Course
Linear Algebra for Data Science in R
4 ч
21.2K
Линейная регрессия — отличный первый вариант модели, но она даёт сбой, как только ваши данные не подчиняются нормальному распределению.
Предположим, вы пытаетесь предсказать, уйдёт ли клиент (исход «да» или «нет»). Линейная регрессия не умеет этого делать. Она предсказывает непрерывные значения, поэтому вы получите выходы вроде -0.3 или 1.7 для величины, которая может быть только 0 или 1. Та же проблема возникает со счётными данными, например количеством обращений в поддержку в час. Линейная регрессия может предсказывать отрицательные значения, что не имеет смысла.
Обобщённые линейные модели (GLM) решают это, расширяя линейную регрессию для работы с разными типами исходов. Суть та же — линейная комбинация входов, — но с гибкостью моделировать бинарные данные и другие ненормальные распределения.
В этой статье я объясню, что такое GLM, разберу три их ключевых компонента и покажу, как обучать и интерпретировать их в Python и R.
А как именно работает линейная регрессия? Прочитайте наше руководство по простой линейной регрессии, чтобы понять её предпосылки и диагностику, а также как интерпретировать результаты.
Обобщённая линейная модель (GLM) — это расширение линейной регрессии, позволяющее отклику следовать разным вероятностным распределениям, а не только нормальному.
Важно помнить, что GLM — это не одна модель, а фреймворк. Линейная регрессия, логистическая регрессия и регрессия Пуассона — это всё GLM. Каждая использует своё распределение и свой способ связи входов с выходами, но все они следуют одной структуре.
Стандартная линейная регрессия делает два крупных допущения: ваш исход нормально распределён, а дисперсия остаётся постоянной по всему диапазону предсказаний. Если эти предпосылки не выполняются, вы получите бессмысленные результаты.
Например, если вы строите модель, предсказывающую дефолт по кредиту, исход бинарный — 0 или 1. Линейная регрессия не уважает эти границы. Она может предсказать -0.2 или 1.4, что невозможно.
Со счётными данными та же история. Если вы предсказываете число повторных госпитализаций в месяц, линейная регрессия может выдавать отрицательные числа. Нельзя иметь -3 повторных госпитализации.
Проблема в обоих случаях не в линейной комбинации входов — эта часть работает нормально. Проблема в том, как модель отображает эти входы в выход. GLM решают это, добавляя функцию связи, которая преобразует выход так, чтобы он попадал в естественный диапазон данных. Вероятности остаются в пределах 0–1. Счётчики остаются неотрицательными. Скоро вы всё это увидите.
Любая GLM состоит из трёх частей: распределение, линейный предиктор и функция связи. Разберём каждую.
Случайная составляющая определяет, какие данные генерирует ваша зависимая переменная. Иными словами, выбирается вероятностное распределение, которое лучше всего описывает исход.
Линейная регрессия предполагает нормальное распределение, поэтому исход непрерывен и симметричен относительно среднего. Но не все данные таковы.
Если исход бинарный (да/нет, 0/1), используют биномиальное распределение. Если вы моделируете счётные данные — например количество ошибок в день, — лучше подходит распределение Пуассона.
Выбор распределения определяет всё остальное в модели.
Систематическая часть — это то, что вы уже знаете по линейной регрессии. Это линейная комбинация входных переменных:
Систематическая составляющая
Где X — матрица входных признаков, а β — вектор коэффициентов. Вы умножаете каждый признак на его вес и суммируете.
Эта часть не меняется между разными GLM. То есть, будь то логистическая регрессия или регрессия Пуассона, линейный предиктор выглядит одинаково.
Функция связи соединяет линейный предиктор с математическим ожиданием отклика. Именно она делает GLM гибкими.
Без функции связи линейный предиктор выдаёт значения от минус до плюс бесконечности. Это подходит для непрерывных исходов, но не для вероятностей или счётчиков. Функция связи преобразует выход так, чтобы он находился в правильном диапазоне для выбранного распределения.
Например, логистическая регрессия использует логит-связь, которая отображает линейный предиктор, принимающий любые вещественные значения, в вероятность между 0 и 1. Регрессия Пуассона использует логарифмическую связь, которая обеспечивает положительность предсказаний.
Полное уравнение GLM объединяет все три компонента:
Уравнение GLM
Где g() — функция связи, а μ — ожидаемое значение отклика. Распределение определяет, что означает μ, линейный предиктор вычисляет Xβ, а функция связи связывает их.
Функция связи определяет, как линейный предиктор преобразуется в исход. Разным типам данных нужны разные преобразования, и у каждого типа GLM есть функция связи по умолчанию, соответствующая его распределению.
Тождественная связь — самая простая: она ничего не делает. Линейный предиктор равен ожидаемому значению отклика:
Тождественная связь
Её использует линейная регрессия. Входы складываются в взвешенную сумму, и эта сумма — предсказание. Преобразование не нужно, потому что исход может принимать любые непрерывные значения.
Логит-связь берёт вероятность (между 0 и 1) и отображает её на всю вещественную прямую:
Логит-связь
Её использует логистическая регрессия. Линейный предиктор может выдавать любые значения от минус до плюс бесконечности, но после обратного преобразования предсказание всегда лежит между 0 и 1. Отношение внутри логарифма — μ/(1-μ) — называется шансами (odds), а логарифм шансов — логит. Поэтому, интерпретируя коэффициенты логистической регрессии, вы работаете в пространстве логитов.
Логарифмическая связь берёт натуральный логарифм математического ожидания:
Логарифмическая связь
Её использует регрессия Пуассона. Линейный предиктор может быть любым вещественным числом, но после возведения в степень (обратное преобразование) предсказание всегда положительно. Это как раз то, что нужно для счётных данных — отрицательных событий не бывает.
GLM могут казаться абстрактными, пока вы не увидите, что это знакомые модели. Линейная, логистическая и пуассоновская регрессии — все это GLM. Разница лишь в сочетаниях распределения и функции связи.
Линейная регрессия — самая простая GLM. Отклик следует нормальному распределению, а функция связи — тождественная, то есть вообще без преобразований.
Линейная регрессия как GLM
Линейный предиктор напрямую равен ожидаемому исходу. Это та GLM, которой вы и так пользовались, просто не называли её так.
Логистическая регрессия моделирует бинарные исходы с биномиальным распределением и логит-связью.
Логистическая регрессия как GLM
Слева — логит шансов события. Справа — стандартная линейная комбинация входов. Логит-связь гарантирует, что предсказания отображаются в вероятности от 0 до 1, независимо от того, насколько велико или мало Xβ.
Регрессия Пуассона моделирует счётные данные с распределением Пуассона и логарифмической связью.
Регрессия Пуассона как GLM
Логарифм ожидаемого счёта равен линейному предиктору. Возведя обе стороны в степень, получим μ = e^(Xβ), что всегда положительно — именно то, что требуется для счётчиков.
GLM не используют метод наименьших квадратов, как линейная регрессия. Вместо этого они опираются на метод максимального правдоподобия (MLE).
Идея проста. MLE находит набор коэффициентов, который делает ваши наблюдаемые данные максимально вероятными при выбранном распределении. Для логистической регрессии он находит коэффициенты, которые делают наблюдаемые 0 и 1 наиболее вероятными при биномиальной модели. Для регрессии Пуассона он находит коэффициенты, которые лучше всего объясняют наблюдаемые счёты.
Для большинства GLM нет аналитического решения, поэтому оптимизация итеративная. Алгоритм начинает с начальной оценки коэффициентов, оценивает, насколько хорошо они описывают данные, корректирует их и повторяет, пока оценки не сойдутся.
Наиболее распространённый метод — итеративные перегруженные наименьшие квадраты (IRLS), которые сводят задачу MLE к последовательности взвешенных линейных регрессий. Также подходят градиентные методы: они вычисляют направление наискорейшего улучшения и делают шаг в эту сторону. Такие библиотеки, как statsmodels и функция R glm(), делают всё это «под капотом», так что вам не нужно реализовывать решатель самостоятельно.
Важно помнить: вы выбираете распределение и функцию связи, а оптимизатор находит наилучшие коэффициенты. Это идея — теперь покажу, как это работает на практике.
В этом разделе я разберу логистическую и пуассоновскую регрессии как в Python, так и в R, используя один и тот же набор данных — сымитированные данные об увольнениях сотрудников со столбцами: зарплата, стаж (годы), сверхурочные часы, факт ухода (бинарный) и число больничных дней (счётчик).
Я создам упомянутый набор данных в Python, а затем использую его для расчётов в Python и R:
import numpy as np
import pandas as pd
np.random.seed(42)
n = 500
# Employee dataset
df = pd.DataFrame({
"salary": np.random.normal(55000, 12000, n).astype(int),
"experience_years": np.random.poisson(5, n),
"overtime_hours": np.random.poisson(8, n),
})
# Simulate binary outcome: left the company
prob_left = 1 / (1 + np.exp(-(
-2 + -0.00003 * df["salary"] + -0.05 * df["experience_years"] + 0.12 * df["overtime_hours"]
)))
df["left"] = np.random.binomial(1, prob_left)
# Simulate count outcome: sick days per year
df["sick_days"] = np.random.poisson(
np.exp(1.2 + 0.00001 * df["salary"] + 0.02 * df["overtime_hours"])
)
# Save to use later in R
df.to_csv("data.csv", index=False)
df.head()
Пример набора данных по увольнениям сотрудников
В Python у вас есть два основных варианта для GLM: statsmodels и scikit-learn. Здесь я использую statsmodels, потому что он предоставляет полный статистический отчёт, включая коэффициенты, p-значения и доверительные интервалы. Всё это нужно при интерпретации GLM.
Вот как можно обучить логистическую регрессию для предсказания ухода сотрудника:
import statsmodels.api as sm
X = sm.add_constant(df[["salary", "experience_years", "overtime_hours"]])
logit_model = sm.GLM(df["left"], X, family=sm.families.Binomial())
logit_results = logit_model.fit()
print(logit_results.summary())
Результаты логистической регрессии GLM
Ключевая строка — sm.families.Binomial(). Она задаёт и распределение (биномиальное), и функцию связи по умолчанию (логит) одним аргументом. Отдельно указывать функцию связи не нужно, если только вы не хотите нестандартную.
Теперь обучим регрессию Пуассона на том же наборе для предсказания больничных дней:
poisson_model = sm.GLM(df["sick_days"], X, family=sm.families.Poisson())
poisson_results = poisson_model.fit()
print(poisson_results.summary())
Результаты регрессии Пуассона GLM
Достаточно заменить Binomial() на Poisson() — и модель использует распределение Пуассона с логарифмической связью. Таблица на выходе выглядит так же, но интерпретация меняется, потому что изменилась функция связи.
Теперь визуализирую предсказанные вероятности логистической регрессии в зависимости от сверхурочных часов:
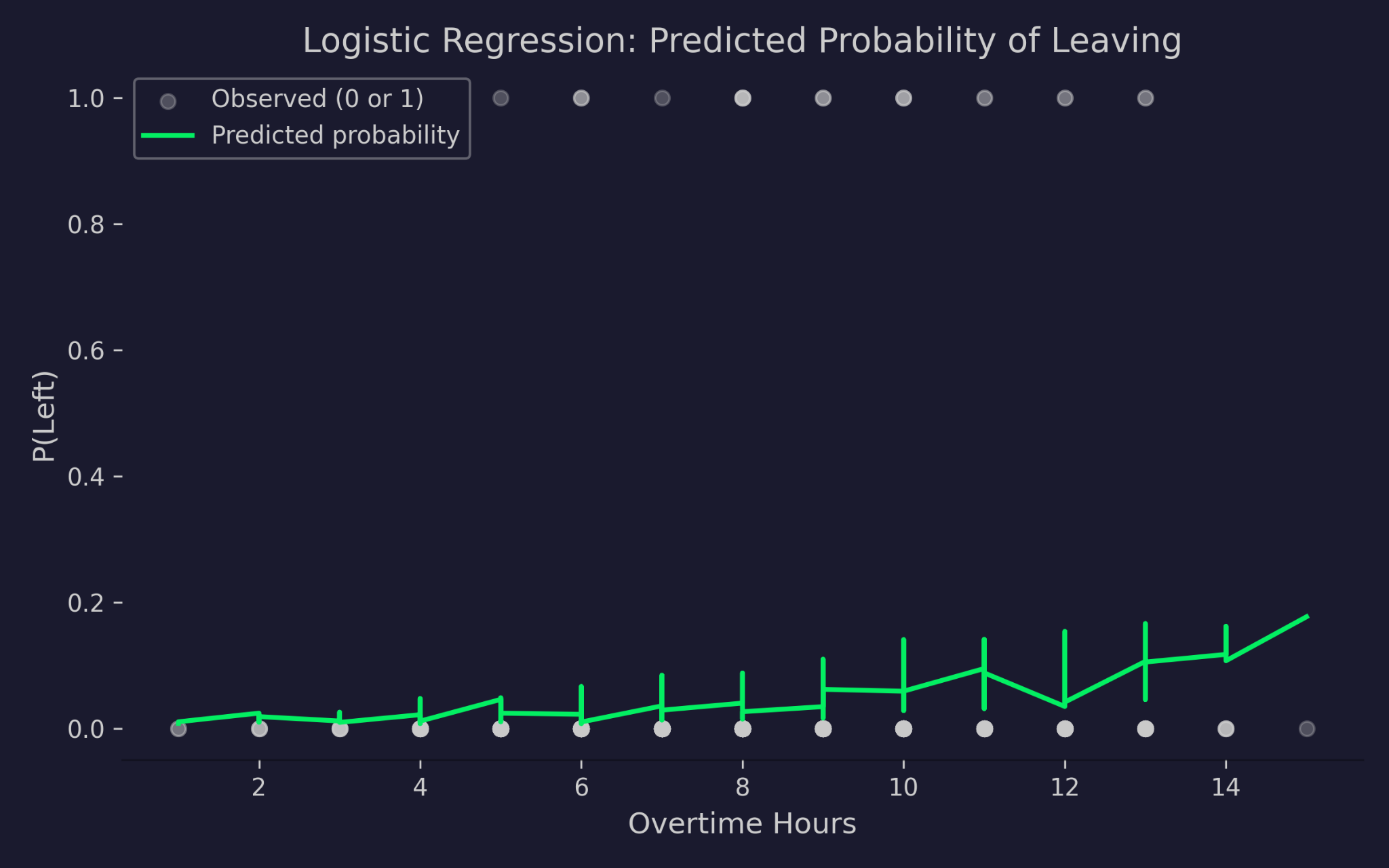
Предсказанные вероятности ухода из компании в зависимости от сверхурочных часов
На графике по оси X — сверхурочные часы, по оси Y — вероятность ухода. Серые точки — фактические исходы: 0 (остался) или 1 (ушёл). Зелёная кривая — предсказанная моделью вероятность. По мере роста сверхурочных часов предсказанная вероятность ухода увеличивается, но никогда не опускается ниже 0 и не превышает 1. Это работа логит-связи: она «сжимает» линейный предиктор в допустимый диапазон вероятностей, как бы ни экстремальны были входы.
Встроенная функция R glm() следует той же логике, но с иной синтаксической формой. Аргумент family задаёт распределение и функцию связи, а модель определяется через формульный интерфейс R.
Вот та же логистическая регрессия в R:
# Read the dataset
df <- read.csv("data.csv")
# Fit logistic regression
logit_model <- glm(left ~ salary + experience_years + overtime_hours,
data = df,
family = binomial(link = "logit"))
summary(logit_model)
Логистическая регрессия GLM в R
Формула left ~ salary + experience_years + overtime_hours сообщает R, что предсказывать и какие входы использовать. Часть family = binomial(link = "logit") задаёт распределение и связь. Можно сократить до family = binomial(), так как логит — связь по умолчанию для биномиального семейства.
Регрессия Пуассона настраивается почти так же:
poisson_model <- glm(sick_days ~ salary + experience_years + overtime_hours,
data = df,
family = poisson(link = "log"))
summary(poisson_model)
Регрессия Пуассона GLM в R
Нужно просто поменять binomial() на poisson(), сменить зависимую переменную — и готово.
Оба языка используют один подход: вы передаёте «семейство»/распределение, которое сочетает распределение и его связь по умолчанию:

Задание распределения и связи в Python и R
У каждого семейства есть связь по умолчанию, но вы можете её переопределить. В Python можно передать объект связи: sm.families.Binomial(link=sm.families.links.Probit()). В R — просто изменить аргумент link: family = binomial(link = "probit").
В большинстве случаев связь по умолчанию — правильный выбор.
Коэффициенты GLM не означают одно и то же для разных типов моделей. Функция связи меняет их интерпретацию.
В линейной регрессии всё просто. Коэффициент 500 при experience_years означает, что каждый дополнительный год стажа добавляет 500 к предсказанной зарплате. Тождественная связь означает прямое соответствие коэффициентов исходу.
С логистической регрессией иначе. Логит-связь означает, что коэффициенты выражены в пространстве логитов/лог-шансов. Коэффициент 0.12 при overtime_hours не означает, что вероятность ухода растёт на 0.12. Это означает, что лог-шансы ухода увеличиваются на 0.12 при каждом дополнительном часу сверхурочной работы. Чтобы получить более интерпретируемую величину, возведите коэффициент в степень: e^0.12 ≈ 1.127. Это отношение шансов: каждый дополнительный час сверхурочной работы умножает шансы ухода примерно на 1.13.
Коэффициенты регрессии Пуассона работают через логарифмическую связь. Коэффициент 0.02 при overtime_hours означает, что каждый дополнительный час увеличивает логарифм ожидаемого счёта на 0.02. Возведя его в степень: e^0.02 ≈ 1.02, вы увидите, что каждый дополнительный час сверхурочной работы умножает ожидаемое число больничных дней примерно на 1.02.
Общий приём — всегда применять обратную функцию связи, чтобы перейти из пространства коэффициентов обратно в пространство исхода.
Выбор подходящей GLM сводится к одному вопросу: как выглядит ваша зависимая переменная?
Если исход бинарный (да/нет, 0/1, сдал/не сдал), используйте логистическую регрессию. Биномиальное распределение, логит-связь. Это покрывает задачи классификации: прогноз оттока, обнаружение мошенничества, классификация заболеваний (есть/нет) или отклик на лечение.
Если исход — это счёт (число событий за интервал времени), используйте регрессию Пуассона. Распределение Пуассона, логарифмическая связь. Это подходит для задач вроде прогноза посещений сайта в час или страховых заявок в год.
Если исход непрерывный и примерно нормальный (выручка, результаты тестов), стандартная линейная регрессия подойдёт. Нормальное распределение, тождественная связь. Это та GLM, которую вы уже знаете.
Всегда начинайте с зависимой переменной, сопоставьте её с распределением, а функция связи последует из него.
Вот распространённые ошибки, которых стоит избегать при работе с GLM.
Это самая частая ошибка. Если ваш исход — счёт, а вы подбираете линейную регрессию, получите отрицательные предсказания. Если исход бинарный, а вы используете Пуассона, модель будет бессмыслена. Всегда сначала смотрите на зависимую переменную и выбирайте соответствующее ей распределение.
Функция связи преобразует отношение между входами и исходом. Коэффициент 0.5 в логистической регрессии не означает «вероятность выросла на 0.5». Это означает рост лог-шансов на 0.5. Игнорирование преобразования ведёт к неверным выводам о размерах эффектов и важности переменных.
Коэффициенты в регрессии Пуассона несопоставимы с коэффициентами в логистической регрессии, даже если числа выглядят схоже. Коэффициент 0.3 означает разное в зависимости от того, проходит ли он через логарифмическую или логит-связь. Всегда интерпретируйте коэффициенты в контексте конкретной модели.
GLM гибче линейной регрессии, но у них тоже есть предпосылки. Регрессия Пуассона предполагает равенство среднего и дисперсии — если дисперсия у ваших счётных данных гораздо больше среднего, стандартные ошибки модели будут занижены, а p-значения — вводить в заблуждение. Логистическая регрессия предполагает независимость наблюдений.
Чтобы это преодолеть, после подгонки любой GLM проверьте остатки и ищите паттерны, указывающие на плохое соответствие.
GLM дают структурированный способ выйти за рамки линейной регрессии, сохраняя её базовую логику. Идея линейной комбинации входов остаётся, но распределение и функция связи меняются, подстраиваясь под ваши данные.
За GLM стоят три компонента. Освоив выбор подходящего распределения, настройку линейного предиктора и применение корректной функции связи, вы сможете одинаково осмысленно работать с бинарными исходами, счётчиками и непрерывными данными.
Лучший следующий шаг — попробовать. Возьмите набор данных с ненормальным исходом, обучите GLM в Python или R и потренируйтесь интерпретировать коэффициенты через функцию связи. Используйте данные, которые вам небезразличны, — и вся теория быстро «встанет на места».
Если хотите выйти за рамки линейной регрессии и GLM, запишитесь на наш трек Machine Learning Scientist in Python. Он покажет всё, что нужно, чтобы быть готовым к работе в 2026 году.
Учитесь с DataCamp
Course
Course
Course