Courses
R 数据科学的线性代数
4小时
21.2K
线性回归是一个很好的起步模型,但一旦您的数据不符合正态分布,它就会力不从心。
假设您要预测客户是否会流失(是/否的结果)。线性回归不懂得如何处理这种情况。它预测的是连续值,于是您会得到像 -0.3 或 1.7 这样的输出,而实际只能是 0 或 1。计数数据也有同样的问题,比如每小时的客服工单数量。线性回归可能会预测出负计数,这显然说不通。
广义线性模型(GLM)通过扩展线性回归来处理不同类型的结果,从而解决这些问题。核心思想相同——输入的线性组合——但具备对二元数据和其他非正态分布建模的灵活性。
在本文中,我将拆解 GLM 的概念,讲解其三个核心组成部分,并展示如何在 Python 和 R 中拟合与解释它们。
但线性回归究竟如何工作?请阅读我们的简单线性回归指南,了解其假设与诊断,以及如何解读结果。
广义线性模型(GLM)是线性回归的扩展,允许响应变量遵循不同的概率分布,而不仅仅是正态分布。
这里需要牢记的一点是,GLM 不是单一模型,而是一个框架。线性回归、逻辑回归和 Poisson 回归都是 GLM。它们各自使用不同的分布和不同的输入到输出的连接方式,但都遵循相同的结构。
标准线性回归有两个重要假设:结果服从正态分布,且方差在预测范围内保持不变。如果这些假设不成立,您会得到毫无意义的结果。
例如,如果您要构建一个模型来预测贷款申请人是否会违约,结果是二元的——0 或 1。线性回归不尊重这个边界。它可能预测 -0.2 或 1.4,这两者都不可能。
计数数据同样有此问题。如果您预测每月住院再入院的次数,线性回归可能输出负数。您不可能有 -3 次再入院。
两种情况下的问题并不在于输入的线性组合——这部分工作得很好。问题在于模型如何将这些输入映射到输出。GLM 通过加入链接函数来解决,它将输出变换到数据的自然取值范围内。概率保持在 0 到 1 之间;计数保持非负。稍后您会看到详细内容。
每个 GLM 都由三部分构成:分布、线性预测子和链接函数。下面逐一介绍。
随机成分定义响应变量会产生何种类型的数据。换句话说,它选择最能描述结果的概率分布。
线性回归假设正态分布,因此结果是连续的,且围绕均值对称。但并非所有数据都如此。
如果结果是二元的(是/否、0/1),应使用二项分布。如果您在建模计数数据——比如每天的错误次数——Poisson 分布更合适。
您选择的分布会影响模型的其他一切。
系统成分就是您在线性回归中已经熟悉的部分。它是输入变量的线性组合:
系统成分
其中 X 是您的特征矩阵,β 是系数向量。您将每个特征乘以其权重再求和。
这一部分在不同 GLM 中并不改变。换言之,无论您拟合的是逻辑回归还是 Poisson 回归,线性预测子的形式看起来都一样。
链接函数把线性预测子与响应变量的期望值连接起来。它让 GLM 具备了灵活性。
没有链接函数时,线性预测子的输出可以从负无穷到正无穷。这对连续结果没问题,但不适合概率或计数。链接函数会把输出变换到与所选分布相匹配的合理范围。
例如,逻辑回归使用logit 链接,它把可以为任意实数的线性预测子映射为 0 到 1 之间的概率。Poisson 回归使用对数链接(log link),确保预测始终为正。
完整的 GLM 方程把这三个部分结合起来:
GLM 方程
其中 g() 是链接函数,μ 是响应的期望值。分布定义了 μ 的含义,线性预测子计算 Xβ,而链接函数则把二者连接起来。
链接函数决定了线性预测子如何转化为您的结果。不同数据类型需要不同的变换,每种 GLM 类型都有与其分布相配套的默认链接函数。
恒等链接是最简单的——它什么也不做。线性预测子等于响应的期望值:
恒等链接
这就是线性回归所用的。您的输入加权求和,和本身就是预测。无需变换,因为结果可以取任意连续值。
Logit 链接把一个概率(介于 0 和 1 之间)映射到整个实数轴:
Logit 链接
这就是逻辑回归所用的。线性预测子可以输出从负无穷到正无穷的任意值,但经过逆变换后,预测总是位于 0 和 1 之间。对数中的那个比值——μ/(1-μ)——称为赔率(odds),其对数即对数赔率(log-odds)。因此,当您解读逻辑回归的系数时,实际上是在对数赔率空间中工作。
对数链接取期望值的自然对数:
对数链接
这就是 Poisson 回归所用的。线性预测子可以是任意实数,但在对其取指数(逆变换)后,预测总为正。这正是计数数据所需,因为不可能有负事件数。
在您将 GLM 与已有模型联系起来之前,它们可能显得很抽象。线性回归、逻辑回归和 Poisson 回归都是 GLM。唯一的区别在于它们各自使用了不同的分布与链接函数组合。
线性回归是最简单的 GLM。响应服从正态分布,链接函数是恒等链接,意味着无需任何变换。
作为 GLM 的线性回归
线性预测子直接等于期望结果。这其实是您一直在使用的 GLM,只是没有这样称呼而已。
逻辑回归用二项分布和 logit 链接来建模二元结果。
作为 GLM 的逻辑回归
左边是事件的对数赔率,右边是标准的输入线性组合。无论 Xβ 多大或多小,logit 链接都能确保预测映射到 0 到 1 之间的概率。
Poisson 回归使用 Poisson 分布与对数链接来建模计数数据。
作为 GLM 的 Poisson 回归
期望计数的对数等于线性预测子。若对双方取指数,就得到 μ = e^(Xβ),其值始终为正——这正是计数数据的要求。
GLM 不使用线性回归的普通最小二乘法。相反,它们依赖于极大似然估计(MLE)。
思想很直接。MLE 会找到一组系数,使得在所选分布下,您观察到的数据出现的概率最大。对于逻辑回归,它会找到在二项模型下最有可能产生观测到的 0 和 1 的系数。对于 Poisson 回归,它会找到最能解释观测计数的系数。
大多数 GLM 没有闭式解,因此优化是迭代进行的。算法从系数的初始猜测开始,评估其拟合程度,进行调整,并重复,直到估计收敛。
最常见的方法是迭代加权最小二乘(IRLS),它将 MLE 问题重写为一系列加权线性回归。基于梯度的方法也可行,因为它们计算最陡改进方向并沿该方向前进。像 statsmodels 和 R 的 glm() 等库会在幕后完成这些工作,因此您无需自己实现求解器。
需要记住的是,您选择分布和链接函数,优化器负责寻找最优系数。理解了思路——接下来我将展示其在实践中的运作方式。
本节中,我将使用同一份数据集,在 Python 和 R 中分别演示逻辑回归与 Poisson 回归——一个模拟的员工流失数据集,包含薪资、工作年限、加班时长、是否离职(二元)以及请病假天数(计数)等列。
我将先在 Python 中创建上述数据集,然后在 Python 和 R 中用于计算:
import numpy as np
import pandas as pd
np.random.seed(42)
n = 500
# Employee dataset
df = pd.DataFrame({
"salary": np.random.normal(55000, 12000, n).astype(int),
"experience_years": np.random.poisson(5, n),
"overtime_hours": np.random.poisson(8, n),
})
# Simulate binary outcome: left the company
prob_left = 1 / (1 + np.exp(-(
-2 + -0.00003 * df["salary"] + -0.05 * df["experience_years"] + 0.12 * df["overtime_hours"]
)))
df["left"] = np.random.binomial(1, prob_left)
# Simulate count outcome: sick days per year
df["sick_days"] = np.random.poisson(
np.exp(1.2 + 0.00001 * df["salary"] + 0.02 * df["overtime_hours"])
)
# Save to use later in R
df.to_csv("data.csv", index=False)
df.head()
员工流失示例数据集
Python 提供了两种主要的 GLM 选项:statsmodels 和 scikit-learn。此处我将使用 statsmodels,因为它能提供完整的统计摘要,包括系数、p 值和置信区间。在解读 GLM 时,您会需要这些信息。
以下是如何拟合一个用于预测员工是否离职的逻辑回归:
import statsmodels.api as sm
X = sm.add_constant(df[["salary", "experience_years", "overtime_hours"]])
logit_model = sm.GLM(df["left"], X, family=sm.families.Binomial())
logit_results = logit_model.fit()
print(logit_results.summary())
GLM 逻辑回归结果
关键行是 sm.families.Binomial()。这一个参数同时设置了分布(二项)和默认链接函数(logit)。除非您想要非默认的链接,否则无需单独指定链接函数。
现在我们在同一数据集上拟合一个 Poisson 回归来预测病假天数:
poisson_model = sm.GLM(df["sick_days"], X, family=sm.families.Poisson())
poisson_results = poisson_model.fit()
print(poisson_results.summary())
GLM Poisson 回归结果
您只需将 Binomial() 替换为 Poisson(),模型就会使用带有对数链接的 Poisson 分布。输出表看起来相似,但由于链接函数不同,解释方式会改变。
下面我将把逻辑回归的预测概率与加班时长进行可视化对比:
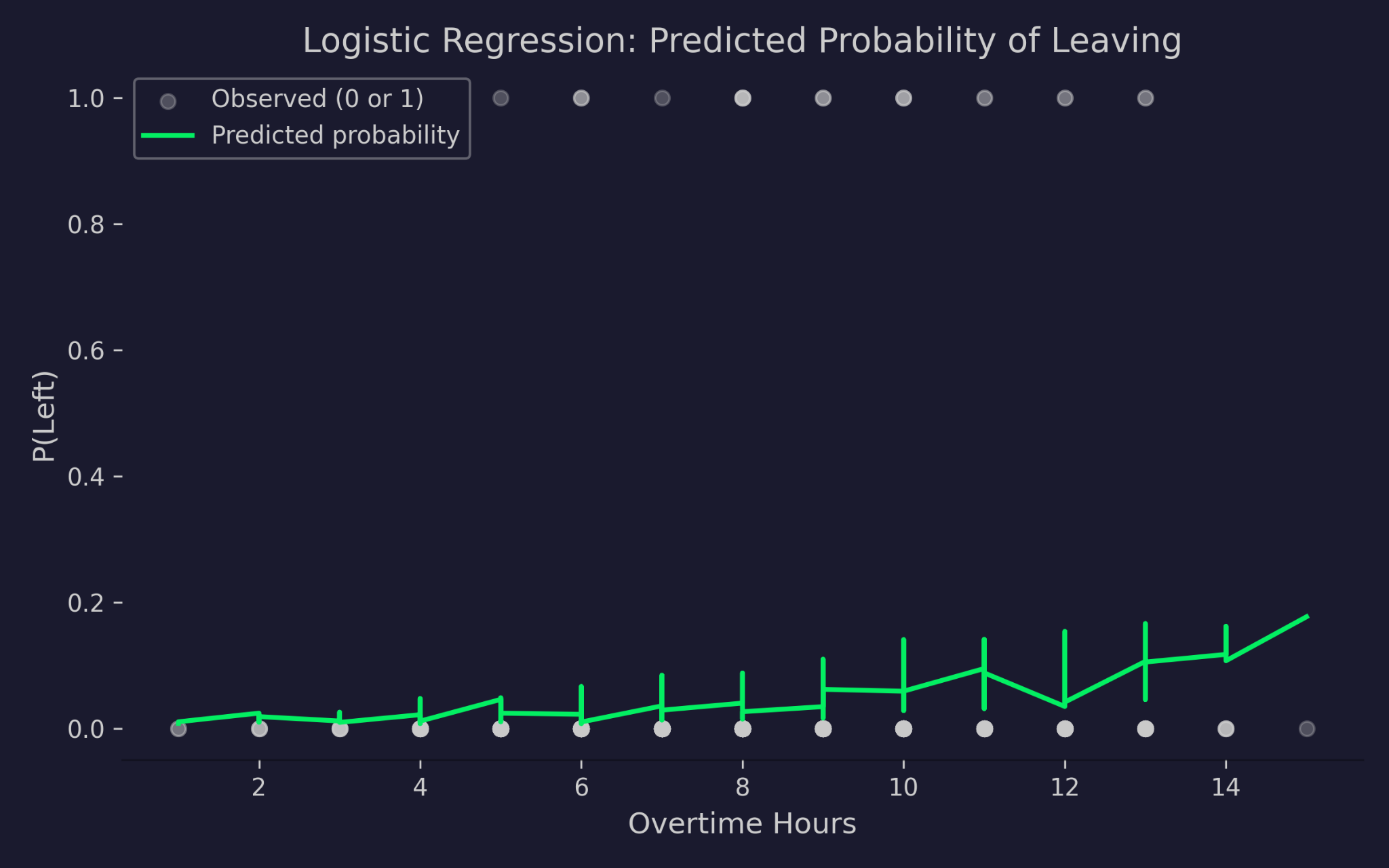
离职预测概率与加班时长的关系
图表的 x 轴为加班时长,y 轴为离职概率。灰点为实际结果——要么 0(留下),要么 1(离开)。绿色曲线是模型的预测概率。随着加班时长增加,预测的离职概率上升,但永远不会低于 0 或超过 1。这就是 logit 链接的作用——无论输入值多极端,它都会把线性预测子压缩到有效的概率范围。
R 内置的 glm() 函数遵循相同逻辑,但语法不同。family 参数设置分布和链接函数,模型通过 R 的公式接口来定义。
以下是在 R 中的同一逻辑回归:
# Read the dataset
df <- read.csv("data.csv")
# Fit logistic regression
logit_model <- glm(left ~ salary + experience_years + overtime_hours,
data = df,
family = binomial(link = "logit"))
summary(logit_model)
R 中的 GLM 逻辑回归
公式 left ~ salary + experience_years + overtime_hours 告诉 R 要预测什么以及使用哪些输入。family = binomial(link = "logit") 部分设置了分布和链接。由于 logit 是二项族的默认链接,您也可以简写为 family = binomial()。
Poisson 回归的写法基本相同:
poisson_model <- glm(sick_days ~ salary + experience_years + overtime_hours,
data = df,
family = poisson(link = "log"))
summary(poisson_model)
R 中的 GLM Poisson 回归
您只需把 binomial() 改为 poisson(),更换响应变量即可。
两种语言的做法相同——传入一个族/分布参数,它将分布与对应的默认链接函数组合在一起:

在 Python 与 R 中指定分布与链接
每个族都有默认链接,但您可以覆盖它。在 Python 中,您可以传入一个链接对象:sm.families.Binomial(link=sm.families.links.Probit())。在 R 中,只需更改链接参数:family = binomial(link = "probit")。
在大多数用例中,默认链接就是正确的选择。
GLM 的系数在不同模型类型中含义并不相同。链接函数会改变解读方式。
在线性回归中,解读很简单。experience_years 的系数为 500 意味着每增加一年经验,预测薪资增加 500。恒等链接使系数可以直接映射到结果上。
逻辑回归不同。logit 链接意味着系数处于对数赔率空间。overtime_hours 的系数为 0.12 并不意味着离职概率增加 0.12,而是意味着每增加一小时加班,离职的对数赔率增加 0.12。为获得更易解读的量,需要对系数取指数:e^0.12 ≈ 1.127。这给出赔率比。每多一小时加班,离职的赔率大约乘以 1.13。
Poisson 回归的系数通过对数链接起作用。overtime_hours 的系数为 0.02 意味着每增加一小时,加班会使期望计数的对数增加 0.02。对其取指数:e^0.02 ≈ 1.02,您会看到每多一小时加班,期望的病假天数大约乘以 1.02。
规律是始终应用链接函数的逆变换,把系数空间映射回结果空间。
选择合适的 GLM 归根结底取决于一个问题:您的结果变量是什么样的?
如果结果是二元(是/否、0/1、通过/未通过),请使用逻辑回归。二项分布,logit 链接。它涵盖诸如预测流失、欺诈检测、疾病分类(有/无),或者患者是否会对治疗产生反应等分类任务。
如果结果是计数(在时间窗内的事件次数),请使用 Poisson 回归。Poisson 分布,对数链接。适用于预测诸如每小时网站访问次数或每年的保险理赔次数等问题。
如果结果是连续且大致正态(如收入、测试分数),标准线性回归就足够了。正态分布,恒等链接。这是您已经熟悉的 GLM。
始终从结果变量入手,为其匹配一个分布,链接函数也随之确定。
以下是使用 GLM 时应避免的一些常见错误。
这是最常见的错误。如果结果是计数却拟合了线性回归,您会得到负数预测。如果结果是二元的却使用了 Poisson,模型就不合理。务必先查看结果变量,并选择与之匹配的分布。
链接函数会变换输入与输出之间的关系。逻辑回归的 0.5 系数并不意味着“概率上升 0.5”。它意味着对数赔率上升 0.5。忽视这种变换会导致对效应大小和变量重要性的错误结论。
Poisson 回归中的系数与逻辑回归中的系数不可直接比较,即便数值看起来相似。0.3 的系数在通过对数链接还是 logit 链接时,含义完全不同。务必在所用具体模型的语境下解读系数。
GLM 比线性回归更灵活,但仍有其假设。Poisson 回归假设均值等于方差——如果您的计数数据方差远大于均值,模型的标准误会偏小,p 值会误导。逻辑回归假设观测相互独立。
要克服这些问题,在拟合任何 GLM 后,请检查残差,留意提示拟合不佳的模式。
GLM 为您提供了一种有结构的方法,超越线性回归,同时仍遵循其基本逻辑。输入线性组合的理念保持不变,但分布与链接函数会根据数据而变化。
GLM 背后有三个组成部分。一旦您学会如何选择合适的分布、建立线性预测子并应用正确的链接函数,就能用同一套思维模型处理二元结果、计数和连续数据。
最佳的下一步就是动手试试。选取一个非正态结果的数据集,在 Python 或 R 中拟合 GLM,并练习通过链接函数来解读系数。选一个您关心的数据集,本文涉及的每一点理论都会在几分钟内豁然开朗。
如果您想超越线性回归与 GLM,欢迎参加我们的Python 机器学习科学家学习路径。它将帮助您在 2026 年具备上岗所需的一切。
与 DataCamp 一起学习
Courses
Courses
Courses