Curso
Redução de Dimensionalidade em Python
4 h
36.4K
A extração de recursos no aprendizado de máquina transforma dados brutos em um conjunto de características significativas, capturando informações essenciais e reduzindo a redundância. Ela pode envolver técnicas e métodos de redução de dimensionalidade que criam novos recursos a partir de dados existentes.
Imagine que você está tentando identificar frutas em um mercado. Embora você possa considerar inúmeros atributos (peso, cor, textura, forma, cheiro etc.), talvez perceba que apenas algumas características-chave, como cor e tamanho, são suficientes para distinguir entre maçãs e laranjas. É exatamente isso que a extração de recursos faz. Ele ajuda você a se concentrar nas características mais informativas dos seus dados.
Ao realizar a extração de recursos, os dados originais são matematicamente transformados em um novo conjunto de recursos. Esses novos recursos foram projetados para capturar os aspectos mais importantes dos dados e, ao mesmo tempo, reduzir sua complexidade. Os recursos extraídos geralmente representam padrões ou estruturas subjacentes que podem não ser imediatamente aparentes nos dados originais.
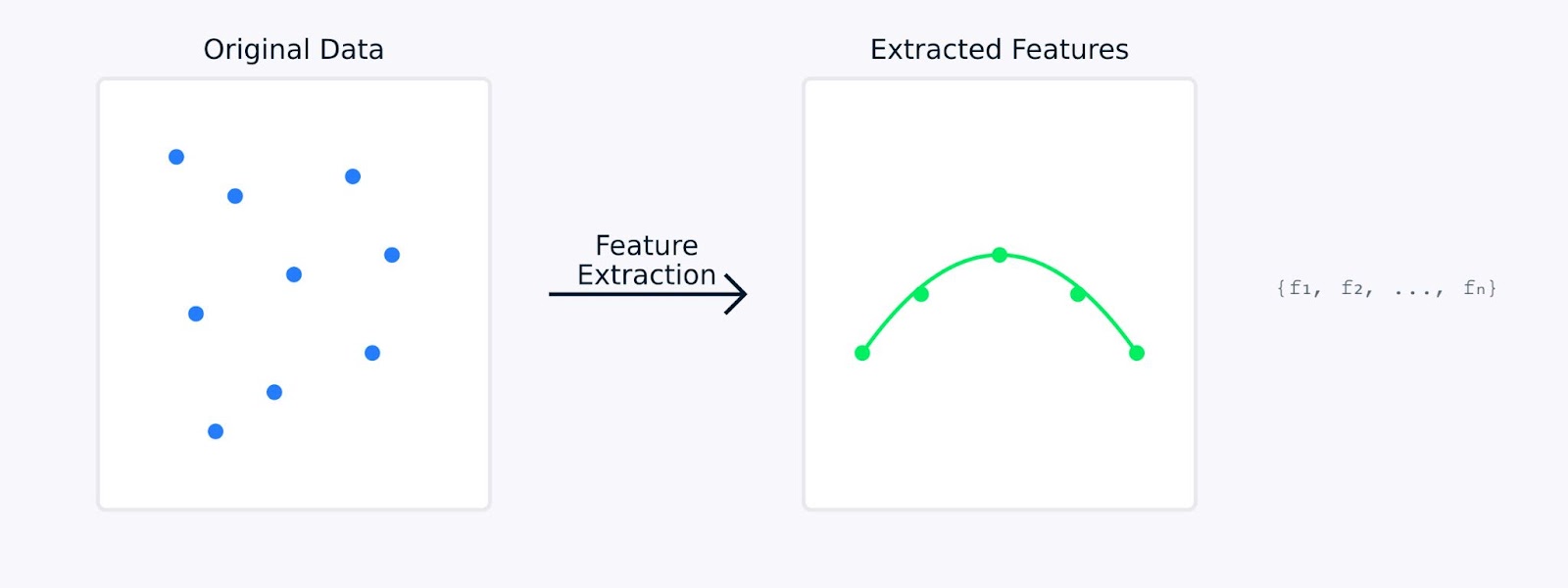
Extração de recursos
Nas próximas seções, exploraremos por que a extração de recursos é tão importante no aprendizado de máquina e analisaremos vários métodos para extrair recursos de diferentes tipos de dados, juntamente com seu código. Se você quiser alguns exemplos práticos, confira nosso Curso de redução de dimensionalidade em Pythonque tem um capítulo dedicado à extração de recursos.
A extração de recursos desempenha uma função importante no aprendizado de máquina. Isso pode fazer a diferença entre um modelo que fracassa e um que tem sucesso. Vamos ver por que isso é tão fundamental para a criação de modelos eficazes de aprendizado de máquina.
Ao trabalhar com dados brutos, modelos de aprendizado de máquina muitas vezes têm dificuldade para distinguir entre padrões significativos e ruído. A extração de recursos serve como uma etapa de pré-processamento de dados que pode melhorar significativamente o aprendizado e o desempenho de seus modelos.
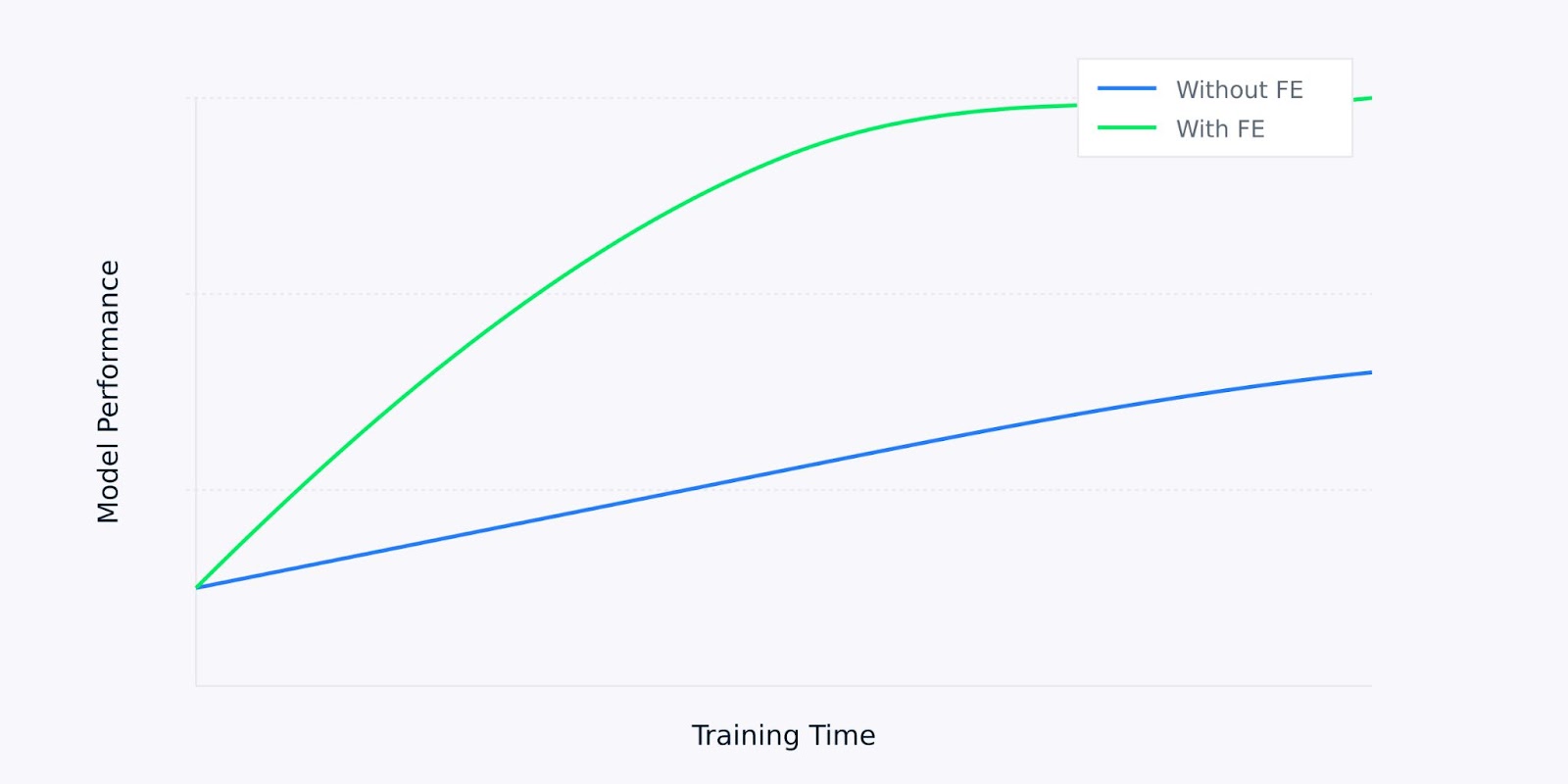
Desempenho do modelo versus tempo de treinamento
Por exemplo, quando um modelo atinge 85% de precisão com dados brutos, o mesmo modelo pode atingir 95% de precisão quando treinado com recursos cuidadosamente extraídos. Essa melhoria não vem da alteração do modelo, mas do fornecimento de dados de entrada de melhor qualidade com os quais você pode aprender.
Os conjuntos de dados modernos geralmente vêm com centenas ou milhares de recursos. Isso traz vários desafios que a extração de recursos ajuda a resolver.
A extração de recursos aborda esses desafios reduzindo a dimensionalidade e preservando as informações essenciais. Essa redução transforma dados extensos e de alta dimensão em uma forma mais compacta e gerenciável, levando a um melhor desempenho do modelo.
A extração de recursos oferece dois benefícios essenciais para os modelos de aprendizado de máquina:
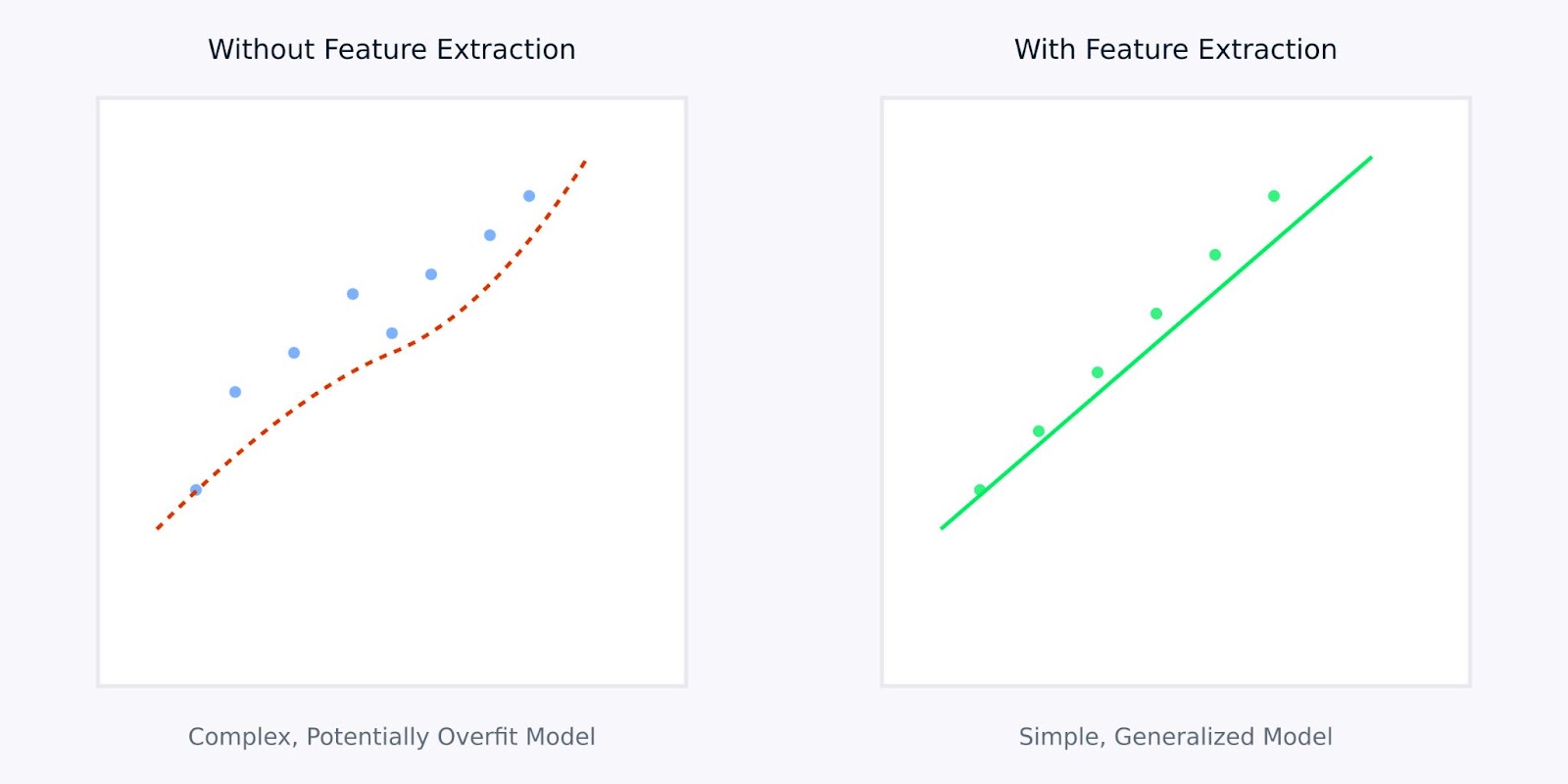
Extrações de recursos versus sem extração de recursos
A visualização acima ilustra como a extração de recursos pode levar a modelos mais simples e mais robustos. O gráfico da esquerda mostra um modelo complexo que tenta se ajustar a dados ruidosos e de alta dimensão, enquanto o gráfico da direita mostra como a extração de recursos pode revelar um padrão mais claro e generalizável.
Trabalhar com recursos extraídos em vez de dados brutos é como dar ao seu modelo uma versão clara e destilada das informações com as quais ele precisa aprender. Isso não apenas torna o processo de aprendizado mais eficiente, mas também leva a modelos com maior probabilidade de bom desempenho em aplicativos do mundo real.
A seguir, veremos diferentes métodos de extração de recursos.
Os métodos de extração de recursos podem ser amplamente categorizados em duas abordagens principais: engenharia manual de recursos e extração automatizada de recursos. Vamos examinar esses dois métodos para entender como eles ajudam a transformar dados brutos em recursos significativos.
A engenharia manual de recursos envolve o uso de conhecimento especializado no domínio para identificar e criar recursos relevantes a partir de dados brutos. Essa abordagem prática se baseia em nosso entendimento do problema e dos dados para criar recursos significativos.
Em processamento de imagensa engenharia manual de recursos pode envolver técnicas como detecção de bordas para identificar limites de objetos, histogramas de cores para capturar a distribuição de cores, análise de textura para quantificar padrões e descritores de forma para caracterizar a geometria do objeto.
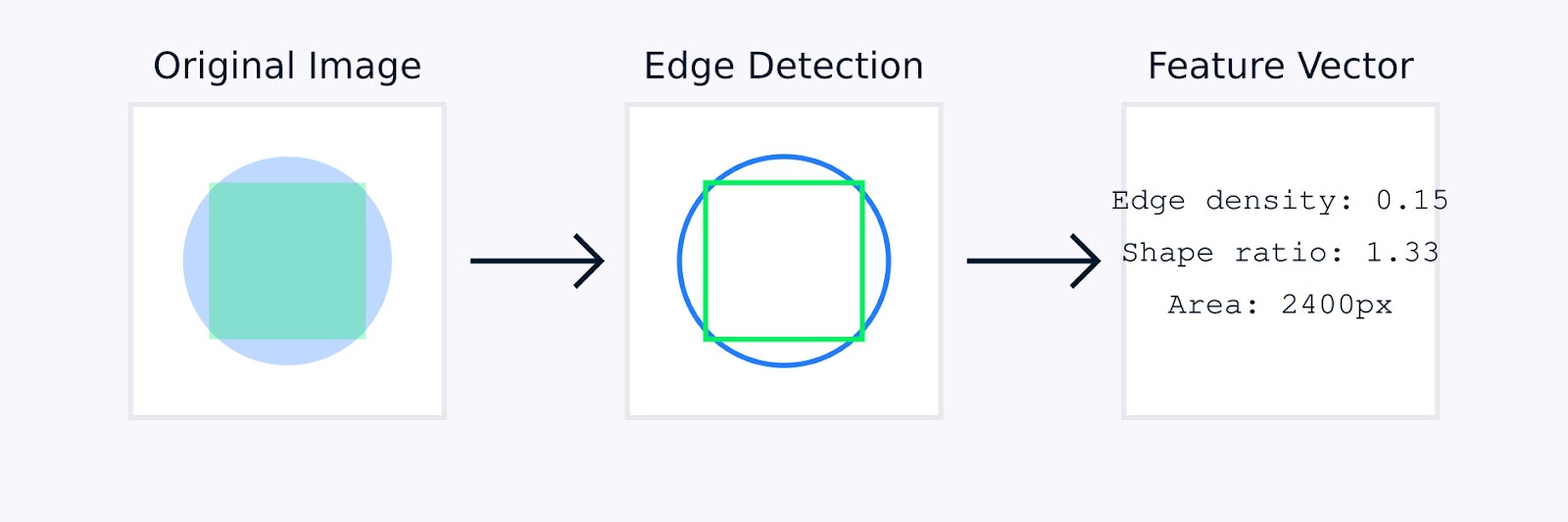
Extração de recursos de imagem
Para dados tabulares, a engenharia manual de recursos envolve a criação de termos de interação entre os recursos existentes, a transformação de variáveis usando funções logarítmicas ou polinomiais, a agregação de pontos de dados em estatísticas significativas e a codificação de variáveis categóricas.
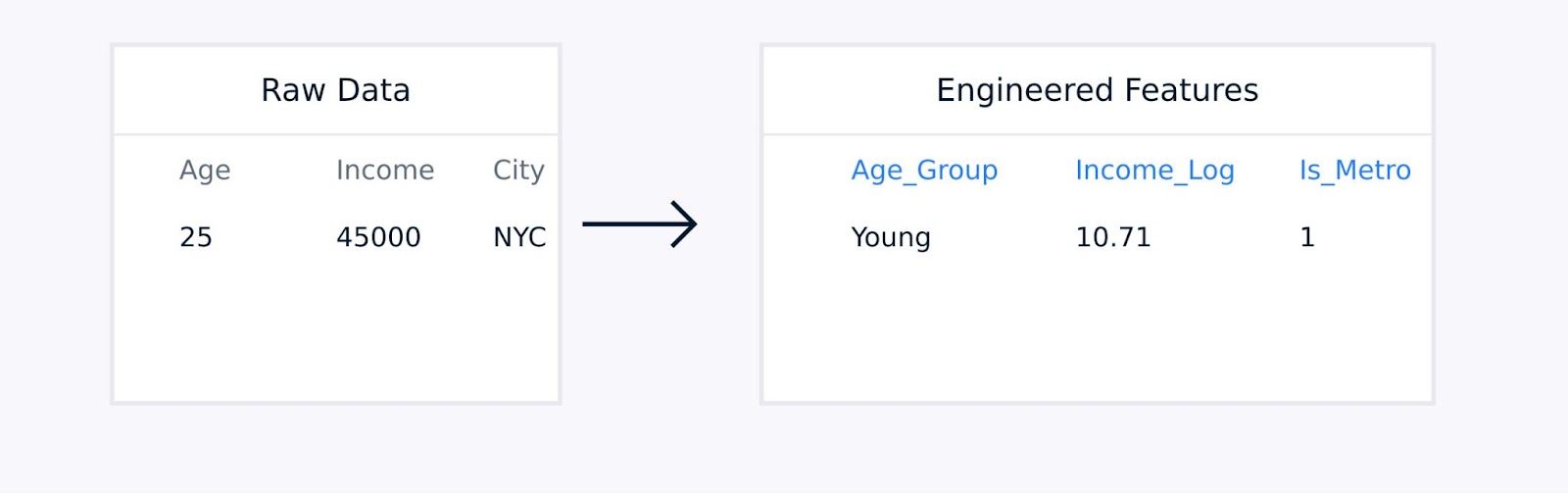
Extração de recursos de dados tabulares
Essas técnicas, orientadas pelo conhecimento do domínio, aprimoram a qualidade da representação dos dados e podem melhorar significativamente o desempenho do modelo.
A extração automatizada de recursos usa algoritmos para descobrir e criar recursos sem orientação humana explícita. Esses métodos são particularmente úteis ao lidar com conjuntos de dados complexos em que a engenharia manual de recursos pode ser impraticável ou ineficiente.
As abordagens automatizadas comuns incluem:
Análise de componentes principais (PCA): Transforma os dados em um conjunto de componentes não correlacionados, com cada componente capturando a variação máxima restante. Essa abordagem é particularmente útil para redução de dimensionalidadepois preserva as informações essenciais nos dados e, ao mesmo tempo, simplifica sua estrutura.
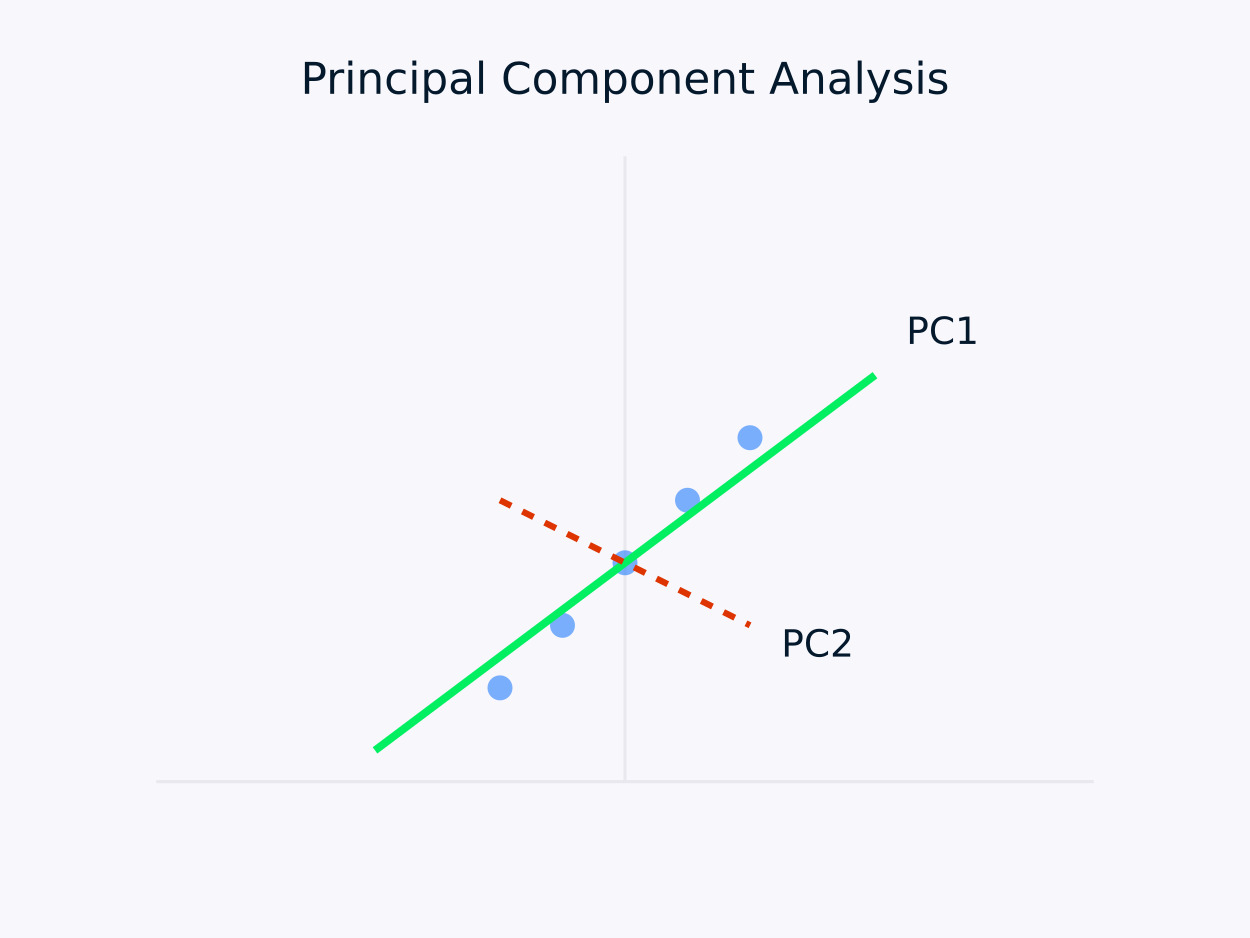
Análise de componentes principais (PCA)
Autoencodificadores: Essas são redes neurais que aprendem representações comprimidas de dados, capturando relações não lineares. Eles são particularmente eficazes para conjuntos de dados de alta dimensão, nos quais os métodos lineares tradicionais podem ser insuficientes.
Várias ferramentas e bibliotecas surgiram para simplificar as tarefas de engenharia de recursos. Por exemplo, o módulo de decomposição do Scikit-learn oferece uma variedade de métodos para redução de dimensionalidade, e o PyCaret fornece recursos de seleção automatizada de recursos.
Tanto as abordagens manuais quanto as automatizadas têm seus pontos fortes. Vamos analisar os pontos fortes de cada abordagem.
|
Engenharia manual |
Extração automatizada |
|
Integração do conhecimento de domínio |
Escalabilidade |
|
Recursos interpretáveis |
Lida com padrões complexos |
|
Controle refinado |
Reduz o preconceito humano |
|
Personalizado para necessidades específicas |
Descobre relacionamentos ocultos |
A escolha entre métodos manuais e automatizados geralmente depende de fatores como a complexidade do conjunto de dados, a disponibilidade de conhecimento especializado no domínio, os requisitos de interpretabilidade, os recursos computacionais e as restrições de tempo.
Para conjuntos de dados altamente complexos ou quando o tempo e os recursos são limitados, os métodos automatizados podem gerar rapidamente recursos úteis. Por outro lado, os métodos manuais podem ser preferíveis quando há conhecimento especializado no domínio e a interpretabilidade é uma prioridade, permitindo uma engenharia de recursos personalizada que se alinhe estreitamente ao problema em questão.
Na prática, muitos projetos bem-sucedidos de aprendizado de máquina combinam as duas abordagens, usando o conhecimento do domínio para orientar a engenharia de recursos e, ao mesmo tempo, aproveitando os métodos automatizados para descobrir padrões adicionais que podem não ser imediatamente aparentes para os especialistas humanos.
Na próxima seção, veremos várias técnicas de extração de recursos em diversos domínios.
Cada tipo de dado requer técnicas específicas de extração de recursos otimizadas para suas características exclusivas. Vamos dar uma olhada nas técnicas mais comuns para diferentes tipos de dados.

Técnicas de extração de recursos
A extração de recursos de imagem transforma dados brutos de pixel em representações significativas que capturam informações visuais essenciais. Há três categorias principais de técnicas usadas na visão computacional moderna. Eles são os métodos tradicionais, os métodos baseados em aprendizagem profunda e os métodos estatísticos.

Métodos de extração de recursos de imagem
Vamos dar uma olhada em cada um dos métodos.
Scale-Invariant Feature Transform (SIFT) é um método robusto que detecta características locais distintas em imagens. Ele funciona identificando pontos-chave e gerando descritores que são:
O algoritmo SIFT processa imagens em vários estágios. Ele começa com a detecção de extremos no espaço de escala para identificar possíveis pontos-chave que são invariáveis à escala. Em seguida, a localização de pontos-chave refina esses candidatos, identificando seus locais precisos e descartando pontos instáveis.
Depois disso, a atribuição de orientação determina uma orientação consistente para cada ponto-chave, garantindo a invariância de rotação. Por fim, a geração de descritor de ponto-chave cria descritores distintos com base em gradientes de imagem locais, facilitando a correspondência robusta entre imagens.
Outro método é o Histograma de Gradientes Orientados (HOG). Ele captura informações de forma local analisando padrões de gradiente em uma imagem. O processo começa com o cálculo de gradientes em toda a imagem para destacar os detalhes das bordas.
A imagem é então dividida em pequenas células e, para cada célula, é criado um histograma de orientações de gradiente para resumir a estrutura local. Por fim, esses histogramas são normalizados em blocos maiores para garantir a robustez contra variações de iluminação e contraste, resultando em um descritor de recursos robusto para tarefas como detecção e reconhecimento de objetos.
Redes neurais convolucionais (CNNs) mudaram a forma como fazemos a extração de recursos, aprendendo automaticamente representações hierárquicas.

Extração de recursos com a CNN
As CNNs aprendem recursos por meio de sua estrutura hierárquica. Nas camadas iniciais, eles detectam elementos visuais básicos, como bordas e cores. As camadas intermediárias combinam esses elementos para reconhecer padrões e formas, enquanto as camadas mais profundas capturam objetos complexos e permitem a compreensão da cena.
A aprendizagem por transferência nos permite usar esses recursos pré-aprendidos de modelos treinados em grandes conjuntos de dados, o que os torna particularmente valiosos quando se trabalha com dados limitados.
Os métodos estatísticos extraem padrões globais e locais das imagens, facilitando a análise e a interpretação robustas das imagens.
Por exemplo, histogramas de cores representam a distribuição de cores em uma imagem e fornecem recursos de rotação e escala invariantes, o que os torna particularmente úteis para tarefas como classificação e recuperação de imagens.
Análise de textura captura padrões repetidos e características de superfície usando técnicas como as Matrizes de Co-ocorrência de Nível de Cinza (GLCM), que são eficazes para aplicações que incluem reconhecimento de materiais e classificação de cenas.
Além disso, detecção de bordas identifica limites e alterações significativas de intensidade por meio de métodos como os operadores Sobel, Canny e Laplaciano, desempenhando um papel fundamental na detecção de objetos e na análise de formas.
A escolha do método de extração de recursos depende de vários fatores. Ele deve estar alinhado com os requisitos específicos da sua tarefa, considerar os recursos computacionais disponíveis e levar em conta a necessidade de interpretabilidade.
Além disso, as características do seu conjunto de dados, como tamanho, níveis de ruído e complexidade, desempenham um papel fundamental, assim como as propriedades de invariância necessárias, como escala, rotação e iluminação.
Imagine tentar ensinar um computador a entender a fala da mesma forma que os humanos entendem. É aqui que entram os coeficientes cepstrais de mel-frequência (MFCC).
Os MFCCs são recursos especiais de áudio que decompõem o som de maneira semelhante à forma como nossos ouvidos o processam. Eles são particularmente eficazes porque se concentram nas frequências às quais os seres humanos são mais sensíveis. Pense neles como a tradução do som em um formato que tanto os computadores quanto a audição humana considerariam significativo.
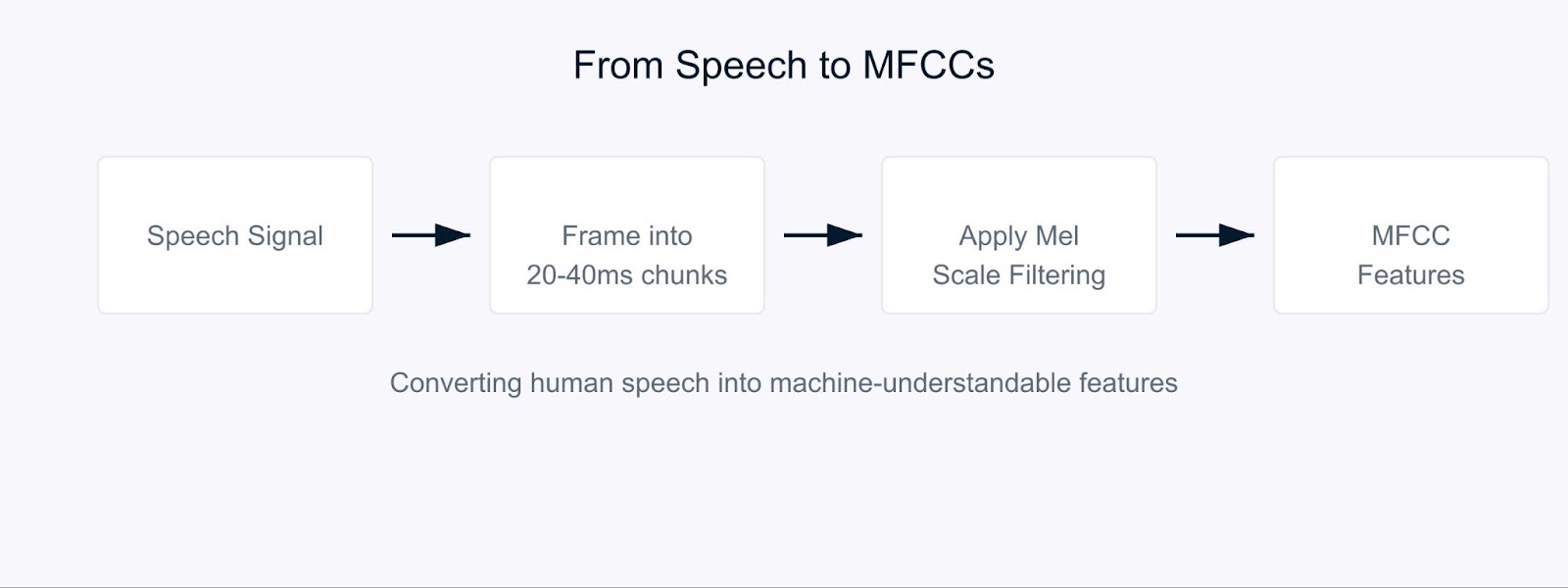
Coeficientes cepstrais de frequência de Mel
O processo começa dividindo o sinal de áudio em partes curtas, geralmente de 20 a 40 milissegundos. Para cada bloco, aplicamos uma série de transformações matemáticas que convertem as ondas sonoras brutas em componentes de frequência. É aqui que as coisas ficam interessantes. Em vez de tratar todas as frequências igualmente, usamos algo chamado escala Mel.
![]()
Essa fórmula pode parecer complexa, mas é simplesmente o mapeamento de frequências para corresponder à forma como os seres humanos percebem o som. Nossos ouvidos são melhores para detectar diferenças em frequências mais baixas do que em frequências mais altas, e a escala Mel leva em conta essa tendência natural.
No reconhecimento de voz, os MFCCs servem como base para entender quem está falando e o que está dizendo. Quando você fala com o assistente virtual do seu telefone, é provável que ele esteja usando MFCCs para processar sua voz. Esses coeficientes ajudam a capturar as características exclusivas da voz de cada pessoa, o que os torna valiosos para os sistemas de identificação de locutores.
Para a análise de sentimentos na fala, os MFCCs ajudam a detectar variações sutis na voz que indicam emoções. Eles podem capturar alterações no tom, no tom e na velocidade da fala que podem indicar se alguém está feliz, triste, irritado ou neutro. Por exemplo, ao analisar as chamadas de atendimento ao cliente, os MFCCs podem ajudar a identificar os níveis de satisfação do cliente com base na forma como ele fala, e não apenas no que ele diz.
Ao trabalhar com séries temporais a extração de recursos significativos nos ajuda a capturar padrões e tendências que evoluem ao longo do tempo. Vamos dar uma olhada em algumas técnicas importantes usadas para transformar dados brutos de séries temporais em recursos úteis.

Métodos de extração de recursos de séries temporais
A Transformada de Fourier decompõe os dados da série temporal em seus componentes de frequência, revelando padrões periódicos ocultos. A fórmula é:
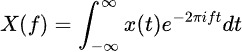
Os métodos estatísticos complementam a análise de frequência, capturando as características temporais. Os recursos comuns incluem médias móveis, desvios padrão e componentes de tendência. Essas técnicas são particularmente poderosas em previsão financeiraonde elas ajudam a identificar tendências e anomalias do mercado.
Por exemplo, na análise do mercado de ações, a combinação de recursos de Fourier com medidas estatísticas pode revelar tendências de longo prazo e padrões cíclicos. Da mesma forma, em ambientes industriais, esses métodos ajudam a detectar anomalias nos equipamentos, analisando os padrões de dados do sensor ao longo do tempo.
Vamos dar uma olhada em algumas ferramentas essenciais que tornam a implementação desses métodos de extração de recursos simples e eficiente.
Ferramentas e bibliotecas para extração de recursos
Para o processamento de imagens, o OpenCV e o scikit-image fornecem ferramentas abrangentes para a implementação de várias técnicas de extração de recursos. Essas bibliotecas oferecem implementações eficientes de SIFT, HOG e outros algoritmos que discutimos anteriormente. Ao trabalhar com abordagens de aprendizagem profunda, estruturas como o TensorFlow e o PyTorch se tornam inestimáveis. Você pode começar com nosso tutorial do OpenCV para que você saiba mais.
As tarefas de processamento de áudio são simplificadas com bibliotecas como a LibROSA, que se destaca na extração de MFCCs e outros recursos acústicos. O PyAudioAnalysis amplia esses recursos com interfaces de alto nível para tarefas de análise de áudio.
Para dados de séries temporais, o tsfresh e o Featuretools automatizam o processo de extração de recursos. Essas bibliotecas podem gerar e selecionar automaticamente recursos relevantes dos seus dados temporais, facilitando o foco no desenvolvimento do modelo em vez da engenharia de recursos.
Vamos colocar nosso conhecimento em prática com alguns exemplos práticos. Começaremos com a extração de recursos de imagem, um dos aplicativos mais comuns em visão computacional.
Primeiro, vamos importar as bibliotecas necessárias
# Import required libraries
import cv2
import numpy as np
import matplotlib.pyplot as pltAgora, vamos carregar uma imagem para extrair recursos relevantes. Para este exemplo, usaremos uma imagem do Godzilla baixada da Internet.
# Load the image
image = cv2.imread('godzilla.jpg')
# Convert BGR to RGB (OpenCV loads in BGR format)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Display the original image
plt.imshow(image_rgb)
plt.title('Original Image')
plt.axis('off')
plt.show()Saída:

Antes de aplicar a detecção de bordas, precisamos pré-processar a imagem. Fazemos isso da seguinte forma:
# Convert the image to grayscale
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Apply Gaussian blur to reduce noise
blurred = cv2.GaussianBlur(gray_image, (5, 5), 0)Por fim, vamos aplicar o algoritmo de detecção de bordas Canny e visualizar os resultados:
# Apply Canny edge detection
edges = cv2.Canny(blurred, threshold1=100, threshold2=200)
# Display the results
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(image_rgb)
plt.title('Original Image')
plt.axis('off')
plt.subplot(1, 2, 2)
plt.imshow(edges, cmap='gray')
plt.title('Edge Detection')
plt.axis('off')
plt.tight_layout()
plt.show()Saída:

O detector de bordas Canny nos ajuda a identificar limites e recursos importantes em nossa imagem, que podem ser usados para análise posterior ou como entrada para modelos de aprendizado de máquina.
Antes de começarmos a processar os arquivos de áudio, precisamos instalar as bibliotecas necessárias. Como a LibROSA não está incluída na biblioteca padrão do Python, usaremos o pip para instalá-la:
# Install required libraries
# Run these commands in your terminal or command prompt
pip install librosa
pip install numpy
pip install matplotlibA LibROSA é uma biblioteca avançada projetada para análise de música e áudio, portanto, vamos começar importando-a junto com outras bibliotecas necessárias:
# Import required libraries
import librosa
import librosa.display
import numpy as np
import matplotlib.pyplot as pltOs arquivos de som contêm muitas informações em formato de onda. Para trabalhar com esses dados, primeiro precisamos carregá-los em nosso programa. A LibROSA nos ajuda a fazer isso convertendo o arquivo de áudio em um formato que podemos analisar:
# Load the audio file
# Duration is limited to 10 seconds for this example
audio_path = 'audio_sample.wav'
y, sr = librosa.load(audio_path, duration=10)
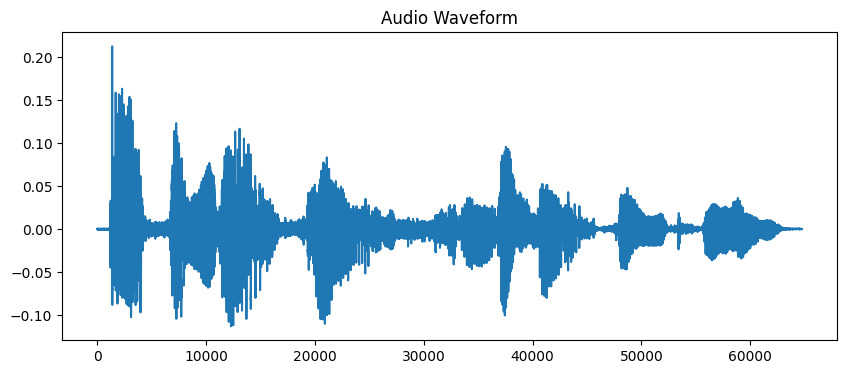
# Display the waveform
plt.figure(figsize=(10, 4))
plt.plot(y)
plt.title('Audio Waveform')
plt.show()Saída:
Agora que temos nosso áudio carregado, precisamos extrair recursos significativos dele. Nossos ouvidos dividem naturalmente o som em diferentes componentes de frequência, e o MFCC imita esse processo. Usamos a função de extração de recursos do librosa para calcular esses coeficientes:
# Extract MFCC features
mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13)
# Display the MFCC
plt.figure(figsize=(10, 4))
librosa.display.specshow(mfccs, x_axis='time')
plt.colorbar(format='%+2.0f dB')
plt.title('MFCC')
plt.show()Saída:
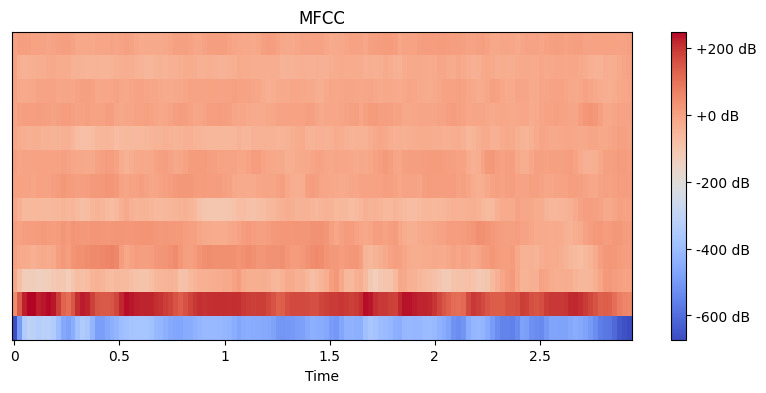
Aqui, definimos n_mfcc=13 porque os primeiros 13 coeficientes normalmente capturam os aspectos mais importantes do som que ajudam em tarefas como o reconhecimento de fala. A visualização resultante mostra como esses recursos mudam ao longo do tempo, onde as cores mais brilhantes representam valores mais altos.
Primeiro, vamos instalar as bibliotecas necessárias. Usaremos o site yfinance para obter dados financeiros, juntamente com o site tsfresh para extração de recursos:
# Install required libraries
# Run these commands in your terminal or command prompt
pip install tsfresh
pip install pandas
pip install numpy
pip install matplotlib
pip install yfinanceAgora vamos importar nossas bibliotecas e buscar alguns dados financeiros reais:
# Import required libraries
import pandas as pd
import numpy as np
from tsfresh import extract_features
from tsfresh.feature_extraction import MinimalFCParameters
import matplotlib.pyplot as plt
import yfinance as yfVamos obter alguns dados reais do mercado de ações. Usaremos os dados das ações da Apple como exemplo:
# Download Apple's stock data for the last 2 years
aapl = yf.Ticker("AAPL")
df = aapl.history(period="2y")
# Prepare the data in the format tsfresh expects
df_tsfresh = pd.DataFrame({
'id': [0] * len(df), # Each time series needs an ID
'time': range(len(df)),
'closing_price': df['Close'] # We'll use closing prices
})
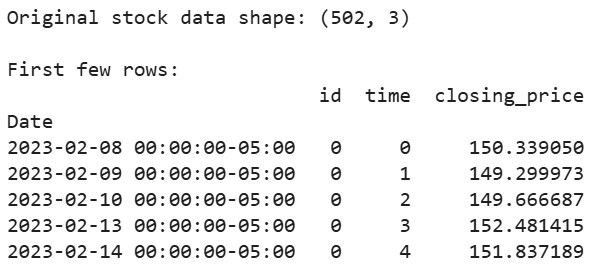
# Display first few rows of our data
print("Original stock data shape:", df_tsfresh.shape)
print("\nFirst few rows:")
print(df_tsfresh.head())Saída:
Agora vamos extrair recursos de nossos dados financeiros de série temporal:
# Set up the feature extraction parameters
extraction_settings = MinimalFCParameters()
# Extract features automatically
extracted_features = extract_features(df_tsfresh,
column_id='id',
column_sort='time',
column_value='values',
default_fc_parameters=extraction_settings)
# Display the extracted features
print("\nExtracted features shape:", extracted_features.shape)
print("\nExtracted features:")
print(extracted_features.head())Saída:

Aqui, usamos o siteMinimalFCParameters() para especificar quais recursos serão extraídos. Isso nos dá um conjunto básico de recursos significativos de séries temporais, como média, variância e características de tendência, que são essenciais para entender os padrões em nossos dados.
Quando trabalhamos com a extração de recursos, frequentemente nos deparamos com desafios.
A alta dimensionalidade e as restrições computacionais geralmente surgem ao lidar com grandes conjuntos de dados. Por exemplo, a extração de recursos de imagens de alta resolução ou de arquivos de áudio longos pode consumir muita memória e poder de processamento.
O excesso de ajuste devido a recursos irrelevantes ou redundantes é outro desafio comum. Quando muitos recursos são extraídos, os modelos podem aprender ruídos em vez de padrões significativos. Isso é especialmente comum no processamento de imagens e áudio, em que milhares de recursos podem ser gerados.
Para superar esses desafios, considere estas estratégias:
Esses desafios exigem uma consideração cuidadosa e o equilíbrio entre a riqueza de recursos e a eficiência computacional.
A extração de recursos é uma habilidade fundamental no aprendizado de máquina que transforma dados brutos em representações significativas. Por meio de nossos exemplos práticos com OpenCV, LibROSA e tsfresh, vimos como extrair recursos de diferentes tipos de dados. Ao compreender essas técnicas e seus desafios, podemos criar modelos eficazes de aprendizado de máquina.
Você está pronto para se aprofundar? Dê uma olhada nestes recursos:
Principais cursos da DataCamp
Curso
Curso
Curso