
Cursus
Lineaire algebra voor data science in R
4 Hr
21.2K
Lineaire regressie is een prima eerste model om te proberen, maar het schiet tekort zodra je data niet in een normale verdeling past.
Stel, je probeert te voorspellen of een klant gaat afhaken (ja of nee). Lineaire regressie kan dat niet. Het voorspelt continue waarden, dus je krijgt uitkomsten als -0,3 of 1,7 voor iets dat alleen 0 of 1 kan zijn. Hetzelfde probleem zie je bij telgegevens, zoals het aantal supporttickets per uur. Lineaire regressie kan negatieve aantallen voorspellen, wat geen zin heeft.
Gegeneraliseerde lineaire modellen (GLM’s) lossen dit op door de lineaire regressie uit te breiden zodat verschillende soorten uitkomsten mogelijk zijn. Het kernidee blijft hetzelfde: een lineaire combinatie van inputvariabelen, maar dan met de flexibiliteit om binaire data en andere niet-normale verdelingen te modelleren.
In dit artikel leg ik uit wat GLM’s zijn, loop ik door hun drie kernelementen en laat ik zien hoe je ze fit en interpreteert in zowel Python als R.
Maar hoe werkt lineaire regressie precies? Lees onze gids Simple Linear Regression om de aannames en diagnostiek te leren kennen en om te leren hoe je de resultaten interpreteert.
Een gegeneraliseerd lineair model (GLM) is een uitbreiding op lineaire regressie die toestaat dat de responsvariabele verschillende kansverdelingen volgt, niet alleen de normale verdeling.
Belangrijk om te onthouden is dat GLM geen enkel model is. Het is een raamwerk. Lineaire regressie, logistische regressie en Poisson-regressie zijn allemaal GLM’s. Elk gebruikt een andere verdeling en een andere manier om inputs aan outputs te koppelen, maar ze volgen allemaal dezelfde structuur.
Standaard lineaire regressie doet twee grote aannames: je uitkomst is normaal verdeeld en de variantie blijft constant over voorspellingen heen. Als die aannames niet kloppen, krijg je onzinnige resultaten.
Als je bijvoorbeeld een model bouwt om te voorspellen of een kredietaanvrager in gebreke zal blijven, is de uitkomst binair - 0 of 1. Lineaire regressie respecteert die grenzen niet. Het kan -0,2 of 1,4 voorspellen, beide onmogelijk.
Telgegevens hebben hetzelfde probleem. Als je het aantal heropnames in het ziekenhuis per maand voorspelt, kan lineaire regressie negatieve aantallen geven. Je kunt geen -3 heropnames hebben.
In beide gevallen is het probleem niet de lineaire combinatie van inputs - dat deel werkt prima. Het probleem is hoe het model die inputs naar de output vertaalt. GLM’s lossen dit op door een koppelfunctie (link function) toe te voegen die de output transformeert zodat die past binnen het natuurlijke bereik van de data. Waarschijnlijkheden blijven tussen 0 en 1. Aantallen blijven niet-negatief. Straks zie je precies hoe dat werkt.
Elk GLM is opgebouwd uit drie delen: een verdeling, een lineaire voorspeller en een koppelfunctie. Ik loop ze één voor één door.
De stochastische component bepaalt wat voor soort data je responsvariabele oplevert. Met andere woorden: hij kiest de kansverdeling die je uitkomst het best beschrijft.
Lineaire regressie gaat uit van een normale verdeling, dus de uitkomst is continu en symmetrisch rond het gemiddelde. Maar niet alle data werkt zo.
Als je uitkomst binair is (ja/nee, 0/1), gebruik je een binomiale verdeling. Als je telgegevens modelleert - zoals het aantal fouten per dag - past een Poisson-verdeling beter.
De gekozen verdeling stuurt de rest van het model aan.
De systematische component ken je al van lineaire regressie. Het is een lineaire combinatie van je inputvariabelen:
Systematische component
Waarbij X je matrix met features is en β de vector met coëfficiënten. Je vermenigvuldigt elke feature met zijn gewicht en telt ze op.
Dit deel verandert niet tussen verschillende GLM’s. Met andere woorden: of je nu een logistische regressie of een Poisson-regressie fit, de lineaire voorspeller ziet er hetzelfde uit.
De koppelfunctie verbindt de lineaire voorspeller met de verwachtingswaarde van de responsvariabele. Dit maakt GLM’s flexibel.
Zonder koppelfunctie geeft de lineaire voorspeller waarden van min oneindig tot plus oneindig. Dat is prima voor continue uitkomsten, maar niet voor waarschijnlijkheden of aantallen. De koppelfunctie transformeert de output zodat die binnen het juiste bereik voor je gekozen verdeling valt.
Zo gebruikt logistische regressie de logit-link, die een lineaire voorspeller die elk reëel getal kan zijn, omzet naar een waarschijnlijkheid tussen 0 en 1. Poisson-regressie gebruikt de log-link, die ervoor zorgt dat voorspellingen altijd positief zijn.
De volledige GLM-vergelijking combineert alle drie de componenten:
GLM-vergelijking
Waarbij g() de koppelfunctie is en μ de verwachtingswaarde van de respons. De verdeling bepaalt wat μ betekent, de lineaire voorspeller berekent Xβ en de koppelfunctie overbrugt de twee.
De koppelfunctie bepaalt hoe de lineaire voorspeller naar je uitkomst wordt vertaald. Verschillende datatypen vragen om verschillende transformaties, en elk GLM-type heeft een standaardkoppeling die bij zijn verdeling past.
De identiteitslink is de simpelste - hij doet niets. De lineaire voorspeller is gelijk aan de verwachtingswaarde van de respons:
Identiteitslink
Dit is wat lineaire regressie gebruikt. Je inputs worden gecombineerd tot een gewogen som, en die som is de voorspelling. Er is geen transformatie nodig, omdat de uitkomst elke continue waarde kan aannemen.
De logit-link neemt een waarschijnlijkheid (tussen 0 en 1) en mapt die op de volledige reële getallenlijn:
Logit-link
Dit is wat logistische regressie gebruikt. De lineaire voorspeller kan elke waarde van min tot plus oneindig aannemen, maar na de inverse transformatie ligt de voorspelling altijd tussen 0 en 1. Die verhouding binnen de logaritme - μ/(1-μ) - heet de odds, en de logaritme daarvan zijn de log-odds. Wanneer je coëfficiënten van logistische regressie interpreteert, werk je dus in log-odds-ruimte.
De log-link neemt de natuurlijke logaritme van de verwachtingswaarde:
Log-link
Dit is wat Poisson-regressie gebruikt. De lineaire voorspeller kan elk reëel getal zijn, maar na exponentiëren (de inverse) is de voorspelling altijd positief. Precies wat je nodig hebt voor telgegevens, want je kunt geen negatieve gebeurtenissen hebben.
GLM’s kunnen abstract aanvoelen totdat je ze ziet als modellen die je al kent. Lineaire regressie, logistische regressie en Poisson-regressie zijn allemaal GLM’s. Het enige verschil is dat elk een andere combinatie van verdeling en koppelfunctie gebruikt.
Lineaire regressie is de eenvoudigste GLM. De respons volgt een normale verdeling en de koppelfunctie is de identiteitslink, oftewel geen transformatie.
Lineaire regressie als GLM
De lineaire voorspeller is direct gelijk aan de verwachte uitkomst. Dit is de GLM die je al die tijd al gebruikte, alleen noemde je het niet zo.
Logistische regressie modelleert binaire uitkomsten met een binomiale verdeling en een logit-link.
Logistische regressie als GLM
De linkerkant is de log-odds van de gebeurtenis. De rechterkant is je standaard lineaire combinatie van inputs. De logit-link zorgt ervoor dat voorspellingen naar waarschijnlijkheden tussen 0 en 1 worden vertaald, hoe groot of klein Xβ ook wordt.
Poisson-regressie modelleert telgegevens met een Poisson-verdeling en een log-link.
Poisson-regressie als GLM
De logaritme van het verwachte aantal is gelijk aan de lineaire voorspeller. Als je beide kanten exponentieert, krijg je μ = e^(Xβ), wat altijd positief is - precies wat aantallen vereisen.
GLM’s gebruiken niet ordinary least squares zoals lineaire regressie. In plaats daarvan vertrouwen ze op maximum likelihood-schattingsmethode (MLE).
Het idee is eenvoudig. MLE vindt de set coëfficiënten die jouw geobserveerde data het meest waarschijnlijk maakt onder de gekozen verdeling. Voor een logistische regressie vindt het de coëfficiënten die de geobserveerde 0’s en 1’s het meest waarschijnlijk maken gegeven een binomiaal model. Voor Poisson-regressie vindt het de coëfficiënten die de geobserveerde aantallen het best verklaren.
Voor de meeste GLM’s bestaat geen gesloten-formuleoplossing, dus de optimalisatie is iteratief. Het algoritme start met een eerste gok voor de coëfficiënten, beoordeelt hoe goed die bij de data passen, past ze aan en herhaalt dit tot de schattingen convergeren.
De meest gebruikte methode is iteratively reweighted least squares (IRLS), waarbij het MLE-probleem wordt herschreven als een reeks gewogen lineaire regressies. Gradiëntgebaseerde methoden werken ook: die berekenen de richting van de grootste verbetering en zetten daar stappen naartoe. Bibliotheken zoals statsmodels en R’s glm() doen dit allemaal achter de schermen, dus je hoeft de oplosser niet zelf te implementeren.
Onthoud vooral: jij kiest de verdeling en koppelfunctie, en de optimizer vindt de beste coëfficiënten. Dat is het idee - nu laat ik zien hoe het in de praktijk werkt.
In deze sectie loop ik door logistische regressie en Poisson-regressie in zowel Python als R met dezelfde dataset - een gesimuleerde medewerkersdataset met kolommen voor salaris, jaren ervaring, overuren, of de medewerker vertrokken is (binair) en het aantal opgenomen ziektedagen (count).
Ik maak de genoemde dataset in Python en gebruik die vervolgens voor berekeningen in zowel Python als R:
import numpy as np
import pandas as pd
np.random.seed(42)
n = 500
# Employee dataset
df = pd.DataFrame({
"salary": np.random.normal(55000, 12000, n).astype(int),
"experience_years": np.random.poisson(5, n),
"overtime_hours": np.random.poisson(8, n),
})
# Simulate binary outcome: left the company
prob_left = 1 / (1 + np.exp(-(
-2 + -0.00003 * df["salary"] + -0.05 * df["experience_years"] + 0.12 * df["overtime_hours"]
)))
df["left"] = np.random.binomial(1, prob_left)
# Simulate count outcome: sick days per year
df["sick_days"] = np.random.poisson(
np.exp(1.2 + 0.00001 * df["salary"] + 0.02 * df["overtime_hours"])
)
# Save to use later in R
df.to_csv("data.csv", index=False)
df.head()
Voorbeeld van een medewerkers-attritiedataset
Python geeft je twee hoofdopties voor GLM’s: statsmodels en scikit-learn. Ik gebruik hier statsmodels omdat het een volledige statistische samenvatting geeft, inclusief coëfficiënten, p-waarden en betrouwbaarheidsintervallen. Die heb je nodig bij het interpreteren van een GLM.
Zo kun je een logistische regressie fitten om te voorspellen of een medewerker vertrokken is:
import statsmodels.api as sm
X = sm.add_constant(df[["salary", "experience_years", "overtime_hours"]])
logit_model = sm.GLM(df["left"], X, family=sm.families.Binomial())
logit_results = logit_model.fit()
print(logit_results.summary())
Resultaten GLM logistische regressie
De sleutelregel is sm.families.Binomial(). Dit stelt zowel de verdeling (binomiaal) als de standaardkoppeling (logit) in met één argument. Je hoeft de link niet apart te specificeren, tenzij je een niet-standaard wilt.
Laten we nu een Poisson-regressie fitten op dezelfde dataset om ziektedagen te voorspellen:
poisson_model = sm.GLM(df["sick_days"], X, family=sm.families.Poisson())
poisson_results = poisson_model.fit()
print(poisson_results.summary())
Resultaten GLM Poisson-regressie
Je hoeft alleen Binomial() te vervangen door Poisson() en het model gebruikt een Poisson-verdeling met een log-link. De outputtabel ziet er hetzelfde uit, maar de interpretatie verandert omdat de koppelfunctie anders is.
Laat me nu de voorspelde waarschijnlijkheden uit de logistische regressie visualiseren tegen overuren:
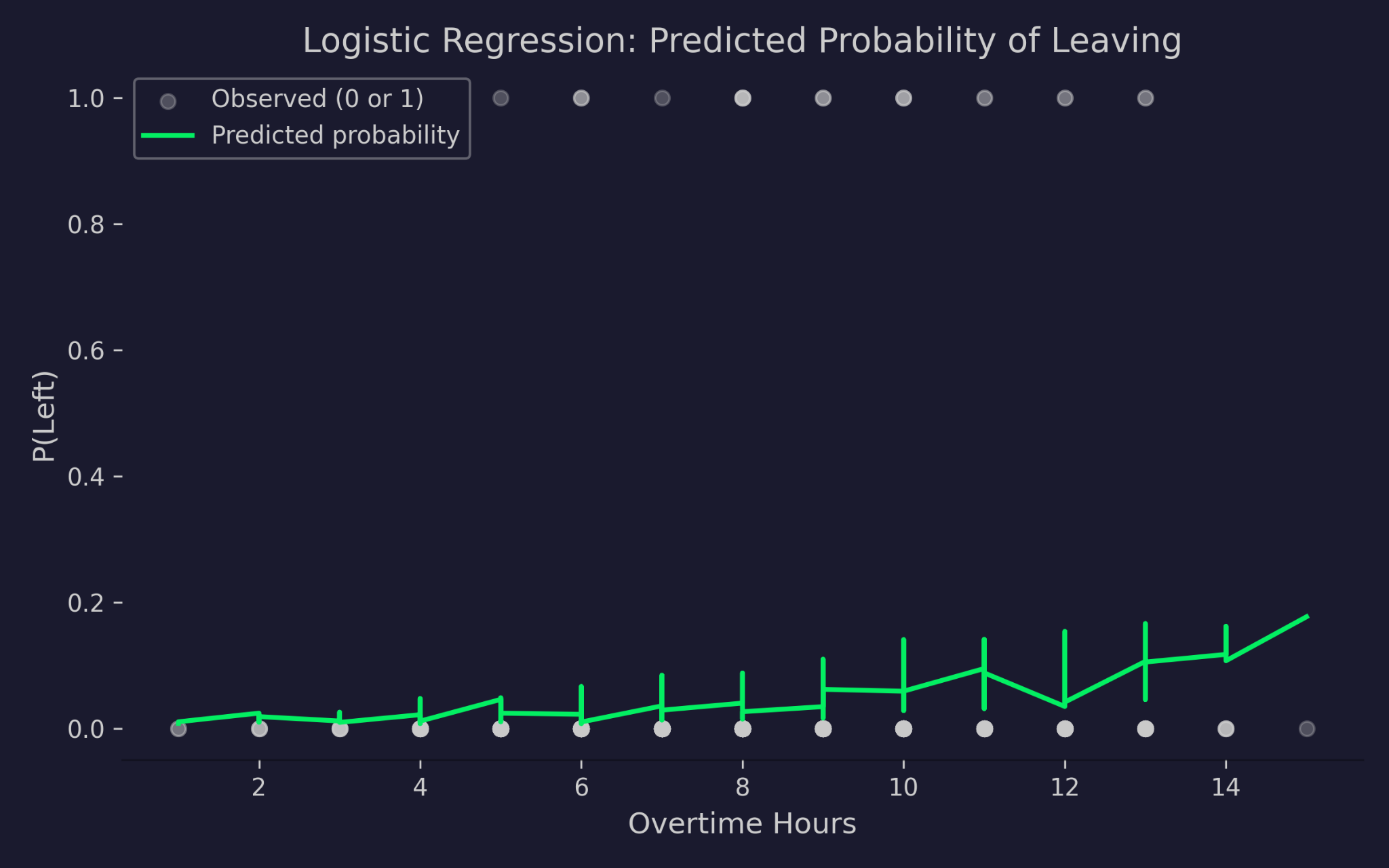
Voorspelde waarschijnlijkheden om het bedrijf te verlaten versus overuren
De grafiek toont overuren op de x-as en de waarschijnlijkheid om te vertrekken op de y-as. De grijze stippen zijn de werkelijke uitkomsten - 0 (gebleven) of 1 (vertrokken). De groene curve is de door het model voorspelde waarschijnlijkheid. Naarmate overuren toenemen, stijgt de voorspelde kans om te vertrekken, maar die daalt nooit onder 0 en overschrijdt nooit 1. Dat is de logit-link in actie - die perst de lineaire voorspeller in een geldig waarschijnlijkheidsbereik, hoe extreem de inputwaarden ook zijn.
R’s ingebouwde functie glm() volgt dezelfde logica maar met een andere syntaxis. Het argument family stelt de verdeling en koppelfunctie in, en je definieert het model met R’s formule-interface.
Hier is dezelfde logistische regressie in R:
# Read the dataset
df <- read.csv("data.csv")
# Fit logistic regression
logit_model <- glm(left ~ salary + experience_years + overtime_hours,
data = df,
family = binomial(link = "logit"))
summary(logit_model)
GLM logistische regressie in R
De formule left ~ salary + experience_years + overtime_hours vertelt R wat er voorspeld moet worden en welke inputs gebruikt worden. Het deel family = binomial(link = "logit") stelt de verdeling en link in. Je kunt dit inkorten tot family = binomial() omdat logit de standaardlink is voor de binomiale familie.
Poisson-regressie is bijna hetzelfde:
poisson_model <- glm(sick_days ~ salary + experience_years + overtime_hours,
data = df,
family = poisson(link = "log"))
summary(poisson_model)
GLM Poisson-regressie in R
Je hoeft alleen binomial() te wijzigen in poisson(), de responsvariabele aan te passen en je bent klaar.
Beide talen gebruiken dezelfde aanpak: je geeft een familie-/verdelingsargument door dat de verdeling en de standaardkoppeling combineert:

Verdeling en link specificeren in Python en R
Elke familie heeft een standaardlink, maar je kunt die overschrijven. In Python kun je een linkobject meegeven: sm.families.Binomial(link=sm.families.links.Probit()). In R verander je simpelweg het link-argument: family = binomial(link = "probit").
Voor de meeste toepassingen is de standaardlink de juiste keuze.
GLM-coëfficiënten betekenen niet hetzelfde tussen verschillende modeltypen. De koppelfunctie bepaalt hoe je ze moet lezen.
In lineaire regressie is de interpretatie eenvoudig. Een coëfficiënt van 500 op experience_years betekent dat elk extra ervaringsjaar 500 aan het voorspelde salaris toevoegt. De identiteitslink betekent dat coëfficiënten direct mappen naar de uitkomst.
Logistische regressie is anders. De logit-link betekent dat coëfficiënten in log-odds-ruimte staan. Een coëfficiënt van 0,12 op overtime_hours betekent niet dat de kans om te vertrekken met 0,12 toeneemt. Het betekent dat de log-odds om te vertrekken met 0,12 toenemen voor elk extra uur overwerk. Voor iets interpreteerbaarders exponentieer je de coëfficiënt: e^0.12 ≈ 1,127. Dit geeft je een oddsratio. Elk extra overuur vermenigvuldigt de odds om te vertrekken met ongeveer 1,13.
Poisson-regressiecoëfficiënten werken via de log-link. Een coëfficiënt van 0,02 op overtime_hours betekent dat elk extra uur de log van het verwachte aantal met 0,02 verhoogt. Als je die exponentieert: e^0.02 ≈ 1,02, zie je dat elk extra overuur het verwachte aantal ziektedagen met ongeveer 1,02 vermenigvuldigt.
Het patroon is dat je altijd de inverse van de koppelfunctie toepast om van coëfficiëntenruimte terug te gaan naar de uitkomstruimte.
De juiste GLM kiezen komt neer op één vraag: hoe ziet je uitkomstvariabele eruit?
Als je uitkomst binair is (ja/nee, 0/1, geslaagd/gezakt), gebruik dan logistische regressie. Binomiale verdeling, logit-link. Dit dekt classificatietaken zoals churnvoorspelling, fraudedetectie, ziekteclassificatie (wel of niet) of of een patiënt op behandeling zal reageren.
Als je uitkomst een aantal is (aantal gebeurtenissen binnen een tijdvenster), gebruik dan Poisson-regressie. Poisson-verdeling, log-link. Dit past bij problemen zoals het voorspellen van het aantal websitebezoeken per uur of verzekeringsclaims per jaar.
Als je uitkomst continu en ongeveer normaal is (omzet, toetsscores), werkt standaard lineaire regressie prima. Normale verdeling, identiteitslink. Dit is de GLM die je al kent.
Begin altijd bij de uitkomstvariabele, koppel die aan een verdeling en dan volgt de koppelfunctie vanzelf.
Hier zijn veelvoorkomende fouten die je moet vermijden bij het werken met GLM’s.
Dit is de meest voorkomende fout. Als je uitkomst een aantal is en je een lineaire regressie fit, krijg je negatieve voorspellingen. Als het binair is en je gebruikt Poisson, slaat het model nergens op. Kijk altijd eerst naar je uitkomstvariabele en kies de verdeling die daarbij past.
De koppelfunctie transformeert de relatie tussen inputs en output. Een logistische regressiecoëfficiënt van 0,5 betekent niet "de waarschijnlijkheid gaat met 0,5 omhoog." Het betekent dat de log-odds met 0,5 toenemen. Als je de transformatie vergeet, trek je verkeerde conclusies over effectgroottes en variabelebelang.
Coëfficiënten in een Poisson-regressie zijn niet vergelijkbaar met coëfficiënten in een logistische regressie, ook al lijken de getallen op elkaar. Een coëfficiënt van 0,3 betekent iets anders afhankelijk van of die door een log-link of een logit-link gaat. Interpreteer coëfficiënten altijd in de context van het specifieke model dat je gebruikt.
GLM’s zijn flexibeler dan lineaire regressie, maar hebben nog steeds aannames. Poisson-regressie gaat ervan uit dat het gemiddelde gelijk is aan de variantie - als je telgegevens veel meer variantie hebben dan het gemiddelde, zijn de standaardfouten te klein en je p-waarden misleidend. Logistische regressie gaat uit van onafhankelijke observaties.
Om dit te ondervangen: controleer na het fitten van een GLM altijd de residuen en zoek naar patronen die op een slechte fit wijzen.
GLM’s geven je een gestructureerde manier om verder te gaan dan lineaire regressie, terwijl je toch de fundamentele logica volgt. Het idee van een lineaire combinatie van inputs blijft hetzelfde, maar de verdeling en koppelfunctie veranderen zodat ze passen bij de data waar je mee werkt.
Er zijn drie componenten achter GLM’s. Zodra je weet hoe je de juiste verdeling kiest, de lineaire voorspeller opzet en de correcte koppelfunctie toepast, kun je binaire uitkomsten, aantallen en continue data aan met hetzelfde denkkader.
De beste volgende stap is om het te proberen. Kies een dataset met een niet-normale uitkomst, fit een GLM in Python of R en oefen met het interpreteren van de coëfficiënten via de koppelfunctie. Gebruik een dataset die je belangrijk vindt, en alle theorie valt binnen een paar minuten op z’n plek.
Wil je verder dan lineaire regressie en GLM’s, schrijf je dan in voor onze Machine Learning Scientist in Python-track. Die laat je alles zien wat je nodig hebt om in 2026 job-ready te zijn.
Leer met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
