course
Linjär algebra för datavetenskap i R
4 timmar
21.2K
Linjär regression är en utmärkt första modell att testa, men den brister så fort dina data inte följer en normalfördelning.
Säg att du vill förutsäga om en kund kommer att lämna (ja eller nej som utfall). Linjär regression kan inte göra det. Den förutsäger kontinuerliga värden, så du får utdata som -0,3 eller 1,7 för något som bara kan vara 0 eller 1. Samma problem uppstår med räkne-data, som antalet supportärenden per timme. Linjär regression kan förutsäga negativa antal, vilket inte är rimligt.
Generaliserade linjära modeller (GLM) löser detta genom att utöka den linjära regressionen så att den hanterar olika typer av utfall. Grundidén är densamma – en linjär kombination av indata – men med flexibiliteten att modellera binära data och andra icke-normala fördelningar.
I den här artikeln går jag igenom vad GLM är, går igenom deras tre kärnkomponenter och visar hur du anpassar och tolkar dem i både Python och R.
Men hur fungerar linjär regression egentligen? Läs vår guide till Enkel linjär regression för att lära dig dess antaganden och diagnostik, och hur du tolkar resultaten.
En generaliserad linjär modell (GLM) är en utökning av linjär regression som tillåter att responsvariabeln följer olika sannolikhetsfördelningar, inte bara normalfördelningen.
Det viktiga att komma ihåg här är att GLM inte är en enskild modell. Det är ett ramverk. Linjär regression, logistisk regression och Poisson-regression är alla GLM:er. Var och en använder en annan fördelning och ett annat sätt att koppla indata till utdata, men de följer samma struktur.
Standardlinjär regression gör två stora antaganden: ditt utfall är normalfördelat och variansen är konstant över förutsägelserna. Om dessa antaganden inte håller får du resultat som inte är vettiga.
Om du till exempel bygger en modell för att förutsäga om en lånesökande kommer att gå i betalningsinställelse är utfallet binärt – 0 eller 1. Linjär regression respekterar inte den gränsen. Den kan förutsäga -0,2 eller 1,4, vilka båda är omöjliga.
Räkne-data har samma problem. Om du förutsäger antalet återinläggningar på sjukhus per månad kan linjär regression ge negativa tal. Du kan inte ha -3 återinläggningar.
Problemet i båda fallen är inte den linjära kombinationen av indata – den delen fungerar bra. Problemet är hur modellen mappar dessa indata till utfallet. GLM löser detta genom att lägga till en länkfunktion som transformerar utfallet så att det passar datats naturliga intervall. Sannolikheter stannar mellan 0 och 1. Antal stannar icke-negativa. Du får se allt om det strax.
Varje GLM byggs av tre delar: en fördelning, en linjär prediktor och en länkfunktion. Låt mig gå igenom var och en.
Slumpkomponenten definierar vilken typ av data din responsvariabel ger upphov till. Med andra ord väljer den den sannolikhetsfördelning som bäst beskriver ditt utfall.
Linjär regression antar en normalfördelning, så utfallet är kontinuerligt och symmetriskt runt medelvärdet. Men alla data fungerar inte så.
Om ditt utfall är binärt (ja/nej, 0/1) använder du en binomialfördelning. Om du modellerar räkne-data – som antalet fel per dag – passar en Poisson-fördelning bättre.
Fördelningen du väljer styr allt annat i modellen.
Den systematiska komponenten är den del du redan känner igen från linjär regression. Det är en linjär kombination av dina indata:
Systematisk komponent
Där X är din matris av indatafunktioner och β är vektorn av koefficienter. Du multiplicerar varje variabel med dess vikt och summerar dem.
Den här delen ändras inte mellan olika GLM:er. Med andra ord, oavsett om du anpassar en logistisk regression eller en Poisson-regression ser den linjära prediktorn likadan ut.
Länkfunktionen kopplar den linjära prediktorn till det förväntade värdet av responsvariabeln. Det är den del som gör GLM flexibla.
Utan en länkfunktion ger den linjära prediktorn värden från minus oändlighet till plus oändlighet. Det är okej för kontinuerliga utfall, men inte för sannolikheter eller antal. Länkfunktionen transformerar utfallet så att det hamnar i rätt intervall för din valda fördelning.
Till exempel använder logistisk regression logit-länken, som mappar en linjär prediktor som kan vara vilket reellt tal som helst till en sannolikhet mellan 0 och 1. Poisson-regression använder log-länken, som ser till att förutsägelser alltid är positiva.
Den fullständiga GLM-ekvationen kombinerar alla tre komponenter:
GLM-ekvation
Där g() är länkfunktionen och μ är det förväntade värdet av responsen. Fördelningen definierar vad μ betyder, den linjära prediktorn beräknar Xβ, och länkfunktionen bygger bron mellan de två.
Länkfunktionen avgör hur den linjära prediktorn omvandlas till ditt utfall. Olika datatyper kräver olika transformationer, och varje GLM-typ har en standardlänkfunktion som paras med sin fördelning.
Identitetslänken är den enklaste – den gör ingenting. Den linjära prediktorn är lika med det förväntade värdet av responsen:
Identitetslänk
Detta är vad linjär regression använder. Dina indata kombineras till en viktad summa, och den summan är förutsägelsen. Ingen transformation behövs, eftersom utfallet kan anta vilket kontinuerligt värde som helst.
Logit-länken tar en sannolikhet (mellan 0 och 1) och mappar den till hela tallinjen:
Logit-länk
Detta är vad logistisk regression använder. Den linjära prediktorn kan ge vilket värde som helst från minus oändlighet till plus oändlighet, men efter den inversa transformationen hamnar förutsägelsen alltid mellan 0 och 1. Förhållandet inuti logaritmen – μ/(1-μ) – kallas oddsen, och logaritmen av oddsen är log-odds. Så när du tolkar koefficienter i logistisk regression arbetar du i log-odds-rymd.
Log-länken tar den naturliga logaritmen av det förväntade värdet:
Log-länk
Detta är vad Poisson-regression använder. Den linjära prediktorn kan vara vilket reellt tal som helst, men efter att du exponentierat tillbaka (inversen) är förutsägelsen alltid positiv. Det är precis vad du behöver för räkne-data eftersom du inte kan ha negativa händelser.
GLM:er kan kännas abstrakta tills du ser dem som modeller du redan känner till. Linjär regression, logistisk regression och Poisson-regression är alla GLM:er. Den enda skillnaden är att varje använder en annan kombination av fördelning och länkfunktion.
Linjär regression är den enklaste GLM:en. Responsen följer en normalfördelning och länkfunktionen är identitetslänken, vilket betyder ingen transformation alls.
Linjär regression som en GLM
Den linjära prediktorn är direkt lika med det förväntade utfallet. Det här är GLM:en du har använt hela tiden, bara utan att kalla den så.
Logistisk regression modellerar binära utfall med en binomialfördelning och en logit-länk.
Logistisk regression som en GLM
Vänster sida är log-oddsen för händelsen. Höger sida är din vanliga linjära kombination av indata. Logit-länken ser till att förutsägelser mappar till sannolikheter mellan 0 och 1, oavsett hur stort eller litet Xβ blir.
Poisson-regression modellerar räkne-data med en Poisson-fördelning och en log-länk.
Poisson-regression som en GLM
Logaritmen av det förväntade antalet är lika med den linjära prediktorn. Om du exponentierar båda sidor får du μ = e^(Xβ), vilket alltid är positivt – precis vad antal kräver.
GLM:er använder inte minsta kvadratmetoden som linjär regression. I stället bygger de på maximum likelihood-estimering (MLE).
Idén är enkel. MLE hittar den uppsättning koefficienter som gör dina observerade data mest sannolika under den valda fördelningen. För en logistisk regression hittar den de koefficienter som gör de observerade 0:orna och 1:orna mest sannolika givet en binomialmodell. För Poisson-regression hittar den de koefficienter som bäst förklarar de observerade antalen.
Det finns ingen sluten formel för de flesta GLM:er, så optimeringen är iterativ. Algoritmen börjar med en initial gissning för koefficienterna, utvärderar hur väl de passar data, justerar dem och upprepar tills skattningarna konvergerar.
Den vanligaste metoden är iterativt viktade minsta kvadrat (IRLS), som omformulerar MLE-problemet som en sekvens av viktade linjära regressioner. Gradientbaserade metoder fungerar också, eftersom de beräknar riktningen för snabbast förbättring och tar steg i den riktningen. Bibliotek som statsmodels och R:s glm() gör allt detta bakom kulisserna, så du behöver inte implementera lösaren själv.
Kom ihåg att du väljer fördelning och länkfunktion, och optimeraren hittar de bästa koefficienterna. Det är idén – nu ska jag visa hur det fungerar i praktiken.
I det här avsnittet går jag igenom logistisk regression och Poisson-regression i både Python och R med samma dataset – ett simulerat dataset över personalomsättning med kolumner för lön, antal års erfarenhet, övertidstimmar, om medarbetaren slutade (binär) och antal sjukdagar (antal).
Jag skapar det nämnda datasetet i Python och använder det sedan för beräkningar i både Python och R:
import numpy as np
import pandas as pd
np.random.seed(42)
n = 500
# Employee dataset
df = pd.DataFrame({
"salary": np.random.normal(55000, 12000, n).astype(int),
"experience_years": np.random.poisson(5, n),
"overtime_hours": np.random.poisson(8, n),
})
# Simulate binary outcome: left the company
prob_left = 1 / (1 + np.exp(-(
-2 + -0.00003 * df["salary"] + -0.05 * df["experience_years"] + 0.12 * df["overtime_hours"]
)))
df["left"] = np.random.binomial(1, prob_left)
# Simulate count outcome: sick days per year
df["sick_days"] = np.random.poisson(
np.exp(1.2 + 0.00001 * df["salary"] + 0.02 * df["overtime_hours"])
)
# Save to use later in R
df.to_csv("data.csv", index=False)
df.head()
Exempeldataset över personalomsättning
Python ger dig två huvudsakliga alternativ för GLM: statsmodels och scikit-learn. Jag använder statsmodels här eftersom det ger en fullständig statistisk sammanfattning, inklusive koefficienter, p-värden och konfidensintervall. Dem behöver du när du tolkar en GLM.
Så här kan du anpassa en logistisk regression för att förutsäga om en medarbetare slutade:
import statsmodels.api as sm
X = sm.add_constant(df[["salary", "experience_years", "overtime_hours"]])
logit_model = sm.GLM(df["left"], X, family=sm.families.Binomial())
logit_results = logit_model.fit()
print(logit_results.summary())
Resultat för GLM logistisk regression
Nyckelraden är sm.families.Binomial(). Detta sätter både fördelningen (binomial) och standardlänkfunktionen (logit) i ett argument. Du behöver inte ange länken separat om du inte vill ha en icke-standard.
Låt oss nu anpassa en Poisson-regression på samma dataset för att förutsäga sjukdagar:
poisson_model = sm.GLM(df["sick_days"], X, family=sm.families.Poisson())
poisson_results = poisson_model.fit()
print(poisson_results.summary())
Resultat för GLM Poisson-regression
Du behöver bara byta Binomial() mot Poisson() så använder modellen en Poisson-fördelning med log-länk. Utdatabordet ser likadant ut, men tolkningen ändras eftersom länkfunktionen ändrades.
Låt mig nu visualisera de förutsagda sannolikheterna från den logistiska regressionen mot övertidstimmar:
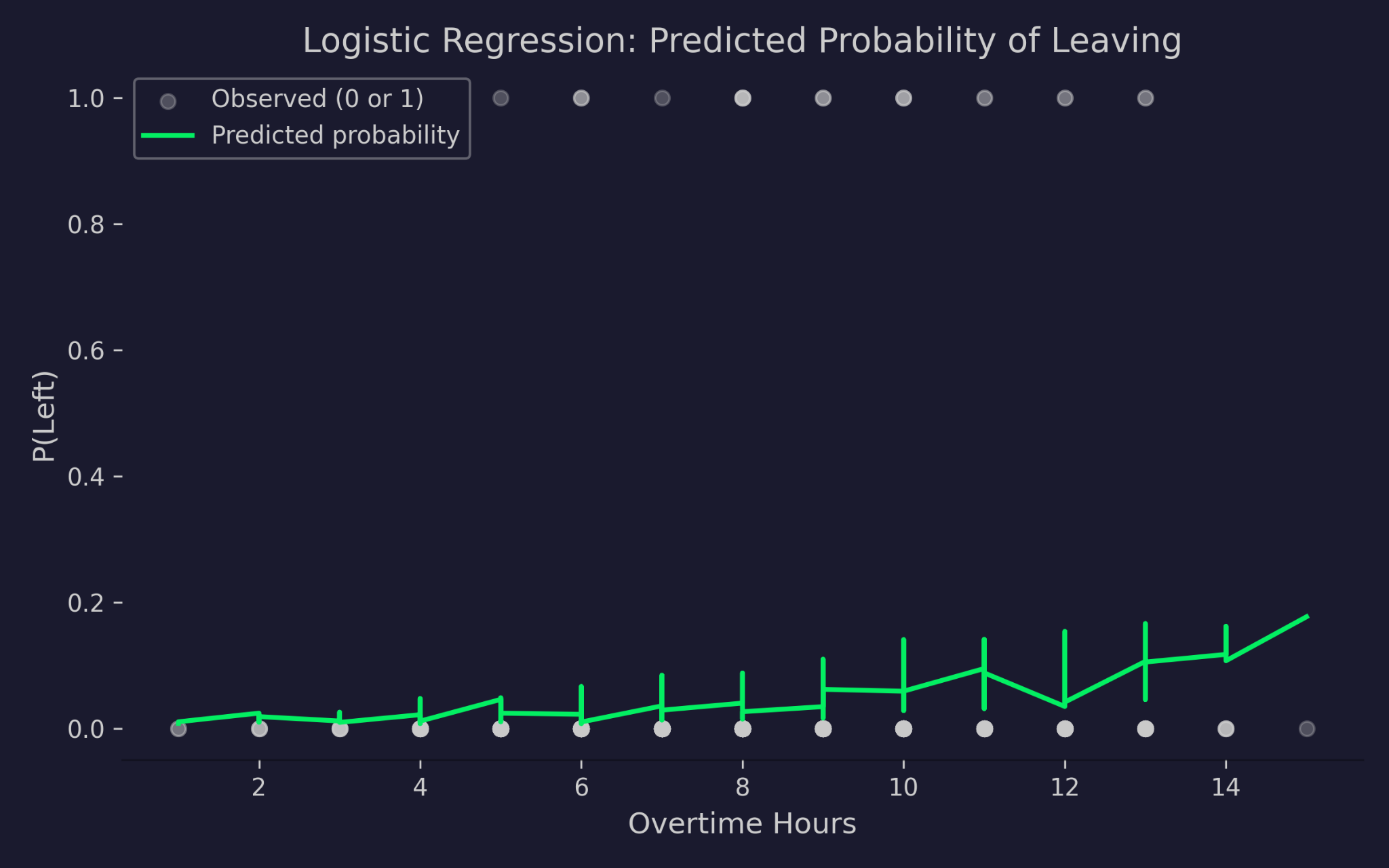
Förutsagda sannolikheter för att lämna företaget mot övertidstimmar
Diagrammet visar övertidstimmar på x-axeln mot sannolikheten att lämna på y-axeln. De grå prickarna är de faktiska utfallen – antingen 0 (stannade) eller 1 (slutade). Den gröna kurvan är modellens förutsagda sannolikhet. När övertidstimmarna ökar stiger den förutsagda sannolikheten att lämna, men den sjunker aldrig under 0 eller överstiger 1. Det är logit-länkfunktionen som arbetar – den pressar ihop den linjära prediktorn till ett giltigt sannolikhetsintervall oavsett hur extrema indata blir.
R:s inbyggda glm()-funktion följer samma logik men med en annan syntax. Argumentet family sätter fördelning och länkfunktion, och du definierar modellen med R:s formelgränssnitt.
Här är samma logistiska regression i R:
# Read the dataset
df <- read.csv("data.csv")
# Fit logistic regression
logit_model <- glm(left ~ salary + experience_years + overtime_hours,
data = df,
family = binomial(link = "logit"))
summary(logit_model)
GLM logistisk regression i R
Formeln left ~ salary + experience_years + overtime_hours talar om för R vad som ska förutsägas och vilka indata som ska användas. Delen family = binomial(link = "logit") sätter fördelning och länk. Du kan förkorta detta till family = binomial() eftersom logit är standardlänken för den binomiala familjen.
Poisson-regression är i stort sett densamma:
poisson_model <- glm(sick_days ~ salary + experience_years + overtime_hours,
data = df,
family = poisson(link = "log"))
summary(poisson_model)
GLM Poisson-regression i R
Du behöver bara byta binomial() mot poisson(), ändra responsvariabeln och du är klar.
Båda språken använder samma angreppssätt – du skickar in ett family/fördelningsargument som kombinerar fördelning och dess standardlänkfunktion:

Anger fördelning och länk i Python och R
Varje familj har en standardlänk, men du kan åsidosätta den. I Python kan du skicka ett länk-objekt: sm.families.Binomial(link=sm.families.links.Probit()). I R ändrar du bara länk-argumentet: family = binomial(link = "probit").
För de flesta användningsfall är standardlänken det rätta valet.
GLM-koefficienter betyder inte samma sak mellan olika modelltyper. Länkfunktionen ändrar hur du tolkar dem.
I linjär regression är tolkningen enkel. En koefficient på 500 för experience_years betyder att varje extra års erfarenhet lägger till 500 på den förutsagda lönen. Identitetslänken innebär att koefficienter mappar direkt till utfallet.
Logistisk regression är annorlunda. Logit-länken innebär att koefficienterna är i log-odds-rymd. En koefficient på 0,12 för overtime_hours betyder inte att sannolikheten att lämna ökar med 0,12. Det betyder att log-oddsen att lämna ökar med 0,12 för varje extra övertidstimme. För att få något mer tolkbart, exponentiera koefficienten: e^0.12 ≈ 1.127. Det ger dig ett odds-förhållande. Varje extra övertidstimme multiplicerar oddsen att lämna med cirka 1,13.
Poisson-regressionskoefficienter verkar via log-länken. En koefficient på 0,02 för overtime_hours betyder att varje extra timme ökar logaritmen av det förväntade antalet med 0,02. När du exponentierar den: e^0.02 ≈ 1.02, ser du att varje extra övertidstimme multiplicerar det förväntade antalet sjukdagar med cirka 1,02.
Mönstret är att alltid tillämpa inversen av länkfunktionen för att gå från koefficientrymden tillbaka till utfallsrymden.
Att välja rätt GLM handlar om en fråga: hur ser din utfallsvariabel ut?
Om ditt utfall är binärt (ja/nej, 0/1, godkänt/underkänt), använd logistisk regression. Binomialfördelning, logit-länk. Detta täcker klassificeringsuppgifter som att förutsäga avhopp, bedrägeriupptäckt, sjukdomsklassificering (har eller har inte) eller om en patient kommer att svara på behandling.
Om ditt utfall är ett antal (antal händelser i ett tidsfönster), använd Poisson-regression. Poisson-fördelning, log-länk. Detta passar problem som att förutsäga antalet webbplatsbesök per timme eller försäkringsanspråk per år.
Om ditt utfall är kontinuerligt och ungefär normalfördelat (intäkter, provresultat) fungerar standardlinjär regression utmärkt. Normalfördelning, identitetslänk. Det här är GLM:en du redan kan.
Börja alltid med utfallsvariabeln, matcha den med en fördelning och sedan följer länkfunktionen.
Här är några vanliga misstag du bör undvika när du arbetar med GLM:er.
Detta är det vanligaste misstaget. Om ditt utfall är ett antal och du anpassar en linjär regression får du negativa förutsägelser. Om det är binärt och du använder Poisson kommer modellen inte att vara meningsfull. Titta alltid på din utfallsvariabel först och välj fördelningen som matchar den.
Länkfunktionen transformerar relationen mellan indata och utdata. En logistisk regressionskoefficient på 0,5 betyder inte ”sannolikheten ökar med 0,5”. Det betyder att log-oddsen ökar med 0,5. Att glömma transformationen leder till fel slutsatser om effektstorlekar och variabelbetydelse.
Koefficienter i en Poisson-regression är inte jämförbara med koefficienter i en logistisk regression, även om siffrorna ser liknande ut. En koefficient på 0,3 betyder olika saker beroende på om den passerar genom en log-länk eller en logit-länk. Tolka alltid koefficienter i kontexten av den specifika modell du använder.
GLM:er är mer flexibla än linjär regression, men de har fortfarande antaganden. Poisson-regression antar att medelvärdet är lika med variansen – om dina räkne-data har mycket större varians än medelvärdet blir modellens standardfel för små och dina p-värden missvisande. Logistisk regression antar att observationer är oberoende.
För att hantera detta, kontrollera residualerna efter att du anpassat en GLM och leta efter mönster som tyder på dålig passform.
GLM:er ger dig ett strukturerat sätt att gå bortom linjär regression men ändå följa dess grundläggande logik. Idén om en linjär kombination av indata är densamma, men fördelningen och länkfunktionen ändras för att passa de data du arbetar med.
Det finns tre komponenter bakom GLM:er. När du vet hur du väljer rätt fördelning, sätter upp den linjära prediktorn och tillämpar rätt länkfunktion kan du hantera binära utfall, antal och kontinuerliga data med samma mentala modell.
Det bästa nästa steget är att prova. Välj ett dataset med ett icke-normalt utfall, anpassa en GLM i Python eller R och öva på att tolka koefficienterna genom länkfunktionen. Använd ett dataset du bryr dig om, så kommer all teori som diskuterats att falla på plats på några minuter.
Om du vill gå bortom linjär regression och GLM:er, anmäl dig till vår Machine Learning Scientist in Python-spår. Det visar dig allt du behöver för att vara jobbklar 2026.
Lär dig med DataCamp
course
course
course