: 재직, 1: 퇴사)이며, 초록색 곡선은 모델의 예측 확률입니다. 초과근무 시간이 늘수록 예측 퇴사 확률은 증가하지만 0 아래로 떨어지거나 1을 넘지 않습니다. 이는 로짓 링크 함수가 작동한 결과로, 입력값이 얼마나 극단적이더라도 선형 예측자를 유효한 확률 범위로 눌러줍니다.
R의 내장 함수 glm()는 동일한 논리를 따르지만 문법이 다릅니다. family 인자는 분포와 링크 함수를 설정하고, 모델은 R의 포뮬러 인터페이스로 정의합니다.
동일한 로지스틱 회귀를 R로 표현하면 다음과 같습니다:
# Read the dataset
df <- read.csv("data.csv")
# Fit logistic regression
logit_model <- glm(left ~ salary + experience_years + overtime_hours,
data = df,
family = binomial(link = "logit"))
summary(logit_model)
R에서의 GLM 로지스틱 회귀
포뮬러 left ~ salary + experience_years + overtime_hours는 무엇을 예측하고 어떤 입력을 사용할지 R에 알려줍니다. family = binomial(link = "logit")는 분포와 링크를 설정합니다. 로짓은 이항 가족의 기본 링크이므로 family = binomial()로 줄여 쓸 수도 있습니다.
포아송 회귀도 거의 동일합니다:
poisson_model <- glm(sick_days ~ salary + experience_years + overtime_hours,
data = df,
family = poisson(link = "log"))
summary(poisson_model)
R에서의 GLM 포아송 회귀
binomial()을 poisson()으로 바꾸고 반응 변수를 변경하면 완료입니다.
두 언어 모두 동일한 접근을 사용합니다. 분포와 해당 기본 링크를 결합한 family/분포 인자를 전달합니다:

Python과 R에서 분포와 링크 지정
각 family에는 기본 링크가 있지만, 재정의할 수 있습니다. Python에서는 링크 객체를 전달합니다: sm.families.Binomial(link=sm.families.links.Probit()). R에서는 링크 인자를 바꾸면 됩니다: family = binomial(link = "probit").
대부분의 경우 기본 링크가 올바른 선택입니다.
GLM 계수는 모델 유형에 따라 의미가 달라집니다. 링크 함수가 해석 방식을 바꿉니다.
선형 회귀에서는 해석이 쉽습니다. experience_years의 계수가 500이라면 경력 1년 증가할 때마다 예측 급여가 500만큼 증가한다는 뜻입니다. 항등 링크 덕분에 계수가 곧 결과에 직접 대응됩니다.
로지스틱 회귀는 다릅니다. 로짓 링크는 계수가 로그 오즈 공간에 있음을 의미합니다. overtime_hours의 계수가 0.12라고 해서 퇴사 확률이 0.12만큼 증가한다는 뜻은 아닙니다. 초과근무 1시간이 추가될 때 퇴사의 로그 오즈가 0.12 증가한다는 뜻입니다. 더 해석하기 쉬운 값이 필요하면 계수를 지수화하세요: e^0.12 ≈ 1.127. 이는 오즈비입니다. 초과근무 1시간마다 퇴사 오즈가 약 1.13배가 됩니다.
포아송 회귀의 계수는 로그 링크를 통해 작동합니다. overtime_hours의 계수가 0.02라면 초과근무 1시간마다 기대 개수의 로그가 0.02 증가함을 의미합니다. 이를 지수화하면 e^0.02 ≈ 1.02가 되어, 초과근무 1시간마다 기대 병가 일수가 약 1.02배가 됩니다.
패턴은 항상 같습니다. 계수 공간에서 결과 공간으로 돌아가려면 링크 함수의 역함수를 적용합니다.
적절한 GLM 선택은 한 가지 질문으로 귀결됩니다. 결과 변수가 어떻게 생겼나요?
결과가 이진(예/아니오, 0/1, 합격/불합격)라면 로지스틱 회귀를 사용하세요. 이항분포, 로짓 링크. 이는 이탈 예측, 사기 탐지, 질병 분류(유/무), 치료 반응 여부 예측 같은 분류 작업을 포괄합니다.
결과가 개수(시간 창 내 사건 수)라면 포아송 회귀를 사용하세요. 포아송 분포, 로그 링크. 시간당 웹사이트 방문 수나 연간 보험 청구 건수 예측 같은 문제에 적합합니다.
결과가 연속형이고 대략 정규분포(매출, 시험 점수)에 가깝다면 표준 선형 회귀로 충분합니다. 정규분포, 항등 링크. 여러분이 이미 알고 있는 GLM입니다.
항상 결과 변수에서 출발해 분포를 매칭하고, 그다음 링크 함수가 따라옵니다.
GLM을 사용할 때 피해야 할 흔한 실수를 소개합니다.
가장 흔한 실수입니다. 결과가 개수인데 선형 회귀를 적합하면 음의 예측이 나옵니다. 결과가 이진인데 포아송을 사용하면 모델이 의미를 잃습니다. 항상 결과 변수를 먼저 살펴보고 그에 맞는 분포를 선택하세요.
링크 함수는 입력과 출력 사이의 관계를 변환합니다. 로지스틱 회귀의 계수 0.5는 "확률이 0.5 증가"를 의미하지 않습니다. 로그 오즈가 0.5 증가함을 뜻합니다. 변환을 잊으면 효과 크기와 변수 중요도에 대한 잘못된 결론으로 이어집니다.
포아송 회귀의 계수는 숫자가 비슷해 보여도 로지스틱 회귀의 계수와 비교할 수 없습니다. 0.3이라는 값이 로그 링크인지 로짓 링크인지에 따라 의미가 달라집니다. 항상 사용 중인 특정 모델의 맥락에서 계수를 해석하세요.
GLM은 선형 회귀보다 유연하지만, 여전히 가정이 있습니다. 포아송 회귀는 평균과 분산이 같다고 가정합니다. 개수 데이터의 분산이 평균보다 훨씬 크면 표준오차가 과소추정되고 p-값이 왜곡됩니다. 로지스틱 회귀는 관측치가 서로 독립이라고 가정합니다.
이를 극복하려면, 어떤 GLM이든 적합 후 잔차를 확인하고 부적합을 시사하는 패턴을 찾아보세요.
GLM은 선형 회귀의 기본 논리를 유지하면서 그 너머로 나아갈 수 있는 체계적인 방법을 제공합니다. 입력의 선형 결합이라는 아이디어는 그대로이되, 사용하는 데이터에 맞춰 분포와 링크 함수가 바뀝니다.
GLM 뒤에는 세 가지 구성요소가 있습니다. 적절한 분포를 선택하고, 선형 예측자를 설정하고, 올바른 링크 함수를 적용하는 방법만 알면 하나의 사고방식으로 이진 결과, 개수, 연속형 데이터를 모두 다룰 수 있습니다.
가장 좋은 다음 단계는 직접 시도하는 것입니다. 비정규 결과를 가진 데이터셋을 골라 Python이나 R에서 GLM을 적합해 보고, 링크 함수를 통해 계수를 해석하는 연습을 하세요. 관심 있는 데이터셋을 사용하면 여기서 다룬 이론이 금세 와닿을 것입니다.
선형 회귀와 GLM을 넘어가고 싶다면, Machine Learning Scientist in Python 트랙에 등록하세요. 2026년에 취업 준비에 필요한 모든 것을 보여드립니다.
DataCamp과 함께 배우세요
courses
courses
courses