Programa
Fundamentos da IA
10 h
Meta lançado recentemente Meta Movie Genque é um evento significativo e, de certa forma, inesperado no cenário de geração de texto para vídeo - acho que o Meta não estava no radar de muitas pessoas quando se trata de geração de vídeo.
Dado o ambiente competitivo, com várias empresas de alto nível, como a OpenAI já estão trabalhando em modelos robustos como o Sorao lançamento do Meta é digno de nota.
O modelo tem um bom desempenho em várias tarefas, superando ou igualando a qualidade das ofertas de empresas estabelecidas, como Runway Gen3LumaLabs e, principalmente, o Sora da OpenAI.
Neste blog, abordarei o que é o Meta Movie Gen, como ele funciona, seus recursos e limitações e as considerações de segurança relacionadas ao seu uso.
Se você quiser ter uma visão geral do campo de geração de vídeo, recomendo ler este artigo sobre principais geradores de vídeo com IA.
O Meta Movie Gen é uma coleção de modelos básicos para a geração de vários tipos de mídia, incluindo texto para vídeo, texto para áudio e texto para imagem. Ele consiste em quatro modelos:
O Movie Gen Video é um modelo de 30 bilhões de parâmetros projetado para criar imagens e vídeos com base em descrições de texto. O modelo pode gerar vídeos de alta qualidade com até 16 segundos de duração que correspondem ao prompt de texto fornecido. Ele pode produzir conteúdo em diferentes tamanhos, resoluções e comprimentos.
Aqui está um exemplo de um vídeo gerado com o prompt:
"Um bicho-preguiça com óculos escuros cor-de-rosa deita-se em uma boia de donut em uma piscina. O bicho-preguiça está segurando uma bebida tropical. O mundo é tropical. A luz do sol projeta uma sombra".
O modelo tem o potencial de revolucionar os fluxos de trabalho de edição de vídeo em vários setores. Sua capacidade de entender e executar com precisão instruções de edição baseadas em texto pode melhorar significativamente o processo de edição, tornando-o mais rápido, mais eficiente e acessível a uma variedade maior de usuários. Essa tecnologia pode beneficiar cineastas, criadores de conteúdo, educadores e qualquer pessoa que trabalhe com conteúdo de vídeo.
O treinamento do modelo Movie Gen Video envolveu vários componentes importantes: coleta e preparação de dados, o próprio processo de treinamento, o ajuste fino para melhorar a qualidade e as técnicas de upsampling usadas para obter resultados de alta resolução.
O modelo Movie Gen Video foi treinado em um enorme conjunto de dados que contém centenas de milhões de pares de texto de vídeo e mais de um bilhão de pares de texto de imagem.
Cada vídeo do conjunto de dados passa por um rigoroso processo de curadoria que envolve a filtragem da qualidade visual, das características de movimento e da relevância do conteúdo. O processo de filtragem tem como objetivo selecionar vídeos com movimentos não triviais, trabalho de câmera de tomada única e uma gama diversificada de conceitos, incluindo uma parte significativa com seres humanos.
Fonte: Trabalho de pesquisa do Movie Gen
As legendas de alta qualidade são muito importantes para o treinamento eficaz do modelo. O Movie Gen Video usa o modelo LLaMa3-Video para gerar legendas detalhadas que descrevem com precisão o conteúdo do vídeo. Essas legendas vão além de simplesmente rotular objetos; elas incluem descrições de ações, movimentos de câmera e até mesmo informações de iluminação. Essas ricas informações textuais ajudam o modelo a aprender uma compreensão mais diferenciada da narrativa visual.
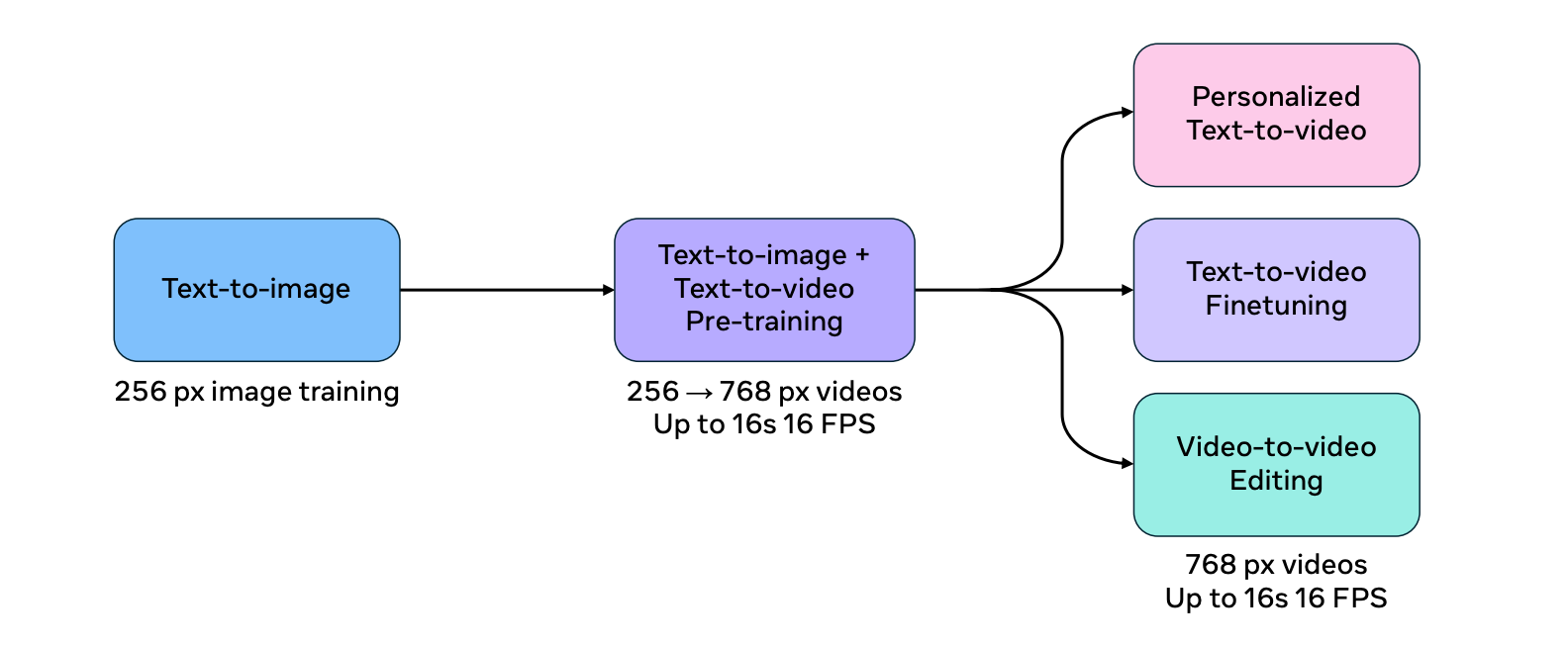
O processo de treinamento do Movie Gen Video é dividido em vários estágios para aumentar a eficiência e a escalabilidade do modelo.
Primeiro, o modelo é treinado na tarefa de texto para imagem usando imagens de baixa resolução. Essa fase de "aquecimento" permite que o modelo aprenda conceitos visuais fundamentais antes de enfrentar a tarefa mais complexa de geração de vídeo.
O modelo é então treinado em conjunto nas tarefas de texto para imagem e texto para vídeo, aumentando progressivamente a resolução dos dados de entrada. Essa abordagem de treinamento conjunto ajuda o modelo a usar a abundância e a diversidade dos conjuntos de dados de imagem-texto e, ao mesmo tempo, a aprender as complexidades da geração de vídeo.
Fonte: Trabalho de pesquisa do Movie Gen
Para lidar com as demandas computacionais de dados de vídeo, o Movie Gen Video usa um modelode Autoencodificador Temporal (TAE) para compactar e descompactar os vídeos no tempo. Isso é análogo a compactar e descompactar arquivos em um computador, permitindo que o modelo trabalhe com uma representação mais gerenciável dos dados de vídeo.
Fonte: Trabalho de pesquisa do Movie Gen
O Movie Gen Video usa um objetivo de treinamento chamado Flow Matching. Em vez de gerar diretamente o vídeo final, a correspondência de fluxo orienta o modelo para transformar gradualmente uma amostra de ruído aleatório na saída de vídeo desejada, passo a passo.
Flow Matching envolve a previsão da velocidade das amostras no espaço latente em vez de prever diretamente as próprias amostras. Esse método é mais eficiente e eficaz do que os métodos tradicionais baseados em difusão.
Para melhorar a qualidade e a estética dos vídeos gerados, o modelo é submetido a um ajuste fino supervisionado. supervisionado usando um conjunto menor de vídeos selecionados manualmente com legendas de alta qualidade. É como um artista refinando sua técnica por meio de orientação especializada, o que resulta em vídeos mais realistas e visualmente atraentes.
O modelo final do Movie Gen Video é criado pela média de vários modelos treinados com diferentes conjuntos de dados, hiperparâmetros e pontos de verificação de pré-treinamento. Essa técnica ajuda a combinar os pontos fortes de diferentes modelos, resultando em um desempenho mais robusto e confiável.
O modelo produz vídeos com uma resolução de 768 pixels e usa upsampling para mudar a resolução para Full HD 1080p, resultando em vídeos mais nítidos e visualmente mais atraentes. Essa abordagem é comumente usada porque oferece uma solução computacionalmente eficiente, pois o modelo básico pode processar menos tokens e ainda produzir resultados de alta resolução.
O Spatial Upsampler funciona como um modelo de geração de vídeo para vídeo. Ele usa o vídeo de resolução mais baixa como entrada, faz o upsample para a resolução de destino usando interpolação bilinear e, em seguida, codifica-o em um espaço latente usando um Variational Autoencoder (VAE) com base no quadro.
Em seguida, um modelo de espaço latente gera as latentes do vídeo HD, condicionadas às latentes codificadas do vídeo de resolução mais baixa. Por fim, o decodificador VAE transforma as latentes de vídeo HD resultantes de volta ao espaço de pixels, produzindo a saída final de alta resolução.
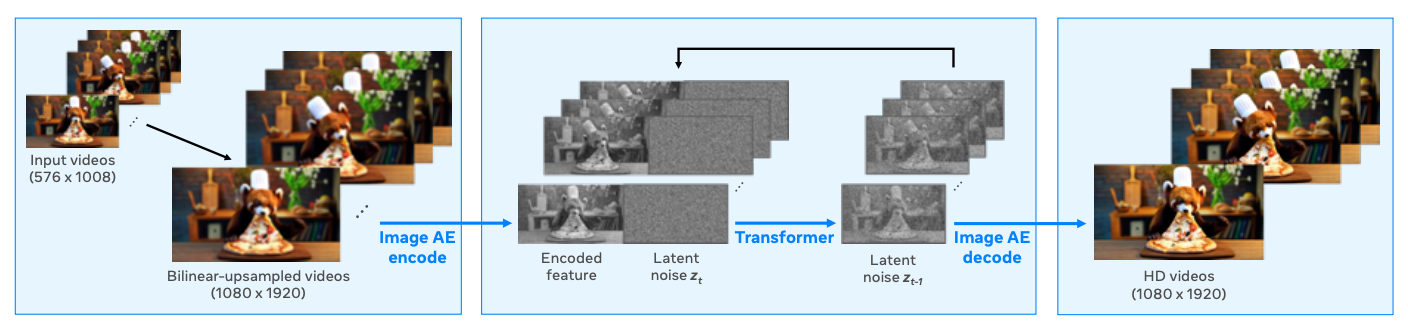
Fonte: Trabalho de pesquisa do Movie Gen
A avaliação de um modelo de texto para vídeo é mais desafiadora do que a de um modelo de texto para imagem devido à dimensão temporal adicional. A equipe do Meta usou três medidas principais para avaliar o modelo:
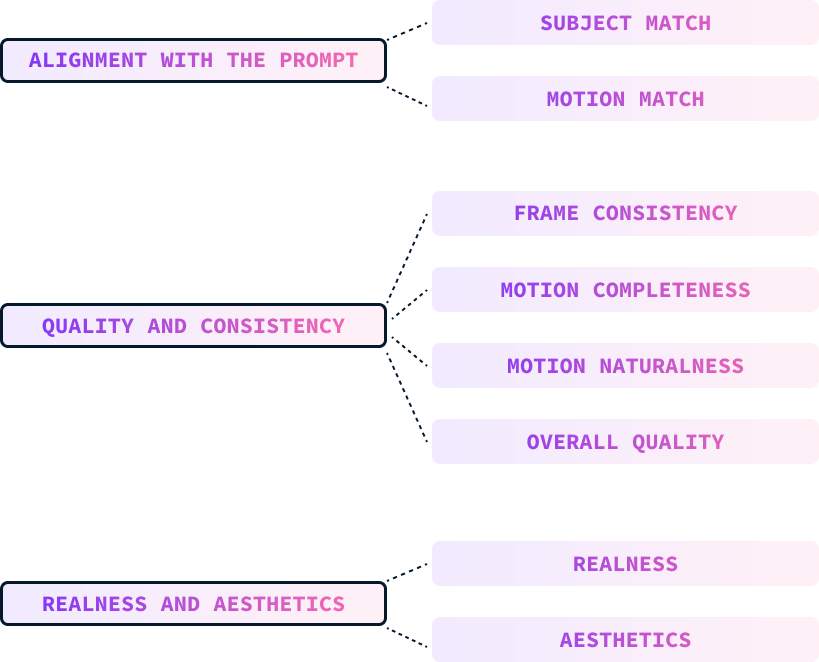
Esses parâmetros são avaliados manualmente por humanos que classificam os vídeos de acordo com esses parâmetros.
O alinhamento do prompt mede o quanto o vídeo gerado corresponde ao prompt do texto de entrada, incluindo descrições do assunto, movimento, plano de fundo e outros detalhes. Isso é subdividido em:
A qualidade e a consistência do vídeo gerado são avaliadas independentemente do prompt de texto. Essa medida é dividida em:
Os avaliadores foram solicitados a classificar a capacidade do modelo de produzir vídeos fotorrealistas e esteticamente agradáveis. Esses critérios são divididos em:
Os dados de benchmark foram projetados para avaliar as gerações de vídeo de forma abrangente. Ele inclui 1.000 sugestões que abrangem vários aspectos do teste, como atividade humana, animais, natureza, física e assuntos ou atividades incomuns.
Seu benchmark é mais de três vezes maior do que os usados em estudos anteriores. Cada prompt é marcado com um nível de movimento (alto, médio, baixo) para avaliar a qualidade da geração em diferentes intensidades de movimento.
A avaliação usa todo o conjunto de solicitações e examina métricas de teste específicas, concentrando-se especialmente em como os modelos lidam com assuntos e movimentos incomuns para testar seus recursos de generalização.
O diagrama a seguir mostra um detalhamento dos prompts usados na avaliação. À esquerda, temos a distribuição dos conceitos dos prompts. No lado direito, vemos os substantivos e verbos comuns usados nos prompts (quanto maior a palavra, mais frequente ela é):
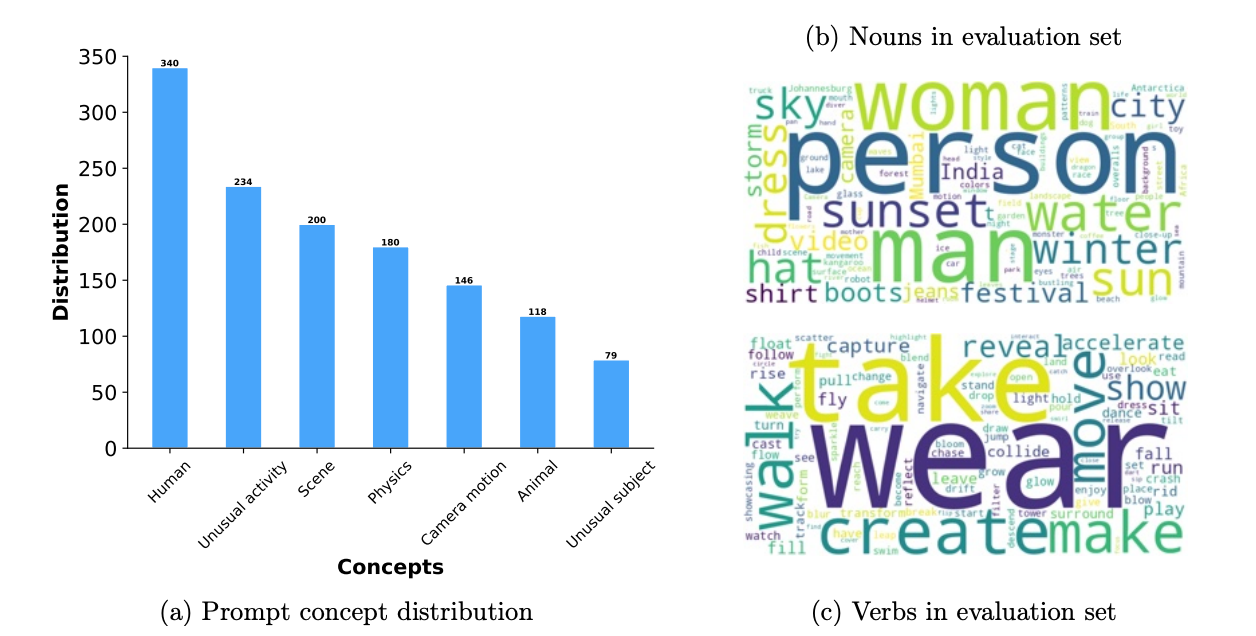
Fonte: Trabalho de pesquisa do Movie Gen
A tabela abaixo mostra os resultados da avaliação humana dos vídeos produzidos por diferentes modelos em vários critérios de avaliação. Os números representam as taxas de ganho líquido, que são calculadas como (% de ganho - % de perda). Ele varia de -100 (perda total) a 100 (vitória total), com 0 indicando um empate.
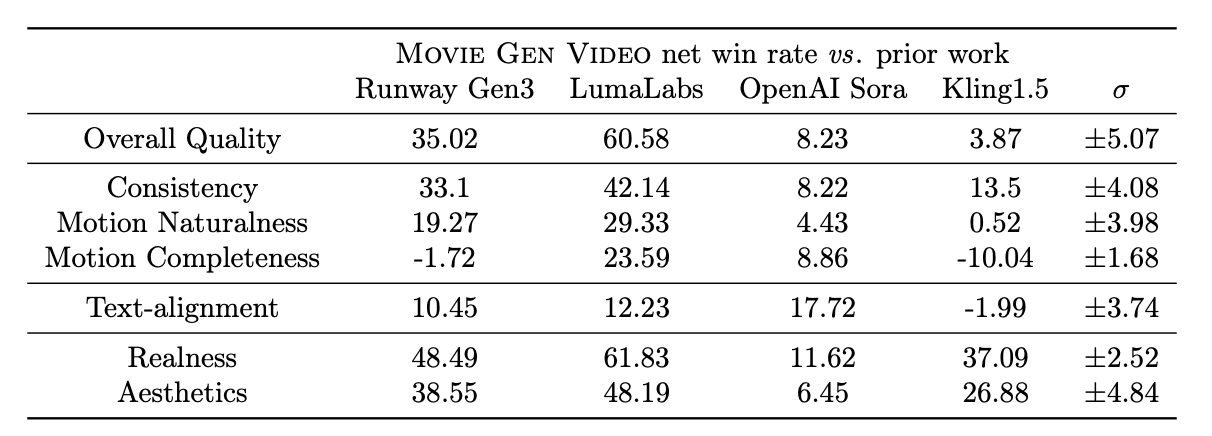
Fonte: Trabalho de pesquisa do Movie Gen
De acordo com seus experimentos, o Movie Gen Video tem um bom desempenho na geração de texto para vídeo, superando vários modelos existentes, inclusive sistemas comerciais como o Runway Gen3 e o LumaLabs, com base em avaliações humanas usando o MovieGen Video Bench. Especificamente, o Movie Gen Video mostra vantagens significativas em:
Embora o MovieGen geralmente supere os outros modelos, o Kling1.5 às vezes gera vídeos com magnitudes de movimento maiores, embora ao custo de distorções e inconsistências. Isso destaca a compensação entre a integridade do movimento e a qualidade visual, em que o Movie Gen Video prioriza a geração de movimentos realistas e consistentes em vez de simplesmente maximizar a magnitude do movimento.
Abaixo estão algumas capturas de tela da apresentação do Meta Connect 2024, mostrando alguns exemplos de comparação de prompts de geração de vídeo:

Fonte: Trabalho de pesquisa do Movie Gen
Aqui estão alguns exemplos de comparação de personalização de vídeo em que uma foto é usada para gerar um vídeo personalizado:

Fonte: Trabalho de pesquisa do Movie Gen
Por fim, as capturas de tela abaixo mostram exemplos comparativos de edição de vídeo:

Fonte: Trabalho de pesquisa do Movie Gen
De modo geral, parece que o Meta Movie Gen elevou o nível e estabeleceu um novo padrão nos modelos de texto para vídeo. O procedimento de avaliação destacado no artigo parece justo, mas, é claro, é difícil ter certeza, a menos que esses modelos sejam disponibilizados publicamente e terceiros neutros possam compará-los.
Embora o Meta Movie Gen pareça ótimo na geração de mídia, ainda há áreas que precisam ser melhoradas.
Às vezes, o modelo tem dificuldades com cenas complexas que envolvem geometria intrincada, manipulação de objetos e simulações de física realistas. Por exemplo, a geração de interações convincentes entre objetos, a representação precisa de transformações de estado (como derretimento ou quebra) e a simulação realista dos efeitos da gravidade ou de colisões ainda podem representar desafios para os modelos.
A sincronização de áudio pode ser problemática em determinados cenários. Especificamente, ao lidar com movimentos que são visualmente pequenos, ocluídos ou que exigem um alto nível de compreensão visual para gerar o som correspondente, os modelos podem ter dificuldades para obter uma sincronização perfeita. Exemplos desses desafios incluem a sincronização precisa de passos com uma pessoa que está andando, a geração de sons apropriados para objetos que estão parcialmente ocultos e o reconhecimento de movimentos sutis da mão em um violão para produzir as notas musicais corretas.
Além disso, o modelo Movie Gen Audio, conforme projetado atualmente, não oferece suporte à geração de voz.
Vídeos realistas gerados por IA trazem riscos significativos riscos e desafios éticos significativos e desafios éticos que devem ser considerados. Esses riscos incluem a manipulação da confiança e a disseminação de desinformação por meio de deepfakes, que podem prejudicar a reputação, desinformar o público e prejudicar as empresas.
Por um lado, pode ser um recurso do Instagram que me permite criar um vídeo legal comigo mesmo para compartilhar com meus amigos, mas, por outro lado, o mesmo recurso possibilita que eu crie um vídeo falso de outra pessoa. À medida que essas tecnologias melhoram, pode ser impossível distingui-las da realidade.
O conteúdo gerado por IA apresenta ameaças à privacidade ameaças à privacidade, podendo levar a extorsão, chantagem ou cyberbullying.
Além disso, essas ferramentas de IA podem prejudicar a arte e os direitos autorais ao imitar estilos artísticos exclusivos sem crédito. As soluções envolvem a disseminação da conscientização e da educação sobre a alfabetização midiática, o investimento em tecnologia de detecção, o estabelecimento de estruturas legais e éticas e o emprego de marcas d'água para autenticação.
Embora a geração de vídeos com IA tenha um grande potencial, ela exige um tratamento cuidadoso para manter a confiança e a autenticidade.
A Meta tem sido aberta com seus desenvolvimentos de IA, abrindo o código aberto dos modelos modelos Llama. No entanto, por motivos de segurança, os modelos Meta Movie Gen ainda não serão lançados. De acordo com o artigo, são necessários vários aprimoramentos e considerações de segurança antes de implantá-los.
Nesta postagem do blog, apresentamos os modelos Movie Gen do Meta, um conjunto de modelos de IA para gerar e editar vídeos usando prompts de texto.
Exploramos os quatro modelos distintos, seus recursos e como eles funcionam. Por meio de uma análise comparativa, mostramos como o Meta Movie Gen se compara a outras ferramentas de geração de vídeo com IA.
Embora o Meta Movie Gen tenha estabelecido uma nova referência no campo, o possível uso indevido da tecnologia levanta preocupações significativas. A Meta reconheceu esses riscos e está adotando uma abordagem cautelosa no lançamento desses modelos.
Para saber mais sobre o ecossistema do Meta AI, recomendo estes blogs:
Aprenda IA com estes cursos!
Programa
Curso
Curso