Curso
Introdução a Deep Learning em Python
4 h
263.5K
A transferência de aprendizado é uma técnica que permite que as máquinas explorem o conhecimento adquirido em uma tarefa anterior para melhorar a generalização sobre outra. É um conceito fundamental por trás do desenvolvimento de modelos como o ChatGPT e o Google Gemini, e ajuda em muitas tarefas importantes e úteis, como resumir documentos longos, redigir ensaios complexos, organizar viagens ou até mesmo escrever poemas e músicas.
Neste guia, exploraremos a aprendizagem por transferência em profundidade. Discutiremos sua definição, por que ela é relevante para a aprendizagem profunda e para os modelos modernos de IA generativa, além dos desafios e das limitações dessa técnica. Também sugeriremos recursos para que você possa continuar aprendendo. Você está pronto? Vamos começar.
A aprendizagem por transferência é uma técnica em que um modelo desenvolvido para uma determinada tarefa é reutilizado como ponto de partida para um modelo em uma segunda tarefa. Em outras palavras, você reaplica os componentes de um modelo de machine learning pré-treinado a novos modelos destinados a algo diferente, porém relacionado.
O conceito é semelhante à forma como os seres humanos aprendem novas habilidades. Vamos dar um exemplo: Imagine que você é um exímio violonista e decide aprender a tocar ukulele. Sua experiência prévia com o violão acelerará o processo de aprendizado. Isso ocorre porque muitas das habilidades e dos conhecimentos necessários para tocar violão - como posições dos dedos, padrões de dedilhado, compreensão do braço da guitarra, teoria musical e ritmo - também se aplicam ao ukulele.
Na IA, a aprendizagem por transferência permite que você aproveite o treinamento anterior para resolver problemas novos e relacionados com mais eficiência, reduzindo assim o tempo e os recursos computacionais.
Há vários motivos convincentes para adotar técnicas de aprendizagem por transferência ao desenvolver redes neurais, incluindo:
Vamos explorar três conceitos relacionados à aprendizagem por transferência: aprendizagem multitarefa, extração de recursos e ajuste fino.
No aprendizado multitarefa, um único modelo é treinado para executar várias tarefas ao mesmo tempo. O modelo tem um conjunto compartilhado de camadas iniciais que processam os dados de forma comum, seguido por camadas separadas para cada tarefa específica. Isso permite que o modelo aprenda recursos gerais que são úteis para todas as tarefas e, ao mesmo tempo, aprenda recursos específicos da tarefa que são mais exclusivos.
Esse paradigma é amplamente usado nos LLMs modernos. Confira nosso curso Introduction to LLMs para saber todos os detalhes.
A extração de recursos envolve o uso de um modelo pré-treinado para extrair recursos ou representações significativas dos dados. Esses recursos são então usados como entrada para um novo modelo focado em algo específico.
A aprendizagem por transferência baseada em recursos aproveita os recursos exclusivos das redes neurais para extrair recursos dos dados. Com a extração de recursos, o modelo "descobre", por assim dizer, qual parte da entrada é importante para, por exemplo, classificar uma imagem. Em termos práticos, isso significa que, quando um modelo é aplicado a uma nova tarefa, somente as primeiras camadas e as camadas intermediárias pré-treinadas do modelo que contêm o conhecimento mais generalizável são aplicadas.
O ajuste fino vai além da extração de recursos e é comumente usado quando as duas tarefas não estão intimamente relacionadas. Isso envolve a utilização de um modelo pré-treinado e o treinamento adicional em um conjunto de dados específico do domínio.
A maioria dos modelos LLM atuais tem um desempenho global muito bom, mas muitas vezes falha em problemas específicos orientados a tarefas. O ajuste fino adapta o modelo para que ele tenha um melhor desempenho em tarefas específicas, tornando-o mais eficaz e versátil em aplicações do mundo real. Se você quiser saber mais sobre ajuste fino, consulte nosso Guia introdutório para ajuste fino de LLMs.
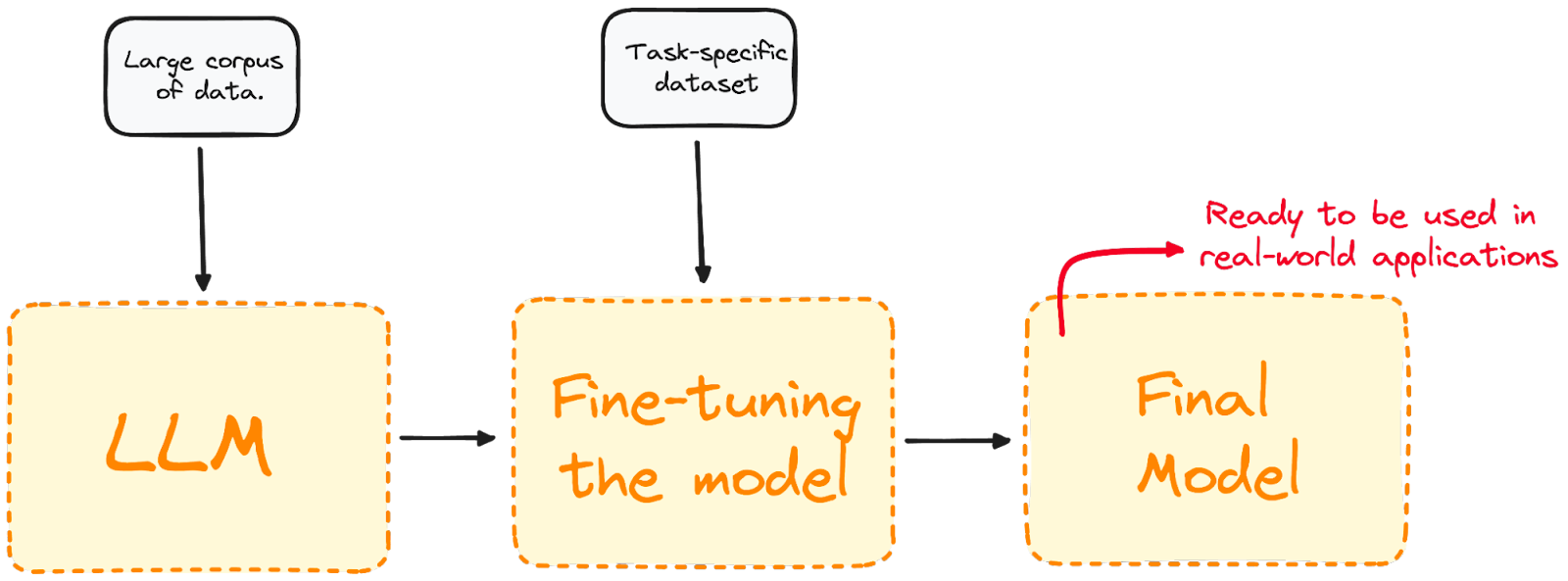 Visualizando o processo de ajuste finoVisualizando o processo de ajuste fino. [DataCamp]
Visualizando o processo de ajuste finoVisualizando o processo de ajuste fino. [DataCamp]
A aprendizagem por transferência é uma técnica comum para lidar com várias tarefas de ciência de dados, inclusive as de visão computacional e processamento de linguagem natural.
A visão computacional é um dos campos em que a aprendizagem por transferência tem sido especialmente proveitosa. As redes neurais desenvolvidas nesse campo requerem grandes quantidades de dados para lidar com tarefas como detecção de objetos e classificação de imagens.
Na visão computacional, as camadas iniciais das redes neurais detectam bordas nas imagens, enquanto as camadas intermediárias identificam formas e formatos. As camadas finais são adaptadas a tarefas específicas. A aprendizagem por transferência nos permite criar novos modelos treinando novamente apenas as camadas finais, mantendo inalterados os pesos e as tendências das camadas inicial e intermediária. Graças à aprendizagem por transferência, é possível criar novos modelos que apenas retreinam as últimas camadas da rede, mantendo os pesos e as tendências da primeira camada e das camadas intermediárias.
Atualmente, há um bom número de redes neurais públicas pré-treinadas em visões de computador, por exemplo:
A PNL é um ramo da IA que se concentra na interação entre computadores e seres humanos por meio da linguagem natural. O objetivo é programar computadores para processar e analisar grandes quantidades de dados de linguagem natural, seja em formato de texto ou áudio.
A aprendizagem por transferência desempenha um papel fundamental no desenvolvimento de modelos de PNL. Ele permite a utilização de modelos de idiomas pré-treinados que foram usados para a compreensão geral do idioma ou para a tradução e, em seguida, o ajuste fino para problemas específicos de PLN, como análise de sentimentos ou tradução de idiomas. As aplicações da PNL são praticamente infinitas e incluem assistentes de voz e reconhecimento de fala.
A aprendizagem por transferência está por trás de alguns dos modelos de PNL mais populares, incluindo:
Em sua essência, a aprendizagem por transferência é essencialmente uma abordagem de design para aumentar a eficiência. Em vez de treinar modelos do zero, o que exige uma grande quantidade de recursos, dinheiro e tempo no caso de modelos de IA geradores de ponta, a aprendizagem por transferência permite que os modelos aprendam de forma mais rápida e eficaz em novas tarefas, aproveitando o conhecimento adquirido no passado.
A aprendizagem por transferência se destaca quando há poucos dados disponíveis para treinar um modelo em uma segunda tarefa. Ao usar o conhecimento de um modelo pré-treinado, a aprendizagem por transferência pode ajudar a evitar o ajuste excessivo e aumentar a precisão geral. No entanto, a aprendizagem por transferência não é infalível e tem limitações e possíveis armadilhas que devem ser abordadas com cuidado. Alguns dos desafios mais comuns na aprendizagem por transferência são:
A aprendizagem por transferência é uma abordagem de projeto fundamental para aumentar a eficiência e o potencial das redes neurais. É justo dizer que a atual revolução da IA não teria sido possível sem as muitas técnicas de aprendizagem por transferência disponíveis.
Se você quiser saber mais sobre os detalhes da aprendizagem por transferência, o DataCamp está aqui para ajudar. Confira nossos materiais dedicados sobre LLMs e redes neurais para que você possa começar hoje mesmo.
Aprenda com a DataCamp
Curso
Curso
Curso