
Kurs
R ile Veri Bilimi için Lineer Cebir
4 sa
21.2K
Doğrusal regresyon denemek için harika bir ilk modeldir, ancak verileriniz normal dağılıma uymadığı anda yetersiz kalır.
Diyelim ki bir müşterinin terk edip etmeyeceğini (evet veya hayır sonucu) tahmin etmeye çalışıyorsunuz. Doğrusal regresyon bunu yapmayı bilmez. Sürekli değerler tahmin eder, bu yüzden yalnızca 0 veya 1 olabilen bir şey için -0.3 veya 1.7 gibi çıktılar elde edersiniz. Aynı sorun, saat başına destek bileti sayısı gibi sayım verilerinde de ortaya çıkar. Doğrusal regresyon negatif sayımlar tahmin edebilir ki bunun bir anlamı yoktur.
Genelleştirilmiş doğrusal modeller (GLM’ler), farklı türde sonuçları ele alacak şekilde doğrusal regresyonu genişleterek bunu düzeltir. Temel fikir aynıdır – girdilerin doğrusal bir birleşimi – ancak ikili verileri ve diğer normal olmayan dağılımları modelleme esnekliğine sahiptir.
Bu makalede GLM’lerin ne olduğunu açıklayacak, üç temel bileşenini adım adım ele alacak ve hem Python hem de R’da nasıl uydurulup yorumlanacaklarını göstereceğim.
Peki doğrusal regresyon tam olarak nasıl çalışır? Varsayımlarını ve tanılarını ve sonuçların nasıl yorumlanacağını öğrenmek için Basit Doğrusal Regresyon rehberimizi okuyun.
Genelleştirilmiş doğrusal model (GLM), yanıt değişkeninin yalnızca normal dağılım değil, farklı olasılık dağılımlarını da takip etmesine olanak tanıyan doğrusal regresyonun bir uzantısıdır.
Burada akılda tutulması gereken ana nokta, GLM’nin tek bir model olmadığıdır. Bu bir çerçevedir. Doğrusal regresyon, lojistik regresyon ve Poisson regresyonu, hepsi GLM’dir. Her biri farklı bir dağılım ve girdileri çıktılara bağlamanın farklı bir yolunu kullanır, ancak hepsi aynı yapıyı takip eder.
Standart doğrusal regresyon iki büyük varsayım yapar: sonucunuz normal dağılır ve varyans tahminler boyunca sabit kalır. Bu varsayımlar sağlanmazsa, hiçbir anlam ifade etmeyen sonuçlar elde edersiniz.
Örneğin, bir kredi başvuru sahibinin temerrüde düşüp düşmeyeceğini tahmin eden bir model kuruyorsanız, sonuç ikilidir – 0 veya 1. Doğrusal regresyon bu sınırları gözetmez. Hem -0.2 hem de 1.4 gibi imkânsız değerleri tahmin edebilir.
Sayım verileri de aynı soruna sahiptir. Aylık yeniden yatış sayısını tahmin ediyorsanız, doğrusal regresyon negatif sayılar verebilir. -3 yeniden yatış olamaz.
Her iki durumda da sorun, girdilerin doğrusal birleşimi değildir – o kısım gayet iyi çalışır. Sorun, modelin bu girdileri çıktıya nasıl eşlediğidir. GLM’ler, çıktıyı verinin doğal aralığına uyduracak şekilde dönüştüren bir bağ (link) fonksiyonu ekleyerek bunu çözer. Olasılıklar 0 ile 1 arasında kalır. Sayımlar negatif olmaz. Az sonra hepsini göreceksiniz.
Her GLM üç kısımdan oluşur: bir dağılım, bir doğrusal yordayıcı ve bir bağ fonksiyonu. Her birini açıklayayım.
Rastgele bileşen, yanıt değişkeninizin ne tür veri ürettiğini tanımlar. Başka bir deyişle, sonucunuzu en iyi tanımlayan olasılık dağılımını seçer.
Doğrusal regresyon normal dağılım varsayar, bu nedenle sonuç süreklidir ve ortalama etrafında simetriktir. Ancak tüm veriler böyle davranmaz.
Sonucunuz ikiliyse (evet/hayır, 0/1), binom dağılımı kullanırsınız. Sayım verilerini – örneğin gün başına hata sayısını – modelliyorsanız, Poisson dağılımı daha uygundur.
Seçtiğiniz dağılım, modeldeki diğer her şeyi kontrol eder.
Sistematik bileşen, doğrusal regresyondan zaten bildiğiniz kısımdır. Girdi değişkenlerinizin doğrusal bir birleşimidir:
Sistematik bileşen
Burada X özellikler matrisinizdir ve β katsayı vektörüdür. Her özelliği kendi ağırlığıyla çarpar ve toplarsınız.
Bu kısım farklı GLM’ler arasında değişmez. Başka bir deyişle, lojistik regresyon ya da Poisson regresyonu uyduruyor olun, doğrusal yordayıcı aynı görünür.
Bağ fonksiyonu, doğrusal yordayıcıyı yanıt değişkeninin beklenen değerine bağlar. GLM’leri esnek kılan parça budur.
Bir bağ fonksiyonu olmadan doğrusal yordayıcı, eksi sonsuzluktan artı sonsuzluğa kadar değerler üretir. Bu, sürekli sonuçlar için uygundur, ancak olasılıklar veya sayımlar için değil. Bağ fonksiyonu, tahminin seçtiğiniz dağılım için doğru aralıkta olmasını sağlayacak şekilde çıktıyı dönüştürür.
Örneğin lojistik regresyon logit bağını kullanır; bu, herhangi bir gerçek sayı olabilen doğrusal yordayıcıyı 0 ile 1 arasındaki bir olasılığa eşler. Poisson regresyonu ise log bağını kullanır ve tahminlerin her zaman pozitif olmasını sağlar.
Tam GLM denklemi bu üç bileşeni birleştirir:
GLM denklemi
Burada g() bağ fonksiyonudur ve μ yanıtın beklenen değeridir. Dağılım, μnun ne anlama geldiğini tanımlar, doğrusal yordayıcı Xβyı hesaplar ve bağ fonksiyonu ikisi arasında köprü kurar.
Bağ fonksiyonu, doğrusal yordayıcının sonuca nasıl dönüştüğünü belirler. Farklı veri türlerinin farklı dönüşümlere ihtiyacı vardır ve her GLM türünün dağılımıyla eşleşen varsayılan bir bağ fonksiyonu bulunur.
Birim bağı en basitidir – hiçbir şey yapmaz. Doğrusal yordayıcı, yanıtın beklenen değerine eşittir:
Birim bağı
Doğrusal regresyonun kullandığı şey budur. Girdileriniz ağırlıklı bir toplamda birleşir ve bu toplam tahmindir. Herhangi bir dönüşüm gerekmez çünkü sonuç herhangi bir sürekli değer alabilir.
Logit bağı, bir olasılığı (0 ile 1 arasında) tüm gerçek sayı doğrusuna eşler:
Logit bağı
Lojistik regresyonun kullandığı şey budur. Doğrusal yordayıcı eksi sonsuzluktan artı sonsuzluğa kadar herhangi bir değer üretebilir, ancak ters dönüşümden sonra tahmin her zaman 0 ile 1 arasında kalır. Logaritma içindeki o oran – μ/(1-μ) – "olasılık oranı"dır (odds) ve bunun logaritması log-odds’tur. Dolayısıyla lojistik regresyon katsayılarını yorumlarken log-odds uzayında çalışırsınız.
Log bağı, beklenen değerin doğal logaritmasını alır:
Log bağı
Poisson regresyonunun kullandığı şey budur. Doğrusal yordayıcı herhangi bir gerçek sayı olabilir, ancak geri üsselendirildiğinde (ters dönüşüm), tahmin her zaman pozitiftir. Bu, negatif olayların olamayacağı sayım verileri için tam olarak ihtiyacınız olan şeydir.
GLM’ler, onları zaten bildiğiniz modellere dönüştürmeden soyut gelebilir. Doğrusal regresyon, lojistik regresyon ve Poisson regresyonu, hepsi GLM’dir. Tek fark, her birinin farklı bir dağılım ve bağ fonksiyonu kombinasyonu kullanmasıdır.
Doğrusal regresyon en basit GLM’dir. Yanıt normal dağılımı izler ve bağ fonksiyonu, yani herhangi bir dönüşüm olmayan birim bağıdır.
Bir GLM olarak doğrusal regresyon
Doğrusal yordayıcı, beklenen sonuca doğrudan eşittir. Aslında baştan beri kullandığınız GLM budur, sadece adını böyle koymamıştınız.
Lojistik regresyon, ikili sonuçları binom dağılımı ve logit bağı ile modeller.
Bir GLM olarak lojistik regresyon
Sol taraf olayın log-odds’udur. Sağ taraf, girdilerin standart doğrusal birleşimidir. Logit bağı, Xβ ne kadar büyük ya da küçük olursa olsun, tahminlerin 0 ile 1 arasındaki olasılıklara eşlenmesini sağlar.
Poisson regresyonu, sayım verilerini Poisson dağılımı ve log bağı ile modeller.
Bir GLM olarak Poisson regresyonu
Beklenen sayının logu, doğrusal yordayıcıya eşittir. Her iki tarafı da üsselendirirseniz μ = e^(Xβ) elde edersiniz; bu her zaman pozitiftir – sayımların tam da gerektirdiği şey.
GLM’ler, doğrusal regresyon gibi en küçük kareler yöntemini kullanmaz. Bunun yerine en çok olabilirlik kestirimi (MLE)ne dayanırlar.
Fikir basittir. MLE, seçilen dağılım altında gözlemlenen verilerinizi en olası kılan katsayı kümesini bulur. Lojistik regresyon için, binom modele göre gözlenen 0 ve 1’leri en olası kılan katsayıları bulur. Poisson regresyonu için, gözlenen sayımları en iyi açıklayan katsayıları bulur.
Çoğu GLM için kapalı formda bir çözüm yoktur, bu nedenle en iyileme yinelemelidir. Algoritma, katsayılar için bir başlangıç tahminiyle başlar, veriye ne kadar iyi uyduklarını değerlendirir, ayarlar ve tahminler yakınsayana kadar tekrarlar.
En yaygın yöntem yinelemeli ağırlıklandırılmış en küçük kareler (IRLS)tir; bu yöntem, MLE problemini bir dizi ağırlıklı doğrusal regresyon olarak yeniden formüle eder. Gradyan tabanlı yöntemler de çalışır; en dik iyileşme yönünü hesaplayıp o yöne adım atarlar. statsmodels ve R’ın glm() gibi kütüphaneler tüm bunları arka planda yapar, bu yüzden çözücüyü kendiniz uygulamanız gerekmez.
Unutulmaması gereken şey, dağılımı ve bağ fonksiyonunu sizin seçtiğiniz, eniyileyicinin ise en iyi katsayıları bulduğudur. Fikir bu – şimdi size bunun pratikte nasıl işlediğini göstereyim.
Bu bölümde, aynı veri kümesini kullanarak – maaş, deneyim yılı, mesai saati, çalışanın ayrılıp ayrılmadığı (ikili) ve alınan hastalık izni sayısı (sayım) sütunlarına sahip simüle edilmiş bir çalışan devri veri seti – hem Python hem de R’da lojistik ve Poisson regresyonunu adım adım ele alacağım.
Belirtilen veri kümesini Python’da oluşturacak ve ardından hem Python hem de R’da hesaplamalar için kullanacağım:
import numpy as np
import pandas as pd
np.random.seed(42)
n = 500
# Employee dataset
df = pd.DataFrame({
"salary": np.random.normal(55000, 12000, n).astype(int),
"experience_years": np.random.poisson(5, n),
"overtime_hours": np.random.poisson(8, n),
})
# Simulate binary outcome: left the company
prob_left = 1 / (1 + np.exp(-(
-2 + -0.00003 * df["salary"] + -0.05 * df["experience_years"] + 0.12 * df["overtime_hours"]
)))
df["left"] = np.random.binomial(1, prob_left)
# Simulate count outcome: sick days per year
df["sick_days"] = np.random.poisson(
np.exp(1.2 + 0.00001 * df["salary"] + 0.02 * df["overtime_hours"])
)
# Save to use later in R
df.to_csv("data.csv", index=False)
df.head()
Örnek çalışan devri veri seti
Python size GLM’ler için iki ana seçenek sunar: statsmodels ve scikit-learn. Burada statsmodels kullanacağım çünkü size katsayılar, p-değerleri ve güven aralıkları dahil tam bir istatistiksel özet sunar. Bir GLM’i yorumlarken bunlara ihtiyacınız olacak.
Bir çalışanın ayrılıp ayrılmadığını tahmin etmek için lojistik regresyonu şu şekilde uydurabilirsiniz:
import statsmodels.api as sm
X = sm.add_constant(df[["salary", "experience_years", "overtime_hours"]])
logit_model = sm.GLM(df["left"], X, family=sm.families.Binomial())
logit_results = logit_model.fit()
print(logit_results.summary())
GLM lojistik regresyon sonuçları
Temel satır sm.families.Binomial() ifadesidir. Bu, tek bir argümanla hem dağılımı (binom) hem de varsayılan bağ fonksiyonunu (logit) ayarlar. Varsayılandan farklı bir bağ istemedikçe bağ fonksiyonunu ayrıca belirtmeniz gerekmez.
Şimdi aynı veri setinde hastalık izni günlerini tahmin etmek için bir Poisson regresyonu uyduralım:
poisson_model = sm.GLM(df["sick_days"], X, family=sm.families.Poisson())
poisson_results = poisson_model.fit()
print(poisson_results.summary())
GLM Poisson regresyon sonuçları
Sadece Binomial() yerine Poisson() kullanmanız yeterlidir ve model, log bağıyla birlikte bir Poisson dağılımı kullanır. Çıktı tablosu aynı görünür, ancak bağ fonksiyonu değiştiği için yorumlama değişir.
Şimdi de lojistik regresyondan tahmin edilen olasılıkları mesai saatlerine karşı görselleştireyim:
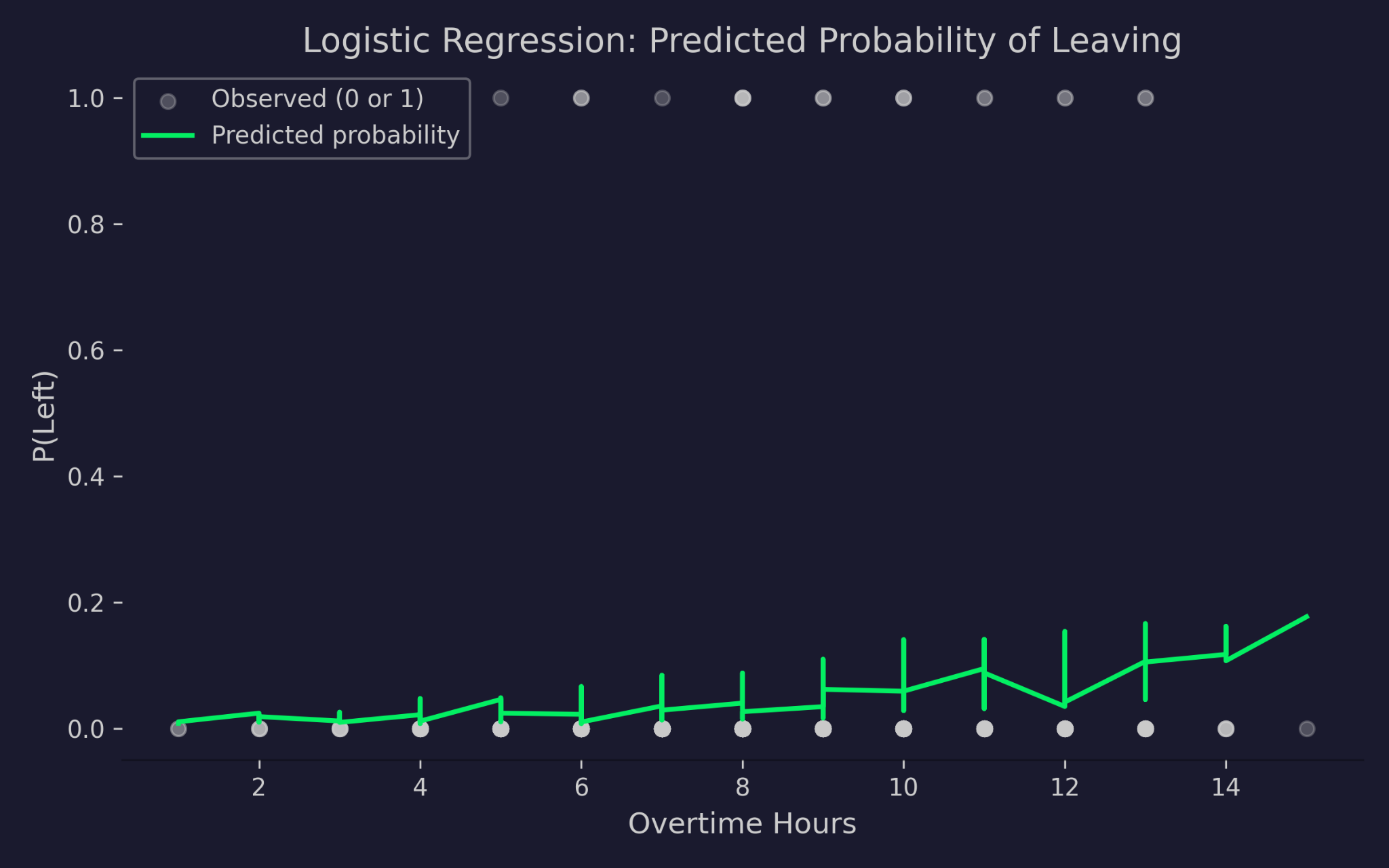
Mesai saatlerine karşı şirketten ayrılma için tahmin edilen olasılıklar
Grafik, x ekseninde mesai saatlerini, y ekseninde ayrılma olasılığını gösterir. Gri noktalar gerçek sonuçlardır – 0 (kaldı) veya 1 (ayrıldı). Yeşil eğri, modelin tahmin ettiği olasılıktır. Mesai saatleri arttıkça ayrılma olasılığı artar, ancak asla 0’ın altına inmez veya 1’in üzerine çıkmaz. Bu, logit bağ fonksiyonunun etkisidir – doğrusal yordayıcıyı, girdi değerleri ne kadar uç olursa olsun, geçerli bir olasılık aralığına sıkıştırır.
R’ın yerleşik glm() fonksiyonu aynı mantığı izler ancak farklı bir sözdizimine sahiptir. family argümanı dağılımı ve bağ fonksiyonunu ayarlar ve modeli R’ın formül arayüzüyle tanımlarsınız.
İşte R’da aynı lojistik regresyon:
# Read the dataset
df <- read.csv("data.csv")
# Fit logistic regression
logit_model <- glm(left ~ salary + experience_years + overtime_hours,
data = df,
family = binomial(link = "logit"))
summary(logit_model)
R’da GLM lojistik regresyon
left ~ salary + experience_years + overtime_hours formülü, R’a neyin tahmin edileceğini ve hangi girdilerin kullanılacağını söyler. family = binomial(link = "logit") kısmı dağılımı ve bağı ayarlar. Bunu family = binomial() olarak kısaltabilirsiniz; çünkü binom ailesi için varsayılan bağ logit’tir.
Poisson regresyonu büyük ölçüde aynıdır:
poisson_model <- glm(sick_days ~ salary + experience_years + overtime_hours,
data = df,
family = poisson(link = "log"))
summary(poisson_model)
R’da GLM Poisson regresyonu
Sadece binomial() yerine poisson() ile değiştirmeniz, yanıt değişkenini değiştirmeniz yeterlidir; işlem tamam.
Her iki dil de aynı yaklaşımı kullanır – dağılımı ve onun varsayılan bağ fonksiyonunu birleştiren bir aile/dağılım argümanı geçersiniz:

Python ve R’da dağılım ve bağ belirtme
Her ailenin bir varsayılan bağı vardır, ancak bunu geçersiz kılabilirsiniz. Python’da bir bağ nesnesi geçebilirsiniz: sm.families.Binomial(link=sm.families.links.Probit()). R’da sadece link argümanını değiştirin: family = binomial(link = "probit").
Çoğu kullanım durumu için varsayılan bağ doğru seçimdir.
GLM katsayıları farklı model türleri arasında aynı şeyi ifade etmez. Bağ fonksiyonu, onları nasıl yorumlayacağınızı değiştirir.
Doğrusal regresyonda yorumlama kolaydır. experience_years üzerinde 500’lük bir katsayı, her ek deneyim yılının tahmin edilen maaşa 500 eklediği anlamına gelir. Birim bağı, katsayıların doğrudan sonuca eşlendiği anlamına gelir.
Lojistik regresyon farklıdır. Logit bağı, katsayıların log-odds uzayında olduğu anlamına gelir. overtime_hours üzerinde 0.12’lik bir katsayı, ayrılma olasılığının 0.12 artması anlamına gelmez. Her ek mesai saati için ayrılmanın log-odds’unun 0.12 arttığı anlamına gelir. Daha yorumlanabilir bir şeye ulaşmak için katsayıyı üsselendirin: e^0.12 ≈ 1.127. Bu size bir odds oranı verir. Her ek mesai saati, ayrılma odds’unu yaklaşık 1.13 ile çarpar.
Poisson regresyonu katsayıları log bağı üzerinden işler. overtime_hours üzerinde 0.02’lik bir katsayı, her ek saatin beklenen sayımın logunu 0.02 artırdığı anlamına gelir. Üsselendirdiğinizde: e^0.02 ≈ 1.02, her ek mesai saatinin beklenen hastalık izni sayısını yaklaşık 1.02 ile çarptığını görürsünüz.
Desen şudur: Katsayı uzayından sonuç uzayına geçmek için her zaman bağ fonksiyonunun tersini uygulayın.
Doğru GLM’i seçmek tek bir soruya bağlıdır: sonuç değişkeniniz nasıl görünüyor?
Sonucunuz ikili ise (evet/hayır, 0/1, geçti/kaldı), lojistik regresyon kullanın. Binom dağılımı, logit bağı. Bu, müşteri kaybını tahmin etme, sahtekârlık tespiti, hastalık sınıflandırması (var/yok) veya bir hastanın tedaviye yanıt verip vermeyeceği gibi sınıflandırma görevlerini kapsar.
Sonucunuz bir sayım ise (bir zaman penceresindeki olay sayısı), Poisson regresyonu kullanın. Poisson dağılımı, log bağı. Bu, saatlik web sitesi ziyaret sayısını veya yıllık sigorta taleplerini tahmin etmek gibi problemler için uygundur.
Sonucunuz sürekli ve kabaca normalse (gelir, test puanları), standart doğrusal regresyon gayet iyi iş görür. Normal dağılım, birim bağı. Bu, zaten bildiğiniz GLM’dir.
Her zaman sonuç değişkeninden başlayın, onu bir dağılımla eşleştirin ve ardından bağ fonksiyonu kendiliğinden gelir.
GLM’lerle çalışırken kaçınmanız gereken bazı yaygın hatalar şunlardır.
Bu en yaygın hatadır. Sonucunuz bir sayımken doğrusal regresyon uydurursanız, negatif tahminler elde edersiniz. İkiliyken Poisson kullanırsanız, model anlamlı olmayacaktır. Her zaman önce sonuç değişkeninize bakın ve ona uyan dağılımı seçin.
Bağ fonksiyonu, girdiler ile çıktı arasındaki ilişkiyi dönüştürür. Lojistik regresyonda 0.5’lik bir katsayı "olasılık 0.5 artar" demek değildir. "Log-odds 0.5 artar" demektir. Dönüşümü unutmak, etki büyüklükleri ve değişken önemine dair yanlış sonuçlara yol açar.
Poisson regresyonundaki katsayılar, sayılar benzer görünse bile lojistik regresyondaki katsayılarla karşılaştırılamaz. 0.3’lük bir katsayı, log ya da logit bağı üzerinden geçip geçmediğine bağlı olarak farklı anlamlara gelir. Katsayıları her zaman kullandığınız belirli modelin bağlamında yorumlayın.
GLM’ler doğrusal regresyondan daha esnektir, ancak yine de varsayımları vardır. Poisson regresyonu, ortalamanın varyansa eşit olduğunu varsayar – sayım verilerinizin ortalamadan çok daha büyük bir varyansı varsa, modelin standart hataları çok küçük olur ve p-değerleriniz yanıltıcı olur. Lojistik regresyon, gözlemlerin bağımsız olduğunu varsayar.
Bunun üstesinden gelmek için, herhangi bir GLM’i uydurduktan sonra artık değerlere (residual) bakın ve kötü uyumu işaret eden desenleri arayın.
GLM’ler, doğrusal regresyonun ötesine yapılandırılmış bir şekilde geçmenizi sağlar, ancak temel mantığını korur. Girdilerin doğrusal birleşimi fikri aynı kalır, fakat çalıştığınız veriye uyması için dağılım ve bağ fonksiyonu değişir.
GLM’lerin arkasında üç bileşen vardır. Doğru dağılımı nasıl seçeceğinizi, doğrusal yordayıcıyı nasıl kuracağınızı ve doğru bağ fonksiyonunu nasıl uygulayacağınızı bildiğinizde, aynı zihinsel modelle ikili sonuçları, sayımları ve sürekli verileri ele alabilirsiniz.
En iyi sonraki adım denemektir. Normal olmayan bir sonuca sahip bir veri seti seçin, Python veya R’da bir GLM uydurun ve katsayıları bağ fonksiyonu üzerinden yorumlama pratiği yapın. Önemsediğiniz bir veri seti kullanın; konuşulan tüm teori birkaç dakika içinde yerine oturacaktır.
Doğrusal regresyon ve GLM’lerin ötesine geçmek isterseniz, Python ile Makine Öğrenimi Bilimcisi programımıza kaydolun. 2026’da işe hazır olmanız için gereken her şeyi gösterir.
DataCamp ile öğrenin
Kurs
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
