course
Algebra liniowa dla data science w R
4 godz.
21.2K
Regresja liniowa to świetny pierwszy model, ale zawodzi w momencie, gdy twoje dane nie mają rozkładu normalnego.
Załóżmy, że próbujesz przewidzieć, czy klient odejdzie (wynik tak/nie). Regresja liniowa nie potrafi tego zrobić. Przewiduje wartości ciągłe, więc otrzymasz wyjścia jak -0,3 lub 1,7 dla czegoś, co może być tylko 0 lub 1. Ten sam problem pojawia się przy danych zliczeń, jak liczba zgłoszeń do supportu na godzinę. Regresja liniowa może przewidywać ujemne zliczenia, co nie ma sensu.
Uogólnione modele liniowe (GLM) rozwiązują to, rozszerzając regresję liniową tak, by obsługiwała różne typy wyników. Rdzeń pozostaje ten sam – liniowa kombinacja wejść – ale z elastycznością modelowania danych binarnych i innych rozkładów nienormalnych.
W tym artykule wyjaśnię, czym są GLM-y, omówię ich trzy kluczowe komponenty i pokażę, jak je dopasować i interpretować w Pythonie i R.
Ale jak dokładnie działa regresja liniowa? Przeczytaj nasz przewodnik po prostej regresji liniowej, aby poznać jej założenia i diagnostykę oraz nauczyć się interpretować wyniki.
Uogólniony model liniowy (GLM) to rozszerzenie regresji liniowej, które pozwala zmiennej zależnej podążać za różnymi rozkładami prawdopodobieństwa, nie tylko rozkładem normalnym.
Kluczowe jest to, że GLM nie jest pojedynczym modelem. To ramy. Regresja liniowa, regresja logistyczna i regresja Poissona to wszystko GLM-y. Każda używa innego rozkładu i innego sposobu łączenia wejść z wyjściem, ale wszystkie mają tę samą strukturę.
Standardowa regresja liniowa zakłada dwie rzeczy: twój wynik ma rozkład normalny, a wariancja pozostaje stała w całym zakresie predykcji. Jeśli te założenia nie są spełnione, otrzymasz wyniki, które nie mają sensu.
Na przykład, jeśli budujesz model przewidujący, czy wnioskodawca kredytu nie spłaci zobowiązań, wynik jest binarny – 0 lub 1. Regresja liniowa nie respektuje tej granicy. Może przewidzieć -0,2 lub 1,4, co jest niemożliwe.
Dane zliczeń mają ten sam problem. Jeśli przewidujesz liczbę ponownych przyjęć do szpitala w miesiącu, regresja liniowa może zwrócić liczby ujemne. Nie możesz mieć -3 rehospitalizacji.
Problemem w obu przypadkach nie jest liniowa kombinacja wejść – ta część działa dobrze. Problemem jest to, jak model mapuje te wejścia na wyjście. GLM-y rozwiązują to, dodając funkcję łączącą (link), która transformuje wyjście tak, by mieściło się w naturalnym zakresie danych. Prawdopodobieństwa pozostają między 0 a 1. Zliczenia pozostają nieujemne. Za chwilę zobaczysz, o co chodzi.
Każdy GLM składa się z trzech części: rozkładu, predyktora liniowego i funkcji łączącej. Przejdę przez każdą z nich.
Komponent losowy definiuje, jaki rodzaj danych generuje twoja zmienna zależna. Innymi słowy, wybiera rozkład prawdopodobieństwa, który najlepiej opisuje twój wynik.
Regresja liniowa zakłada rozkład normalny, więc wynik jest ciągły i symetryczny wokół średniej. Ale nie wszystkie dane tak działają.
Jeśli twój wynik jest binarny (tak/nie, 0/1), użyjesz rozkładu dwumianowego. Jeśli modelujesz dane zliczeń – jak liczba błędów na dzień – lepiej pasuje rozkład Poissona.
Wybór rozkładu kontroluje całą resztę modelu.
Komponent systematyczny to część, którą już znasz z regresji liniowej. To liniowa kombinacja twoich zmiennych wejściowych:
Komponent systematyczny
Gdzie X to macierz cech wejściowych, a β to wektor współczynników. Mnożysz każdą cechę przez jej wagę i sumujesz.
Ta część nie zmienia się między różnymi GLM-ami. Innymi słowy, niezależnie od tego, czy dopasowujesz regresję logistyczną, czy Poissona, predyktor liniowy wygląda tak samo.
Funkcja łącząca łączy predyktor liniowy z wartością oczekiwaną zmiennej zależnej. To element, który nadaje GLM-om elastyczność.
Bez funkcji łączącej predyktor liniowy zwraca wartości od minus nieskończoności do plus nieskończoności. To w porządku dla wyników ciągłych, ale nie dla prawdopodobieństw czy zliczeń. Funkcja łącząca transformuje wyjście tak, by mieściło się we właściwym zakresie dla wybranego rozkładu.
Na przykład regresja logistyczna używa linku logit, który odwzorowuje predyktor liniowy mogący przyjmować dowolną liczbę rzeczywistą na prawdopodobieństwo między 0 a 1. Regresja Poissona używa linku log, który zapewnia, że predykcje są zawsze dodatnie.
Pełne równanie GLM łączy wszystkie trzy komponenty:
Równanie GLM
Gdzie g() to funkcja łącząca, a μ to wartość oczekiwana odpowiedzi. Rozkład definiuje, czym jest μ, predyktor liniowy oblicza Xβ, a funkcja łącząca spina oba elementy.
Funkcja łącząca określa, jak predyktor liniowy przekłada się na twój wynik. Różne typy danych wymagają różnych transformacji, a każdy typ GLM ma domyślną funkcję łączącą sparowaną z jego rozkładem.
Link tożsamościowy jest najprostszy – nie robi nic. Predyktor liniowy równa się wartości oczekiwanej odpowiedzi:
Link tożsamościowy
Tego używa regresja liniowa. Twoje wejścia łączą się w ważoną sumę i ta suma jest predykcją. Nie potrzeba transformacji, bo wynik może przyjmować dowolną wartość ciągłą.
Link logit bierze prawdopodobieństwo (między 0 a 1) i odwzorowuje je na całą prostą rzeczywistą:
Link logit
Tego używa regresja logistyczna. Predyktor liniowy może przyjąć dowolną wartość od minus do plus nieskończoności, ale po transformacji odwrotnej predykcja zawsze mieści się między 0 a 1. Ten iloraz wewnątrz logarytmu – μ/(1-μ) – to szanse (odds), a logarytm szans to log-szanse (log-odds). Więc interpretując współczynniki regresji logistycznej, pracujesz w przestrzeni log-szans.
Link logarytmiczny przyjmuje logarytm naturalny wartości oczekiwanej:
Link log
Tego używa regresja Poissona. Predyktor liniowy może być dowolną liczbą rzeczywistą, ale po jego wyeksponentowaniu (transformacja odwrotna) predykcja jest zawsze dodatnia. To dokładnie to, czego potrzebujesz dla danych zliczeń, bo nie możesz mieć ujemnych zdarzeń.
GLM-y mogą wydawać się abstrakcyjne, dopóki nie zobaczysz ich jako modeli, które już znasz. Regresja liniowa, logistyczna i Poissona to wszystko GLM-y. Jedyna różnica polega na tym, że każda używa innej kombinacji rozkładu i funkcji łączącej.
Regresja liniowa to najprostszy GLM. Odpowiedź ma rozkład normalny, a funkcja łącząca to link tożsamościowy, czyli brak transformacji.
Regresja liniowa jako GLM
Predyktor liniowy równa się bezpośrednio oczekiwanemu wynikowi. To GLM, którego używałeś od dawna – tylko nie nazywając go tak.
Regresja logistyczna modeluje wyniki binarne, używając rozkładu dwumianowego i linku logit.
Regresja logistyczna jako GLM
Lewa strona to log-szanse zdarzenia. Prawa strona to standardowa liniowa kombinacja wejść. Link logit sprawia, że predykcje mapują się na prawdopodobieństwa między 0 a 1, niezależnie od tego, jak duże lub małe stanie się Xβ.
Regresja Poissona modeluje dane zliczeń, używając rozkładu Poissona i linku log.
Regresja Poissona jako GLM
Logarytm oczekiwanej liczby równa się predyktorowi liniowemu. Jeśli wyeksponentujesz obie strony, otrzymasz μ = e^(Xβ), co jest zawsze dodatnie – dokładnie tak, jak wymagają tego zliczenia.
GLM-y nie używają zwykłej metody najmniejszych kwadratów jak regresja liniowa. Zamiast tego opierają się na estymacji największej wiarygodności (MLE).
Idea jest prosta. MLE znajduje taki zestaw współczynników, który sprawia, że twoje zaobserwowane dane są najbardziej prawdopodobne przy wybranym rozkładzie. Dla regresji logistycznej znajduje współczynniki, które czynią zaobserwowane 0 i 1 najbardziej prawdopodobnymi przy modelu dwumianowym. Dla regresji Poissona – współczynniki, które najlepiej wyjaśniają zaobserwowane zliczenia.
Dla większości GLM-ów nie ma rozwiązania w postaci zamkniętej, więc optymalizacja jest iteracyjna. Algorytm zaczyna od wstępnego oszacowania współczynników, ocenia dopasowanie do danych, koryguje je i powtarza, aż estymaty się zbiegną.
Najczęstszą metodą jest iteracyjnie ważone najmniejsze kwadraty (IRLS), które przekształcają problem MLE w sekwencję ważonych regresji liniowych. Działają też metody gradientowe, które wyznaczają kierunek najszybszej poprawy i podążają w jego stronę. Biblioteki takie jak statsmodels i glm() w R robią to wszystko pod spodem, więc nie musisz samodzielnie implementować solvera.
Zapamiętaj, że to ty wybierasz rozkład i funkcję łączącą, a optymalizator znajduje najlepsze współczynniki. To idea – teraz pokażę, jak działa w praktyce.
W tej sekcji przejdę przez regresję logistyczną i Poissona w Pythonie i R, używając tego samego zbioru danych – symulowanego zbioru odejść pracowników z kolumnami: pensja, lata doświadczenia, godziny nadliczbowe, czy pracownik odszedł (binarne) oraz liczba dni chorobowych (zliczenia).
Utworzę wspomniany zbiór danych w Pythonie, a następnie użyję go do obliczeń w Pythonie i R:
import numpy as np
import pandas as pd
np.random.seed(42)
n = 500
# Employee dataset
df = pd.DataFrame({
"salary": np.random.normal(55000, 12000, n).astype(int),
"experience_years": np.random.poisson(5, n),
"overtime_hours": np.random.poisson(8, n),
})
# Simulate binary outcome: left the company
prob_left = 1 / (1 + np.exp(-(
-2 + -0.00003 * df["salary"] + -0.05 * df["experience_years"] + 0.12 * df["overtime_hours"]
)))
df["left"] = np.random.binomial(1, prob_left)
# Simulate count outcome: sick days per year
df["sick_days"] = np.random.poisson(
np.exp(1.2 + 0.00001 * df["salary"] + 0.02 * df["overtime_hours"])
)
# Save to use later in R
df.to_csv("data.csv", index=False)
df.head()
Przykładowy zbiór danych o odejściach pracowników
Python daje ci dwie główne opcje dla GLM-ów: statsmodels i scikit-learn. Tutaj użyję statsmodels, bo daje pełne podsumowanie statystyczne, w tym współczynniki, wartości p i przedziały ufności. Będziesz ich potrzebować, interpretując GLM.
Tak możesz dopasować regresję logistyczną do przewidywania, czy pracownik odszedł:
import statsmodels.api as sm
X = sm.add_constant(df[["salary", "experience_years", "overtime_hours"]])
logit_model = sm.GLM(df["left"], X, family=sm.families.Binomial())
logit_results = logit_model.fit()
print(logit_results.summary())
Wyniki regresji logistycznej GLM
Kluczowy wiersz to sm.families.Binomial(). Ustala on jednocześnie rozkład (dwumianowy) i domyślną funkcję łączącą (logit). Nie musisz osobno podawać funkcji łączącej, chyba że chcesz inną niż domyślna.
Teraz dopasujmy regresję Poissona do przewidywania dni chorobowych:
poisson_model = sm.GLM(df["sick_days"], X, family=sm.families.Poisson())
poisson_results = poisson_model.fit()
print(poisson_results.summary())
Wyniki regresji Poissona GLM
Wystarczy zamienić Binomial() na Poisson() i model używa rozkładu Poissona z linkiem log. Tabela wyników wygląda tak samo, ale interpretacja się zmienia, bo zmieniła się funkcja łącząca.
Zobrazujmy teraz przewidywane prawdopodobieństwa z regresji logistycznej względem godzin nadliczbowych:
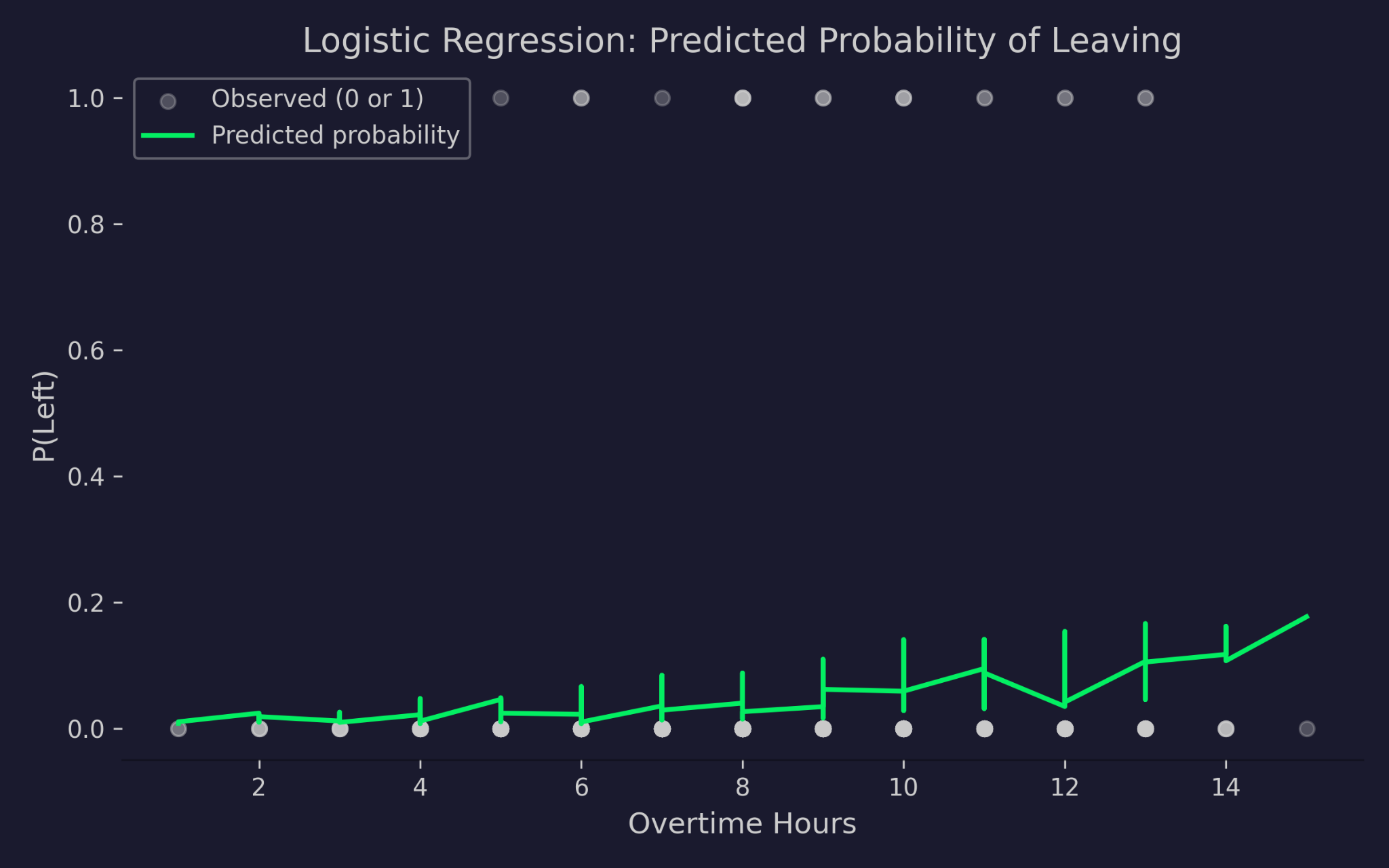
Przewidywane prawdopodobieństwa odejścia a godziny nadliczbowe
Wykres pokazuje godziny nadliczbowe na osi X i prawdopodobieństwo odejścia na osi Y. Szare kropki to rzeczywiste wyniki – 0 (został) lub 1 (odszedł). Zielona krzywa to przewidywane prawdopodobieństwo modelu. Wraz ze wzrostem godzin nadliczbowych przewidywane prawdopodobieństwo odejścia rośnie, ale nigdy nie spada poniżej 0 ani nie przekracza 1. To zasługa linku logit – ściska predyktor liniowy do prawidłowego zakresu prawdopodobieństw, niezależnie od ekstremalnych wartości wejść.
Wbudowana funkcja R glm() działa tak samo, ale ze zmienioną składnią. Argument family ustawia rozkład i funkcję łączącą, a model definiujesz z użyciem interfejsu formuł R.
Oto ta sama regresja logistyczna w R:
# Read the dataset
df <- read.csv("data.csv")
# Fit logistic regression
logit_model <- glm(left ~ salary + experience_years + overtime_hours,
data = df,
family = binomial(link = "logit"))
summary(logit_model)
Regresja logistyczna GLM w R
Formuła left ~ salary + experience_years + overtime_hours mówi R, co przewidywać i jakich wejść użyć. Część family = binomial(link = "logit") ustawia rozkład i link. Możesz to skrócić do family = binomial(), ponieważ logit jest domyślnym linkiem dla rodziny dwumianowej.
Regresja Poissona wygląda niemal tak samo:
poisson_model <- glm(sick_days ~ salary + experience_years + overtime_hours,
data = df,
family = poisson(link = "log"))
summary(poisson_model)
Regresja Poissona GLM w R
Wystarczy zmienić binomial() na poisson(), podmienić zmienną zależną i gotowe.
Oba języki używają tego samego podejścia – przekazujesz argument rodziny/rozkładu, który łączy rozkład i jego domyślną funkcję łączącą:

Określanie rozkładu i linku w Pythonie i R
Każda rodzina ma domyślny link, ale możesz go nadpisać. W Pythonie możesz przekazać obiekt linku: sm.families.Binomial(link=sm.families.links.Probit()). W R po prostu zmień argument link: family = binomial(link = "probit").
W większości przypadków domyślny link jest właściwym wyborem.
Współczynniki GLM nie znaczą tego samego w różnych typach modeli. Funkcja łącząca zmienia sposób ich interpretacji.
W regresji liniowej interpretacja jest prosta. Współczynnik 500 przy experience_years oznacza, że każdy dodatkowy rok doświadczenia dodaje 500 do przewidywanej pensji. Link tożsamościowy oznacza, że współczynniki mapują się bezpośrednio na wynik.
Regresja logistyczna jest inna. Link logit oznacza, że współczynniki są w przestrzeni log-szans. Współczynnik 0,12 przy overtime_hours nie oznacza, że prawdopodobieństwo odejścia rośnie o 0,12. Oznacza, że log-szanse odejścia rosną o 0,12 na każdą dodatkową godzinę nadliczbową. Aby uzyskać coś bardziej interpretowalnego, wyeksponentuj współczynnik: e^0.12 ≈ 1.127. Daje to iloraz szans. Każda dodatkowa godzina nadliczbowa mnoży szanse odejścia mniej więcej przez 1,13.
Współczynniki regresji Poissona działają przez link log. Współczynnik 0,02 przy overtime_hours oznacza, że każda dodatkowa godzina zwiększa logarytm oczekiwanej liczby o 0,02. Po wyeksponentowaniu: e^0.02 ≈ 1.02, zobaczysz, że każda dodatkowa godzina nadliczbowa mnoży oczekiwaną liczbę dni chorobowych około 1,02 raza.
Zasadą jest zawsze zastosować odwrotność funkcji łączącej, aby przejść ze „świata współczynników” z powrotem do przestrzeni wyników.
Wybór właściwego GLM sprowadza się do jednego pytania: jak wygląda twoja zmienna wynikowa?
Jeśli twój wynik jest binarny (tak/nie, 0/1, zdał/nie zdał), użyj regresji logistycznej. Rozkład dwumianowy, link logit. To obejmuje zadania klasyfikacyjne, jak przewidywanie churnu, wykrywanie nadużyć, klasyfikacja chorób (ma lub nie ma) czy to, czy pacjent zareaguje na leczenie.
Jeśli twój wynik to zliczenie (liczba zdarzeń w oknie czasowym), użyj regresji Poissona. Rozkład Poissona, link log. To pasuje do problemów takich jak przewidywanie liczby wizyt na stronie na godzinę czy liczby zgłoszeń ubezpieczeniowych w roku.
Jeśli twój wynik jest ciągły i w przybliżeniu normalny (przychody, wyniki testów), standardowa regresja liniowa sprawdzi się dobrze. Rozkład normalny, link tożsamościowy. To GLM, który już znasz.
Zawsze zacznij od zmiennej wynikowej, dopasuj do niej rozkład, a funkcja łącząca wyniknie z tego wyboru.
Oto kilka typowych błędów, których warto unikać, pracując z GLM-ami.
To najczęstszy błąd. Jeśli twój wynik to zliczenia, a dopasujesz regresję liniową, otrzymasz ujemne predykcje. Jeśli jest binarny, a użyjesz Poissona, model nie będzie miał sensu. Zawsze najpierw spójrz na zmienną wynikową i wybierz pasujący do niej rozkład.
Funkcja łącząca transformuje relację między wejściami a wyjściem. Współczynnik 0,5 w regresji logistycznej nie znaczy „prawdopodobieństwo rośnie o 0,5”. Oznacza, że log-szanse rosną o 0,5. Zapominanie o tej transformacji prowadzi do błędnych wniosków o wielkości efektów i ważności zmiennych.
Współczynniki w regresji Poissona nie są porównywalne ze współczynnikami w regresji logistycznej, nawet jeśli liczby wyglądają podobnie. Współczynnik 0,3 znaczy co innego zależnie od tego, czy przechodzi przez link log, czy link logit. Zawsze interpretuj współczynniki w kontekście konkretnego używanego modelu.
GLM-y są bardziej elastyczne niż regresja liniowa, ale nadal mają założenia. Regresja Poissona zakłada równość średniej i wariancji – jeśli twoje zliczenia mają znacznie większą wariancję niż średnia, błędy standardowe modelu będą zbyt małe, a wartości p – mylące. Regresja logistyczna zakłada niezależność obserwacji.
Aby temu zaradzić, po dopasowaniu dowolnego GLM sprawdź reszty i poszukaj wzorców sugerujących złe dopasowanie.
GLM-y dają ci uporządkowany sposób na wyjście poza regresję liniową, ale z zachowaniem jej fundamentalnej logiki. Idea liniowej kombinacji wejść pozostaje ta sama, ale rozkład i funkcja łącząca zmieniają się tak, by pasować do danych, z którymi pracujesz.
Za GLM-ami stoją trzy komponenty. Gdy wiesz, jak dobrać właściwy rozkład, ustawić predyktor liniowy i zastosować odpowiedni link, możesz ogarnąć wyniki binarne, zliczenia i dane ciągłe tym samym sposobem myślenia.
Najlepszy kolejny krok to spróbować. Wybierz zbiór danych z nienormalnym wynikiem, dopasuj GLM w Pythonie lub R i poćwicz interpretację współczynników przez pryzmat funkcji łączącej. Użyj zbioru, na którym ci zależy, a cała teoria kliknie w kilka minut.
Jeśli chcesz wyjść poza regresję liniową i GLM-y, zapisz się na naszą ścieżkę Machine Learning Scientist in Python. Pokaże ci wszystko, czego potrzebujesz, by być gotowym do pracy w 2026 roku.
Ucz się z DataCamp
course
course
course