Courses
Rで学ぶデータサイエンスのための線形代数
4時間
21.2K
線形回帰は最初に試すモデルとしては優れていますが、データが正規分布に当てはまらない瞬間に限界が訪れます。
たとえば、顧客が解約するかどうか(はい/いいえの二値)を予測したいとします。線形回帰はそれが苦手です。連続値を予測するため、0か1でしかあり得ないものに対して-0.3や1.7のような出力になってしまいます。同じ問題はカウントデータ(1時間あたりのサポートチケット数など)でも起こります。線形回帰は負の件数を予測し得ますが、それは意味を成しません。
一般化線形モデル(GLM)は、線形回帰を拡張してさまざまな種類の結果変数を扱えるようにすることで、この問題を解決します。核となる考え方は同じ、すなわち入力の線形結合ですが、二値データやその他の非正規分布も柔軟に表現できます。
本記事では、GLMとは何かを解説し、その3つの主要構成要素を見ていき、PythonとRの両方での当てはめ方と解釈方法を紹介します。
では、線形回帰は具体的にどのように機能するのでしょうか?前提条件や診断、結果の解釈を学ぶには、単回帰の入門ガイドをお読みください。
一般化線形モデル(GLM)は、応答変数が正規分布に限らず、さまざまな確率分布に従うことを許す、線形回帰の拡張です。
ここで重要なのは、GLMは単一のモデルではなく、枠組みだということです。線形回帰、ロジスティック回帰、ポアソン回帰はいずれもGLMです。各モデルは異なる分布と、入力と出力を結びつける異なる方法を用いますが、同じ構造に従います。
標準的な線形回帰は2つの大きな仮定を置きます。結果が正規分布であること、そして予測全体で分散が一定であることです。これらが成り立たないと、意味を成さない結果になります。
例えば、ローン申請者が延滞するかどうかを予測するモデルでは、結果は二値(0/1)です。線形回帰はその境界を尊重しません。-0.2や1.4のように不可能な値を予測し得ます。
カウントデータも同様です。月あたりの再入院数を予測しようとすると、線形回帰は負の数を出力することがあります。-3件の再入院ということは起こり得ません。
どちらの場合も問題は入力の線形結合自体ではありません。そこはうまく機能します。問題は、その入力を出力に写像する方法です。GLMはここにリンク関数を導入して解決します。リンク関数は出力をデータの自然な範囲に変換します。確率は0から1の間に収まり、カウントは非負に保たれます。詳しくはこの後に説明します。
すべてのGLMは、分布、線形予測子、リンク関数の3要素から成ります。順に見ていきましょう。
確率成分は、応答変数がどのようなデータを生み出すか、つまり結果を最もよく表す確率分布を定めます。
線形回帰は正規分布を仮定するため、結果は連続で平均の周りに対称です。しかし、すべてのデータがそうとは限りません。
結果が二値(はい/いいえ、0/1)の場合は二項分布を用います。カウントデータ(1日あたりのエラー数など)をモデル化する場合は、ポアソン分布がより適しています。
選ぶ分布が、その後のすべてを左右します。
系統成分は、線形回帰でおなじみの部分です。入力変数の線形結合です:
系統成分
ここで、Xは入力特徴量の行列、βは係数ベクトルです。各特徴量に重みを掛けて合計します。
この部分はGLM間で変わりません。つまり、ロジスティック回帰でもポアソン回帰でも、線形予測子の形は同じです。
リンク関数は、線形予測子と応答の期待値を結びつけます。GLMを柔軟にしている要素です。
リンク関数がなければ、線形予測子の出力は負の無限大から正の無限大まで取り得ます。これは連続的な結果には問題ありませんが、確率やカウントには不適切です。リンク関数は出力を選んだ分布に適した範囲へと変換します。
例えば、ロジスティック回帰はロジットリンクを使い、任意の実数を取り得る線形予測子を0〜1の確率に写像します。ポアソン回帰は対数リンクを使い、予測値が常に正になるようにします。
完全なGLMの式は、この3つを組み合わせたものです:
GLMの式
ここで、g()はリンク関数、μは応答の期待値です。分布がμの意味を定め、線形予測子がXβを計算し、リンク関数が両者を橋渡しします。
リンク関数は、線形予測子がどのように結果へ変換されるかを決めます。データ型ごとに異なる変換が必要で、各GLMには分布と組み合わさる既定のリンク関数があります。
恒等リンクは最も単純で、何もしません。線形予測子が応答の期待値に等しくなります:
恒等リンク
これは線形回帰が用いるものです。入力は加重和にまとめられ、その和が予測値になります。結果が任意の連続値を取り得るため、変換は不要です。
ロジットリンクは、0〜1の確率を実数全体へ写像します:
ロジットリンク
これはロジスティック回帰が用います。線形予測子は負の無限大から正の無限大まで取り得ますが、逆変換後の予測値は常に0〜1に収まります。対数の中の比μ/(1-μ)はオッズと呼ばれ、その対数が対数オッズです。したがってロジスティック回帰の係数を解釈する際は、対数オッズの空間で考えることになります。
対数リンクは期待値の自然対数を取ります:
対数リンク
これはポアソン回帰が用います。線形予測子は任意の実数を取り得ますが、逆変換で指数をとると予測値は常に正になります。負のイベント数はあり得ないため、カウントデータにうってつけです。
GLMは、見慣れたモデルとして捉えると抽象性が薄れます。線形回帰、ロジスティック回帰、ポアソン回帰はいずれもGLMです。違いは、分布とリンク関数の組み合わせが異なるだけです。
線形回帰は最も単純なGLMです。応答は正規分布に従い、リンク関数は恒等リンク、つまり変換なしです。
GLMとしての線形回帰
線形予測子は期待される結果にそのまま等しくなります。これは、これまで使ってきたGLMをあえてそう呼んでいなかっただけとも言えます。
ロジスティック回帰は、二値の結果を二項分布とロジットリンクでモデル化します。
GLMとしてのロジスティック回帰
左辺は事象の対数オッズ、右辺は標準的な入力の線形結合です。ロジットリンクにより、Xβがどれほど大きく(小さく)なっても、予測は常に0から1の確率に写像されます。
ポアソン回帰は、カウントデータをポアソン分布と対数リンクでモデル化します。
GLMとしてのポアソン回帰
期待カウントの対数が線形予測子に等しくなります。両辺を指数化するとμ = e^(Xβ)となり、常に正になります。カウントに必要な性質そのものです。
GLMは線形回帰のように最小二乗法は使いません。代わりに最尤推定(MLE)に依拠します。
考え方は単純です。MLEは、選んだ分布の下で観測データが最も起こりやすくなる係数の組を見つけます。ロジスティック回帰なら、二項モデルのもとで観測された0と1が最も尤もらしくなる係数を見つけます。ポアソン回帰なら、観測されたカウントを最もよく説明する係数を求めます。
多くのGLMには閉形式解がないため、最適化は反復的に行われます。アルゴリズムは係数の初期値から始め、当てはまりを評価し、調整し、推定値が収束するまで繰り返します。
最も一般的な方法は反復再重み付き最小二乗法(IRLS)で、MLE問題を重み付き線形回帰の逐次解として解き直します。勾配ベースの手法も有効で、最急降下方向を計算してそこへ進みます。statsmodelsやRのglm()のようなライブラリが裏側ですべて処理するので、自分でソルバーを実装する必要はありません。
覚えておくべきなのは、分布とリンク関数を選ぶのは自分で、最適化器が最良の係数を見つけてくれるということです。では実際にどのように機能するのか見ていきましょう。
このセクションでは、同じデータセット(給与、経験年数、残業時間、退職の有無(二値)、取得病欠日数(カウント)を含むシミュレートした従業員離職データ)を用いて、PythonとRでロジスティック回帰とポアソン回帰を実演します。
ここではPythonで前述のデータセットを作成し、以降の計算をPythonとRの両方で行います。
import numpy as np
import pandas as pd
np.random.seed(42)
n = 500
# Employee dataset
df = pd.DataFrame({
"salary": np.random.normal(55000, 12000, n).astype(int),
"experience_years": np.random.poisson(5, n),
"overtime_hours": np.random.poisson(8, n),
})
# Simulate binary outcome: left the company
prob_left = 1 / (1 + np.exp(-(
-2 + -0.00003 * df["salary"] + -0.05 * df["experience_years"] + 0.12 * df["overtime_hours"]
)))
df["left"] = np.random.binomial(1, prob_left)
# Simulate count outcome: sick days per year
df["sick_days"] = np.random.poisson(
np.exp(1.2 + 0.00001 * df["salary"] + 0.02 * df["overtime_hours"])
)
# Save to use later in R
df.to_csv("data.csv", index=False)
df.head()
従業員離職データ(サンプル)
PythonでGLMを扱う主な選択肢はstatsmodelsとscikit-learnの2つです。ここでは、係数・p値・信頼区間などの統計的サマリーを提供してくれるstatsmodelsを使います。GLMの解釈にはこれらが必要になります。
従業員が退職したかどうかを予測するロジスティック回帰の当てはめは以下の通りです。
import statsmodels.api as sm
X = sm.add_constant(df[["salary", "experience_years", "overtime_hours"]])
logit_model = sm.GLM(df["left"], X, family=sm.families.Binomial())
logit_results = logit_model.fit()
print(logit_results.summary())
GLMロジスティック回帰の結果
重要なのはsm.families.Binomial()という一行です。これにより分布(二項)と既定のリンク関数(ロジット)が一度に設定されます。既定以外のリンクを使いたい場合を除き、リンクを別途指定する必要はありません。
次に、同じデータセットで病欠日数を予測するポアソン回帰を当てはめます。
poisson_model = sm.GLM(df["sick_days"], X, family=sm.families.Poisson())
poisson_results = poisson_model.fit()
print(poisson_results.summary())
GLMポアソン回帰の結果
ここではBinomial()をPoisson()に置き換えるだけで、ポアソン分布と対数リンクが使われます。出力表は見た目こそ同じですが、リンク関数が異なるため解釈は変わります。
続いて、ロジスティック回帰から得た予測確率を残業時間に対して可視化します。
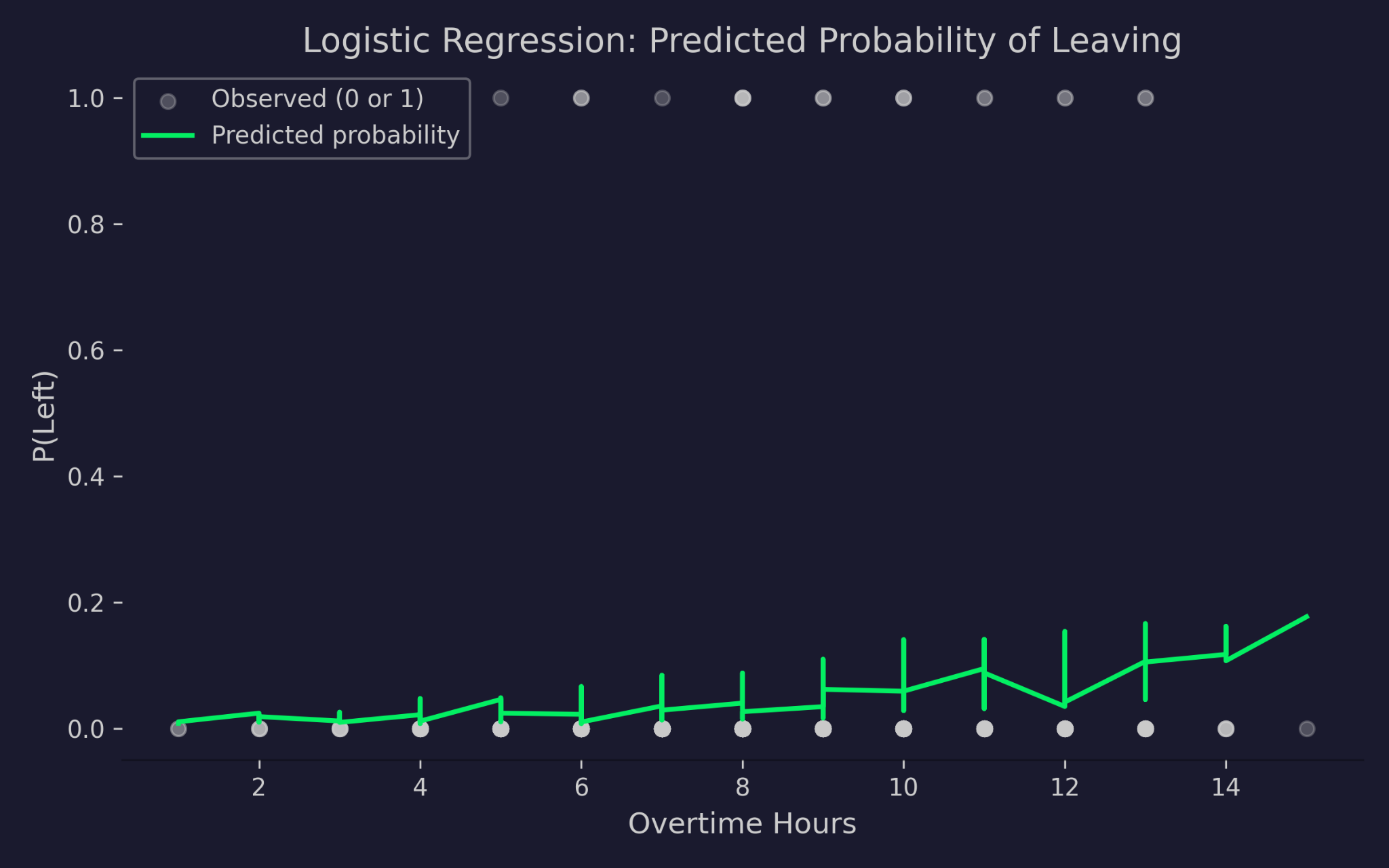
残業時間に対する退職確率の予測
グラフは、横軸に残業時間、縦軸に退職確率を示しています。灰色の点は実際の結果(0=在籍、1=退職)です。緑の曲線はモデルの予測確率です。残業時間が増えるにつれて退職確率の予測値は上昇しますが、0を下回ったり1を超えたりすることはありません。これがロジットリンクの働きで、入力が極端でも線形予測子を有効な確率範囲へ押し縮めます。
Rに組み込まれたglm()関数も同じ考え方ですが、文法が異なります。family引数で分布とリンク関数を設定し、モデルはRのフォーミュラ記法で定義します。
Rでの同じロジスティック回帰は次の通りです。
# Read the dataset
df <- read.csv("data.csv")
# Fit logistic regression
logit_model <- glm(left ~ salary + experience_years + overtime_hours,
data = df,
family = binomial(link = "logit"))
summary(logit_model)
RでのGLMロジスティック回帰
フォーミュラleft ~ salary + experience_years + overtime_hoursは、予測対象と使用する入力をRに伝えます。family = binomial(link = "logit")が分布とリンクを設定します。ロジットは二項族の既定リンクなので、family = binomial()と省略しても構いません。
ポアソン回帰もほぼ同様です。
poisson_model <- glm(sick_days ~ salary + experience_years + overtime_hours,
data = df,
family = poisson(link = "log"))
summary(poisson_model)
RでのGLMポアソン回帰
ここでもbinomial()をpoisson()に、応答変数を適切なものに変えれば完了です。
両言語とも同じアプローチで、分布とその既定リンクを組み合わせたファミリー(族)引数を渡します。

PythonとRでの分布とリンクの指定
各ファミリーには既定のリンクがありますが、上書きも可能です。Pythonではリンクオブジェクトを渡します:sm.families.Binomial(link=sm.families.links.Probit())。Rではリンク引数を変更します:family = binomial(link = "probit")。
多くの用途では、既定のリンクが適切です。
GLMの係数は、モデルの種類によって意味が同じではありません。リンク関数が解釈の仕方を変えます。
線形回帰の解釈は容易です。experience_yearsの係数が500なら、経験年数が1年増えるごとに予測給与が500増えることを意味します。恒等リンクにより、係数は結果へ直接対応します。
ロジスティック回帰は異なります。ロジットリンクにより係数は対数オッズの空間にあります。overtime_hoursの係数が0.12だからといって、退職確率が0.12上がるわけではありません。残業時間が1時間増えるごとに、退職の対数オッズが0.12増えるという意味です。より解釈しやすくするには、係数を指数化します:e^0.12 ≈ 1.127。これはオッズ比で、残業1時間あたり退職のオッズが約1.13倍になることを示します。
ポアソン回帰の係数は対数リンクを通じて解釈します。overtime_hoursの係数が0.02なら、1時間増えるごとに期待カウントの対数が0.02増えることを意味します。指数化するとe^0.02 ≈ 1.02で、残業1時間あたり期待される病欠日数が約1.02倍になるとわかります。
基本は、係数の空間から結果の空間へ戻るために、常にリンク関数の逆関数を適用することです。
適切なGLMの選択は、ひとえに「結果変数がどのような形か」にかかっています。
結果が二値(はい/いいえ、0/1、合格/不合格)ならロジスティック回帰です。二項分布、ロジットリンク。解約予測、不正検知、疾患の有無の分類、治療反応の有無といった分類タスクに当てはまります。
結果がカウント(時間枠内のイベント数)ならポアソン回帰です。ポアソン分布、対数リンク。時間当たりのサイト訪問数、年当たりの保険金請求数などに適します。
結果が連続で大まかに正規的(売上、テストスコアなど)なら、標準的な線形回帰で問題ありません。正規分布、恒等リンク。これはすでに馴染みのあるGLMです。
常に結果変数から出発し、それに合う分布を選べば、リンク関数は自ずと決まります。
GLMを扱う際に避けたい、よくある誤りを挙げます。
これが最も一般的です。結果がカウントなのに線形回帰を当てると、負の予測が出ます。二値なのにポアソンを使えば、モデルは意味を成しません。まず結果変数を確認し、それに合った分布を選んでください。
リンク関数は、入力と出力の関係を変換します。ロジスティック回帰の係数0.5は「確率が0.5上がる」ことを意味しません。対数オッズが0.5上がるという意味です。この変換を忘れると、効果量や変数重要度について誤った結論に至ります。
ポアソン回帰の係数は、数値が似ていてもロジスティック回帰の係数と比較できません。0.3という係数の意味は、それが対数リンクを通るのかロジットリンクを通るのかで異なります。常に使用中の特定モデルの文脈で係数を解釈してください。
GLMは線形回帰より柔軟ですが、依然として仮定があります。ポアソン回帰は平均と分散が等しいと仮定します。カウントデータの分散が平均より大きすぎると、標準誤差が過小評価され、p値が誤解を招きます。ロジスティック回帰は観測の独立性を仮定します。
これに対処するには、GLMを当てはめた後に常に残差を確認し、不適合を示唆するパターンがないかを調べてください。
GLMは、線形回帰の基本的なロジックを保ちながら、その先へ進むための体系的な方法を提供します。入力の線形結合という考えはそのままに、扱うデータに合わせて分布とリンク関数を変えます。
GLMの背後には3つの構成要素があります。適切な分布を選び、線形予測子を設定し、正しいリンク関数を適用する方法を理解すれば、同じ思考枠組みで二値・カウント・連続データを扱えます。
次にやるべき最良の一歩は実践です。非正規の結果を持つデータセットを選び、PythonまたはRでGLMを当てはめ、リンク関数を通じて係数を解釈する練習をしてください。関心のあるデータを使えば、ここで扱った理論は短時間で腹落ちするはずです。
線形回帰とGLMのその先へ進みたい場合は、Machine Learning Scientist in Pythonトラックに登録してください。2026年に即戦力となるために必要なすべてを学べます。
DataCampで学ぶ
Courses
Courses
Courses