
Kurs
Lineare Algebra für Data Science in R
4 Std.
21.2K
Die lineare Regression ist ein guter Startpunkt, stößt aber sofort an Grenzen, wenn deine Daten nicht normalverteilt sind.
Angenommen, du willst vorhersagen, ob ein Kunde abwandert (Ja/Nein-Ergebnis). Lineare Regression kann das nicht. Sie sagt stetige Werte voraus – du bekommst also Ausgaben wie -0,3 oder 1,7 für etwas, das nur 0 oder 1 sein kann. Dasselbe Problem tritt bei Zähldaten auf, etwa der Anzahl an Support-Tickets pro Stunde. Lineare Regression kann negative Zählwerte liefern – das ist unsinnig.
Generalisierte lineare Modelle (GLMs) beheben das, indem sie die lineare Regression so erweitern, dass unterschiedliche Ergebnistypen möglich sind. Die Grundidee bleibt gleich – eine lineare Kombination der Eingaben –, aber mit der Flexibilität, binäre Daten und andere nicht-normalverteilte Größen zu modellieren.
In diesem Artikel erkläre ich, was GLMs sind, gehe ihre drei Kernkomponenten durch und zeige dir, wie du sie in Python und R schätzt und interpretierst.
Wie genau funktioniert eigentlich lineare Regression? Lies unseren Leitfaden zu Einfacher linearer Regression, um Annahmen, Diagnostik und die Interpretation der Ergebnisse kennenzulernen.
Ein generalisiertes lineares Modell (GLM) ist eine Erweiterung der linearen Regression, bei der die Zielvariable unterschiedlichen Wahrscheinlichkeitsverteilungen folgen kann – nicht nur der Normalverteilung.
Wichtig ist: GLM ist kein einzelnes Modell, sondern ein Framework. Lineare Regression, logistische Regression und Poisson-Regression sind alles GLMs. Sie verwenden jeweils eine andere Verteilung und eine andere Kopplung zwischen Eingabe und Ausgabe, folgen aber derselben Struktur.
Standardmäßige lineare Regression macht zwei starke Annahmen: Dein Outcome ist normalverteilt und die Varianz bleibt über die Vorhersagen hinweg konstant. Wenn das nicht gilt, bekommst du Ergebnisse, die keinen Sinn ergeben.
Wenn du etwa vorhersagst, ob ein Kreditnehmer ausfällt, ist das Ergebnis binär – 0 oder 1. Lineare Regression respektiert diese Grenze nicht. Sie kann -0,2 oder 1,4 vorhersagen – beides unmöglich.
Bei Zähldaten ist es das Gleiche. Wenn du die Anzahl der Wiederaufnahmen ins Krankenhaus pro Monat vorhersagst, kann die lineare Regression negative Zahlen liefern. -3 Wiederaufnahmen gibt es nicht.
Das Problem ist in beiden Fällen nicht die lineare Kombination der Eingaben – die passt. Das Problem ist die Abbildung der Eingaben auf das Ergebnis. GLMs lösen das mit einer Linkfunktion, die das Ergebnis in den natürlichen Wertebereich der Daten transformiert. Wahrscheinlichkeiten bleiben zwischen 0 und 1. Zählwerte bleiben nicht-negativ. Gleich mehr dazu.
Jedes GLM besteht aus drei Teilen: einer Verteilung, einem linearen Prädiktor und einer Linkfunktion. Hier ist, was dahinter steckt.
Die Zufallskomponente definiert, welche Art von Daten deine Zielvariable liefert. Anders gesagt: Sie wählt die Wahrscheinlichkeitsverteilung, die dein Outcome am besten beschreibt.
Lineare Regression setzt eine Normalverteilung voraus, also ist das Ergebnis stetig und symmetrisch um den Mittelwert. Nicht alle Daten verhalten sich so.
Ist dein Outcome binär (Ja/Nein, 0/1), verwendest du eine Binomialverteilung. Modellierst du Zähldaten – etwa die Anzahl der Fehler pro Tag –, passt eine Poisson-Verteilung besser.
Die gewählte Verteilung steuert den Rest des Modells.
Die systematische Komponente kennst du aus der linearen Regression. Es ist eine lineare Kombination deiner Eingabevariablen:
Systematische Komponente
Dabei ist X deine Merkmalematrix und β der Vektor der Koeffizienten. Du multiplizierst jedes Merkmal mit seinem Gewicht und addierst alles auf.
Dieser Teil ändert sich zwischen GLMs nicht. Egal ob du eine logistische oder eine Poisson-Regression schätzt – der lineare Prädiktor sieht gleich aus.
Die Linkfunktion verbindet den linearen Prädiktor mit dem Erwartungswert der Zielvariable. Sie ist der Flexibilitätshebel der GLMs.
Ohne Linkfunktion liefert der lineare Prädiktor Werte von minus unendlich bis plus unendlich. Für stetige Outcomes ist das okay, für Wahrscheinlichkeiten oder Zählungen nicht. Die Linkfunktion transformiert die Ausgabe in den passenden Bereich für deine Verteilung.
Die logistische Regression nutzt zum Beispiel die Logit-Link, die einen beliebigen Realwert auf eine Wahrscheinlichkeit zwischen 0 und 1 abbildet. Die Poisson-Regression verwendet die Log-Link und stellt sicher, dass Vorhersagen immer positiv sind.
Die vollständige GLM-Gleichung kombiniert alle drei Komponenten:
GLM-Gleichung
Dabei ist g() die Linkfunktion und μ der Erwartungswert der Antwort. Die Verteilung definiert, was μ bedeutet, der lineare Prädiktor berechnet Xβ, und die Linkfunktion schlägt die Brücke dazwischen.
Die Linkfunktion bestimmt, wie der lineare Prädiktor auf das Outcome abgebildet wird. Unterschiedliche Datentypen brauchen unterschiedliche Transformationen, und jeder GLM-Typ hat eine Standard-Linkfunktion, die zu seiner Verteilung passt.
Die Identitäts-Link ist die einfachste – sie tut nichts. Der lineare Prädiktor entspricht dem Erwartungswert der Antwort:
Identitäts-Link
Das verwendet die lineare Regression. Deine Eingaben werden zu einer gewichteten Summe kombiniert, und diese Summe ist die Vorhersage. Es braucht keine Transformation, weil das Outcome jeden stetigen Wert annehmen kann.
Die Logit-Link nimmt eine Wahrscheinlichkeit (zwischen 0 und 1) und bildet sie auf die gesamte reelle Achse ab:
Logit-Link
Das ist die Linkfunktion der logistischen Regression. Der lineare Prädiktor kann jeden Wert von minus bis plus unendlich annehmen, aber nach der inversen Transformation liegt die Vorhersage immer zwischen 0 und 1. Das Verhältnis im Logarithmus – μ/(1-μ) – heißt Odds, und der Logarithmus der Odds sind die Log-Odds. Wenn du Koeffizienten der logistischen Regression interpretierst, bewegst du dich also im Log-Odds-Raum.
Die Log-Link nimmt den natürlichen Logarithmus des Erwartungswerts:
Log-Link
Das verwendet die Poisson-Regression. Der lineare Prädiktor kann jeder Realwert sein, aber nach dem Exponenzieren (inverse Transformation) ist die Vorhersage immer positiv. Genau das brauchen Zähldaten, da es keine negativen Ereignisse gibt.
GLMs wirken abstrakt, bis du sie als Modelle erkennst, die du bereits kennst. Lineare Regression, logistische Regression und Poisson-Regression sind alles GLMs. Der Unterschied liegt in der Kombination aus Verteilung und Linkfunktion.
Die lineare Regression ist das einfachste GLM. Die Antwort folgt einer Normalverteilung, und die Linkfunktion ist die Identitäts-Link, also gar keine Transformation.
Lineare Regression als GLM
Der lineare Prädiktor entspricht direkt dem erwarteten Outcome. Dieses GLM hast du vermutlich schon genutzt – nur ohne es so zu nennen.
Die logistische Regression modelliert binäre Outcomes mit einer Binomialverteilung und einer Logit-Link.
Logistische Regression als GLM
Links stehen die Log-Odds des Ereignisses. Rechts steht die gewohnte lineare Kombination der Eingaben. Die Logit-Link stellt sicher, dass Vorhersagen immer als Wahrscheinlichkeiten zwischen 0 und 1 herauskommen – egal wie groß oder klein Xβ wird.
Die Poisson-Regression modelliert Zähldaten mit einer Poisson-Verteilung und einer Log-Link.
Poisson-Regression als GLM
Der Logarithmus des erwarteten Zählwerts entspricht dem linearen Prädiktor. Exponenzierst du beide Seiten, erhältst du μ = e^(Xβ) – das ist immer positiv und damit passend für Zählungen.
GLMs verwenden nicht die Methode der kleinsten Quadrate wie die lineare Regression. Stattdessen setzen sie auf Maximum-Likelihood-Schätzung (MLE).
Die Idee ist simpel: MLE findet die Koeffizienten, die deine beobachteten Daten unter der gewählten Verteilung am wahrscheinlichsten machen. Für die logistische Regression sind das die Koeffizienten, die die beobachteten 0en und 1en unter einem Binomialmodell am wahrscheinlichsten machen. Für die Poisson-Regression sind es die Koeffizienten, die die beobachteten Zählungen am besten erklären.
Für die meisten GLMs gibt es keine geschlossene Lösung, daher läuft die Optimierung iterativ. Der Algorithmus startet mit einem Startwert für die Koeffizienten, bewertet die Anpassung an die Daten, passt an und wiederholt das, bis die Schätzung konvergiert.
Die gängigste Methode ist iteratively reweighted least squares (IRLS), die das MLE-Problem als Sequenz gewichteter linearer Regressionen formuliert. Auch Gradientenverfahren funktionieren, indem sie in Richtung der stärksten Verbesserung gehen. Bibliotheken wie statsmodels und Rs glm() erledigen all das im Hintergrund – du musst den Solver nicht selbst implementieren.
Wichtig ist: Du wählst Verteilung und Linkfunktion, und der Optimierer findet die besten Koeffizienten. So viel zur Idee – jetzt zeige ich dir, wie das in der Praxis aussieht.
In diesem Abschnitt gehe ich die logistische Regression und die Poisson-Regression in Python und R durch – mit demselben Datensatz: einem simulierten Fluktuationsdatensatz mit Gehalt, Berufserfahrung in Jahren, Überstunden, ob die Person gegangen ist (binär) und der Anzahl der genommenen Krankheitstage (Zählwert).
Ich erstelle den Datensatz in Python und nutze ihn dann für Berechnungen in Python und R:
import numpy as np
import pandas as pd
np.random.seed(42)
n = 500
# Employee dataset
df = pd.DataFrame({
"salary": np.random.normal(55000, 12000, n).astype(int),
"experience_years": np.random.poisson(5, n),
"overtime_hours": np.random.poisson(8, n),
})
# Simulate binary outcome: left the company
prob_left = 1 / (1 + np.exp(-(
-2 + -0.00003 * df["salary"] + -0.05 * df["experience_years"] + 0.12 * df["overtime_hours"]
)))
df["left"] = np.random.binomial(1, prob_left)
# Simulate count outcome: sick days per year
df["sick_days"] = np.random.poisson(
np.exp(1.2 + 0.00001 * df["salary"] + 0.02 * df["overtime_hours"])
)
# Save to use later in R
df.to_csv("data.csv", index=False)
df.head()
Beispieldatensatz zur Mitarbeiterfluktuation
In Python hast du zwei Hauptoptionen für GLMs: statsmodels und scikit-learn. Ich nutze hier statsmodels, weil es eine vollständige statistische Zusammenfassung liefert – inklusive Koeffizienten, p-Werten und Konfidenzintervallen. Die brauchst du für die Interpretation eines GLM.
So passt du eine logistische Regression an, um vorherzusagen, ob eine Person das Unternehmen verlässt:
import statsmodels.api as sm
X = sm.add_constant(df[["salary", "experience_years", "overtime_hours"]])
logit_model = sm.GLM(df["left"], X, family=sm.families.Binomial())
logit_results = logit_model.fit()
print(logit_results.summary())
Ergebnisse der GLM-logistischen Regression
Die entscheidende Zeile ist sm.families.Binomial(). Damit legst du Verteilung (binomial) und Standard-Linkfunktion (Logit) in einem Argument fest. Du musst die Linkfunktion nur angeben, wenn du vom Standard abweichen willst.
Jetzt passen wir eine Poisson-Regression an demselben Datensatz an, um Krankheitstage vorherzusagen:
poisson_model = sm.GLM(df["sick_days"], X, family=sm.families.Poisson())
poisson_results = poisson_model.fit()
print(poisson_results.summary())
Ergebnisse der GLM-Poisson-Regression
Du tauschst einfach Binomial() gegen Poisson() aus – das Modell nutzt dann eine Poisson-Verteilung mit Log-Link. Die Ausgabetabelle sieht gleich aus, aber die Interpretation ändert sich, weil die Linkfunktion eine andere ist.
Lass uns nun die vorhergesagten Wahrscheinlichkeiten der logistischen Regression gegen die Überstunden visualisieren:
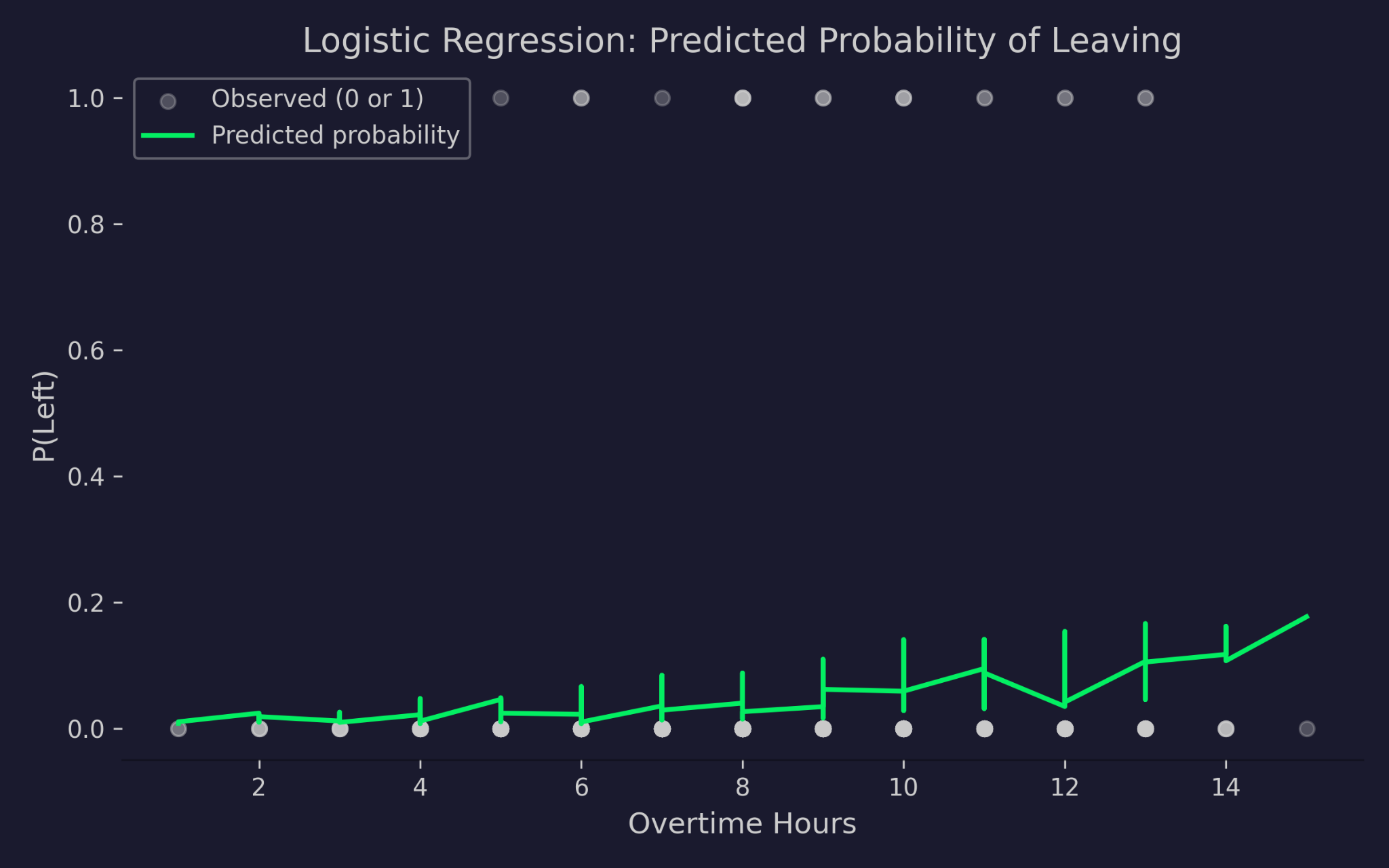
Vorhergesagte Weggangswahrscheinlichkeiten in Abhängigkeit von Überstunden
Das Diagramm zeigt Überstunden auf der x-Achse und die Weggangswahrscheinlichkeit auf der y-Achse. Die grauen Punkte sind die tatsächlichen Outcomes – 0 (geblieben) oder 1 (gegangen). Die grüne Kurve ist die vorhergesagte Wahrscheinlichkeit des Modells. Mit steigenden Überstunden steigt die vorhergesagte Wahrscheinlichkeit, das Unternehmen zu verlassen, aber sie fällt nie unter 0 und überschreitet nie 1. Das ist die Logit-Link in Aktion – sie quetscht den linearen Prädiktor zuverlässig in den gültigen Wahrscheinlichkeitsbereich, egal wie extrem die Eingaben sind.
Rs eingebaute Funktion glm() folgt derselben Logik mit anderer Syntax. Das Argument family legt Verteilung und Linkfunktion fest, und du definierst das Modell über die Formel-Syntax von R.
Hier die gleiche logistische Regression in R:
# Read the dataset
df <- read.csv("data.csv")
# Fit logistic regression
logit_model <- glm(left ~ salary + experience_years + overtime_hours,
data = df,
family = binomial(link = "logit"))
summary(logit_model)
GLM-logistische Regression in R
Die Formel left ~ salary + experience_years + overtime_hours sagt R, was vorhergesagt werden soll und welche Eingaben zu nutzen sind. Der Teil family = binomial(link = "logit") legt Verteilung und Link fest. Du kannst das zu family = binomial() verkürzen, da Logit die Standard-Link der Binomial-Familie ist.
Die Poisson-Regression sieht nahezu identisch aus:
poisson_model <- glm(sick_days ~ salary + experience_years + overtime_hours,
data = df,
family = poisson(link = "log"))
summary(poisson_model)
GLM-Poisson-Regression in R
Du musst nur binomial() gegen poisson() tauschen, die Zielvariable anpassen – und fertig.
Beide Sprachen nutzen denselben Ansatz – du übergibst ein Family-/Verteilungs-Argument, das Verteilung und Standard-Linkfunktion kombiniert:

Verteilung und Link in Python und R festlegen
Jede Family hat eine Standard-Link, aber du kannst sie überschreiben. In Python übergibst du ein Link-Objekt: sm.families.Binomial(link=sm.families.links.Probit()). In R änderst du einfach das Link-Argument: family = binomial(link = "probit").
Für die meisten Anwendungsfälle passt die Standard-Link.
GLM-Koeffizienten bedeuten nicht in jedem Modelltyp dasselbe. Die Linkfunktion bestimmt die Interpretation.
In der linearen Regression ist es einfach. Ein Koeffizient von 500 auf experience_years heißt: Jedes zusätzliche Jahr Erfahrung erhöht die vorhergesagte Größe um 500. Die Identitäts-Link sorgt dafür, dass die Koeffizienten direkt auf das Outcome wirken.
Bei der logistischen Regression ist es anders. Die Logit-Link bedeutet, dass Koeffizienten im Log-Odds-Raum liegen. Ein Koeffizient von 0,12 auf overtime_hours bedeutet nicht, dass die Wahrscheinlichkeit um 0,12 steigt. Er bedeutet, dass die Log-Odds pro zusätzlicher Überstunde um 0,12 steigen. Für eine besser greifbare Größe exponentierst du den Koeffizienten: e^0.12 ≈ 1.127. Das ergibt ein Odds Ratio. Jede weitere Überstunde multipliziert die Chance zu gehen um etwa 1,13.
Poisson-Koeffizienten wirken über die Log-Link. Ein Koeffizient von 0,02 auf overtime_hours heißt: Jede zusätzliche Stunde erhöht den Logarithmus des erwarteten Zählwerts um 0,02. Exponentiert: e^0.02 ≈ 1.02 – jede weitere Überstunde multipliziert die erwarteten Krankheitstage um etwa 1,02.
Die Faustregel: Wende immer die inverse Linkfunktion an, um vom Koeffizientenraum zurück in den Outcome-Raum zu übersetzen.
Die Wahl des passenden GLM hängt an einer Frage: Wie sieht deine Zielvariable aus?
Ist dein Outcome binär (Ja/Nein, 0/1, Bestanden/Nicht bestanden), nutze die logistische Regression. Binomialverteilung, Logit-Link. Das deckt Klassifikationsaufgaben wie Churn-Prediction, Betrugserkennung, Krankheitsklassifikation (hat/hat nicht) oder Therapieansprechen ab.
Ist dein Outcome eine Zählung (Anzahl von Ereignissen in einem Zeitfenster), nutze die Poisson-Regression. Poisson-Verteilung, Log-Link. Das passt etwa für die Vorhersage von Website-Besuchen pro Stunde oder Versicherungsschäden pro Jahr.
Ist dein Outcome stetig und grob normalverteilt (Umsatz, Testergebnisse), funktioniert die lineare Regression wunderbar. Normalverteilung, Identitäts-Link. Das ist das GLM, das du bereits kennst.
Starte immer beim Outcome, wähle dazu die passende Verteilung – die Linkfunktion folgt daraus.
Hier sind typische Stolperfallen, die du bei GLMs vermeiden solltest.
Das ist der häufigste Fehler. Wenn dein Outcome eine Zählung ist und du eine lineare Regression fitst, bekommst du negative Vorhersagen. Ist es binär und du nutzt Poisson, passt das Modell nicht. Schau dir immer zuerst deine Zielvariable an und wähle die passende Verteilung.
Die Linkfunktion transformiert die Beziehung zwischen Eingaben und Outcome. Ein logistischer Regressionskoeffizient von 0,5 heißt nicht „die Wahrscheinlichkeit steigt um 0,5“. Er heißt: Die Log-Odds steigen um 0,5. Wer die Transformation vergisst, zieht falsche Schlüsse zu Effektgrößen und Wichtigkeit von Variablen.
Koeffizienten in einer Poisson-Regression sind nicht mit denen in einer logistischen Regression vergleichbar – auch wenn die Zahlen ähnlich aussehen. Ein Koeffizient von 0,3 bedeutet je nach Log- oder Logit-Link etwas anderes. Interpretiere Koeffizienten immer im Kontext des konkreten Modells.
GLMs sind flexibler als lineare Regression, haben aber dennoch Annahmen. Die Poisson-Regression setzt Gleichheit von Mittelwert und Varianz voraus – hat dein Zähldatensatz deutlich mehr Varianz als den Mittelwert, sind die Standardfehler zu klein und p-Werte irreführend. Die logistische Regression setzt unabhängige Beobachtungen voraus.
Abhilfe: Prüfe nach dem Fit die Residuen und suche nach Mustern, die auf eine schlechte Anpassung hinweisen.
GLMs geben dir einen strukturierten Weg über die lineare Regression hinaus – bei gleicher Grundlogik. Die lineare Kombination der Eingaben bleibt, Verteilung und Linkfunktion passen sich deinen Daten an.
Hinter GLMs stehen drei Bausteine. Wenn du die richtige Verteilung wählst, den linearen Prädiktor aufsetzt und die passende Linkfunktion anwendest, kannst du binäre Outcomes, Zählungen und stetige Daten mit demselben Denkmodell bearbeiten.
Der beste nächste Schritt ist die Praxis. Such dir einen Datensatz mit nicht-normalem Outcome, fit ein GLM in Python oder R und übe, die Koeffizienten über die Linkfunktion zu deuten. Nimm ein Thema, das dich interessiert – dann klickt die Theorie in Minuten.
Wenn du über lineare Regression und GLMs hinausgehen willst, melde dich für unseren Machine Learning Scientist in Python Lernpfad an. Er zeigt dir alles, was du brauchst, um 2026 jobready zu sein.
Lerne mit DataCamp
Kurs
Kurs
Kurs
Tutorial
Mark Pedigo
Tutorial
Matt Crabtree
Tutorial
Derrick Mwiti
Tutorial
Sejal Jaiswal
Tutorial
Laiba Siddiqui
Tutorial
Javier Canales Luna

