course
Linear Algebra for Data Science in R
4 घंटा
21.2K
लीनियर रिग्रेशन शुरू करने के लिए बेहतरीन मॉडल है, लेकिन जैसे ही आपका डेटा नॉर्मल डिस्ट्रीब्यूशन में फिट नहीं बैठता, यह कमज़ोर पड़ जाता है।
मान लीजिए आप यह भविष्यवाणी करना चाहते हैं कि कोई ग्राहक छोड़ देगा या नहीं (हां/नहीं का परिणाम)। लीनियर रिग्रेशन यह नहीं कर पाता। यह निरंतर मानों की भविष्यवाणी करता है, तो 0 या 1 जैसे परिणाम के लिए -0.3 या 1.7 जैसे आउटपुट देता है। यही समस्या काउंट डेटा के साथ भी आती है, जैसे प्रति घंटे सपोर्ट टिकटों की संख्या। लीनियर रिग्रेशन नकारात्मक काउंट भी भविष्यवाणी कर सकता है, जिसका कोई मतलब नहीं।
जनरलाइज़्ड लीनियर मॉडल (GLMs) इसे ठीक करते हैं—वे लीनियर रिग्रेशन का विस्तार करके अलग-अलग प्रकार के परिणामों को संभालते हैं। मूल विचार वही है—इनपुट्स का लीनियर संयोजन—लेकिन बाइनरी डेटा और अन्य नॉन-नॉर्मल डिस्ट्रीब्यूशन्स को मॉडल करने की लचीलापन जोड़ते हैं।
इस लेख में, मैं बताऊंगा कि GLM क्या हैं, उनके तीन मुख्य घटकों से गुजरूंगा, और आपको दिखाऊंगा कि Python और R दोनों में उन्हें कैसे फिट और इंटरप्रेट किया जाता है।
लेकिन लीनियर रिग्रेशन वास्तव में कैसे काम करता है? हमारी सिंपल लीनियर रिग्रेशन गाइड पढ़ें—इसकी धारणाएँ और डायग्नोस्टिक्स, और परिणामों की व्याख्या कैसे करें।
जनरलाइज़्ड लीनियर मॉडल (GLM) लीनियर रिग्रेशन का विस्तार है, जो रिस्पॉन्स वेरिएबल को केवल नॉर्मल डिस्ट्रीब्यूशन ही नहीं, बल्कि अलग-अलग प्रायिकता वितरणों का पालन करने देता है।
ध्यान रखने वाली बात यह है कि GLM कोई एकल मॉडल नहीं है। यह एक फ्रेमवर्क है। लीनियर रिग्रेशन, लॉजिस्टिक रिग्रेशन, और पॉइसन रिग्रेशन सभी GLM हैं। हर एक अलग डिस्ट्रीब्यूशन और इनपुट्स-आउटपुट्स को जोड़ने के अलग तरीके का उपयोग करता है, लेकिन सभी की संरचना समान रहती है।
मानक लीनियर रिग्रेशन दो बड़ी धारणा बनाता है: आपका आउटकम नॉर्मली डिस्ट्रीब्यूटेड है, और वैरिएंस भविष्यवाणियों के पार स्थिर रहता है। यदि ये मान्यताएँ सही नहीं बैठतीं, तो परिणामों का कोई अर्थ नहीं निकलता।
उदाहरण के लिए, यदि आप यह मॉडल बना रहे हैं कि कोई लोन आवेदक डिफॉल्ट करेगा या नहीं, तो परिणाम बाइनरी है—0 या 1। लीनियर रिग्रेशन उस सीमा का सम्मान नहीं करता। यह -0.2 या 1.4 जैसी भविष्यवाणियाँ दे सकता है, जो असंभव हैं।
काउंट डेटा में भी यही समस्या है। यदि आप प्रति माह अस्पताल रीडमिशन की संख्या का पूर्वानुमान लगा रहे हैं, तो लीनियर रिग्रेशन नकारात्मक संख्याएँ दे सकता है। -3 रीडमिशन नहीं हो सकते।
दोनों मामलों में समस्या इनपुट्स के लीनियर संयोजन में नहीं है—वह हिस्सा ठीक काम करता है। समस्या यह है कि मॉडल उन इनपुट्स को आउटपुट में कैसे मैप करता है। GLM इसे एक लिंक फंक्शन जोड़कर हल करते हैं, जो आउटपुट को डेटा की प्राकृतिक सीमा में ट्रांसफॉर्म करता है। प्रायिकताएँ 0 और 1 के बीच रहती हैं। काउंट्स गैर-निगेटिव रहते हैं। आगे आप इसके बारे में सब देखेंगे।
हर GLM तीन हिस्सों से बना होता है: एक डिस्ट्रीब्यूशन, एक लीनियर प्रेडिक्टर, और एक लिंक फंक्शन। आइए एक-एक करके देखें।
रैंडम कंपोनेंट यह परिभाषित करता है कि आपका रिस्पॉन्स वेरिएबल किस तरह का डेटा पैदा करता है। दूसरे शब्दों में, यह उस प्रायिकता वितरण का चयन करता है जो आपके आउटकम का सबसे अच्छा वर्णन करता है।
लीनियर रिग्रेशन नॉर्मल डिस्ट्रीब्यूशन मानता है, इसलिए आउटकम सतत और औसत के आस-पास सममित होता है। लेकिन सारा डेटा ऐसा नहीं होता।
यदि आपका आउटकम बाइनरी है (हां/नहीं, 0/1), तो आप बाइनोमियल डिस्ट्रीब्यूशन का उपयोग करेंगे। यदि आप काउंट डेटा—जैसे प्रति दिन एरर्स की संख्या—मॉडल कर रहे हैं, तो पॉइसन डिस्ट्रीब्यूशन बेहतर फिट है।
आपका चुना हुआ डिस्ट्रीब्यूशन मॉडल की बाकी हर चीज़ को नियंत्रित करता है।
सिस्टमैटिक कंपोनेंट वह हिस्सा है जिसे आप पहले से लीनियर रिग्रेशन से जानते हैं। यह आपके इनपुट वेरिएबल्स का लीनियर संयोजन है:
सिस्टमैटिक कंपोनेंट
जहाँ X आपकी इनपुट फीचर्स की मैट्रिक्स है और β कोएफिशिएंट्स का वेक्टर है। आप हर फीचर को उसके वेट से गुणा करते हैं और उन्हें जोड़ते हैं।
यह हिस्सा अलग-अलग GLM में नहीं बदलता। यानी, आप लॉजिस्टिक रिग्रेशन फिट कर रहे हों या पॉइसन रिग्रेशन, लीनियर प्रेडिक्टर एक जैसा दिखता है।
लिंक फंक्शन लीनियर प्रेडिक्टर को रिस्पॉन्स वेरिएबल के अपेक्षित मान से जोड़ता है। यही हिस्सा GLM को लचीला बनाता है।
बिना लिंक फंक्शन के, लीनियर प्रेडिक्टर नकारात्मक अनंत से धनात्मक अनंत तक मान देता है। यह सतत परिणामों के लिए ठीक है, लेकिन प्रायिकताओं या काउंट्स के लिए नहीं। लिंक फंक्शन आउटपुट को इस तरह ट्रांसफॉर्म करता है कि वह आपके चुने हुए डिस्ट्रीब्यूशन की सही रेंज में आ जाए।
उदाहरण के लिए, लॉजिस्टिक रिग्रेशन लॉजिट लिंक का उपयोग करता है, जो किसी भी वास्तविक संख्या वाले लीनियर प्रेडिक्टर को 0 और 1 के बीच की प्रायिकता में मैप करता है। पॉइसन रिग्रेशन लॉग लिंक का उपयोग करता है, जो सुनिश्चित करता है कि भविष्यवाणियाँ हमेशा धनात्मक रहें।
पूरा GLM समीकरण इन तीनों कंपोनेंट्स को मिलाता है:
GLM समीकरण
जहाँ g() लिंक फंक्शन है और μ रिस्पॉन्स का अपेक्षित मान है। डिस्ट्रीब्यूशन परिभाषित करता है कि μ का मतलब क्या है, लीनियर प्रेडिक्टर Xβ गणना करता है, और लिंक फंक्शन दोनों के बीच पुल का काम करता है।
लिंक फंक्शन यह निर्धारित करता है कि लीनियर प्रेडिक्टर आपके आउटकम में कैसे बदलेगा। अलग डेटा प्रकारों को अलग ट्रांसफॉर्मेशन चाहिए, और हर GLM प्रकार के साथ उसके डिस्ट्रीब्यूशन का एक डिफॉल्ट लिंक फंक्शन जुड़ा होता है।
आइडेंटिटी लिंक सबसे सरल है—यह कुछ नहीं करता। लीनियर प्रेडिक्टर रिस्पॉन्स के अपेक्षित मान के बराबर होता है:
आइडेंटिटी लिंक
यही लीनियर रिग्रेशन उपयोग करता है। आपके इनपुट वेटेड सम में मिलते हैं, और वही सम भविष्यवाणी है। कोई ट्रांसफॉर्मेशन नहीं चाहिए, क्योंकि आउटकम कोई भी सतत मान ले सकता है।
लॉजिट लिंक किसी प्रायिकता (0 और 1 के बीच) को पूरी वास्तविक संख्या रेखा पर मैप करता है:
लॉजिट लिंक
यही लॉजिस्टिक रिग्रेशन उपयोग करता है। लीनियर प्रेडिक्टर नकारात्मक अनंत से धनात्मक अनंत तक कोई भी मान दे सकता है, लेकिन इन्वर्स ट्रांसफॉर्मेशन के बाद भविष्यवाणी हमेशा 0 और 1 के बीच बैठती है। लॉगरिद्म के अंदर का वह अनुपात—μ/(1-μ)—ऑड्स कहलाता है, और ऑड्स का लॉगरिद्म लॉग-ऑड्स। इसलिए जब आप लॉजिस्टिक रिग्रेशन के कोएफिशिएंट्स की व्याख्या करते हैं, तो आप लॉग-ऑड्स स्पेस में काम कर रहे होते हैं।
लॉग लिंक अपेक्षित मान का नेचुरल लॉगरिद्म लेता है:
लॉग लिंक
यही पॉइसन रिग्रेशन उपयोग करता है। लीनियर प्रेडिक्टर कोई भी वास्तविक संख्या हो सकता है, लेकिन जब आप उसे एक्सपोनेंशिएट करके वापस लाते हैं (इन्वर्स), तो भविष्यवाणी हमेशा धनात्मक रहती है। काउंट डेटा के लिए यही चाहिए, क्योंकि नकारात्मक घटनाएँ नहीं हो सकतीं।
GLM तब तक अमूर्त लग सकते हैं जब तक आप उन्हें अपने जाने-पहचाने मॉडलों के रूप में न देखें। लीनियर रिग्रेशन, लॉजिस्टिक रिग्रेशन, और पॉइसन रिग्रेशन सभी GLM हैं। फर्क सिर्फ इतना है कि हर एक डिस्ट्रीब्यूशन और लिंक फंक्शन का अलग संयोजन उपयोग करता है।
लीनियर रिग्रेशन सबसे सरल GLM है। रिस्पॉन्स नॉर्मल डिस्ट्रीब्यूशन का पालन करता है, और लिंक फंक्शन आइडेंटिटी लिंक होता है—यानी कोई ट्रांसफॉर्मेशन नहीं।
GLM के रूप में लीनियर रिग्रेशन
लीनियर प्रेडिक्टर सीधे अपेक्षित आउटकम के बराबर होता है। यही वह GLM है जिसे आप अब तक उपयोग कर रहे थे—बस इसे उसी नाम से नहीं बुला रहे थे।
लॉजिस्टिक रिग्रेशन बाइनरी परिणामों को बाइनोमियल डिस्ट्रीब्यूशन और लॉजिट लिंक के साथ मॉडल करता है।
GLM के रूप में लॉजिस्टिक रिग्रेशन
बाईं ओर घटना के लॉग-ऑड्स हैं। दाईं ओर आपके इनपुट्स का मानक लीनियर संयोजन है। लॉजिट लिंक सुनिश्चित करता है कि भविष्यवाणियाँ 0 और 1 के बीच प्रायिकताओं में मैप हों, चाहे Xβ कितना भी बड़ा या छोटा क्यों न हो जाए।
पॉइसन रिग्रेशन काउंट डेटा को पॉइसन डिस्ट्रीब्यूशन और लॉग लिंक के साथ मॉडल करता है।
GLM के रूप में पॉइसन रिग्रेशन
अपेक्षित काउंट का लॉग लीनियर प्रेडिक्टर के बराबर होता है। यदि आप दोनों तरफ एक्सपोनेंशिएट करें, तो μ = e^(Xβ) मिलता है, जो हमेशा धनात्मक है—काउंट्स के लिए बिल्कुल सही।
GLM, लीनियर रिग्रेशन की तरह ऑर्डिनरी लीस्ट स्क्वेयर्स का उपयोग नहीं करते। इसके बजाय वे मैक्सिमम लाइकलिहुड एस्टीमेशन (MLE) पर निर्भर करते हैं।
विचार सीधा है। MLE उन कोएफिशिएंट्स का सेट ढूंढता है जो चुने हुए डिस्ट्रीब्यूशन के तहत आपके देखे गए डेटा को सबसे अधिक संभावित बनाते हैं। लॉजिस्टिक रिग्रेशन के लिए, यह ऐसे कोएफिशिएंट्स ढूंढता है जो बाइनोमियल मॉडल के हिसाब से देखे गए 0 और 1 को सबसे अधिक संभावित बनाते हैं। पॉइसन रिग्रेशन के लिए, यह ऐसे कोएफिशिएंट्स ढूंढता है जो देखे गए काउंट्स को सबसे अच्छा समझाते हैं।
अधिकांश GLM के लिए कोई क्लोज़्ड-फॉर्म समाधान नहीं होता, इसलिए ऑप्टिमाइज़ेशन इटरेटिव होता है। एल्गोरिथ्म कोएफिशिएंट्स के एक आरंभिक अनुमान से शुरू करता है, फिट का आकलन करता है, उन्हें समायोजित करता है, और तब तक दोहराता है जब तक अनुमान कन्वर्ज न कर जाएँ।
सबसे सामान्य तरीका इटरेटिवली रीवेटेड लीस्ट स्क्वेयर्स (IRLS) है, जो MLE समस्या को वेटेड लीनियर रिग्रेशनों की शृंखला के रूप में ढाल देता है। ग्रेडिएंट-आधारित तरीके भी काम करते हैं, जो तीव्रतम सुधार की दिशा निकालते हैं और उसी ओर कदम बढ़ाते हैं। statsmodels और R का glm() जैसी लाइब्रेरी यह सब परदे के पीछे करती हैं, इसलिए आपको सॉल्वर खुद लागू करने की ज़रूरत नहीं।
ध्यान रखने की बात यह है कि आप डिस्ट्रीब्यूशन और लिंक फंक्शन चुनते हैं, और ऑप्टिमाइज़र सर्वश्रेष्ठ कोएफिशिएंट्स ढूंढता है। यही विचार है—अब देखें यह व्यवहार में कैसे काम करता है।
इस खंड में, मैं उसी डेटासेट का उपयोग करते हुए Python और R दोनों में लॉजिस्टिक और पॉइसन रिग्रेशन से होकर चलूंगा—एक सिम्युलेटेड एम्प्लॉयी एट्रिशन डेटासेट, जिसमें सैलरी, अनुभव के वर्ष, ओवरटाइम घंटे, कर्मचारी ने छोड़ा या नहीं (बाइनरी), और लिए गए बीमार दिनों की संख्या (काउंट) शामिल हैं।
मैं Python में यह डेटासेट बनाऊंगा, और फिर गणनाओं के लिए Python और R दोनों में इसका उपयोग करूंगा:
import numpy as np
import pandas as pd
np.random.seed(42)
n = 500
# Employee dataset
df = pd.DataFrame({
"salary": np.random.normal(55000, 12000, n).astype(int),
"experience_years": np.random.poisson(5, n),
"overtime_hours": np.random.poisson(8, n),
})
# Simulate binary outcome: left the company
prob_left = 1 / (1 + np.exp(-(
-2 + -0.00003 * df["salary"] + -0.05 * df["experience_years"] + 0.12 * df["overtime_hours"]
)))
df["left"] = np.random.binomial(1, prob_left)
# Simulate count outcome: sick days per year
df["sick_days"] = np.random.poisson(
np.exp(1.2 + 0.00001 * df["salary"] + 0.02 * df["overtime_hours"])
)
# Save to use later in R
df.to_csv("data.csv", index=False)
df.head()
नमूना कर्मचारी एट्रिशन डेटासेट
Python आपको GLM के लिए दो मुख्य विकल्प देता है: statsmodels और scikit-learn। यहाँ मैं statsmodels का उपयोग करूंगा क्योंकि यह आपको पूर्ण सांख्यिकीय सारांश देता है—कोएफिशिएंट्स, p-वैल्यूज़, और कॉन्फिडेंस इंटरवल्स सहित। GLM की व्याख्या करते समय इनकी ज़रूरत पड़ेगी।
किसी कर्मचारी के छोड़ने की भविष्यवाणी के लिए लॉजिस्टिक रिग्रेशन ऐसे फिट कर सकते हैं:
import statsmodels.api as sm
X = sm.add_constant(df[["salary", "experience_years", "overtime_hours"]])
logit_model = sm.GLM(df["left"], X, family=sm.families.Binomial())
logit_results = logit_model.fit()
print(logit_results.summary())
GLM लॉजिस्टिक रिग्रेशन परिणाम
मुख्य पंक्ति sm.families.Binomial() है। यह एक ही आर्ग्युमेंट में डिस्ट्रीब्यूशन (बाइनोमियल) और डिफॉल्ट लिंक फंक्शन (लॉजिट) दोनों सेट करता है। जब तक आपको नॉन-डिफॉल्ट लिंक नहीं चाहिए, अलग से लिंक बताने की ज़रूरत नहीं।
अब उसी डेटासेट पर बीमार दिनों की भविष्यवाणी के लिए पॉइसन रिग्रेशन फिट करें:
poisson_model = sm.GLM(df["sick_days"], X, family=sm.families.Poisson())
poisson_results = poisson_model.fit()
print(poisson_results.summary())
GLM पॉइसन रिग्रेशन परिणाम
आपको बस Binomial() को Poisson() से बदलना है और मॉडल पॉइसन डिस्ट्रीब्यूशन के साथ लॉग लिंक का उपयोग करेगा। आउटपुट तालिका एक जैसी दिखेगी, लेकिन व्याख्या बदलेगी क्योंकि लिंक फंक्शन बदला है।
अब मैं ओवरटाइम घंटों के विरुद्ध लॉजिस्टिक रिग्रेशन से भविष्यवाणी की गई प्रायिकताओं को विज़ुअलाइज़ करता हूँ:
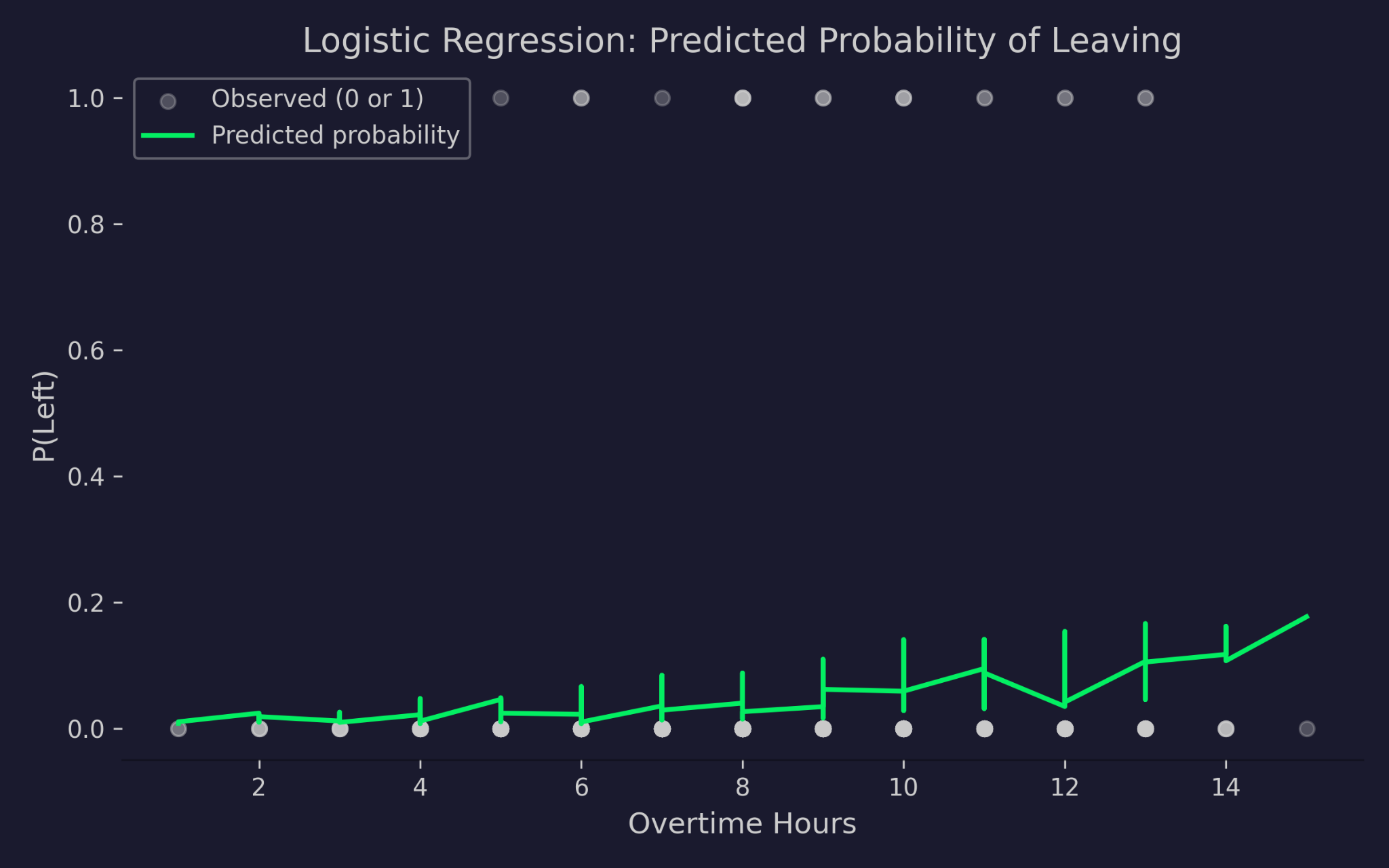
कंपनी छोड़ने की भविष्यवाणी की गई प्रायिकताएँ बनाम ओवरटाइम घंटे
चार्ट में x-अक्ष पर ओवरटाइम घंटे और y-अक्ष पर छोड़ने की प्रायिकता है। ग्रे डॉट्स वास्तविक परिणाम हैं—या तो 0 (रुके) या 1 (छोड़ा)। हरी कर्व मॉडल की भविष्यवाणी की गई प्रायिकता है। जैसे-जैसे ओवरटाइम घंटे बढ़ते हैं, छोड़ने की अनुमानित प्रायिकता बढ़ती है, लेकिन 0 से नीचे या 1 से ऊपर कभी नहीं जाती। यही लॉजिट लिंक का काम है—वह लीनियर प्रेडिक्टर को, इनपुट मान कितने भी चरम हों, वैध प्रायिकता रेंज में समेट देता है।
R का बिल्ट-इन glm() वही लॉजिक अपनाता है, बस सिंटैक्स अलग है। family आर्ग्युमेंट डिस्ट्रीब्यूशन और लिंक फंक्शन सेट करता है, और आप मॉडल को R के फॉर्मूला इंटरफ़ेस से परिभाषित करते हैं।
यही लॉजिस्टिक रिग्रेशन R में इस प्रकार है:
# Read the dataset
df <- read.csv("data.csv")
# Fit logistic regression
logit_model <- glm(left ~ salary + experience_years + overtime_hours,
data = df,
family = binomial(link = "logit"))
summary(logit_model)
R में GLM लॉजिस्टिक रिग्रेशन
फॉर्मूला left ~ salary + experience_years + overtime_hours R को बताता है कि क्या भविष्यवाणी करनी है और किन इनपुट्स का उपयोग करना है। family = binomial(link = "logit") हिस्सा डिस्ट्रीब्यूशन और लिंक सेट करता है। आप इसे छोटा कर family = binomial() भी लिख सकते हैं, क्योंकि बाइनोमियल फैमिली के लिए लॉजिट डिफॉल्ट लिंक है।
पॉइसन रिग्रेशन लगभग वैसा ही है:
poisson_model <- glm(sick_days ~ salary + experience_years + overtime_hours,
data = df,
family = poisson(link = "log"))
summary(poisson_model)
R में GLM पॉइसन रिग्रेशन
आपको बस binomial() को poisson() से बदलना है, रिस्पॉन्स वेरिएबल बदलना है, और काम पूरा।
दोनों भाषाएँ एक ही तरीका अपनाती हैं—आप फैमिली/डिस्ट्रीब्यूशन आर्ग्युमेंट पास करते हैं, जो डिस्ट्रीब्यूशन और उसके डिफॉल्ट लिंक फंक्शन को जोड़ता है:

Python और R में डिस्ट्रीब्यूशन और लिंक बताना
हर फैमिली का एक डिफॉल्ट लिंक होता है, लेकिन आप उसे ओवरराइड कर सकते हैं। Python में आप लिंक ऑब्जेक्ट पास कर सकते हैं: sm.families.Binomial(link=sm.families.links.Probit())। R में बस लिंक आर्ग्युमेंट बदलें: family = binomial(link = "probit")।
अधिकांश उपयोग मामलों में डिफॉल्ट लिंक ही सही विकल्प होता है।
GLM कोएफिशिएंट्स का अर्थ अलग-अलग मॉडल प्रकारों में एक जैसा नहीं होता। लिंक फंक्शन यह बदल देता है कि उन्हें कैसे समझा जाए।
लीनियर रिग्रेशन में व्याख्या आसान है। experience_years पर 500 का कोएफिशिएंट मतलब है कि अनुभव के हर अतिरिक्त साल से भविष्यवाणी की गई सैलरी में 500 की वृद्धि। आइडेंटिटी लिंक का मतलब है कि कोएफिशिएंट्स सीधे आउटकम से मैप होते हैं।
लॉजिस्टिक रिग्रेशन अलग है। लॉजिट लिंक का मतलब है कि कोएफिशिएंट्स लॉग-ऑड्स स्पेस में होते हैं। overtime_hours पर 0.12 का कोएफिशिएंट यह नहीं बताता कि छोड़ने की प्रायिकता 0.12 बढ़ जाती है। इसका मतलब है कि हर अतिरिक्त ओवरटाइम घंटे पर छोड़ने के लॉग-ऑड्स 0.12 बढ़ते हैं। कुछ अधिक व्याख्यात्मक पाने के लिए, कोएफिशिएंट को एक्सपोनेंशिएट करें: e^0.12 ≈ 1.127। यह आपको ऑड्स रेशियो देता है। हर अतिरिक्त ओवरटाइम घंटे पर छोड़ने के ऑड्स लगभग 1.13 गुना हो जाते हैं।
पॉइसन रिग्रेशन के कोएफिशिएंट्स लॉग लिंक से काम करते हैं। overtime_hours पर 0.02 का कोएफिशिएंट मतलब है कि हर अतिरिक्त घंटे पर अपेक्षित काउंट के लॉग में 0.02 की वृद्धि। जब आप इसे एक्सपोनेंशिएट करते हैं: e^0.02 ≈ 1.02, तो आप देखेंगे कि हर अतिरिक्त ओवरटाइम घंटा अपेक्षित बीमार दिनों की संख्या को लगभग 1.02 गुना कर देता है।
पैटर्न यह है कि हमेशा लिंक फंक्शन के इन्वर्स को लागू करके कोएफिशिएंट स्पेस से आउटकम स्पेस में लौटें।
सही GLM चुनना एक सवाल पर आता है: आपका आउटकम वेरिएबल कैसा दिखता है?
यदि आपका आउटकम बाइनरी है (हां/नहीं, 0/1, पास/फेल), तो लॉजिस्टिक रिग्रेशन उपयोग करें। बाइनोमियल डिस्ट्रीब्यूशन, लॉजिट लिंक। यह चर्न प्रेडिक्शन, फ्रॉड डिटेक्शन, रोग वर्गीकरण (है या नहीं है), या कोई मरीज उपचार का जवाब देगा या नहीं—जैसे वर्गीकरण टास्क कवर करता है।
यदि आपका आउटकम काउंट है (किसी समय खिड़की में घटनाओं की संख्या), तो पॉइसन रिग्रेशन उपयोग करें। पॉइसन डिस्ट्रीब्यूशन, लॉग लिंक। यह प्रति घंटे वेबसाइट विज़िट्स या प्रति वर्ष इंश्योरेंस क्लेम की संख्या जैसी समस्याओं पर फिट बैठता है।
यदि आपका आउटकम सतत है और मोटे तौर पर नॉर्मल (रेवेन्यू, टेस्ट स्कोर), तो मानक लीनियर रिग्रेशन पर्याप्त है। नॉर्मल डिस्ट्रीब्यूशन, आइडेंटिटी लिंक। यही वह GLM है जिसे आप पहले से जानते हैं।
हमेशा आउटकम वेरिएबल से शुरू करें, उसे किसी डिस्ट्रीब्यूशन से मिलाएँ, और फिर लिंक फंक्शन अपने-आप तय हो जाएगा।
यहाँ GLM के साथ काम करते समय बचने लायक कुछ आम गलतियाँ हैं।
यह सबसे आम गलती है। यदि आपका आउटकम काउंट है और आप लीनियर रिग्रेशन फिट करते हैं, तो आपको नकारात्मक भविष्यवाणियाँ मिलेंगी। यदि यह बाइनरी है और आप पॉइसन का उपयोग करते हैं, तो मॉडल समझ नहीं आएगा। हमेशा पहले अपने आउटकम वेरिएबल को देखें और उससे मेल खाता डिस्ट्रीब्यूशन चुनें।
लिंक फंक्शन इनपुट्स और आउटपुट के बीच संबंध को ट्रांसफॉर्म करता है। लॉजिस्टिक रिग्रेशन में 0.5 का कोएफिशिएंट यह नहीं कहता कि "प्रायिकता 0.5 बढ़ जाती है।" इसका मतलब है कि लॉग-ऑड्स 0.5 बढ़ते हैं। इस ट्रांसफॉर्मेशन को भूल जाना इफ़ेक्ट साइज और वेरिएबल महत्व के बारे में ग़लत निष्कर्षों तक ले जाता है।
पॉइसन रिग्रेशन के कोएफिशिएंट्स लॉजिस्टिक रिग्रेशन के कोएफिशिएंट्स से तुलनीय नहीं होते, भले ही संख्याएँ समान दिखें। 0.3 का कोएफिशिएंट अलग मायने रखता है, इस पर निर्भर कि वह लॉग लिंक से गुजरा है या लॉजिट लिंक से। हमेशा कोएफिशिएंट्स की व्याख्या उसी विशेष मॉडल के संदर्भ में करें जिसे आप उपयोग कर रहे हैं।
GLM लीनियर रिग्रेशन से अधिक लचीले हैं, लेकिन इनकी भी धारणाएँ हैं। पॉइसन रिग्रेशन मानता है कि औसत वैरिएंस के बराबर है—यदि आपके काउंट डेटा में औसत से कहीं अधिक वैरिएंस है, तो मॉडल के स्टैंडर्ड एरर्स बहुत छोटे होंगे और आपकी p-वैल्यूज़ भ्रामक होंगी। लॉजिस्टिक रिग्रेशन मानता है कि ऑब्ज़र्वेशंस स्वतंत्र हैं।
इसे दूर करने के लिए, कोई भी GLM फिट करने के बाद रेज़िडुअल्स जाँचें और ऐसे पैटर्न देखें जो खराब फिट का संकेत देते हों।
GLM आपको लीनियर रिग्रेशन से आगे जाने का स्ट्रक्चर्ड तरीका देते हैं, जबकि उसके मूल तर्क का पालन करते रहते हैं। इनपुट्स के लीनियर संयोजन का विचार वही रहता है, लेकिन डिस्ट्रीब्यूशन और लिंक फंक्शन उस डेटा के अनुरूप बदलते हैं जिस पर आप काम कर रहे हैं।
GLM के पीछे तीन कंपोनेंट्स हैं। एक बार जब आप सही डिस्ट्रीब्यूशन चुनना, लीनियर प्रेडिक्टर सेट करना, और सही लिंक फंक्शन लागू करना सीख लेते हैं, तो आप एक ही मानसिक मॉडल से बाइनरी आउटकम, काउंट्स, और सतत डेटा संभाल सकते हैं।
सबसे अच्छा अगला कदम है इसे आज़माना। किसी नॉन-नॉर्मल आउटकम वाले डेटासेट को चुनें, Python या R में GLM फिट करें, और लिंक फंक्शन के माध्यम से कोएफिशिएंट्स की व्याख्या करने का अभ्यास करें। किसी ऐसे डेटासेट का उपयोग करें जिसकी आपको परवाह हो, और यहाँ की हर थ्योरी कुछ ही मिनटों में स्पष्ट हो जाएगी।
यदि आप लीनियर रिग्रेशन और GLM से आगे जाना चाहते हैं, तो हमारे Machine Learning Scientist in Python ट्रैक में नामांकन करें। यह आपको 2026 में जॉब-रेडी होने के लिए आवश्यक सभी चीज़ें दिखाता है।
DataCamp के साथ सीखें
course
course
course