Cursus
Principes fondamentaux de l'IA
10 h
Meta récemment sorti Meta Movie Genqui est à la fois un événement important et quelque peu inattendu dans le paysage de la génération de texte à partir de la vidéo - je ne pense pas que Meta était sur le radar de beaucoup de gens en ce qui concerne la génération de vidéo.
Compte tenu de l'environnement concurrentiel, avec plusieurs entreprises de premier plan telles que OpenAI travaillent déjà sur des modèles robustes comme Sorala publication de Meta est digne d'intérêt.
Le modèle est performant dans diverses tâches, surpassant ou égalant la qualité des offres d'acteurs établis tels que Runway Gen3LumaLabs et, notamment, Sora d'OpenAI.
Dans ce blog, je vais vous expliquer ce qu'est la Meta Movie Gen, comment elle fonctionne, quelles sont ses capacités et ses limites, et quelles sont les considérations de sécurité qui entourent son utilisation.
Si vous souhaitez avoir une vue d'ensemble du domaine de la génération de vidéos, je vous recommande de lire cet article sur les les meilleurs générateurs de vidéos d'IA.
Meta Movie Gen est une collection de modèles fondamentaux pour la génération de divers types de médias, y compris le texte-vidéo, le texte-audio et le texte-image. Il se compose de quatre modèles :
Movie Gen Video est un modèle de 30 milliards de paramètres conçu pour créer des images et des vidéos à partir de descriptions textuelles. Le modèle peut générer des vidéos de haute qualité d'une durée maximale de 16 secondes qui correspondent à l'invite textuelle donnée. Il peut produire des contenus de différentes tailles, résolutions et longueurs.
Voici un exemple de vidéo générée à l'aide de l'invite :
"Un paresseux avec des lunettes de soleil roses est allongé sur un donut flottant dans une piscine. Le paresseux tient une boisson tropicale. Le monde est tropical. La lumière du soleil projette une ombre".
Ce modèle a le potentiel de révolutionner les flux de travail de l'édition vidéo dans divers secteurs. Sa capacité à comprendre et à exécuter avec précision des instructions d'édition textuelles pourrait améliorer considérablement le processus d'édition, en le rendant plus rapide, plus efficace et accessible à un plus grand nombre d'utilisateurs. Cette technologie pourrait être utile aux cinéastes, aux créateurs de contenu, aux éducateurs et à tous ceux qui travaillent avec du contenu vidéo.
La formation du modèle Movie Gen Video a comporté plusieurs éléments clés : la collecte et la préparation des données, le processus de formation lui-même, la mise au point pour améliorer la qualité et les techniques de suréchantillonnage utilisées pour obtenir des résultats à haute résolution.
Le modèle Movie Gen Video a été entraîné sur un vaste ensemble de données contenant des centaines de millions de paires vidéo-texte et plus d'un milliard de paires image-texte.
Chaque vidéo de l'ensemble de données est soumise à un processus de curation rigoureux qui implique un filtrage de la qualité visuelle, des caractéristiques de mouvement et de la pertinence du contenu. Le processus de filtrage vise à sélectionner des vidéos présentant des mouvements non triviaux, des prises de vue uniques et une gamme variée de concepts, y compris une part importante d'images humaines.
Source : Document de recherche sur le cinéma Gen
Des légendes de haute qualité sont très importantes pour former efficacement le modèle. Movie Gen Video utilise le modèle LLaMa3-Video pour générer des sous-titres détaillés qui décrivent avec précision le contenu de la vidéo. Ces légendes ne se limitent pas à l'étiquetage des objets ; elles comprennent des descriptions des actions, des mouvements de caméra et même des informations sur l'éclairage. Ces informations textuelles riches aident le modèle à acquérir une compréhension plus nuancée de la narration visuelle.
Le processus de formation pour Movie Gen Video est divisé en plusieurs étapes afin d'améliorer l'efficacité et l'extensibilité du modèle.
Le modèle est d'abord entraîné à la tâche de conversion texte-image à l'aide d'images à faible résolution. Cette phase d'échauffement permet au modèle d'apprendre les concepts visuels fondamentaux avant de s'attaquer à la tâche plus complexe de la génération de vidéos.
Le modèle est ensuite entraîné conjointement sur les tâches texte-image et texte-vidéo, en augmentant progressivement la résolution des données d'entrée. Cette approche de formation conjointe permet au modèle d'utiliser l'abondance et la diversité des ensembles de données image-texte tout en apprenant les complexités de la génération de vidéos.
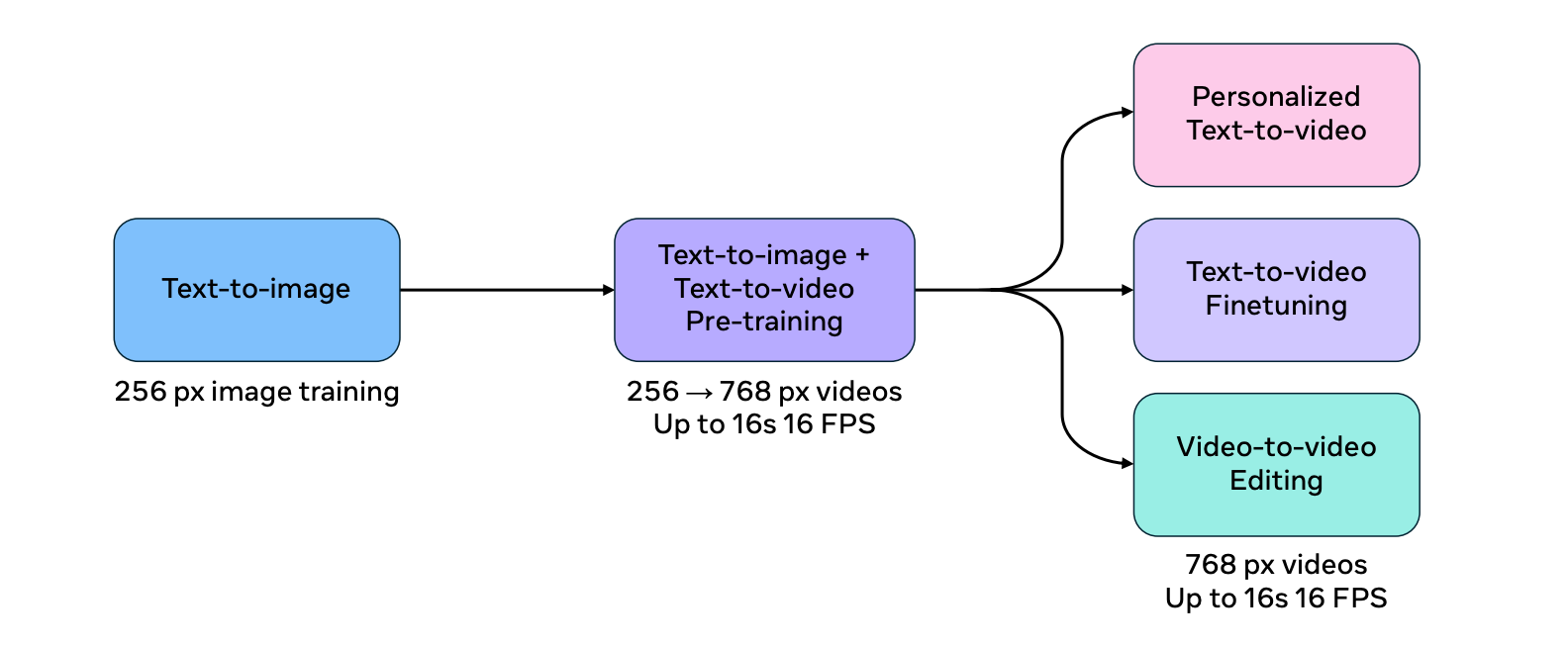
Source : Document de recherche sur le cinéma Gen
Pour répondre aux exigences de calcul des données vidéo, Movie Gen Video utilise un modèle d'autoencodeur temporel (TAE) pour compresser et décompresser les vidéos dans le temps. C'est un peu comme si l'on zippait et dézippait des fichiers sur un ordinateur, ce qui permet au modèle de travailler avec une représentation plus facile à gérer des données vidéo.
Source : Document de recherche sur le cinéma Gen
Movie Gen Video utilise un objectif de formation appelé Flow Matching. Au lieu de générer directement la vidéo finale, la correspondance des flux guide le modèle pour transformer progressivement un échantillon de bruit aléatoire en la sortie vidéo souhaitée, étape par étape.
Correspondance des flux implique de prédire la vitesse des échantillons dans l'espace latent plutôt que de prédire directement les échantillons eux-mêmes. Cette méthode est plus efficace et plus performante que les méthodes traditionnelles basées sur la diffusion.
Pour améliorer la qualité et l'esthétique des vidéos générées, le modèle fait l'objet d'une mise au point supervisée. supervisé à l'aide d'un ensemble plus restreint de vidéos à l'aide d'un ensemble plus restreint de vidéos sélectionnées manuellement et dotées de légendes de haute qualité. C'est comme si un artiste affinait sa technique grâce aux conseils d'un expert, ce qui permet d'obtenir des vidéos plus attrayantes et plus réalistes.
Le modèle Movie Gen Video final est créé en faisant la moyenne de plusieurs modèles entraînés avec différents ensembles de données, hyperparamètres et points de contrôle de pré-entraînement. Cette technique permet de combiner les points forts de différents modèles, ce qui se traduit par des performances plus robustes et plus fiables.
Le modèle produit des vidéos à une résolution de 768 pixels et utilise le suréchantillonnage pour passer à la résolution Full HD 1080p, ce qui permet d'obtenir des vidéos plus nettes et plus attrayantes sur le plan visuel. Cette approche est couramment utilisée car elle constitue une solution efficace en termes de calcul, le modèle de base pouvant traiter moins de jetons tout en produisant des résultats à haute résolution.
L'échantillonneur spatial fonctionne comme un modèle de génération de vidéo à vidéo. Il prend la vidéo basse résolution en entrée, la suréchantillonne à la résolution cible à l'aide d'une interpolation bilinéaire, puis l'encode dans un espace latent à l'aide d'unautoencodeur variationnel (VAE) à l'échelle de la trame .
Un modèle d'espace latent génère ensuite les latents de la vidéo HD, en fonction des latents encodés de la vidéo à plus faible résolution. Enfin, le décodeur VAE retransforme les latents vidéo HD résultants dans l'espace pixel, produisant ainsi la sortie haute résolution finale.
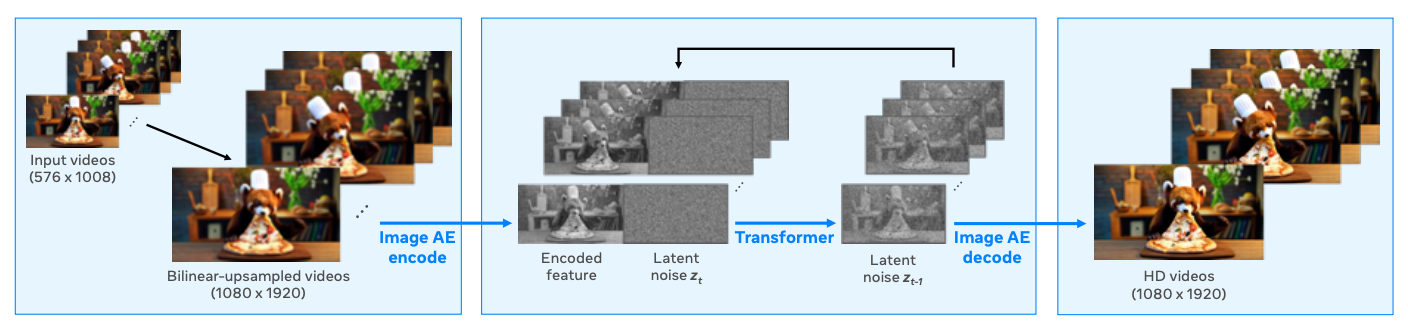
Source : Document de recherche sur le cinéma Gen
L'évaluation d'un modèle texte-vidéo est plus difficile que celle d'un modèle texte-image en raison de la dimension temporelle ajoutée. L'équipe Meta a utilisé trois mesures principales pour évaluer le modèle :
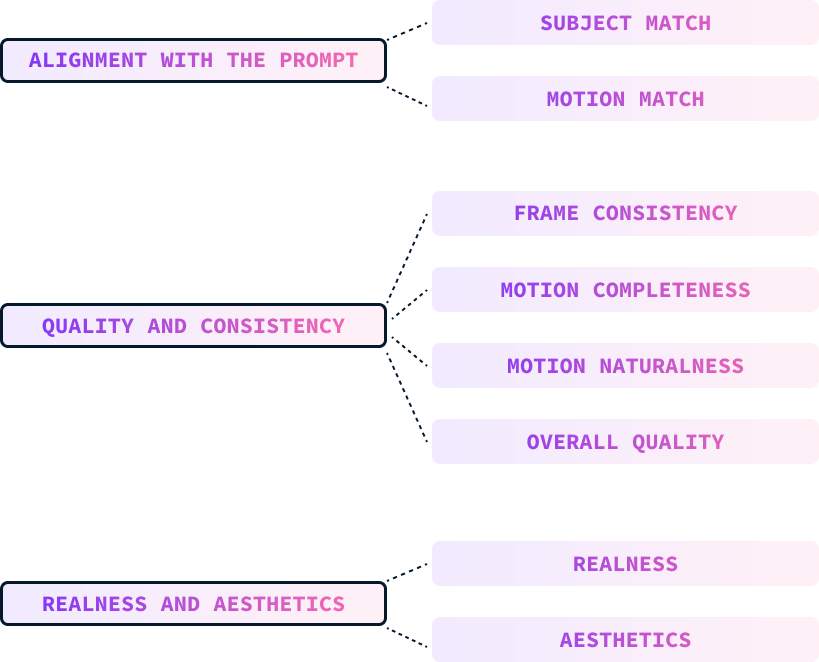
Ces paramètres sont évalués manuellement par des humains qui classent les vidéos en fonction de ces paramètres.
L'alignement de l'invite mesure le degré d'adéquation entre la vidéo générée et l'invite du texte d'entrée, y compris les descriptions du sujet, du mouvement, de l'arrière-plan et d'autres détails. Il se décompose en deux parties :
La qualité et la cohérence de la vidéo générée sont évaluées indépendamment de l'invite textuelle. Cette mesure se décompose en
Les évaluateurs ont été invités à noter la capacité du modèle à produire des vidéos photoréalistes et esthétiques. Ces critères sont divisés en plusieurs catégories :
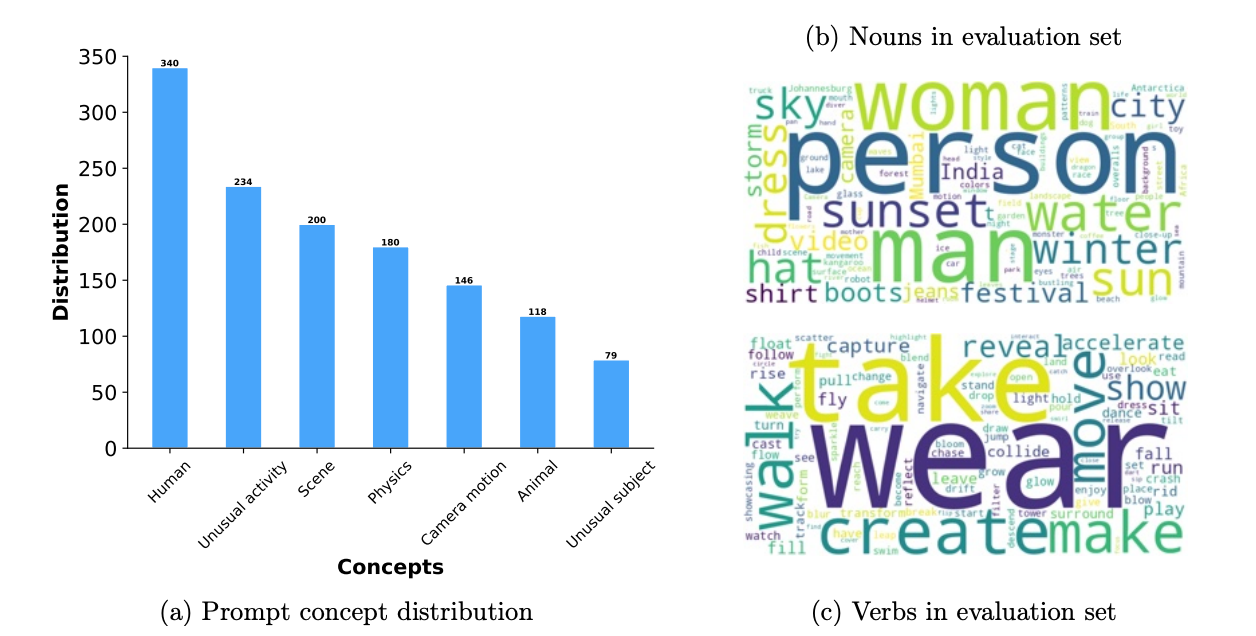
Les données de référence ont été conçues pour évaluer les générations de vidéos de manière exhaustive. Il comprend 1 000 questions qui couvrent divers aspects des tests, tels que l'activité humaine, les animaux, la nature, la physique et les sujets ou activités inhabituels.
Leur référence est plus de trois fois supérieure à celles utilisées dans les études précédentes. Chaque message est associé à un niveau de mouvement (élevé, moyen, faible) afin d'évaluer la qualité de la génération en fonction de l'intensité du mouvement.
L'évaluation utilise l'ensemble des invites et examine des paramètres de test spécifiques, en se concentrant particulièrement sur la manière dont les modèles gèrent les sujets et les mouvements inhabituels afin de tester leurs capacités de généralisation.
Le diagramme suivant présente une ventilation des questions posées dans le cadre de l'évaluation. Sur la gauche, on trouve la répartition des concepts des messages-guides. Sur le côté droit, nous voyons les noms et les verbes courants utilisés dans les messages-guides (plus le mot est grand, plus il est fréquent) :
Source : Document de recherche sur le cinéma Gen
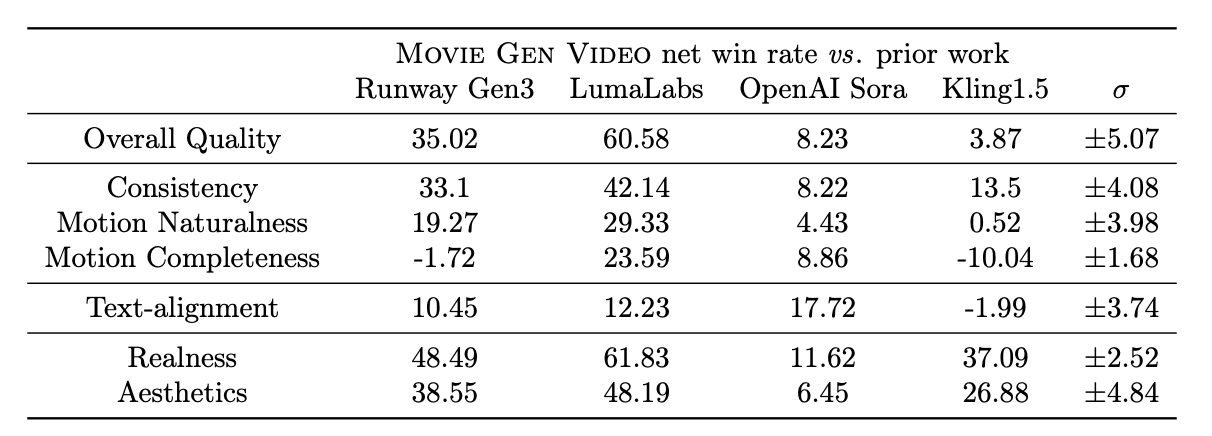
Le tableau ci-dessous présente les résultats de l'évaluation humaine des vidéos produites par différents modèles sur plusieurs critères d'évaluation. Les chiffres représentent les taux de gains nets qui sont calculés comme suit : (% de gains - % de pertes). Il va de -100 (perte totale) à 100 (victoire totale), 0 indiquant une égalité.
Source : Document de recherche sur le cinéma Gen
D'après leurs expériences, Movie Gen Video est très performant dans la génération de texte à partir de vidéo, surpassant plusieurs modèles existants, y compris des systèmes commerciaux tels que Runway Gen3 et LumaLabs, sur la base d'évaluations humaines réalisées à l'aide du banc MovieGen Video. Plus précisément, Movie Gen Video présente des avantages significatifs dans les domaines suivants :
Si MovieGen est généralement plus performant que les autres modèles, Kling1.5 génère parfois des vidéos avec des amplitudes de mouvement plus importantes, mais au prix de distorsions et d'incohérences. Cela met en évidence le compromis entre l'exhaustivité du mouvement et la qualité visuelle, Movie Gen Video donnant la priorité à la génération de mouvements réalistes et cohérents plutôt qu'à la simple maximisation de l'amplitude des mouvements.
Vous trouverez ci-dessous quelques captures d'écran de la présentation de Meta Connect 2024 présentant quelques exemples d'invites de génération de vidéos :

Source : Document de recherche sur le cinéma Gen
Voici quelques exemples de comparaison de la personnalisation de vidéos où une photo est utilisée pour générer une vidéo personnalisée :

Source : Document de recherche sur le cinéma Gen
Enfin, les captures d'écran ci-dessous présentent des exemples comparatifs de montage vidéo :

Source : Document de recherche sur le cinéma Gen
Dans l'ensemble, il semble que Meta Movie Gen ait repoussé les limites et établi une nouvelle norme pour les modèles de conversion de texte en vidéo. La procédure d'évaluation décrite dans le document semble équitable mais, bien entendu, il est difficile d'en être certain tant que ces modèles ne seront pas rendus publics et que des tiers neutres ne pourront pas les comparer.
Bien que Meta Movie Gen soit très performant en matière de génération de médias, il y a encore des points à améliorer.
Le modèle a parfois du mal à gérer des scènes complexes impliquant une géométrie complexe, la manipulation d'objets et des simulations physiques réalistes. Par exemple, la génération d'interactions convaincantes entre les objets, la représentation précise des transformations d'état (comme la fusion ou l'éclatement) et la simulation réaliste des effets de la gravité ou des collisions peuvent encore constituer des défis pour les modèles.
La synchronisation audio peut être problématique dans certains scénarios. Plus précisément, lorsqu'il s'agit de mouvements qui sont visuellement petits, occultés ou qui nécessitent un niveau élevé de compréhension visuelle pour générer le son correspondant, les modèles peuvent avoir du mal à atteindre une synchronisation parfaite. Parmi les exemples de ces défis, citons la synchronisation précise des pas d'une personne qui marche, la génération de sons appropriés pour des objets partiellement cachés et la reconnaissance des mouvements subtils de la main sur une guitare pour produire les notes de musique correctes.
En outre, le modèle Movie Gen Audio, tel qu'il est conçu actuellement, ne prend pas en charge la génération de voix.
Les vidéos réalistes générées par l'IA comportent des risques et éthiques éthiques qu'il convient de prendre en compte. Ces risques comprennent la manipulation de la confiance et la diffusion de fausses informations par le biais de "deepfakes", qui pourraient nuire à la réputation, désinformer le public et porter préjudice aux entreprises.
D'une part, il peut s'agir d'une fonctionnalité d'Instagram qui me permet de créer une vidéo sympa avec moi pour la partager avec mes amis, mais d'autre part, cette même fonctionnalité me permet de créer une fausse vidéo de quelqu'un d'autre. Au fur et à mesure que ces technologies s'améliorent, il pourrait devenir impossible de les distinguer de la réalité.
Les contenus générés par l'IA posent menaces pour la vie privée menace la vie privée et peut conduire à l'extorsion, au chantage ou à la cyberintimidation.
En outre, ces outils d'IA pourraient porter atteinte à l'art et aux droits d'auteur en imitant des styles artistiques uniques sans en être crédités. Les solutions passent par la sensibilisation et l'éducation aux médias, l'investissement dans les technologies de détection, la mise en place d'un cadre juridique pour la protection des droits de l'homme et des libertés fondamentales. cadres et éthiques, et l'utilisation du filigrane pour l'authentification.
Si la génération de vidéos par l'IA offre un grand potentiel, elle nécessite une manipulation prudente pour maintenir la confiance et l'authenticité.
Meta a fait preuve d'ouverture dans ses développements en matière d'IA en mettant à disposition les modèles modèles Llama. Toutefois, pour des raisons de sécurité, les modèles Meta Movie Gen ne seront pas encore commercialisés. Selon leur article, de nombreuses améliorations et considérations de sécurité sont nécessaires avant de les déployer.
Dans cet article de blog, nous avons présenté les modèles Movie Gen de Meta, une suite de modèles d'IA pour générer et éditer des vidéos à l'aide d'invites textuelles.
Nous avons exploré les quatre modèles distincts, leurs capacités et leur fonctionnement. Grâce à une analyse comparative, nous avons montré comment Meta Movie Gen se positionne par rapport à d'autres outils de génération de vidéos par IA.
Bien que Meta Movie Gen ait établi une nouvelle référence dans le domaine, l'utilisation abusive potentielle de la technologie soulève des préoccupations importantes. Meta a reconnu ces risques et adopte une approche prudente dans la diffusion de ces modèles.
Pour en savoir plus sur l'écosystème de Meta AI, je vous recommande ces blogs :
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach