
Curso
Álgebra lineal para data science en R
4 h
21.2K
La regresión lineal es un gran primer modelo, pero se queda corta en cuanto tus datos no siguen una distribución normal.
Imagina que quieres predecir si un cliente hará churn (resultado sí o no). La regresión lineal no sabe hacerlo. Predice valores continuos, así que obtendrás salidas como -0.3 o 1.7 para algo que solo puede ser 0 o 1. Pasa lo mismo con datos de conteo, como el número de tickets de soporte por hora. La regresión lineal puede predecir conteos negativos, lo cual no tiene sentido.
Los modelos lineales generalizados (GLM) solucionan esto ampliando la regresión lineal para manejar distintos tipos de resultados. La idea central es la misma —una combinación lineal de entradas— pero con la flexibilidad para modelar datos binarios y otras distribuciones no normales.
En este artículo, te explicaré qué son los GLM, sus tres componentes clave y cómo ajustarlos e interpretarlos tanto en Python como en R.
Pero ¿cómo funciona exactamente la regresión lineal? Lee nuestra guía de regresión lineal simple para conocer sus supuestos y diagnósticos, y cómo interpretar los resultados.
Un modelo lineal generalizado (GLM) es una extensión de la regresión lineal que permite que la variable respuesta siga distintas distribuciones de probabilidad, no solo la normal.
Lo importante aquí es recordar que un GLM no es un único modelo. Es un marco de trabajo. La regresión lineal, la regresión logística y la regresión de Poisson son todos GLM. Cada uno usa una distribución distinta y una forma diferente de conectar entradas y salidas, pero todos siguen la misma estructura.
La regresión lineal estándar hace dos grandes supuestos: que tu resultado sigue una distribución normal y que la varianza se mantiene constante en las predicciones. Si estos supuestos no se cumplen, obtendrás resultados que no tienen sentido.
Por ejemplo, si construyes un modelo para predecir si una persona que solicita un préstamo incumplirá, el resultado es binario: 0 o 1. La regresión lineal no respeta ese límite. Puede predecir -0.2 o 1.4, ambos imposibles.
Con los datos de conteo pasa igual. Si predices el número de reingresos hospitalarios al mes, la regresión lineal puede dar números negativos. No puedes tener -3 reingresos.
El problema en ambos casos no está en la combinación lineal de entradas —esa parte funciona bien—. El problema es cómo el modelo mapea esas entradas a la salida. Los GLM lo resuelven añadiendo una función de enlace que transforma la salida para que encaje en el rango natural de los datos. Las probabilidades permanecen entre 0 y 1. Los conteos se mantienen no negativos. En un momento lo verás con más detalle.
Todo GLM se compone de tres partes: una distribución, un predictor lineal y una función de enlace. Vamos con cada una.
El componente aleatorio define qué tipo de datos produce tu variable respuesta. En otras palabras, elige la distribución de probabilidad que mejor describe tu resultado.
La regresión lineal asume una distribución normal, por lo que el resultado es continuo y simétrico alrededor de la media. Pero no todos los datos funcionan así.
Si tu resultado es binario (sí/no, 0/1), usarías una distribución binomial. Si modelas datos de conteo —como el número de errores por día—, la distribución de Poisson encaja mejor.
La distribución que elijas condiciona todo lo demás en el modelo.
El componente sistemático es la parte que ya conoces de la regresión lineal. Es una combinación lineal de tus variables de entrada:
Componente sistemático
Donde X es tu matriz de características de entrada y β es el vector de coeficientes. Multiplicas cada característica por su peso y las sumas.
Esta parte no cambia entre distintos GLM. Es decir, tanto si ajustas una regresión logística como una de Poisson, el predictor lineal se ve igual.
La función de enlace conecta el predictor lineal con el valor esperado de la variable respuesta. Es la pieza que hace flexibles a los GLM.
Sin una función de enlace, el predictor lineal produce valores desde menos infinito hasta más infinito. Eso está bien para resultados continuos, pero no para probabilidades o conteos. La función de enlace transforma la salida para que quede en el rango adecuado para tu distribución elegida.
Por ejemplo, la regresión logística usa el enlace logit, que mapea un predictor lineal que puede ser cualquier número real a una probabilidad entre 0 y 1. La regresión de Poisson usa el enlace log, que asegura que las predicciones sean siempre positivas.
La ecuación completa de un GLM combina los tres componentes:
Ecuación de GLM
Donde g() es la función de enlace y μ es el valor esperado de la respuesta. La distribución define qué significa μ, el predictor lineal calcula Xβ y la función de enlace conecta ambos.
La función de enlace determina cómo el predictor lineal se convierte en tu resultado. Diferentes tipos de datos necesitan transformaciones distintas, y cada tipo de GLM tiene una función de enlace predeterminada que se asocia a su distribución.
El enlace identidad es el más simple: no hace nada. El predictor lineal es igual al valor esperado de la respuesta:
Enlace identidad
Esto es lo que usa la regresión lineal. Tus entradas se combinan en una suma ponderada, y esa suma es la predicción. No se necesita transformación, porque el resultado puede tomar cualquier valor continuo.
El enlace logit toma una probabilidad (entre 0 y 1) y la mapea a toda la recta real:
Enlace logit
Esto es lo que usa la regresión logística. El predictor lineal puede tomar cualquier valor desde menos hasta más infinito, pero tras la transformación inversa, la predicción siempre queda entre 0 y 1. Ese cociente dentro del logaritmo —μ/(1-μ)— se llama odds (probabilidad a favor), y su logaritmo son los log-odds. Así que, cuando interpretas los coeficientes de una logística, trabajas en el espacio de los log-odds.
El enlace log aplica el logaritmo natural al valor esperado:
Enlace log
Esto es lo que usa la regresión de Poisson. El predictor lineal puede ser cualquier número real, pero al volver a exponentiar (la inversa), la predicción es siempre positiva. Es justo lo que necesitas para datos de conteo, ya que no puede haber eventos negativos.
Los GLM pueden parecer abstractos hasta que los ves como modelos que ya conoces. La regresión lineal, la logística y la de Poisson son todos GLM. La única diferencia es que cada uno usa una combinación distinta de distribución y función de enlace.
La regresión lineal es el GLM más simple. La respuesta sigue una distribución normal y la función de enlace es la identidad, es decir, sin transformación alguna.
Regresión lineal como GLM
El predictor lineal es igual al resultado esperado. Este es el GLM que has estado usando siempre, solo que sin llamarlo así.
La regresión logística modela resultados binarios usando una distribución binomial y un enlace logit.
Regresión logística como GLM
El lado izquierdo son los log-odds del suceso. El derecho es tu combinación lineal estándar de entradas. El enlace logit garantiza que las predicciones se mapeen a probabilidades entre 0 y 1, por muy grande o pequeño que sea Xβ.
La regresión de Poisson modela datos de conteo usando una distribución de Poisson y un enlace log.
Regresión de Poisson como GLM
El logaritmo del conteo esperado es igual al predictor lineal. Si exponencias ambos lados, obtienes μ = e^(Xβ), que siempre es positivo —exactamente lo que requieren los conteos.
Los GLM no usan mínimos cuadrados ordinarios como la regresión lineal. En su lugar, se basan en la estimación por máxima verosimilitud (MLE).
La idea es sencilla. La MLE encuentra el conjunto de coeficientes que hace que tus datos observados sean lo más probables posible bajo la distribución elegida. Para una logística, encuentra los coeficientes que hacen más probables los 0 y 1 observados dado un modelo binomial. Para Poisson, halla los coeficientes que mejor explican los conteos observados.
No hay solución en forma cerrada para la mayoría de los GLM, así que la optimización es iterativa. El algoritmo empieza con una estimación inicial de los coeficientes, evalúa qué tal encajan, los ajusta y repite hasta converger.
El método más común es mínimos cuadrados reponderados iterativos (IRLS), que reformula el problema de MLE como una secuencia de regresiones lineales ponderadas. Los métodos basados en gradiente también funcionan, ya que calculan la dirección de mayor mejora y avanzan hacia ella. Librerías como statsmodels y la función glm() de R hacen todo esto por detrás, así que no necesitas implementar el solver tú mismo.
Quédate con la idea: tú eliges la distribución y la función de enlace, y el optimizador encuentra los mejores coeficientes. Ahora veamos cómo funciona en la práctica.
En esta sección, recorreré la regresión logística y la de Poisson en Python y R usando el mismo conjunto de datos: un dataset simulado de rotación de empleados con columnas de salario, años de experiencia, horas extra, si el empleado se fue (binario) y número de días de baja (conteo).
Crearé el dataset mencionado en Python y luego lo usaré para cálculos tanto en Python como en R:
import numpy as np
import pandas as pd
np.random.seed(42)
n = 500
# Employee dataset
df = pd.DataFrame({
"salary": np.random.normal(55000, 12000, n).astype(int),
"experience_years": np.random.poisson(5, n),
"overtime_hours": np.random.poisson(8, n),
})
# Simulate binary outcome: left the company
prob_left = 1 / (1 + np.exp(-(
-2 + -0.00003 * df["salary"] + -0.05 * df["experience_years"] + 0.12 * df["overtime_hours"]
)))
df["left"] = np.random.binomial(1, prob_left)
# Simulate count outcome: sick days per year
df["sick_days"] = np.random.poisson(
np.exp(1.2 + 0.00001 * df["salary"] + 0.02 * df["overtime_hours"])
)
# Save to use later in R
df.to_csv("data.csv", index=False)
df.head()
Muestra del dataset de rotación de empleados
Python te da dos opciones principales para GLM: statsmodels y scikit-learn. Aquí usaré statsmodels porque te da un resumen estadístico completo, incluidos coeficientes, p-valores e intervalos de confianza. Los necesitarás para interpretar un GLM.
Así puedes ajustar una regresión logística para predecir si una persona se fue de la empresa:
import statsmodels.api as sm
X = sm.add_constant(df[["salary", "experience_years", "overtime_hours"]])
logit_model = sm.GLM(df["left"], X, family=sm.families.Binomial())
logit_results = logit_model.fit()
print(logit_results.summary())
Resultados de la regresión logística con GLM
La línea clave es sm.families.Binomial(). Esta define tanto la distribución (binomial) como la función de enlace por defecto (logit) en un solo argumento. No necesitas especificar el enlace por separado salvo que quieras uno no predeterminado.
Ahora ajustemos una regresión de Poisson en el mismo dataset para predecir días de baja:
poisson_model = sm.GLM(df["sick_days"], X, family=sm.families.Poisson())
poisson_results = poisson_model.fit()
print(poisson_results.summary())
Resultados de la regresión de Poisson con GLM
Solo tienes que cambiar Binomial() por Poisson() y el modelo usa una distribución de Poisson con enlace log. La tabla de salida se ve igual, pero la interpretación cambia porque cambió la función de enlace.
Ahora voy a visualizar las probabilidades predichas de la regresión logística frente a las horas extra:
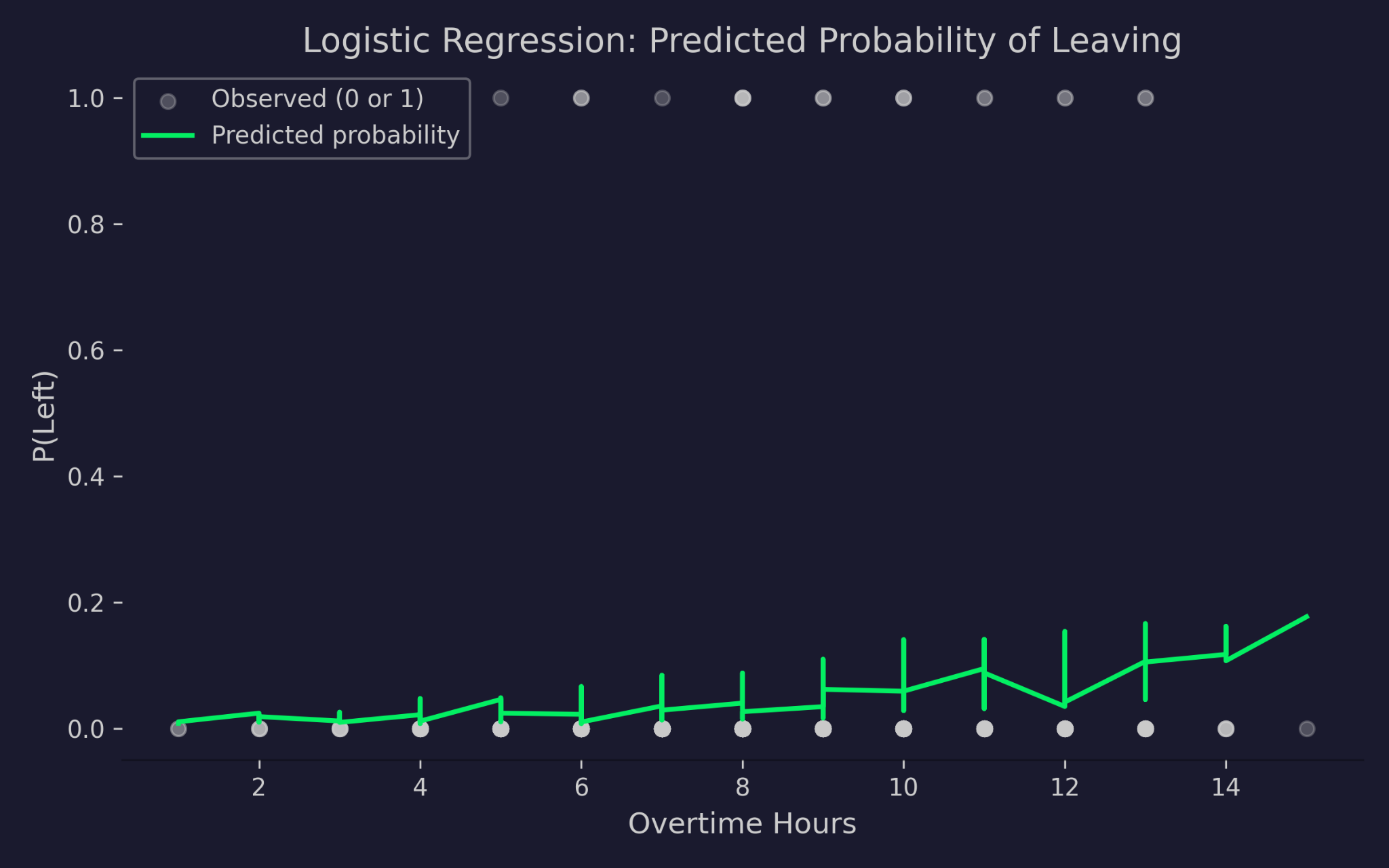
Probabilidades predichas de abandonar la empresa frente a horas extra
El gráfico muestra las horas extra en el eje X frente a la probabilidad de irse en el eje Y. Los puntos grises son los resultados reales —0 (se quedó) o 1 (se fue)—. La curva verde es la probabilidad predicha por el modelo. A medida que aumentan las horas extra, sube la probabilidad prevista de irse, pero nunca baja de 0 ni supera 1. Ahí está trabajando el enlace logit: comprime el predictor lineal a un rango de probabilidad válido, por extremos que sean los valores de entrada.
La función integrada glm() de R sigue la misma lógica, pero con sintaxis distinta. El argumento family define la distribución y la función de enlace, y el modelo se especifica con la interfaz de fórmulas de R.
Aquí tienes la misma logística en R:
# Read the dataset
df <- read.csv("data.csv")
# Fit logistic regression
logit_model <- glm(left ~ salary + experience_years + overtime_hours,
data = df,
family = binomial(link = "logit"))
summary(logit_model)
Regresión logística con GLM en R
La fórmula left ~ salary + experience_years + overtime_hours le indica a R qué predecir y qué entradas usar. La parte family = binomial(link = "logit") define la distribución y el enlace. Puedes abreviarlo como family = binomial() porque logit es el enlace por defecto para la familia binomial.
La regresión de Poisson es prácticamente igual:
poisson_model <- glm(sick_days ~ salary + experience_years + overtime_hours,
data = df,
family = poisson(link = "log"))
summary(poisson_model)
Regresión de Poisson con GLM en R
Solo tienes que cambiar binomial() por poisson(), cambiar la variable respuesta y listo.
Ambos lenguajes usan el mismo enfoque: pasas un argumento de familia/distribución que combina la distribución y su enlace predeterminado:

Especificar distribución y enlace en Python y R
Cada familia tiene un enlace por defecto, pero puedes sobrescribirlo. En Python, puedes pasar un objeto de enlace: sm.families.Binomial(link=sm.families.links.Probit()). En R, cambia el argumento del enlace: family = binomial(link = "probit").
Para la mayoría de casos de uso, el enlace por defecto es la elección adecuada.
Los coeficientes de un GLM no significan lo mismo en todos los tipos de modelo. La función de enlace cambia cómo los interpretas.
En regresión lineal, la interpretación es sencilla. Un coeficiente de 500 en experience_years significa que cada año adicional de experiencia suma 500 al salario predicho. El enlace identidad hace que los coeficientes mapeen directamente al resultado.
La logística es distinta. El enlace logit hace que los coeficientes estén en el espacio de log-odds. Un coeficiente de 0.12 en overtime_hours no significa que la probabilidad de irse suba en 0.12. Significa que los log-odds de irse aumentan 0.12 por cada hora extra adicional. Para algo más interpretable, exponencia el coeficiente: e^0.12 ≈ 1.127. Esto te da un ratio de odds. Cada hora extra multiplica las odds de irse por ~1.13.
Los coeficientes en Poisson funcionan a través del enlace log. Un coeficiente de 0.02 en overtime_hours significa que cada hora adicional aumenta en 0.02 el logaritmo del conteo esperado. Al exponenciar: e^0.02 ≈ 1.02, verás que cada hora extra multiplica el número esperado de días de baja por ~1.02.
La pauta es aplicar siempre la inversa de la función de enlace para pasar del espacio de los coeficientes al espacio del resultado.
Elegir el GLM adecuado se reduce a una pregunta: ¿cómo es tu variable de resultado?
Si tu resultado es binario (sí/no, 0/1, aprobado/suspenso), usa regresión logística. Distribución binomial, enlace logit. Cubre tareas de clasificación como predecir churn, detección de fraude, diagnóstico (tiene o no tiene) o si un paciente responderá a un tratamiento.
Si tu resultado es un conteo (número de eventos en una ventana temporal), usa regresión de Poisson. Distribución de Poisson, enlace log. Encaja en problemas como predecir visitas por hora a una web o siniestros al año.
Si tu resultado es continuo y aproximadamente normal (ingresos, notas), la regresión lineal estándar va perfecta. Distribución normal, enlace identidad. Es el GLM que ya conoces.
Empieza siempre por la variable de resultado, asígnale una distribución y la función de enlace vendrá dada.
Estos son algunos errores habituales que conviene evitar al trabajar con GLM.
Es el error más común. Si tu resultado es un conteo y ajustas una regresión lineal, obtendrás predicciones negativas. Si es binario y usas Poisson, el modelo no tendrá sentido. Mira siempre primero tu variable de resultado y elige la distribución que le corresponde.
La función de enlace transforma la relación entre entradas y salida. Un coeficiente de 0.5 en una logística no significa "la probabilidad sube 0.5". Significa que los log-odds suben 0.5. Olvidar la transformación lleva a conclusiones erróneas sobre tamaños de efecto e importancia de variables.
Los coeficientes en una Poisson no son comparables a los de una logística, aunque los números se parezcan. Un 0.3 significa cosas distintas según pase por un enlace log o por un logit. Interpreta siempre los coeficientes en el contexto del modelo concreto que usas.
Los GLM son más flexibles que la regresión lineal, pero siguen teniendo supuestos. La Poisson asume que la media es igual a la varianza: si tu conteo tiene mucha más varianza que la media, los errores estándar serán demasiado pequeños y los p-valores, engañosos. La logística asume observaciones independientes.
Para evitarlo, tras ajustar cualquier GLM, revisa los residuos y busca patrones que sugieran mal ajuste.
Los GLM te dan una forma estructurada de ir más allá de la regresión lineal manteniendo su lógica fundamental. La idea de la combinación lineal de entradas se mantiene, pero la distribución y la función de enlace cambian para adaptarse a los datos con los que trabajas.
Detrás de los GLM hay tres componentes. Cuando sepas elegir la distribución adecuada, configurar el predictor lineal y aplicar la función de enlace correcta, podrás manejar resultados binarios, conteos y datos continuos con el mismo modelo mental.
El mejor siguiente paso es probarlo. Elige un dataset con un resultado no normal, ajusta un GLM en Python o R y practica la interpretación de los coeficientes a través de la función de enlace. Si usas un conjunto de datos que te importe, toda la teoría vista encajará en cuestión de minutos.
Si quieres ir más allá de la regresión lineal y los GLM, inscríbete en nuestro itinerario Machine Learning Scientist in Python. Te muestra todo lo que necesitas para estar listo para trabajar en 2026.
Aprende con DataCamp
Curso
Curso
Curso