
Programa
Llama Fundamentals
4 h
A Meta acaba de anunciar o conjunto de modelos Llama 4, que inclui dois modelos lançados - Llama4 Scout e Llama 4 Maverick- e um terceiro ainda em treinamento: Llama 4 Behemoth.
As variantes Scout e Maverick já estão disponíveis, lançadas abertamente sob a típica licença de peso aberto da Meta, com uma ressalva notável: se os seus serviços excederem 700 milhões de usuários ativos mensais, você deverá obter uma licença separada da Meta, que poderá ou não ser concedida a seu critério.
O Llama Scout suporta uma janela de contexto de 10 milhões de tokens, a maior de qualquer modelo lançado publicamente. O Llama Maverick é um modelo generalista e tem como objetivo o GPT-4o, o Gemini 2.0 Flash e o DeepSeek-V3. Llama Behemoth, ainda em treinamento, serve como um modelo de professor de alta capacidade.
Nossa equipe está testando ativamente o modelo, e publicaremos blogs separados sobre o ajuste fino do Llama 4, executando-o no vLLMe testando sua enorme janela de contexto - atualizarei este artigo com links assim que eles estiverem prontos. Neste blog introdutório, darei a você uma visão geral do pacote Llama 4.
Mantemos nossos leitores atualizados sobre as últimas novidades em IA enviando o The Median, nosso boletim informativo gratuito de sexta-feira que detalha as principais histórias da semana. Inscreva-se e fique atento em apenas alguns minutos por semana:
O Llama 4 é a nova família de modelos de idiomas grandes do Meta. O lançamento inclui dois modelos já disponíveis - Llama 4 Scout e Llama 4 Maverick - e um terceiro, Llama 4 Behemoth, ainda em treinamento.

Fonte: Meta AI
O Llama 4 apresenta aprimoramentos substanciais. Notavelmente, ele incorpora uma mistura de especialistas (MoE) com o objetivo de melhorar a eficiência e o desempenho ativando apenas os componentes necessários para tarefas específicas (falaremos mais sobre isso daqui a pouco). Esse design representa uma mudança em direção a modelos de IA mais dimensionáveis e especializados.
O Llama 4 dá continuidade à estratégia da Meta de lançar modelos de peso aberto, mas com uma ressalva. Se a sua empresa opera serviços com mais de 700 milhões de usuários ativos mensais, você precisará de uma licença separada da Meta, que poderá ou não ser concedida. Deixando de lado essa limitação, o lançamento ainda parece ser um evento importante no cenário de peso aberto, embora o próprio cenário tenha mudado rapidamente nos últimos meses.
Se as Llama 2 e 3 já definiram a categoria, a Llama 4 agora entra em um campo muito mais competitivo. DeepSeek chegou com fortes recursos de raciocínio. A empresa do Alibaba Qwen da Alibaba teve um bom desempenho em benchmarks multilíngues e de codificação. A Gemma do Google, estão entrando no mesmo espaço com arquiteturas menores e eficientes. E, há poucos dias, a OpenAI anunciou planos para lançar um modelo de peso aberto, uma mudança que pareceria improvável há um ano.
Vamos descobrir mais detalhes sobre cada modelo.
O Llama 4 Scout é o modelo mais leve da nova suíte, mas é indiscutivelmente o mais intrigante. Ele é executado em uma única GPU H100 e suporta uma janela de contexto de 10 milhões de tokens. Isso faz do Scout o modelo de peso aberto mais exigente em termos de contexto lançado até o momento e, possivelmente, o mais útil para tarefas como resumo de vários documentos, raciocínio de código longo e análise de atividades.

O Scout tem 17 bilhões de parâmetros ativos, organizados por 16 especialistas, com uma contagem total de parâmetros de 109 bilhões. Ele foi pré-treinado e pós-treinado com uma janela de contexto de 256K, mas o Meta diz que ele generaliza bem além disso (essa afirmação ainda precisa ser testada). Na prática, isso abre a porta para fluxos de trabalho que envolvem bases de código inteiras, históricos de sessões ou documentos legais, todos processados em uma única passagem.
Arquitetonicamente, o Scout foi criado usando a estrutura de mistura de especialistas (MoE) do Meta, em que apenas um subconjunto de parâmetros é ativado por token, ao contrário de modelos densos como o GPT-4o, em que todos os parâmetros são ativados. Isso significa que ele é eficiente em termos de computação e altamente dimensionável.
Além da arquitetura principal, o Meta enfatizou a multimodais do Scout. Ele foi pré-treinado em dados de texto, imagem e vídeo usando a fusão antecipada, o que lhe permite lidar com combinações de texto e avisos visuais de forma nativa. Em tarefas com muitas imagens, como aterramento visual e VQA (resposta a perguntas visuais), o Scout tem um desempenho melhor do que qualquer modelo anterior da Llama - e se mantém firme contra sistemas muito maiores.
Em resumo, o Scout foi criado para ser amplo e escalável. Ele foi projetado para funcionar com eficiência, lidar com mais entradas do que qualquer modelo aberto anterior e operar bem em tarefas de texto e imagem. Testaremos esse limite de 10 milhões de contextos em breve e informaremos a você.
O Llama 4 Maverick é o generalista da linha - um modelo multimodal em escala real criado para desempenho em bate-papo, raciocínio, compreensão de imagens e código. Enquanto o Scout ultrapassa os limites do comprimento do contexto, o Maverick se concentra em resultados equilibrados e de alta qualidade em todas as tarefas. É a resposta do Meta ao GPT-4o, DeepSeek-V3e ao Gemini 2.0 Flash.

O Maverick tem os mesmos 17 bilhões de parâmetros ativos que o Scout, mas com uma configuração MoE maior: 128 especialistas e uma contagem total de parâmetros de 400 bilhões. Assim como o Scout, ele usa uma arquitetura de mistura de especialistas, que ativa apenas parte do modelo por token, reduzindo o custo de inferência e aumentando a capacidade. O modelo é executado em um único host H100 DGX, mas também pode ser implantado com inferência distribuída para aplicativos de grande escala.
Aqui, a Meta adotou uma abordagem diferente para o pós-treinamento, usando uma combinação de supervisão leve e ajuste finoe online aprendizado por reforçoe otimização direta de preferências. O objetivo era aprimorar o desempenho em prompts difíceis sem sobrecarregar o modelo. Para isso, o Meta filtrou mais de 50% dos exemplos de treinamento marcados como "fáceis" pelos modelos anteriores do Llama e criou um currículo que enfatizava tarefas mais difíceis de raciocínio, codificação e multimodais.
O Maverick também foi co-destilado a partir do Llama 4 Behemoth, o modelo interno muito maior da Meta, o que ajudou a aumentar o desempenho sem aumentar o custo de treinamento. De acordo com o Meta, esse pipeline de destilação produziu um salto notável na qualidade do raciocínio e do bate-papo.
O Llama 4 Behemoth é o modelo mais potente e maior da Meta até o momento, mas ainda não está disponível. Ainda em treinamento, o Behemoth não é um modelo de raciocínio no mesmo sentido que o DeepSeek-R1 ou o o3 da OpenAIda OpenAI, que foram criados e otimizados para tarefas de cadeia de raciocínio de várias etapas.
Com base no que sabemos até agora, ele também não parece ter sido projetado como um produto para uso direto. Em vez disso, ele atua como um modelo de professor, usado para destilar e moldar tanto o Scout quanto o Maverick. Uma vez lançado, ele poderá permitir que outras pessoas também destilem seus próprios modelos.

O Behemoth tem 288 bilhões de parâmetros ativos, organizados por 16 especialistas, com uma contagem total de parâmetros próxima a 2 trilhões. A Meta criou uma infraestrutura de treinamento totalmente nova para dar suporte ao Behemoth nessa escala. Ele introduziu o aprendizado por reforço assíncrono, a amostragem de currículo com base na dificuldade do prompt e uma nova função de perda de destilação que equilibra dinamicamente alvos fáceis e difíceis.
O Behemoth pós-treinamento também exigiu uma receita diferente. O Meta descartou mais de 95% dos exemplos de SFT para restringir-se a solicitações difíceis e focar o aprendizado por reforço em cenários complexos de raciocínio, codificação e multilíngues. A amostragem de instruções variadas do sistema ajudou a generalizar o modelo, enquanto a filtragem dinâmica removeu prompts de baixo valor durante o treinamento de RL.
A Meta divulgou resultados de benchmark internos para cada um dos modelos Llama 4, comparando-os com as variantes anteriores do Llama e com vários modelos concorrentes de peso aberto e de fronteira.
Nesta seção, mostrarei a você os destaques de benchmark do Scout, Maverick e Behemoth, usando os números do próprio Meta. Como sempre, recomendo que você tenha cuidado com os benchmarks informados por você mesmo, mas essas pontuações oferecem uma primeira visão útil do desempenho de cada modelo em diferentes tarefas e de sua posição no cenário atual. Vamos começar com o Scout.
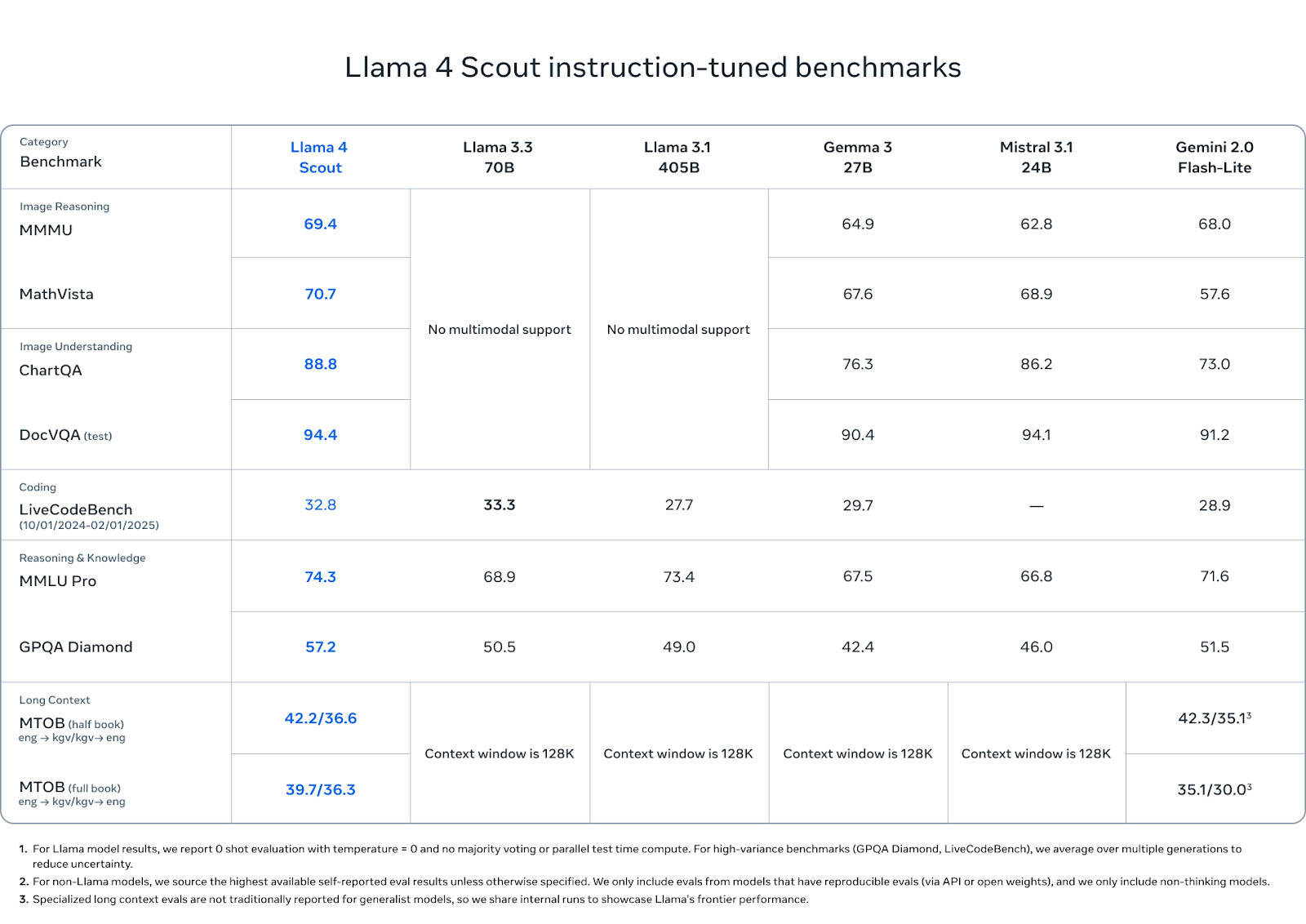
O Llama 4 Scout tem um bom desempenho em uma combinação de benchmarks de raciocínio, codificação e multimodais - especialmente considerando sua menor contagem de parâmetros ativos e a pegada de uma única GPU.
Fonte: MetaAI
No que diz respeito à compreensão de imagens, o Scout está à frente dos concorrentes: obteve 88,8 pontos no ChartQA e 94,4 no DocVQA (teste), superando o Gemini 2.0 Flash-Lite (73,0 e 91,2, respectivamente) e igualando ou superando ligeiramente o Mistral 3.1 e o Gemma 3 27B.
Em benchmarks de raciocínio de imagem como MMMU (69,4) e MathVista (70,7), ele também lidera o pacote de peso aberto, superando o Gemma 3 (64,9, 67,6), Mistral 3.1 (62,8, 68,9) e Gemini Flash-Lite (68,0, 57,6).
Em termos de codificação, o Scout obteve 32,8 pontos no LiveCodeBench, ficando à frente do Gemini Flash-Lite (28,9) e do Gemma 3 27B (29,7), embora ligeiramente atrás dos 33,3 do Llama 3.3. Não se trata de um modelo que prioriza a codificação, mas ele se sustenta.
Em conhecimento e raciocínio, o Scout atinge 74,3 no MMLU Pro e 57,2 no GPQA Diamond, superando todos os outros modelos de peso aberto em ambos. Esses benchmarks favorecem o raciocínio longo em várias etapas, portanto, o bom desempenho do Scout aqui é notável, especialmente nessa escala.
Por fim, os recursos de contexto longo do Scout mostram o potencial do mundo real. No MTOB (Massive Textual Overlap Benchmark), que testa a capacidade do modelo de traduzir entre o inglês e o KGV, um idioma com poucos recursos, ele obteve 42,2/36,6 pontos no teste de meio livro e 39,7/36,3 no teste de livro completo. No teste de meio livro, o Gemini 2.0 Flash-Lite está ligeiramente à frente com 42,3, mas o Scout fecha a lacuna no livro completo, superando os 35,1/30,0 do Gemini.
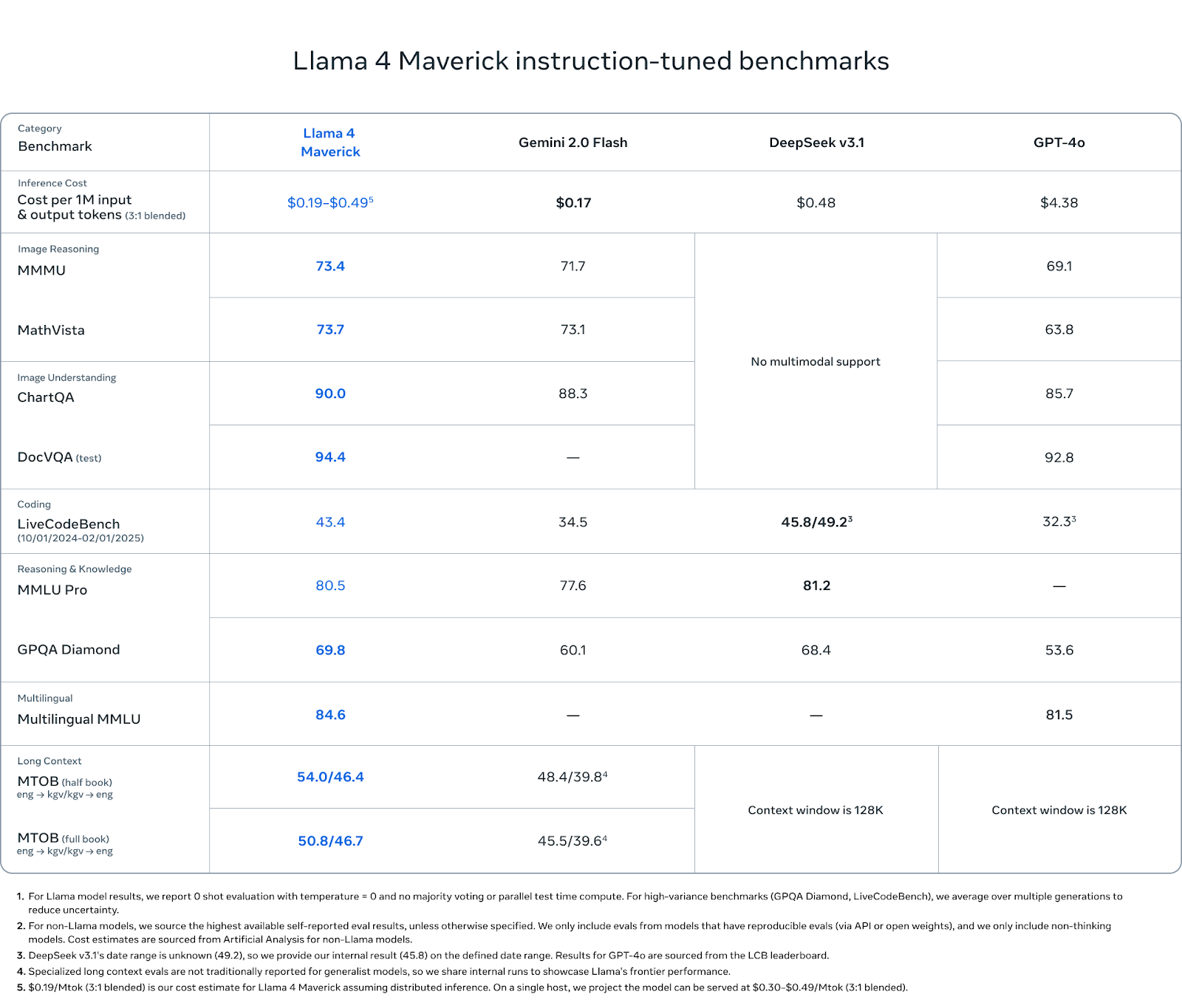
O Maverick é o modelo mais completo da linha Llama 4 - e os resultados de benchmark refletem isso. Embora não tenha como objetivo os extremos de comprimento de contexto do Scout ou a escala bruta do Behemoth, ele tem um desempenho consistente em todas as categorias importantes: raciocínio multimodal, codificação, compreensão de linguagem e retenção de contexto longo.
Fonte: MetaAI
No raciocínio de imagens, o Maverick obteve 73,4 pontos no MMMU e 73,7 no MathVista, superando o Gemini 2.0 Flash (71,7 e 73,1) e o GPT-4o (69,1 e 63,8). No ChartQA (compreensão da imagem), ele obteve 90,0 pontos, um pouco acima dos 88,3 do Gemini e bem acima dos 85,7 do GPT-4o. No DocVQA, o Maverick atinge 94,4, igualando-se ao Scout e superando os 92,8 do GPT-4o.
Na codificação, o Maverick obteve 43,4 pontos no LiveCodeBench, ficando acima do GPT-4o (32,3), do Gemini Flash (34,5) e próximo dos 45,8 do DeepSeek v3.1.
Em termos de raciocínio e conhecimento, o Maverick obteve 80,5 pontos no MMLU Pro e 69,8 no GPQA Diamond, superando novamente o Gemini Flash (77,6 e 60,1) e o GPT-4o (sem registro no MMLU Pro, 53,6 no GPQA). O DeepSeek v3.1 lidera por uma margem de 0,7 no MMLU Pro.
O Maverick também tem um bom desempenho na compreensão multilíngue, com pontuação de 84,6 no Multilingual MMLU, um pouco acima dos 81,5 do Gemini. Isso lhe dá uma vantagem para os desenvolvedores que trabalham em vários idiomas ou regiões geográficas.
Nas avaliações de contexto longo (MTOB), o Maverick obteve 54,0/46,4 pontos no teste de meio livro e 50,8/46,7 no de livro completo - significativamente à frente do Gemini, que obteve 48,4/39,8 e 45,5/39,6, respectivamente. Essas pontuações sugerem que, embora o Maverick não anuncie a duração de seu contexto de forma tão intensa quanto o Scout, ele ainda se beneficia significativamente de sua janela estendida.
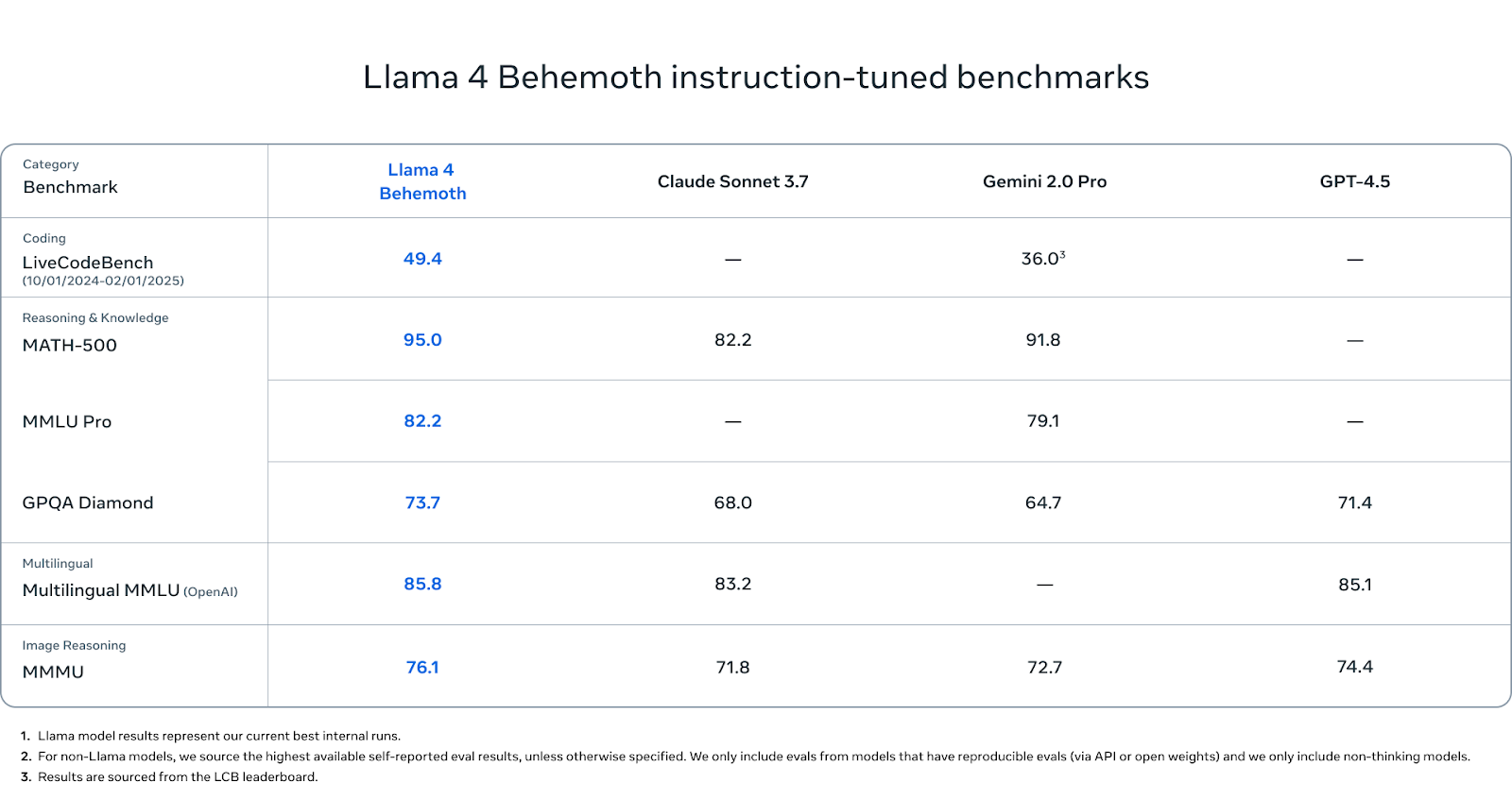
O Behemoth ainda não foi lançado, mas vale a pena prestar atenção em seus números de benchmark.
Fonte: MetaAI
Em benchmarks com alto índice de STEM, o Behemoth tem um desempenho excepcional. Ele obteve uma pontuação de 95,0 no MATH-500, superior à do Gemini 2.0 Pro (91,8) e significativamente acima do Claude Sonnet 3.7 (82.2). No MMLU Pro, o Behemoth tem pontuação de 82,2, enquanto o Gemini Pro tem 79,1 (o Claude não tem pontuação informada). E no GPQA Diamond, outro benchmark que recompensa a profundidade e a precisão dos fatos, o Behemoth atinge 73,7, à frente do Claude (68,0), Gemini (64,7) e GPT-4.5 (71.4).
Na compreensão multilíngue, o Behemoth obteve 85,8 pontos no Multilingual MMLU, superando ligeiramente o Claude Sonnet (83,2) e o GPT-4.5 (85,1). Essas pontuações são importantes para os desenvolvedores globais que trabalham fora do inglês, e a Behemoth atualmente lidera essa categoria.
Em termos de raciocínio de imagem, o Behemoth atinge 76,1 no MMMU, superando o Gemini (71,8), o Claude (72,7) e o GPT-4.5 (74,4). Embora esse não seja seu foco principal, ele ainda tem um desempenho competitivo em relação aos principais modelos multimodais.
Na geração de código, o Behemoth obteve 49,4 pontos no LiveCodeBench. Isso está bem acima do Gemini 2.0 Pro (36,0).
Tanto o Llama 4 Scout quanto o Llama 4 Maverick já estão disponíveis sob a licença de peso aberto do Meta. Você pode baixá-los diretamente do site oficial da site oficial da Llama ou por meio do Hugging Face.
Para acessar os modelos por meio dos próprios serviços do Meta, você pode interagir com o Meta AI em várias plataformas: WhatsApp, Messenger, Instagram e Facebook. Atualmente, o acesso exige que você faça login com uma conta do Meta e não há um ponto de extremidade de API independente para o Meta AI, pelo menos por enquanto.
Se você planeja integrar os modelos em seus próprios aplicativos ou infraestrutura, lembre-se da cláusula de licenciamento: se o seu produto ou serviço tiver mais de 700 milhões de usuários ativos mensais, você precisará obter permissão separada da Meta. Os modelos podem ser usados para pesquisa, experimentação e na maioria dos casos de uso comercial.
O Scout apresenta um comprimento de contexto sem precedentes em uma única GPU. O Maverick se destaca em relação a modelos maiores em tarefas de raciocínio, código e multimodais. E o Behemoth, ainda em treinamento, oferece um vislumbre de como os modelos de professores podem moldar variantes mais eficientes e implementáveis.
O espaço de peso aberto está mais competitivo do que nunca. DeepSeek, Qwen, Gemma e, em breve, OpenAI estão avançando com lançamentos sólidos. O Llama 4 é uma continuação do esforço contínuo da Meta para oferecer modelos dimensionáveis e disponíveis abertamente para uma variedade de casos de uso.
Aprenda IA com estes cursos!
Programa
Curso
Curso
blog
Abid Ali Awan
8 min
blog
Stanislav Karzhev
9 min
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Ryan Ong

