Courses
Linear Algebra for Data Science in R
4 ชม.
21.2K
การถดถอยเชิงเส้นเป็นโมเดลตั้งต้นที่ดี แต่จะไปไม่รอดทันทีที่ข้อมูลของคุณไม่เป็นไปตามการแจกแจงแบบปกติ
สมมติว่ากำลังทำนายว่าลูกค้าจะยกเลิกการใช้งานหรือไม่ (ผลลัพธ์แบบใช่หรือไม่ใช่) การถดถอยเชิงเส้นทำแบบนั้นไม่ได้ เพราะมันทำนายค่าเชิงต่อเนื่อง จึงได้ผลลัพธ์อย่าง -0.3 หรือ 1.7 สำหรับสิ่งที่ควรเป็นได้แค่ 0 หรือ 1 ปัญหาเดียวกันเกิดกับข้อมูลนับ เช่นจำนวนทิกเก็ตซัพพอร์ตต่อชั่วโมง การถดถอยเชิงเส้นอาจทำนายค่าเป็นลบ ซึ่งไม่สมเหตุสมผล
แบบจำลองเชิงเส้นแบบเหมารวม (GLM) แก้ปัญหานี้ด้วยการต่อขยายการถดถอยเชิงเส้นให้รองรับผลลัพธ์หลายประเภท แนวคิดหลักยังเหมือนเดิมคือการรวมเชิงเส้นของอินพุต แต่ยืดหยุ่นพอที่จะจำลองข้อมูลทวิภาคและการแจกแจงที่ไม่ปกติอื่น ๆ ได้
บทความนี้จะแจกแจงว่า GLM คืออะไร อธิบายองค์ประกอบหลักทั้งสาม และสาธิตการฟิตและตีความโมเดลทั้งใน Python และ R
แต่การถดถอยเชิงเส้นทำงานอย่างไรแน่ ๆ อ่านคู่มือของเราเรื่อง การถดถอยเชิงเส้นอย่างง่าย เพื่อเรียนรู้ข้อสมมติ ฐานการวินิจฉัย และวิธีตีความผลลัพธ์
แบบจำลองเชิงเส้นแบบเหมารวม (GLM) เป็นการต่อขยายของการถดถอยเชิงเส้นที่เปิดให้ตัวแปรตอบสนองมีการแจกแจงแบบความน่าจะเป็นหลายรูปแบบ ไม่ใช่แค่การแจกแจงแบบปกติเท่านั้น
สิ่งสำคัญที่ต้องจำคือ GLM ไม่ใช่โมเดลตัวเดียว แต่เป็นกรอบแนวคิด การถดถอยเชิงเส้น การถดถอยลอจิสติก และการถดถอยปัวซอง ล้วนเป็น GLM ทั้งสิ้น แต่ละตัวใช้การแจกแจงและวิธีเชื่อมอินพุตกับเอาต์พุตต่างกัน ทว่ามีโครงสร้างร่วมกัน
การถดถอยเชิงเส้นมาตรฐานมีสมมติฐานใหญ่สองข้อ: ผลลัพธ์ต้องแจกแจงแบบปกติ และความแปรปรวนคงที่ตลอดการทำนาย หากสมมติฐานเหล่านี้ไม่เป็นจริง ผลลัพธ์ที่ได้จะไม่สมเหตุสมผล
ตัวอย่างเช่น หากสร้างโมเดลทำนายว่าผู้กู้จะผิดนัดหรือไม่ ผลลัพธ์เป็นทวิภาคคือ 0 หรือ 1 การถดถอยเชิงเส้นไม่เคารพขอบเขตนี้ มันทำนายได้ -0.2 หรือ 1.4 ซึ่งล้วนเป็นไปไม่ได้
ข้อมูลนับก็มีปัญหาเดียวกัน หากทำนายจำนวนการกลับเข้าโรงพยาบาลต่อเดือน การถดถอยเชิงเส้นอาจให้ค่าติดลบ ซึ่งไม่มีทางเกิดขึ้นได้ คุณไม่อาจมีการกลับเข้ารับการรักษา -3 ครั้ง
ปัญหาในทั้งสองกรณีไม่ได้อยู่ที่การรวมเชิงเส้นของอินพุต—ส่วนนั้นทำงานได้ดี—แต่อยู่ที่วิธีที่โมเดลทำแผนที่อินพุตไปยังเอาต์พุต GLM แก้ปัญหานี้ด้วยการเพิ่มฟังก์ชันลิงก์ที่แปลงเอาต์พุตให้พอดีกับช่วงธรรมชาติของข้อมูล ความน่าจะเป็นยังคงอยู่ระหว่าง 0 ถึง 1 ค่าจำนวนยังคงไม่ติดลบ เดี๋ยวจะเห็นรายละเอียดต่อไป
ทุก GLM สร้างจากสามส่วน: การแจกแจง ตัวทำนายเชิงเส้น และฟังก์ชันลิงก์ มาดูทีละส่วน
องค์ประกอบสุ่มกำหนดว่าตัวแปรตอบสนองของคุณให้ข้อมูลลักษณะไหน กล่าวคือเลือกการแจกแจงความน่าจะเป็นที่อธิบายผลลัพธ์ของคุณได้ดีที่สุด
การถดถอยเชิงเส้นถือว่ามีการแจกแจงแบบปกติ ดังนั้นผลลัพธ์จึงเป็นแบบต่อเนื่องและสมมาตรรอบค่าเฉลี่ย แต่ไม่ใช่ข้อมูลทั้งหมดจะเป็นเช่นนั้น
หากผลลัพธ์เป็นทวิภาค (ใช่/ไม่ใช่, 0/1) ควรใช้การแจกแจงแบบไบนอมีอัล หากจำลองข้อมูลนับ—เช่นจำนวนข้อผิดพลาดต่อวัน—การแจกแจงปัวซองจะเหมาะกว่า
การเลือกการแจกแจงจะกำหนดทุกอย่างที่เหลือในโมเดล
องค์ประกอบเชิงระบบคือส่วนที่คุณคุ้นเคยจากการถดถอยเชิงเส้น เป็นการรวมเชิงเส้นของตัวแปรอินพุต:
องค์ประกอบเชิงระบบ
โดยที่ X เป็นเมทริกซ์ของฟีเจอร์อินพุต และ β เป็นเวกเตอร์สัมประสิทธิ์ นำแต่ละฟีเจอร์คูณด้วยน้ำหนักของมันแล้วบวกเข้าด้วยกัน
ส่วนนี้ไม่เปลี่ยนไปใน GLM ประเภทต่าง ๆ กล่าวคือ ไม่ว่าจะฟิตลอจิสติกรีเกรสชันหรือปัวซองรีเกรสชัน ตัวทำนายเชิงเส้นก็ดูเหมือนเดิม
ฟังก์ชันลิงก์เชื่อมตัวทำนายเชิงเส้นกับค่าคาดหมายของตัวแปรตอบสนอง เป็นชิ้นส่วนที่ทำให้ GLM มีความยืดหยุ่น
หากไม่มีฟังก์ชันลิงก์ ตัวทำนายเชิงเส้นจะให้ค่าตั้งแต่ลบอนันต์ถึงบวกอนันต์ ซึ่งใช้ได้กับผลลัพธ์ต่อเนื่อง แต่ไม่เหมาะกับความน่าจะเป็นหรือค่าจำนวน ฟังก์ชันลิงก์จะแปลงเอาต์พุตให้ตกอยู่ในช่วงที่เหมาะกับการแจกแจงที่เลือก
เช่น ลอจิสติกรีเกรสชันใช้ลอจิตลิงก์ ซึ่งแมประหว่างตัวทำนายเชิงเส้นที่เป็นจำนวนจริงใด ๆ กับความน่าจะเป็นระหว่าง 0 ถึง 1 ปัวซองรีเกรสชันใช้ลอกลิงก์ เพื่อให้แน่ใจว่าการทำนายเป็นค่าบวกเสมอ
สมการ GLM แบบเต็มรวมองค์ประกอบทั้งสามเข้าด้วยกัน:
สมการ GLM
โดยที่ g() คือฟังก์ชันลิงก์ และ μ คือค่าคาดหมายของการตอบสนอง การแจกแจงนิยามว่า μ หมายถึงอะไร ตัวทำนายเชิงเส้นคำนวณ Xβ และฟังก์ชันลิงก์เชื่อมทั้งสองส่วนเข้าหากัน
ฟังก์ชันลิงก์กำหนดว่าตัวทำนายเชิงเส้นจะแปลงเป็นผลลัพธ์อย่างไร ข้อมูลคนละชนิดต้องการทรานส์ฟอร์มคนละแบบ และ GLM แต่ละชนิดมีฟังก์ชันลิงก์ค่าเริ่มต้นที่จับคู่กับการแจกแจงของมัน
ไอดเอนทิตีลิงก์ง่ายที่สุด—ไม่ทำอะไรเลย ตัวทำนายเชิงเส้นเท่ากับค่าคาดหมายของการตอบสนอง:
ไอดเอนทิตีลิงก์
นี่คือสิ่งที่การถดถอยเชิงเส้นใช้ อินพุตถูกรวมเป็นผลรวมถ่วงน้ำหนัก และผลรวมนั้นคือค่าทำนาย ไม่ต้องมีการแปลง เพราะผลลัพธ์รับค่าเชิงต่อเนื่องใด ๆ ก็ได้
ลอจิตลิงก์รับความน่าจะเป็น (ระหว่าง 0 และ 1) แล้วแมปไปยังเส้นจำนวนจริงทั้งหมด:
ลอจิตลิงก์
นี่คือสิ่งที่ลอจิสติกรีเกรสชันใช้ ตัวทำนายเชิงเส้นอาจให้ค่าได้ตั้งแต่ลบถึงบวกอนันต์ แต่หลังการแปลงย้อน ค่าทำนายจะอยู่ระหว่าง 0 ถึง 1 เสมอ อัตราส่วนภายในลอการิทึม μ/(1-μ) เรียกว่าออดส์ และลอการิทึมของออดส์คือล็อก-ออดส์ ดังนั้นเมื่อคุณตีความสัมประสิทธิ์ของลอจิสติกรีเกรสชัน คุณกำลังทำงานในพื้นที่ล็อก-ออดส์
ลอกลิงก์คือการนำลอการิทึมธรรมชาติของค่าคาดหมาย:
ลอกลิงก์
นี่คือสิ่งที่ปัวซองรีเกรสชันใช้ ตัวทำนายเชิงเส้นเป็นจำนวนจริงใด ๆ ก็ได้ แต่เมื่อเอ็กซ์โปเนนเชียลกลับ (การแปลงย้อน) ค่าทำนายจะเป็นบวกเสมอ ซึ่งเหมาะกับข้อมูลนับเพราะไม่อาจมีเหตุการณ์ติดลบ
GLM อาจดูนามธรรมจนกว่าจะเห็นว่าแท้จริงคือโมเดลที่คุณคุ้นเคย การถดถอยเชิงเส้น ลอจิสติกรีเกรสชัน และปัวซองรีเกรสชัน ล้วนเป็น GLM ความต่างเดียวคือแต่ละตัวใช้การแจกแจงและฟังก์ชันลิงก์คนละแบบ
การถดถอยเชิงเส้นเป็น GLM ที่ง่ายที่สุด การตอบสนองแจกแจงแบบปกติ และฟังก์ชันลิงก์เป็นไอดเอนทิตี หมายถึงไม่มีการแปลงเลย
การถดถอยเชิงเส้นในฐานะ GLM
ตัวทำนายเชิงเส้นเท่ากับค่าคาดหมายของผลลัพธ์โดยตรง นี่คือ GLM ที่คุณใช้มาโดยตลอด เพียงแต่ไม่ได้เรียกชื่อนั้น
ลอจิสติกรีเกรสชันจำลองผลลัพธ์ทวิภาคโดยใช้การแจกแจงแบบไบนอมีอัลและลอจิตลิงก์
ลอจิสติกรีเกรสชันในฐานะ GLM
ด้านซ้ายคือล็อก-ออดส์ของเหตุการณ์ ด้านขวาคือการรวมเชิงเส้นมาตรฐานของอินพุต ลอจิตลิงก์ทำให้ค่าทำนายถูกแมปเป็นความน่าจะเป็นระหว่าง 0 และ 1 ไม่ว่า Xβ จะมากหรือน้อยเพียงใด
ปัวซองรีเกรสชันจำลองข้อมูลนับโดยใช้การแจกแจงปัวซองและลอกลิงก์
ปัวซองรีเกรสชันในฐานะ GLM
ลอกของค่าคาดหมายของจำนวน เท่ากับตัวทำนายเชิงเส้น หากยกกำลังอีให้ทั้งสองข้าง จะได้ μ = e^(Xβ) ซึ่งเป็นบวกเสมอ—ตรงตามที่ข้อมูลนับต้องการ
GLM ไม่ได้ใช้วิธีกำลังสองน้อยที่สุดแบบปกติอย่างการถดถอยเชิงเส้น แต่ใช้การประมาณด้วยความน่าจะเป็นสูงสุด (MLE)แทน
แนวคิดตรงไปตรงมา MLE หาชุดสัมประสิทธิ์ที่ทำให้ข้อมูลที่สังเกตมีความน่าจะเป็นมากที่สุดภายใต้การแจกแจงที่เลือก สำหรับลอจิสติกรีเกรสชัน มันหาสัมประสิทธิ์ที่ทำให้ 0 และ 1 ที่เห็นมีความน่าจะเป็นสูงสุดภายใต้โมเดลไบนอมีอัล สำหรับปัวซองรีเกรสชัน มันหาสัมประสิทธิ์ที่อธิบายจำนวนที่สังเกตได้ดีที่สุด
สำหรับ GLM ส่วนใหญ่ไม่มีวิธีแก้แบบปิดรูป การทำเหมาะที่สุดจึงเป็นเชิงวนรอบ อัลกอริทึมเริ่มจากค่าคาดสำหรับสัมประสิทธิ์ ประเมินความพอดีของข้อมูล ปรับค่า แล้วทำซ้ำจนค่าประมาณลู่เข้า
วิธีที่พบบ่อยคือวิธีกำลังสองน้อยที่สุดแบบถ่วงน้ำหนักซ้ำ (IRLS) ซึ่งจัดกรอบปัญหา MLE ให้เป็นลำดับของการถดถอยเชิงเส้นแบบมีน้ำหนัก นอกจากนี้วิธีอาศัยกราดิเอนต์ก็ใช้ได้ โดยคำนวณทิศทางของการปรับปรุงที่ชันที่สุดและก้าวไปทางนั้น ไลบรารีอย่าง statsmodels และฟังก์ชัน glm() ของ R ทำทุกอย่างให้เบื้องหลัง จึงไม่ต้องลงมือเขียนตัวแก้เอง
สาระคือคุณเลือกการแจกแจงและฟังก์ชันลิงก์ แล้วตัวหาค่าที่เหมาะที่สุดจะหาสัมประสิทธิ์ให้ นั่นคือแนวคิด—ต่อไปจะสาธิตการใช้งานจริง
ส่วนนี้จะแสดงลอจิสติกรีเกรสชันและปัวซองรีเกรสชันทั้งใน Python และ R ด้วยชุดข้อมูลเดียวกัน—ข้อมูลจำลองการลาออกของพนักงาน โดยมีคอลัมน์เงินเดือน ปีประสบการณ์ ชั่วโมงล่วงเวลา เลิกงานหรือไม่ (ทวิภาค) และจำนวนวันลาป่วย (ข้อมูลนับ)
ฉันจะสร้างชุดข้อมูลที่กล่าวถึงใน Python แล้วนำไปใช้คำนวณทั้งใน Python และ R:
import numpy as np
import pandas as pd
np.random.seed(42)
n = 500
# Employee dataset
df = pd.DataFrame({
"salary": np.random.normal(55000, 12000, n).astype(int),
"experience_years": np.random.poisson(5, n),
"overtime_hours": np.random.poisson(8, n),
})
# Simulate binary outcome: left the company
prob_left = 1 / (1 + np.exp(-(
-2 + -0.00003 * df["salary"] + -0.05 * df["experience_years"] + 0.12 * df["overtime_hours"]
)))
df["left"] = np.random.binomial(1, prob_left)
# Simulate count outcome: sick days per year
df["sick_days"] = np.random.poisson(
np.exp(1.2 + 0.00001 * df["salary"] + 0.02 * df["overtime_hours"])
)
# Save to use later in R
df.to_csv("data.csv", index=False)
df.head()
ตัวอย่างชุดข้อมูลการลาออกของพนักงาน
Python มีตัวเลือกหลักสองตัวสำหรับ GLM คือ statsmodels และ scikit-learn ที่นี่จะใช้ statsmodels เพราะให้สรุปเชิงสถิติครบถ้วน รวมถึงสัมประสิทธิ์ ค่า p และช่วงความเชื่อมั่น ซึ่งจำเป็นต่อการตีความ GLM
นี่คือวิธีฟิตลอจิสติกรีเกรสชันเพื่อทำนายว่าพนักงานลาออกหรือไม่:
import statsmodels.api as sm
X = sm.add_constant(df[["salary", "experience_years", "overtime_hours"]])
logit_model = sm.GLM(df["left"], X, family=sm.families.Binomial())
logit_results = logit_model.fit()
print(logit_results.summary())
ผลลัพธ์ลอจิสติกรีเกรสชันแบบ GLM
บรรทัดสำคัญคือ sm.families.Binomial() ซึ่งตั้งค่าทั้งการแจกแจง (ไบนอมีอัล) และฟังก์ชันลิงก์เริ่มต้น (ลอจิต) ในอาร์กิวเมนต์เดียว ไม่จำเป็นต้องระบุลิงก์แยกต่างหาก เว้นแต่ต้องการใช้แบบที่ไม่ใช่ค่าเริ่มต้น
ต่อไปมาฟิตปัวซองรีเกรสชันกับชุดข้อมูลเดียวกันเพื่อทำนายวันลาป่วย:
poisson_model = sm.GLM(df["sick_days"], X, family=sm.families.Poisson())
poisson_results = poisson_model.fit()
print(poisson_results.summary())
ผลลัพธ์ปัวซองรีเกรสชันแบบ GLM
แค่สลับจาก Binomial() เป็น Poisson() โมเดลก็จะใช้การแจกแจงปัวซองกับลอกลิงก์ ตารางผลลัพธ์ดูคล้ายเดิม แต่การตีความเปลี่ยนไปเพราะฟังก์ชันลิงก์ต่างกัน
ต่อไปมาดูภาพการพยากรณ์ความน่าจะเป็นจากลอจิสติกรีเกรสชันเทียบกับชั่วโมงล่วงเวลา:
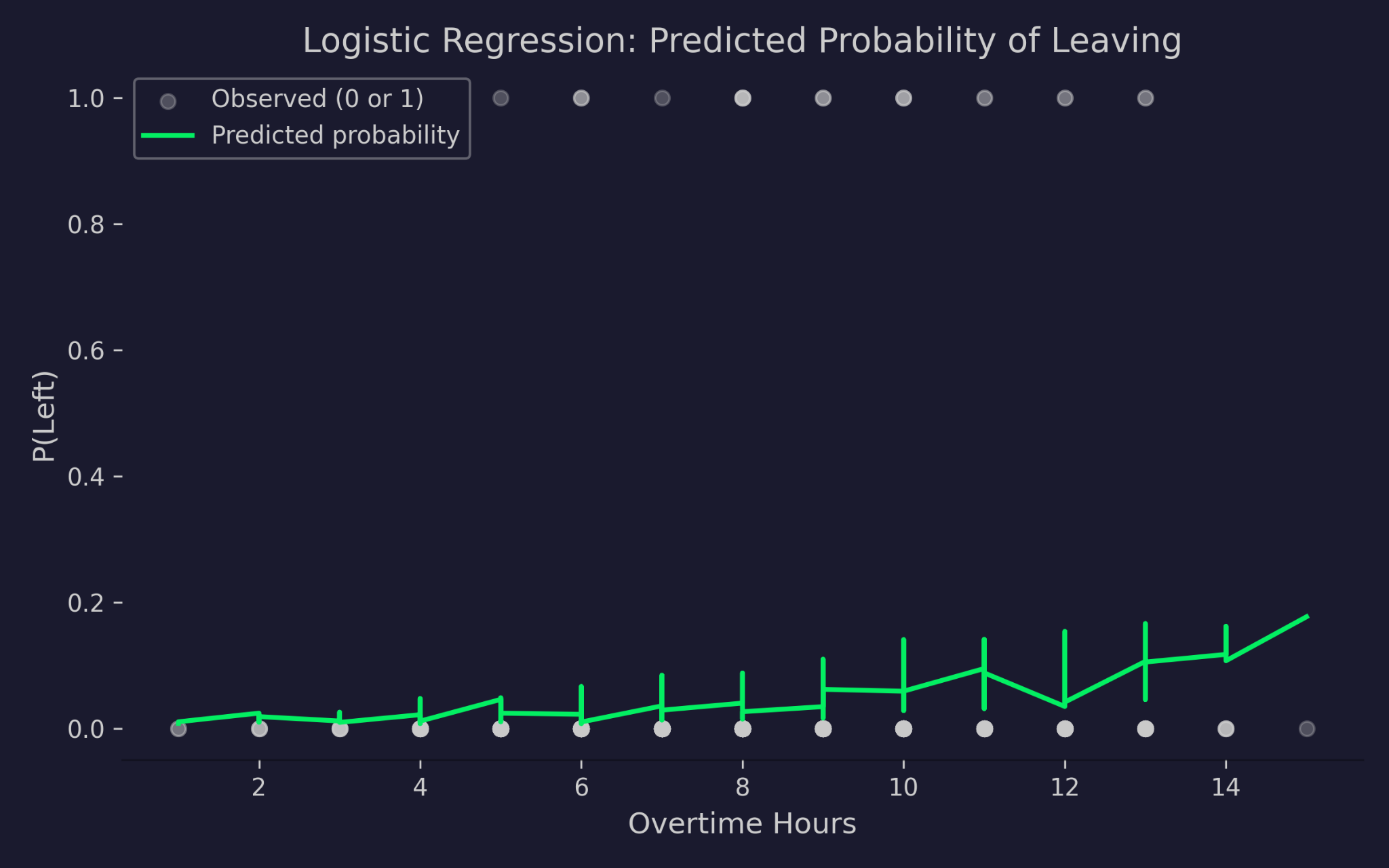
ความน่าจะเป็นที่คาดการณ์ของการลาออก เทียบกับชั่วโมงล่วงเวลา
กราฟแสดงชั่วโมงล่วงเวลาบนแกนนอน เทียบกับความน่าจะเป็นของการลาออกบนแกนตั้ง จุดสีเทาคือผลลัพธ์จริง—0 (อยู่ต่อ) หรือ 1 (ลาออก) เส้นสีเขียวคือความน่าจะเป็นที่โมเดลคาดการณ์ เมื่อชั่วโมงล่วงเวลาเพิ่ม ความน่าจะเป็นของการลาออกที่คาดการณ์ก็เพิ่มขึ้น แต่ไม่เคยต่ำกว่า 0 หรือเกิน 1 นี่คือการทำงานของลอจิตลิงก์—มันบีบตัวทำนายเชิงเส้นให้อยู่ในช่วงความน่าจะเป็นที่ถูกต้อง ไม่ว่าค่าอินพุตจะสุดขั้วเพียงใด
ฟังก์ชัน glm() ที่มากับ R ใช้ตรรกะเดียวกันแต่ไวยากรณ์ต่างกัน อาร์กิวเมนต์ family ตั้งค่าการแจกแจงและฟังก์ชันลิงก์ และคุณนิยามโมเดลด้วยสูตรของ R
นี่คือลอจิสติกรีเกรสชันเดียวกันใน R:
# Read the dataset
df <- read.csv("data.csv")
# Fit logistic regression
logit_model <- glm(left ~ salary + experience_years + overtime_hours,
data = df,
family = binomial(link = "logit"))
summary(logit_model)
ลอจิสติกรีเกรสชันแบบ GLM ใน R
สูตร left ~ salary + experience_years + overtime_hours บอก R ว่าจะทำนายอะไรและใช้อินพุตใดบ้าง ส่วน family = binomial(link = "logit") ตั้งค่าการแจกแจงและลิงก์ สามารถย่อเป็น family = binomial() ได้ เพราะลอจิตเป็นลิงก์เริ่มต้นของตระกูลไบนอมีอัล
ปัวซองรีเกรสชันก็คล้ายกันเกือบทั้งหมด:
poisson_model <- glm(sick_days ~ salary + experience_years + overtime_hours,
data = df,
family = poisson(link = "log"))
summary(poisson_model)
ปัวซองรีเกรสชันแบบ GLM ใน R
แค่เปลี่ยนจาก binomial() เป็น poisson() เปลี่ยนตัวแปรตอบสนอง แล้วก็เรียบร้อย
ทั้งสองภาษาใช้แนวทางเดียวกัน—ส่งอาร์กิวเมนต์ตระกูล/การแจกแจงที่รวมการแจกแจงและฟังก์ชันลิงก์เริ่มต้นเข้าด้วยกัน:

การระบุการแจกแจงและลิงก์ใน Python และ R
แต่ละตระกูลมีลิงก์เริ่มต้น แต่คุณสามารถเปลี่ยนได้ ใน Python สามารถส่งออบเจกต์ลิงก์: sm.families.Binomial(link=sm.families.links.Probit()) ใน R เปลี่ยนพารามิเตอร์ลิงก์: family = binomial(link = "probit")
สำหรับการใช้งานส่วนใหญ่ ลิงก์เริ่มต้นคือทางเลือกที่เหมาะ
สัมประสิทธิ์ของ GLM ไม่มีความหมายเหมือนกันข้ามโมเดลต่างชนิด ฟังก์ชันลิงก์ทำให้วิธีตีความเปลี่ยนไป
ในการถดถอยเชิงเส้น การตีความง่ายมาก สัมประสิทธิ์ 500 บน experience_years หมายถึงแต่ละปีประสบการณ์ที่เพิ่มขึ้น จะเพิ่มเงินเดือนที่ทำนาย 500 ไอดเอนทิตีลิงก์ทำให้สัมประสิทธิ์แมปไปยังผลลัพธ์โดยตรง
ลอจิสติกรีเกรสชันต่างออกไป ลอจิตลิงก์ทำให้สัมประสิทธิ์อยู่ในพื้นที่ล็อก-ออดส์ สัมประสิทธิ์ 0.12 บน overtime_hours ไม่ได้หมายความว่าความน่าจะเป็นของการลาออกเพิ่มขึ้น 0.12 แต่มันหมายถึงล็อก-ออดส์ของการลาออกเพิ่มขึ้น 0.12 ต่อชั่วโมงล่วงเวลาที่เพิ่มขึ้นหนึ่งชั่วโมง เพื่อให้อ่านออกมากขึ้น ให้ยกกำลังอีของสัมประสิทธิ์: e^0.12 ≈ 1.127 จะได้อัตราส่วนออดส์ แต่ละชั่วโมงล่วงเวลาที่เพิ่มขึ้นคูณออดส์ของการลาออกราว 1.13 เท่า
สัมประสิทธิ์ของปัวซองรีเกรสชันทำงานผ่านลอกลิงก์ สัมประสิทธิ์ 0.02 บน overtime_hours หมายถึงแต่ละชั่วโมงที่เพิ่มขึ้นเพิ่มล็อกของค่าคาดหมายของจำนวน 0.02 เมื่อยกกำลังอี: e^0.02 ≈ 1.02 จะเห็นว่าแต่ละชั่วโมงล่วงเวลาที่เพิ่มขึ้นคูณจำนวนวันลาป่วยที่คาดหวังราว 1.02 เท่า
รูปแบบทั่วไปคือให้ใช้ฟังก์ชันผกผันของลิงก์เสมอ เพื่อย้ายจากพื้นที่สัมประสิทธิ์กลับไปยังพื้นที่ผลลัพธ์
การเลือก GLM ที่เหมาะขึ้นอยู่กับคำถามเดียว: ตัวแปรผลลัพธ์ของคุณมีลักษณะอย่างไร
หากผลลัพธ์เป็นทวิภาค (ใช่/ไม่ใช่, 0/1, ผ่าน/ไม่ผ่าน) ให้ใช้ลอจิสติกรีเกรสชัน การแจกแจงไบนอมีอัล ลอจิตลิงก์ ครอบคลุมงานจัดประเภท เช่น การทำนายการยกเลิก การตรวจจับฉ้อโกง การจัดประเภทโรค (มีหรือไม่มี) หรือการตอบสนองต่อการรักษาหรือไม่
หากผลลัพธ์เป็นข้อมูลนับ (จำนวนเหตุการณ์ในช่วงเวลา) ให้ใช้ปัวซองรีเกรสชัน การแจกแจงปัวซอง ลอกลิงก์ เหมาะกับปัญหาอย่างทำนายจำนวนผู้เข้าชมเว็บไซต์ต่อชั่วโมงหรือจำนวนเคลมประกันต่อปี
หากผลลัพธ์เป็นเชิงต่อเนื่อง และโดยรวมใกล้เคียงปกติ (รายได้ คะแนนสอบ) การถดถอยเชิงเส้นมาตรฐานก็เพียงพอแล้ว การแจกแจงปกติ ไอดเอนทิตีลิงก์ นี่คือ GLM ที่คุณรู้จักดี
เริ่มจากตัวแปรผลลัพธ์ จับคู่กับการแจกแจง แล้วฟังก์ชันลิงก์จะตามมาเอง
ต่อไปนี้คือข้อผิดพลาดที่พบบ่อยซึ่งควรหลีกเลี่ยงเมื่อทำงานกับ GLM
นี่คือความผิดพลาดที่พบบ่อยที่สุด หากผลลัพธ์เป็นข้อมูลนับแต่ฟิตการถดถอยเชิงเส้น คุณจะได้การทำนายติดลบ หากเป็นทวิภาคแต่ใช้ปัวซอง โมเดลจะไม่สมเหตุสมผล ดูตัวแปรผลลัพธ์ก่อนเสมอแล้วเลือกการแจกแจงที่สอดคล้อง
ฟังก์ชันลิงก์แปลงความสัมพันธ์ระหว่างอินพุตและเอาต์พุต สัมประสิทธิ์ 0.5 ในลอจิสติกรีเกรสชันไม่ได้หมายความว่า “ความน่าจะเป็นเพิ่มขึ้น 0.5” แต่มันหมายถึงล็อก-ออดส์เพิ่มขึ้น 0.5 การละเลยการแปลงจะนำไปสู่ข้อสรุปผิดเกี่ยวกับขนาดอิทธิพลและความสำคัญของตัวแปร
สัมประสิทธิ์ในปัวซองรีเกรสชันเปรียบเทียบกับสัมประสิทธิ์ในลอจิสติกรีเกรสชันไม่ได้ แม้ตัวเลขจะดูคล้ายกันก็ตาม ค่าที่ 0.3 มีความหมายต่างกันขึ้นอยู่กับว่าผ่านลอกลิงก์หรือลอจิตลิงก์ ตีความสัมประสิทธิ์ในบริบทของโมเดลที่ใช้อยู่เสมอ
GLM ยืดหยุ่นกว่าการถดถอยเชิงเส้น แต่ก็ยังมีข้อสมมติ ปัวซองรีเกรสชันสมมติว่าค่าเฉลี่ยเท่ากับความแปรปรวน—หากข้อมูลนับของคุณมีความแปรปรวนมากกว่าค่าเฉลี่ยมาก ค่าคลาดเคลื่อนมาตรฐานของโมเดลจะเล็กเกินไปและค่า p จะชวนให้เข้าใจผิด ลอจิสติกรีเกรสชันสมมติว่าการสังเกตเป็นอิสระต่อกัน
เพื่อรับมือ หลังจากฟิต GLM ใด ๆ แล้ว ให้ตรวจเรสิดวลและมองหารูปแบบที่บ่งชี้ถึงความไม่พอดี
GLM ให้แนวทางที่เป็นระบบในการก้าวข้ามการถดถอยเชิงเส้น แต่ยังคงตรรกะพื้นฐานไว้เหมือนเดิม แนวคิดเรื่องการรวมเชิงเส้นของอินพุตยังคงเดิม ต่างกันที่การแจกแจงและฟังก์ชันลิงก์ที่ปรับให้เข้ากับข้อมูลที่กำลังทำงานด้วย
GLM มีสามองค์ประกอบ เมื่อรู้วิธีเลือกการแจกแจงที่เหมาะ ตั้งค่าตัวทำนายเชิงเส้น และใช้ฟังก์ชันลิงก์ที่ถูกต้อง คุณก็รับมือผลลัพธ์ทวิภาค ค่าจำนวน และข้อมูลต่อเนื่องได้ด้วยกรอบความคิดเดียวกัน
ขั้นตอนถัดไปที่ดีที่สุดคือการลองทำ เลือกชุดข้อมูลที่ผลลัพธ์ไม่ปกติ ฟิต GLM ใน Python หรือ R และฝึกตีความสัมประสิทธิ์ผ่านฟังก์ชันลิงก์ ใช้ชุดข้อมูลที่คุณใส่ใจ แล้วทฤษฎีทั้งหมดจะลงล็อกในไม่กี่นาที
หากต้องการก้าวไกลกว่าการถดถอยเชิงเส้นและ GLM ลงทะเบียนในแทร็ก Machine Learning Scientist in Python ของเรา ซึ่งจะแสดงทุกอย่างที่จำเป็นเพื่อพร้อมทำงานในปี 2026
เรียนกับ DataCamp
Courses
Courses
Courses