
Curso
Álgebra Linear para Data Science em R
4 h
21.2K
A regressão linear é um ótimo primeiro modelo para testar, mas falha no momento em que seus dados não seguem uma distribuição normal.
Digamos que você queira prever se um cliente vai churnar (resultado sim ou não). A regressão linear não sabe fazer isso. Ela prevê valores contínuos, então você acaba com saídas como -0,3 ou 1,7 para algo que só pode ser 0 ou 1. O mesmo problema aparece com dados de contagem, como o número de chamados de suporte por hora. A regressão linear pode prever contagens negativas, o que não faz sentido.
Os modelos lineares generalizados (GLMs) resolvem isso ao estender a regressão linear para lidar com diferentes tipos de desfechos. A ideia central é a mesma — uma combinação linear de entradas — mas com a flexibilidade de modelar dados binários e outras distribuições não normais.
Neste artigo, vou explicar o que são GLMs, passar pelos seus três componentes principais e mostrar como ajustar e interpretar esses modelos em Python e R.
Mas como exatamente funciona a regressão linear? Leia nosso guia de regressão linear simples para entender suas suposições e diagnósticos e como interpretar os resultados.
Um modelo linear generalizado (GLM) é uma extensão da regressão linear que permite que a variável resposta siga diferentes distribuições de probabilidade, não apenas a normal.
A principal coisa a lembrar é que GLM não é um único modelo. É um framework. Regressão linear, regressão logística e regressão de Poisson são todos GLMs. Cada um usa uma distribuição diferente e uma maneira diferente de conectar entradas a saídas, mas todos seguem a mesma estrutura.
A regressão linear padrão faz duas grandes suposições: seu desfecho é normalmente distribuído e a variância permanece constante nas previsões. Se essas suposições não se mantêm, você terá resultados que não fazem sentido.
Por exemplo, se você estiver construindo um modelo para prever se um solicitante de empréstimo vai dar default, o desfecho é binário — 0 ou 1. A regressão linear não respeita esse limite. Ela pode prever -0,2 ou 1,4, ambos impossíveis.
Dados de contagem têm o mesmo problema. Se você estiver prevendo o número de readmissões hospitalares por mês, a regressão linear pode gerar números negativos. Não existe -3 readmissões.
O problema em ambos os casos não é a combinação linear das entradas — essa parte funciona bem. O problema é como o modelo mapeia essas entradas para a saída. Os GLMs resolvem isso adicionando uma função de ligação (link) que transforma a saída para se ajustar ao intervalo natural dos dados. Probabilidades ficam entre 0 e 1. Contagens permanecem não negativas. Já já você vai ver como isso funciona.
Todo GLM é construído a partir de três partes: uma distribuição, um preditor linear e uma função de ligação. Vamos a cada uma delas.
O componente aleatório define que tipo de dados sua variável resposta gera. Em outras palavras, escolhe a distribuição de probabilidade que melhor descreve seu desfecho.
A regressão linear assume distribuição normal, então o desfecho é contínuo e simétrico em torno da média. Mas nem todos os dados funcionam assim.
Se seu desfecho é binário (sim/não, 0/1), você usaria uma distribuição binomial. Se estiver modelando dados de contagem — como o número de erros por dia — uma distribuição de Poisson é mais adequada.
A distribuição que você escolhe controla todo o resto no modelo.
O componente sistemático é a parte que você já conhece da regressão linear. É uma combinação linear das variáveis de entrada:
Componente sistemático
Onde X é sua matriz de features de entrada e β é o vetor de coeficientes. Você multiplica cada variável pelo seu peso e soma tudo.
Essa parte não muda entre diferentes GLMs. Ou seja, seja ajustando uma regressão logística ou uma regressão de Poisson, o preditor linear é o mesmo.
A função de ligação conecta o preditor linear ao valor esperado da variável resposta. É a peça que torna os GLMs flexíveis.
Sem uma função de ligação, o preditor linear gera valores de menos infinito a mais infinito. Isso é ok para desfechos contínuos, mas não para probabilidades ou contagens. A função de ligação transforma a saída para que ela fique no intervalo correto da distribuição escolhida.
Por exemplo, a regressão logística usa o link logit, que mapeia um preditor linear que pode ser qualquer número real para uma probabilidade entre 0 e 1. A regressão de Poisson usa o link log, garantindo previsões sempre positivas.
A equação completa do GLM combina os três componentes:
Equação do GLM
Onde g() é a função de ligação e μ é o valor esperado da resposta. A distribuição define o que μ significa, o preditor linear calcula Xβ e a função de ligação faz a ponte entre os dois.
A função de ligação determina como o preditor linear se converte no seu desfecho. Diferentes tipos de dados precisam de transformações diferentes, e cada tipo de GLM tem um link padrão que combina com sua distribuição.
O link identidade é o mais simples — ele não faz nada. O preditor linear é igual ao valor esperado da resposta:
Link identidade
É o que a regressão linear usa. Suas entradas se combinam em uma soma ponderada, e essa soma é a previsão. Não há transformação necessária, porque o desfecho pode assumir qualquer valor contínuo.
O link logit pega uma probabilidade (entre 0 e 1) e a mapeia para toda a reta real:
Link logit
É o que a regressão logística usa. O preditor linear pode gerar qualquer valor de menos a mais infinito, mas após a transformação inversa, a previsão sempre fica entre 0 e 1. A razão dentro do logaritmo — μ/(1-μ) — é chamada de odds (chance), e o logaritmo das odds é o log-odds. Então, ao interpretar coeficientes de regressão logística, você está no espaço de log-odds.
O link log aplica o logaritmo natural ao valor esperado:
Link log
É o que a regressão de Poisson usa. O preditor linear pode ser qualquer número real, mas após a exponenciação (a inversa), a previsão é sempre positiva. É exatamente o que você precisa para dados de contagem, já que não existem eventos negativos.
GLMs podem parecer abstratos até você vê-los como modelos que já conhece. Regressão linear, regressão logística e regressão de Poisson são todos GLMs. A única diferença é que cada um usa uma combinação diferente de distribuição e função de ligação.
A regressão linear é o GLM mais simples. A resposta segue uma distribuição normal e a função de ligação é a identidade, ou seja, sem transformação.
Regressão linear como um GLM
O preditor linear é igual ao desfecho esperado. Este é o GLM que você já vinha usando, só não chamava assim.
A regressão logística modela desfechos binários usando uma distribuição binomial e um link logit.
Regressão logística como um GLM
O lado esquerdo é o log-odds do evento. O lado direito é sua combinação linear padrão das entradas. O link logit garante que as previsões virem probabilidades entre 0 e 1, não importa o quão grande ou pequeno fique Xβ.
A regressão de Poisson modela dados de contagem usando uma distribuição de Poisson e um link log.
Regressão de Poisson como um GLM
O log da contagem esperada é igual ao preditor linear. Se você exponenciar ambos os lados, terá μ = e^(Xβ), que é sempre positivo — exatamente o que contagens exigem.
GLMs não usam mínimos quadrados ordinários como a regressão linear. Em vez disso, eles se baseiam em máxima verossimilhança (MLE).
A ideia é simples. A MLE encontra o conjunto de coeficientes que torna seus dados observados mais prováveis sob a distribuição escolhida. Para uma regressão logística, encontra os coeficientes que tornam os 0s e 1s observados mais prováveis dado um modelo binomial. Para a regressão de Poisson, encontra os coeficientes que melhor explicam as contagens observadas.
Não há solução em forma fechada para a maioria dos GLMs, então a otimização é iterativa. O algoritmo começa com um chute inicial para os coeficientes, avalia o ajuste aos dados, ajusta-os e repete até que as estimativas convirjam.
O método mais comum é o mínimos quadrados reponderados iterativos (IRLS), que reconfigura o problema de MLE como uma sequência de regressões lineares ponderadas. Métodos baseados em gradiente também funcionam, pois calculam a direção de maior melhoria e avançam nessa direção. Bibliotecas como statsmodels e a função glm() do R fazem tudo isso por baixo dos panos, então você não precisa implementar o solucionador.
O que você precisa lembrar é: você escolhe a distribuição e o link, e o otimizador encontra os melhores coeficientes. Essa é a ideia — agora deixa eu te mostrar isso na prática.
Nesta seção, vou passar por regressão logística e de Poisson em Python e R usando o mesmo dataset — um conjunto simulado de desligamento de funcionários com colunas para salário, anos de experiência, horas extras, se o funcionário saiu (binário) e número de dias de atestado (contagem).
Vou criar o dataset mencionado em Python e depois usá-lo para cálculos em Python e R:
import numpy as np
import pandas as pd
np.random.seed(42)
n = 500
# Employee dataset
df = pd.DataFrame({
"salary": np.random.normal(55000, 12000, n).astype(int),
"experience_years": np.random.poisson(5, n),
"overtime_hours": np.random.poisson(8, n),
})
# Simulate binary outcome: left the company
prob_left = 1 / (1 + np.exp(-(
-2 + -0.00003 * df["salary"] + -0.05 * df["experience_years"] + 0.12 * df["overtime_hours"]
)))
df["left"] = np.random.binomial(1, prob_left)
# Simulate count outcome: sick days per year
df["sick_days"] = np.random.poisson(
np.exp(1.2 + 0.00001 * df["salary"] + 0.02 * df["overtime_hours"])
)
# Save to use later in R
df.to_csv("data.csv", index=False)
df.head()
Sample employee attrition dataset
Python oferece duas opções principais para GLMs: statsmodels e scikit-learn. Vou usar statsmodels aqui porque ele fornece um resumo estatístico completo, incluindo coeficientes, valores-p e intervalos de confiança. Você vai precisar disso ao interpretar um GLM.
Veja como ajustar uma regressão logística para prever se um funcionário saiu:
import statsmodels.api as sm
X = sm.add_constant(df[["salary", "experience_years", "overtime_hours"]])
logit_model = sm.GLM(df["left"], X, family=sm.families.Binomial())
logit_results = logit_model.fit()
print(logit_results.summary())
GLM logistic regression results
A linha-chave é sm.families.Binomial(). Ela define tanto a distribuição (binomial) quanto o link padrão (logit) em um único argumento. Você não precisa especificar o link separadamente, a menos que queira um não padrão.
Agora vamos ajustar uma regressão de Poisson no mesmo dataset para prever dias de atestado:
poisson_model = sm.GLM(df["sick_days"], X, family=sm.families.Poisson())
poisson_results = poisson_model.fit()
print(poisson_results.summary())
GLM Poisson regression results
Basta trocar Binomial() por Poisson() e o modelo passa a usar uma distribuição de Poisson com link log. A tabela de saída parece a mesma, mas a interpretação muda porque o link mudou.
Agora, vamos visualizar as probabilidades previstas pela regressão logística em função das horas extras:
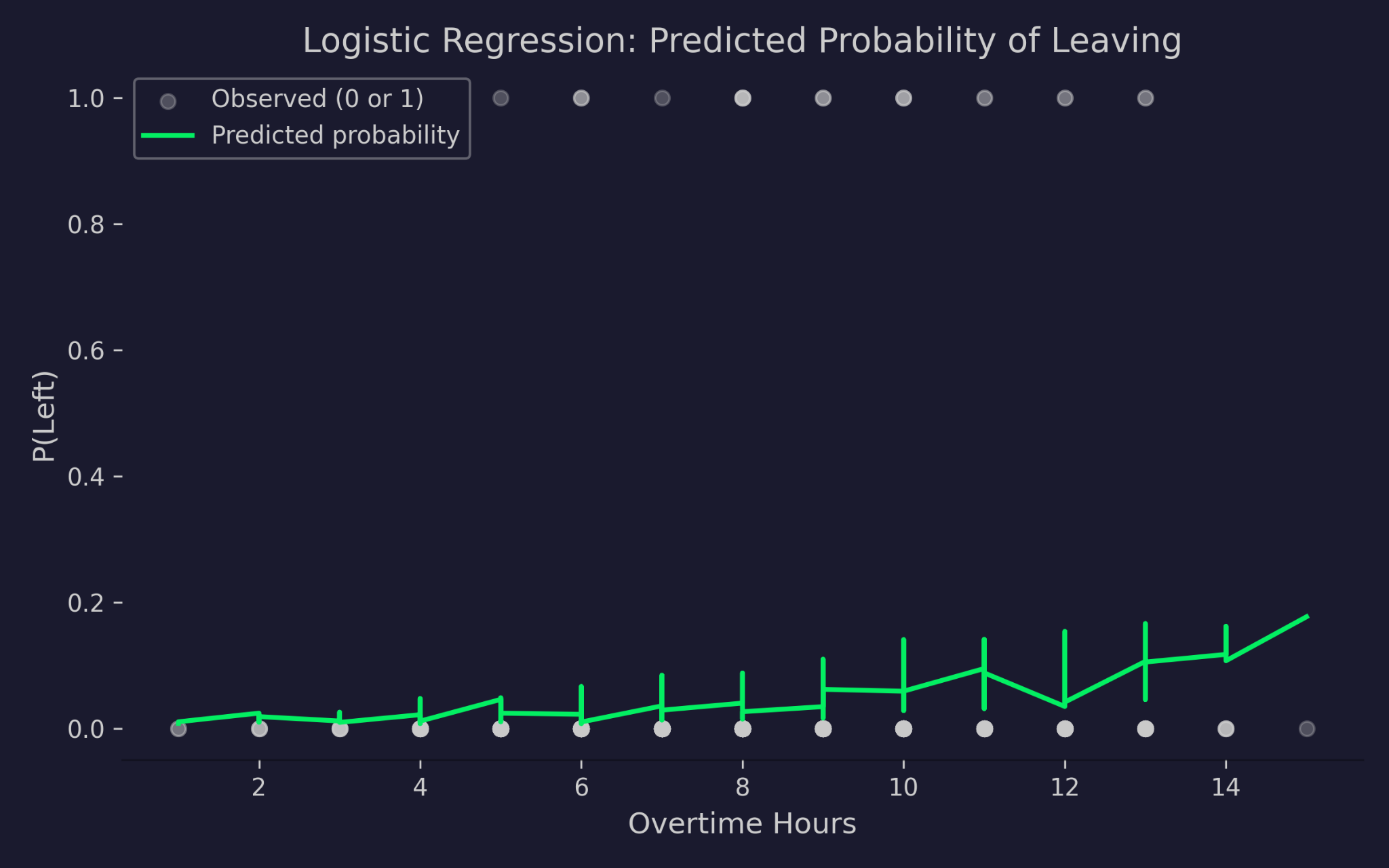
Probabilidades previstas de sair da empresa em função das horas extras
O gráfico mostra horas extras no eixo x e a probabilidade de sair no eixo y. Os pontos cinzas são os resultados reais — 0 (permaneceu) ou 1 (saiu). A curva verde é a probabilidade prevista pelo modelo. Conforme as horas extras aumentam, a probabilidade prevista de sair cresce, mas nunca fica abaixo de 0 nem acima de 1. Esse é o link logit em ação — ele comprime o preditor linear para um intervalo de probabilidade válido, por mais extremos que sejam os valores de entrada.
A função glm() nativa do R segue a mesma lógica, mas com sintaxe diferente. O argumento family define a distribuição e o link, e você especifica o modelo com a interface de fórmulas do R.
Aqui está a mesma regressão logística em R:
# Read the dataset
df <- read.csv("data.csv")
# Fit logistic regression
logit_model <- glm(left ~ salary + experience_years + overtime_hours,
data = df,
family = binomial(link = "logit"))
summary(logit_model)
GLM logistic regression in R
A fórmula left ~ salary + experience_years + overtime_hours diz ao R o que prever e quais entradas usar. A parte family = binomial(link = "logit") define a distribuição e o link. Você pode encurtar para family = binomial() já que logit é o link padrão da família binomial.
A regressão de Poisson é praticamente a mesma coisa:
poisson_model <- glm(sick_days ~ salary + experience_years + overtime_hours,
data = df,
family = poisson(link = "log"))
summary(poisson_model)
GLM Poisson regression in R
Você só precisa trocar binomial() por poisson(), mudar a variável resposta e pronto.
As duas linguagens usam a mesma abordagem — você passa um argumento de família/distribuição que combina a distribuição e seu link padrão:

Especificando distribuição e link em Python e R
Cada família tem um link padrão, mas você pode sobrescrevê-lo. Em Python, você pode passar um objeto link: sm.families.Binomial(link=sm.families.links.Probit()). Em R, basta mudar o argumento do link: family = binomial(link = "probit").
Para a maioria dos casos, o link padrão é a melhor escolha.
Coeficientes de GLM não significam a mesma coisa entre tipos de modelos. A função de ligação muda como você os interpreta.
Na regressão linear, a interpretação é simples. Um coeficiente de 500 em experience_years significa que cada ano extra de experiência adiciona 500 ao salário previsto. O link identidade faz com que os coeficientes mapeiem diretamente para o desfecho.
Na regressão logística é diferente. O link logit significa que os coeficientes estão no espaço de log-odds. Um coeficiente de 0,12 em overtime_hours não significa que a probabilidade de sair aumenta 0,12. Significa que o log-odds de sair aumenta 0,12 para cada hora extra adicional. Para algo mais interpretável, exponencie o coeficiente: e^0.12 ≈ 1.127. Isso dá a razão de chances (odds ratio). Cada hora extra multiplica as chances de sair por cerca de 1,13.
Coeficientes de regressão de Poisson operam via link log. Um coeficiente de 0,02 em overtime_hours significa que cada hora adicional aumenta o log da contagem esperada em 0,02. Ao exponenciar: e^0.02 ≈ 1.02, você vê que cada hora extra multiplica o número esperado de dias de atestado por cerca de 1,02.
A regra é sempre aplicar a inversa da função de ligação para ir do espaço dos coeficientes de volta ao espaço do desfecho.
Escolher o GLM certo se resume a uma pergunta: como é a sua variável de desfecho?
Se o desfecho é binário (sim/não, 0/1, aprova/reprova), use regressão logística. Distribuição binomial, link logit. Isso cobre tarefas de classificação como prever churn, detecção de fraude, classificação de doenças (tem ou não tem) ou se um paciente vai responder ao tratamento.
Se o desfecho é uma contagem (número de eventos em uma janela de tempo), use regressão de Poisson. Distribuição de Poisson, link log. Isso se aplica a problemas como prever visitas ao site por hora ou sinistros de seguro por ano.
Se o desfecho é contínuo e aproximadamente normal (receita, notas de prova), a regressão linear padrão dá conta do recado. Distribuição normal, link identidade. Esse é o GLM que você já conhece.
Sempre comece pela variável de desfecho, combine-a a uma distribuição e, então, o link vem junto.
Aqui estão alguns erros comuns que você deve evitar ao trabalhar com GLMs.
Este é o erro mais comum. Se seu desfecho é uma contagem e você ajusta uma regressão linear, vai obter previsões negativas. Se é binário e você usa Poisson, o modelo não fará sentido. Sempre olhe primeiro para sua variável de desfecho e escolha a distribuição que a representa.
A função de ligação transforma a relação entre entradas e saída. Um coeficiente de 0,5 na regressão logística não significa "a probabilidade sobe 0,5". Significa que o log-odds sobe 0,5. Esquecer a transformação leva a conclusões erradas sobre efeitos e importância das variáveis.
Coeficientes em uma regressão de Poisson não são comparáveis aos de uma regressão logística, mesmo que os números pareçam semelhantes. Um coeficiente de 0,3 significa algo diferente dependendo se passa por um link log ou logit. Sempre interprete os coeficientes no contexto do modelo específico.
GLMs são mais flexíveis do que a regressão linear, mas ainda têm suposições. A regressão de Poisson assume que a média é igual à variância — se seus dados de contagem têm variância muito maior que a média, os erros-padrão do modelo serão pequenos demais e seus valores-p, enganosos. A regressão logística assume observações independentes.
Para contornar isso, após ajustar qualquer GLM, verifique os resíduos e procure padrões que indiquem mau ajuste.
GLMs oferecem uma forma estruturada de ir além da regressão linear mantendo sua lógica fundamental. A ideia de uma combinação linear de entradas continua a mesma, mas a distribuição e o link mudam para se ajustar aos dados com que você está trabalhando.
Existem três componentes por trás dos GLMs. Depois que você entende como escolher a distribuição certa, configurar o preditor linear e aplicar o link correto, consegue lidar com desfechos binários, contagens e dados contínuos com o mesmo raciocínio.
O melhor próximo passo é praticar. Escolha um dataset com desfecho não normal, ajuste um GLM em Python ou R e treine interpretar os coeficientes via função de ligação. Use um conjunto de dados que faça sentido para você e toda a teoria discutida vai "clicar" em minutos.
Se você quer ir além de regressão linear e GLMs, inscreva-se na trilha Machine Learning Scientist in Python. Ela mostra tudo o que você precisa para estar pronto para o mercado em 2026.
Aprenda com a DataCamp
Curso
Curso
Curso
Tutorial
DataCamp Team
Tutorial
Vidhi Chugh
Tutorial
Zoumana Keita
Tutorial
Eladio Montero Porras
Tutorial
Avinash Navlani
Tutorial
Somil Asthana


