
Courses
Đại số tuyến tính cho Khoa học dữ liệu với R
4 giờ
21.2K
Hồi quy tuyến tính là mô hình khởi đầu tuyệt vời, nhưng nó thiếu sót ngay khi dữ liệu của bạn không tuân theo phân phối chuẩn.
Giả sử bạn muốn dự đoán khách hàng có rời bỏ hay không (kết quả có/không). Hồi quy tuyến tính không làm được điều đó. Nó dự đoán giá trị liên tục, nên bạn sẽ nhận các đầu ra như -0.3 hoặc 1.7 cho một thứ chỉ có thể là 0 hoặc 1. Vấn đề tương tự xuất hiện với dữ liệu đếm, như số phiếu hỗ trợ mỗi giờ. Hồi quy tuyến tính có thể dự đoán số đếm âm, điều này vô nghĩa.
Mô hình tuyến tính tổng quát (GLM) khắc phục điều này bằng cách mở rộng hồi quy tuyến tính để xử lý các kiểu kết quả khác nhau. Ý tưởng cốt lõi vẫn vậy - tổ hợp tuyến tính của đầu vào - nhưng linh hoạt để mô hình hóa dữ liệu nhị phân và các phân phối không chuẩn khác.
Trong bài viết này, tôi sẽ phân tích GLM là gì, đi qua ba thành phần cốt lõi của chúng, và hướng dẫn bạn cách fit và diễn giải trong cả Python và R.
Nhưng chính xác thì hồi quy tuyến tính hoạt động thế nào? Đọc hướng dẫn về Hồi quy tuyến tính đơn để hiểu các giả định, chẩn đoán, và cách diễn giải kết quả.
Mô hình tuyến tính tổng quát (GLM) là phần mở rộng của hồi quy tuyến tính, cho phép biến phản hồi tuân theo các phân phối xác suất khác nhau, không chỉ phân phối chuẩn.
Điều cần nhớ ở đây là GLM không phải một mô hình đơn lẻ. Nó là một khung mô hình. Hồi quy tuyến tính, hồi quy logistic và hồi quy Poisson đều là GLM. Mỗi loại dùng một phân phối khác nhau và một cách kết nối đầu vào với đầu ra khác nhau, nhưng tất cả đều theo cùng cấu trúc.
Hồi quy tuyến tính tiêu chuẩn có hai giả định lớn: kết quả của bạn phân phối chuẩn, và phương sai không đổi trên các dự đoán. Nếu các giả định này không đúng, bạn sẽ nhận kết quả vô nghĩa.
Ví dụ, nếu bạn xây dựng mô hình dự đoán người vay có vỡ nợ hay không, kết quả là nhị phân - 0 hoặc 1. Hồi quy tuyến tính không tôn trọng ranh giới đó. Nó có thể dự đoán -0.2 hoặc 1.4, đều là bất khả thi.
Dữ liệu đếm cũng vậy. Nếu bạn dự đoán số ca tái nhập viện mỗi tháng, hồi quy tuyến tính có thể cho ra số âm. Bạn không thể có -3 lần tái nhập viện.
Vấn đề trong cả hai trường hợp không nằm ở tổ hợp tuyến tính của đầu vào - phần đó hoạt động tốt. Vấn đề là cách mô hình ánh xạ các đầu vào tới đầu ra. GLM giải quyết bằng cách thêm một hàm liên kết (link) để biến đổi đầu ra sao cho phù hợp miền giá trị tự nhiên của dữ liệu. Xác suất luôn nằm giữa 0 và 1. Số đếm luôn không âm. Bạn sẽ thấy chi tiết ngay sau đây.
Mỗi GLM được xây từ ba phần: phân phối, bộ dự đoán tuyến tính, và hàm liên kết. Hãy đi qua từng phần.
Thành phần ngẫu nhiên xác định kiểu dữ liệu mà biến phản hồi tạo ra. Nói cách khác, nó chọn phân phối xác suất mô tả kết quả của bạn tốt nhất.
Hồi quy tuyến tính giả định phân phối chuẩn, nên kết quả liên tục và đối xứng quanh trung bình. Nhưng không phải dữ liệu nào cũng vậy.
Nếu kết quả là nhị phân (có/không, 0/1), bạn sẽ dùng phân phối nhị thức (binomial). Nếu bạn mô hình hóa dữ liệu đếm - như số lỗi mỗi ngày - phân phối Poisson phù hợp hơn.
Phân phối bạn chọn sẽ chi phối mọi thứ còn lại trong mô hình.
Thành phần hệ thống là phần bạn đã biết từ hồi quy tuyến tính. Đó là tổ hợp tuyến tính của các biến đầu vào:
Thành phần hệ thống
Trong đó X là ma trận đặc trưng đầu vào và β là véc-tơ hệ số. Bạn nhân mỗi đặc trưng với trọng số của nó và cộng lại.
Phần này không thay đổi giữa các GLM khác nhau. Nói cách khác, dù bạn fit hồi quy logistic hay hồi quy Poisson, bộ dự đoán tuyến tính trông như nhau.
Hàm liên kết kết nối bộ dự đoán tuyến tính với giá trị kỳ vọng của biến phản hồi. Đây là mảnh ghép làm GLM trở nên linh hoạt.
Không có hàm liên kết, bộ dự đoán tuyến tính cho giá trị từ âm vô cực đến dương vô cực. Điều đó ổn với kết quả liên tục, nhưng không phù hợp cho xác suất hay số đếm. Hàm liên kết biến đổi đầu ra sao cho nằm trong khoảng đúng với phân phối bạn chọn.
Ví dụ, hồi quy logistic dùng liên kết logit, ánh xạ bộ dự đoán tuyến tính (có thể là mọi số thực) thành xác suất giữa 0 và 1. Hồi quy Poisson dùng liên kết log, đảm bảo dự đoán luôn dương.
Phương trình GLM đầy đủ kết hợp cả ba thành phần:
Phương trình GLM
Trong đó g() là hàm liên kết và μ là giá trị kỳ vọng của phản hồi. Phân phối xác định μ nghĩa là gì, bộ dự đoán tuyến tính tính Xβ, và hàm liên kết bắc cầu giữa hai phần.
Hàm liên kết quyết định cách bộ dự đoán tuyến tính chuyển thành kết quả. Các kiểu dữ liệu khác nhau cần các phép biến đổi khác nhau, và mỗi loại GLM có một hàm liên kết mặc định ghép với phân phối của nó.
Liên kết đồng nhất là đơn giản nhất - không làm gì cả. Bộ dự đoán tuyến tính bằng với giá trị kỳ vọng của phản hồi:
Liên kết đồng nhất
Đây là những gì hồi quy tuyến tính sử dụng. Đầu vào của bạn cộng lại thành một tổng có trọng số, và tổng đó là dự đoán. Không cần biến đổi vì kết quả có thể nhận mọi giá trị liên tục.
Liên kết logit lấy một xác suất (giữa 0 và 1) và ánh xạ nó lên toàn bộ trục số thực:
Liên kết logit
Đây là những gì hồi quy logistic sử dụng. Bộ dự đoán tuyến tính có thể cho ra bất kỳ giá trị nào từ âm vô cực đến dương vô cực, nhưng sau phép biến đổi ngược, dự đoán luôn nằm giữa 0 và 1. Tỷ số bên trong logarit - μ/(1-μ) - gọi là odds (tỷ số chênh), và logarit của odds là log-odds. Vậy khi bạn diễn giải hệ số hồi quy logistic, bạn đang làm việc trong không gian log-odds.
Liên kết log lấy log tự nhiên của giá trị kỳ vọng:
Liên kết log
Đây là những gì hồi quy Poisson sử dụng. Bộ dự đoán tuyến tính có thể là bất kỳ số thực nào, nhưng sau khi bạn mũ hóa trở lại (biến đổi ngược), dự đoán luôn dương. Đó chính xác là điều bạn cần cho dữ liệu đếm vì không thể có số âm sự kiện.
GLM có thể trừu tượng cho đến khi bạn nhìn chúng như các mô hình bạn đã biết. Hồi quy tuyến tính, hồi quy logistic và hồi quy Poisson đều là GLM. Khác biệt duy nhất là mỗi loại dùng một kết hợp khác nhau giữa phân phối và hàm liên kết.
Hồi quy tuyến tính là GLM đơn giản nhất. Biến phản hồi tuân theo phân phối chuẩn, và hàm liên kết là đồng nhất, tức không có biến đổi nào cả.
Hồi quy tuyến tính như một GLM
Bộ dự đoán tuyến tính bằng trực tiếp với kết quả kỳ vọng. Đây là GLM bạn vẫn dùng bấy lâu, chỉ là không gọi tên như vậy.
Hồi quy logistic mô hình hóa kết quả nhị phân bằng phân phối nhị thức và liên kết logit.
Hồi quy logistic như một GLM
Vế trái là log-odds của sự kiện. Vế phải là tổ hợp tuyến tính tiêu chuẩn của đầu vào. Liên kết logit đảm bảo các dự đoán ánh xạ thành xác suất từ 0 đến 1, bất kể Xβ lớn hay nhỏ thế nào.
Hồi quy Poisson mô hình hóa dữ liệu đếm bằng phân phối Poisson và liên kết log.
Hồi quy Poisson như một GLM
Log của số đếm kỳ vọng bằng với bộ dự đoán tuyến tính. Nếu bạn mũ hóa cả hai vế, bạn được μ = e^(Xβ), luôn dương - chính xác như yêu cầu của dữ liệu đếm.
GLM không dùng bình phương tối thiểu thông thường như hồi quy tuyến tính. Thay vào đó, chúng dựa vào ước lượng hợp lý tối đa (MLE).
Ý tưởng rất trực quan. MLE tìm bộ hệ số khiến dữ liệu quan sát của bạn có xác suất lớn nhất dưới phân phối đã chọn. Với hồi quy logistic, nó tìm hệ số làm cho các giá trị 0 và 1 quan sát được là hợp lý nhất theo mô hình nhị thức. Với hồi quy Poisson, nó tìm hệ số giải thích tốt nhất các số đếm quan sát được.
Hầu hết GLM không có nghiệm dạng đóng, nên tối ưu là lặp. Thuật toán bắt đầu với một ước lượng ban đầu cho hệ số, đánh giá mức độ phù hợp với dữ liệu, điều chỉnh chúng, và lặp lại cho đến khi hội tụ.
Phương pháp phổ biến nhất là bình phương tối thiểu lặp có trọng số (IRLS), chuyển bài toán MLE thành một chuỗi hồi quy tuyến tính có trọng số. Phương pháp dựa trên gradient cũng hoạt động, vì chúng tính hướng cải thiện dốc nhất và bước theo hướng đó. Thư viện như statsmodels và glm() của R xử lý tất cả phía sau, nên bạn không cần tự cài đặt bộ giải.
Điều cần nhớ là bạn chọn phân phối và hàm liên kết, còn bộ tối ưu tìm hệ số tốt nhất. Đó là ý tưởng - giờ tôi sẽ cho bạn thấy cách vận hành trong thực tế.
Trong phần này, tôi sẽ đi qua hồi quy logistic và hồi quy Poisson trong cả Python và R dùng cùng một bộ dữ liệu - bộ dữ liệu nghỉ việc nhân viên mô phỏng với các cột lương, số năm kinh nghiệm, giờ làm thêm, việc nhân viên rời đi (nhị phân), và số ngày nghỉ ốm (đếm).
Tôi sẽ tạo bộ dữ liệu đã đề cập trong Python, sau đó dùng nó để tính toán trong cả Python và R:
import numpy as np
import pandas as pd
np.random.seed(42)
n = 500
# Employee dataset
df = pd.DataFrame({
"salary": np.random.normal(55000, 12000, n).astype(int),
"experience_years": np.random.poisson(5, n),
"overtime_hours": np.random.poisson(8, n),
})
# Simulate binary outcome: left the company
prob_left = 1 / (1 + np.exp(-(
-2 + -0.00003 * df["salary"] + -0.05 * df["experience_years"] + 0.12 * df["overtime_hours"]
)))
df["left"] = np.random.binomial(1, prob_left)
# Simulate count outcome: sick days per year
df["sick_days"] = np.random.poisson(
np.exp(1.2 + 0.00001 * df["salary"] + 0.02 * df["overtime_hours"])
)
# Save to use later in R
df.to_csv("data.csv", index=False)
df.head()
Mẫu bộ dữ liệu nghỉ việc nhân viên
Python cung cấp cho bạn hai lựa chọn chính cho GLM: statsmodels và scikit-learn. Tôi sẽ dùng statsmodels ở đây vì nó cung cấp bản tóm tắt thống kê đầy đủ, gồm hệ số, p-value và khoảng tin cậy. Bạn sẽ cần những thứ này khi diễn giải GLM.
Đây là cách bạn có thể fit hồi quy logistic để dự đoán nhân viên có rời đi hay không:
import statsmodels.api as sm
X = sm.add_constant(df[["salary", "experience_years", "overtime_hours"]])
logit_model = sm.GLM(df["left"], X, family=sm.families.Binomial())
logit_results = logit_model.fit()
print(logit_results.summary())
Kết quả hồi quy logistic bằng GLM
Dòng quan trọng là sm.families.Binomial(). Tham số này thiết lập cả phân phối (nhị thức) và hàm liên kết mặc định (logit) trong một đối số. Bạn không cần chỉ định liên kết riêng trừ khi muốn dùng loại không mặc định.
Giờ hãy fit hồi quy Poisson trên cùng bộ dữ liệu để dự đoán số ngày nghỉ ốm:
poisson_model = sm.GLM(df["sick_days"], X, family=sm.families.Poisson())
poisson_results = poisson_model.fit()
print(poisson_results.summary())
Kết quả hồi quy Poisson bằng GLM
Bạn chỉ cần thay Binomial() bằng Poisson() và mô hình sẽ dùng phân phối Poisson với liên kết log. Bảng đầu ra trông giống nhau, nhưng cách diễn giải thay đổi vì hàm liên kết đã đổi.
Giờ tôi sẽ trực quan hóa xác suất dự đoán từ hồi quy logistic theo giờ làm thêm:
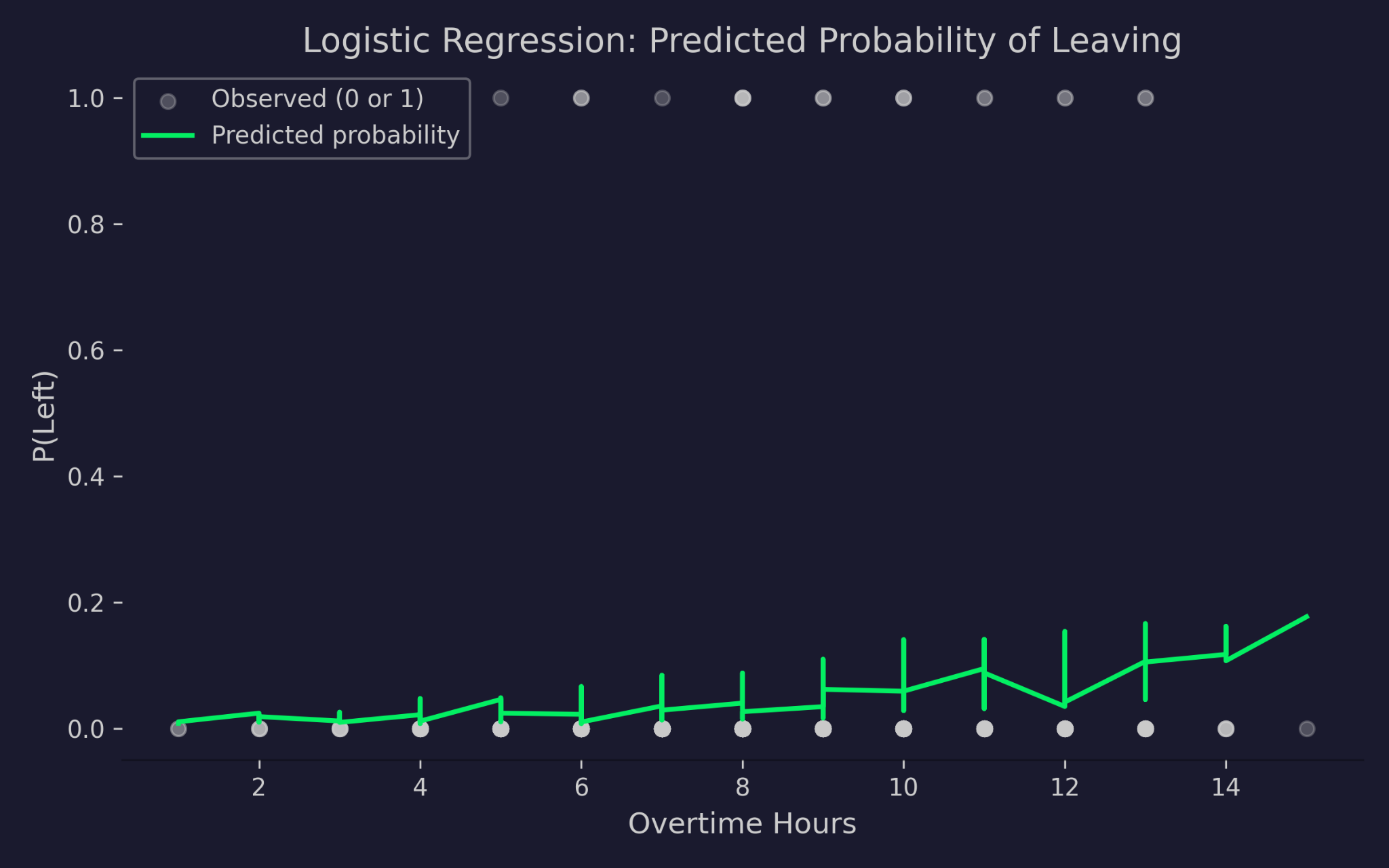
Xác suất dự đoán rời công ty theo giờ làm thêm
Biểu đồ cho thấy giờ làm thêm trên trục x và xác suất rời đi trên trục y. Các chấm xám là kết quả thực - hoặc 0 (ở lại) hoặc 1 (rời đi). Đường cong xanh lục là xác suất do mô hình dự đoán. Khi giờ làm thêm tăng, xác suất dự đoán rời đi tăng, nhưng không bao giờ dưới 0 hoặc vượt 1. Đó là tác dụng của liên kết logit - nó nén bộ dự đoán tuyến tính vào miền xác suất hợp lệ dù giá trị đầu vào cực đoan đến đâu.
Hàm glm() tích hợp sẵn của R tuân theo cùng logic nhưng cú pháp khác. Tham số family thiết lập phân phối và hàm liên kết, và bạn định nghĩa mô hình bằng giao diện công thức của R.
Đây là hồi quy logistic tương tự trong R:
# Read the dataset
df <- read.csv("data.csv")
# Fit logistic regression
logit_model <- glm(left ~ salary + experience_years + overtime_hours,
data = df,
family = binomial(link = "logit"))
summary(logit_model)
Hồi quy logistic bằng GLM trong R
Công thức left ~ salary + experience_years + overtime_hours cho R biết cần dự đoán gì và dùng đầu vào nào. Phần family = binomial(link = "logit") thiết lập phân phối và liên kết. Bạn có thể rút gọn thành family = binomial() vì logit là liên kết mặc định của họ nhị thức.
Hồi quy Poisson gần như tương tự:
poisson_model <- glm(sick_days ~ salary + experience_years + overtime_hours,
data = df,
family = poisson(link = "log"))
summary(poisson_model)
Hồi quy Poisson bằng GLM trong R
Bạn chỉ cần đổi binomial() sang poisson(), đổi biến phản hồi, và xong.
Cả hai ngôn ngữ dùng cùng cách tiếp cận - bạn truyền một tham số family/phân phối kết hợp phân phối và hàm liên kết mặc định của nó:

Chỉ định phân phối và liên kết trong Python và R
Mỗi họ phân phối có một liên kết mặc định, nhưng bạn có thể ghi đè. Trong Python, bạn có thể truyền một đối tượng liên kết: sm.families.Binomial(link=sm.families.links.Probit()). Trong R, chỉ cần đổi tham số link: family = binomial(link = "probit").
Với đa số trường hợp, liên kết mặc định là lựa chọn đúng.
Các hệ số GLM không mang cùng ý nghĩa giữa các loại mô hình khác nhau. Hàm liên kết làm thay đổi cách bạn diễn giải chúng.
Trong hồi quy tuyến tính, diễn giải rất dễ. Một hệ số 500 trên experience_years nghĩa là mỗi năm kinh nghiệm thêm làm tăng 500 đơn vị của giá trị dự đoán. Liên kết đồng nhất khiến hệ số ánh xạ trực tiếp tới kết quả.
Hồi quy logistic thì khác. Liên kết logit khiến hệ số ở trong không gian log-odds. Một hệ số 0.12 trên overtime_hours không có nghĩa xác suất rời đi tăng 0.12. Nó có nghĩa log-odds rời đi tăng 0.12 cho mỗi giờ làm thêm. Để có thứ dễ hiểu hơn, hãy mũ hóa hệ số: e^0.12 ≈ 1.127. Đây là tỷ số chênh (odds ratio). Mỗi giờ làm thêm nhân odds rời đi lên khoảng 1.13 lần.
Hệ số hồi quy Poisson hoạt động qua liên kết log. Một hệ số 0.02 trên overtime_hours nghĩa là mỗi giờ tăng thêm làm tăng log của số đếm kỳ vọng thêm 0.02. Khi bạn mũ hóa: e^0.02 ≈ 1.02, bạn sẽ thấy mỗi giờ làm thêm nhân số ngày nghỉ ốm kỳ vọng lên khoảng 1.02 lần.
Quy luật là luôn áp dụng hàm liên kết ngược để đi từ không gian hệ số quay về không gian kết quả.
Chọn đúng GLM quy về một câu hỏi: biến kết quả của bạn trông như thế nào?
Nếu kết quả là nhị phân (có/không, 0/1, đạt/trượt), dùng hồi quy logistic. Phân phối nhị thức, liên kết logit. Điều này bao phủ các tác vụ phân loại như dự đoán rời bỏ, phát hiện gian lận, phân loại bệnh (có hay không), hoặc bệnh nhân có đáp ứng điều trị hay không.
Nếu kết quả là số đếm (số sự kiện trong một cửa sổ thời gian), dùng hồi quy Poisson. Phân phối Poisson, liên kết log. Phù hợp các bài toán như dự đoán số lượt truy cập website mỗi giờ hoặc số yêu cầu bồi thường bảo hiểm mỗi năm.
Nếu kết quả là liên tục và xấp xỉ chuẩn (doanh thu, điểm kiểm tra), hồi quy tuyến tính tiêu chuẩn hoạt động tốt. Phân phối chuẩn, liên kết đồng nhất. Đây là GLM bạn đã biết.
Luôn bắt đầu từ biến kết quả, ghép nó với một phân phối, rồi hàm liên kết sẽ theo sau.
Dưới đây là một số lỗi thường gặp bạn nên tránh khi làm việc với GLM.
Đây là lỗi phổ biến nhất. Nếu kết quả là số đếm mà bạn fit hồi quy tuyến tính, bạn sẽ nhận dự đoán âm. Nếu là nhị phân mà bạn dùng Poisson, mô hình sẽ vô nghĩa. Luôn xem xét biến kết quả trước và chọn phân phối khớp với nó.
Hàm liên kết biến đổi mối quan hệ giữa đầu vào và đầu ra. Một hệ số 0.5 trong hồi quy logistic không có nghĩa là "xác suất tăng 0.5". Nó có nghĩa log-odds tăng 0.5. Quên mất phép biến đổi sẽ dẫn tới kết luận sai về cỡ hiệu ứng và tầm quan trọng biến.
Các hệ số trong hồi quy Poisson không thể so sánh với hệ số trong hồi quy logistic, ngay cả khi con số trông giống nhau. Một hệ số 0.3 mang ý nghĩa khác nhau tùy thuộc nó đi qua liên kết log hay logit. Luôn diễn giải hệ số trong ngữ cảnh mô hình cụ thể bạn đang dùng.
GLM linh hoạt hơn hồi quy tuyến tính, nhưng vẫn có giả định. Hồi quy Poisson giả định trung bình bằng phương sai - nếu dữ liệu đếm của bạn có phương sai lớn hơn nhiều so với trung bình, sai số chuẩn của mô hình sẽ quá nhỏ và p-value sẽ gây hiểu lầm. Hồi quy logistic giả định các quan sát độc lập.
Để khắc phục, sau khi fit bất kỳ GLM nào, hãy kiểm tra phần dư (residual) và tìm các mẫu gợi ý sự phù hợp kém.
GLM mang đến một cách có cấu trúc để vượt ra ngoài hồi quy tuyến tính nhưng vẫn theo logic nền tảng của nó. Ý tưởng về tổ hợp tuyến tính của đầu vào giữ nguyên, còn phân phối và hàm liên kết thay đổi để phù hợp với dữ liệu bạn đang làm việc.
GLM có ba thành phần. Khi bạn biết cách chọn đúng phân phối, thiết lập bộ dự đoán tuyến tính, và áp dụng hàm liên kết phù hợp, bạn có thể xử lý kết quả nhị phân, số đếm và dữ liệu liên tục với cùng một mô hình tư duy.
Bước tiếp theo tốt nhất là thử ngay. Chọn một bộ dữ liệu có kết quả không chuẩn, fit một GLM trong Python hoặc R, và luyện tập diễn giải hệ số qua hàm liên kết. Hãy dùng bộ dữ liệu bạn quan tâm, và mọi lý thuyết đã bàn sẽ "vào" rất nhanh.
Nếu bạn muốn đi xa hơn hồi quy tuyến tính và GLM, hãy đăng ký lộ trình Nhà khoa học Máy học với Python của chúng tôi. Lộ trình cung cấp mọi thứ bạn cần để sẵn sàng cho công việc vào năm 2026.
Học với DataCamp
Courses
Courses
Courses
blogs
Matt Crabtree
10 phút