
Track
AI Fundamentals
10 hr
Meta recently released Meta Movie Gen, which is both a significant and somewhat unexpected event in the text-to-video generation landscape—I don’t think Meta was on many people’s radar when it comes to video generation.
Given the competitive environment, with several high-profile companies such as OpenAI already working on robust models like Sora, Meta's release is noteworthy.
The model performs well across various tasks, outperforming or matching the quality of offerings from established players like Runway Gen3, LumaLabs, and, notably, OpenAI's Sora.
In this blog, I'm going to cover what Meta Movie Gen is, how it works, its capabilities and limitations, and the safety considerations surrounding its use.
If you want to get an overview of the video generation field, I recommend going over this article on top AI video generators.
Meta Movie Gen is a collection of foundational models for generating various types of media, including text-to-video, text-to-audio, and text-to-image. It consists of four models:
Movie Gen Video is a 30-billion-parameter model designed to create images and videos based on text descriptions. The model can generate high-quality videos up to 16 seconds long that match the given text prompt. It can produce content in different sizes, resolutions, and lengths.
Here’s an example of a video generated with the prompt:
“A sloth with pink sunglasses lays on a donut float in a pool. The sloth is holding a tropical drink. The world is tropical. The sunlight casts a shadow.”
The model has the potential to revolutionize video editing workflows across various industries. Its ability to accurately understand and execute text-based editing instructions could significantly improve the editing process, making it faster, more efficient, and accessible to a wider range of users. This technology could benefit filmmakers, content creators, educators, and anyone who works with video content.
The training of the Movie Gen Video model involved several key components: data collection and preparation, the training process itself, fine-tuning for enhanced quality, and the upsampling techniques used to achieve high-resolution outputs.
The Movie Gen Video model was trained on a massive dataset containing hundreds of millions of video-text pairs and over a billion image-text pairs.
Each video in the dataset undergoes a rigorous curation process that involves filtering for visual quality, motion characteristics, and content relevance. The filtering process aims to select videos with non-trivial motion, single-shot camera work, and a diverse range of concepts, including a significant portion featuring humans.
Source: Movie Gen research paper
High-quality captions are very important for effectively training the model. Movie Gen Video uses the LLaMa3-Video model to generate detailed captions that accurately describe the video content. These captions go beyond simply labeling objects; they include descriptions of actions, camera movements, and even lighting information. This rich textual information helps the model learn a more nuanced understanding of visual storytelling.
The training process for Movie Gen Video is divided into several stages to improve efficiency and model scalability.
The model is first trained on the text-to-image task using lower-resolution images. This "warm-up" phase allows the model to learn fundamental visual concepts before tackling the more complex task of video generation.
The model is then trained jointly on both the text-to-image and text-to-video tasks, progressively increasing the resolution of the input data. This joint training approach helps the model use the abundance and diversity of image-text datasets while also learning the complexities of video generation.
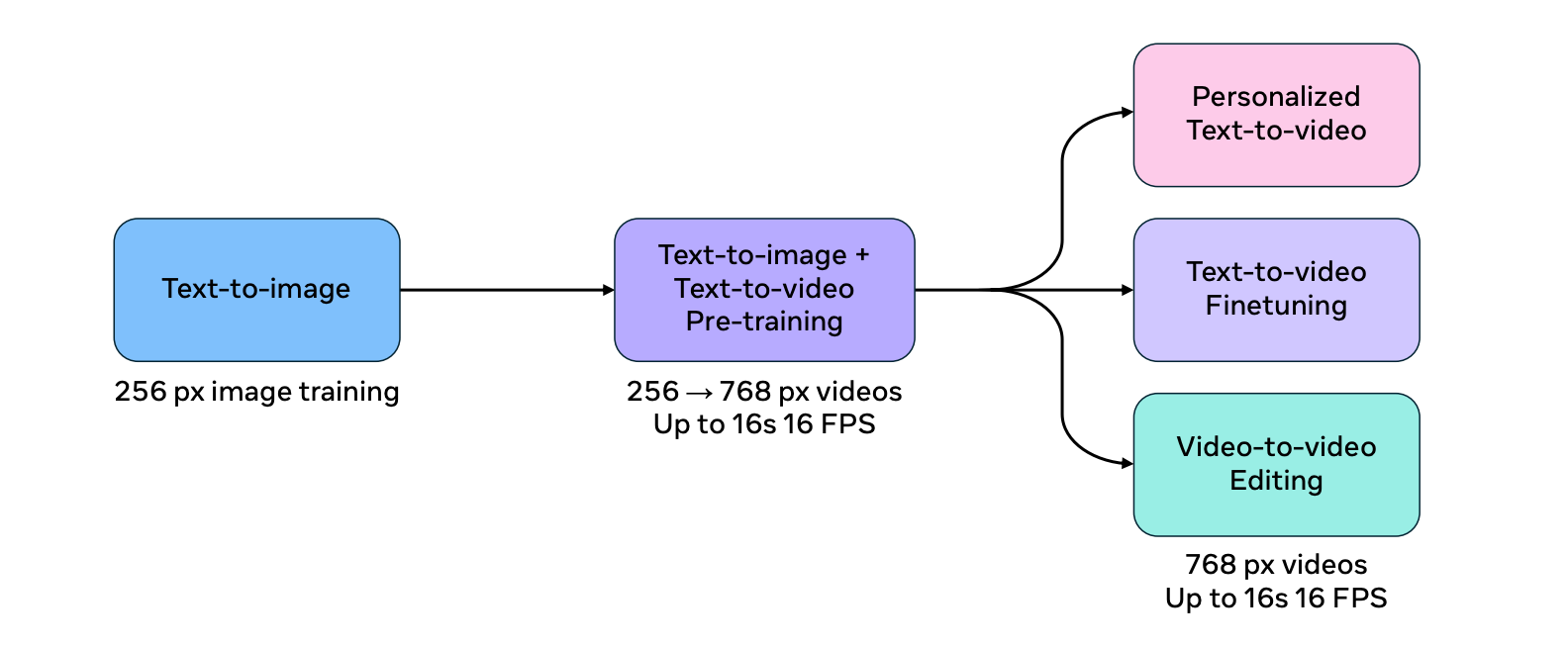
Source: Movie Gen research paper
To handle the computational demands of video data, Movie Gen Video uses a Temporal Autoencoder model (TAE) to compress and decompress the videos in time. This is analogous to zipping and unzipping files on a computer, allowing the model to work with a more manageable representation of the video data.
Source: Movie Gen research paper
Movie Gen Video uses a training objective called Flow Matching. Instead of directly generating the final video, flow matching guides the model to gradually transform a sample of random noise into the desired video output, step by step.
Flow Matching involves predicting the velocity of samples in the latent space rather than directly predicting the samples themselves. This method is more efficient and performant than traditional diffusion-based methods.
To improve the quality and aesthetics of the generated videos, the model undergoes supervised fine-tuning using a smaller set of manually curated videos with high-quality captions. This is like an artist refining their technique through expert guidance, leading to more visually appealing and realistic video outputs.
The final Movie Gen Video model is created by averaging multiple models trained with different datasets, hyperparameters, and pretraining checkpoints. This technique helps combine the strengths of different models, leading to more robust and reliable performance.
The model produces videos at a resolution of 768 pixels and uses upsampling to exchange the resolution to full HD 1080p, resulting in sharper and more visually appealing videos. This approach is commonly used because it provides a computationally efficient solution since the base model can process fewer tokens while still producing high-resolution outputs.
The Spatial Upsampler functions as a video-to-video generation model. It takes the lower-resolution video as input, upsamples it to the target resolution using bilinear interpolation, and then encodes it into a latent space using a frame-wise Variational Autoencoder (VAE).
A latent space model then generates the latents of the HD video, conditioned on the encoded latents of the lower-resolution video. Finally, the VAE decoder transforms the resulting HD video latents back into the pixel space, producing the final high-resolution output.
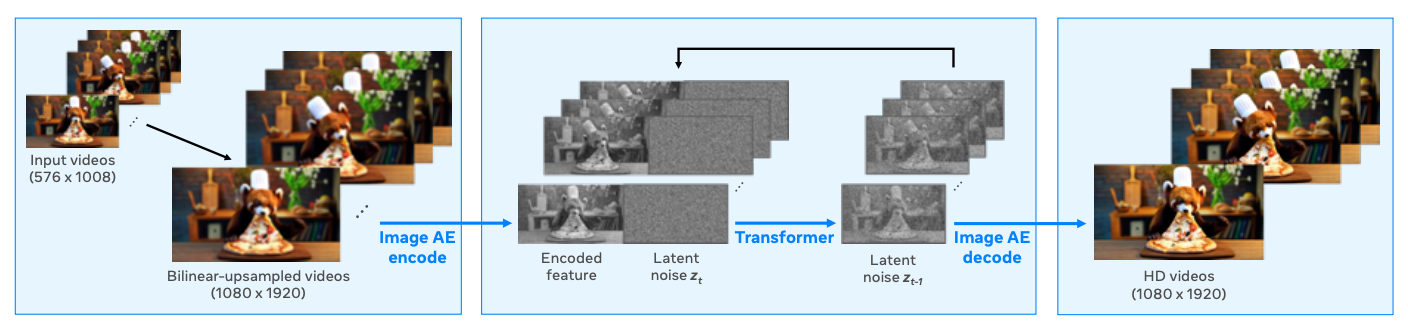
Source: Movie Gen research paper
Evaluating a text-to-video model is more challenging than a text-to-image model because of the added temporal dimension. The Meta team used three main measures to evaluate the model:
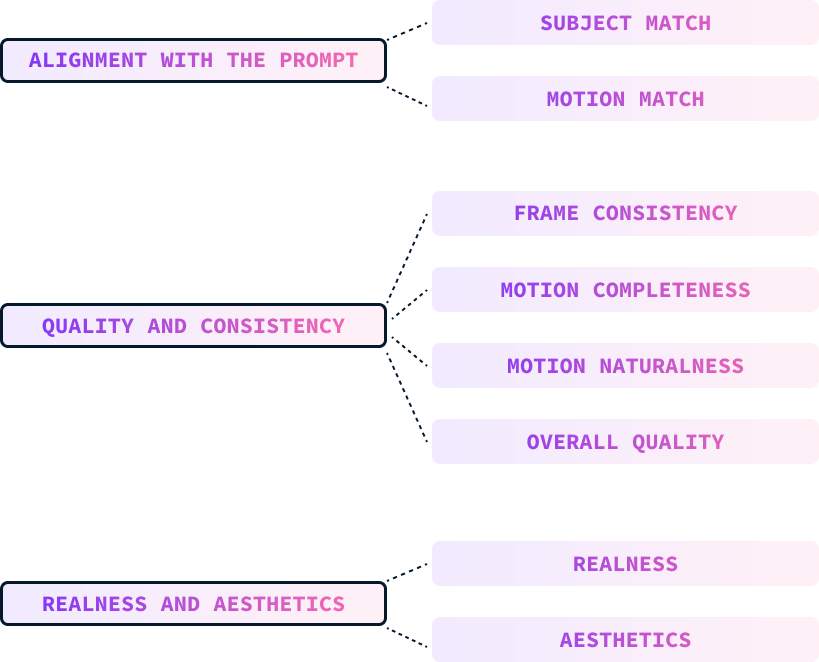
These parameters are evaluated manually by humans who grade the videos according to these parameters.
Prompt alignment measures how well the generated video matches the input text prompt, including descriptions of the subject, motion, background, and other details. This is further broken down into:
The quality and consistency of the generated video are evaluated independently of the text prompt. This measure is broken down into:
Evaluators were asked to rate the model's ability to produce photorealistic and aesthetically pleasing videos. This criteria is divided into:
The benchmark data was designed to evaluate video generations comprehensively. It includes 1,000 prompts that cover various testing aspects, such as human activity, animals, nature, physics, and unusual subjects or activities.
Their benchmark is over three times larger than those used in previous studies. Each prompt is tagged with a motion level (high, medium, low) to assess generation quality across different motion intensities.
The evaluation uses the entire prompt set and examines specific testing metrics, particularly focusing on how well models handle unusual subjects and motions to test their generalization capabilities.
The following diagram shows a breakdown of the prompts used in the evaluation. On the left, we are given the distribution of the concepts of the prompts. On the right side, we see common nouns and verbs used inside the prompts (the bigger the word, the more frequent it is):
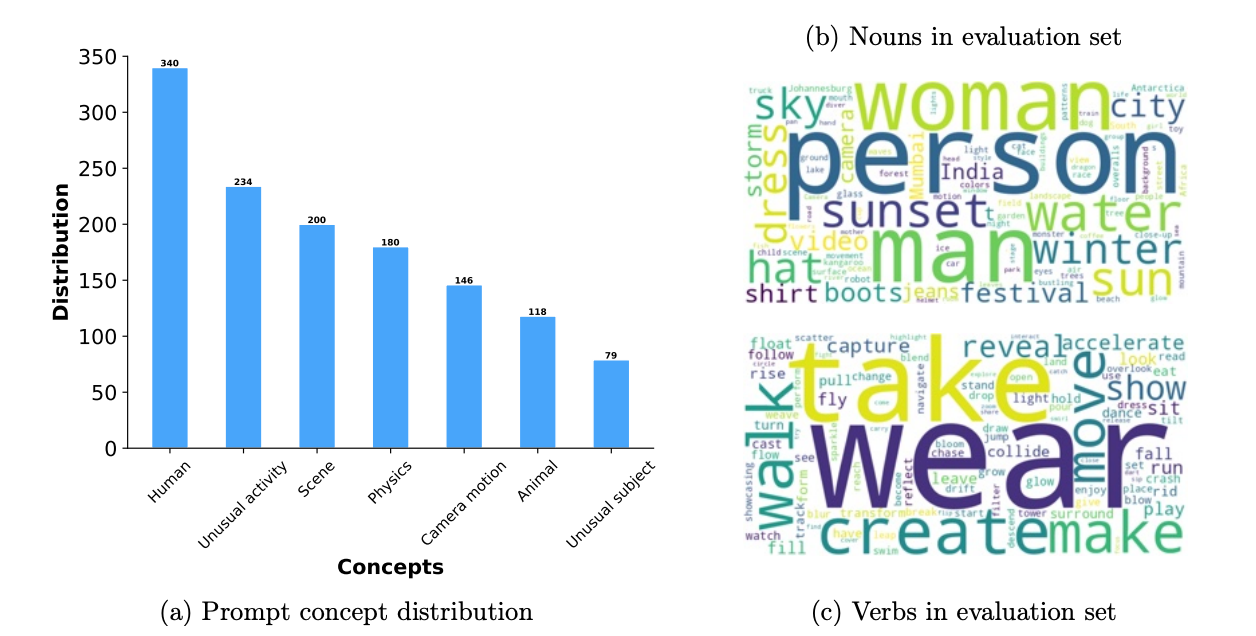
Source: Movie Gen research paper
The table below shows the results of the human evaluation of the videos produced by different models over several evaluation criteria. The numbers represent net win rates which are calculated as (Win % - Loss %). It ranges from -100 (complete loss) to 100 (complete win), with 0 indicating a tie.
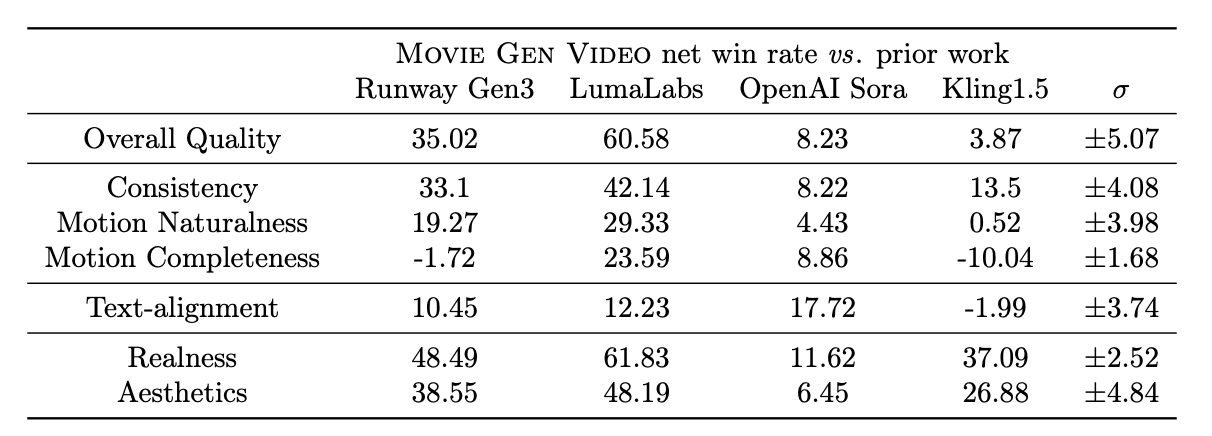
Source: Movie Gen research paper
According to their experiments, Movie Gen Video has strong performance in text-to-video generation, outperforming several existing models, including commercial systems like Runway Gen3 and LumaLabs, based on human evaluations using the MovieGen Video Bench. Specifically, Movie Gen Video shows significant advantages in:
While MovieGen generally outperforms other models, Kling1.5 sometimes generates videos with larger motion magnitudes, although at the cost of distortions and inconsistencies. This highlights the trade-off between motion completeness and visual quality, where Movie Gen Video prioritizes generating realistic and consistent motion over simply maximizing movement magnitude.
Below are some screenshots from the Meta Connect 2024 presentation showcasing a few comparison examples of video generation prompts:

Source: Movie Gen research paper
Here are some comparison examples of video personalization where a photo is used to generate a personalized video:

Source: Movie Gen research paper
Finally, the screenshots below showcase comparison examples of video editing:

Source: Movie Gen research paper
Overall, it seems that Meta Movie Gen pushed the bar and set a new standard in text-to-video models. The evaluation procedure highlighted in the paper appears fair but, of course, it’s hard to know for sure unless these models become publicly available and neutral third parties can compare them.
While Meta Movie Gen looks great in media generation, there are still areas for improvement.
The model sometimes struggles with complex scenes involving intricate geometry, object manipulation, and realistic physics simulations. For example, generating convincing interactions between objects, accurately depicting state transformations (like melting or shattering), and realistically simulating the effects of gravity or collisions can still pose challenges for the models.
Audio synchronization can be problematic in certain scenarios. Specifically, when dealing with motions that are visually small, occluded, or require a high level of visual understanding to generate the corresponding sound, the models may struggle to achieve perfect synchronization. Examples of such challenges include accurately synchronizing footsteps with a walking person, generating appropriate sounds for objects that are partially hidden from view, and recognizing subtle hand movements on a guitar to produce the correct musical notes.
Additionally, the Movie Gen Audio model, as currently designed, does not support voice generation.
Realistic AI-generated videos bring significant risks and ethical challenges that must be considered. These risks include the manipulation of trust and the spread of misinformation through deepfakes, which could damage reputations, misinform the public, and harm businesses.
On one hand, it can be an Instagram feature that lets me create a cool video with myself in it to share with my friends but on the other hand, the same feature makes it possible for me to create a fake video of someone else. As these technologies improve, it may become impossible to distinguish them from the real thing.
AI-generated content poses privacy threats, potentially leading to extortion, blackmail, or cyberbullying.
Moreover, these AI tools could undermine art and copyright by mimicking unique art styles without credit. Solutions involve spreading awareness and education about media literacy, investing in detection technology, establishing legal and ethical frameworks, and employing watermarking for authentication.
While AI video generation holds great potential, it requires careful handling to maintain trust and authenticity.
Meta has been open with its AI developments by open-sourcing the Llama models. However, for safety reasons, the Meta Movie Gen models aren’t going to be released yet. According to their article, multiple improvements and safety considerations are required before deploying them.
In this blog post, we introduced Meta's Movie Gen models, a suite of AI models for generating and editing videos using text prompts.
We explored the four distinct models, their capabilities, and how they work. Through a comparative analysis, we showcased how Meta Movie Gen stacks up against other AI video generation tools.
While Meta Movie Gen has set a new benchmark in the field, the technology's potential misuse raises significant concerns. Meta has acknowledged these risks and is taking a cautious approach to releasing these models.
To learn more about Meta AI’s ecosystem, I recommend these blogs:
Learn AI with these courses!
Track
Course
Course
blog
Richie Cotton
8 min
blog
Dr Ana Rojo-Echeburúa
9 min
blog
Iva Vrtaric
11 min
blog
Dr Ana Rojo-Echeburúa
8 min
blog
Dr Ana Rojo-Echeburúa
8 min
blog
Alex Olteanu
8 min

