
Corso
Algebra lineare per la Data Science in R
4 h
21.2K
La regressione lineare è un ottimo primo modello da provare, ma va in crisi non appena i tuoi dati non seguono una distribuzione normale.
Poniamo che tu stia cercando di prevedere se un cliente abbandonerà (esito sì o no). La regressione lineare non sa farlo. Prevede valori continui, quindi finisci con output come -0,3 o 1,7 per qualcosa che può essere solo 0 o 1. Lo stesso problema emerge con i dati di conteggio, come il numero di ticket di supporto all’ora. La regressione lineare può prevedere conteggi negativi, cosa che non ha senso.
I modelli lineari generalizzati (GLM) risolvono questo problema estendendo la regressione lineare per gestire diversi tipi di esiti. L’idea di base è la stessa: una combinazione lineare degli input, ma con la flessibilità di modellare dati binari e altre distribuzioni non normali.
In questo articolo ti spiegherò cosa sono i GLM, illustrerò i loro tre componenti principali e ti mostrerò come adattarli e interpretarli sia in Python che in R.
Ma come funziona esattamente la regressione lineare? Leggi la nostra guida alla Regressione Lineare Semplice per capire assunzioni e diagnostiche, e come interpretarne i risultati.
Un modello lineare generalizzato (GLM) è un’estensione della regressione lineare che consente alla variabile risposta di seguire diverse distribuzioni di probabilità, non solo quella normale.
La cosa fondamentale da ricordare è che il GLM non è un singolo modello. È un framework. Regressione lineare, regressione logistica e regressione di Poisson sono tutte GLM. Ognuna usa una distribuzione diversa e un diverso modo di collegare input e output, ma seguono tutte la stessa struttura.
La regressione lineare standard fa due grandi assunzioni: l’esito è distribuito normalmente e la varianza resta costante lungo le previsioni. Se queste assunzioni non tengono, otterrai risultati privi di senso.
Per esempio, se stai costruendo un modello per prevedere se un richiedente un prestito andrà in default, l’esito è binario - 0 o 1. La regressione lineare non rispetta quel vincolo. Può prevedere -0,2 o 1,4, entrambi impossibili.
I dati di conteggio hanno lo stesso problema. Se stai prevedendo il numero di riammissioni ospedaliere al mese, la regressione lineare può restituire numeri negativi. Non puoi avere -3 riammissioni.
In entrambi i casi, il problema non è la combinazione lineare degli input: quella parte funziona bene. Il problema è come il modello mappa quegli input all’output. I GLM lo risolvono aggiungendo una funzione di collegamento (link) che trasforma l’output per adattarlo all’intervallo naturale dei dati. Le probabilità restano tra 0 e 1. I conteggi restano non negativi. Tra poco vedrai tutto nel dettaglio.
Ogni GLM è costruito da tre parti: una distribuzione, un predittore lineare e una funzione di collegamento. Vediamole una per una.
La componente casuale definisce che tipo di dati produce la tua variabile risposta. In altre parole, sceglie la distribuzione di probabilità che meglio descrive il tuo esito.
La regressione lineare assume una distribuzione normale, quindi l’esito è continuo e simmetrico attorno alla media. Ma non tutti i dati funzionano così.
Se il tuo esito è binario (sì/no, 0/1), useresti una distribuzione binomiale. Se stai modellando dati di conteggio - come il numero di errori al giorno - una distribuzione di Poisson è più adatta.
La distribuzione che scegli controlla tutto il resto del modello.
La componente sistematica è la parte che già conosci dalla regressione lineare. È una combinazione lineare delle tue variabili in input:
Componente sistematica
Dove X è la matrice delle feature in input e β è il vettore dei coefficienti. Moltiplichi ogni feature per il suo peso e sommi.
Questa parte non cambia tra i diversi GLM. In altre parole, che tu stia adattando una regressione logistica o una di Poisson, il predittore lineare ha lo stesso aspetto.
La funzione di collegamento connette il predittore lineare al valore atteso della variabile risposta. È l’elemento che rende i GLM flessibili.
Senza una funzione di collegamento, il predittore lineare produce valori da meno infinito a più infinito. Va bene per esiti continui, ma non per probabilità o conteggi. La funzione di collegamento trasforma l’output in modo che rientri nell’intervallo giusto per la distribuzione scelta.
Per esempio, la regressione logistica usa il link logit, che mappa un predittore lineare che può essere un qualsiasi numero reale in una probabilità tra 0 e 1. La regressione di Poisson usa il link log, che garantisce previsioni sempre positive.
L’equazione completa del GLM combina tutti e tre i componenti:
Equazione del GLM
Dove g() è la funzione di collegamento e μ è il valore atteso della risposta. La distribuzione definisce cosa significa μ, il predittore lineare calcola Xβ e la funzione di collegamento fa da ponte tra i due.
La funzione di collegamento determina come il predittore lineare si traduce nel tuo esito. Tipi di dati diversi richiedono trasformazioni diverse e ogni tipo di GLM ha una funzione di collegamento predefinita che si abbina alla sua distribuzione.
Il link identità è il più semplice: non fa nulla. Il predittore lineare è uguale al valore atteso della risposta:
Link identità
È quello usato dalla regressione lineare. I tuoi input si combinano in una somma pesata, e quella somma è la previsione. Non serve alcuna trasformazione perché l’esito può assumere qualsiasi valore continuo.
Il link logit prende una probabilità (tra 0 e 1) e la mappa sull’intera retta reale:
Link logit
È quello usato dalla regressione logistica. Il predittore lineare può restituire qualsiasi valore da meno infinito a più infinito, ma dopo la trasformazione inversa, la previsione resta sempre tra 0 e 1. Quel rapporto dentro il logaritmo - μ/(1-μ) - si chiama odds (quote), e il logaritmo delle odds è il log-odds. Quindi, quando interpreti i coefficienti della regressione logistica, lavori nello spazio dei log-odds.
Il link log prende il logaritmo naturale del valore atteso:
Link log
È quello usato dalla regressione di Poisson. Il predittore lineare può essere qualsiasi numero reale, ma dopo averlo esponenziato (l’inversa), la previsione è sempre positiva. È esattamente ciò che serve per i dati di conteggio, perché non puoi avere eventi negativi.
I GLM possono sembrare astratti finché non li vedi come modelli che già conosci. Regressione lineare, regressione logistica e regressione di Poisson sono tutti GLM. L’unica differenza è che ognuno usa una combinazione diversa di distribuzione e funzione di collegamento.
La regressione lineare è il GLM più semplice. La risposta segue una distribuzione normale e la funzione di collegamento è il link identità, cioè nessuna trasformazione.
Regressione lineare come GLM
Il predittore lineare è direttamente uguale all’esito atteso. È il GLM che hai sempre usato, solo che non lo chiamavi così.
La regressione logistica modella esiti binari usando una distribuzione binomiale e un link logit.
Regressione logistica come GLM
Il lato sinistro è il log-odds dell’evento. Il lato destro è la tua classica combinazione lineare degli input. Il link logit fa sì che le previsioni si mappino su probabilità tra 0 e 1, indipendentemente da quanto grande o piccolo diventi Xβ.
La regressione di Poisson modella dati di conteggio usando una distribuzione di Poisson e un link log.
Regressione di Poisson come GLM
Il log del conteggio atteso è uguale al predittore lineare. Se esponenzi entrambi i lati, ottieni μ = e^(Xβ), che è sempre positivo: esattamente ciò che richiedono i conteggi.
I GLM non usano i minimi quadrati ordinari come la regressione lineare. Invece si basano sulla massima verosimiglianza (MLE).
L’idea è semplice. La MLE trova l’insieme di coefficienti che rende i tuoi dati osservati più probabili sotto la distribuzione scelta. Per una regressione logistica, trova i coefficienti che rendono più probabili gli 0 e 1 osservati dato un modello binomiale. Per la regressione di Poisson, trova i coefficienti che spiegano meglio i conteggi osservati.
Per la maggior parte dei GLM non esiste una soluzione in forma chiusa, quindi l’ottimizzazione è iterativa. L’algoritmo parte da una stima iniziale dei coefficienti, valuta quanto bene si adattano ai dati, li aggiusta e ripete finché le stime non convergono.
Il metodo più comune è la Iteratively Reweighted Least Squares (IRLS), che riformula il problema MLE come una sequenza di regressioni lineari pesate. Funzionano anche i metodi basati sul gradiente, che calcolano la direzione di miglioramento più ripida e vi si spostano. Librerie come statsmodels e la glm() di R fanno tutto questo dietro le quinte, quindi non devi implementare tu il solver.
La cosa da ricordare è che sei tu a scegliere distribuzione e funzione di collegamento, e l’ottimizzatore trova i coefficienti migliori. Questa è l’idea: ora vediamo come funziona in pratica.
In questa sezione, passerò in rassegna la regressione logistica e quella di Poisson sia in Python che in R usando lo stesso dataset: un dataset simulato di abbandono dei dipendenti con colonne per stipendio, anni di esperienza, ore di straordinario, se il dipendente ha lasciato (binario) e numero di giorni di malattia (conteggio).
Creerò il dataset menzionato in Python e poi lo userò per i calcoli sia in Python che in R:
import numpy as np
import pandas as pd
np.random.seed(42)
n = 500
# Employee dataset
df = pd.DataFrame({
"salary": np.random.normal(55000, 12000, n).astype(int),
"experience_years": np.random.poisson(5, n),
"overtime_hours": np.random.poisson(8, n),
})
# Simulate binary outcome: left the company
prob_left = 1 / (1 + np.exp(-(
-2 + -0.00003 * df["salary"] + -0.05 * df["experience_years"] + 0.12 * df["overtime_hours"]
)))
df["left"] = np.random.binomial(1, prob_left)
# Simulate count outcome: sick days per year
df["sick_days"] = np.random.poisson(
np.exp(1.2 + 0.00001 * df["salary"] + 0.02 * df["overtime_hours"])
)
# Save to use later in R
df.to_csv("data.csv", index=False)
df.head()
Esempio di dataset sull’abbandono dei dipendenti
Python ti offre due opzioni principali per i GLM: statsmodels e scikit-learn. Qui userò statsmodels perché fornisce un riepilogo statistico completo, inclusi coefficienti, p-value e intervalli di confidenza. Ti serviranno quando interpreti un GLM.
Ecco come puoi adattare una regressione logistica per prevedere se un dipendente ha lasciato:
import statsmodels.api as sm
X = sm.add_constant(df[["salary", "experience_years", "overtime_hours"]])
logit_model = sm.GLM(df["left"], X, family=sm.families.Binomial())
logit_results = logit_model.fit()
print(logit_results.summary())
Risultati della regressione logistica GLM
La riga chiave è sm.families.Binomial(). Con un solo argomento imposti sia la distribuzione (binomiale) sia la funzione di collegamento predefinita (logit). Non devi specificare separatamente il link a meno che tu non voglia quello non predefinito.
Ora adattiamo una regressione di Poisson sullo stesso dataset per prevedere i giorni di malattia:
poisson_model = sm.GLM(df["sick_days"], X, family=sm.families.Poisson())
poisson_results = poisson_model.fit()
print(poisson_results.summary())
Risultati della regressione di Poisson GLM
Ti basta sostituire Binomial() con Poisson() e il modello usa una distribuzione di Poisson con link log. La tabella in output sembra la stessa, ma l’interpretazione cambia perché è cambiata la funzione di collegamento.
Ora visualizziamo le probabilità previste dalla regressione logistica rispetto alle ore di straordinario:
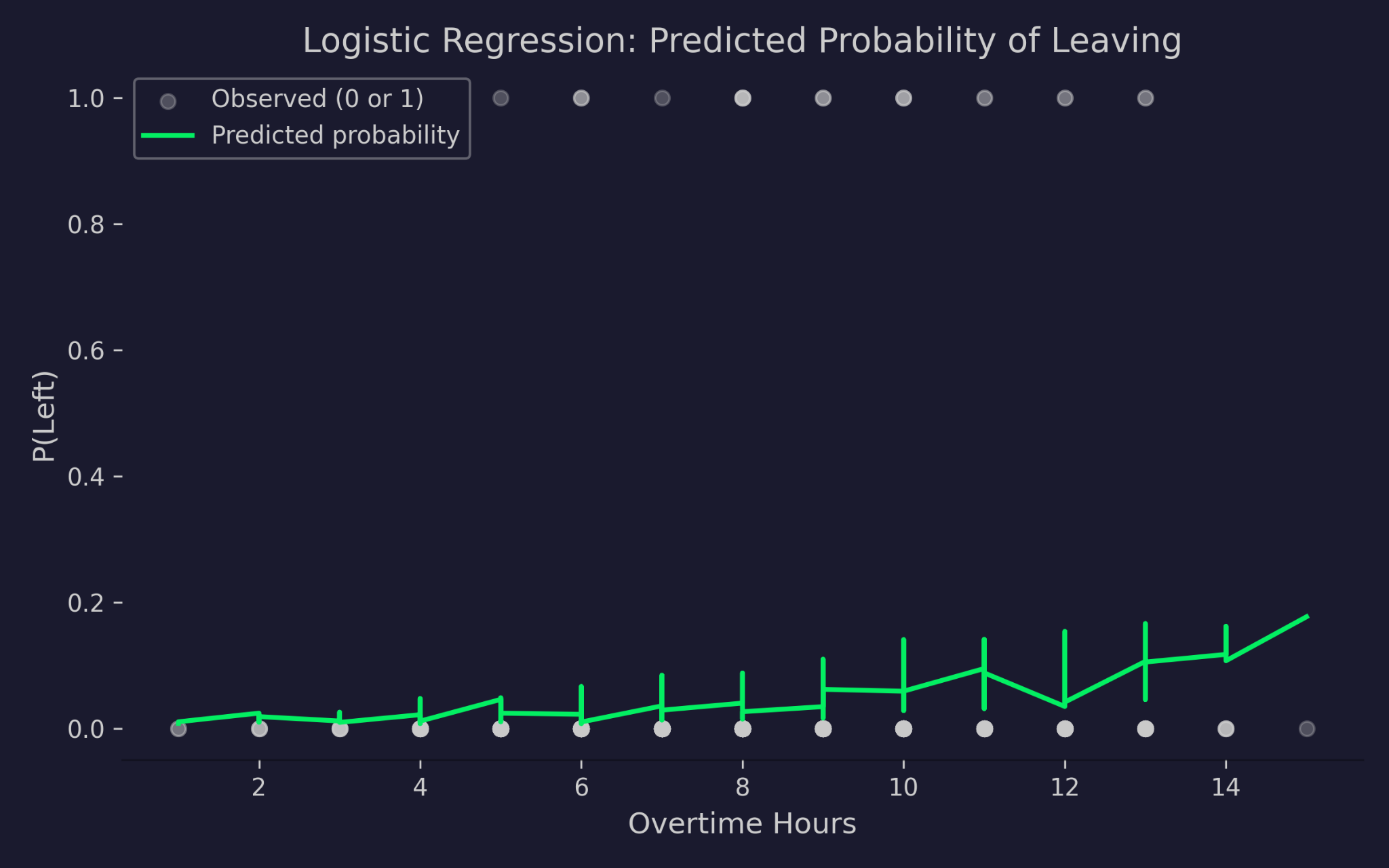
Probabilità previste di lasciare l’azienda in funzione delle ore di straordinario
Il grafico mostra le ore di straordinario sull’asse x e la probabilità di lasciare sull’asse y. I punti grigi sono gli esiti reali - 0 (rimasto) o 1 (ha lasciato). La curva verde è la probabilità prevista dal modello. All’aumentare delle ore di straordinario, la probabilità prevista di lasciare cresce, ma non scende mai sotto 0 né supera 1. È il link logit che agisce: comprime il predittore lineare in un intervallo di probabilità valido per quanto estremi siano i valori in input.
La funzione nativa di R glm() segue la stessa logica ma con una sintassi diversa. L’argomento family imposta distribuzione e funzione di collegamento, e definisci il modello con l’interfaccia a formula di R.
Ecco la stessa regressione logistica in R:
# Read the dataset
df <- read.csv("data.csv")
# Fit logistic regression
logit_model <- glm(left ~ salary + experience_years + overtime_hours,
data = df,
family = binomial(link = "logit"))
summary(logit_model)
Regressione logistica GLM in R
La formula left ~ salary + experience_years + overtime_hours dice a R cosa prevedere e quali input usare. La parte family = binomial(link = "logit") imposta distribuzione e link. Puoi abbreviare in family = binomial() dato che il logit è il link predefinito per la famiglia binomiale.
La regressione di Poisson è perlopiù uguale:
poisson_model <- glm(sick_days ~ salary + experience_years + overtime_hours,
data = df,
family = poisson(link = "log"))
summary(poisson_model)
Regressione di Poisson GLM in R
Devi solo cambiare binomial() con poisson(), cambiare la variabile risposta e hai finito.
Entrambi i linguaggi usano lo stesso approccio: passi un argomento family/distribuzione che combina la distribuzione e il suo link predefinito:

Specificare distribuzione e link in Python e R
Ogni famiglia ha un link predefinito, ma puoi sovrascriverlo. In Python, puoi passare un oggetto link: sm.families.Binomial(link=sm.families.links.Probit()). In R, cambia semplicemente l’argomento del link: family = binomial(link = "probit").
Per la maggior parte dei casi d’uso, il link predefinito è la scelta giusta.
I coefficienti dei GLM non significano la stessa cosa tra i diversi tipi di modelli. La funzione di collegamento ne cambia l’interpretazione.
Nella regressione lineare, l’interpretazione è semplice. Un coefficiente di 500 su experience_years significa che ogni anno di esperienza in più aggiunge 500 allo stipendio previsto. Il link identità fa sì che i coefficienti si mappino direttamente sull’esito.
La regressione logistica è diversa. Il link logit significa che i coefficienti sono nello spazio dei log-odds. Un coefficiente di 0,12 su overtime_hours non significa che la probabilità di lasciare aumenti di 0,12. Significa che i log-odds di lasciare aumentano di 0,12 per ogni ora di straordinario aggiuntiva. Per ottenere qualcosa di più interpretabile, esponenzia il coefficiente: e^0.12 ≈ 1.127. Questo ti dà un odds ratio. Ogni ora di straordinario in più moltiplica le odds di lasciare di circa 1,13.
I coefficienti della regressione di Poisson funzionano tramite il link log. Un coefficiente di 0,02 su overtime_hours significa che ogni ora in più aumenta di 0,02 il log del conteggio atteso. Quando lo esponenzi: e^0.02 ≈ 1.02, vedi che ogni ora di straordinario aggiuntiva moltiplica il numero atteso di giorni di malattia di circa 1,02.
La regola è applicare sempre l’inversa della funzione di collegamento per passare dallo spazio dei coefficienti allo spazio dell’esito.
Scegliere il GLM giusto si riduce a una domanda: com’è la tua variabile di esito?
Se il tuo esito è binario (sì/no, 0/1, pass/fail), usa la regressione logistica. Distribuzione binomiale, link logit. Copre attività di classificazione come prevedere il churn, il rilevamento frodi, la classificazione di malattie (ha o non ha) o se un paziente risponderà al trattamento.
Se il tuo esito è un conteggio (numero di eventi in una finestra temporale), usa la regressione di Poisson. Distribuzione di Poisson, link log. È adatta a problemi come prevedere il numero di visite al sito per ora o i sinistri assicurativi per anno.
Se il tuo esito è continuo e approssimativamente normale (ricavi, punteggi ai test), la regressione lineare standard va benissimo. Distribuzione normale, link identità. È il GLM che già conosci.
Parti sempre dalla variabile di esito, abbinala a una distribuzione e poi la funzione di collegamento segue di conseguenza.
Ecco alcuni errori comuni da evitare quando lavori con i GLM.
È l’errore più comune. Se il tuo esito è un conteggio e adatti una regressione lineare, otterrai previsioni negative. Se è binario e usi Poisson, il modello non avrà senso. Guarda sempre prima la tua variabile di esito e scegli la distribuzione che le corrisponde.
La funzione di collegamento trasforma la relazione tra input e output. Un coefficiente di 0,5 in una regressione logistica non significa "la probabilità aumenta di 0,5". Significa che i log-odds aumentano di 0,5. Dimenticare la trasformazione porta a conclusioni errate su entità degli effetti e importanza delle variabili.
I coefficienti in una regressione di Poisson non sono confrontabili con quelli in una regressione logistica, anche se i numeri sembrano simili. Un coefficiente di 0,3 significa qualcosa di diverso a seconda che passi attraverso un link log o un link logit. Interpreta sempre i coefficienti nel contesto del modello specifico che stai usando.
I GLM sono più flessibili della regressione lineare, ma hanno comunque delle assunzioni. La regressione di Poisson assume che media e varianza coincidano: se i tuoi dati di conteggio hanno molta più varianza della media, gli errori standard del modello saranno troppo piccoli e i p-value fuorvianti. La regressione logistica assume che le osservazioni siano indipendenti.
Per rimediare, dopo aver adattato qualsiasi GLM, controlla i residui e cerca pattern che suggeriscano un cattivo adattamento.
I GLM ti offrono un modo strutturato per andare oltre la regressione lineare mantenendone però la logica fondamentale. L’idea di una combinazione lineare degli input resta la stessa, ma distribuzione e funzione di collegamento cambiano per adattarsi ai dati con cui lavori.
Dietro ai GLM ci sono tre componenti. Una volta che sai come scegliere la distribuzione giusta, impostare il predittore lineare e applicare il link corretto, puoi gestire esiti binari, conteggi e dati continui con lo stesso modello mentale.
Il passo successivo migliore è provare. Scegli un dataset con un esito non normale, adatta un GLM in Python o R e fai pratica nell’interpretare i coefficienti attraverso la funzione di collegamento. Usa un dataset che ti interessa e tutta la teoria discussa ti sarà chiara in pochi minuti.
Se vuoi andare oltre la regressione lineare e i GLM, iscriviti al nostro percorso Machine Learning Scientist in Python. Ti mostra tutto ciò che ti serve per essere pronto per il lavoro nel 2026.
Impara con DataCamp
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

