
Cours
Algèbre linéaire pour la data science en R
4 h
21.2K
La régression linéaire est un excellent premier modèle à tester, mais elle atteint vite ses limites dès que vos données ne suivent pas une loi normale.
Supposons que vous cherchiez à prédire si un client va résilier (oui ou non). La régression linéaire ne sait pas gérer ce type d'issue. Elle prédit des valeurs continues, et vous vous retrouvez avec des sorties comme -0,3 ou 1,7 pour une variable qui ne peut être que 0 ou 1. Même problème avec les données de comptage, comme le nombre de tickets de support par heure. La régression linéaire peut prédire des comptes négatifs, ce qui n'a aucun sens.
Les modèles linéaires généralisés (GLM) corrigent cela en étendant la régression linéaire pour gérer différents types d'issues. L'idée de base reste la même — une combinaison linéaire des entrées — mais avec la flexibilité de modéliser des données binaires et d'autres distributions non normales.
Dans cet article, je vous explique ce que sont les GLM, je présente leurs trois composants clés et je vous montre comment les ajuster et les interpréter en Python et en R.
Mais comment fonctionne exactement la régression linéaire ? Consultez notre guide sur la régression linéaire simple pour en comprendre les hypothèses et les diagnostics, ainsi que la façon d'interpréter les résultats.
Un modèle linéaire généralisé (GLM) est une extension de la régression linéaire qui permet à la variable réponse de suivre différentes lois de probabilité, pas seulement la loi normale.
L'élément clé à retenir est que le GLM n'est pas un modèle unique. C'est un cadre. La régression linéaire, la régression logistique et la régression de Poisson sont toutes des GLM. Chacune utilise une distribution différente et une manière différente de relier les entrées aux sorties, mais elles suivent toutes la même structure.
La régression linéaire classique repose sur deux grandes hypothèses : votre issue suit une distribution normale et la variance reste constante sur l'ensemble des prédictions. Si ces hypothèses ne tiennent pas, vous obtiendrez des résultats incohérents.
Par exemple, si vous construisez un modèle pour prédire si un demandeur de prêt fera défaut, l'issue est binaire — 0 ou 1. La régression linéaire ne respecte pas cette contrainte. Elle peut prédire -0,2 ou 1,4, deux valeurs impossibles.
Même chose pour les données de comptage. Si vous prédisez le nombre de réadmissions à l'hôpital par mois, la régression linéaire peut renvoyer des nombres négatifs. On ne peut pas avoir -3 réadmissions.
Dans les deux cas, le problème ne vient pas de la combinaison linéaire des entrées — cette partie fonctionne bien. Le problème vient de la façon dont le modèle relie ces entrées à la sortie. Les GLM résolvent cela en ajoutant une fonction de lien qui transforme la sortie pour qu'elle respecte l'intervalle naturel des données. Les probabilités restent entre 0 et 1. Les comptes restent non négatifs. Vous allez voir tout cela dans un instant.
Chaque GLM se compose de trois éléments : une distribution, un prédicteur linéaire et une fonction de lien. Passons-les en revue.
La composante aléatoire décrit le type de données que produit votre variable réponse. Autrement dit, elle choisit la loi de probabilité qui décrit le mieux votre issue.
La régression linéaire suppose une distribution normale, donc une issue continue et symétrique autour de la moyenne. Mais toutes les données ne se comportent pas ainsi.
Si votre issue est binaire (oui/non, 0/1), vous utiliserez une distribution binomiale. Si vous modélisez des données de comptage — comme le nombre d'erreurs par jour — une distribution de Poisson est plus appropriée.
La distribution choisie conditionne tout le reste du modèle.
La composante systématique, vous la connaissez déjà via la régression linéaire. C'est une combinaison linéaire de vos variables explicatives :
Composante systématique
Où X est votre matrice de caractéristiques d'entrée et β le vecteur des coefficients. Vous multipliez chaque variable par son poids puis vous additionnez le tout.
Cette partie ne change pas d'un GLM à l'autre. Autrement dit, que vous ajustiez une régression logistique ou une régression de Poisson, le prédicteur linéaire a la même forme.
La fonction de lien relie le prédicteur linéaire à la valeur attendue de la variable réponse. C'est elle qui rend les GLM flexibles.
Sans fonction de lien, le prédicteur linéaire prend des valeurs de moins l'infini à plus l'infini. C'est acceptable pour des issues continues, mais pas pour des probabilités ou des comptes. La fonction de lien transforme la sortie pour qu'elle se situe dans l'intervalle adapté à votre distribution choisie.
Par exemple, la régression logistique utilise le lien logit, qui convertit un prédicteur linéaire pouvant prendre toute valeur réelle en une probabilité comprise entre 0 et 1. La régression de Poisson utilise le lien logarithmique, qui garantit des prédictions toujours positives.
L'équation complète d'un GLM combine ces trois composants :
Équation d'un GLM
Où g() est la fonction de lien et μ la valeur attendue de la réponse. La distribution définit ce que signifie μ, le prédicteur linéaire calcule Xβ et la fonction de lien fait le pont entre les deux.
La fonction de lien détermine comment le prédicteur linéaire se convertit en votre issue. Différents types de données nécessitent différentes transformations, et chaque type de GLM possède une fonction de lien par défaut associée à sa distribution.
Le lien identité est le plus simple — il ne fait rien. Le prédicteur linéaire est égal à la valeur attendue de la réponse :
Lien identité
C'est ce qu'utilise la régression linéaire. Vos entrées se combinent en une somme pondérée, et cette somme est la prédiction. Aucune transformation n'est nécessaire, car l'issue peut prendre n'importe quelle valeur continue.
Le lien logit prend une probabilité (entre 0 et 1) et la projette sur l'ensemble de la droite réelle :
Lien logit
C'est ce qu'utilise la régression logistique. Le prédicteur linéaire peut prendre n'importe quelle valeur de moins l'infini à plus l'infini, mais après la transformation inverse, la prédiction est toujours comprise entre 0 et 1. Le ratio à l'intérieur du logarithme — μ/(1-μ) — s'appelle les cotes (odds), et le logarithme des cotes correspond au log-odds. Quand vous interprétez les coefficients d'une régression logistique, vous travaillez donc dans l'espace des log-odds.
Le lien logarithmique prend le logarithme naturel de la valeur attendue :
Lien logarithmique
C'est ce qu'utilise la régression de Poisson. Le prédicteur linéaire peut être n'importe quel nombre réel, mais après exponentiation (transformation inverse), la prédiction est toujours positive. C'est exactement ce qu'il faut pour des données de comptage, puisque les événements négatifs n'existent pas.
Les GLM peuvent sembler abstraits jusqu'à ce que vous les voyiez sous la forme de modèles que vous connaissez déjà. La régression linéaire, la régression logistique et la régression de Poisson sont toutes des GLM. La seule différence est que chacune combine une distribution et une fonction de lien différentes.
La régression linéaire est le GLM le plus simple. La réponse suit une distribution normale et la fonction de lien est l'identité, c'est-à-dire aucune transformation.
Régression linéaire comme GLM
Le prédicteur linéaire est directement égal à l'issue attendue. C'est le GLM que vous utilisez déjà, sans forcément le nommer ainsi.
La régression logistique modélise des issues binaires à l'aide d'une distribution binomiale et d'un lien logit.
Régression logistique comme GLM
Le côté gauche est le log-odds de l'événement. Le côté droit est votre combinaison linéaire standard des entrées. Le lien logit garantit que les prédictions se convertissent en probabilités entre 0 et 1, quelle que soit l'amplitude de Xβ.
La régression de Poisson modélise des données de comptage à l'aide d'une distribution de Poisson et d'un lien logarithmique.
Régression de Poisson comme GLM
Le logarithme du compte attendu est égal au prédicteur linéaire. En exponentiant les deux côtés, on obtient μ = e^(Xβ), toujours positif — exactement ce que requièrent les comptes.
Les GLM n'utilisent pas les moindres carrés ordinaires comme la régression linéaire. Ils s'appuient plutôt sur l'estimation du maximum de vraisemblance (EMV).
Le principe est simple. L'EMV trouve l'ensemble de coefficients qui rend vos données observées les plus probables sous la distribution choisie. Pour une régression logistique, elle trouve les coefficients qui rendent les 0 et 1 observés les plus plausibles dans un modèle binomial. Pour une régression de Poisson, elle trouve les coefficients qui expliquent le mieux les comptes observés.
Il n'existe pas de solution analytique pour la plupart des GLM, l'optimisation est donc itérative. L'algorithme démarre avec une estimation initiale des coefficients, évalue l'ajustement, les ajuste et répète jusqu'à convergence.
La méthode la plus courante est l'algorithme des moindres carrés repondérés itératifs (IRLS), qui reformule l'EMV en une suite de régressions linéaires pondérées. Les méthodes à base de gradient fonctionnent aussi, en suivant la direction d'amélioration la plus forte. Des bibliothèques comme statsmodels et la fonction glm() de R gèrent tout cela en coulisse — vous n'avez pas à implémenter le solveur vous-même.
Retenez que vous choisissez la distribution et la fonction de lien, et l'optimiseur trouve les meilleurs coefficients. Voilà pour l'idée — voyons maintenant comment cela fonctionne en pratique.
Dans cette section, je passe en revue la régression logistique et la régression de Poisson en Python et en R sur le même jeu de données — un jeu simulé sur l'attrition des employés avec le salaire, les années d'expérience, les heures supplémentaires, l'information de départ (binaire) et le nombre de jours d'arrêt maladie (compte).
Je crée le jeu de données en Python, puis je l'utilise pour les calculs en Python et en R :
import numpy as np
import pandas as pd
np.random.seed(42)
n = 500
# Employee dataset
df = pd.DataFrame({
"salary": np.random.normal(55000, 12000, n).astype(int),
"experience_years": np.random.poisson(5, n),
"overtime_hours": np.random.poisson(8, n),
})
# Simulate binary outcome: left the company
prob_left = 1 / (1 + np.exp(-(
-2 + -0.00003 * df["salary"] + -0.05 * df["experience_years"] + 0.12 * df["overtime_hours"]
)))
df["left"] = np.random.binomial(1, prob_left)
# Simulate count outcome: sick days per year
df["sick_days"] = np.random.poisson(
np.exp(1.2 + 0.00001 * df["salary"] + 0.02 * df["overtime_hours"])
)
# Save to use later in R
df.to_csv("data.csv", index=False)
df.head()
Extrait du jeu de données d'attrition des employés
Python propose deux options principales pour les GLM : statsmodels et scikit-learn. J'utilise ici statsmodels car il fournit un résumé statistique complet, incluant coefficients, valeurs p et intervalles de confiance — indispensables pour interpréter un GLM.
Voici comment ajuster une régression logistique pour prédire si un employé est parti :
import statsmodels.api as sm
X = sm.add_constant(df[["salary", "experience_years", "overtime_hours"]])
logit_model = sm.GLM(df["left"], X, family=sm.families.Binomial())
logit_results = logit_model.fit()
print(logit_results.summary())
Résultats de la régression logistique (GLM)
La ligne clé est sm.families.Binomial(). Elle fixe à la fois la distribution (binomiale) et la fonction de lien par défaut (logit) en un seul argument. Inutile de préciser le lien séparément, sauf si vous en voulez un non par défaut.
Ajustons maintenant une régression de Poisson sur le même jeu de données pour prédire les jours d'arrêt maladie :
poisson_model = sm.GLM(df["sick_days"], X, family=sm.families.Poisson())
poisson_results = poisson_model.fit()
print(poisson_results.summary())
Résultats de la régression de Poisson (GLM)
Il suffit de remplacer Binomial() par Poisson() et le modèle utilise une distribution de Poisson avec un lien logarithmique. Le tableau de sortie a la même apparence, mais l'interprétation change car la fonction de lien n'est plus la même.
Visualisons à présent les probabilités prédites par la régression logistique en fonction des heures supplémentaires :
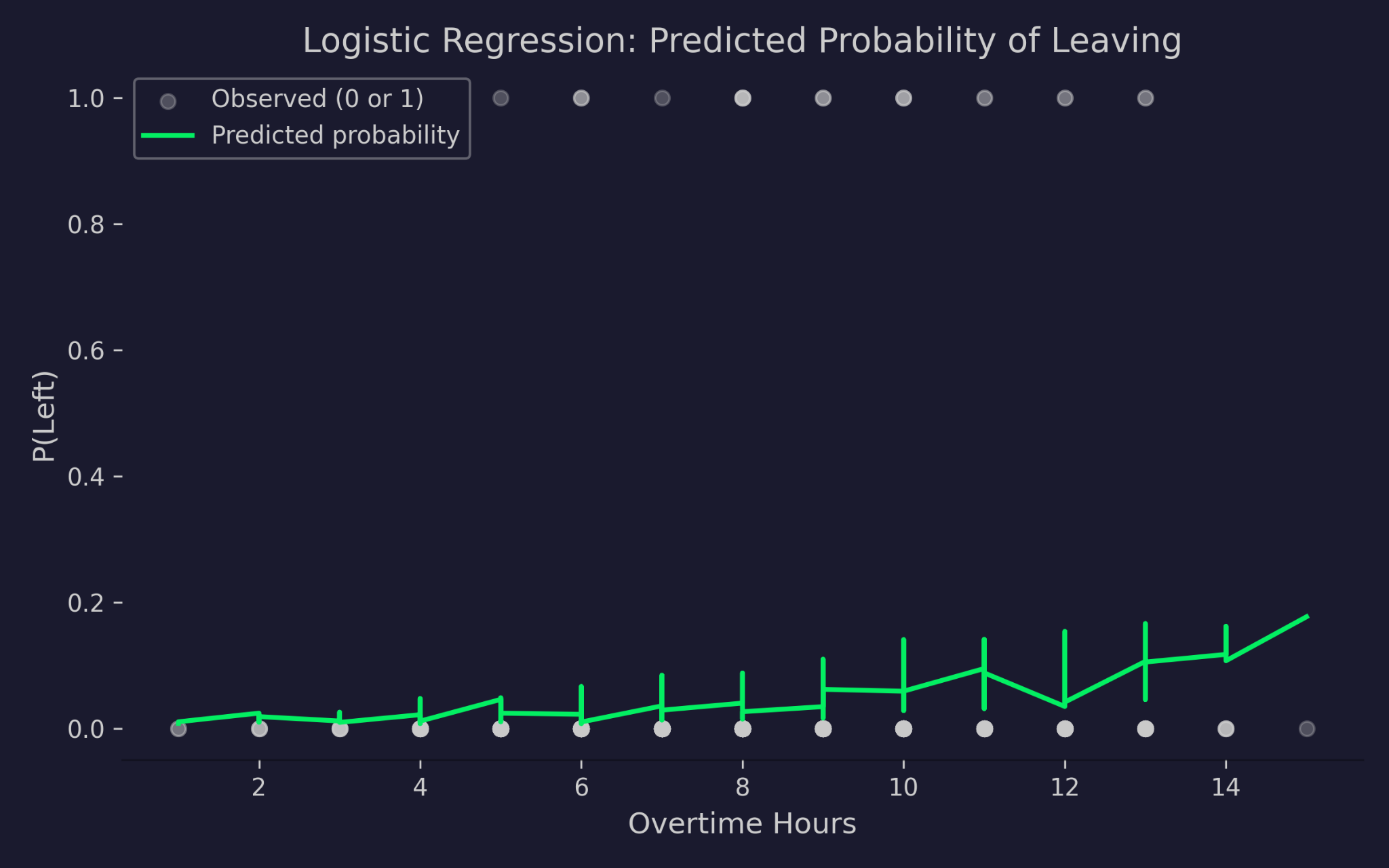
Probabilités prédites de départ en fonction des heures supplémentaires
Le graphique montre les heures supplémentaires en abscisse et la probabilité de départ en ordonnée. Les points gris sont les issues observées — 0 (resté) ou 1 (parti). La courbe verte est la probabilité prédite par le modèle. À mesure que les heures supplémentaires augmentent, la probabilité prédite de départ s'accroît, sans jamais être inférieure à 0 ni supérieure à 1. C'est l'effet du lien logit — il comprime le prédicteur linéaire dans un intervalle de probabilité valide, même pour des valeurs d'entrée extrêmes.
La fonction native glm() de R suit la même logique avec une syntaxe différente. L'argument family fixe la distribution et la fonction de lien, et vous définissez le modèle via l'interface de formules de R.
Voici la même régression logistique en R :
# Read the dataset
df <- read.csv("data.csv")
# Fit logistic regression
logit_model <- glm(left ~ salary + experience_years + overtime_hours,
data = df,
family = binomial(link = "logit"))
summary(logit_model)
Régression logistique (GLM) sous R
La formule left ~ salary + experience_years + overtime_hours indique à R quoi prédire et quelles variables explicatives utiliser. La partie family = binomial(link = "logit") définit la distribution et le lien. Vous pouvez l'abréger en family = binomial() puisque logit est le lien par défaut pour la famille binomiale.
La régression de Poisson est très similaire :
poisson_model <- glm(sick_days ~ salary + experience_years + overtime_hours,
data = df,
family = poisson(link = "log"))
summary(poisson_model)
Régression de Poisson (GLM) sous R
Il suffit de remplacer binomial() par poisson(), de changer la variable réponse, et le tour est joué.
Les deux langages adoptent la même approche — vous passez un argument famille/distribution qui combine la distribution et sa fonction de lien par défaut :

Spécifier la distribution et le lien en Python et en R
Chaque famille a un lien par défaut, mais vous pouvez le remplacer. En Python, vous pouvez passer un objet lien : sm.families.Binomial(link=sm.families.links.Probit()). En R, il suffit de modifier l'argument de lien : family = binomial(link = "probit").
Dans la plupart des cas, le lien par défaut est le bon choix.
Les coefficients d'un GLM ne signifient pas la même chose d'un type de modèle à l'autre. La fonction de lien change la manière de les interpréter.
En régression linéaire, l'interprétation est simple. Un coefficient de 500 sur experience_years signifie qu'une année d'expérience supplémentaire ajoute 500 à la valeur prédite du salaire. Le lien identité fait correspondre directement les coefficients à l'issue.
La régression logistique est différente. Le lien logit implique que les coefficients sont dans l'espace des log-odds. Un coefficient de 0,12 sur overtime_hours ne signifie pas que la probabilité de départ augmente de 0,12. Il signifie que le log-odds de départ augmente de 0,12 pour chaque heure supplémentaire. Pour quelque chose de plus parlant, exponentiez le coefficient : e^0.12 ≈ 1,127. Cela donne un ratio de cotes. Chaque heure supplémentaire multiplie les cotes de départ par environ 1,13.
Les coefficients d'une régression de Poisson s'interprètent via le lien logarithmique. Un coefficient de 0,02 sur overtime_hours signifie que chaque heure supplémentaire augmente le logarithme du compte attendu de 0,02. En l'exponentiant : e^0.02 ≈ 1,02, vous voyez que chaque heure supplémentaire multiplie le nombre attendu de jours d'arrêt maladie par environ 1,02.
La règle d'or consiste à appliquer l'inverse de la fonction de lien pour passer de l'espace des coefficients à l'espace de l'issue.
Choisir le bon GLM se résume à une question : à quoi ressemble votre variable réponse ?
Si votre issue est binaire (oui/non, 0/1, succès/échec), utilisez la régression logistique. Distribution binomiale, lien logit. Cela couvre des tâches de classification comme la prédiction de churn, la détection de fraude, la classification de maladies (présent/absent) ou la probabilité de réponse à un traitement.
Si votre issue est un compte (nombre d'événements dans une fenêtre de temps), utilisez la régression de Poisson. Distribution de Poisson, lien logarithmique. Cela convient à des problèmes tels que prédire le nombre de visites de site par heure ou de sinistres d'assurance par an.
Si votre issue est continue et à peu près normale (revenu, notes), la régression linéaire standard convient parfaitement. Distribution normale, lien identité. C'est le GLM que vous connaissez déjà.
Partez toujours de la variable réponse, associez-la à une distribution, puis la fonction de lien s'impose d'elle-même.
Voici des erreurs courantes à éviter lorsque vous travaillez avec des GLM.
C'est l'erreur la plus fréquente. Si votre issue est un compte et que vous ajustez une régression linéaire, vous obtiendrez des prédictions négatives. Si elle est binaire et que vous utilisez Poisson, le modèle n'aura pas de sens. Regardez toujours votre variable réponse en premier et choisissez la distribution qui lui correspond.
La fonction de lien transforme la relation entre entrées et sortie. Un coefficient de 0,5 en régression logistique ne signifie pas « la probabilité augmente de 0,5 ». Il signifie que le log-odds augmente de 0,5. Oublier la transformation conduit à de mauvaises conclusions sur les tailles d'effet et l'importance des variables.
Les coefficients d'une régression de Poisson ne sont pas comparables à ceux d'une régression logistique, même si les valeurs se ressemblent. Un coefficient de 0,3 signifie autre chose selon qu'il passe par un lien logarithmique ou logit. Interprétez toujours les coefficients dans le contexte du modèle utilisé.
Les GLM sont plus flexibles que la régression linéaire, mais ils conservent des hypothèses. La régression de Poisson suppose égalité de la moyenne et de la variance — si vos données de comptage ont une variance bien supérieure à la moyenne, les erreurs standards seront sous-estimées et vos valeurs p trompeuses. La régression logistique suppose l'indépendance des observations.
Pour y remédier, après l'ajustement de tout GLM, examinez les résidus et recherchez des motifs indiquant un mauvais ajustement.
Les GLM offrent une manière structurée d'aller au-delà de la régression linéaire tout en conservant sa logique fondamentale. L'idée de combinaison linéaire des entrées reste la même, mais la distribution et la fonction de lien s'adaptent aux données que vous modélisez.
Les GLM reposent sur trois composants. Une fois que vous savez choisir la bonne distribution, définir le prédicteur linéaire et appliquer la fonction de lien adaptée, vous pouvez traiter des issues binaires, des comptes et des données continues avec le même cadre mental.
La meilleure suite consiste à pratiquer. Choisissez un jeu de données avec une issue non normale, ajustez un GLM en Python ou en R, et entraînez-vous à interpréter les coefficients via la fonction de lien. Travaillez sur des données qui vous tiennent à cœur, et toute la théorie vue ici deviendra limpide en quelques minutes.
Si vous souhaitez aller au-delà de la régression linéaire et des GLM, inscrivez-vous à notre parcours Machine Learning Scientist in Python. Il couvre tout ce dont vous avez besoin pour être opérationnel en 2026.
Learn with DataCamp
Cours
Cours
Cours
Tutoriel
Mark Pedigo
Tutoriel
DataCamp Team
Tutoriel
Matt Crabtree
Tutoriel
Moez Ali
Tutoriel
Sejal Jaiswal
Tutoriel
Aditya Sharma