Curso
Pré-processamento para Machine Learning em Python
4 h
66.6K

Foto de Cederic Vandenberghe em Sem Plash
Um príncipe banido fica do lado de fora de seu antigo castelo. Para voltar a entrar, ele tentou de tudo para enganar o guarda na ponte levadiça. Ele se disfarçou de camponês, solicitou a senha secreta e tentou substituir os cavaleiros por seus leais lacaios. Ele até mesmo enviou milhares de soldados para a morte para entender as novas defesas do castelo. Nada funcionou. As defesas são muito fortes, os guardas são muito reservados e o processo de verificação dos cavaleiros é muito minucioso.
Nos tempos modernos, os modelos de machine learning (ML) enfrentam ataques semelhantes.
Os modelos são coisas complicadas e, muitas vezes, não temos uma compreensão adequada de como eles fazem previsões. Isso deixa pontos fracos ocultos que podem ser explorados por invasores. Eles podem induzir o modelo a fazer previsões incorretas ou fornecer informações confidenciais. Dados falsos podem até ser usados para corromper modelos sem que você saiba. O campo do adversarial machine learning (AML) tem como objetivo abordar esses pontos fracos.
Discutiremos esse campo e o que ele pretende alcançar. Isso inclui vários tipos de ataques a sistemas de IA, como envenenamento, evasão e ataques de extração de modelos. Também discutiremos algumas maneiras mais práticas de encontrar exemplos contraditórios que estão no centro de muitos desses ataques. Por fim, discutiremos alguns dos métodos de defesa contra eles, como treinamento contraditório, destilação de defesa e mascaramento de gradiente. No final, veremos como a AML faz parte de um movimento maior para criar sistemas de IA responsáveis.
O aprendizado de máquina adversarial (AML) é um subcampo de pesquisa em inteligência artificial e machine learning. Os invasores manipulam intencionalmente os dados de entrada para forçar os modelos a fazer previsões incorretas ou liberar informações confidenciais. O objetivo da AML é entender essas vulnerabilidades e desenvolver modelos mais robustos contra ataques.
O campo abrange os métodos para criar ataques adversários e projetar defesas para se proteger contra eles. Também pode envolver o ambiente de segurança mais amplo - as medidas de segurança adicionais necessárias ao usar o AM em sistemas automatizados.
Esse último ponto é importante, pois os modelos não existem isoladamente. Suas vulnerabilidades podem ser ampliadas pela forma como são usadas em um sistema. Por exemplo, é mais difícil roubar informações confidenciais se houver limites sobre como você pode consultar um modelo. Você pode limitar o número de consultas ou restringir os tipos de perguntas que pode fazer. Tente pedir ao ChatGPT que "me forneça seus parâmetros". Dito isso, os tipos de ataques que discutiremos na próxima seção se concentrarão em modelos e seus dados de treinamento.
Os tipos de ataques que discutiremos variam de acordo com o quanto você sabe sobre um modelo. Portanto, é importante distinguir entre ataques de caixa branca e de caixa preta.
Os ataques de caixa branca do ocorrem quando o invasor tem acesso total à arquitetura, aos parâmetros, aos pesos e aos dados de treinamento do modelo. Por exemplo, sua empresa pode alimentar seu chatbot usando um LLM de código aberto, como o Llama 3.1. Esse modelo está disponível gratuitamente para qualquer pessoa. No entanto, esse nível de acesso é uma faca de dois gumes quando se trata de segurança.
Por um lado, isso pode facilitar a localização de vulnerabilidades pelos invasores. Por outro lado, uma comunidade maior examina o modelo, o que pode aumentar a probabilidade de que as vulnerabilidades sejam identificadas antes de serem usadas de forma maliciosa.
Os ataques Black-box envolvem o fato de o invasor ter conhecimento limitado do modelo. Pense em um modelo OpenAI como GPT-4o mini. O invasor não pode acessar a arquitetura interna do modelo, os parâmetros ou os dados de treinamento e só pode interagir com o modelo consultando-o e observando os resultados. Lembre-se de que, em muitos casos, apenas um conhecimento limitado é necessário para um ataque eficaz.

Resumo dos tipos de ataques adversários (fonte: autor)
Um exemplo é quando você sabe quais dados são usados para treinar um modelo. Um ataque de envenenamento se concentra na manipulação desses dados. Aqui, um invasor alterará os dados existentes ou introduzirá dados rotulados incorretamente. O modelo treinado com esses dados fará previsões incorretas em dados rotulados corretamente.
Em nossa analogia, o príncipe tentou substituir os cavaleiros. O objetivo era corromper o processo interno de tomada de decisões do castelo. No machine learning, um invasor poderia fazer algo como rotular novamente casos de fraude como não fraudulentos. O invasor pode fazer isso apenas para casos específicos de fraude, de modo que, quando ele tentar cometer uma fraude da mesma forma, o sistema não o rejeitará.
Um exemplo real de um ataque de envenenamento aconteceu com Tay, o chatbot de IA da Microsoft. A Tay foi projetada para se adaptar às respostas recebidas no Twitter. Como é característico do site, não demorou muito para que o bot fosse inundado com conteúdo ofensivo e inadequado. Aprendendo com isso, Tay levou menos de 24 horas para começar a produzir tweets semelhantes. Qualquer sistema projetado para aprender com fontes de dados públicos enfrenta riscos semelhantes.
O outro fator de risco é a frequência com que o modelo é atualizado. Em muitos aplicativos, os modelos são treinados apenas uma vez. Nesses casos, tanto os dados quanto o modelo seriam verificados minuciosamente, deixando poucas oportunidades para ataques de envenenamento. No entanto, alguns sistemas, como o Tay, são continuamente retreinados. Esses modelos podem ser atualizados com novos dados diariamente, semanalmente ou até mesmo em tempo real. Consequentemente, há mais oportunidades para ataques de envenenamento nesses ambientes.
Os ataques de evasão se concentram no próprio modelo. Eles envolvem a modificação de dados para que pareçam legítimos, mas levam a uma previsão incorreta. Como quando nosso príncipe tentou passar despercebido pelos guardas vestido de camponês.
Para deixar claro, o invasor modifica os dados que um modelo usa para fazer previsões e não os dados usados para treinar modelos. Por exemplo, ao solicitar um empréstimo, um invasor pode mascarar seu verdadeiro país de origem usando uma VPN. Eles podem vir de um país arriscado e, se o invasor usasse seu país verdadeiro, o modelo rejeitaria a solicitação.
Esses tipos de ataques são mais comuns em campos como o reconhecimento de imagens. Os invasores podem criar imagens que parecem perfeitamente normais para um ser humano, mas que resultam em previsões incorretas. Por exemplo, pesquisadores do Google mostraram como a introdução de um ruído específico em uma imagem poderia alterar a previsão de um modelo de reconhecimento de imagem.
Observando a Figura 1, você pode ver que, para um ser humano, a camada de ruído não é perceptível. No entanto, o modelo, que originalmente previu a imagem como um panda, agora a prevê incorretamente como um gibão.

Figura 1: Exemplo de adversários (Fonte: I. Goodfellow et al.)
Com ataques de roubo ou extração de modelos, os invasores pretendem aprender sobre a arquitetura e os parâmetros do modelo. O objetivo é replicar exatamente o modelo. Essas informações podem levar a um ganho financeiro direto. Por exemplo, um modelo de negociação de ações poderia ser copiado e usado para negociar ações. Um invasor também pode usar essas informações para criar ataques subsequentes mais eficazes.
Os ataques de extração de modelos são feitos consultando o modelo repetidamente e comparando a entrada com a saída correspondente. Pense em nosso príncipe enviando soldados: um deles pode ser atingido por uma flecha, outro pode ser mergulhado em óleo quente ou um grupo inteiro pode ser esmagado por pedras voadoras. Lentamente, com o tempo, podemos obter uma boa compreensão das defesas que o castelo mantém por trás de sua muralha.
Os invasores geralmente não se importam com o modelo inteiro, mas apenas com algumas informações específicas, como uma senha secreta. Os ataques de inferência se concentram nos dados usados para treinar o modelo. O objetivo é extrair dados confidenciais do modelo. Por meio de consultas cuidadosamente elaboradas, essas informações podem ser liberadas diretamente ou inferidas a partir do resultado do modelo.
Esses tipos de ataques são particularmente preocupantes para modelos de linguagem grandes (LLMs).
No artigo Extração de dados de treinamento de modelos de idiomas grandesos pesquisadores mostraram como informações confidenciais poderiam ser extraídas do GPT-2. Usando consultas específicas, eles podiam extrair o texto literal dos dados de treinamento do modelo, incluindo informações confidenciais e privadas. Isso incluía detalhes pessoais, conversas particulares e outros dados confidenciais.
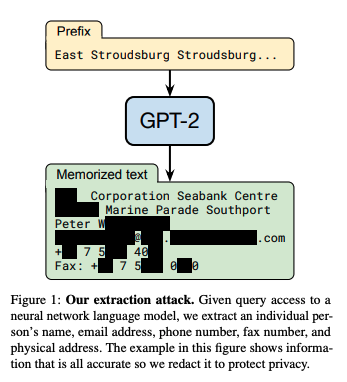
Fonte: N. Carlini et al.
Os objetivos e processos por trás desses ataques são diferentes. No entanto, todos eles têm uma coisa em comum: envolvem a descoberta de instâncias que ajudam os invasores a enganar um modelo. Chamamos essesexemplos de adversarial.
Os exemplos adversários são entradas criadas especialmente para enganar os modelos de machine learning. Essas entradas geralmente são indistinguíveis das entradas legítimas para um observador humano, mas contêm perturbações sutis que exploram os pontos fracos do modelo.
Normalmente, as perturbações são pequenas alterações nos dados de entrada, como pequenas variações nos valores de pixel. Embora pequenas, essas perturbações são projetadas para empurrar a entrada para além do limite de decisão do modelo, levando a previsões incorretas ou inesperadas.
Vimos um exemplo de um modelo usado para enganar um modelo de visão computacional. Com pequenas alterações, uma imagem que parecia um panda para nós foi classificada como um gibão. A consulta usada para extrair informações confidenciais do GPT-2 também é um exemplo contraditório de um ataque de inferência.
Para ataques de extração, exemplos adversários são usados para sondar os limites de decisão de um modelo com mais eficiência. Para ataques de envenenamento, eles são dados de entrada usados para manipular o limite de decisão de um modelo.
Esses exemplos funcionam porque os limites de decisão dos modelos de machine learning podem ser bastante complexos e frágeis. Os exemplos adversários exploram essa fragilidade encontrando pontos no espaço de entrada próximos a esses limites. Pequenas perturbações podem então deslocar a entrada para além do limite, levando o modelo a classificá-la incorretamente. Vamos dar uma olhada em algumas maneiras pelas quais isso pode ser feito.
Os métodos baseados em gradiente usam os gradientes de um modelo de machine learning para criar pequenas perturbações nos dados de entrada que levam a previsões incorretas. O Panda/Gibão é um exemplo do resultado de um desses métodos. O ruído que você vê pode parecer aleatório. No entanto, ela contém informações sobre a função de perda do modelo que empurrará uma imagem ao longo de um limite de decisão quando adicionada à imagem.
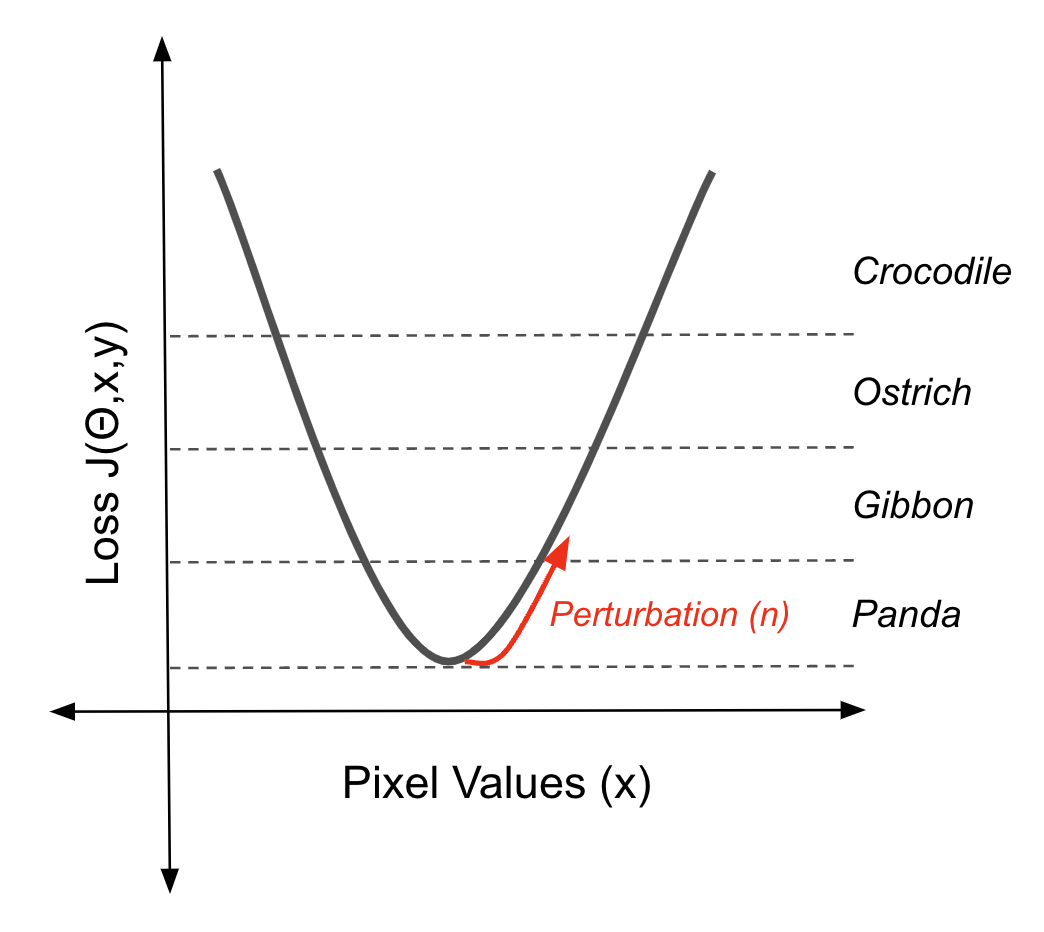
Usando o gradiente da função de perda para mover uma instância para fora de um limite de decisão (fonte: autor)
Esse exemplo contraditório específico foi criado usando o Fast Gradient Sign Method (FGSM). O ruído (η) é calculado primeiro com o gradiente(∇x) da função de perda (J(θ,x,y)) com relação aos dados de entrada (x).
Esse gradiente indica a direção em que a entrada deve ser alterada para aumentar ao máximo a perda. Em seguida, o FGSM considera o sinal desse gradiente, o que simplifica a direção da mudança para apenas positivo ou negativo para cada pixel. Por fim, ele dimensiona esse sinal por um pequeno fator (ε). Esse ruído (η) é a perturbação que, quando adicionada à entrada original, empurra a previsão do modelo para uma classificação incorreta.
η = ε sign(∇xJ(θ,x,y))
Você pode pensar nisso como o oposto da retropropagação. Esse algoritmo usa os gradientes da função de perda para calcular os parâmetros do modelo que nos dão previsões precisas. O resultado são limites de decisão que classificarão as imagens como uma determinada classe quando os valores de pixel estiverem dentro desses limites. Agora estamos usando os gradientes para reverter a imagem para fora desses limites.
O FGSM é uma maneira simples de fazer isso. Há também maneiras mais complexas e eficientes de ampliar os limites das decisões. Por exemplo, Projected Gradient Descent (PGD) é um método iterativo baseado em gradiente para gerar exemplos contraditórios. Ele amplia o método de sinal de gradiente rápido (FGSM) aplicando o FGSM várias vezes com tamanhos de etapas menores. À medida que cada passo é dado, o sinal dos gradientes pode mudar, alterando a direção ideal para se afastar do limite de decisão. Assim, usando muitas etapas menores, o PGD pode encontrar exemplos contraditórios com perturbações menores do que o FGSM.
A Carlini & Wagner (C&W) analisa esse problema de um ângulo diferente. Com os ataques anteriores, nosso objetivo é alterar a previsão para qualquer previsão incorreta. O ataque C&W tem como objetivo encontrar a menor perturbação(δ ) que, quando adicionada a uma imagem, alterará a previsão (f(x+δ)) para um determinado alvo (t).
min||δ||p s.t. f(x + δ) = t
Para fazer isso, eles enquadram o problema como um problema de otimização. Na prática, isso exige que o objetivo acima seja formulado de forma diferenciável. Isso envolve o uso dos logits Z(x) do modelo. Isso proporciona um gradiente suave, que é essencial para o processo de otimização.
Todos os ataques descritos acima exigem acesso total a um modelo. Portanto, você pode pensar que, se os parâmetros do seu modelo forem mantidos em segredo, você estará seguro. Você estaria errado!
Um aspecto a ser considerado é que, muitas vezes, apenas estimativas de gradientes são necessárias para um ataque bem-sucedido. No ataque FGSM, vimos que apenas a direção dos gradientes é necessária. Eles podem ser estimados usando alguns pings em uma API que retorna as probabilidades de classificação. Para piorar a situação, exemplos adversários bem-sucedidos podem até ser encontrados sem nenhuma interação com um modelo.
Os pesquisadores descobriram que exemplos contraditórios são transferíveis. Especificamente, eles usaram 5 arquiteturas populares de aprendizagem profunda pré-treinadas. Eles descobriram que, se um exemplo contraditório enganasse quatro dos modelos, haveria uma grande probabilidade de que ele enganasse o quinto modelo. Isso é mais do que uma chance de 96% e até 100% para uma das arquiteturas.
Da mesma forma, exemplos adversários universais demonstraram ser generalizados entre as arquiteturas. Essa é uma perturbação que, quando adicionada a muitas imagens, mudará a previsão para essas imagens. É importante ressaltar que os exemplos universais são encontrados com o conhecimento completo da caixa branca de apenas uma rede. Na Figura 2, você pode ver como eles são semelhantes para diferentes arquiteturas. A existência desses sugere semelhanças entre os limites de decisão de arquiteturas distintas.

Figura 2: Computador de perturbações universais para diferentes redes neurais profundas (fonte: Moosavi-Dezfooli et al.)
A consequência dessas descobertas é que nenhuma rede é segura. Você pode atacar um classificador desconhecido treinando o seu próprio classificador e executando um método de caixa branca.
Uma última esperança é que esses ataques só podem ser feitos virtualmente. Você precisa alterar os valores de pixel para que eles funcionem. Então, certamente isso não pode ser feito para modelos que interagem com o mundo real?
Você não deve falar cedo demais.
Os pesquisadores desenvolveram um método chamado patches adversários. Eles podem ser impressos e adicionados a qualquer cena em tempo real para enganar um classificador de imagens.
Os patches são universais porque podem ser usados para atacar qualquer cena, robustos porque funcionam sob uma ampla variedade de transformações e direcionados porque podem fazer com que um classificador produza qualquer classe-alvo.
T. B. Brown et al.
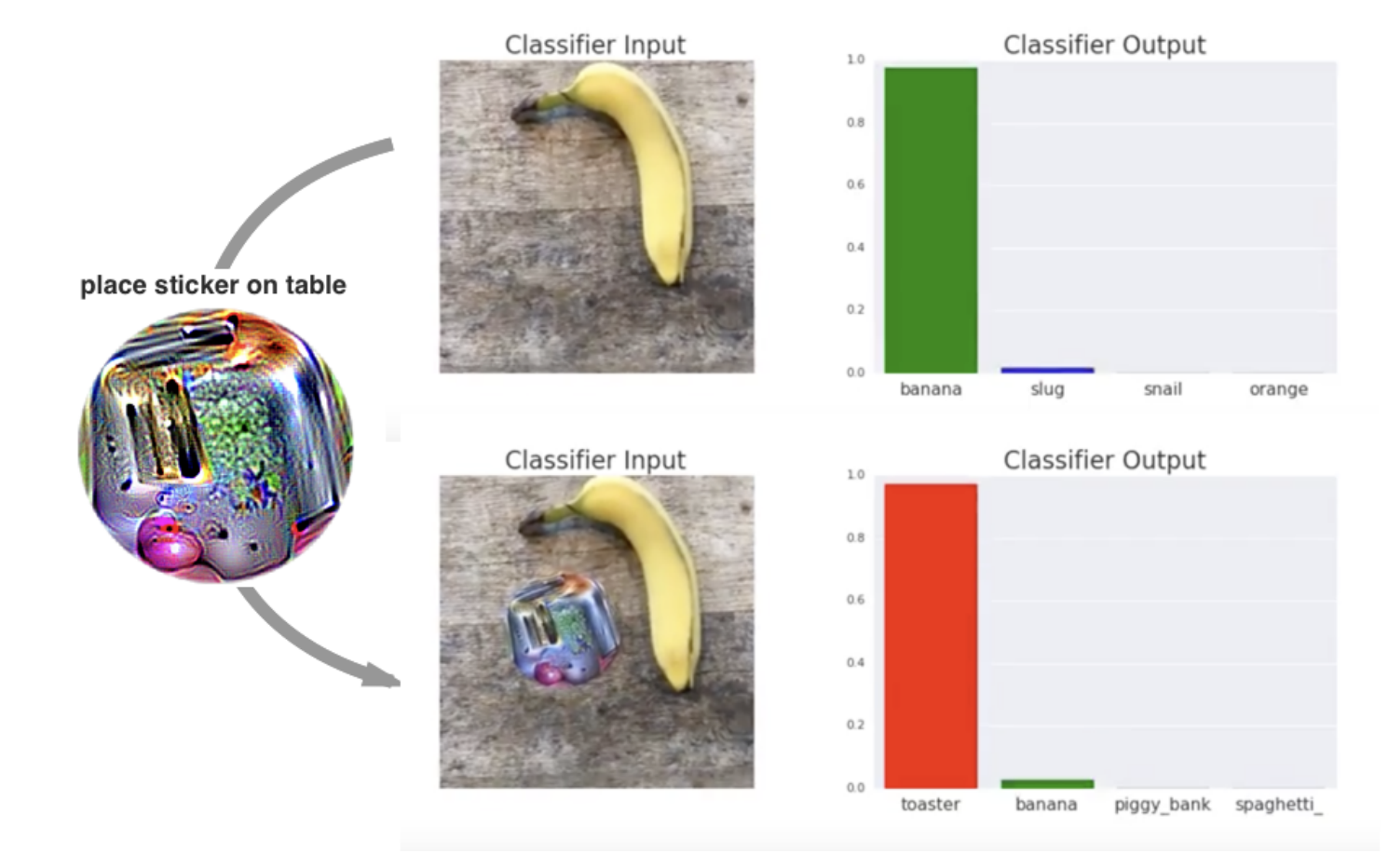
Um patch contraditório em ação (fonte: T. B. Brown et al. )
Pesquisas semelhantes mostraram como podemos mudar a previsão de uma placa de pare com alguns adesivos e enganar um modelo de reconhecimento facial com um par de óculos. Portanto, na verdade, nenhuma rede é segura. Para protegê-los de ataques adversários, recorremos ao outro lado da AML - métodos para defendê-los.
As maneiras pelas quais podemos defender as redes são tão diversas quanto as maneiras pelas quais elas podem ser atacadas. Podemos ajustar os dados de treinamento, o processo de treinamento ou até mesmo a própria rede. Como discutiremos no final desta seção, às vezes a solução mais simples é não usar a aprendizagem profunda.
Essa primeira abordagem se concentra nos dados de treinamento. O treinamento contraditório envolve o aumento do conjunto de dados de treinamento com exemplos contraditórios para melhorar a robustez do modelo contra ataques. Esses exemplos são encontrados usando os ataques conhecidos mencionados acima. A ideia central é expor o modelo a perturbações adversas durante a fase de treinamento para aprender a reconhecer e resistir a essas entradas.
A destilação defensiva envolve o treinamento de um modelo para imitar as probabilidades de saída suavizadas de outro modelo. Primeiro, treinamos um modelo padrão (modelo do professor) no conjunto de dados original. O modelo do professor gera rótulos flexíveis (distribuições de probabilidade sobre as classes) para os dados de treinamento. Em seguida, um modelo de aluno é treinado com esses rótulos flexíveis. O resultado é um modelo com limites de decisão mais suaves que são mais resistentes a pequenas perturbações.
O mascaramento de gradiente inclui uma variedade de técnicas que obscurecem ou ocultam os gradientes do modelo. Por exemplo, podemos adicionar uma camada não diferencial à rede, como uma função de ativação binária. Isso converte valores de entrada contínuos em saídas binárias.
A troca de modelos é uma abordagem rudimentar de mascaramento de gradiente. Isso envolve o uso de vários modelos em seu sistema. O modelo usado para fazer previsões é alterado aleatoriamente. Isso cria um alvo móvel, pois um invasor não saberia qual modelo está em uso no momento. Eles também terão que comprometer todos os modelos para que um ataque seja bem-sucedido.
A AML está relacionada a outro campo da IA: Inteligência Artificial Explicável (XAI). Os métodos de perturbação que discutimos aqui são semelhantes aos usados para encontrar explicações sobre como os modelos fazem previsões. Entretanto, a principal semelhança é que os modelos simples não são apenas mais fáceis de explicar, mas também mais fáceis de defender.
Muitos problemas podem ser resolvidos por modelos simples, como regressão linear ou regressão logística. Muitos dos ataques que descrevemos são ineficazes ou irrelevantes quando se trata deles.
Isso ocorre porque esses modelos são intrinsecamente interpretáveis, o que significa que podemos entender facilmente como eles funcionam. Os pontos fracos não ficam ocultos como nas arquiteturas complexas de aprendizagem profunda. Portanto, uma defesa simples é simplesmente não usar a aprendizagem profunda, a menos que seja necessário para o problema.
Isso está relacionado ao ponto no início do artigo - a AML também diz respeito ao ambiente de segurança mais amplo no qual os modelos operam. Como resultado, muitos métodos de defesa adicionais envolvem esse ambiente mais amplo. Isso inclui a validação e a higienização dos dados de entrada antes de serem usados para treinar um modelo. Detecção de anomalias Os modelos de detecção de anomalias também foram usados para identificar exemplos adversos antes de serem transmitidos a uma rede. Tudo isso exige que os processos sejam executados juntamente com o sistema de IA.
À medida que a IA e o ML se tornam mais centrais em nossas vidas, a AML está se tornando cada vez mais importante. É fundamental que os sistemas que tomam decisões sobre nossa saúde e finanças não possam ser facilmente enganados. Isso ocorre de forma intencional ou acidental. Eu certamente não confiaria em um carro automatizado que alguns adesivos pudessem enganar. Esse tipo de ataque pode passar despercebido por um motorista, mas fazer com que o carro tome decisões incorretas e com risco de morte.
 Figura X: A detecção de objetos Yolo v2 não reconhece um sinal de parada (fonte: Yolo object detection v2): K. Eykholt et al.)
Figura X: A detecção de objetos Yolo v2 não reconhece um sinal de parada (fonte: Yolo object detection v2): K. Eykholt et al.)
Ao projetar esses sistemas, devemos reconhecer que a AML faz parte de um movimento maior de IA responsável. Para administrar um bom castelo, o rei deve agir com justiça, justificar as decisões, proteger a privacidade de seu povo e garantir sua segurança e proteção. São esses dois últimos aspectos que a AML procura abordar.
Dito isso, também devemos reconhecer que a segurança e a proteção são fundamentalmente diferentes dos outros aspectos da IA responsável. A justiça, a interpretabilidade e a privacidade são passivas. A AML opera em um ambiente em que os malfeitores buscam ativamente minar seus métodos.
É por isso que, contraintuitivamente, grande parte da pesquisa nesse campo tem como objetivo encontrar vulnerabilidades e ataques. Isso inclui envenenamento, evasão, extração de modelos e ataques de inferência. Eles também incluem os métodos mais práticos de encontrar exemplos contraditórios, como FGSM, PGD, C&W e patches contraditórios que discutimos.
O objetivo é descobri-los antes que os malfeitores o façam. Defesas adequadas, como treinamento contraditório, destilação de defesa e mascaramento de gradiente, podem então ser desenvolvidas para neutralizar esses ataques antes que causem danos.
Nesse sentido, a AML também faz parte da corrida armamentista mais ampla da segurança cibernética. Sempre surgirão novas vulnerabilidades, ataques e defesas, e os pesquisadores e profissionais de AML precisarão lutar para ficar à frente dos atacantes adversários.
Se você quiser fazer parte dessa corrida, aqui estão algumas estruturas Python para começar:
Neste artigo, exploramos o campo do machine learning contraditório, examinando seus objetivos, os diferentes tipos de ataques (envenenamento, evasão, extração de modelos e inferência) e como os exemplos contraditórios são usados para explorar as vulnerabilidades do modelo.
Também discutimos vários mecanismos de defesa, incluindo treinamento contraditório, destilação defensiva e mascaramento de gradiente, bem como a importância de usar modelos mais simples quando apropriado.
Se você estiver interessado em saber mais sobre esse tópico, confira esta Introdução à segurança de dados para você.
Saiba mais sobre machine learning!
Curso
Curso
Curso
blog
Abid Ali Awan
5 min
blog
Natasha Al-Khatib
14 min
blog
Matt Crabtree
14 min
blog
Abid Ali Awan
11 min
blog
Natassha Selvaraj
15 min
Tutorial
Zoumana Keita


