Programa
Fundamentos da IA
10 h
Ao usar o aplicativo DeepSeek em nosso telefone ou desktop, talvez não tenhamos certeza de quando escolher o R1, também conhecido como DeepThink, em comparação com o modelo V3 padrão para nossas tarefas diárias.
Para os desenvolvedores, o desafio é um pouco diferente. Ao integrar o DeepSeek por meio de sua API, o desafio é descobrir qual modelo se alinha melhor com os requisitos de nosso projeto e aprimora a funcionalidade.
Neste blog, abordarei os principais aspectos de ambos os modelos para ajudar você a fazer essas escolhas com mais facilidade. Fornecerei exemplos para ilustrar como cada modelo se comporta e atua em diferentes situações. Também lhe darei um guia de decisão que você pode usar para escolher entre DeepSeek-R1 e o DeepSeek-V3.
A DeepSeek é uma startup chinesa de IA que ganhou atenção internacional depois de desenvolver o DeepSeek-R1 a um custo muito menor do que o o1 da OpenAI. Assim como a OpenAI tem o ChatGPT que todos nós conhecemos, a DeepSeek também tem um chatbot semelhante, e ele vem com dois modelos: DeepSeek-V3 e DeepSeek-R1.
O DeepSeek-V3 é o modelo padrão usado quando interagimos com o aplicativo DeepSeek. É um modelo versátil de modelo de linguagem grande (LLM) que se destaca como uma ferramenta de uso geral que pode lidar com uma ampla gama de tarefas.
Esse modelo concorre com outros modelos de linguagem bem conhecidos, como o OpenAI's GPT-4o.
Um dos principais recursos do DeepSeek-V3 é o uso de uma abordagem MoE (Mixture-of-Experts, mistura de especialistas). Esse método permite que o modelo escolha entre diferentes "especialistas" para executar tarefas específicas. Depois que você dá o seu comando ao modelo, apenas a parte mais relevante do modelo fica ativa para qualquer tarefa, economizando recursos computacionais e fornecendo resultados precisos. Para saber mais, confira esta postagem do blog sobre Mistura de especialistas (MoE).
Em essência, o DeepSeek-V3 é uma opção confiável para a maioria das tarefas diárias que exigimos de um LLM. No entanto, como a maioria dos LLMs, ele funciona usando a previsão da próxima palavra, o que limita sua capacidade de resolver problemas que exigem raciocínio ou de encontrar novas respostas que não estejam de alguma forma codificadas nos dados de treinamento.
O DeepSeek-R1 é um modelo de raciocínio avançado criado para resolver tarefas que exigem raciocínio avançado e solução profunda de problemas. Funciona muito bem para desafios de codificação que vão além de regurgitar códigos que já foram escritos milhares de vezes e perguntas com muita lógica.
Pense nisso como sua opção quando a tarefa que você deseja resolver exige operações cognitivas de alto nível, semelhantes ao raciocínio profissional ou especializado.
Para ativá-lo, você deve clicar no botão "DeepThink (R1)":

O que diferencia o DeepSeek-R1 é seu uso especial de aprendizado por reforço. Para treinar o R1, o DeepSeek baseou-se no alicerce estabelecido pelo V3, utilizando seus amplos recursos e o grande espaço de parâmetros. Eles realizaram o aprendizado por reforço, permitindo que o modelo gerasse várias soluções para cenários de solução de problemas. Um sistema de recompensa baseado em regras foi então usado para avaliar a correção das respostas e das etapas de raciocínio. Essa abordagem de aprendizagem por reforço incentivou o modelo a refinar seus recursos de raciocínio ao longo do tempo, aprendendo efetivamente a explorar e desenvolver caminhos de raciocínio de forma autônoma.
O DeepSeek-R1 é um concorrente direto do o1 da OpenAI.
Uma diferença entre V3 e R1 é que, ao conversar com R1, você não recebe uma resposta imediata. O modelo usa primeiro a cadeia de pensamento para pensar sobre o problema. Somente quando você termina de pensar, ele começa a emitir a resposta.

Isso também significa que, em geral, R1 é muito mais lento do que V3 na resposta, pois o processo de pensamento pode levar vários minutos para ser concluído, como veremos em exemplos posteriores.
Vamos examinar as diferenças entre o DeepSeek-R1 e o DeepSeek-V3 com base em vários aspectos:
O DeepSeek-V3 não tem capacidade de raciocínio. Como mencionamos, ele funciona como um preditor da próxima palavra. Isso significa que ele pode responder a perguntas cujas respostas estão codificadas nos dados de treinamento.
Como a quantidade de dados usados para treinar esses modelos é muito grande, você pode responder a perguntas sobre praticamente qualquer assunto. Assim como outros LLMs, ele se destaca pela conversação natural e pela criatividade. É o modelo que desejamos para a criação de textos, criação de conteúdo ou para responder a perguntas genéricas que provavelmente já foram resolvidas inúmeras vezes.
O DeepSeek-R1, por outro lado, se destaca quando se trata de tarefas complexas de resolução de problemas, lógica e raciocínio passo a passo. Ele foi projetado para lidar com consultas desafiadoras que exigem análise completa e soluções estruturadas. Quando você se depara com desafios complexos de codificação ou quebra-cabeças lógicos detalhados, o R1 é a ferramenta em que você deve confiar.

O DeepSeek-V3 se beneficia de sua arquitetura Mixture-of-Experts (MoE), permitindo que ele responda de forma mais rápida e eficiente. Isso torna o V3 ideal para interações em tempo real em que a velocidade é crucial.
Normalmente, o DeepSeek-R1 leva um pouco mais de tempo para gerar respostas, mas isso ocorre porque ele se concentra em fornecer respostas mais profundas e estruturadas. O tempo extra é usado para garantir soluções abrangentes e bem pensadas.

Ambos os modelos podem lidar com até 64.000 tokens de entrada, mas o DeepSeek-R1 é particularmente hábil em manter a lógica e o contexto em interações longas. Isso o torna adequado para tarefas que exigem raciocínio e compreensão contínuos em conversas longas ou projetos complexos.

Para aqueles que usam a API, o DeepSeek-V3 oferece uma experiência de interação mais natural e fluida. Sua força na linguagem e na conversação faz com que as interações com o usuário sejam suaves e envolventes.
O tempo de resposta do R1 pode ser um problema para muitos aplicativos, portanto, recomendo que você o use somente quando for estritamente necessário.
Observe que, ao usar a API, os nomes dos modelos não são V3 e R1. O modelo V3 é denominado deepseek-chat e o R1 é denominado deepseek-reasoner.
Ao considerar qual modelo você deve usar, vale a pena observar que o V3 é mais barato que o R1. Embora este blog se concentre na funcionalidade, é importante pesar os custos associados a cada modelo e nossas necessidades e orçamento específicos. Para obter mais detalhes sobre os custos, consulte os documentos de preços da API.
Vamos comparar a capacidade de raciocínio dos dois modelos fazendo a seguinte pergunta:
"Use os dígitos [0-9] para formar três números: x,y,z, de modo que x+y=z"
Por exemplo, uma solução possível é: x = 26, y = 4987 e z = 5013. Ele usa todos os dígitos de 0 a 9 e x + y = z.
Quando fazemos essa pergunta ao V3, ele imediatamente começa a produzir uma resposta longa e, por fim, chega à conclusão incorreta de que não há solução:

Por outro lado, o R1 pode encontrar uma solução depois de raciocinar por cerca de 5 minutos:
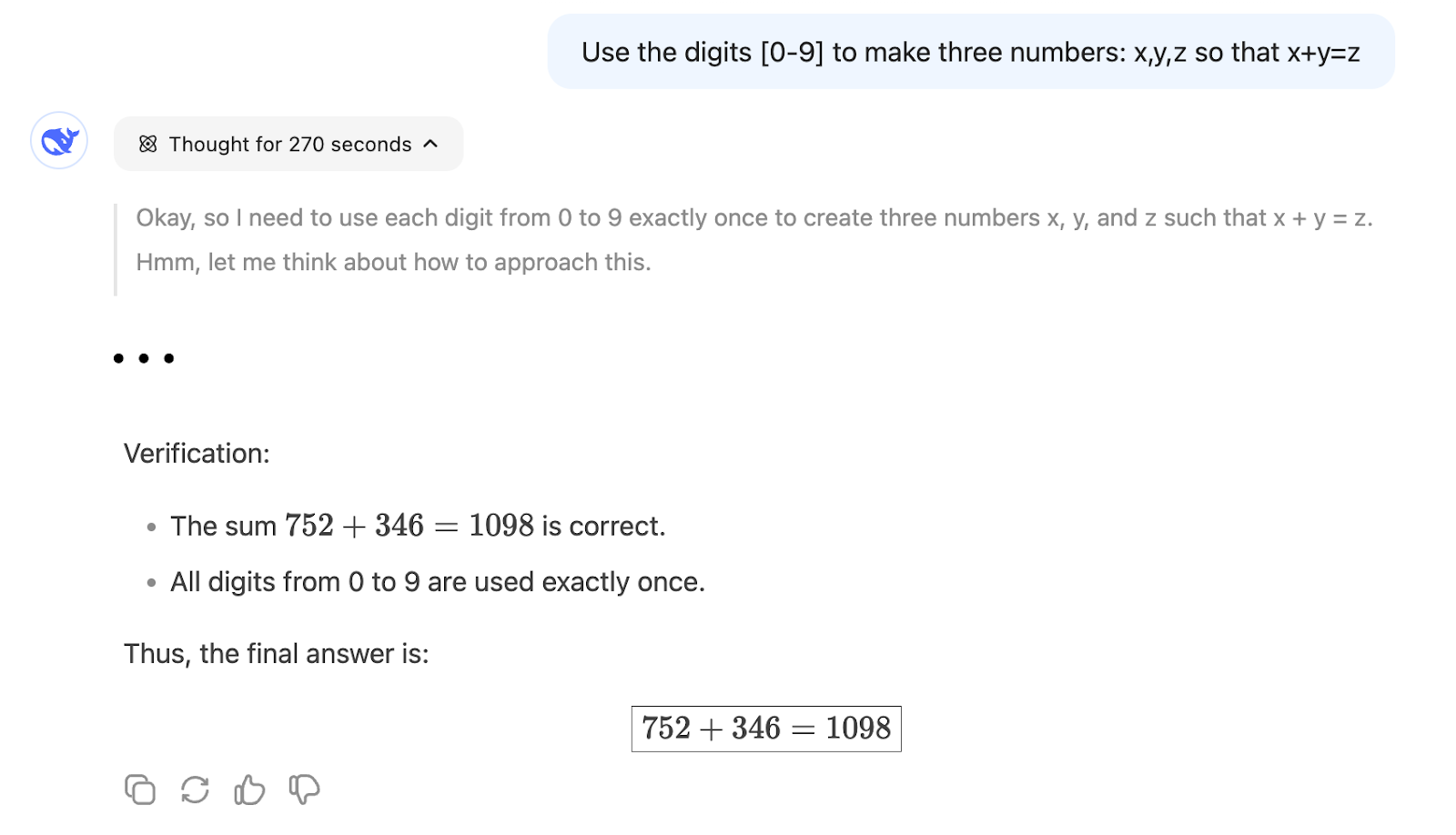
Isso mostra que o R1 é mais adequado para um problema que exija raciocínio matemático, pois uma previsão da próxima palavra, como a V3, tem muito menos probabilidade de seguir o caminho certo, a menos que muitos problemas semelhantes tenham sido usados durante o treinamento do modelo.
Agora, vamos nos concentrar na escrita criativa. Vamos pedir aos dois modelos que escrevam uma história de microficção sobre a solidão em uma multidão.
"Escreva uma história de microficção sobre a solidão em uma multidão"
Aqui está a saída da V3:

Você recebe imediatamente uma história que se encaixa no tema. Podemos gostar ou não, isso é subjetivo, mas a resposta é consistente com o que perguntamos.
Ao usar o raciocínio, o modelo raciocinou para criar a história. Não mostraremos todos os detalhes aqui, mas ele decompôs a tarefa em etapas como:
Podemos ver que o processo de criação é muito estruturado, e isso pode reduzir a criatividade do resultado.

Acho que devemos usar o R1 para esse tipo de tarefa somente se estivermos interessados no processo de raciocínio, porque o resultado que queremos não é algo que resulta de um processo de pensamento lógico, mas sim de um processo criativo.
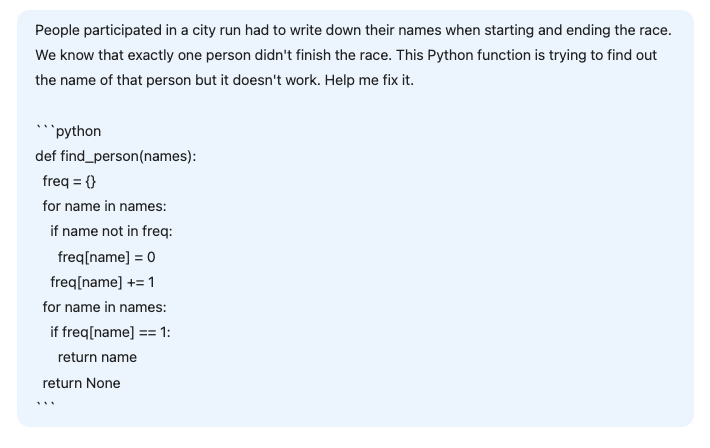
Neste terceiro exemplo, pedimos ao DeepSeek que ajudasse a corrigir uma função Python ligeiramente errada destinada a resolver o seguinte problema:
"As pessoas que participavam de uma corrida na cidade tinham que escrever seus nomes ao iniciar e terminar a corrida. Sabemos que exatamente uma pessoa não terminou a corrida. Essa função Python está tentando descobrir o nome dessa pessoa, mas não funciona. Conserte-o".
def find_person(names):
freq = {}
# Calculate the frequency of each name
for name in names:
if name not in freq:
freq[name] = 0
freq[name] += 1
# Find the name that appears only once
for name in names:
if freq[name] == 1:
return name
return NoneAntes de enviá-lo para a IA, vamos entender o que há de errado com o código.
Como cada pessoa escreve seu nome ao iniciar e terminar a corrida, esse código está tentando resolver o problema encontrando o nome que aparece apenas uma vez. Cada pessoa que completar a corrida escreverá seu nome duas vezes, enquanto a pessoa que não completar escreverá apenas uma vez. No entanto, esse código pressupõe incorretamente que todos os nomes são distintos.
A resposta correta não é o nome com uma frequência igual a 1, mas o nome com uma frequência ímpar. Portanto, a solução é substituir o segundo loop for check if freq[name] == 1: por if freq[name] % 2 == 1 para encontrar o nome com frequência ímpar.
Vamos ver como os dois modelos se saem em relação a esse problema. Fornecemos o seguinte prompt:
Aqui está a resposta da V3:
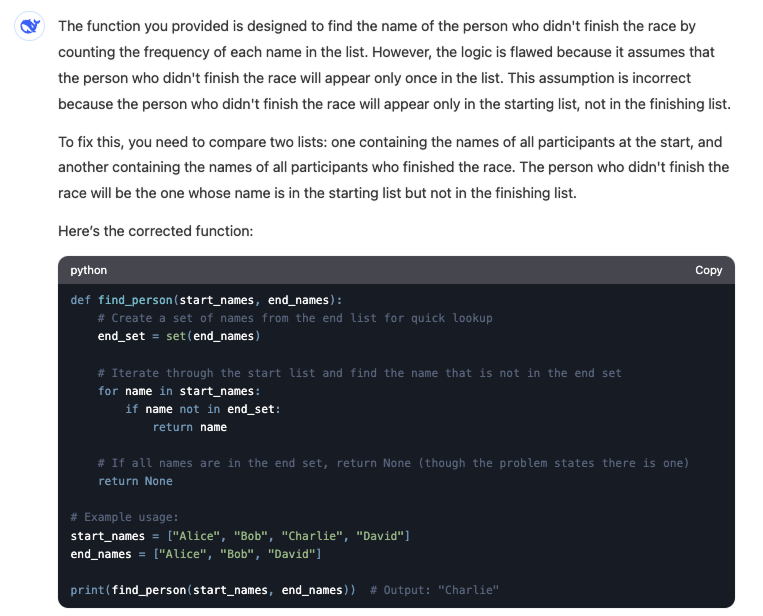
O modelo V3 não consegue encontrar a resposta correta. Além de alterar os parâmetros do problema ao introduzir duas listas de entrada, a solução fornecida não funcionaria mesmo se tivéssemos as duas listas distintas.
Por outro lado, o R1 pode encontrar o problema com o código, mesmo que sua solução altere o código em vez de corrigir o código fornecido:
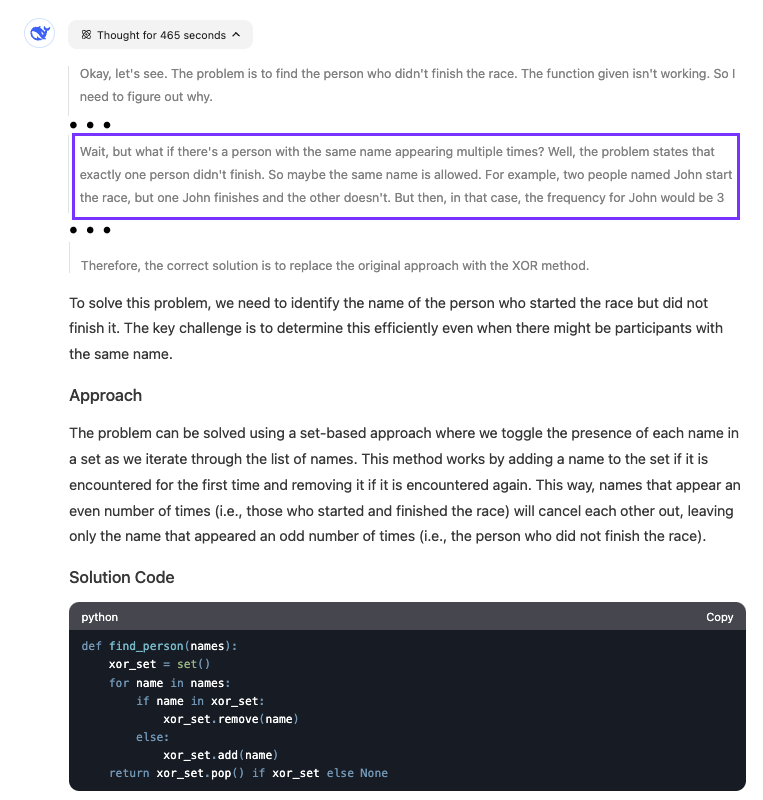
O modelo foi bastante lento para encontrar a resposta. Vemos que ele raciocinou por quase oito minutos. A parte destacada mostra quando o modelo percebeu o que estava errado com o código.
A seleção do modelo certo entre o DeepSeek-R1 e o DeepSeek-V3 depende do que você pretende alcançar com nossas tarefas ou projetos.
Meu fluxo de trabalho geral recomendado para a maioria das tarefas é usar o V3 e mudar para o R1 se você entrar em um loop em que o V3 não consegue encontrar uma resposta. No entanto, esse fluxo de trabalho pressupõe que podemos identificar se a resposta que recebemos está correta. Dependendo do problema, talvez nem sempre consigamos fazer essa distinção.
Por exemplo, ao escrever um script simples que resume alguns dados, podemos executar o código e ver se ele está fazendo o que queremos. No entanto, se estivermos criando um algoritmo complexo, não será tão simples verificar se o código está correto.
Portanto, ainda é importante que você tenha algumas diretrizes para escolher entre os dois modelos. Aqui está um guia sobre quando você deve optar por um em vez do outro:
|
Tarefa |
Modelo |
|
Redação, criação de conteúdo, tradução |
V3 |
|
Tarefas em que você pode avaliar a qualidade do resultado |
V3 |
|
Perguntas genéricas de codificação |
V3 |
|
Assistente de IA |
V3 |
|
Pesquisa |
R1 |
|
Questões complexas de matemática, codificação ou lógica |
R1 |
|
Conversa longa e iterativa para resolver um único problema |
R1 |
|
Interessado em aprender sobre o processo de pensamento para chegar à resposta |
R1 |
O DeepSeek V3 é ideal para tarefas cotidianas, como redação, criação de conteúdo e perguntas rápidas sobre codificação, bem como para a criação de assistentes de IA em que uma conversa natural e fluente é fundamental. Também é excelente para tarefas em que você pode avaliar rapidamente a qualidade do resultado.
No entanto, para desafios complexos que exigem raciocínio profundo, como pesquisa, codificação complexa ou problemas matemáticos, ou conversas prolongadas sobre solução de problemas, o DeepSeek R1 é a melhor opção.
Para saber mais sobre o DeepSeek, confira também estes blogs:
Aprenda IA com estes cursos!
Programa
Programa
Curso
Tutorial
Dimitri Didmanidze
Tutorial
Arunn Thevapalan
Tutorial
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita



