Programa
Fundamentos de machine learning Em Python
16 h
O campo cada vez maior da ciência de dados prospera com os dados, mas a aquisição de conjuntos de dados grandes e rotulados pode ser um gargalo significativo no processo de desenvolvimento de modelos. É aí que entra o aprendizado de poucos disparos, oferecendo uma abordagem revolucionária que nos permite extrair insights valiosos de apenas alguns exemplos.
Em contraste com os métodos tradicionais de aprendizagem supervisionada que exigem grandes quantidades de dados, a aprendizagem com poucos disparos permite que os modelos aprendam e se adaptem rapidamente, o que os torna altamente relevantes em domínios em que os dados são escassos, caros para coletar ou sensíveis por natureza.
Este artigo oferece uma exploração abrangente da aprendizagem de poucos disparos, aprofundando-se em sua importância, mecanismos e diversas aplicações em vários setores.
O aprendizado com poucas tentativas (FSL) é um subcampo do machine learning em que os modelos aprendem a reconhecer padrões e a fazer previsões com base em um número muito pequeno de exemplos de treinamento. Isso contrasta com o aprendizado supervisionado tradicional, que geralmente requer grandes quantidades de dados rotulados para um treinamento eficaz.
O FSL enfatiza a generalização em vez da memorização. Um dos primeiros trabalhos foi o artigo "Language Models are Few Shot Learners", de Tom B. Brown et al, que desafiava a necessidade de um ajuste fino extensivo.
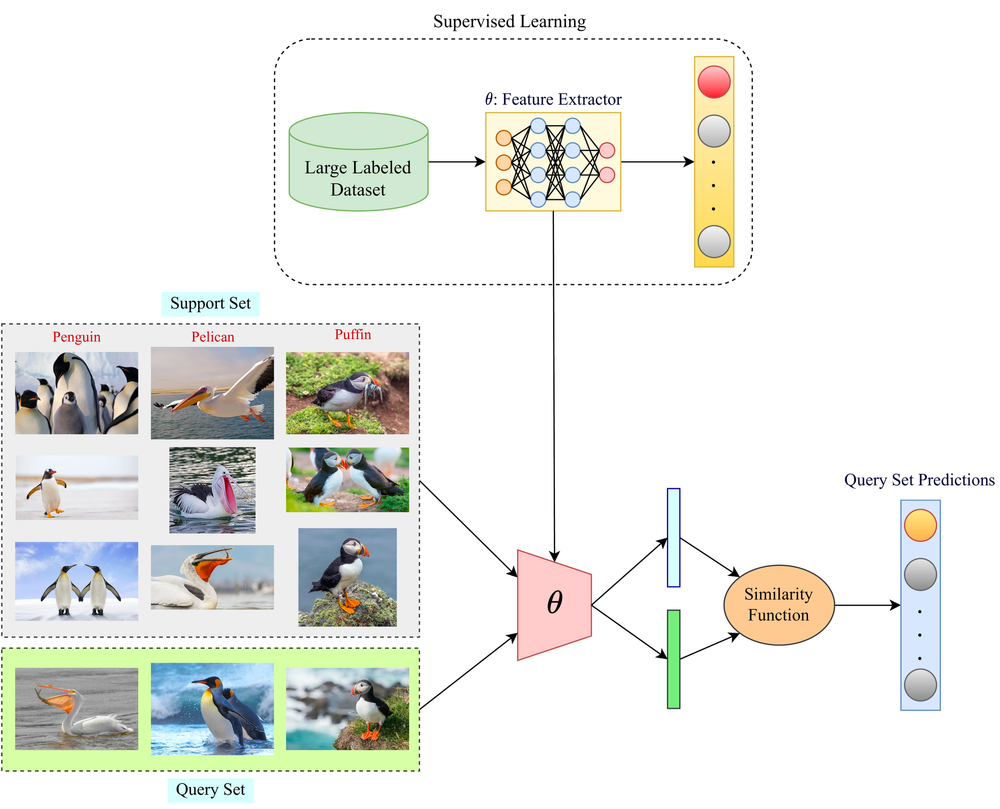
Um diagrama que ilustra a diferença entre as abordagens de aprendizado supervisionado e de aprendizado de poucos disparos. A seção de aprendizado supervisionado mostra um grande conjunto de dados rotulados sendo usado para treinar um modelo de extrator de recursos, enquanto a seção de aprendizado de poucos disparos demonstra o uso de um pequeno conjunto de exemplos de suporte e uma função de similaridade para fazer previsões em um conjunto de consultas. Fonte: Espaço de papel
Pense em uma criança que está aprendendo a identificar diferentes animais. Com apenas alguns exemplos de cães, gatos e pássaros, eles podem reconhecer e distinguir rapidamente essas criaturas no futuro, mesmo que encontrem raças ou espécies que nunca tenham visto antes.
Essa capacidade de generalizar a partir de dados limitados é uma característica marcante da inteligência humana e é exatamente o que o aprendizado de poucos disparos pretende alcançar.
A chave está na capacidade de discernir a estrutura subjacente e os recursos que definem uma categoria.
Os seres humanos possuem uma capacidade inata de extrair informações essenciais de experiências limitadas e aplicar esse conhecimento a novas situações. Os modelos de aprendizagem de poucos disparos tentam imitar isso, aprendendo uma compreensão geral da estrutura subjacente dos dados a partir de experiências anteriores.
Esse conhecimento é então aproveitado para se adaptar rapidamente a novas tarefas com o mínimo de informações adicionais, assim como a criança que reconhece uma nova raça de cachorro com base em seu conhecimento existente sobre cães.
A FSL ajuda o desenvolvedor a se concentrar no desenvolvimento de modelos em vez de na aquisição de dados. A capacidade de aprender com dados limitados oferece várias vantagens:
A aprendizagem de poucas tentativas se enquadra no conceito mais amplo de aprendizagem de n tentativas, abrangendo várias técnicas com base no número de exemplos fornecidos:
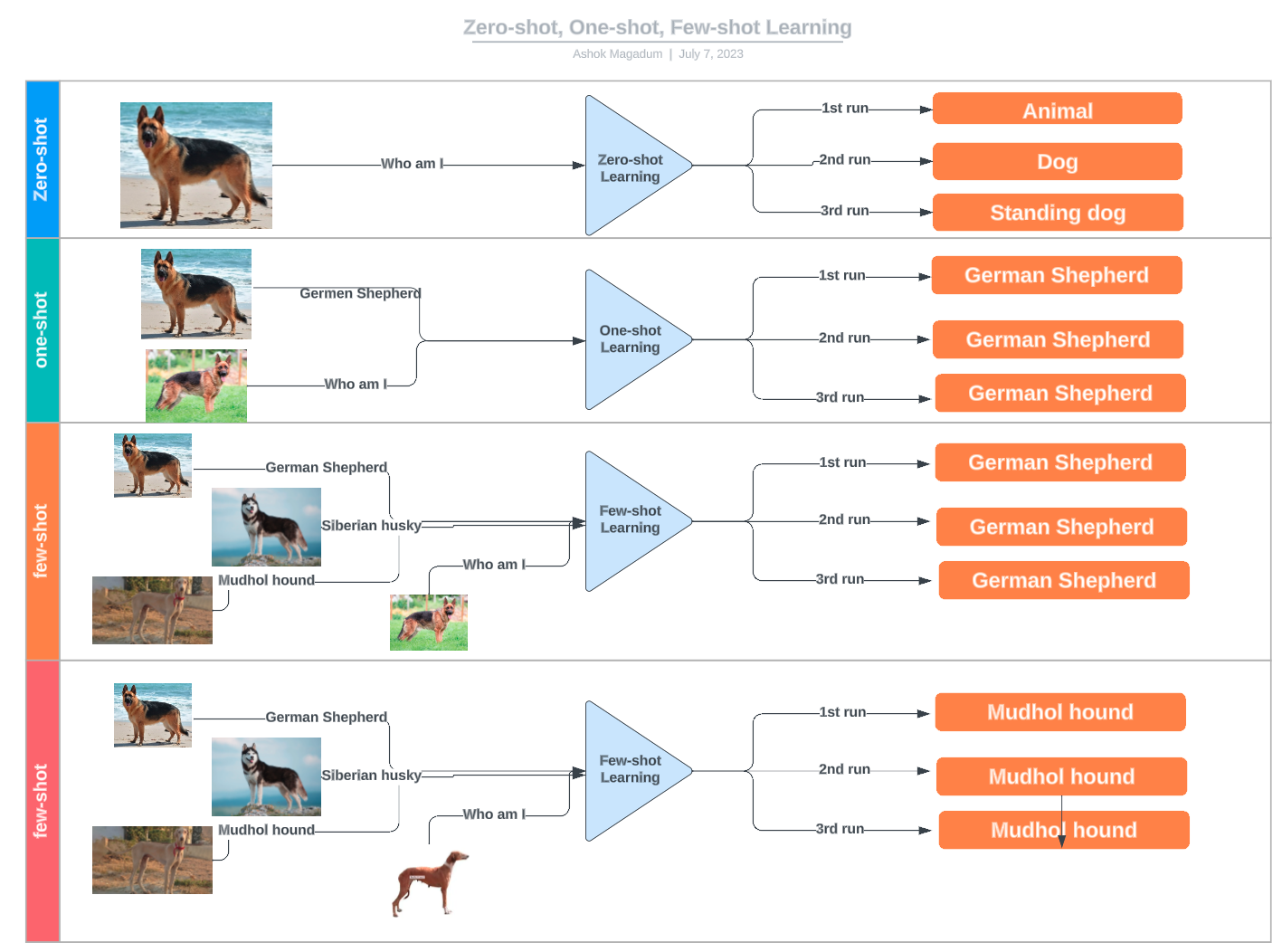
Um diagrama que ilustra as diferenças entre o aprendizado com zero, um e poucos disparos usando exemplos de classificação de raças de cães. Fonte: LinkedIn
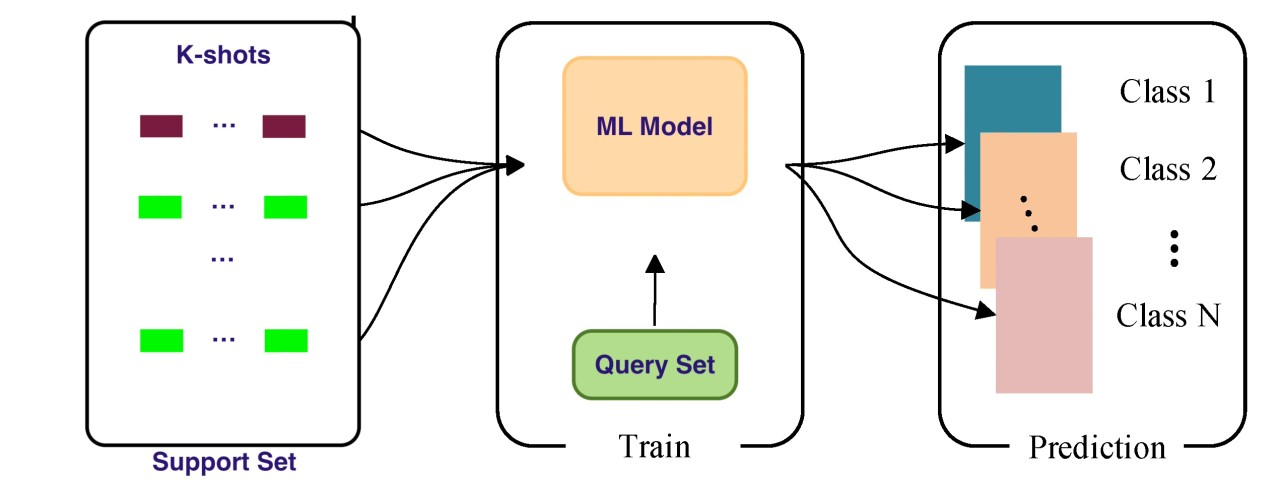
Um diagrama que ilustra o processo de aprendizado de poucos disparos. Ele mostra um conjunto de suporte contendo k exemplos de disparos para várias classes, um modelo de machine learning sendo treinado em um conjunto de consultas e o modelo fazendo previsões para novas instâncias de dados em diferentes classes. Fonte: LinkedIn
Ao contrário da aprendizagem supervisionada tradicional, que depende de extensos conjuntos de dados de treinamento, os modelos de aprendizagem de poucos disparos aproveitam o conhecimento prévio e as experiências de aprendizagem para se adaptar rapidamente a novas tarefas com o mínimo de dados adicionais. Ao discernir a estrutura subjacente e os recursos mais importantes que definem um conceito, esses modelos podem generalizar com eficiência, fazendo previsões precisas sobre novas instâncias com apenas alguns exemplos.
Esse conhecimento é então aplicado para se adaptar rapidamente a novas tarefas por meio de uma função de similaridade que pode mapear as classes nos conjuntos de consulta e suporte com o mínimo de informações adicionais.
Para fins de contexto, o conjunto de consultas aqui se refere às amostras de categorias antigas e novas, que o modelo generaliza e usa para avaliar o desempenho. Por outro lado, o conjunto de suporte consiste nas poucas amostras rotuladas de cada nova categoria de dados, que são usadas para atualizar os parâmetros do modelo:
O MAML aprende uma inicialização de modelo geral que pode ser ajustada para tarefas específicas com apenas algumas etapas de gradiente. É uma abordagem de meta-aprendizagem versátil e avançada, que permite que os modelos se adaptem a novas tarefas com eficiência notável.
Sua força está na capacidade de aprender uma inicialização de modelo que facilita a aprendizagem rápida por meio de apenas algumas etapas de descida de gradiente em uma nova tarefa.
Essa característica efetivamente torna o modelo "fácil de ajustar", permitindo que ele compreenda rapidamente as complexidades de novas tarefas com o mínimo de dados.
O MAML funciona com base no princípio de aprender um conjunto de parâmetros iniciais θ que são altamente sensíveis às mudanças na tarefa. Essa sensibilidade garante que pequenos ajustes nos parâmetros possam melhorar significativamente a função de perda de qualquer tarefa extraída da distribuição de tarefas p(T) quando atualizada na direção do gradiente dessa perda.
Aqui você encontra um detalhamento do algoritmo MAML:
O aprendizado métrico se concentra no aprendizado de uma função de distância que mede a similaridade entre os pontos de dados. Ele se concentra no aprendizado de uma função de distância, denotada como d(x, x'), que mede a similaridade entre os pontos de dados x e x'. Isso permite que os modelos classifiquem novos pontos de dados comparando-os com alguns exemplos conhecidos.
A aprendizagem por transferência aproveita o conhecimento adquirido em uma tarefa de origem para melhorar o desempenho em uma tarefa de destino relacionada.
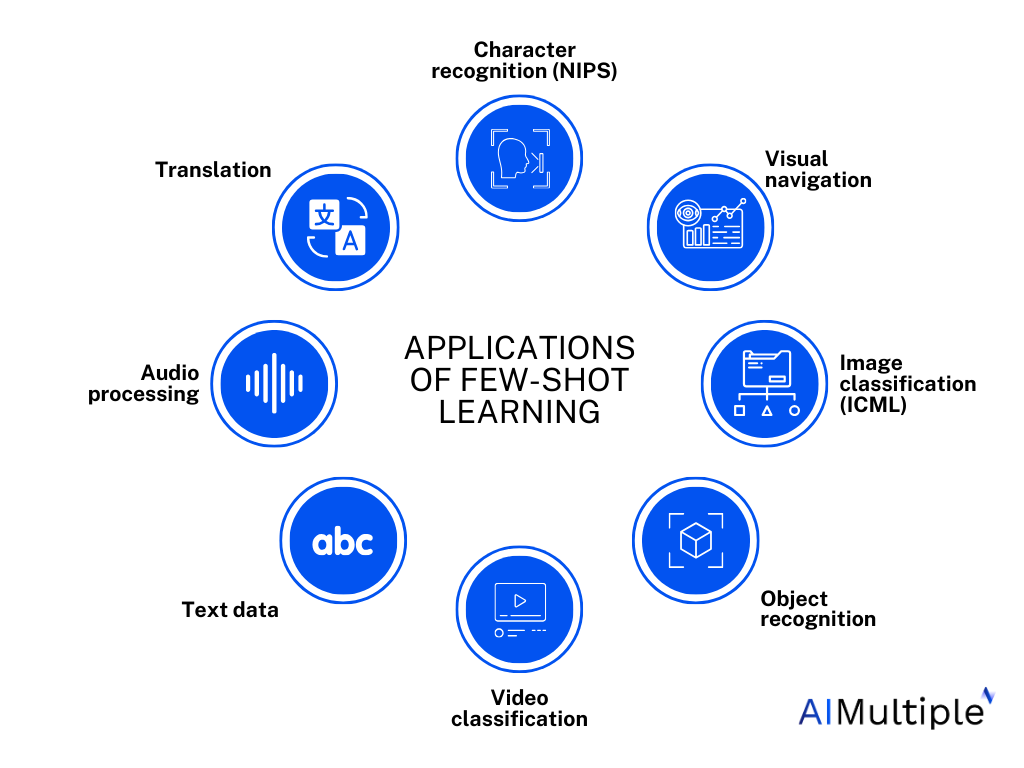
Um resumo das aplicações da FSL em vários domínios. Fonte: Pesquisa múltipla de IA
As aplicações da aprendizagem de poucos disparos são vastas e de longo alcance, abrangendo campos tão diversos quanto visão computacional, processamento de linguagem natural, robótica e saúde. No campo da visão computacional, por exemplo, o aprendizado de poucos disparos pode permitir que os sistemas reconheçam objetos raros ou identifiquem padrões obscuros em imagens médicas com apenas alguns exemplos de treinamento.
No processamento de linguagem natural, o aprendizado de poucos disparos pode abrir caminho para modelos de linguagem personalizados que podem imitar o estilo de escrita ou o dialeto exclusivo de um indivíduo, revolucionando a criação de conteúdo e a comunicação. Além disso, ela tem um imenso potencial para preservar e traduzir idiomas com poucos recursos, promovendo maior compreensão e inclusão cultural.
Talvez uma das aplicações mais transformadoras esteja na descoberta de medicamentos e na área da saúde. Ao treinar modelos com dados limitados de testes clínicos ou casos de doenças raras, o aprendizado de poucos disparos pode acelerar o desenvolvimento de tratamentos que salvam vidas e permitir um diagnóstico mais preciso, melhorando, em última análise, os resultados para os pacientes.
Apesar de seu imenso potencial, o aprendizado com poucas fotos tem seus desafios. Um dos principais obstáculos é o risco de sobreajuste, em que os modelos se tornam muito especializados nos dados de treinamento limitados e não conseguem generalizar com eficiência para novas instâncias. Além disso, a seleção da medida de similaridade ou da função de distância adequada é crucial para o desempenho preciso, e a ambiguidade da tarefa ou os dados ruidosos podem impedir ainda mais a eficácia do modelo.
No entanto, esses desafios apenas alimentaram uma onda de pesquisa e inovação no campo. Abordagens como meta-aprendizagem, aprendizagem métrica e aprendizagem por transferência surgiram como estratégias promissoras para aprimorar os recursos de aprendizagem de poucos disparos. Técnicas como MAML (Model-Agnostic Meta-Learning) e Redes Prototípicas demonstraram um sucesso notável na adaptação rápida a novas tarefas com o mínimo de dados.
À medida que o campo continua a evoluir, podemos esperar o surgimento de métodos de aprendizado de poucos disparos ainda mais sofisticados e robustos, ampliando os limites do que é possível com dados limitados. Em última análise, o verdadeiro poder do aprendizado de poucos disparos está em sua capacidade de democratizar a IA, tornando-a acessível a domínios e aplicativos que antes eram prejudicados pela escassez de dados e dando início a uma nova era de inteligência artificial eficiente em termos de dados, adaptável e inclusiva.
O aprendizado de poucos disparos representa um avanço significativo no campo do machine learning, permitindo que você extraia insights de dados limitados. Ao compreender as várias abordagens e aplicações, os profissionais de dados juniores podem aproveitar essa poderosa ferramenta para resolver problemas do mundo real em diversos domínios.
À medida que a pesquisa continua, podemos esperar o surgimento de técnicas de aprendizado de poucos disparos ainda mais inovadoras e eficientes, ampliando ainda mais os limites da ciência de dados.
Se você quiser dominar outros conceitos de machine learning, confira nosso programa de carreira Cientista de Machine Learning com Python.
Continue aprendendo com a DataCamp
Programa
Programa
Curso