course
Algebră liniară pentru știința datelor în R
4 oră
21.2K
Regresia liniară e un prim model excelent de încercat, dar cedează în clipa în care datele tale nu urmează o distribuție normală.
Să zicem că încerci să prezici dacă un client va renunța (rezultat da sau nu). Regresia liniară nu știe să facă asta. Ea prezice valori continue, așa că ajungi cu ieșiri precum -0,3 sau 1,7 pentru ceva ce poate fi doar 0 sau 1. Aceeași problemă apare la date de numărare, cum ar fi numărul de tichete de suport pe oră. Regresia liniară poate prezice numere negative, ceea ce nu are sens.
Modelele liniare generalizate (GLM) rezolvă asta extinzând regresia liniară pentru a gestiona diferite tipuri de rezultate. Ideea de bază e aceeași – o combinație liniară a intrărilor – dar cu flexibilitatea de a modela date binare și alte distribuții nenormale.
În acest articol, îți explic ce sunt GLM-urile, parcurg cele trei componente de bază și îți arăt cum să le potrivești și interpretezi atât în Python, cât și în R.
Dar cum funcționează exact regresia liniară? Citește ghidul nostru despre Regresia liniară simplă ca să înveți ipotezele și diagnosticele ei și cum să interpretezi rezultatele.
Un model liniar generalizat (GLM) este o extensie a regresiei liniare care permite variabilei răspuns să urmeze diferite distribuții de probabilitate, nu doar distribuția normală.
Important de reținut este că GLM nu este un singur model. Este un cadru. Regresia liniară, regresia logistică și regresia Poisson sunt toate GLM-uri. Fiecare folosește o distribuție diferită și un mod diferit de conectare a intrărilor la ieșiri, dar toate urmează aceeași structură.
Regresia liniară standard face două presupuneri mari: rezultatul e distribuit normal și varianța rămâne constantă pe tot intervalul predicțiilor. Dacă aceste presupuneri nu se respectă, vei obține rezultate fără sens.
De exemplu, dacă construiești un model care prezice dacă un solicitant de credit va intra în neplată, rezultatul este binar – 0 sau 1. Regresia liniară nu respectă acea limită. Poate prezice -0,2 sau 1,4, ambele imposibile.
Datele de numărare au aceeași problemă. Dacă prezici numărul de re-internări în spital pe lună, regresia liniară poate da numere negative. Nu poți avea -3 re-internări.
Problema, în ambele cazuri, nu este combinația liniară a intrărilor – acea parte funcționează bine. Problema este modul în care modelul mapează acele intrări la ieșire. GLM-urile rezolvă asta adăugând o funcție de legătură (link) care transformă ieșirea astfel încât să se potrivească intervalului natural al datelor. Probabilitățile rămân între 0 și 1. Numărările rămân nenegative. Vei vedea imediat cum.
Fiecare GLM este construit din trei părți: o distribuție, un predictor liniar și o funcție de legătură. Le iau pe rând.
Componenta aleatoare definește ce fel de date produce variabila răspuns. Cu alte cuvinte, alege distribuția de probabilitate care descrie cel mai bine rezultatul tău.
Regresia liniară presupune o distribuție normală, deci rezultatul e continuu și simetric în jurul mediei. Dar nu toate datele arată așa.
Dacă rezultatul tău este binar (da/nu, 0/1), vei folosi o distribuție binomială. Dacă modelezi date de numărare – cum ar fi numărul de erori pe zi – o distribuție Poisson este o alegere mai bună.
Distribuția pe care o alegi controlează tot restul modelului.
Componenta sistematică este partea pe care o știi deja din regresia liniară. Este o combinație liniară a variabilelor de intrare:
Componentă sistematică
Unde X este matricea ta de caracteristici de intrare, iar β este vectorul coeficienților. Înmulțești fiecare caracteristică cu ponderea ei și le aduni.
Această parte nu se schimbă între diferite GLM-uri. Cu alte cuvinte, indiferent dacă potrivești o regresie logistică sau o regresie Poisson, predictorul liniar arată la fel.
Funcția de legătură conectează predictorul liniar la valoarea așteptată a variabilei răspuns. Este piesa care face GLM-urile flexibile.
Fără o funcție de legătură, predictorul liniar produce valori de la minus infinit la plus infinit. Asta e în regulă pentru rezultate continue, dar nu pentru probabilități sau numărări. Funcția de legătură transformă ieșirea astfel încât să se încadreze în intervalul corect pentru distribuția aleasă.
De exemplu, regresia logistică folosește link-ul logit, care mapează un predictor liniar ce poate fi orice număr real la o probabilitate între 0 și 1. Regresia Poisson folosește link-ul log, care se asigură că predicțiile sunt întotdeauna pozitive.
Ecuația completă GLM combină toate cele trei componente:
Ecuația GLM
Unde g() este funcția de legătură, iar μ este valoarea așteptată a răspunsului. Distribuția definește ce înseamnă μ, predictorul liniar calculează Xβ, iar funcția de legătură le conectează pe cele două.
Funcția de legătură determină cum se convertește predictorul liniar în rezultat. Tipuri diferite de date au nevoie de transformări diferite, iar fiecare tip de GLM are o funcție de legătură implicită care se potrivește cu distribuția lui.
Link-ul identitate este cel mai simplu – nu face nimic. Predictorul liniar este egal cu valoarea așteptată a răspunsului:
Link identitate
Acesta este cel folosit de regresia liniară. Intrările tale se combină într-o sumă ponderată, iar acea sumă este predicția. Nu e nevoie de transformare, pentru că rezultatul poate lua orice valoare continuă.
Link-ul logit ia o probabilitate (între 0 și 1) și o mapează pe întreaga axă a numerelor reale:
Link logit
Acesta este cel folosit de regresia logistică. Predictorul liniar poate produce orice valoare de la minus infinit la plus infinit, dar după transformarea inversă, predicția rămâne întotdeauna între 0 și 1. Raportul din interiorul logaritmului – μ/(1-μ) – se numește șanse (odds), iar logaritmul șanselor este log-șansa (log-odds). Așadar, când interpretezi coeficienții din regresia logistică, lucrezi în spațiul log-șanselor.
Link-ul log ia logaritmul natural al valorii așteptate:
Link log
Acesta este cel folosit de regresia Poisson. Predictorul liniar poate fi orice număr real, dar după ce îl exponentiezi înapoi (inversa), predicția este întotdeauna pozitivă. Exact ce ai nevoie pentru date de numărare, deoarece nu poți avea evenimente negative.
GLM-urile pot părea abstracte până când le vezi ca pe modele pe care deja le cunoști. Regresia liniară, regresia logistică și regresia Poisson sunt toate GLM-uri. Singura diferență este că fiecare folosește o altă combinație de distribuție și funcție de legătură.
Regresia liniară este cel mai simplu GLM. Răspunsul urmează o distribuție normală, iar funcția de legătură este link-ul identitate, adică fără nicio transformare.
Regresia liniară ca GLM
Predictorul liniar este egal direct cu rezultatul așteptat. Acesta este GLM-ul pe care l-ai folosit tot timpul, doar că nu i-ai spus așa.
Regresia logistică modelează rezultate binare folosind o distribuție binomială și un link logit.
Regresia logistică ca GLM
Partea stângă este log-șansa evenimentului. Partea dreaptă este combinația liniară standard a intrărilor. Link-ul logit se asigură că predicțiile se mapează la probabilități între 0 și 1, oricât de mare sau mic ar deveni Xβ.
Regresia Poisson modelează date de numărare folosind o distribuție Poisson și un link log.
Regresia Poisson ca GLM
Logaritmul numărului așteptat este egal cu predictorul liniar. Dacă exponentiezi ambele părți, obții μ = e^(Xβ), care este întotdeauna pozitiv – exact ce impun numărările.
GLM-urile nu folosesc metoda celor mai mici pătrate obișnuite ca regresia liniară. În schimb, se bazează pe estimarea prin verosimilitate maximă (MLE).
Ideea e simplă. MLE găsește setul de coeficienți care face datele observate cât mai probabile sub distribuția aleasă. Pentru o regresie logistică, găsește coeficienții care fac 0-urile și 1-urile observate cât mai probabile într-un model binomial. Pentru regresia Poisson, găsește coeficienții care explică cel mai bine numărările observate.
Pentru majoritatea GLM-urilor nu există o soluție în formă închisă, așa că optimizarea este iterativă. Algoritmul pornește cu o presupunere inițială pentru coeficienți, evaluează cât de bine se potrivesc datelor, îi ajustează și repetă până când estimările converg.
Cea mai comună metodă este cei mai mici pătrați reponderați iterativ (IRLS), care reformulează problema MLE ca o succesiune de regresii liniare ponderate. Metodele pe bază de gradient funcționează și ele, deoarece calculează direcția celei mai abrupte îmbunătățiri și fac pași în acea direcție. Biblioteci precum statsmodels și glm() din R fac toate acestea în culise, așa că nu trebuie să implementezi singur solverul.
De reținut este că tu alegi distribuția și funcția de legătură, iar optimizatorul găsește cei mai buni coeficienți. Aceasta e ideea – acum îți arăt cum funcționează în practică.
În această secțiune, voi parcurge regresia logistică și regresia Poisson atât în Python, cât și în R, folosind același set de date – un set simulat despre plecarea angajaților, cu coloane pentru salariu, ani de experiență, ore suplimentare, dacă angajatul a plecat (binar) și numărul de zile de concediu medical (numărare).
Voi crea setul de date menționat în Python și apoi îl voi folosi pentru calcule atât în Python, cât și în R:
import numpy as np
import pandas as pd
np.random.seed(42)
n = 500
# Employee dataset
df = pd.DataFrame({
"salary": np.random.normal(55000, 12000, n).astype(int),
"experience_years": np.random.poisson(5, n),
"overtime_hours": np.random.poisson(8, n),
})
# Simulate binary outcome: left the company
prob_left = 1 / (1 + np.exp(-(
-2 + -0.00003 * df["salary"] + -0.05 * df["experience_years"] + 0.12 * df["overtime_hours"]
)))
df["left"] = np.random.binomial(1, prob_left)
# Simulate count outcome: sick days per year
df["sick_days"] = np.random.poisson(
np.exp(1.2 + 0.00001 * df["salary"] + 0.02 * df["overtime_hours"])
)
# Save to use later in R
df.to_csv("data.csv", index=False)
df.head()
Set de date eșantion despre plecarea angajaților
Python îți oferă două opțiuni principale pentru GLM-uri: statsmodels și scikit-learn. Voi folosi aici statsmodels pentru că îți oferă un rezumat statistic complet, inclusiv coeficienți, valori p și intervale de încredere. Ai nevoie de acestea când interpretezi un GLM.
Iată cum poți potrivi o regresie logistică pentru a prezice dacă un angajat a plecat:
import statsmodels.api as sm
X = sm.add_constant(df[["salary", "experience_years", "overtime_hours"]])
logit_model = sm.GLM(df["left"], X, family=sm.families.Binomial())
logit_results = logit_model.fit()
print(logit_results.summary())
Rezultate GLM pentru regresia logistică
Linia-cheie este sm.families.Binomial(). Aceasta setează atât distribuția (binomială), cât și funcția de legătură implicită (logit) într-un singur argument. Nu trebuie să specifici separat link-ul decât dacă vrei unul neimplicit.
Acum să potrivim o regresie Poisson pe același set de date pentru a prezice zilele de concediu medical:
poisson_model = sm.GLM(df["sick_days"], X, family=sm.families.Poisson())
poisson_results = poisson_model.fit()
print(poisson_results.summary())
Rezultate GLM pentru regresia Poisson
Trebuie doar să înlocuiești Binomial() cu Poisson() și modelul folosește o distribuție Poisson cu link log. Tabelul de ieșire arată la fel, dar interpretarea se schimbă pentru că s-a schimbat funcția de legătură.
Acum voi vizualiza probabilitățile prezise de la regresia logistică în raport cu orele suplimentare:
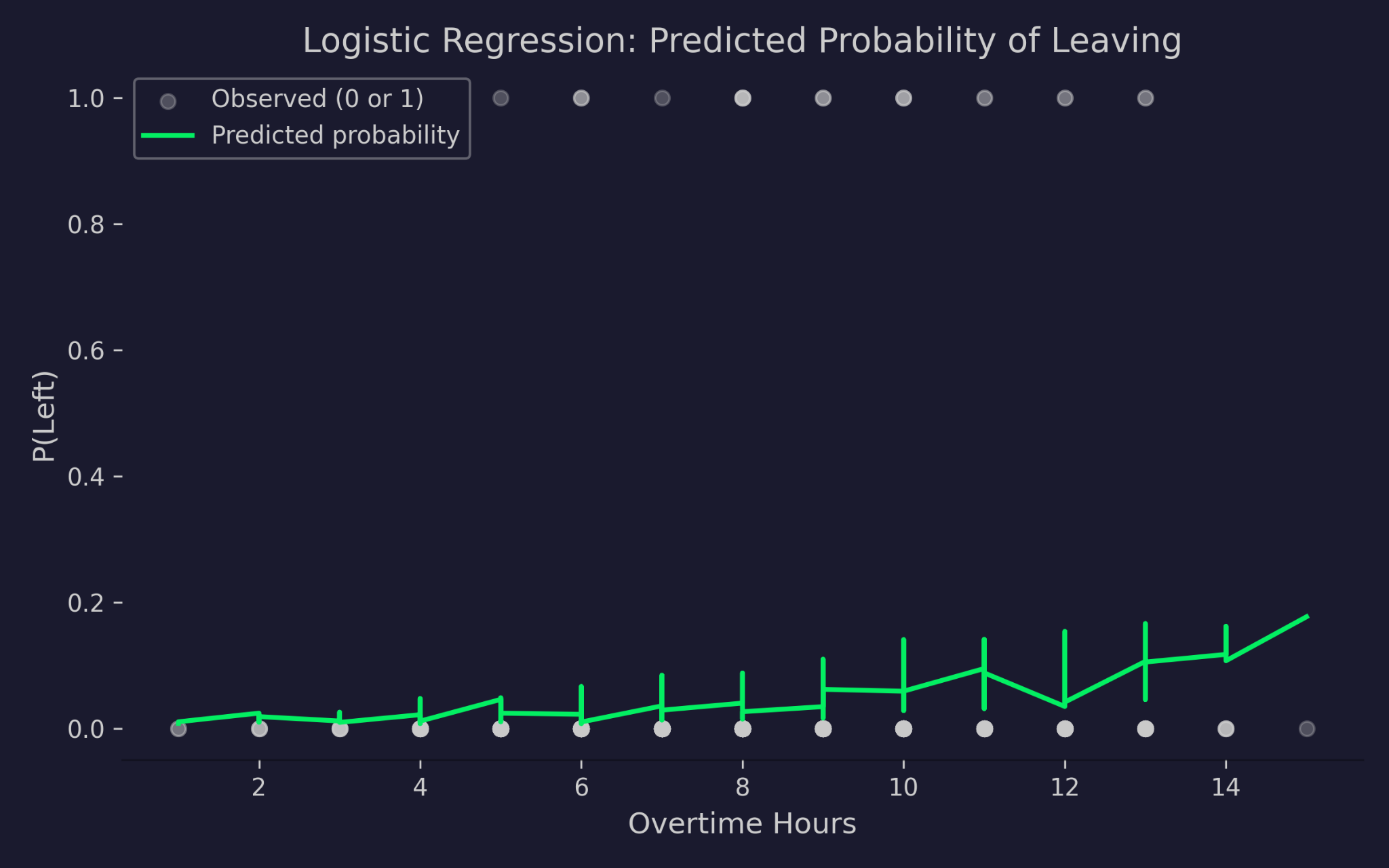
Probabilități prezise de plecare în funcție de orele suplimentare
Graficul arată orele suplimentare pe axa x și probabilitatea de plecare pe axa y. Punctele gri sunt rezultatele reale – fie 0 (a rămas), fie 1 (a plecat). Curba verde este probabilitatea prezisă de model. Pe măsură ce cresc orele suplimentare, probabilitatea prezisă de plecare crește, dar nu scade niciodată sub 0 și nu depășește 1. Asta este efectul link-ului logit – el comprimă predictorul liniar într-un interval valid al probabilităților, oricât de extreme ar fi valorile de intrare.
Funcția încorporată glm() din R urmează aceeași logică, dar cu altă sintaxă. Argumentul family setează distribuția și funcția de legătură, iar modelul este definit cu interfața de formule a lui R.
Iată aceeași regresie logistică în R:
# Read the dataset
df <- read.csv("data.csv")
# Fit logistic regression
logit_model <- glm(left ~ salary + experience_years + overtime_hours,
data = df,
family = binomial(link = "logit"))
summary(logit_model)
Regresie logistică GLM în R
Formula left ~ salary + experience_years + overtime_hours îi spune lui R ce să prezică și ce intrări să folosească. Partea family = binomial(link = "logit") setează distribuția și link-ul. Poți scurta la family = binomial() deoarece logit este link-ul implicit pentru familia binomială.
Regresia Poisson este în mare parte la fel:
poisson_model <- glm(sick_days ~ salary + experience_years + overtime_hours,
data = df,
family = poisson(link = "log"))
summary(poisson_model)
Regresie Poisson GLM în R
Trebuie doar să schimbi binomial() cu poisson(), să schimbi variabila răspuns și ai terminat.
Ambele limbaje folosesc aceeași abordare – transmiți un argument family/distribution care combină distribuția și funcția ei de legătură implicită:

Specificarea distribuției și link-ului în Python și R
Fiecare familie are un link implicit, dar îl poți înlocui. În Python, poți transmite un obiect de link: sm.families.Binomial(link=sm.families.links.Probit()). În R, schimbă pur și simplu argumentul link: family = binomial(link = "probit").
Pentru cele mai multe cazuri de utilizare, link-ul implicit este alegerea potrivită.
Coeficienții GLM nu înseamnă același lucru între diferite tipuri de model. Funcția de legătură schimbă modul în care îi interpretezi.
În regresia liniară, interpretarea e ușoară. Un coeficient de 500 pe experience_years înseamnă că fiecare an suplimentar de experiență adaugă 500 la salariul prezis. Link-ul identitate înseamnă că coeficienții se mapează direct pe rezultat.
Regresia logistică este diferită. Link-ul logit înseamnă că coeficienții sunt în spațiul log-șanselor. Un coeficient de 0,12 pe overtime_hours nu înseamnă că probabilitatea de plecare crește cu 0,12. Înseamnă că log-șansa plecării crește cu 0,12 pentru fiecare oră suplimentară. Pentru ceva mai ușor de interpretat, exponentiază coeficientul: e^0.12 ≈ 1.127. Asta îți dă un raport de șanse (odds ratio). Fiecare oră suplimentară multiplică șansa de plecare cu aproximativ 1,13.
Coeficienții din regresia Poisson funcționează prin link-ul log. Un coeficient de 0,02 pe overtime_hours înseamnă că fiecare oră suplimentară crește logaritmul numărului așteptat cu 0,02. Când îl exponentiezi: e^0.02 ≈ 1.02, vei vedea că fiecare oră suplimentară multiplică numărul așteptat de zile de concediu medical cu aproximativ 1,02.
Regula este să aplici întotdeauna inversa funcției de legătură pentru a trece din spațiul coeficienților înapoi în spațiul rezultatului.
Alegerea GLM-ului potrivit se reduce la o întrebare: cum arată variabila ta de rezultat?
Dacă rezultatul este binar (da/nu, 0/1, promovat/respins), folosește regresia logistică. Distribuție binomială, link logit. Acoperă sarcini de clasificare precum prezicerea churn-ului, detectarea fraudelor, clasificarea bolilor (are sau nu are) sau dacă un pacient va răspunde la tratament.
Dacă rezultatul este o numărare (număr de evenimente într-o fereastră de timp), folosește regresia Poisson. Distribuție Poisson, link log. Se potrivește cu probleme precum prezicerea numărului de vizite pe site pe oră sau a daunelor de asigurare pe an.
Dacă rezultatul este continuu și aproximativ normal (venituri, scoruri la teste), regresia liniară standard funcționează foarte bine. Distribuție normală, link identitate. Acesta este GLM-ul pe care îl cunoști deja.
Începe întotdeauna cu variabila de rezultat, potrivește-o cu o distribuție și apoi urmează funcția de legătură.
Iată câteva greșeli frecvente pe care ar trebui să le eviți când lucrezi cu GLM-uri.
Aceasta este cea mai comună greșeală. Dacă rezultatul tău este o numărare și potrivești o regresie liniară, vei obține predicții negative. Dacă este binar și folosești Poisson, modelul nu va avea sens. Privește întotdeauna mai întâi variabila de rezultat și alege distribuția care i se potrivește.
Funcția de legătură transformă relația dintre intrări și ieșire. Un coeficient de 0,5 într-o regresie logistică nu înseamnă „probabilitatea crește cu 0,5”. Înseamnă că log-șansa crește cu 0,5. Dacă uiți de transformare, ajungi la concluzii greșite despre mărimea efectelor și importanța variabilelor.
Coeficienții dintr-o regresie Poisson nu sunt comparabili cu cei dintr-o regresie logistică, chiar dacă numerele par similare. Un coeficient de 0,3 înseamnă altceva în funcție de faptul că trece printr-un link log sau un link logit. Interpretează întotdeauna coeficienții în contextul modelului specific pe care îl folosești.
GLM-urile sunt mai flexibile decât regresia liniară, dar au totuși ipoteze. Regresia Poisson presupune că media este egală cu varianța – dacă datele tale de numărare au mult mai multă varianță decât media, erorile standard ale modelului vor fi prea mici, iar valorile p vor fi înșelătoare. Regresia logistică presupune că observațiile sunt independente.
Pentru a depăși asta, după ce potrivești orice GLM, verifică reziduurile și caută tipare care sugerează o potrivire slabă.
GLM-urile îți oferă o modalitate structurată de a merge dincolo de regresia liniară, dar respectându-i logica fundamentală. Ideea unei combinații liniare a intrărilor rămâne aceeași, dar distribuția și funcția de legătură se schimbă pentru a se potrivi datelor cu care lucrezi.
Există trei componente în spatele GLM-urilor. Odată ce știi cum să alegi distribuția potrivită, să configurezi predictorul liniar și să aplici funcția de legătură corectă, poți gestiona rezultate binare, numărări și date continue cu același mod mental de lucru.
Cel mai bun pas următor este să încerci. Alege un set de date cu un rezultat nenormal, potrivește un GLM în Python sau R și exersează interpretarea coeficienților prin funcția de legătură. Folosește un set de date care te interesează, iar fiecare pic de teorie discutată va căpăta sens în câteva minute.
Dacă vrei să mergi dincolo de regresia liniară și GLM-uri, înscrie-te la traseul nostru Machine Learning Scientist in Python. Te duce cu tot ce ai nevoie până la nivelul de job-ready în 2026.
Învață cu DataCamp
course
course
course