
Course
Prompt Engineering with the OpenAI API
4 hr
47.9K
Imagine having a brilliant friend who is incredibly good at solving complex problems. However, every time you ask this friend a new question, the process must begin from scratch, with everything learned from previous problems completely forgotten.
This would be quite frustrating, right? That's exactly the challenge we face with large language models (LLMs) when it comes to complex reasoning tasks. LLMs excel at generating text but often struggle with complex reasoning tasks due to their inability to retain knowledge from past interactions.
Imagine, however, giving these LLMs a "mental notebook" to store and reuse valuable insights – this is the essence of the Buffer of Thoughts (BoT) framework.
In this tutorial, we’ll explore Buffer of Thoughts (BoT), a new framework that's changing how LLMs solve complex problems. I'll start by explaining the basic ideas behind BoT, including the meta-buffer and buffer manager. Then, we'll look at how BoT works step-by-step, from understanding the problem to finding and using the right thought-templates—you'll see how BoT makes LLMs more accurate, efficient, and reliable.
I'll also share some impressive experiment results from this paper that show how well BoT performs on different tasks. By the end of this tutorial, you'll understand why BoT is a big deal at the moment and how it can be used in real-world applications.
Buffer of Thoughts (BoT) is a new framework designed to improve the reasoning capabilities of LLMs.
BoT combines two main elements to guide LLMs through complex reasoning tasks:
Let’s look at these two components in more detail.
The meta-buffer is like a library of universal problem-solving strategies. It stores "thought-templates," which are high-level approaches to solving problems. These templates come from different tasks the LLM has encountered.
Think of it as a toolbox filled with versatile tools that can be adapted to many different jobs.
The buffer manager is the dynamic organizer of the BoT system. Its role includes updating the meta-buffer with new thought-templates as more tasks are solved, selecting the most relevant thought-templates for each new problem, and refining existing templates based on their effectiveness.
It's like having a personal assistant who constantly organizes your notes, highlights the most useful information, and helps you apply it to new challenges.
The real magic happens through the thought-augmented reasoning. When faced with a new problem, the BoT framework:
1. Analyzes the problem to understand its key elements.
2. Retrieves relevant thought-templates from the meta-buffer.
3. Adapts these templates to create a specific reasoning structure for the problem.
4. Guides the LLM through the problem-solving process using this structure.
Imagine you are a chef. The meta-buffer would be your personal cookbook. This cookbook doesn't just contain specific recipes but also a variety of cooking techniques. For example, it has sections on how to properly sauté vegetables, create the perfect reduction sauce or balance flavors. These high-level strategies can be applied to a wide range of dishes.
Now, imagine you also have a sous-chef who is extremely organized and knowledgeable. This sous-chef is your buffer manager. They help you by deciding which techniques from your cookbook are best suited for the dish you're currently preparing. As you cook, the sous-chef takes notes on what worked well and what didn’t, updating your techniques and strategies accordingly.
When a new order comes in, you don’t start from scratch. Instead, you consult your cookbook (meta-buffer) for the best techniques and rely on your sous-chef (buffer manager) to guide you through the process efficiently. The sous-chef remembers what worked best for similar dishes in the past and helps you adjust your approach, ensuring the meal is prepared quickly and to the highest standard.

Here's how the process would work in your kitchen:
Now that we understand what is BoT and its key components, we can have a look at how it works behind the scenes. We'll break it down into four elements:
The problem distiller functions like a skilled translator, converting complex problems into a language that BoT can easily understand and work with.
Imagine it as a meticulous reader who extracts critical information and constraints from the input problem, much like highlighting the most important parts of a textbook chapter.
Once the problem distiller has identified these key elements, it organizes them into high-level concepts and structures. This process can be compared to creating a concise summary of a long article, focusing on the main ideas and leaving out the unnecessary details.
For instance, suppose you are given a complex problem about train schedules. The problem distiller would carefully extract essential elements such as "train speeds," "departure times," and "distance between stations." It would then organize these elements into a structured format that is easy for BoT to process and understand.
The meta-buffer is BoT's knowledge bank, storing and organizing thought-templates for easy access. It contains thought-templates and their descriptions, categorizing them for efficient retrieval.
It's like a well-organized library where each book (thought-template) has a detailed description and is placed in the right section.
When BoT needs to retrieve a thought-template, it finds the most relevant one by comparing the distilled problem with the template descriptions. This process is similar to a librarian quickly finding the perfect book based on your description of what you need.
BoT can also recognize when a task is entirely new and requires a new thought-template. This is like realizing you need to create a new category in your personal library for a unique type of book.
Following our example for the train problem, BoT would have various thought-templates in its meta-buffer, each with a detailed description. For instance, some templates might be related to time management, others to spatial reasoning, and others to optimization strategies.
When BoT encounters the train schedule problem, it retrieves the most relevant thought-template by comparing the distilled elements of the problem, such as "train speeds," "departure times," and "distance between stations," with the descriptions in its meta-buffer. For example, BoT might select a thought-template that specializes in scheduling and time optimization to tackle this problem effectively.
Suppose BoT recognizes that the train schedule problem involves a unique element it has never encountered before, such as an unusual type of constraint or a novel optimization goal. In that case, it can identify that this task is entirely new and requires a new thought-template.
Suppose the problem involves coordinating schedules across multiple transportation modes (trains, buses, flights). In that case, BoT might create and store a new thought-template that addresses multimodal scheduling, ensuring it is better prepared for similar problems in the future.
In this way, the meta-buffer allows BoT to efficiently store, retrieve, and create new strategies for problem-solving, enhancing its ability to handle complex tasks.
This is where BoT applies the selected thought-templates to solve the specific problem at hand.
For existing templates, the retrieved thought-template is adapted to fit the current problem. It's similar to using a recipe but adjusting ingredients and quantities for a larger group. BoT fine-tunes the thought-template to match the specifics of the problem, ensuring a tailored and effective solution.
When faced with a new task for which no existing templates are available, BoT resorts to pre-defined, general-purpose templates. Think of it as using basic cooking techniques to prepare a dish you've never made before. Relying on fundamental principles allows BoT to navigate unfamiliar problems and develop new strategies as needed.
For our train schedule problem, the BoT would retrieve a thought-template focused on time optimization and scheduling. To fit the current problem, BoT would adapt this template. For example, if the original thought-template includes a method for optimizing a single train's schedule, BoT modifies it to handle multiple trains, varying speeds, and different departure times. This tailored approach ensures that all trains run efficiently and on time, taking into account the unique constraints of the current problem.
But now, suppose BoT encounters a new aspect of the train schedule problem, like integrating train schedules with bus and flight schedules to create a seamless multimodal transportation system. Since there's no existing thought-template for this specific scenario, BoT uses pre-defined, general-purpose templates. BoT might apply fundamental principles of scheduling and optimization, such as breaking down the problem into smaller parts, analyzing each transportation mode separately, and then integrating the solutions. Through this process, BoT can develop new strategies and templates, enhancing its ability to tackle similar multimodal scheduling problems in the future.
The buffer manager is the system's learning and optimization component, constantly improving BoT's knowledge base.
In the process of template distillation, the buffer manager summarizes the problem-solving process into high-level thoughts. This is like writing a "lessons learned" document after completing a project, capturing the essence of what was effective and why.
For dynamic updates, the buffer manager updates the meta-buffer with new thought-templates. It uses similarity thresholds to decide whether to add new templates or update existing ones, ensuring the meta-buffer remains lightweight and efficient. This is similar to a chef constantly refining their recipe book, adding new techniques and improving existing ones, while keeping the book concise and practical.
Imagine BoT has just solved a complex train schedule problem involving multiple trains, varying speeds, and different departure times. After completing this task, the buffer manager summarizes the problem-solving process into high-level thoughts, capturing the key strategies that worked well, such as specific techniques for optimizing overlapping schedules or handling peak travel times.
Now, suppose BoT encounters a similar but slightly different train scheduling problem in the future. The buffer manager updates the meta-buffer with new thought-templates based on this experience. For instance, if the new problem involves integrating train schedules with bus schedules, the buffer manager might refine the existing train scheduling template to include multimodal integration techniques.
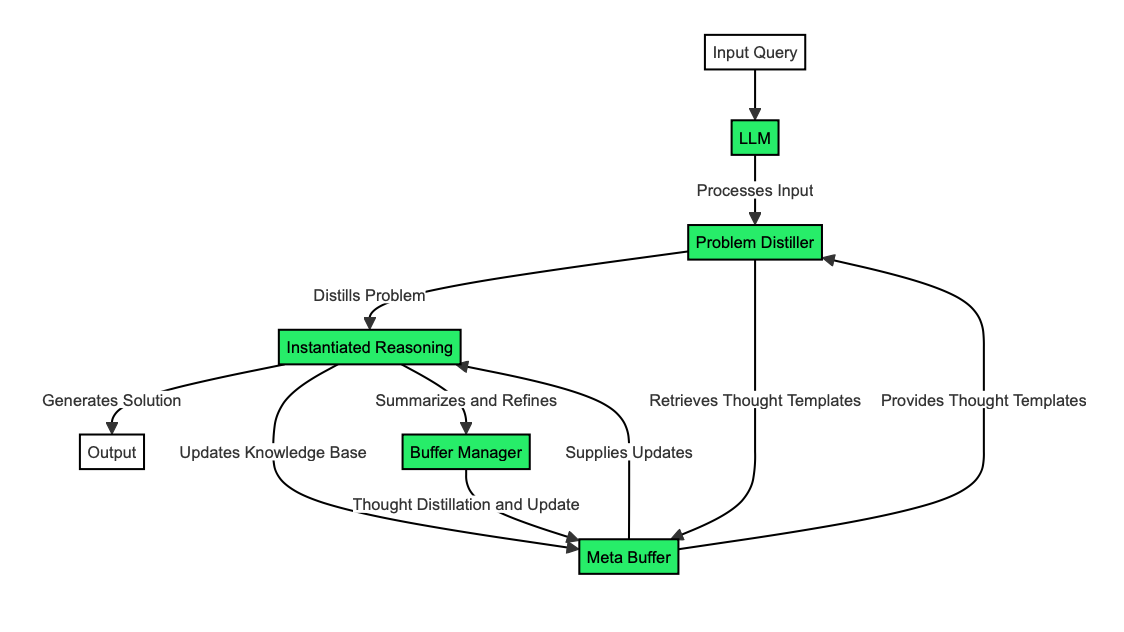
The Buffer of Thoughts (BoT) framework offers several significant advantages for developing LLM reasoning, such as improved accuracy, reasoning efficiency, and model robustness.
BoT significantly improves the reasoning accuracy of LLMs through its new approach:
BoT dramatically improves the efficiency of LLM reasoning, saving time and computational resources:
BoT improves the robustness of LLMs, making them more reliable and consistent across various tasks:
The Buffer of Thoughts (BoT) framework has been tested across a diverse range of tasks giving impressive results. For more detailed information, refer to the paper and GitHub repository, where the results covered in this section are presented in greater detail.
BoT was evaluated on 10 challenging reasoning-intensive tasks, showing versatility and effectiveness. These tasks included:
These tasks were chosen to represent a variety of complex reasoning scenarios, from mathematical problem-solving to strategic game-playing and language manipulation.
BoT demonstrated significant performance improvements over previous state-of-the-art methods:
What's particularly impressive is that BoT achieved these results while requiring only about 12% of the computational cost of multi-query prompting methods!
It was also found that implementing BoT with smaller language models, such as Llama3-8B, has the potential to surpass the performance of larger models like Llama3-70. This finding shows that BoT can significantly improve the capabilities of more compact and efficient language models.
These results show that BoT can improve accuracy while staying efficient and robust across different reasoning tasks. The consistent results highlight BoT's reliable performance improvements. However, further independent verification and testing on more diverse tasks are needed to fully understand BoT's capabilities and limitations.
We’ve covered a lot of ground today, so let’s wrap it up with some key takeaways and thoughts on where BoT is headed.

This is all for our exploration of Buffer of Thoughts. I hope this tutorial has given you a clear understanding of its key concepts, workings, benefits, and potential impact on AI reasoning.
Thanks for reading, and until next time!
If you want to learn more about prompt engineering, I recommend these blogs:
Learn AI with these courses!
Course
Course
Course
blog
Yesha Shastri
8 min
blog
Richie Cotton
15 min
blog
Matt Crabtree
14 min
blog
Abid Ali Awan
5 min
blog
Richie Cotton
8 min
Tutorial
Andrea Valenzuela



