
Kursus
Aljabar Linear untuk Data Science di R
4 Hr
21.2K
Regresi linear adalah model awal yang bagus untuk dicoba, tetapi langsung kewalahan ketika data Anda tidak mengikuti distribusi normal.
Misalnya, Anda ingin memprediksi apakah seorang pelanggan akan churn (hasil ya atau tidak). Regresi linear tidak tahu cara melakukannya. Ia memprediksi nilai kontinu, sehingga Anda akan mendapatkan keluaran seperti -0,3 atau 1,7 untuk sesuatu yang seharusnya hanya 0 atau 1. Masalah yang sama muncul pada data hitung, seperti jumlah tiket dukungan per jam. Regresi linear bisa memprediksi hitungan negatif, yang jelas tidak masuk akal.
Generalized linear models (GLM) mengatasi hal ini dengan memperluas regresi linear agar dapat menangani berbagai jenis keluaran. Gagasannya tetap sama — kombinasi linear dari masukan — namun dengan fleksibilitas untuk memodelkan data biner dan distribusi non-normal lainnya.
Dalam artikel ini, saya akan menguraikan apa itu GLM, membahas tiga komponennya, dan menunjukkan cara memfitting serta menafsirkan modelnya di Python dan R.
Namun bagaimana tepatnya regresi linear bekerja? Baca panduan kami tentang Regresi Linear Sederhana untuk mempelajari asumsi, diagnostik, dan cara menafsirkan hasilnya.
Generalized linear model (GLM) adalah perluasan regresi linear yang memungkinkan variabel respons mengikuti berbagai distribusi probabilitas, bukan hanya distribusi normal.
Hal penting yang perlu diingat adalah GLM bukan satu model tunggal. Ini adalah sebuah kerangka kerja. Regresi linear, regresi logistik, dan regresi Poisson semuanya adalah GLM. Masing-masing menggunakan distribusi dan cara pengaitan masukan ke keluaran yang berbeda, tetapi strukturnya sama.
Regresi linear standar membuat dua asumsi besar: keluaran Anda berdistribusi normal, dan varian tetap konstan di seluruh prediksi. Jika asumsi ini tidak terpenuhi, Anda akan mendapatkan hasil yang tidak masuk akal.
Sebagai contoh, jika Anda membangun model untuk memprediksi apakah pemohon pinjaman akan gagal bayar, keluarannya biner — 0 atau 1. Regresi linear tidak menghormati batas itu. Ia bisa memprediksi -0,2 atau 1,4, yang keduanya mustahil.
Data hitung juga mengalami masalah yang sama. Jika Anda memprediksi jumlah rawat inap ulang per bulan, regresi linear bisa menghasilkan angka negatif. Anda tidak mungkin memiliki -3 rawat inap ulang.
Masalah dalam kedua kasus bukan pada kombinasi linear dari masukan — bagian itu baik-baik saja. Masalahnya ada pada cara model memetakan masukan ke keluaran. GLM menyelesaikannya dengan menambahkan fungsi taut yang mentransformasikan keluaran agar sesuai dengan rentang alami data. Probabilitas tetap di antara 0 dan 1. Hitungan tetap tidak negatif. Anda akan melihat semuanya sebentar lagi.
Setiap GLM dibangun dari tiga bagian: distribusi, prediktor linear, dan fungsi taut. Mari saya jelaskan satu per satu.
Komponen acak menentukan jenis data yang dihasilkan oleh variabel respons Anda. Dengan kata lain, ia memilih distribusi probabilitas yang paling menggambarkan keluaran Anda.
Regresi linear mengasumsikan distribusi normal, sehingga keluarannya kontinu dan simetris terhadap mean. Namun tidak semua data bekerja seperti itu.
Jika keluaran Anda biner (ya/tidak, 0/1), Anda akan menggunakan distribusi binomial. Jika Anda memodelkan data hitung — seperti jumlah kesalahan per hari — distribusi Poisson lebih sesuai.
Distribusi yang Anda pilih mengendalikan semua hal lain dalam model.
Komponen sistematis adalah bagian yang sudah Anda kenal dari regresi linear. Ini adalah kombinasi linear dari variabel masukan Anda:
Komponen sistematis
Di mana X adalah matriks fitur masukan Anda dan β adalah vektor koefisien. Anda mengalikan setiap fitur dengan bobotnya lalu menjumlahkannya.
Bagian ini tidak berubah di berbagai GLM. Dengan kata lain, apakah Anda memfitting regresi logistik atau regresi Poisson, prediktor linear terlihat sama.
Fungsi taut menghubungkan prediktor linear dengan nilai harapan variabel respons. Inilah bagian yang membuat GLM fleksibel.
Tanpa fungsi taut, prediktor linear menghasilkan nilai dari minus tak terhingga hingga plus tak terhingga. Itu baik untuk keluaran kontinu, tetapi tidak untuk probabilitas atau hitungan. Fungsi taut mentransformasikan keluaran agar berada dalam rentang yang tepat untuk distribusi yang dipilih.
Sebagai contoh, regresi logistik menggunakan taut logit, yang memetakan prediktor linear yang bisa berupa bilangan real apa pun menjadi probabilitas antara 0 dan 1. Regresi Poisson menggunakan taut log, yang memastikan prediksi selalu positif.
Persamaan GLM lengkap menggabungkan ketiga komponen tersebut:
Persamaan GLM
Di mana g() adalah fungsi taut dan μ adalah nilai harapan dari respons. Distribusi mendefinisikan apa arti μ, prediktor linear menghitung Xβ, dan fungsi taut menjembatani keduanya.
Fungsi taut menentukan bagaimana prediktor linear diubah menjadi keluaran Anda. Berbagai tipe data memerlukan transformasi yang berbeda, dan setiap jenis GLM memiliki fungsi taut bawaan yang dipasangkan dengan distribusinya.
Taut identitas adalah yang paling sederhana — tidak melakukan apa-apa. Prediktor linear sama dengan nilai harapan dari respons:
Taut identitas
Inilah yang digunakan regresi linear. Masukan Anda digabungkan menjadi jumlah berbobot, dan jumlah tersebut adalah prediksi. Tidak diperlukan transformasi karena keluarannya bisa berupa nilai kontinu apa pun.
Taut logit mengambil probabilitas (antara 0 dan 1) dan memetakannya ke seluruh garis bilangan real:
Taut logit
Inilah yang digunakan regresi logistik. Prediktor linear dapat menghasilkan nilai apa pun dari minus hingga plus tak terhingga, tetapi setelah transformasi balik, prediksi selalu berada antara 0 dan 1. Rasio di dalam logaritma — μ/(1-μ) — disebut odds, dan logaritma dari odds adalah log-odds. Jadi saat Anda menafsirkan koefisien regresi logistik, Anda bekerja dalam ruang log-odds.
Taut log mengambil logaritma natural dari nilai harapan:
Taut log
Inilah yang digunakan regresi Poisson. Prediktor linear bisa berupa bilangan real apa pun, tetapi setelah dieksponensialkan kembali (transformasi balik), prediksi selalu positif. Itulah yang dibutuhkan data hitung karena Anda tidak bisa memiliki kejadian negatif.
GLM bisa terasa abstrak sampai Anda melihatnya sebagai model yang sudah Anda kenal. Regresi linear, regresi logistik, dan regresi Poisson semuanya adalah GLM. Perbedaannya hanya pada kombinasi distribusi dan fungsi taut yang digunakan.
Regresi linear adalah GLM yang paling sederhana. Respons mengikuti distribusi normal, dan fungsi tautnya adalah taut identitas, artinya tanpa transformasi sama sekali.
Regresi linear sebagai GLM
Prediktor linear sama persis dengan nilai harapan keluaran. Ini adalah GLM yang selama ini Anda gunakan, hanya saja tidak menyebutnya demikian.
Regresi logistik memodelkan keluaran biner dengan menggunakan distribusi binomial dan taut logit.
Regresi logistik sebagai GLM
Sisi kiri adalah log-odds dari kejadian. Sisi kanan adalah kombinasi linear standar dari masukan. Taut logit memastikan prediksi dipetakan menjadi probabilitas antara 0 dan 1, tidak peduli seberapa besar atau kecil Xβ nilainya.
Regresi Poisson memodelkan data hitung dengan menggunakan distribusi Poisson dan taut log.
Regresi Poisson sebagai GLM
Log dari nilai harapan hitungan sama dengan prediktor linear. Jika Anda mengeksponeksialkan kedua sisi, Anda mendapatkan μ = e^(Xβ), yang selalu positif — tepat seperti yang dibutuhkan data hitung.
GLM tidak menggunakan kuadrat terkecil biasa seperti regresi linear. Sebagai gantinya, GLM mengandalkan pendugaan kemungkinan maksimum (maximum likelihood estimation/MLE).
Idenya mudah. MLE mencari sekumpulan koefisien yang membuat data yang Anda amati paling mungkin terjadi di bawah distribusi yang dipilih. Untuk regresi logistik, MLE mencari koefisien yang membuat 0 dan 1 yang diamati paling mungkin terjadi dalam model binomial. Untuk regresi Poisson, ia mencari koefisien yang paling baik menjelaskan hitungan yang diamati.
Tidak ada solusi bentuk tertutup untuk sebagian besar GLM, jadi optimisasinya bersifat iteratif. Algoritme dimulai dengan tebakan awal koefisien, mengevaluasi seberapa baik kecocokannya terhadap data, menyesuaikannya, dan mengulang sampai estimasinya konvergen.
Metode yang paling umum adalah iteratively reweighted least squares (IRLS), yang mengubah masalah MLE menjadi rangkaian regresi linear berbobot. Metode berbasis gradien juga berfungsi, karena metode tersebut menghitung arah perbaikan tercepat dan melangkah ke arahnya. Pustaka seperti statsmodels dan glm() di R menangani semua ini di balik layar, jadi Anda tidak perlu mengimplementasikan solusinya sendiri.
Intinya adalah Anda memilih distribusi dan fungsi taut, lalu pengoptimal menemukan koefisien terbaik. Itu konsepnya — sekarang mari saya tunjukkan cara kerjanya dalam praktik.
Di bagian ini, saya akan membahas regresi logistik dan regresi Poisson di Python dan R menggunakan dataset yang sama — dataset attrition karyawan tersimulasi dengan kolom gaji, tahun pengalaman, jam lembur, apakah karyawan keluar (biner), dan jumlah hari sakit yang diambil (hitung).
Saya akan membuat dataset tersebut di Python, lalu menggunakannya untuk perhitungan di Python dan R:
import numpy as np
import pandas as pd
np.random.seed(42)
n = 500
# Employee dataset
df = pd.DataFrame({
"salary": np.random.normal(55000, 12000, n).astype(int),
"experience_years": np.random.poisson(5, n),
"overtime_hours": np.random.poisson(8, n),
})
# Simulate binary outcome: left the company
prob_left = 1 / (1 + np.exp(-(
-2 + -0.00003 * df["salary"] + -0.05 * df["experience_years"] + 0.12 * df["overtime_hours"]
)))
df["left"] = np.random.binomial(1, prob_left)
# Simulate count outcome: sick days per year
df["sick_days"] = np.random.poisson(
np.exp(1.2 + 0.00001 * df["salary"] + 0.02 * df["overtime_hours"])
)
# Save to use later in R
df.to_csv("data.csv", index=False)
df.head()
Contoh dataset attrition karyawan
Python memberi Anda dua opsi utama untuk GLM: statsmodels dan scikit-learn. Di sini saya akan menggunakan statsmodels karena pustaka ini memberikan ringkasan statistik lengkap, termasuk koefisien, nilai p, dan interval kepercayaan. Anda akan memerlukannya saat menafsirkan GLM.
Berikut cara memfitting regresi logistik untuk memprediksi apakah seorang karyawan keluar:
import statsmodels.api as sm
X = sm.add_constant(df[["salary", "experience_years", "overtime_hours"]])
logit_model = sm.GLM(df["left"], X, family=sm.families.Binomial())
logit_results = logit_model.fit()
print(logit_results.summary())
Hasil regresi logistik GLM
Baris kunci adalah sm.families.Binomial(). Ini menetapkan sekaligus distribusi (binomial) dan fungsi taut bawaan (logit) dalam satu argumen. Anda tidak perlu menentukan taut secara terpisah kecuali ingin menggunakan yang non-bawaan.
Sekarang mari memfitting regresi Poisson pada dataset yang sama untuk memprediksi hari sakit:
poisson_model = sm.GLM(df["sick_days"], X, family=sm.families.Poisson())
poisson_results = poisson_model.fit()
print(poisson_results.summary())
Hasil regresi Poisson GLM
Anda hanya perlu menukar Binomial() menjadi Poisson() dan model akan menggunakan distribusi Poisson dengan taut log. Tabel keluarannya terlihat sama, tetapi penafsirannya berubah karena fungsi tautnya berbeda.
Sekarang mari memvisualisasikan probabilitas prediksi dari regresi logistik terhadap jam lembur:
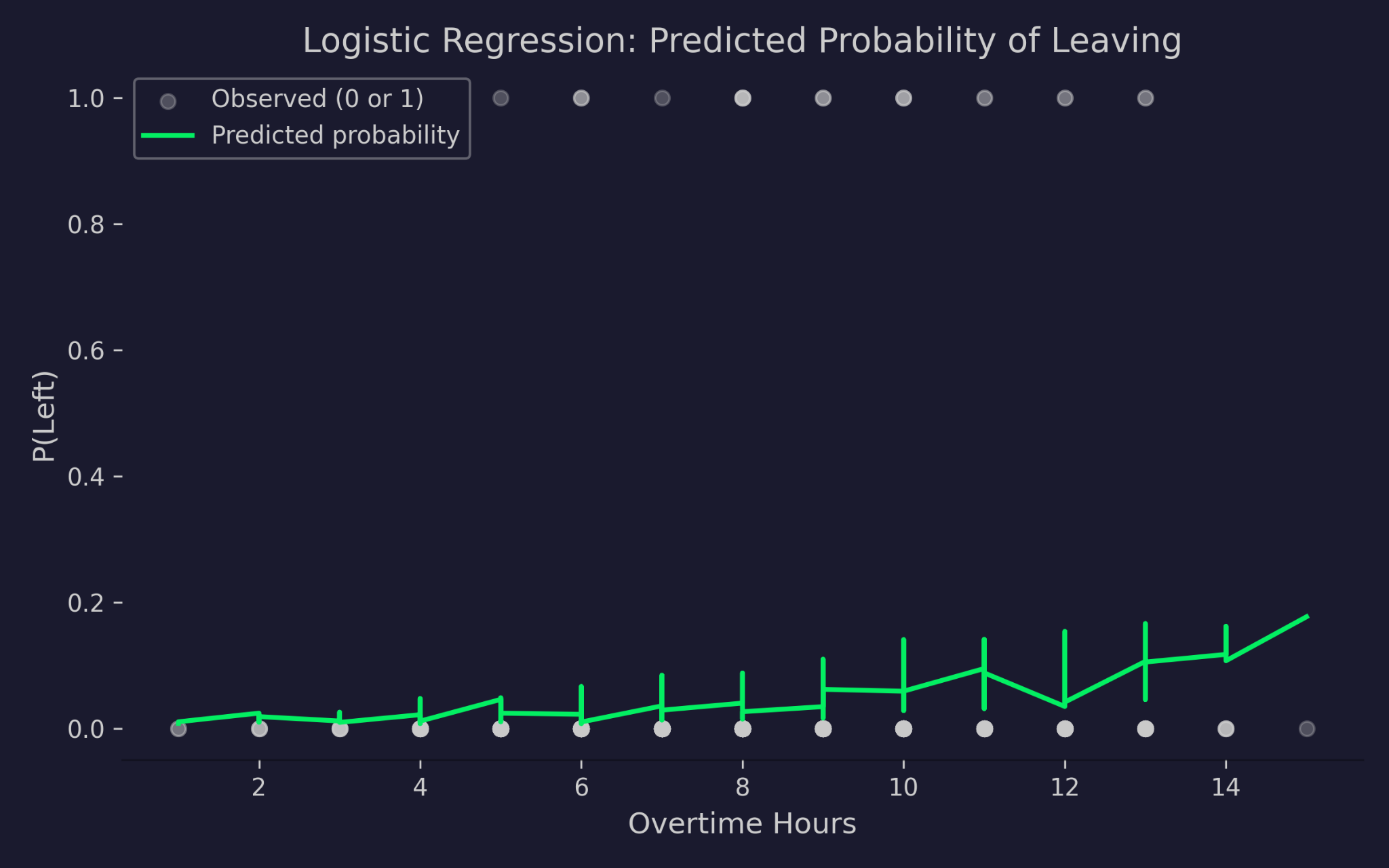
Probabilitas prediksi keluar dari perusahaan terhadap jam lembur
Bagan menunjukkan jam lembur pada sumbu x dan probabilitas keluar pada sumbu y. Titik abu-abu adalah hasil aktual — 0 (tetap) atau 1 (keluar). Kurva hijau adalah probabilitas yang diprediksi model. Seiring bertambahnya jam lembur, probabilitas keluar yang diprediksi meningkat, tetapi tidak pernah di bawah 0 atau melebihi 1. Itulah fungsi taut logit — ia menekan prediktor linear ke rentang probabilitas yang valid berapa pun ekstremnya nilai masukan.
Fungsi bawaan R glm() mengikuti logika yang sama namun dengan sintaks berbeda. Argumen family menetapkan distribusi dan fungsi taut, dan Anda mendefinisikan model dengan antarmuka formula R.
Berikut regresi logistik yang sama di R:
# Read the dataset
df <- read.csv("data.csv")
# Fit logistic regression
logit_model <- glm(left ~ salary + experience_years + overtime_hours,
data = df,
family = binomial(link = "logit"))
summary(logit_model)
Regresi logistik GLM di R
Formula left ~ salary + experience_years + overtime_hours memberi tahu R apa yang harus diprediksi dan masukan mana yang digunakan. Bagian family = binomial(link = "logit") menetapkan distribusi dan taut. Anda dapat menyingkatnya menjadi family = binomial() karena logit adalah taut bawaan untuk keluarga binomial.
Regresi Poisson sebagian besarnya sama:
poisson_model <- glm(sick_days ~ salary + experience_years + overtime_hours,
data = df,
family = poisson(link = "log"))
summary(poisson_model)
Regresi Poisson GLM di R
Anda hanya perlu mengganti binomial() menjadi poisson(), mengganti variabel respons, dan selesai.
Kedua bahasa menggunakan pendekatan yang sama — Anda memberikan argumen family/distribution yang menggabungkan distribusi dan fungsi taut bawaannya:

Menentukan distribusi dan taut di Python dan R
Setiap keluarga memiliki taut bawaan, tetapi Anda dapat menimpanya. Di Python, Anda dapat memberikan objek taut: sm.families.Binomial(link=sm.families.links.Probit()). Di R, cukup ubah argumen taut: family = binomial(link = "probit").
Untuk sebagian besar kasus penggunaan, taut bawaan adalah pilihan yang tepat.
Koefisien GLM tidak memiliki makna yang sama di berbagai jenis model. Fungsi taut mengubah cara Anda menafsirkannya.
Dalam regresi linear, penafsiran mudah. Koefisien 500 pada experience_years berarti setiap tambahan satu tahun pengalaman menambah 500 pada gaji yang diprediksi. Taut identitas berarti koefisien dipetakan langsung ke keluaran.
Regresi logistik berbeda. Taut logit berarti koefisien berada dalam ruang log-odds. Koefisien 0,12 pada overtime_hours tidak berarti probabilitas keluar naik 0,12. Itu berarti log-odds untuk keluar meningkat 0,12 untuk setiap jam lembur tambahan. Untuk mendapatkan sesuatu yang lebih mudah ditafsirkan, eksponenkan koefisiennya: e^0.12 ≈ 1,127. Ini memberikan rasio odds. Setiap jam lembur tambahan mengalikan odds untuk keluar sekitar 1,13.
Koefisien regresi Poisson bekerja melalui taut log. Koefisien 0,02 pada overtime_hours berarti setiap jam tambahan meningkatkan log dari nilai harapan hitungan sebesar 0,02. Ketika Anda mengeksponeksialkannya: e^0.02 ≈ 1,02, Anda akan melihat setiap jam lembur tambahan mengalikan jumlah hari sakit yang diharapkan sekitar 1,02.
Polanya adalah selalu menerapkan fungsi taut balik untuk berpindah dari ruang koefisien kembali ke ruang keluaran.
Memilih GLM yang tepat bermuara pada satu pertanyaan: seperti apa variabel keluaran Anda?
Jika keluaran Anda biner (ya/tidak, 0/1, lulus/gagal), gunakan regresi logistik. Distribusi binomial, taut logit. Ini mencakup tugas klasifikasi seperti memprediksi churn, deteksi penipuan, klasifikasi penyakit (memiliki atau tidak), atau apakah pasien akan merespons terapi.
Jika keluaran Anda berupa hitungan (jumlah kejadian dalam suatu jangka waktu), gunakan regresi Poisson. Distribusi Poisson, taut log. Ini sesuai untuk masalah seperti memprediksi jumlah kunjungan situs per jam atau klaim asuransi per tahun.
Jika keluaran Anda kontinu dan kira-kira normal (pendapatan, nilai ujian), regresi linear standar sudah memadai. Distribusi normal, taut identitas. Ini adalah GLM yang sudah Anda kenal.
Selalu mulai dari variabel keluaran, cocokkan dengan distribusi, lalu fungsi taut akan mengikutinya.
Berikut beberapa kesalahan umum yang harus Anda hindari saat bekerja dengan GLM.
Ini adalah kesalahan paling umum. Jika keluaran Anda adalah hitungan dan Anda memfitting regresi linear, Anda akan mendapatkan prediksi negatif. Jika biner dan Anda menggunakan Poisson, modelnya tidak masuk akal. Selalu lihat terlebih dahulu variabel keluaran Anda dan pilih distribusi yang cocok.
Fungsi taut mentransformasikan hubungan antara masukan dan keluaran. Koefisien regresi logistik 0,5 tidak berarti “probabilitas naik 0,5.” Itu berarti log-odds naik 0,5. Melupakan transformasi ini menyebabkan kesimpulan yang keliru tentang besaran efek dan pentingnya variabel.
Koefisien dalam regresi Poisson tidak dapat dibandingkan dengan koefisien dalam regresi logistik, meskipun angkanya terlihat mirip. Koefisien 0,3 berarti sesuatu yang berbeda tergantung apakah ia melalui taut log atau taut logit. Selalu tafsirkan koefisien dalam konteks model spesifik yang Anda gunakan.
GLM lebih fleksibel daripada regresi linear, tetapi tetap memiliki asumsi. Regresi Poisson mengasumsikan mean sama dengan varian — jika data hitung Anda memiliki varian jauh lebih besar daripada mean, galat baku model akan terlalu kecil dan nilai p Anda akan menyesatkan. Regresi logistik mengasumsikan observasi independen.
Untuk mengatasinya, setelah memfitting GLM apa pun, periksa residual dan cari pola yang mengindikasikan kecocokan yang buruk.
GLM memberi Anda cara terstruktur untuk melampaui regresi linear namun tetap mengikuti logika dasarnya. Gagasan kombinasi linear dari masukan tetap sama, tetapi distribusi dan fungsi taut berubah agar sesuai dengan data yang Anda gunakan.
Ada tiga komponen di balik GLM. Setelah Anda tahu cara memilih distribusi yang tepat, menyusun prediktor linear, dan menerapkan fungsi taut yang benar, Anda dapat menangani keluaran biner, hitungan, dan data kontinu dengan kerangka pikir yang sama.
Langkah terbaik berikutnya adalah mencobanya. Pilih dataset dengan keluaran non-normal, fit GLM di Python atau R, dan latih menafsirkan koefisien melalui fungsi taut. Gunakan dataset yang Anda pedulikan, dan setiap bagian teori yang dibahas akan terasa masuk akal dalam hitungan menit.
Jika Anda ingin melangkah lebih jauh dari regresi linear dan GLM, daftarlah ke jalur Machine Learning Scientist in Python kami. Anda akan mempelajari semua yang diperlukan untuk siap kerja pada 2026.
Belajar bersama DataCamp
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
